
Heim >Schlagzeilen >Drei Jahre Erfahrungsaustausch im Vorstellungsgespräch: vier Phasen und drei entscheidende Faktoren von Front-End-Interviews
Drei Jahre Erfahrungsaustausch im Vorstellungsgespräch: vier Phasen und drei entscheidende Faktoren von Front-End-Interviews

- 青灯夜游nach vorne
- 2022-12-16 15:32:333956Durchsuche
Die Beschäftigungssituation ist dieses Jahr einfach düster. Aufgrund der „Glücksmentalität“, dass das nächste Jahr schlimmer sein wird als dieses Jahr, habe ich mich ohne zu zögern entschieden, zu kündigen. Nach anderthalb Monaten harter Arbeit erhielt ich ein ziemlich gutes Angebot , Gehalt und Die Plattform wurde erheblich verbessert, aber es gibt immer noch eine große Lücke zwischen ihr und meinen psychologischen Erwartungen. Die wichtigste Schlussfolgerung lautet also: Sprechen Sie nicht offen! Sag nichts nackt! Sag nichts nackt! Da der Druck, der während des Interviews auf die Menschen ausgeübt wird, und der psychologische Schaden, der durch die Kluft zwischen Realität und Idealen verursacht wird, unermesslich sind, ist es eine gute Wahl, in einem solchen Umfeld zu überleben. 🔜
Als Front-End-Mitarbeiter stehen die Tiefe und Breite der Technologie an erster Stelle. Zu diesem Zeitpunkt müssen Sie Ihre Position und Richtung finden. Manche Leute sind sehr kompetent, aber der Interviewer fühlt sich während des Interviews unwohl. Er denkt, dass Sie arrogant/schlampig/selbstgerecht sind/sich nicht klar ausdrücken können, also wird er Sie einfach ablehnen. Das ist der größte Verlust, der den Gewinn überwiegt.
Das Folgende ist eine Zusammenfassung meiner gesamten Interviewvorbereitung und der Fragen, die mir gestellt wurden, da die Kommunikation mit dem Interviewer zu einem großen Teil keine einfache Bestätigung ist. Es ist am besten, das Wissen selbst weiterzugeben Fassen Sie es zusammen und drücken Sie es prägnant aus und vervollständigen Sie es dann vor Ort entsprechend den Fragen des Interviewers. [Empfohlenes Lernen:
Web-Frontend, 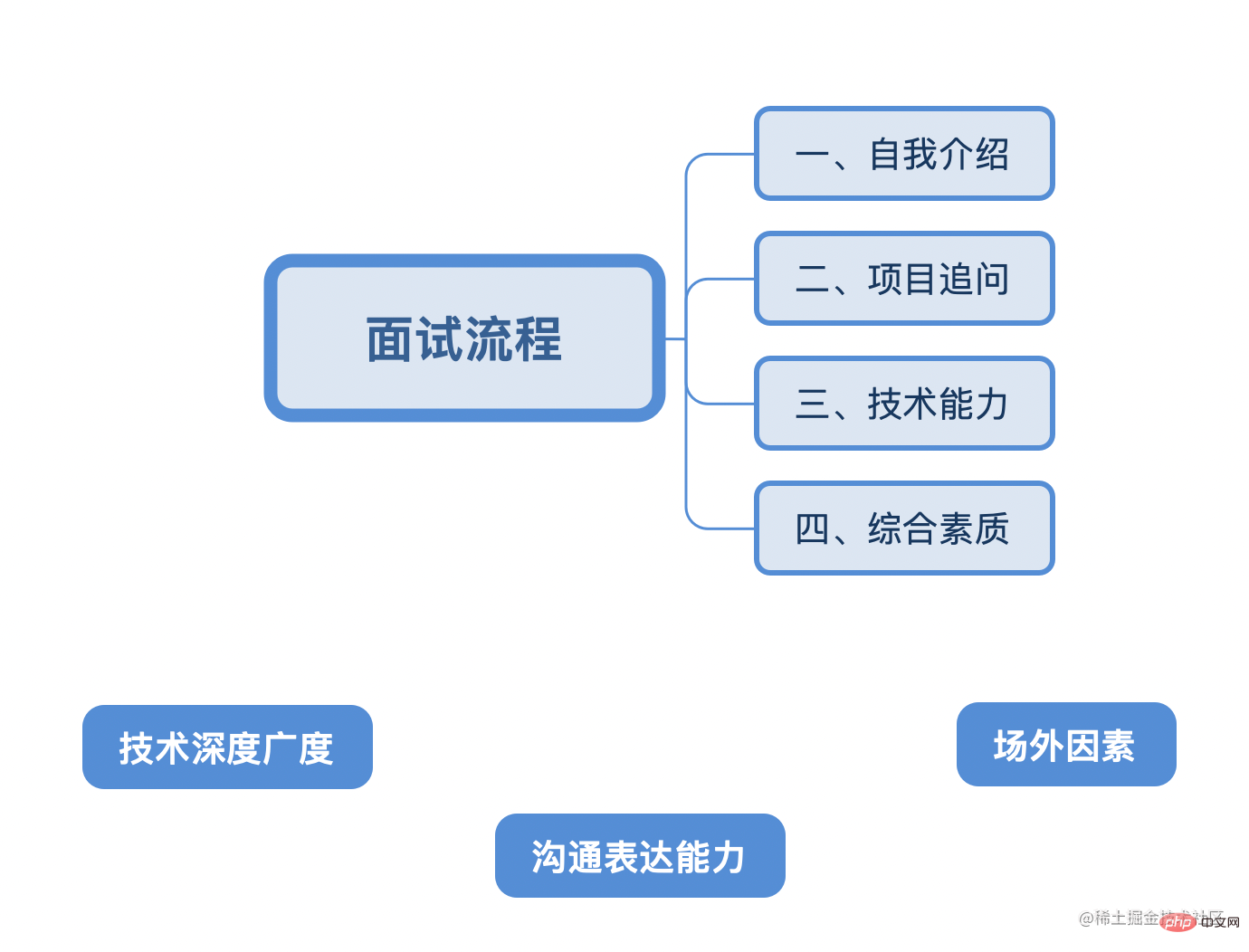 Programmierunterricht
Programmierunterricht
