
Heim >Datenbank >MySQL-Tutorial >Ein umfassender Überblick über die MySql-Master-Slave-Synchronisierung in einem Artikel
Ein umfassender Überblick über die MySql-Master-Slave-Synchronisierung in einem Artikel

- 藏色散人nach vorne
- 2023-03-01 16:59:592097Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL. Er stellt hauptsächlich die Master-Slave-Synchronisation von MySQL und sein Funktionsprinzip usw. vor. Freunde, die interessiert sind, können es sich gemeinsam ansehen!
1 Einführung
Hallo allerseits, MySQL ist die am häufigsten verwendete Datenbank für alle. Im Folgenden werden Wissenspunkte zur MySQL-Master-Slave-Synchronisation weitergegeben, um die Grundkenntnisse von MySQL zu festigen Fehler, bitte lassen Sie es mich wissen.
2 Übersicht über die MySql-Master-Slave-Synchronisation
MySQL-Master-Slave-Synchronisation, nämlich MySQL-Replikation, kann Daten von einem Datenbankserver auf mehrere Datenbankserver synchronisieren. Die MySQL-Datenbank verfügt über eine Master-Slave-Synchronisationsfunktion. Nach der Konfiguration kann sie eine Master-Slave-Synchronisation in verschiedenen Schemata basierend auf Datenbank- und Tabellenstrukturen realisieren.
Redis ist eine leistungsstarke In-Memory-Datenbank, aber heute ist MySQL eine relationale Datenbank, die auf Festplattendateien basiert. Die Lesegeschwindigkeit ist langsamer, aber sie ist leistungsstark und kann verwendet werden zur Speicherung persistenter Daten. In der Praxis verwenden wir häufig Redis als Cache, wenn eine Datenzugriffsanforderung vorliegt. Wenn sie vorhanden ist, wird sie direkt herausgenommen. Auf die Datenbank wird erneut zugegriffen. Dadurch wird die Leistung verbessert und der Zugriffsdruck auf die Back-End-Datenbank verringert. Die Verwendung einer Cache-Architektur wie Redis ist ein sehr wichtiger Bestandteil einer Architektur mit hoher Parallelität.
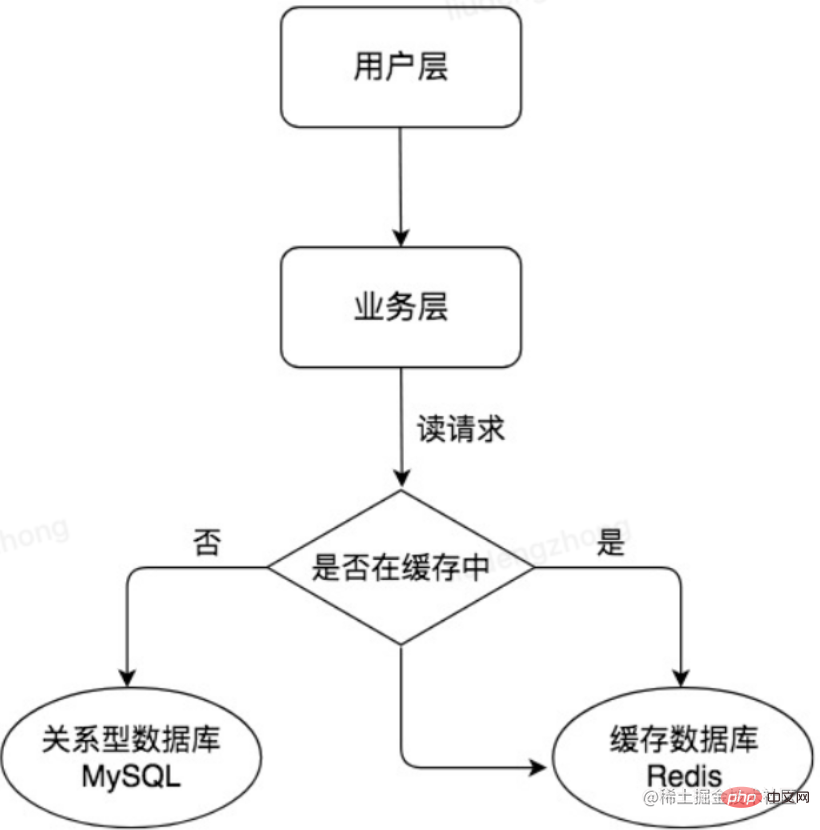
Mit dem kontinuierlichen Wachstum des Geschäftsvolumens wird der Druck auf die Datenbank weiter zunehmen. Häufige Änderungen im Cache hängen auch stark von den Abfrageergebnissen der Daten ab, was zu einer geringen Effizienz der Datenabfrage und einer hohen Auslastung führt. zu viele Verbindungen und andere Probleme. Für E-Commerce-Szenarien gibt es oft viele typische Szenarien mit mehr Lesen und weniger Schreiben. Wir können eine Master-Slave-Architektur für MySQL verwenden und Lese- und Schreibvorgänge trennen, sodass der Master-Server (Master) Schreibanfragen verarbeitet und der Slave-Server (Slave) verarbeitet Leseanfragen. Dadurch können die gleichzeitigen Verarbeitungsfähigkeiten der Datenbank weiter verbessert werden. Wie im Bild unten gezeigt:
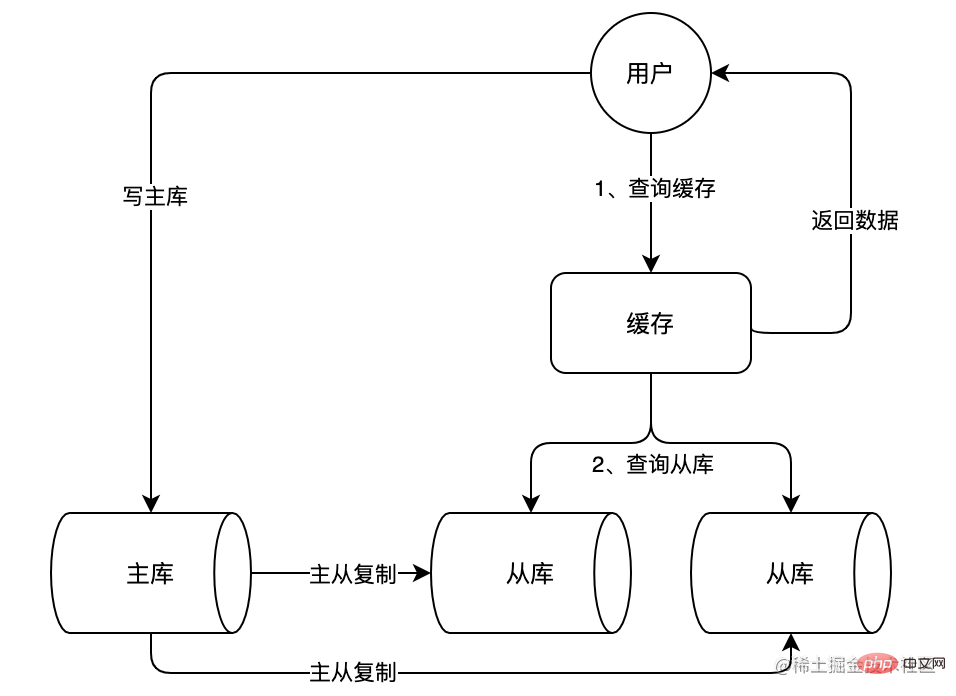
