
Heim >Web-Frontend >js-Tutorial >[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen
[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen

- 青灯夜游nach vorne
- 2023-01-28 19:25:373192Durchsuche
Wie behebe ich Speicherlecks in Node? Der folgende Artikel fasst die Erfahrung bei der Fehlerbehebung bei Knotenspeicherlecks für alle zusammen. Ich hoffe, er ist für alle hilfreich!
![[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen](https://img.php.cn/upload/article/000/000/024/63d505e3d0d7d931.jpg)
Im Szenario der serverseitigen Nodejs-Entwicklung ist Speicherverlust definitiv das problematischste Problem;
Aber solange das Projekt weiter entwickelt und iteriert wird, ist das Problem des Speicherverlusts absolut unvermeidlich, es passiert einfach früher oder später. Daher ist die systematische Beherrschung effektiver Methoden zur Fehlerbehebung bei Speicherlecks die grundlegendste und wichtigste Fähigkeit eines Nodejs-Ingenieurs. Nodejs 服务端开发的场景中,内存泄漏 绝对是最令人头疼的问题;
但是只要项目一直在开发迭代,那么出现 内存泄漏 的问题绝对不可避免,只是出现的时间早晚而已。所以系统性掌握有效的 内存泄漏 排查方法是一名Nodejs 工程师最基础、最核心的能力。
内存泄漏处理的难点就是如何能在无数的功能、函数中找到具体是哪一个功能中的哪一个函数的第多少行到多少行引起了内存泄漏。
很遗憾目前市面上没有能够轻松定位内存泄漏的工具,所以很多初次遇到这种问题的工程师会感到茫然,一下子不知道该如何处理。
这里我以22年的一次排查 内存泄漏 的案例分享一下我的处理思路。
问题描述
2022 Q4 某天,研发用户群中反馈我们的研发平台不能访问,后台中出现了大量的异常任务未完成。
