
Heim >Web-Frontend >js-Tutorial >Douyins sehr beliebte Bild-Multiple-Choice-Spezialeffekte können über das Frontend schnell implementiert werden!
Douyins sehr beliebte Bild-Multiple-Choice-Spezialeffekte können über das Frontend schnell implementiert werden!

- 藏色散人nach vorne
- 2023-01-20 15:56:353624Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Front-End-Bildspezialeffekte. Er stellt hauptsächlich vor, wie das Front-End einen Bild-Multiple-Choice-Spezialeffekt implementiert, der in letzter Zeit sehr beliebt ist Schauen Sie es sich gemeinsam an. Ich hoffe, es wird Ihnen helfen, wenn Sie es brauchen.


Aus Sicherheitsgründen haben die Nuggets nicht „allow="microphone *;camera *" auf dem iframe-Tag festgelegt, was dazu führte, dass die Kamera nicht geöffnet werden konnte! Klicken Sie zum Anzeigen bitte oben rechts auf „Details anzeigen“! Oder klicken Sie auf den Link unten, um das
//复制链接预览 https://code.juejin.cn/pen/7160886403805970445
Vorwort
anzuzeigen. Kürzlich gab es eine sehr beliebte Bild-Multiple-Choice-Frage. Ende. Im Folgenden werde ich hauptsächlich darüber sprechen, wie Sie bestimmen, ob Sie Ihren Kopf nach links oder rechts bewegen. 图片选择题特别火,今天就来讲一下前端如何实现,下面我主要讲一下如何判断左右摆头。
架构和概念
抽象整体的实现思路如下

MediaPipe Face Mesh是一个解决方案,即使在移动设备上也能实时估计468个3D面部地标。它使用机器学习(ML)来推断3D面部表面,只需要一个摄像头输入,而无需专用的深度传感器。该解决方案利用轻量级模型架构以及整个管道中的GPU加速,为实时体验提供了至关重要的实时性能。
引入
import '@mediapipe/face_mesh'; import '@tensorflow/tfjs-core'; import '@tensorflow/tfjs-backend-webgl'; import * as faceLandmarksDetection from '@tensorflow-models/face-landmarks-detection';
创建人脸模型
引入tensorflow训练好的人脸特征点检测模型,预测 486 个 3D 人脸特征点,推断出人脸的近似面部几何图形。
-
maxFaces默认为1。模型将检测到的最大人脸数量。返回的面孔数量可以小于最大值(例如,当输入中没有人脸时)。强烈建议将此值设置为预期的最大人脸数量,否则模型将继续搜索缺失的面孔,这可能会减慢性能。 -
refineLandmarks默认为false。如果设置为真,则细化眼睛和嘴唇周围的地标坐标,并在虹膜周围输出其他地标。(这里我可以设置false,因为我们没有用到眼部坐标) -
solutionPath通往am二进制文件和模型文件所在位置的路径。(强烈建议将模型放到国内的对象存储里面,首次加载可以节省大量时间,大小大概10M)
async createDetector(){
const model = faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;
const detectorConfig = {
maxFaces:1, //检测到的最大面部数量
refineLandmarks:false, //可以完善眼睛和嘴唇周围的地标坐标,并在虹膜周围输出其他地标
runtime: 'mediapipe',
solutionPath: 'https://cdn.jsdelivr.net/npm/@mediapipe/face_mesh', //WASM二进制文件和模型文件所在的路径
};