Im Bild oben können Sie sehen, dass wir zwei Slave-Bibliotheken hinzugefügt haben, die zusammen einer großen Anzahl von Leseanforderungen standhalten und den Druck auf die Hauptbibliothek teilen können. Die Slave-Datenbank synchronisiert kontinuierlich Daten aus der Master-Datenbank durch Master-Slave-Replikation, um sicherzustellen, dass die Daten in der Slave-Datenbank mit den Daten in der Master-Datenbank konsistent sind.
Als nächstes werfen wir einen Blick auf die Funktionen der Master-Slave-Synchronisation und wie die Master-Slave-Synchronisation implementiert wird.
3 Die Rolle der Master-Slave-Synchronisation
Im Allgemeinen müssen nicht alle Systeme eine Master-Slave-Architektur für die Datenbank entwerfen, da die Architektur selbst gewisse Kosten verursacht, wenn unser Ziel darin besteht, den hohen gleichzeitigen Zugriff zu verbessern Um die Datenbankeffizienz zu verbessern, sollten wir zunächst SQL-Anweisungen und Indizes optimieren, um die maximale Leistung der Datenbank auszuschöpfen. Zweitens sollten wir Caching-Strategien übernehmen, z. B. die Verwendung von Caching-Tools wie Redis und MongoDB, um Daten in In-Memory-Datenbanken zu speichern Durch ihre Hochleistungsvorteile besteht der letzte Schritt darin, eine Master-Slave-Architektur für die Datenbank einzuführen und Lese- und Schreibvorgänge zu trennen. Die Kosten für Systemnutzung und -wartung steigen mit der Aktualisierung der Architektur schrittweise an.
Um auf das Thema zurückzukommen: Die Master-Slave-Synchronisation kann nicht nur den Durchsatz der Datenbank verbessern, sondern hat auch die folgenden drei Aspekte:
3.1 Lese- und Schreibtrennung
Wir können Daten durch Master-Slave-Replikation synchronisieren , und dann Lese- und Schreibtrennung verbessert die gleichzeitige Verarbeitungsfähigkeit der Datenbank. Vereinfacht ausgedrückt werden unsere Daten in mehreren Datenbanken abgelegt, von denen eine die Master-Datenbank und der Rest die Slave-Datenbanken sind. Wenn sich die Daten in der Hauptdatenbank ändern, werden die Daten automatisch mit der Slave-Datenbank synchronisiert, und unser Programm kann Daten aus der Slave-Datenbank lesen, d. h. mithilfe einer Lese-/Schreib-Trennmethode. Bei E-Commerce-Anwendungen wird häufig „mehr gelesen und weniger geschrieben“, und durch die Trennung von Lesen und Schreiben kann ein höherer gleichzeitiger Zugriff erzielt werden. Ursprünglich wurde der gesamte Lese- und Schreibdruck von einem Server getragen. Jetzt verarbeiten mehrere Server gemeinsam Leseanforderungen, wodurch der Druck auf die Hauptdatenbank verringert wird. Darüber hinaus können Sie auch die Last der Slave-Server ausgleichen, sodass unterschiedliche Leseanforderungen gemäß der Richtlinie gleichmäßig auf verschiedene Slave-Server verteilt werden, was das Lesen reibungsloser macht. Ein weiterer Grund für ein reibungsloses Lesen besteht darin, die Auswirkungen von Sperrtabellen zu verringern. Wenn wir beispielsweise die Hauptbibliothek für das Schreiben verantwortlich machen, wirkt sich eine Schreibsperre in der Hauptbibliothek nicht auf den Abfragevorgang der Slave-Bibliothek aus.