第一反应就是可能出现了内存泄漏还好服务接入了监控(prometheus + grafana),在grafana 监控面板中发现在 10.00 后内存一直在涨没有下来过出现了明显的数据泄漏。【相关教程推荐:nodejs视频教程】
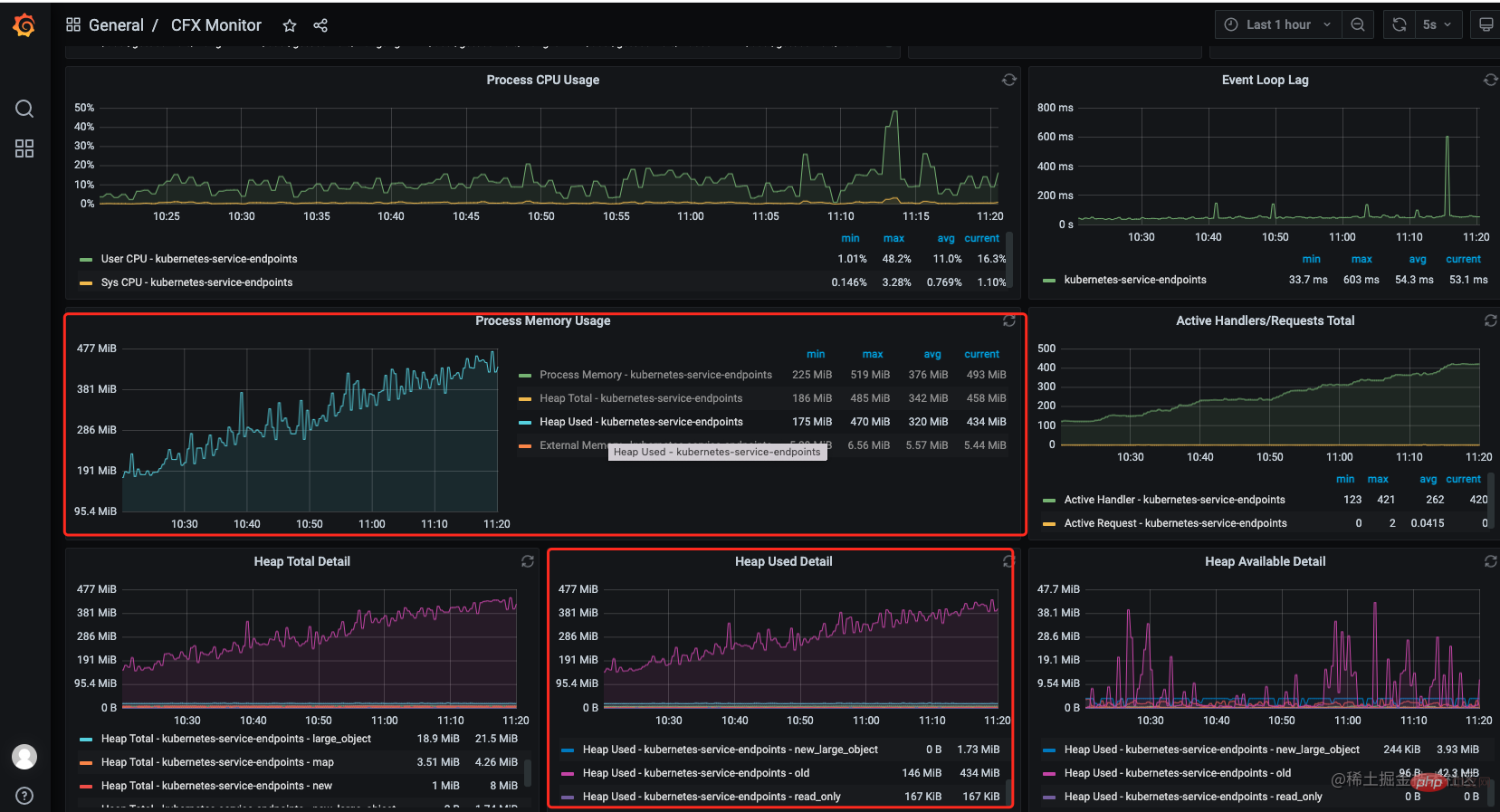
说明:
process memory:rss(Resident Set Size),进程的常驻内存大小。heapTotal: V8 堆的总大小。heapUsed: V8 堆已使用的大小。external: V8 堆外的内存使用量。在
Nodejs中可以调用全局方法process.memoryUsage()获取这些数据其中heapTotal和heapUsed是 V8 堆的使用情况,V8 堆是Node.js中 JavaScript 对象存储的地方。而external则表示非 V8 堆中分配的内存,例如 C++ 对象。rss则是进程所有内存的使用量。一般看监控数据的时候重点关注heapUsed的指标就行了
内存泄漏类型
内存泄漏主要分为:
- 全局性泄漏
- 局部性泄漏
其实不管是全局性内存泄漏还是局部性的内存泄漏,要做的都是尽可能缩小排除范围。
全局性内存泄漏
全局性内容泄漏出现一般高发于:中间件与组件中,这种类型的内存泄漏排查起来也是最简单的。
很遗憾我在 2022 Q4 中遇到的内存泄漏不属于这个类型,所以还得按照局部性泄漏的思路进行分析。
二分法排查
这种类型我就不讲其它科学的分析方法了,这种情况下我认为使用二分法排查是最快的。
流程流程:
先注释一半的代码(减少一半
中间件、组件、或其它公用逻辑的使用)随便选择一个接口或新写一个测试接口进行压测
如果出现内存泄漏,那么泄漏点就在当前使用的代码之中,若没有泄漏则泄漏点出现在
然后一直循环往复上述流程大约 20 ~ 60 min 一定可以定位到内存泄漏的详细位置
2020 年的时候我在做基于
NuxtSSR 应用时,上线前压测发现应用内存泄漏,判断定为全局性的泄漏之后,采用二分法排查大约花了 30min 就成功定位了问题。
当时泄漏的原因是我们在服务端使用axios导致的泄漏,后来统一axios相关的全换成node-fetch后就解决了,从此换上了axios PDST后来绝对不会在Node服务中使用axios了
局部性内存泄漏排查
大多数内存泄漏的情况都是局部性的泄漏,泄漏点可能存在与某个中间件、某个接口、某个异步任务中,由于这样的特性它的排查难度也较大。这种情况都会做 heapdump
Speicherlecks in 22 Jahren teilen. 🎜Problembeschreibung
🎜2022 Q4 Eines Tages berichtete die F&E-Benutzergruppe, dass unsere F&E-Plattform nicht funktionieren kann Beim Zugriff wurde eine große Anzahl ungewöhnlicher Aufgaben im Hintergrund nicht abgeschlossen.