this.detector = await faceLandmarksDetection.createDetector(model, detectorConfig);
}
人脸识别
返回的面孔列表包含图像中每个面孔的检测面。如果模型无法检测到任何面孔,列表将是空的。 对于每个面,它包含一个检测到的面孔的边界框,以及一个关键点数组。MediaPipeFaceMesh返回468个关键点。每个关键点都包含x和y,以及一个名称。
现在,您可以使用探测器来检测人脸。estimateFaces方法接受多种格式的图像和视频,包括:
HTMLVideoElement、HTMLImageElement、HTMLCanvasElement和Tensor3D。
-
flipHorizontal可选。默认为false。当图像数据来自相机时,结果必须水平翻转。
async renderPrediction() {
var video = this.$refs['video'];
var canvas = this.$refs['canvas'];
var context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const Faces = await this.detector.estimateFaces(video, {
flipHorizontal:false, //镜像
});
if (Faces.length > 0) {
this.log(`检测到人脸`);
} else {
this.log(`没有检测到人脸`);
}
}
该框表示图像像素空间中面部的边界框,xMin、xMax表示x-bounds、yMin、yMax表示y-bounds,宽度、高度表示边界框的尺寸。 对于关键点,x和y表示图像像素空间中的实际关键点位置。z表示头部中心为原点的深度,值越小,键点离相机越近。Z的大小使用与x大致相同的比例。 这个名字为一些关键点提供了一个标签,例如“嘴唇”、“左眼”等。请注意,并非每个关键点都有标签。
如何判断
找到人脸上的两个两个点
第一个点 额头中心位置第二个点 下巴中心位置
const place1 = (face.keypoints || []).find((e,i)=>i===10); //额头位置
const place2 = (face.keypoints || []).find((e,i)=>i===152); //下巴位置
/*
x1,y1
|
|
|
x2,y2 -------|------- x4,y4
x3,y3
*/
const [x1,y1,x2,y2,x3,y3,x4,y4] = [
place1.x,place1.y,
0,place2.y,
place2.x,place2.y,
this.canvas.width, place2.y
];通过canvas.width 额头中心位置和下巴中心位置计算出 x1,y1,x2,y2,x3,y3,x4,y4
Architektur und Konzepte
Die allgemeine Implementierungsidee der Abstraktion ist wie folgt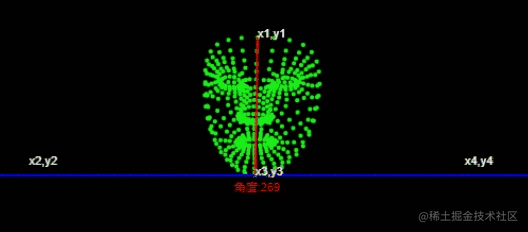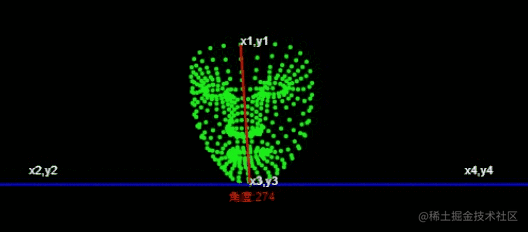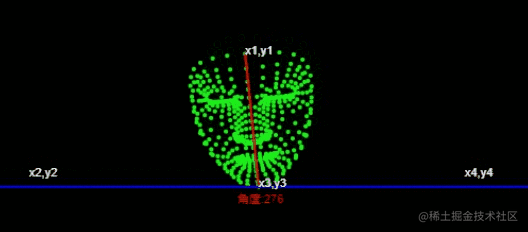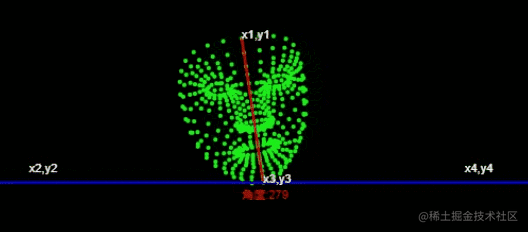
 🎜🎜
🎜🎜Führen Sie 🎜getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle) ein, um ein Gesichtsmodell zu erstellen. 🎜🎜Führen Sie den Tensorflow-trainierten Modell zur Erkennung von Gesichtsmerkmalspunkten ein >, <code>486 3D-Gesichtsmerkmalspunkte vorhersagen und die ungefähre Gesichtsgeometrie des Gesichts ableiten. 🎜
-
maxFaces Standard ist 1. Die maximale Anzahl an Gesichtern, die das Modell erkennt. Die Anzahl der zurückgegebenen Gesichter kann unter dem Maximum liegen (z. B. wenn die Eingabe keine Gesichter enthält). Es wird dringend empfohlen, diesen Wert auf die maximal erwartete Anzahl von Gesichtern festzulegen, da das Modell andernfalls weiterhin nach fehlenden Gesichtern sucht, was die Leistung beeinträchtigen kann.