3.2 Datensicherung
Die Master-Slave-Synchronisation entspricht auch einem Daten-Hot-Backup-Mechanismus, der im Normalbetrieb der Hauptdatenbank gesichert wird, ohne die Bereitstellung von Datendiensten zu beeinträchtigen.
3.3 Hochverfügbarkeit
Datensicherung ist eigentlich ein redundanter Mechanismus. Durch diese Redundanzmethode kann die hohe Verfügbarkeit der Datenbank ausgetauscht werden, wenn sie ausfällt und nicht verfügbar ist und lassen Sie die Slave-Datenbank als Master-Datenbank fungieren, um den normalen Betrieb des Dienstes sicherzustellen. Sie können sich über die Hochverfügbarkeits-SLA-Indikatoren der E-Commerce-Systemdatenbank informieren.
4 Prinzip der Master-Slave-Synchronisation
Apropos Prinzip der Master-Slave-Synchronisation: Wir müssen eine wichtige Protokolldatei in der Datenbank verstehen, nämlich die Binlog-Binärdatei, die Ereignisse aufzeichnet, die die Datenbank aktualisieren. Tatsächlich basiert sie auf dem Prinzip der Master-Slave-Synchronisation zur Datensynchronisation basierend auf Binlog.
Im Prozess der Master-Slave-Replikation basieren die Vorgänge auf drei Threads. Einer ist der Binlog-Dump-Thread, der sich auf dem Master-Knoten befindet. Die anderen beiden Threads sind der E/A-Thread und der SQL-Thread befinden sich auf dem Slave-Knoten, wie unten gezeigt:
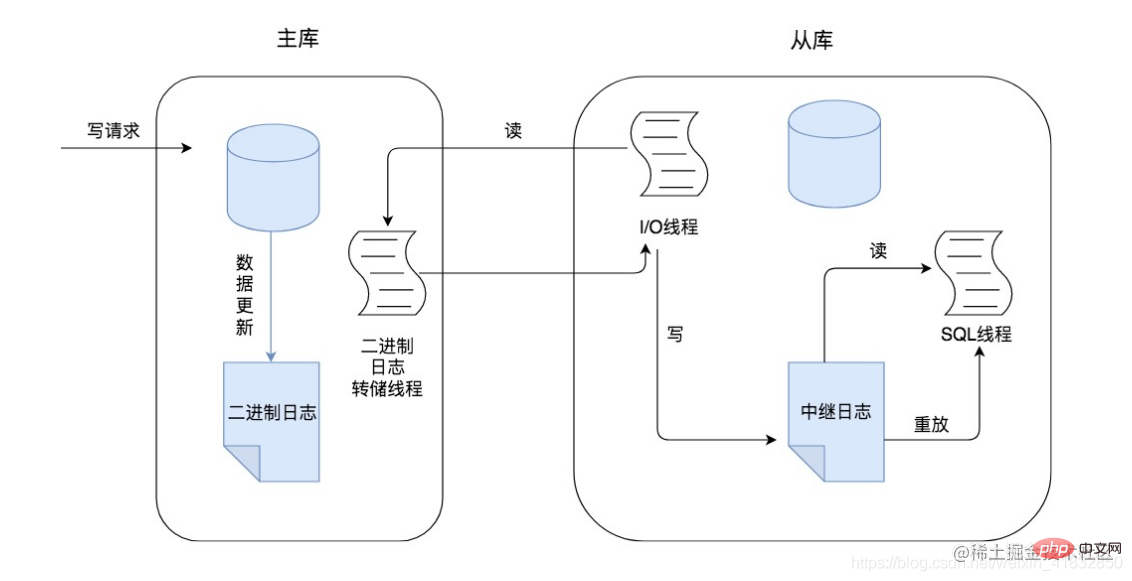
In Kombination mit den obigen Bildern verstehen wir den Kernprozess der Master-Slave-Replikation:
Wenn der Masterknoten eine Schreibanforderung empfängt, wird die Schreibanforderung angezeigt Es kann sich um einen Hinzufügungs-, Lösch- oder Änderungsvorgang handeln. Zu diesem Zeitpunkt werden alle Aktualisierungsvorgänge von Schreibanforderungen im Binlog-Protokoll aufgezeichnet.
Der Masterknoten kopiert die Daten auf den Slaveknoten, z. B. den Slave01-Knoten und den Slave02-Knoten im Bild. Bei diesem Vorgang muss jeder Slave-Knoten zuerst mit dem Masterknoten verbunden werden an den Master-Knoten. Der Master-Knoten erstellt einen Binlog-Dump-Thread für jeden Slave-Knoten, um Binlog-Protokolle an jeden Slave-Knoten zu senden.
Der Binlog-Dump-Thread liest das Binlog-Protokoll auf dem Master-Knoten und sendet das Binlog-Protokoll dann an den E/A-Thread auf dem Slave-Knoten. Wenn die Hauptbibliothek Ereignisse liest, wird das Binglog gesperrt. Nach Abschluss des Lesevorgangs wird die Sperre aufgehoben.
Nach dem Empfang des Binlog-Protokolls schreibt der E/A-Thread auf dem Slave-Knoten zunächst das Binlog-Protokoll in das lokale Relaylog und das Binlog-Protokoll wird im Relaylog gespeichert.