Die erste Reaktion ist, dass möglicherweise ein Speicherverlust vorliegt. Der Dienst ist mit der Überwachung verbunden (prometheus + grafana). Im Überwachungspanel stellte ich fest, dass der Speicher nach 10.00 Uhr weiter zunahm und nie abfiel und es ein offensichtliches Datenleck gab. [Empfohlene verwandte Tutorials: nodejs-Video-Tutorial]🎜🎜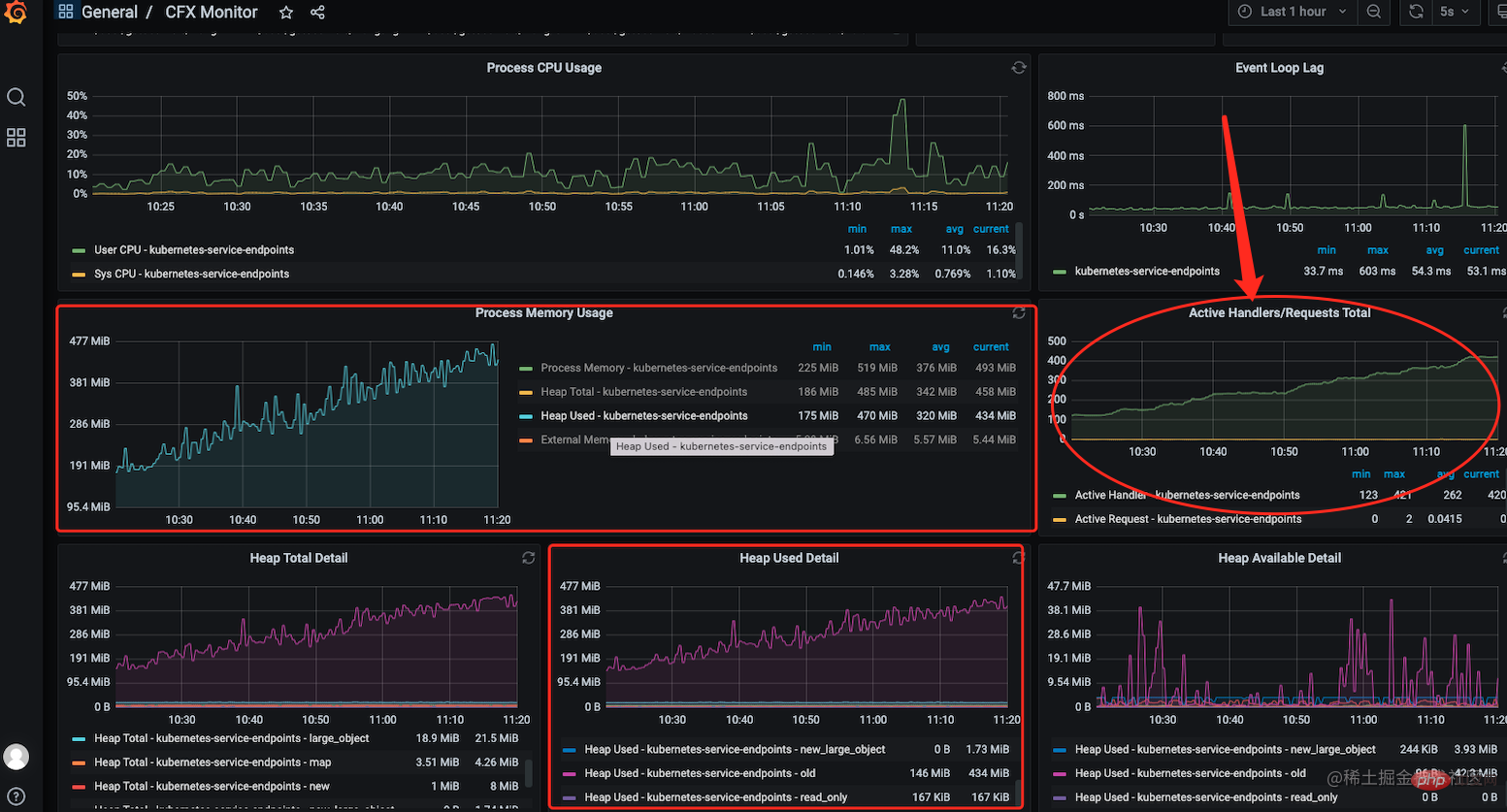 🎜
🎜🎜Beschreibung: 🎜🎜In
Prozessspeicher:rss(Resident Set Size), die residente Speichergröße des Prozesses.heapTotal: Die Gesamtgröße des V8-Heaps.heapUsed: Die Größe des verwendeten V8-Heaps.external: Speichernutzung außerhalb des V8-Heaps.Nodejskönnen Sie die globale Methodeprocess.memoryUsage()aufrufen, um diese Daten zu erhalten, darunterheapTotalundheapUsedist die Verwendung des V8-Heaps, in dem JavaScript-Objekte inNode.jsgespeichert werden. Undexternalstellt Speicher dar, der in einem Nicht-V8-Heap zugewiesen wird, z. B. bei C++-Objekten.rssist die gesamte Speichernutzung des Prozesses. Im Allgemeinen konzentrieren Sie sich bei der Betrachtung von Überwachungsdaten nur auf den IndikatorheapUsed🎜
Typ des Speicherlecks h2 >🎜Speicherlecks werden hauptsächlich unterteilt in:🎜
- Globale Lecks
- Lokale Lecks
🎜In der Tat, ob es sich um ein globales Speicherleck handelt oder ein lokales Leck Bei Speicherlecks müssen Sie lediglich den Ausschlussbereich so weit wie möglich einschränken. 🎜
Globaler Speicherverlust
🎜Globale Inhaltsverluste treten im Allgemeinen auf in: MiddlewareMit component ist diese Art von Speicherverlust auch am einfachsten zu beheben. 🎜🎜Leider gehört der Speicherverlust, auf den ich im vierten Quartal 2022 gestoßen bin, nicht zu diesem Typ, daher muss ich ihn nach der Idee lokaler Lecks analysieren. 🎜Dichotomie-Fehlerbehebung
🎜Ich werde nicht über andere wissenschaftliche Analysemethoden für diesen Typ sprechen. In diesem Fall denke ich, dass ich die Dichotomie-Französisch-Fehlerbehebung verwende ist am schnellsten. 🎜🎜Prozessablauf: 🎜
- 🎜Kommentieren Sie zuerst die Hälfte des Codes (reduzieren Sie die Hälfte der
Middleware). >, component oder die Verwendung anderer öffentlicher Logik)🎜
- 🎜Wählen Sie eine Schnittstelle oder schreiben Sie eine neue Testschnittstelle für Stresstests🎜
- 🎜Wenn Wenn im Speicher ein Leck auftritt, liegt der Leckpunkt im aktuell verwendeten Code. Wenn kein Leck vorliegt, wird der Leckpunkt angezeigt. 🎜
Finden Sie auf jeden Fall die Details des Speicherlecks. 🎜