-
refineLandmarks Der Standardwert ist „false“. Bei der Einstellung „true“ werden die Orientierungspunktkoordinaten um die Augen und Lippen verfeinert und zusätzliche Orientierungspunkte um die Iris ausgegeben. (Ich kann hier false festlegen, da wir keine Augenkoordinaten verwenden)
-
solutionPath Der Pfad zum Speicherort der Binär- und Modelldateien. (Es wird dringend empfohlen, das Modell in den heimischen Objektspeicher zu legen. Das erste Laden kann viel Zeit sparen. Die Größe beträgt etwa 10M)
rrreee🎜 🎜Gesichtserkennung🎜🎜Die zurückgegebene Gesichtsliste enthält die erkannten Gesichter für jedes Gesicht im Bild. Wenn das Modell keine Gesichter erkennen kann, ist die Liste leer.
Für jedes Gesicht enthält es einen Begrenzungsrahmen des erkannten Gesichts und ein Array von Schlüsselpunkten. MediaPipeFaceMesh gibt 468 Schlüsselpunkte zurück. Jeder Schlüsselpunkt enthält x und y sowie einen Namen. 🎜🎜🎜Jetzt können Sie den Detektor verwenden, um Gesichter zu erkennen. Die Methode „estimateFaces“ akzeptiert Bilder und Videos in verschiedenen Formaten, darunter:
🎜Gesichtserkennung🎜🎜Die zurückgegebene Gesichtsliste enthält die erkannten Gesichter für jedes Gesicht im Bild. Wenn das Modell keine Gesichter erkennen kann, ist die Liste leer.
Für jedes Gesicht enthält es einen Begrenzungsrahmen des erkannten Gesichts und ein Array von Schlüsselpunkten. MediaPipeFaceMesh gibt 468 Schlüsselpunkte zurück. Jeder Schlüsselpunkt enthält x und y sowie einen Namen. 🎜🎜🎜Jetzt können Sie den Detektor verwenden, um Gesichter zu erkennen. Die Methode „estimateFaces“ akzeptiert Bilder und Videos in verschiedenen Formaten, darunter: HTMLVideoElement, HTMLImageElement, HTMLCanvasElement und Tensor3D. 🎜🎜-
flipHorizontal Optional. Der Standardwert ist falsch. Wenn Bilddaten von einer Kamera stammen, muss das Ergebnis horizontal gespiegelt werden.
rrreee🎜🎜🎜Dieses Feld stellt den Begrenzungsrahmen des Gesichts im Bildpixelraum dar, xMin und xMax stellen x-Grenzen dar, yMin und yMax stellen y-Grenzen dar und die Breite und Höhe stellen die Größe des Begrenzungsrahmens dar .
Bei Schlüsselpunkten stellen x und y die tatsächliche Schlüsselpunktposition im Bildpixelraum dar. z stellt die Tiefe dar, in der die Mitte des Kopfes der Ursprung ist. Je kleiner der Wert, desto näher liegt der Schlüsselpunkt an der Kamera. Die Größe von Z verwendet ungefähr denselben Maßstab wie x.
Dieser Name dient als Bezeichnung für einige wichtige Punkte, z. B. „Lippen“, „linkes Auge“ usw. Beachten Sie, dass nicht jeder Schlüsselpunkt eine Beschriftung hat. 🎜So beurteilen Sie🎜🎜Finden Sie zwei Punkte im Gesicht einer Person🎜🎜Der erste Punkt Stirnmittenposition Der zweite Punkt Kinnmittenposition🎜rrreee🎜Berechnen Sie <code>x1,y1,x2,y2,x3, durch canvas.width <code>Stirnmittenposition und Kinnmittenposition y3,x4,y4 🎜🎜🎜🎜getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)
Modell zur Erkennung von Gesichtsmerkmalspunkten ein >, <code>486 3D-Gesichtsmerkmalspunkte vorhersagen und die ungefähre Gesichtsgeometrie des Gesichts ableiten. 🎜-
maxFacesStandard ist 1. Die maximale Anzahl an Gesichtern, die das Modell erkennt. Die Anzahl der zurückgegebenen Gesichter kann unter dem Maximum liegen (z. B. wenn die Eingabe keine Gesichter enthält). Es wird dringend empfohlen, diesen Wert auf die maximal erwartete Anzahl von Gesichtern festzulegen, da das Modell andernfalls weiterhin nach fehlenden Gesichtern sucht, was die Leistung beeinträchtigen kann. -
refineLandmarksDer Standardwert ist „false“. Bei der Einstellung „true“ werden die Orientierungspunktkoordinaten um die Augen und Lippen verfeinert und zusätzliche Orientierungspunkte um die Iris ausgegeben. (Ich kann hierfalsefestlegen, da wir keine Augenkoordinaten verwenden) -
solutionPathDer Pfad zum Speicherort der Binär- und Modelldateien. (Es wird dringend empfohlen, das Modell in den heimischen Objektspeicher zu legen. Das erste Laden kann viel Zeit sparen. Die Größe beträgt etwa10M)
🎜Gesichtserkennung🎜🎜Die zurückgegebene Gesichtsliste enthält die erkannten Gesichter für jedes Gesicht im Bild. Wenn das Modell keine Gesichter erkennen kann, ist die Liste leer.