Der SQL-Thread auf dem Slave-Knoten liest das Binlog-Protokoll im Relaylog, analysiert es in bestimmte Hinzufügungs-, Lösch- und Änderungsvorgänge und wiederholt diese auf dem Master-Knoten ausgeführten Vorgänge Die Datenwiederherstellung wird erreicht, sodass die Datenkonsistenz des Masterknotens und des Slaveknotens gewährleistet werden kann.
Der Dateninhalt der Master-Slave-Synchronisation ist eigentlich ein Binärprotokoll (Binlog), es speichert tatsächlich Ereignisse nacheinander. Diese Ereignisse entsprechen den Aktualisierungsvorgängen der Datenbank, z EINFÜGEN, AKTUALISIEREN, LÖSCHEN usw.
Außerdem müssen wir beachten, dass nicht alle Versionen von MySQL das Binärprotokoll des Servers standardmäßig aktivieren. Bei der Master-Slave-Synchronisierung müssen wir zunächst prüfen, ob der Server das Binärprotokoll aktiviert hat.
Binärprotokoll ist eine Datei. Während der Netzwerkübertragung kommt es zu einer gewissen Verzögerung, z. B. 200 ms. Dies kann dazu führen, dass die vom Benutzer aus der Slave-Bibliothek gelesenen Daten nicht die neuesten sind, was ebenfalls zum Ausfall des Masters führt. Bei der Synchronisierung kommt es zu Dateninkonsistenzen. Wenn wir beispielsweise einen Datensatz aktualisieren, wird dieser Vorgang in der Hauptdatenbank abgeschlossen und innerhalb eines kurzen Zeitraums, z. B. 100 ms, wird derselbe Datensatz erneut gelesen. Zu diesem Zeitpunkt hat die Slave-Datenbank die Datensynchronisierung noch nicht abgeschlossen. Dann sind die Daten, die wir aus der Bibliothek lesen, alte Daten. Was tun in dieser Situation?
5 So lösen Sie das Datenkonsistenzproblem der Master-Slave-Synchronisation
Wie Sie sich vorstellen können, können wir beim Aktualisieren der Daten eine Datensatzsperre hinzufügen, wenn die Daten, die wir verarbeiten möchten, alle in derselben Datenbank gespeichert sind , damit es beim Lesen nicht zu Dateninkonsistenzen kommt. Derzeit besteht die Rolle der Slave-Bibliothek jedoch darin, Daten ohne Trennung von Lesen und Schreiben zu sichern und so den Druck der Hauptbibliothek zu teilen.
