
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Was ist Kompilierung und Installation unter Linux?
Was ist Kompilierung und Installation unter Linux?

- 青灯夜游Original
- 2023-02-14 11:05:203429Durchsuche
Unter Linux bezieht sich Kompilierung und Installation auf die Umwandlung des Quellcodes in eine maschinenausführbare Codedatei basierend auf der eigenen Hardware, dem Kernel und der Umgebung der Maschine und die anschließende Installation der ausführbaren Datei im Betriebssystem. Da es für die lokale Software- und Hardwareumgebung kompiliert wird, weist das generierte Binärprogramm theoretisch eine bessere Leistung auf und spart Ressourcen bei der Ausführung.

Die Betriebsumgebung dieses Tutorials: Linux7.3-System, Dell G3-Computer.
Was ist Kompilierung und Installation?
Kompilierung: Quellcode in maschinenausführbare Codedateien umwandeln.
Installation: Installieren Sie die ausführbare Datei im Betriebssystem, bevor sie verwendet werden kann.
Kompilieren und Installieren bedeutet, den Quellcode zu verwenden, ihn entsprechend der Hardware, dem Kernel und der Umgebung der Maschine zu kompilieren und Binärdateien zu generieren. Der Vorteil besteht darin, dass unabhängig von der Maschine eine vollständige vorhanden ist Kompilierungsumgebung (im Grunde verfügen alle Linux-Distributionen über eine eigene Kompilierungsumgebung), mit der Sie ein Binärpaket generieren können, das für Ihren eigenen Computer geeignet ist. Gleichzeitig wird die generierte Binärdatei für die lokale Software- und Hardwareumgebung kompiliert Programm läuft theoretisch mit besserer Leistung und spart Ressourcen.
Nachteile: Der Kompilierungsprozess ist für Anfänger umständlich (natürlich geht er auch sehr schnell, wenn Sie damit vertraut sind), und das Aktualisieren ist umständlich (natürlich lösen einige Programme Aktualisierungskonflikte und Überschreibungen während des Kompilierungs- und Installationsprozesses selbst)
Hinweis:
Um den Quellcode auszuführen, muss er zunächst in binären Maschinencode umgewandelt werden. Dies ist die Aufgabe des Compilers.
Nehmen Sie zum Beispiel den folgenden Quellcode (vorausgesetzt, der Dateiname lautet test.c).
#include <stdio.h>
int main(void)
{
fputs("Hello, world!\n", stdout);
return 0;
}</stdio.h>
Es muss vom Compiler verarbeitet werden, bevor es ausgeführt werden kann.
$ gcc test.c $ ./a.out Hello, world!
Bei komplexen Projekten muss der Kompilierungsprozess ebenfalls in drei Schritte unterteilt werden.
$ ./configure $ make $ make install
Ablaufdiagramm des Kompilierungsprozesses:
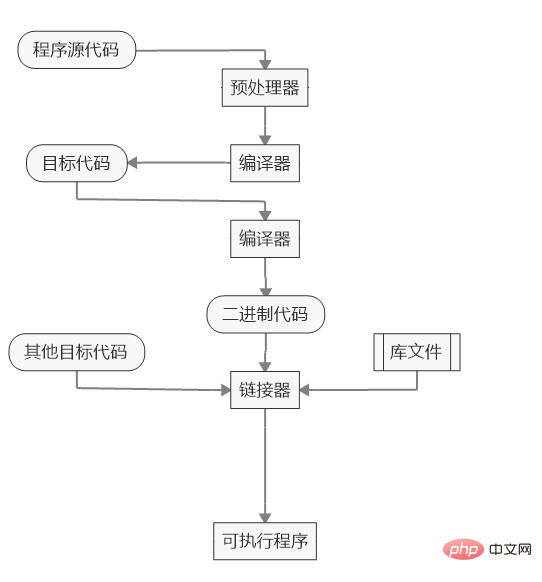
Spezifischer Kompilierungsprozess
1. Konfiguration
Bevor der Compiler mit der Arbeit beginnt, muss er die aktuelle Systemumgebung kennen, z. B. wo sich die Standardbibliothek befindet. Wo ist der Installationsort der Software, welche Komponenten müssen installiert werden usw. Dies liegt daran, dass die Systemumgebungen verschiedener Computer unterschiedlich sind. Durch die Angabe von Kompilierungsparametern kann sich der Compiler flexibel an die Umgebung anpassen und Maschinencode kompilieren, der in verschiedenen Umgebungen ausgeführt werden kann. Dieser Schritt zur Bestimmung der Kompilierungsparameter wird als „Konfigurieren“ bezeichnet.