1. Der Interviewer bittet Sie, sich vorzustellen, und schränkt den Umfang der Selbstvorstellung nicht ein Um aus Ihrer Selbstvorstellung etwas zu lernen, muss die Einleitung kurz und reibungslos sein. Der Inhalt der Selbstvorstellung kann bei verschiedenen Interviewern genau gleich sein, daher ist es wichtig, Ihre Worte im Voraus vorzubereiten und sicher zu sein Aufpassen: Stolpern Sie nicht, seien Sie zuversichtlich!
Geschmeidiger Ausdruck und Kommunikationsfähigkeitengehören ebenfalls zu den Bewertungspunkten des Interviewers für Kandidaten. Ich war auch ein Interviewer, der selbstbewusst und großzügig ist und oft eher bevorzugt wird. 1. Persönliche Vorstellung (grundlegende Informationen), einschließlich des Hauptlebenslaufs, der kurz sein muss2 Was Sie gut können, einschließlich technischer und nichttechnischer. Techniker können Ihren Übergang verstehen, und Nicht-Techniker können Sie als Person verstehen
3 Wählen Sie die wichtigsten Projekte aus, die Sie durchgeführt haben, und stellen Sie nicht alle Projekte wie Empfehlungen vor4 Interessen oder Meinungen oder sogar Ihre eigenen Karrierepläne. Dies sollte dem Interviewer das Gefühl geben, dass er Lust auf „Werfen“ oder „Denken“ hat . Arbeiten.
Der Technologie-Stack, in dem ich gut bin, ist der Vue-Familien-Bucket. Ich bin mit den Verpackungstools Webpack und Vite vertraut von mittleren und großen Projekten von Grund auf und mit viel Geschick. In meinem vorherigen Unternehmen war ich hauptsächlich für die Produktlinie xx verantwortlich, und meine Hauptaufgaben waren. . . . . .
Zusätzlich zu entwicklungsbezogener Arbeit verfügt er auch über gewisse Erfahrung im technischen Management: z. B. als Anforderungsüberprüfung, UI/UE-Interaktionsüberprüfungsrichter, verantwortlich für die Entwicklungsplanung, Mitgliederzusammenarbeit, Überprüfung des Mitgliedercodes, Organisation regelmäßiger Treffen usw
Normalerweise schreibe ich einige Studienartikel oder Studiennotizen auf dem Blog, den ich erstellt habe, und veröffentliche sie auf Nuggets. Ich habe den XX Award gewonnen.