Wir müssen also noch einen Weg finden, das Problem der Dateninkonsistenz bei der Master-Slave-Synchronisation bei der Trennung von Lesen und Schreiben zu lösen, das heißt, das Problem der Datenreplikation zwischen Master und Slave zu lösen, wenn wir der Datenkonsistenz folgen schwach bis stark Zum Teilen gibt es die folgenden drei Kopiermethoden.
5.1 Vollständig synchrone Replikation
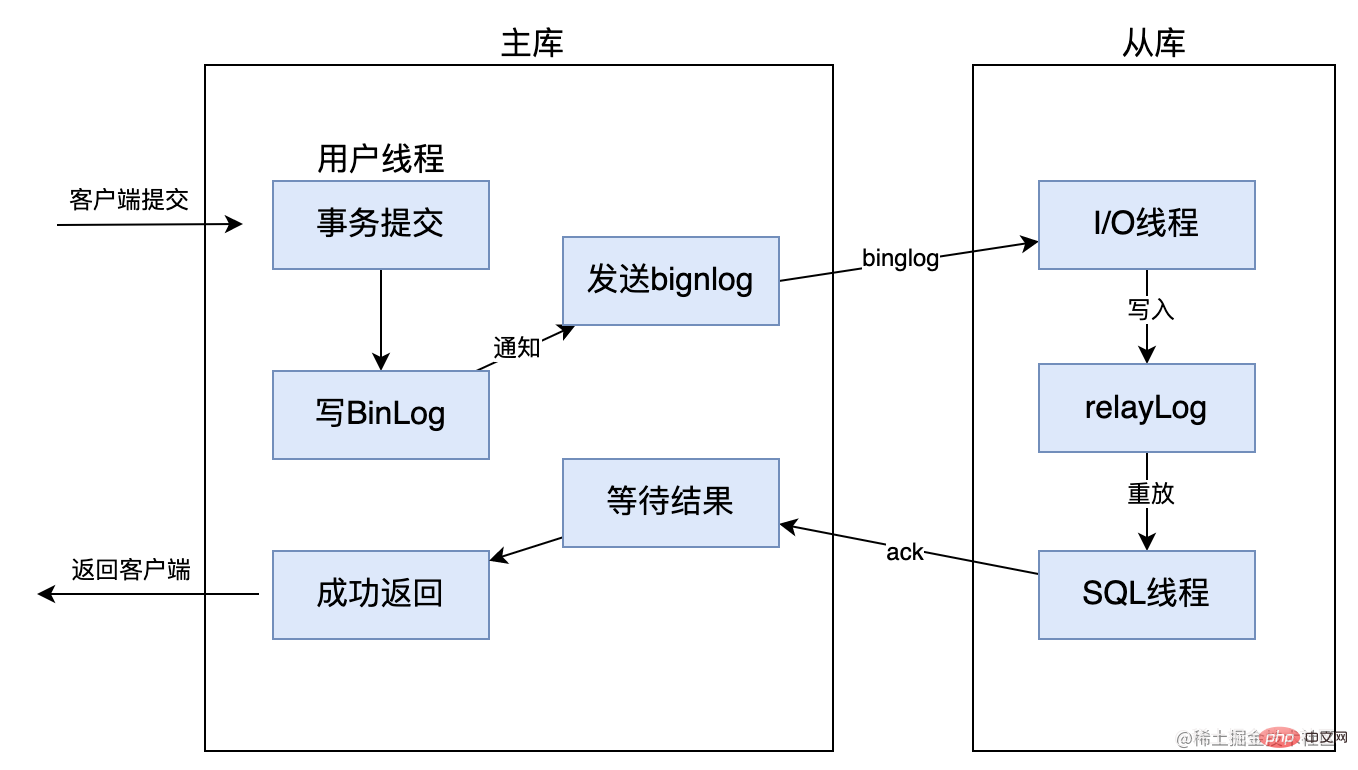
Zunächst bedeutet die vollständige synchrone Replikation, dass nach Abschluss einer Transaktion durch die Hauptbibliothek auch alle Slave-Bibliotheken die Transaktion abschließen müssen, bevor die Verarbeitungsergebnisse an den Client zurückgegeben werden können Die Datenkonsistenz bei der synchronen Replikation ist garantiert, aber die Master-Datenbank muss warten, bis alle Slave-Datenbanken eine Transaktion abgeschlossen haben, sodass die Leistung relativ gering ist. Wie unten gezeigt:
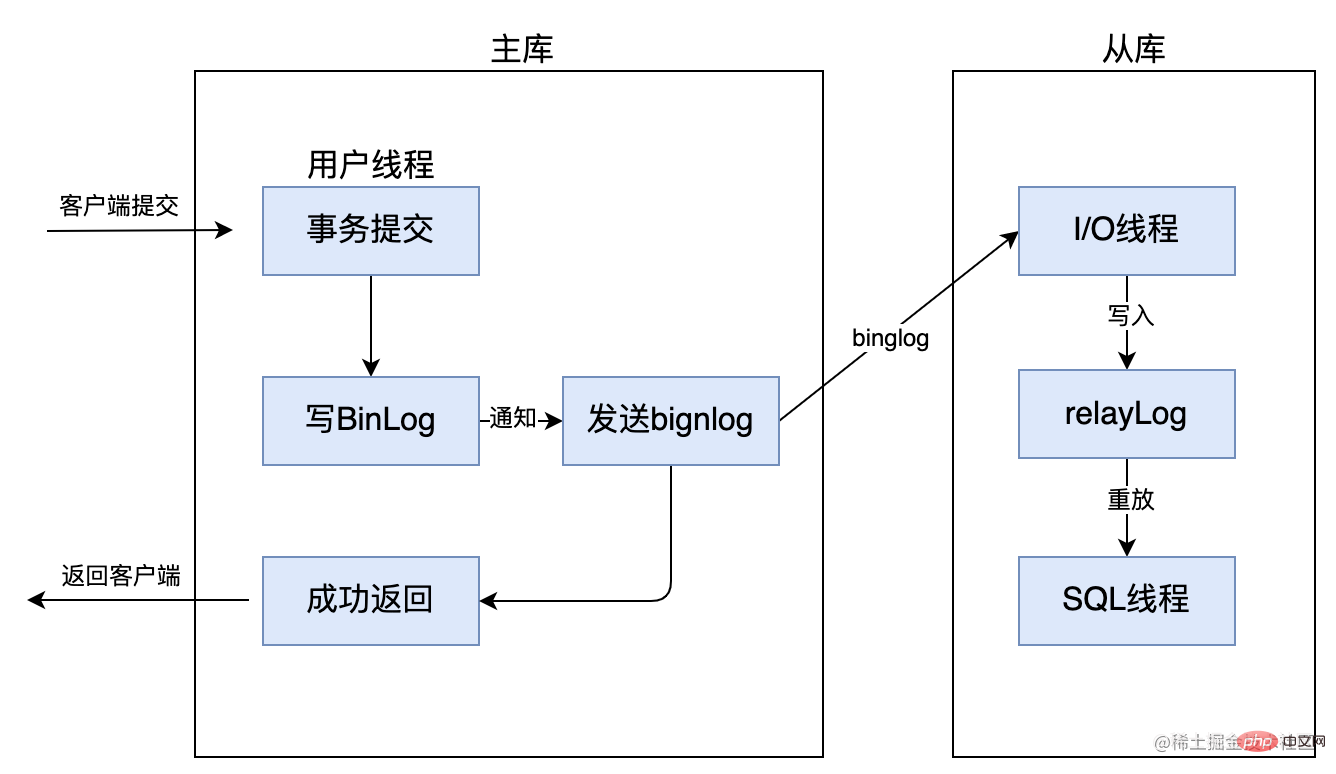
5.2 Asynchrone Replikation
Asynchrone Replikation bedeutet, dass, wenn die Hauptbibliothek Dinge übermittelt, sie den Binlog-Dump-Thread benachrichtigt, das Binlog-Protokoll an die Slave-Bibliothek zu senden, sobald der Binlog-Dump-Thread sendet Das Binlog-Protokoll wird an die Slave-Bibliothek gesendet. Es muss nicht darauf gewartet werden, dass die Slave-Bibliothek die Transaktion synchron abschließt. Die Master-Bibliothek gibt die Verarbeitungsergebnisse an den Client zurück.
Da die Hauptbibliothek die Transaktion nur selbst abschließen muss, kann sie die Verarbeitungsergebnisse an den Client zurückgeben, ohne sich darum zu kümmern, ob die Slave-Bibliothek die Transaktion abgeschlossen hat. Dies kann zu kurzfristigen Master-Slave-Dateninkonsistenzen führen, z Wenn die Hauptbibliothek gerade die Transaktion abgeschlossen hat, werden die neu eingefügten Daten sofort aus der Datenbank abgefragt.