Diese Konfigurationsinformationen werden in einer Konfigurationsdatei gespeichert, bei der es sich herkömmlicherweise um eine Skriptdatei namens „configure“ handelt. Normalerweise wird es vom Autoconf-Tool generiert. Der Compiler lernt die Kompilierungsparameter, indem er dieses Skript ausführt.
Das Konfigurationsskript hat sein Bestes gegeben, um die Unterschiede zwischen verschiedenen Systemen zu berücksichtigen, und gibt Standardwerte für verschiedene Kompilierungsparameter an. Wenn die Systemumgebung des Benutzers speziell ist oder bestimmte Anforderungen stellt, muss er oder sie manuell Kompilierungsparameter für das Konfigurationsskript bereitstellen.
$ ./configure --prefix=/www --with-mysql
Der obige Code ist eine Kompilierungskonfiguration des PHP-Quellcodes. Der Benutzer gibt an, dass die installierten Dateien im WWW-Verzeichnis gespeichert werden und während der Kompilierung Unterstützung für das MySQL-Modul hinzugefügt wird.
2. Bestimmen Sie den Speicherort der Standardbibliothek und Header-Dateien.
Der Quellcode verwendet auf jeden Fall die Standardbibliotheksfunktionen (Standardbibliothek) und Header-Dateien (Header). Sie können in jedem Verzeichnis auf dem System gespeichert werden. Es gibt für den Compiler eigentlich keine Möglichkeit, ihren Speicherort automatisch zu erkennen. Dies kann nur über die Konfigurationsdatei erfolgen.
Der zweite Schritt der Kompilierung besteht darin, den Speicherort der Standardbibliothek und der Header-Dateien aus der Konfigurationsdatei zu ermitteln. Im Allgemeinen enthält die Konfigurationsdatei eine Liste mehrerer spezifischer Verzeichnisse. Beim Kompilieren geht der Compiler in diese Verzeichnisse, um das Ziel zu finden.
3. Abhängigkeiten bestimmen
Bei großen Projekten gibt es häufig Abhängigkeiten zwischen Quellcodedateien und der Compiler muss die Reihenfolge der Kompilierung bestimmen. Unter der Annahme, dass Datei A von Datei B abhängt, sollte der Compiler die folgenden zwei Punkte sicherstellen.
(1)只有在B文件编译完成后,才开始编译A文件。 (2)当B文件发生变化时,A文件会被重新编译。
Die Kompilierungsreihenfolge wird in einer Datei namens Makefile gespeichert, in der aufgeführt ist, welche Datei zuerst und welche später kompiliert wird. Die Makefile-Datei wird durch Ausführen des configure-Skripts generiert, weshalb configure beim Kompilieren zuerst ausgeführt werden muss.
Während der Ermittlung der Abhängigkeiten bestimmt der Compiler auch, welche Header-Dateien bei der Kompilierung verwendet werden.
4. Vorkompilierung von Header-Dateien
Verschiedene Quellcodedateien können auf dieselbe Header-Datei verweisen (z. B. stdio.h). Beim Kompilieren müssen auch die Header-Dateien zusammen kompiliert werden. Um Zeit zu sparen, kompiliert der Compiler die Header-Dateien vor dem Kompilieren des Quellcodes. Dadurch wird sichergestellt, dass die Header-Datei nur einmal kompiliert werden muss und nicht bei jeder Verwendung neu kompiliert werden muss.
Allerdings werden nicht alle Inhalte der Header-Datei vorkompiliert. Der zum Deklarieren von Makros verwendete Befehl #define wird nicht vorkompiliert.