Versuchen Sie im Allgemeinen, die Selbstvorstellung auf 3-5 Minuten zu beschränken. Die erste Priorität besteht darin, prägnant und auf den Punkt zu kommen, gefolgt von der Hervorhebung Ihrer Fähigkeiten und Stärken. Für normale technische Interviewer ist die Selbstvorstellung lediglich eine übliche Eröffnungsrede vor dem Interview. Im Allgemeinen haben die im Lebenslauf aufgeführten grundlegenden Informationen bereits ihr grundlegendes Verständnis von Ihnen befriedigt. Aber Interviewer auf Vorgesetztenebene oder in der Personalabteilung werden Ihre Persönlichkeit, Ihre Verhaltensgewohnheiten, Ihre Stressresistenz und andere umfassende Fähigkeiten schätzen. Daher sollten Sie während des Vorstellungsgesprächs so positiv wie möglich sein, vielfältige Hobbys haben, wie kontinuierliches Lernen, Teamarbeit, und in der Lage sein, bedingungslos Überstunden zu machen usw. Natürlich möchte ich Sie nicht schummeln lassen, aber in dieser Umgebung sind diese „Nebenfähigkeiten“ auch magische Waffen, die Ihre Wettbewerbsfähigkeit bis zu einem gewissen Grad verbessern können. 2. Project Mining Daher sollten Sie der Vorbereitung des Projekts besondere Aufmerksamkeit schenken, wie zum Beispiel:Eingehende Untersuchung der
Technologie, die im Projekt verwendet wird
Kontrolle des GesamtdesignsIdeen des Projekts
Management des ProjektsBetriebsprozess
Die Fähigkeit zur Teamarbeit
.Ich werde hier nicht auf Details eingehen, da diese von Person zu Person unterschiedlich sind. Finden Sie es einfach basierend auf Ihrer eigenen Situation heraus. Was sind die Optimierungspunkte
des Projekts?3. Persönlich
Wenn Sie das technische Vorstellungsgespräch bestehen und die Ebene des Vorgesetzten und der Personalabteilung erreichen, werden zusätzlich Ihr persönliches Potenzial, Ihre Lernfähigkeit und Ihr persönliches Potenzial geprüft. Persönlichkeit und In Bezug auf Soft Skills wie Teamintegration sind hier einige Fragen, die leicht zu stellen sind:Warum haben Sie den Job gewechselt?
Beginnen Sie direkt mit der persönlichen Entwicklung, um Ihren Ehrgeiz zu zeigen:
- Ich wollte schon immer zu einer größeren Plattform gehen, die nicht nur eine bessere technische Atmosphäre bietet, sondern auch mehr lernt
- Ich möchte mich erweitern Wissenstechnisch habe ich schon immer x-end xx-Produkte hergestellt. Der Technologie-Stack ist relativ einfach, daher sollte ich von xx lernen.
- Ich bin in meinem vorherigen Job in eine Komfortzone geraten und konnte nur die Dinge tun, die ich tun möchte, um meine technische Breite zu erweitern und mit einigen neuen technischen Systemen in Kontakt zu treten und sie zu erlernen, die von größerem Nutzen sein werden zu meiner weiteren persönlichen Entwicklung
Erzählen Sie uns etwas über Sie und gewöhnliche Frontends. Was sind Ihre Highlights?
1. Ich bin gut im Planen und Zusammenfassen der von mir bearbeiteten Projekte. Das eine ist die Geschäftszerlegung, das andere ist die Zerlegung der Codemodule. Lösung: Unterscheiden Sie jedes Codemodul nach seiner Funktion. Gehen Sie erneut zur Entwicklung. Ich denke, das ist etwas, was viele Front-Ends, die nur blinde Geschäftsentwicklung betreiben, nicht können intensiv gelesen, es hat ungefähr dreißig Stunden gedauert, ihn zu schreiben und die Funktion und Rolle jeder Zeile Quellcode zu interpretieren (aber warum sind die Lese- und Like-Werte so gering)? .Was sind deine Defizite?