🎜Im Jahr 2020, als ich an einer SSR-Anwendung auf Basis von Nuxt arbeitete, führte ich vor dem Start einen Stresstest durch online wurde ein Anwendungsspeicherleck festgestellt, bei dem es sich um ein globales Leck handelte. Danach dauerte es etwa 30 Minuten, bis das Problem mithilfe der Dichotomiemethode erfolgreich lokalisiert werden konnte.
Der Grund für das Leck war damals, dass wir axios auf der Serverseite verwendeten. Später haben wir axios vereinheitlicht und durch node- ersetzt. fetch Danach wurde das Problem gelöst und ich bin auf axios PDST umgestiegen. Ich werde axios nie mehr im Node-Dienst verwenden
Fehlerbehebung bei lokalen Speicherlecks
🎜Die meisten Speicherlecks sind lokale Lecks, und der Leckpunkt kann mit einem bestimmten Middleware). >, component oder die Verwendung anderer öffentlicher Logik)🎜Nuxt arbeitete, führte ich vor dem Start einen Stresstest durch online wurde ein Anwendungsspeicherleck festgestellt, bei dem es sich um ein globales Leck handelte. Danach dauerte es etwa 30 Minuten, bis das Problem mithilfe der Dichotomiemethode erfolgreich lokalisiert werden konnte. Der Grund für das Leck war damals, dass wir
axios auf der Serverseite verwendeten. Später haben wir axios vereinheitlicht und durch node- ersetzt. fetch Danach wurde das Problem gelöst und ich bin auf axios PDST umgestiegen. Ich werde axios nie mehr im Node-Dienst verwenden Middleware, eine bestimmte Schnittstelle und eine bestimmte asynchrone Aufgabe sind aufgrund solcher Merkmale schwieriger zu beheben. In diesem Fall wird heapdump zur Analyse durchgeführt. 🎜Hier spreche ich hauptsächlich über meine Ideen in diesem Fall. Die detaillierte Beschreibung von heapdump werde ich im nächsten Absatz einfügen, heapdump的详细说明我放在下个段落,
Heap Dump:堆转储, 后面部分都使用heapdump表示,做heapdump的工具和教程也非常多比如:chrome、vscode、heapdump 这个开源库。我用的 heapdump 库做的网上教程非常多这里不展开了。
局部性内存泄漏排查需要一定的内存泄漏排查经验,每次遇到都把它当成对自己的一次磨砺,这样的经验积累多了以后排查内存泄漏问题会越来越快。
1. 确定内存泄漏出现的时间范围
这一点非常重要,明确了这一点可以大幅度缩小排查范围。
经常会出现这种情况,这个迭代做了A、B、C 三个功能,压测时或上线后出现了内存泄漏。那么就可以直接锁定,内存泄漏发生小这三个新的功能之中。这种情况下就不需要非常麻烦的去生产做 heapdump 我们在本地通过一些工具就可以很轻松的分析定位出内存泄漏点。
由于我们 20年Q4 的一些特殊情况,当我们发现存在内存泄漏的时候已经很难确定内存泄漏初次出现在什么时间点了,只能大概锁定在 1 月的时间内。这一个月中我们又经历了一个大版本迭代,如果一一排查这些功能与接口成本必然非常高。
所以还需要结合更多的数据进行进一步分析
2. 采集 heapdump 数据
- 生产启动时
node添加--expose-gc,这个参数会向全局注入gc()方法,方便手动触发 GC 获取更准确的堆快照数据 - 这里我加入了两个接口并带上了自己的专属权限,
- 手动触发 GC
- 打印堆快照
-
heapdump- 项目启动后第一次打印快照数据
- 内存上涨 100M 后:先触发 GC,再第二次打印堆快照数据
- 内存接近临界时再次触发 GC 然后打印堆快照
采集堆快照数据时需要特别注意的一些点!