Für jedes Gesicht enthält es einen Begrenzungsrahmen des erkannten Gesichts und ein Array von Schlüsselpunkten. MediaPipeFaceMesh gibt 468 Schlüsselpunkte zurück. Jeder Schlüsselpunkt enthält x und y sowie einen Namen. 🎜🎜🎜Jetzt können Sie den Detektor verwenden, um Gesichter zu erkennen. Die Methode „estimateFaces“ akzeptiert Bilder und Videos in verschiedenen Formaten, darunter: HTMLVideoElement, HTMLImageElement, HTMLCanvasElement und Tensor3D. 🎜🎜-
flipHorizontalOptional. Der Standardwert ist falsch. Wenn Bilddaten von einer Kamera stammen, muss das Ergebnis horizontal gespiegelt werden.
🎜🎜Dieses Feld stellt den Begrenzungsrahmen des Gesichts im Bildpixelraum dar, xMin und xMax stellen x-Grenzen dar, yMin und yMax stellen y-Grenzen dar und die Breite und Höhe stellen die Größe des Begrenzungsrahmens dar .
Bei Schlüsselpunkten stellen x und y die tatsächliche Schlüsselpunktposition im Bildpixelraum dar. z stellt die Tiefe dar, in der die Mitte des Kopfes der Ursprung ist. Je kleiner der Wert, desto näher liegt der Schlüsselpunkt an der Kamera. Die Größe von Z verwendet ungefähr denselben Maßstab wie x.
Dieser Name dient als Bezeichnung für einige wichtige Punkte, z. B. „Lippen“, „linkes Auge“ usw. Beachten Sie, dass nicht jeder Schlüsselpunkt eine Beschriftung hat. 🎜So beurteilen Sie🎜🎜Finden Sie zwei Punkte im Gesicht einer Person🎜🎜Der erste Punkt Stirnmittenposition Der zweite Punkt Kinnmittenposition🎜rrreee🎜Berechnen Sie <code>x1,y1,x2,y2,x3, durch canvas.width <code>Stirnmittenposition und Kinnmittenposition y3,x4,y4 🎜🎜🎜🎜getAngle({ x: x1, y: y1 }, { x: x2, y: y2 }){
const dot = x1 * x2 + y1 * y2
const det = x1 * y2 - y1 * x2
const angle = Math.atan2(det, dot) / Math.PI * 180
return Math.round(angle + 360) % 360
}
const angle = this.getAngle({
x: x1 - x3,
y: y1 - y3,
}, {
x: x2 - x3,
y: y2 - y3,
});
console.log('角度',angle)
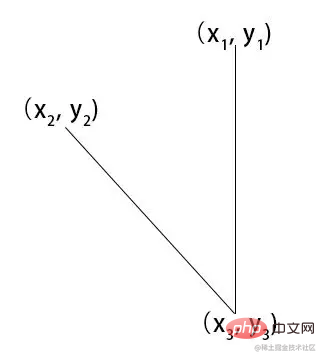
通过获取角度,通过角度的大小来判断左右摆头。
推荐:《web前端开发视频教程》
Das obige ist der detaillierte Inhalt vonDouyins sehr beliebte Bild-Multiple-Choice-Spezialeffekte können über das Frontend schnell implementiert werden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- CSS3 realisiert den Animationseffekt, wenn man klebrige Reisbällchen mit einem Löffel aufnimmt (super süß)!
- Lassen Sie uns darüber sprechen, wie Sie mit CSS Milchglaseffekte erzielen können (Untersuchung von Kompatibilitätslösungen).
- Reines CSS, um den Batterielade-Animationseffekt von Wasserwellen zu realisieren
- Empfehlung für das Atom-Basis-Plug-in: Synchronisierung und Spezialeffekttypisierung realisieren