Ich bin ernster und introvertierter, deshalb werde ich auch versuchen, mich extrovertierter zu machen. Eine besteht darin, verschiedene Review-Meetings abzuhalten. Als Front-End-Vertreter muss ich verschiedene Materialien vorbereiten und Reden halten. Deshalb tausche ich mich mehr über technische Themen im Team aus und veranstalte jede Woche regelmäßige Meetings, die mir auch den Mut geben, mich zu äußern und zu diskutieren.Achten Sie in letzter Zeit auf neue Technologien?
- Paketabhängigkeitsverwaltungstool pnpm (keine wiederholte Installation von Abhängigkeiten, nicht flache node_modules-Struktur, Hinzufügen abhängiger Pakete über symbolische Links)
- Paketierungstool vite (extrem schnelle Entwicklungsumgebung)
- flutter (Google Einführung eines Open-Source-Frameworks für die Entwicklung mobiler Anwendungen (Apps), das sich auf plattformübergreifende Funktionalität, hohe Wiedergabetreue und hohe Leistung konzentriert , sagte Es ist 10-mal schneller als Vite und Webpack ist 700-mal schneller. Dann hat Yuxi persönlich bestätigt, dass es nicht 10-mal schneller als Vite ist Immer in eine bestimmte Richtung? Weiter studieren?
- In 3-5 Jahren werde ich neben der Verbesserung meiner technischen Tiefe auch mein Wissen erweitern, d. h. sowohl die Tiefe als auch die Breite verbessern, hauptsächlich in der Breite Großes Front-End: Können Sie bessere Entscheidungen treffen?
Mein persönlicher Plan ist wie folgt:
Wenn Sie in 5 bis 7 Jahren genügend Wissen gesammelt haben, können Sie eine bestimmte Interessensrichtung auswählen, um sich eingehend zu informieren, und danach streben, ein Experte auf diesem Gebiet zu werden.
- Team Umfang, Teamvorgaben und Entwicklungsprozess
Das ist von Person zu Person unterschiedlich, also bereiten Sie sich einfach entsprechend vor, denn die F&E-Modelle von Teams unterschiedlicher Größe sind sehr unterschiedlich.Die Ziele der Codeüberprüfung
1. Das Wichtigste ist die Wartbarkeit des Codes (Variablenbenennung, Kommentare, Funktionseinheitsprinzip usw.)
2. Erweiterbarkeit: Kapselungsfunktionen (ob Komponenten und Codelogik). reproduzierbare Anwendung, Skalierbarkeit)
3. ES neue Funktionen (es6+, ES2020, ES2021 optionale Kette, at)
4. Funktionsnutzungsspezifikationen (z. B. bei Verwendung von Karte als forEach)5 Algorithmen zu nutzen, um eleganteren und leistungsfähigeren Code zu schreiben
Wie man ein Team führtIn meinem letzten Unternehmen war ich in einer technischen Managementposition tätig.
0,
Entwicklungsspezifikationen implementieren, ich habe im unternehmensinternen Wiki gepostet, von der Benennung über Best Practices bis hin zur Verwendung verschiedener Werkzeugbibliotheken. In der frühen Phase, in der neue Leute hinzukommen, werde ich der Überwachung ihrer Codequalität Priorität einräumen
1
Arbeitsteilung im Team: Jede Person ist für die Entwicklung eines Produkts allein verantwortlich, und dann werde ich sie generell benennen ein paar Leute, um öffentliche Module zu entwickeln
2. Codequalitätssicherung: Wir werden ihren Code jede Woche überprüfen, wir werden auch eine Gegenüberprüfung des Codes organisieren und die geänderten Ergebnisausgabeartikel in das Wiki stellen
3. Regelmäßige Treffen organisieren: Regelmäßige Besprechungen organisieren Treffen Sie sich jede Woche, um ihre jeweiligen Fortschritte und Risiken zu synchronisieren und Arbeitsaufgaben entsprechend ihrem eigenen Fortschritt zu verteilen
4. Technologieaustausch: Wir werden auch gelegentlichen Technologieaustausch organisieren. Am Anfang teilte ich nur das Micro-Front-End-System, den Quellcode von Ice Stark
5, Public Demand Pool: wie das Upgrade von webpack5/vite; das Upgrade von vue2.7 Einführung von Setup-Syntax-Zucker; Verwendung von pnpm; Optimierung der Topologiekartenleistung
6, Optimierungsprojekt: Nach der Veröffentlichung der ersten Version des Produkts startete ich auch ein spezielles Leistungsoptimierungsprojekt, die erste Bildschirmladeleistung und die Optimierung des Verpackungsvolumens ; Lassen Sie jeden für die entsprechenden Optimierungspunkte verantwortlich sein
Was halten Sie von Überstunden?