- 在
heapdump时 Node 服务会中断,根据当时服务器内存大小这个时间会在 2 ~ 30min 左右。在生产环境做heapdump需要和运维一起制定合理的策略。我在这里是使用了主、备两个pod, 当主pod停掉之后,业务请求会通过负载均衡到备用pod由此保障生产业务的正常进行。(这个过程必定是一个与运维密切配合的过程,毕竟heapdump玩抽还需要通过他们拿到服务器中堆快照文件)- 上述接近临界点打印快照只是一个模糊的描述,如果你试过就知道等非常接近临界点再打印内存快照就打印不出来了。所以接近这个度需要自己把握。
- 做至少 3 次
heapdump(实际上为了拿到最详细的数据我是做了 5 次)
3. 结合监控面板的数据进行分析
需要你的应用服务接入监控,我这里应用是使用prometheus + grafana 做的监控, 主要监控服务的以下指标
-
QPS(每秒请求访问量) ,请求状态,及其访问路径 -
ART(平均接口响应时间) 及其访问数据 -
NodeJs版本 -
Actice Handlers(句柄) -
Event Loop Lag(事件滞后) - 服务进程重启次数
- CPU 使用率
- 内存使用:
rss、heapTotal、heapUsed、external、heapAvailableDetail
只有
heapdump数据是不够的,heapdump数据非常晦涩,就算在可视化工具的加持下也难以准确定位问题。这个时候我是结合了grafana的一些数据一起看。
我的分析处理结果
由于当时的对快照数据丢失了,我这里模拟一下当时的场景。
1、通过 grafana 监控面看看到内存一直在涨一直下不来,但同时我也注意到,服务中的句柄
Heap Dump: Heapdump, Die folgenden Teile sind alle: Die Verwendung vonheapdumpbedeutet, dass es viele Tools und Tutorials zum Ausführen vonheapdumpgibt, wie zum Beispiel: Chrome, vscode und die Open-Source-Bibliothek heapdump. Es gibt viele Online-Tutorials für die von mir verwendete Heapdump-Bibliothek, auf die ich hier nicht näher eingehen werde.schneller.
1. Bestimmen Sie den Zeitraum, in dem der Speicherverlust auftritt
Das ist sehr wichtig verbessern Den Umfang der Untersuchung eingrenzen.
Diese Situation tritt häufig auf. Diese Iteration hat drei Funktionen A, B und C, und während des Stresstests oder nach dem Online-Gehen tritt ein Speicherverlust auf. Dann können Sie direkt sperren und bei diesen drei neuen Funktionen treten kleine Speicherlecks auf. In diesem Fall ist es nicht erforderlich, in die Produktion zu gehen, umheapdumpdurchzuführen. Mit einigen Tools können wir den Speicherleckpunkt einfach lokal analysieren und lokalisieren. 🎜🎜Aufgrund einiger besonderer Umstände in unseremQ4 von 2020, als wir ein Speicherleck entdeckten, war es schwierig zu bestimmen, wann das Speicherleck zum ersten Mal auftrat. Wir konnten es nur grob im Januar beheben. Diesen Monat haben wir eine weitere große Versionsiteration durchlaufen. Wenn wir diese Funktionen und Schnittstellen einzeln überprüfen, werden die Kosten sehr hoch sein. Daher müssen mehr Daten für die weitere Analyse kombiniert werden🎜2 Heapdump-Daten sammeln
🎜Erfassung Es gibt einige Punkte, die beim Häufen von Snapshot-Daten besondere Aufmerksamkeit erfordern! 🎜
- Wenn die Produktion beginntnode Fügen Sie
--expose-gchinzu. Dieser Parameter fügt die Methodegc()global ein, um das manuelle Auslösen von GC zu erleichtern und einen genauerenHeap-SnapshotDaten- Hier habe ich zwei Schnittstellen hinzugefügt und meine eigenen exklusiven Berechtigungen mitgebracht:
- GC manuell auslösen
- Heap-Snapshot drucken
heapdumpli>
- Drucken Sie Snapshot-Daten zum ersten Mal nach dem Start des Projekts
- Nachdem der Speicher um 100 MB erhöht wurde : Zuerst GC auslösen und dann die Heap-Snapshot-Daten ein zweites Mal drucken
- GC erneut auslösen, wenn der Speicher fast kritisch ist, und dann den Heap-Snapshot drucken
- Der Node-Dienst wird während des
heapdumpunterbrochen. Diese Zeit beträgt etwa 2 bis 30 Minuten, abhängig von der Größe des Serverspeichers zu diesem Zeitpunkt . Wenn Sieheapdumpin einer Produktionsumgebung ausführen, müssen Sie mit Betrieb und Wartung zusammenarbeiten, um eine vernünftige Strategie zu entwickeln. Hier verwende ich zweiPod, den primären und den Backup-Pod. Wenn der primärePodgestoppt wird, werden die Geschäftsanforderungen auf den Backup-Podverteilt . Dies stellt den normalen Ablauf des Produktionsbetriebs sicher. (Dieser Prozess muss eng mit Betrieb und Wartung koordiniert werden. Schließlich mussheapdumpüber sie dieHeap-Snapshot-Datei auf dem Server abrufen.)- Das oben erwähnte Drucken von Schnappschüssen in der Nähe des kritischen Punkts ist nur eine vage Beschreibung. Wenn Sie es ausprobiert haben, wissen Sie, dass es nicht ausgedruckt wird, wenn Sie warten, bis es sehr nahe am kritischen Punkt ist, und dann den Speicher drucken Schnappschuss. Sie müssen sich also beherrschen, um diesem Grad nahe zu kommen.