Darüber hinaus hat das Binlog nach der Übermittlung von Daten durch die Master-Datenbank möglicherweise keine Zeit, sich mit der Slave-Datenbank zu synchronisieren. Wenn zu diesem Zeitpunkt die Master- und Slave-Knoten aufgrund eines Wiederherstellungsfehlers umgeschaltet werden, kommt es daher zu Datenverlust asynchron Obwohl die Replikation eine hohe Leistung aufweist, ist sie hinsichtlich der Datenkonsistenz am schwächsten.
Die MySQL-Master-Slave-Replikation übernimmt standardmäßig die asynchrone Replikation.
5.3 Halbsynchrone Replikation
MySQL unterstützt ab Version 5.5 die halbsynchrone Replikation. Das Prinzip besteht darin, dass nach der Übermittlung von COMMIT durch den Client das Ergebnis nicht direkt an den Client zurückgegeben wird, sondern darauf gewartet wird, dass mindestens eine Slave-Bibliothek das Binlog empfängt und in das Relay-Protokoll schreibt, bevor es an den Client zurückgegeben wird. Dies hat den Vorteil, dass die Konsistenz der Daten verbessert wird. Im Vergleich zur asynchronen Replikation erhöht sich natürlich die Verzögerung mindestens einer weiteren Netzwerkverbindung und die Effizienz beim Schreiben in die Hauptdatenbank wird verringert.
In Version MySQL 5.7 wurde auch ein Parameter rpl_semi_sync_master_wait_for_slave_count hinzugefügt. Der Standardwert ist 1, was bedeutet, dass er an die zurückgegeben werden kann, solange eine Slave-Bibliothek antwortet Kunde. Wenn Sie diesen Parameter erhöhen, können Sie die Stärke der Datenkonsistenz verbessern, verlängern aber auch die Zeit, die die Master-Datenbank auf die Antwort der Slave-Datenbank wartet.
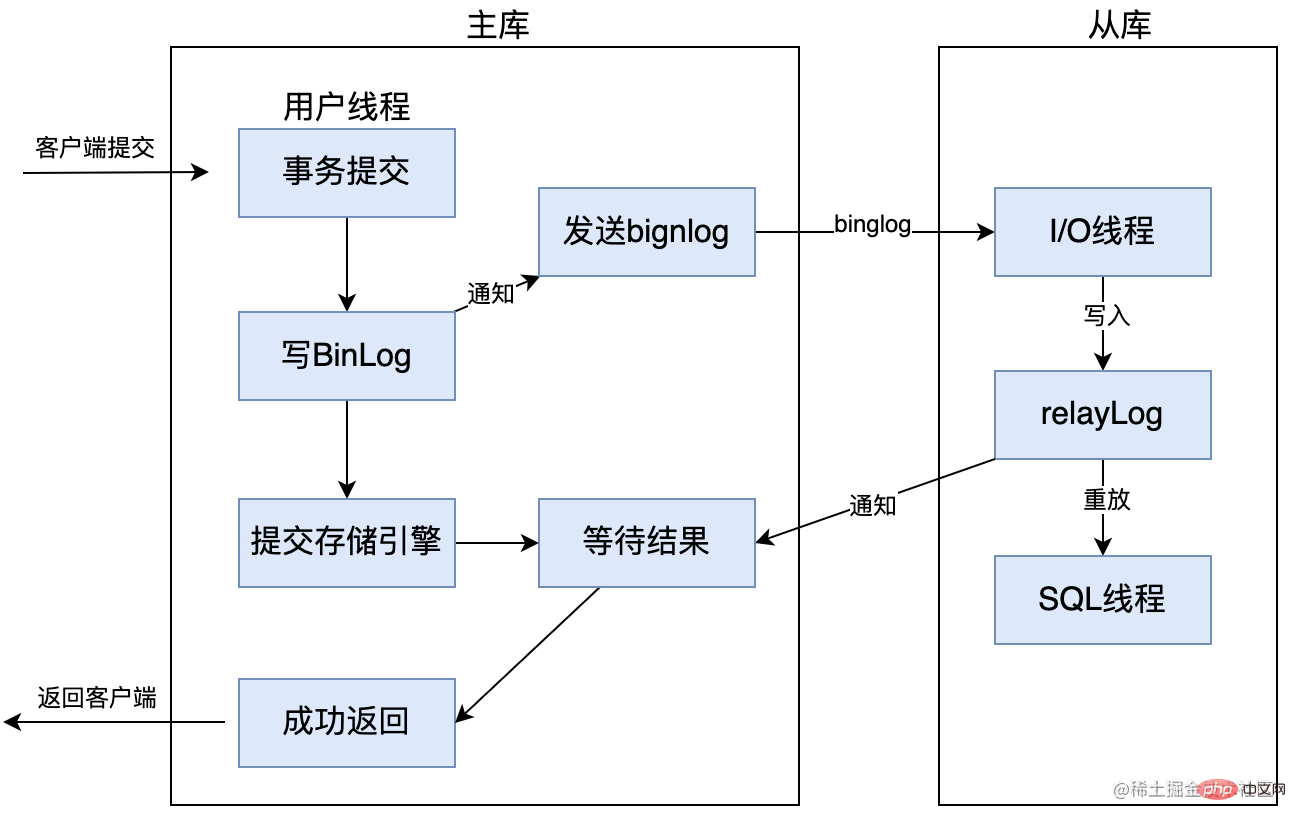
Die halbsynchrone Replikation weist jedoch auch die folgenden Probleme auf:
- Die Leistung der halbsynchronen Replikation ist im Vergleich zur asynchronen Replikation zurückgegangen, es besteht keine Notwendigkeit, auf eine Slave-Bibliothek zu warten Empfangen Um auf die Daten zu reagieren, muss die halbsynchrone Replikation darauf warten, dass mindestens eine Slave-Datenbank die Antwort auf den Empfang des Binlog-Protokolls bestätigt, was hinsichtlich der Leistung teurer ist.