Ich denke, es gibt generell zwei Situationen, wenn man Überstunden leistet:
Erstens ist der Projektzeitplan eng, daher steht natürlich der Projektfortschritt an erster Stelle, schließlich hängt jeder für seinen Lebensunterhalt davon ab
Zweitens ist es ein Ob es um die eigenen Fähigkeiten geht, man sich nicht mit dem Geschäft auskennt oder einen brandneuen Technologie-Stack einführt, ich glaube, ich muss nicht nur Überstunden machen, um mitzuhalten, sondern auch meine Freizeit nutzen, um zu lernen und meine Defizite auszugleichen
Was sind deine Hobbys?
Normalerweise lese ich gerne, das heißt, ich lese einige Bücher über Psychologie, Zeitmanagement und einige Sprachkenntnisse beim Lesen auf WeChat.
Dann schreibe ich Artikel, weil ich finde, dass man leicht vergisst, sich nur Notizen zu machen Ich nehme nur die Inhalte anderer Leute auf und schreibe meine eigenen Originalartikel, dabei kann ich einen sehr hohen Anteil an Wissen in meine eigenen Dinge umsetzen. Daher habe ich neben meinen eigenen Goldminen-Artikeln oft auch Meinungen dazu Ausgabe des Projekts. Der Artikel wird in das Wiki exportiert
Weitere Hobbys sind Basketball spielen und Singen mit Freunden
4. Technologie
Achten Sie unbedingt auf technische Interviews: Seien Sie prägnant und auf den Punkt Gehen Sie dabei angemessen detailliert vor, und wenn Sie es nicht verstehen, sagen Sie einfach, dass Sie es nicht verstehen. Da es sich beim Interviewprozess um einen persönlichen Kommunikationsprozess mit dem Interviewer handelt, möchte kein Interviewer, dass der Kandidat lange plaudert, ohne über die wichtigsten Punkte zu sprechen. Gleichzeitig wird der Zuhörer dies passiv tun Ignorieren Sie die Teile, die ihn nicht interessieren. Daher ist es notwendig, die Kernmerkmale einer bestimmten Technologie hervorzuheben und den Kern entsprechend zu erweitern.
Große Unternehmen prüfen Kandidaten grundsätzlich anhand von Algorithmen. Es gibt keine Abkürzungen zu Algorithmen. Sie können Fragen nur Schritt für Schritt beantworten und dann erneut Fragen beantworten.
Im technischen Interviewprozess werden hauptsächlich Fragen zu Technologien im Front-End-Bereich gestellt. Im Allgemeinen basiert der Interviewer auf Ihrer Einrichtung, und häufiger basiert der Interviewer auf den Interviewfragen, die er zuvor vorbereitet hat die Technologie, mit der das Projektteam vertraut ist. Klicken Sie hier, um Fragen zu stellen, da sie alle unbekannt sind und daher alle Aspekte recht anspruchsvoll sind.
Wenn Sie in ein mittleres bis großes Unternehmen mit guten Entwicklungsaussichten einsteigen möchten, werden Sie nicht durchkommen, indem Sie sich nur die Erfahrungen anderer Leute merken. Obwohl jede Zusammenfassung hier sehr kurz ist, ist es mein Verständnis für jede einzelne Die Wissenspunkte gehören zu den Kernwissenspunkten, die nach einem umfassenden Studium extrahiert werden, sodass Sie keine Angst vor dem „divergenten Denken“ des Interviewers haben.
Der Interviewprozess beinhaltet im Allgemeinen die Berücksichtigung der folgenden acht Haupttypen von Wissen:
JS/CSS/TypeScript/Framework (Vue, React)/Browser und Netzwerk/Leistungsoptimierung/Front-End-Engineering/Architektur/Sonstiges
Daher ist die technische Vorbereitung vor dem Vorstellungsgespräch keineswegs von heute auf morgen erledigt. Sie können beispielsweise zehn bis zwanzig Minuten am Tag nutzen, um einen der kleinen Wissenspunkte umfassend zu studieren. Unabhängig davon, wie viele Jahre die Interviews dauern, wird es ausreichen, eloquent zu sprechen.