- Führen Sie
heapdumpmindestens dreimal durch (eigentlich habe ich es fünfmal gemacht, um die detailliertesten Daten zu erhalten)3. Kombinieren Sie die Daten aus dem Überwachungspanel zur Analyse🎜Sie benötigen Ihren Anwendungsdienst, um auf die Überwachung zuzugreifen. Meine Anwendung verwendet hier prometheus + <code>grafanaÜberwachung, hauptsächlich Überwachung der folgenden Indikatoren des Dienstes 🎜
QPS(Anfragebesuche pro Sekunde), Anforderungsstatus und ZugriffspfadART(durchschnittliche Antwortzeit der Schnittstelle) und seine ZugriffsdatenNodeJsVersionAktische Handler(Handle)Ereignisschleifenverzögerung(Ereignisverzögerung)- Anzahl der Dienstprozessneustarts
- CPU-Auslastung
- Speichernutzung:
rss,heapTotal,heapUsed,external,heapAvailableDetail🎜Nurheapdump-Daten reichen nicht aus,heapdump-Daten sind selbst in Visualisierungstools sehr undurchsichtig Es ist auch schwierig, das Problem mit dem Segen genau zu lokalisieren. Zu diesem Zeitpunkt habe ich es mit einigen Daten vongrafanakombiniert, um es mir anzusehen. 🎜Meine Analyse- und Verarbeitungsergebnisse
🎜Da die Snapshot-Daten zu diesem Zeitpunkt verloren gingen, werde ich die Szene hier simulieren . . 🎜🎜1. Über diegrafana-Überwachungsschnittstelle habe ich gesehen, dass der Speicher gestiegen und nicht gesunken ist. Gleichzeitig ist mir aber auch aufgefallen, dass die Anzahl derHandlescode> im Dienst ist ebenfalls in die Höhe geschossen und ist nicht zurückgegangen. 🎜🎜🎜🎜<p>2. Dies ist meine Überprüfung der neuen Funktionen in dem Monat, in dem das Leck auftrat. Ich vermute, dass das Speicherleck durch die Verwendung der Nachrichtenwarteschlangenkomponente <code>bullverursacht wurde. Ich habe zuerst den relevanten Anwendungscode analysiert, konnte aber nicht erkennen, dass darin etwas nicht stimmte, das einen Speicherverlust verursachte. In Kombination mit dem Handle-Leak-Problem in 1 scheint es, dass Sie nach der Verwendung vonbullbestimmte Ressourcen manuell freigeben müssen. Zu diesem Zeitpunkt bin ich mir über den genauen Grund nicht sicher.bull消息队列组件造成的内存泄漏。先去分析了相关应用代码,但并看不出那里写的有问题导致了内存泄漏, 结合 1 中句柄泄漏的问题感觉是在使用bull后需要手动的去释放某些资源,在这个时候还不太确定具体原因。3、然后对 5 次的
heapdunmp数据进行了分析,数据导入chrome对 5 次堆快照进行对比后,发现每次创建队列后 TCP、Socket、EventEmitter 的事件都没有被释放到。到这里基本可以确定是由于对bull的使用不规范导致的。在bull通常不会频繁创建队列,队列占用的系统资源并不会被自动释放,若有需要,需手动释放。
4、在调整完代码后重新进行了压测,问题解决。
Tips: Nodejs 中的
句柄是一种指针,指向底层系统资源(如文件、网络连接等)。句柄允许 Node.js 程序访问和操作这些资源,而无需直接与底层系统交互。句柄可以是整数或对象,具体取决于 Node.js 库或模块使用的句柄类型。常见句柄:
fs.open()返回的文件句柄net.createServer()返回的网络服务器句柄dgram.createSocket()返回的 UDP socket 句柄child_process.spawn()返回的子进程句柄crypto.createHash()返回的哈希句柄zlib.createGzip()返回的压缩句柄heapdump 分析总结
通常很多人第一次拿到
堆快照数据是懵的,我也是。在看了网上无数的分析技巧结合自身实战后总结了一些比较好用的技巧,一些基础的使用教程这里就不讲了。这里主要讲数据导入chrome后如何看图;Summary 视图
TCPSocketEventEmitterglobalComparison 视图
如果通过
Summary视图, 不能定位到问题这时我们一般会使用Comparison视图。通过这个视图我们能对比两个堆快照中对象个数、与对象占有内存的变化; 通过这些信息我们可以判断在一段时间(某些操作)之后,堆中的对象与内存变化的数值,通过这些数值我们可以找出一些异常的对象。通过这些对象的名称属性或作用可以缩小我们内存泄漏的排查范围。在
3. Dann wurden die 5-maligenComparison视图中选择两个堆快照,并在它们之间进行比较。您可以查看哪些对象在两个堆快照之间新增,哪些对象在两个堆快照之间减少,以及哪些对象的大小发生了变化。Comparisonheapdunmp-Daten analysiert und die Daten inchromeimportiert. Nach dem Vergleich der 5-maligen Heap-Snapshots wurde festgestellt, dass danach Bei jeder Warteschlangenerstellung werden TCP-, Socket- und EventEmitter-Ereignisse nicht freigegeben. Zum jetzigen Zeitpunkt ist grundsätzlich sicher, dass die Ursache in der unregelmäßigen Verwendung vonbullliegt. Warteschlangen werden inbullnormalerweise nicht häufig erstellt und die von der Warteschlange belegten Systemressourcen werden bei Bedarf nicht automatisch freigegeben.