- Die maximale Zeit, die die Master-Bibliothek auf die Antwort der Slave-Bibliothek wartet, ist konfigurierbar. Wenn die konfigurierte Zeit überschritten wird, wird die halbsynchrone Replikation zur asynchronen Replikation und es entsteht auch das Problem der asynchronen Replikation.
- In Versionen vor MySQL 5.7.2 gab es bei der halbsynchronen Replikation ein Phantomleseproblem.
Wenn die Hauptbibliothek die Transaktion erfolgreich übermittelt und auf die Bestätigung der Slave-Bibliothek wartet, hatte die Slave-Bibliothek zu diesem Zeitpunkt keine Zeit, die Verarbeitungsergebnisse an den Client zurückzugeben, sondern die Hauptbibliothek Die Speicher-Engine hat die Transaktion bereits übermittelt, andere Clients Der Client kann Daten aus der Hauptbibliothek lesen.
Wenn die Hauptbibliothek jedoch in der nächsten Sekunde plötzlich auflegt und zu diesem Zeitpunkt die nächste Anfrage eingeht, kann die Anfrage nur an die Slave-Bibliothek weitergeleitet werden, weil die Hauptbibliothek aufgelegt hat, da dies bei der Slave-Bibliothek nicht der Fall ist Die Synchronisierung der Daten aus der Hauptbibliothek ist noch nicht abgeschlossen, sodass diese Daten natürlich nicht aus der Bibliothek gelesen werden können. Verglichen mit dem Ergebnis des Lesens der Daten in der vorherigen Sekunde wird das Phänomen des Phantomlesens verursacht.
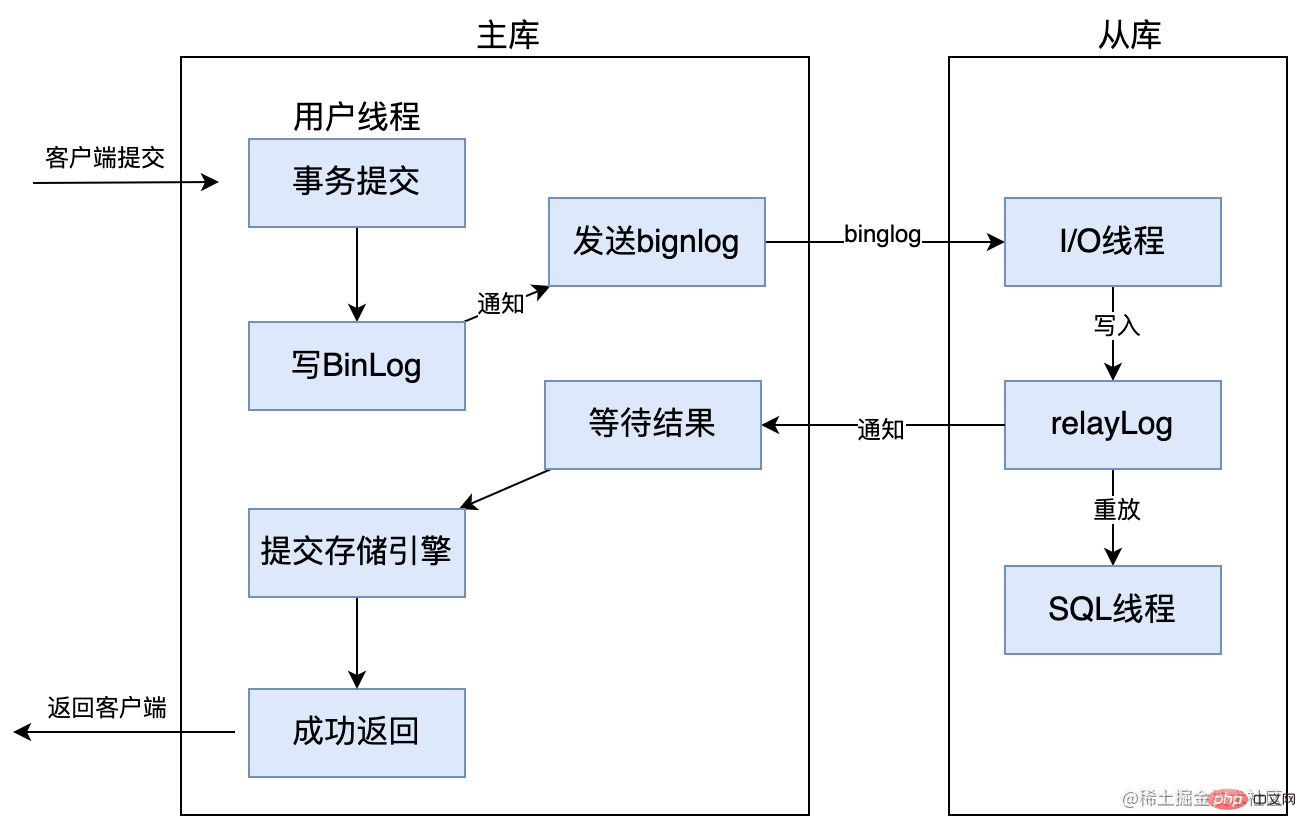
5.4 Erweiterte halbsynchrone Replikation
Die verbesserte halbsynchrone Replikation ist eine Verbesserung der halbsynchronen Replikation in Versionen nach MySQL 5.7.2. Das Prinzip ist fast dasselbe, hauptsächlich um das Problem der Phantom-Lesevorgänge zu lösen.