5. 预处理(Preprocessing)
预编译完成后,编译器就开始替换掉源码中bash的头文件和宏。以本文开头的那段源码为例,它包含头文件stdio.h,替换后的样子如下。
extern int fputs(const char *, FILE *);
extern FILE *stdout;
int main(void)
{
fputs("Hello, world!\n", stdout);
return 0;
}
为了便于阅读,上面代码只截取了头文件中与源码相关的那部分,即fputs和FILE的声明,省略了stdio.h的其他部分(因为它们非常长)。另外,上面代码的头文件没有经过预编译,而实际上,插入源码的是预编译后的结果。编译器在这一步还会移除注释。
这一步称为"预处理"(Preprocessing),因为完成之后,就要开始真正的处理了。
6. 编译(Compilation)
预处理之后,编译器就开始生成机器码。对于某些编译器来说,还存在一个中间步骤,会先把源码转为汇编码(assembly),然后再把汇编码转为机器码。
下面是本文开头的那段源码转成的汇编码。
.file "test.c" .section .rodata .LC0: .string "Hello, world!\n" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movq stdout(%rip), %rax movq %rax, %rcx movl $14, %edx movl $1, %esi movl $.LC0, %edi call fwrite movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Debian 4.9.1-19) 4.9.1" .section .note.GNU-stack,"",@progbits
这种转码后的文件称为对象文件(object file)。
注:make (gcc), 其调用 gcc 执行编译的过程依赖于配置文件makefile
7. 连接(Linking)
对象文件还不能运行,必须进一步转成执行文件。如果你仔细看上一步的转码结果,会发现其中引用了stdout函数和fwrite函数。也就是说,程序要正常运行,除了上面的代码以外,还必须有stdout和fwrite这两个函数的代码,它们是由C语言的标准库提供的。
编译器的下一步工作,就是把外部函数的代码(通常是后缀名为.lib和.a的文件),添加到可执行文件中。这就叫做连接(linking)。这种通过拷贝,将外部函数库添加到可执行文件的方式,叫做静态连接(static linking),后文会提到还有动态连接(dynamic linking)。
make命令的作用,就是从第四步头文件预编译开始,一直到做完这一步。
8. 安装(Installation)
上一步的连接是在内存中进行的,即编译器在内存中生成了可执行文件。下一步,必须将可执行文件保存到用户事先指定的安装目录。
表面上,这一步很简单,就是将可执行文件(连带相关的数据文件)拷贝过去就行了。但是实际上,这一步还必须完成创建目录、保存文件、设置权限等步骤。这整个的保存过程就称为"安装"(Installation)。
9. 操作系统连接
可执行文件安装后,必须以某种方式通知操作系统,让其知道可以使用这个程序了。比如,我们安装了一个文本阅读程序,往往希望双击txt文件,该程序就会自动运行。
这就要求在操作系统中,登记这个程序的元数据:文件名、文件描述、关联后缀名等等。Linux系统中,这些信息通常保存在/usr/share/applications目录下的.desktop文件中。另外,在Windows操作系统中,还需要在Start启动菜单中,建立一个快捷方式。
这些事情就叫做"操作系统连接"。make install命令,就用来完成"安装"和"操作系统连接"这两步。
10. 生成安装包
写到这里,源码编译的整个过程就基本完成了。但是只有很少一部分用户,愿意耐着性子,从头到尾做一遍这个过程。事实上,如果你只有源码可以交给用户,他们会认定你是一个不友好的家伙。大部分用户要的是一个二进制的可执行程序,立刻就能运行。这就要求开发者,将上一步生成的可执行文件,做成可以分发的安装包。
所以,编译器还必须有生成安装包的功能。通常是将可执行文件(连带相关的数据文件),以某种目录结构,保存成压缩文件包,交给用户。
11. 动态连接(Dynamic linking)
正常情况下,到这一步,程序已经可以运行了。至于运行期间(runtime)发生的事情,与编译器一概无关。但是,开发者可以在编译阶段选择可执行文件连接外部函数库的方式,到底是静态连接(编译时连接),还是动态连接(运行时连接)。所以,最后还要提一下,什么叫做动态连接。
前面已经说过,静态连接就是把外部函数库,拷贝到可执行文件中。这样做的好处是,适用范围比较广,不用担心用户机器缺少某个库文件;缺点是安装包会比较大,而且多个应用程序之间,无法共享库文件。动态连接的做法正好相反,外部函数库不进入安装包,只在运行时动态引用。好处是安装包会比较小,多个应用程序可以共享库文件;缺点是用户必须事先安装好库文件,而且版本和安装位置都必须符合要求,否则就不能正常运行。
现实中,大部分软件采用动态连接,共享库文件。这种动态共享的库文件,Linux平台是后缀名为.so的文件,Windows平台是.dll文件,Mac平台是.dylib文件。
Linux编译安装的具体实现
1.编译安装源程序的前提:
1).提供开发环境:开发工具和开发库
2).编译安装需要的包组:
Development Tools、Server Platform Development、Desktop Platform Development、Debug Tools
2.configure脚本常用的选项:
--help获取./configure脚本帮助 --prefix=: 指定安装路径;多数程序都有默认安装路径; --sysconfidr=: 指定配置文件安装路径; --with-PACKAGE[=ARG]:在自由软件社区里,有使用已有软件包和库的优秀传统.当用'configure'来配置一个源码树时, 可以提供其他已经安装的软件包的信息 --without-PACKAGE:有时候你可能不想让你的软件包与系统已有的软件包交互。例如,你可能不想让你的新编译器使用 GNU ld --enable-FEATURE:一些软件包可能提供了一些默认被禁止的特性,可以使用'--enable-FEATURE'来起用它 --disable-EEATURE:关闭指定的默认特性
3.编译安装源程序方法:
1)、展开源代码,找INSTALL、README;不存在此类文件时,找项目官方文档;
2)、根据安装说明执行安装操作;
4.程序安装于专用目录时,安装后的配置:
1)、导出二进制程序所在路径至PATH环境中
# export PATH=/usr/local/nginx/sbin:$PATH 实现永久有效的办法: /etc/profile.d/*.sh
2)、导出库文件给OS
OS查找库文件方法:根据/etc/ld.so.conf配置文件指定的路径搜索,或搜索/lib, /lib64, /usr/lib, /usr/lib64,把查找到的所有的库文件路径和其名称映射关系保存为一个缓存文件/etc/ld.so.cache;
/etc/ld.so.conf配置文件有其它组成部分:/etc/ld.so.conf.d/*.conf
假设nginx安装于/usr/local/nginx,此目录中有其库文件子目录lib,导出此目录中库文件:
(1)新建文件/etc/ld.so.conf.d/nginx.conf,在文件添加如下行:
/usr/local/nginx/lib
(2)运行命令:ldconfig
ldconfig的主要用途:
默认搜寻/lilb和/usr/lib,以及配置文件/etc/ld.so.conf内所列的目录下的库文件。
搜索出可共享的动态链接库,库文件的格式为:lib***.so.**,进而创建出动态装入程序(ld.so)所需的连接和缓存文件。
缓存文件默认为/etc/ld.so.cache,该文件保存已排好序的动态链接库名字列表。
ldconfig通常在系统启动时运行,而当用户安装了一个新的动态链接库时,就需要手工运行这个命令。
常用选项:
-v: 用此选项时,ldconfig将显示正在扫描的目录及搜索到的动态链接库,还有它所创建的连接的名字. -p: 显示当前OS已经加载到的所有库文件名称及其文件所在路径的映射关系;
ldconfig需要注意的地方:
(a)、往/lib和/usr/lib里面加东西,是不用修改/etc/ld.so.conf文件的,但是添加完后需要调用下ldconfig,不然添加的library会找不到。
(b)、如果添加的library不在/lib和/usr/lib里面的话,就一定要修改/etc/ld.so.conf文件,往该文件追加library所在的路径,然后也需要重新调用下ldconfig命令。比如在安装mysql的时候,其库文件/usr/local/mysql/lib,就需要追加到/etc/ld.so.conf文件中。命令如下:
# echo "/usr/local/mysql/lib" >> /etc/ld.so.conf # ldconfig -v | grep mysql
(c)、如果添加的library不在/lib或/usr/lib下,但是却没有权限操作写/etc/ld.so.conf文件的话,这时就需要往export里写一个全局变量LD_LIBRARY_PATH,就可以了。
(3)、帮助文件导出
man命令搜索特定路径查找手册页文件,这些路径是定义在/etc/man.config中的MANPATH参数所指定的路径下的;
新增办法:编辑/etc/man.config文件,新增一个MANPATH参数,其值为新安装程序的man手册所在的目录;
/usr/local/nginx/share/man/{man1,man8}
man -M /path/to/man KEYWORD
(4)、头文件导出
有些程序安装后会生成对自己拥有库文件调用接口相关头文件系统查找头文件的路径为/usr/include
导出独立安装应用程序的头文件方法:创建链接至/usr/include下即可;
例如:
/usr/local/nginx/include # ln -sv /usr/local/nginx/include/* /usr/include/ # ln -sv /usr/local/nginx/include /usr/include/nginx
perl源程序的编译安装方法:
(1) perl Makefile.in (2) make (3) make install
相关推荐:《Linux视频教程》
Das obige ist der detaillierte Inhalt vonWas ist Kompilierung und Installation unter Linux?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!