4. Nach der Anpassung des Codes wurde der Stresstest erneut durchgeführt und das Problem behoben. Tipps: Das
handlein Nodejs ist ein Zeiger, der auf die zugrunde liegenden Systemressourcen (wie Dateien, Netzwerkverbindungen usw.) verweist. Mithilfe von Handles können Node.js-Programme auf diese Ressourcen zugreifen und diese bearbeiten, ohne direkt mit dem zugrunde liegenden System zu interagieren. Das Handle kann eine Ganzzahl oder ein Objekt sein, abhängig vom Handle-Typ, der von der Node.js-Bibliothek oder dem Node.js-Modul verwendet wird. AllgemeinerHandle:
fs.open()Dateihandle zurückgegebennet.createServer() Code > Das zurückgegebene Netzwerkserver-Handledgram.createSocket()Das zurückgegebene UDP-Socket-Handlechild_process.spawn()Das Zurückgegebenes untergeordnetes Prozesshandlecrypto.createHash()Das zurückgegebene Hash-Handlezlib.createGzip()Zurückgegebenes Komprimierungshandle
![[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen](https://img.php.cn/upload/article/000/000/024/3ac32851609e14d3da1d33f80496eee4-2.png)
![[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen](https://img.php.cn/upload/article/000/000/024/5ec58d2950a8a038af2e3794ac452eac-3.png) 看这个视图的时候一般会先对 Retained Size 进行排查,然后观察其中对象的大小与数量,有经验的工程师,可以快速判断出某些对象数量异常。在这个视图中除了关心自己定义的一些对象之外,
一些容易发生内存泄漏的对象也需要注意如:
看这个视图的时候一般会先对 Retained Size 进行排查,然后观察其中对象的大小与数量,有经验的工程师,可以快速判断出某些对象数量异常。在这个视图中除了关心自己定义的一些对象之外,
一些容易发生内存泄漏的对象也需要注意如:![[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen](https://img.php.cn/upload/article/000/000/024/2b53f8bd03c08e00f15929d1f42ae4da-4.png)
Zusammenfassung der Heapdump-Analyse
Normalerweise erhalten viele Leute zum ersten Mal den Heap-SnapshotDie Daten sind verwirrt, und ich auch. Nachdem ich unzählige Analysetechniken im Internet gelesen und mit meiner eigenen Praxis kombiniert habe, habe ich einige weitere nützliche Techniken zusammengefasst. Einige grundlegende Tutorials zur Verwendung werden hier nicht besprochen. Hier sprechen wir hauptsächlich darüber, wie man Bilder nach dem Importieren von Daten in <code>chrome anzeigt ![[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen](https://img.php.cn/upload/article/000/000/024/fb8d54159c4bbba0c28af97d6b1eb853-5.png)
Wenn wir uns diese Ansicht ansehen, überprüfen wir normalerweise zuerst die beibehaltene Größe Erfahrene Ingenieure können anhand der Größe und Anzahl der Objekte schnell feststellen, dass die Anzahl bestimmter Objekte abnormal ist. Aus dieser Sicht kümmern Sie sich nicht nur um einige von Ihnen definierte Objekte, sondern
Einige Objekte, die anfällig für Speicherverluste sind, erfordern ebenfalls Aufmerksamkeit, wie zum Beispiel:
TCPSocket- EventEmitter
global
Vergleichsansicht
![[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen](https://img.php.cn/upload/article/000/000/024/8075e15765360c3c802b42b410e6b54b-6.png) If Wir haben die Ansicht
If Wir haben die Ansicht Zusammenfassung übergeben. Wenn das Problem nicht lokalisiert werden kann, verwenden wir normalerweise die Ansicht Vergleich. Durch diese Ansicht können wir die Anzahl der Objekte in den beiden Heap-Snapshots und die Änderungen im von den Objekten belegten Speicher vergleichen;
Anhand dieser Informationen können wir die Werte von Objekten im Heap und die Speicheränderungen nach einer gewissen Zeit beurteilen (bestimmte Vorgänge). Anhand dieser Werte können wir einige abnormale Objekte finden. Die Namensattribute oder Funktionen dieser Objekte können den Umfang unserer Speicherleckuntersuchung einschränken.