Nachdem die Master-Bibliothek mit dem Parameter rpl_semi_sync_master_wait_point = AFTER_SYNC konfiguriert wurde, muss die Master-Bibliothek vor dem Festschreiben der Transaktion eine Bestätigung von der Slave-Bibliothek erhalten, dass die Datensynchronisierung abgeschlossen ist, bevor die Speicher-Engine die Transaktion festschreibt, wodurch das Phantomleseproblem gelöst wird . Siehe das Bild unten:
6 Zusammenfassung
Durch den obigen Inhalt verstehen wir die Master-Slave-Synchronisation der MySQL-Datenbank. Wenn Ihr Ziel nur eine hohe Parallelität der Datenbank ist, können Sie mit der SQL-Optimierung beginnen , Indizierung und Redis Erwägen Sie die Optimierung von Aspekten wie dem Zwischenspeichern von Daten und überlegen Sie dann, ob eine Master-Slave-Architektur eingeführt werden soll.
Wenn wir in der Konfiguration der Master-Slave-Architektur eine Strategie zur Lese-/Schreibtrennung anwenden möchten, können wir unser eigenes Programm schreiben oder es über Middleware von Drittanbietern implementieren.
Der Vorteil des Schreibens eines eigenen Programms besteht darin, dass wir selbst beurteilen können, welche Abfragen in der Slave-Datenbank ausgeführt werden sollen. Bei hohen Echtzeitanforderungen können wir auch berücksichtigen, welche Abfragen in der Hauptdatenbank ausgeführt werden können Datenbank. Gleichzeitig stellt das Programm eine direkte Verbindung zur Datenbank her, wodurch die Middleware-Schicht reduziert und einige Leistungsverluste reduziert werden.
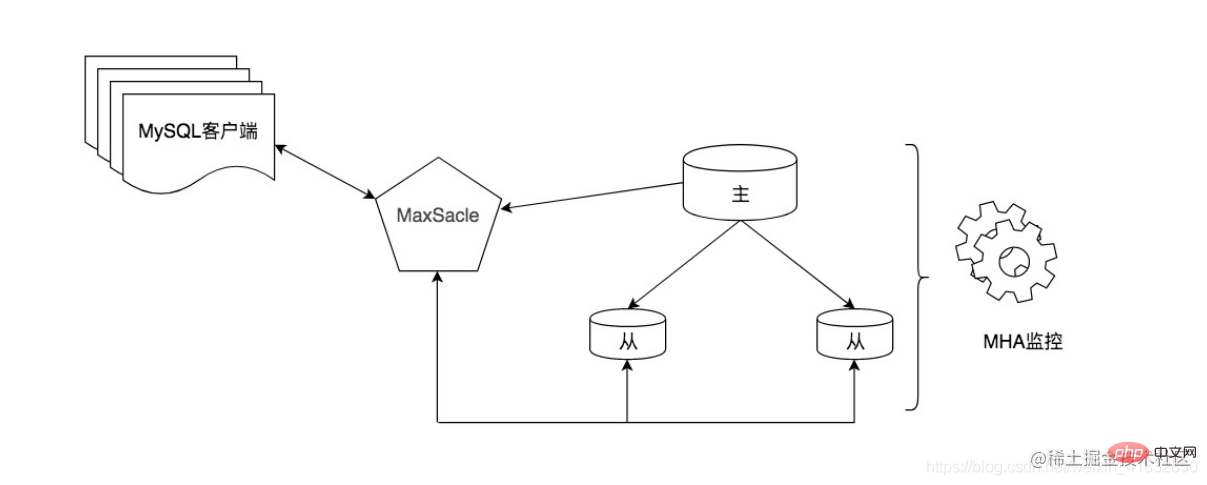
Die Methode der Verwendung von Middleware hat offensichtliche Vorteile, sie ist leistungsstark und einfach zu verwenden. Durch das Hinzufügen einer Middleware-Schicht zwischen dem Client und der Datenbank kommt es jedoch zu einem gewissen Leistungsverlust. Gleichzeitig ist der Preis für kommerzielle Middleware relativ hoch und es fallen gewisse Lernkosten an. Darüber hinaus können wir auch die Verwendung einiger hervorragender Open-Source-Tools wie MaxScale in Betracht ziehen. Es handelt sich um eine von MariaDB entwickelte MySQL-Daten-Middleware. In der folgenden Abbildung wird beispielsweise MaxScale als Datenbank-Proxy verwendet und die Lese-/Schreibtrennung wird durch Routing und Weiterleitung abgeschlossen. Gleichzeitig können wir das MHA-Tool auch als stark konsistentes Master-Slave-Switching-Tool verwenden, um die Hochverfügbarkeitsarchitektur von MySQL zu vervollständigen.
Empfohlenes Lernen: „MySQL-Video-Tutorial“
Das obige ist der detaillierte Inhalt vonEin umfassender Überblick über die MySql-Master-Slave-Synchronisierung in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!