
So deduplizieren Sie Daten in Oracle

- 青灯夜游Original
- 2023-01-04 14:42:2513839Durchsuche
Entfernungsmethode: 1. Verwenden Sie das Schlüsselwort „distinct“, um Duplikate zu entfernen, Syntax „SELECT DISTINCT field name FROM table name;“ 2. Verwenden Sie die Fensterfunktion row_number () over(), um Duplikate zu entfernen deduplizieren, die Syntax lautet „Feldnamen aus Tabellennamengruppe nach Feldnamen auswählen“; 4. Verwenden Sie rowid, um Pseudospalten zu deduplizieren.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, Oracle 11g-Version, Dell G3-Computer.
Geschäftsszenario
Bestimmte Daten müssen abgefragt werden, da zum Abfragen verwandter Informationen drei Tabellen erforderlich sind. Die Abfrageergebnisse lauten wie folgt:

Original-SQL-Anweisung
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
Methode 1: eindeutig Deduplizierung
SELECT DISTINCT kann verwendet werden, um doppelte Zeilen im Ergebnissatz zu filtern, um sicherzustellen, dass die Werte in der angegebenen Spalte oder den angegebenen Spalten, die in der SELECT-Klausel zurückgegeben werden, eindeutig sind. Die Syntax der
DISTINCT-Anweisung lautet wie folgt:
SELECT DISTINCT column_1,
column_2,
...
FROM
table_name;Beispiel:
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
Hinweis: Auf DISTINCT muss zuerst ein ORDER BY-Feld folgen, um Duplikate zu entfernen, und dann ORDER BY zum Sortieren verwenden. Wenn sich das Feld, das in ORDER BY sortiert werden muss, nicht im Feld nach „distinct“ befindet, wird daher natürlich ein Fehler ausgegeben.
Die Fehlermeldung lautet wie folgt:
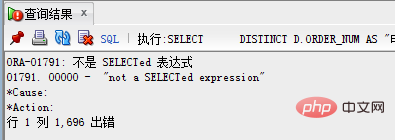
Methode 2: row_number() over()
Syntaxformat
select * from (select A.*, row_number() over(partition by A.name1 order by A.name12 desc) rn from A) where rn = 1
Beispiel
select * from ( select d.order_num as "申请单号" , d.create_time , d.emp_name as "申请人", (select extractvalue(t1.row_data,'/root/row/FI13_wasteName') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "废料名称", (select extractvalue(t1.row_data,'/root/row/FI13_units') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "单位", (select extractvalue(t1.row_data,'/root/row/FI13_estimate') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "预估数量", (select extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "累计出库数量", (select extractvalue(t1.row_data,'/root/row/FI13_receivingTime') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdCGYTX' ) as "收购方收货时间", (select extractvalue(t2.row_data,'/root/row/FI13_collectionTime') from dat_table_row t2 where d.document_id = t2.document_id and t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) as "实际收款时间", row_number() over(partition by d.order_num order by d.create_time desc) rn from dat_document d, dat_table_row dtr where d.form_name ='FI14' and d.document_id =dtr.document_id and (d.document_status != 'deleted' or d.document_status is null ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' and d.order_num = 'FI1420210708002' --FI1420210708002 ) where rn = 1;
Abfrageergebnisse

Methode 3 : Gruppieren nach
select 字段名 from 表名 group by 字段名;
Methode 4: Rowid verwenden (Pseudospaltendeduplizierung)
select id,name,age from test t1 where t1.rowid in (select min(rowid) from test t2 where t1.name=t2.name and t1.age=t2.age);
Empfohlenes Tutorial: „Oracle Tutorial“
Das obige ist der detaillierte Inhalt vonSo deduplizieren Sie Daten in Oracle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!