Vergleich zwei Heap-Snapshots aus und vergleichen Sie sie. Sie können sehen, welche Objekte zwischen zwei Heap-Snapshots hinzugefügt wurden, welche Objekte zwischen zwei Heap-Snapshots reduziert wurden und welche Objekte sich in der Größe geändert haben. Mit der Ansicht Vergleich können Sie auch Beziehungen zwischen Objekten sowie Objektdetails wie Typ, Größe und Referenzanzahl anzeigen. Anhand dieser Informationen können Sie nachvollziehen, welche Objekte den Speicherverlust verursachen. 🎜🎜🎜🎜🎜🎜Containment-Ansicht🎜🎜🎜 zeigt alle erreichbaren Referenzbeziehungen zwischen Objekten. Jedes Objekt wird als Punkt dargestellt und durch eine Linie mit seinem übergeordneten Objekt verbunden. Auf diese Weise können Sie die hierarchischen Beziehungen zwischen Objekten sehen und verstehen, welche Objekte Speicherverluste verursachen. 🎜🎜🎜🎜🎜🎜Statistikansicht🎜🎜🎜Dieses Bild ist sehr einfach und ich werde nicht auf Details eingehen🎜🎜🎜🎜Speicherleckszenario
- Globale Variablen: Globale Variablen werden nicht recycelt
- Cache: Die Verwendung einer speicherintensiven Bibliothek eines Drittanbieters wie
lru-cacheführt zu einem Speicherausfall. Dies ist nicht der Fall Es wird empfohlen,redisanstelle vonlru-cacheim Nodejs-Dienst zu verwenden.lru-cache存的太多就会导致内存不够用,在 Nodejs 服务中建议使用redis替代lru-cache - 句柄泄漏:调用完系统资源没有释放
- 事件监听
- 闭包
- 循环引用
总结
服务需要接入监控,方便第一时间确定问题类型
判断内存泄漏是全局性的还是局部性的
全局性内存泄漏使用二分法快速排查定位
-
局部内存泄漏
- 确定内存泄漏出现时间点,快速定位问题功能
- 采堆快照数据,至少 3 次
- 结合监控数据、堆快照数据、与出现泄漏事时间点内的新功能对内存泄漏点进行定位
Summary遇到内存泄漏的问题不要畏惧,多积累内存泄漏问题的排查经验处理经验多了找起来就非常快了。每次解决之后做复盘总结回头再多看看
Handle-Leck: Systemressourcen werden nach dem Aufruf von Quote nicht freigegeben. id="heading-16">堆快照
🎜Keine Erinnerung Haben Sie keine Angst: Sammeln Sie mehr Erfahrung bei der Behebung von Speicherleckproblemen. Je mehr Erfahrung Sie bei der Lösung von Speicherleckproblemen haben, desto einfacher wird es, sie zu finden. Erstellen Sie nach jeder Lösung eine Überprüfungszusammenfassung und schauen Sie sich Heap Snapshot noch einmal an. Die Daten helfen Ihnen, schneller relevante Erfahrungen zu sammeln🎜🎜🎜🎜Andere🎜🎜🎜🎜Stresstest-Tools: wrk🎜🎜🎜Mehr Knoten Für entsprechendes Wissen besuchen Sie bitte: 🎜nodejs-Tutorial🎜! 🎜Das obige ist der detaillierte Inhalt von[Erfahrungszusammenfassung] Wie kann man Speicherlecks in Node beheben? Teilen Sie Ideen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Der Knoten lernt, wie er die Heap-Zuweisung minimiert und Speicherlecks verhindert
- Ein Artikel, in dem die Express- und Routing-Module in Node ausführlich erläutert werden
- In diesem Artikel erfahren Sie mehr über das Modulsystem im Knoten
- Ein Artikel, in dem die Identitätsauthentifizierung von Express in Node ausführlich erläutert wird
- Ein Artikel, der kurz analysiert, wie die Nachrichtenwarteschlange im Knoten verwendet wird
- Ein Artikel über das automatische Laden des Node-Back-End-Routings