JS-Kapitel
JS-Lernbuch mit rotem Umschlag und Mr. Yu Yus Ausführlicher JS-Serien-BlogGrundsätzlich ist es in Ordnung
Zu den häufigsten JS-Interviewfragen gehören im Allgemeinen diese
Was ist ein Prototyp? Prototypenkette?
Die Essenz eines Prototyps ist ein Objekt.
Wenn wir einen Konstruktor erstellen, verfügt diese Funktion standardmäßig über ein
prototype-Attribut, und der Wert dieses Attributs verweist auf das Prototypobjekt dieser Funktion.Dieses Prototypobjekt wird verwendet, um gemeinsame Attribute für die durch den Konstruktor erstellten Instanzobjekte bereitzustellen, d alle sind von Das Prototypobjekt dieser Funktion erbt die oben genannten Eigenschaften
Was ist ein Abschluss?Wenn die Attribute der Instanz nicht gefunden werden, wird nach den Attributen im Prototyp gesucht, der dem Objekt zugeordnet ist. Wenn sie nicht gefunden werden kann, wird nach dem Prototyp des Prototyps gesucht, bis er die oberste Ebene erreicht (Die oberste Ebene ist
Prototype of Object.prototype, der Wert ist null).Object.prototype的原型,值为null)。所以通过原型一层层相互关联的链状结构就称为原型链。
什么是闭包?
定义:闭包是指引用了其他函数作用域中变量的函数,通常是在嵌套函数中实现的。
从技术角度上所有 js 函数都是闭包。
从实践角度来看,满足以下俩个条件的函数算闭包
即使创建它的上下文被销毁了,它依然存在。(比如从父函数中返回)
在代码中引用了自由变量(在函数中使用的既不是函数参数也不是函数局部变量的变量称作自由变量)
使用场景:
创建私有变量
vue 中的data,需要是一个闭包,保证每个data中数据唯一,避免多次引用该组件造成的data共享
延长变量的生命周期
一般函数的词法环境在函数返回后就被销毁,但是闭包会保存对创建时所在词法环境的引用,即便创建时所在的执行上下文被销毁,但创建时所在词法环境依然存在,以达到延长变量的生命周期的目的
应用
- 柯里化函数
- 例如计数器、延迟调用、回调函数等
this 的指向
在绝大多数情况下,函数的调用方式决定了
this的值(运行时绑定)1、全局的this非严格模式指向window对象,严格模式指向 undefined
2、对象的属性方法中的this 指向对象本身
3、apply、call、bind 可以变更 this 指向为第一个传参
4、箭头函数中的this指向它的父级作用域,它自身不存在 this
浏览器的事件循环?
js 代码执行过程中,会创建对应的执行上下文并压入执行上下文栈中。
如果遇到异步任务就会将任务挂起,交给其他线程去处理异步任务,当异步任务处理完后,会将回调结果加入事件队列中。
当执行栈中所有任务执行完毕后,就是主线程处于闲置状态时,才会从事件队列中取出排在首位的事件回调结果,并把这个回调加入执行栈中然后执行其中的代码,如此反复,这个过程就被称为事件循环。
事件队列分为了宏任务队列和微任务队列,在当前执行栈为空时,主线程回先查看微任务队列是否有事件存在,存在则依次执行微任务队列中的事件回调,直至微任务队列为空;不存在再去宏任务队列中处理。
常见的宏任务有
setTimeout()、setInterval()、setImmediate()、I/O、用户交互操作,UI渲染常见的微任务有
Alsopromise.then()、promise.catch()、new MutationObserver、process.nextTick()Die Kettenstruktur, die Schicht für Schicht durch Prototypen miteinander verbunden ist, wird Prototypenkette genannt.
Definition: „Closure“ bezieht sich auf eine Funktion
, die auf Variablen im Rahmen anderer Funktionen verweist, die normalerweise in verschachtelten Funktionen implementiert sind.- Technisch gesehen sind alle js-Funktionen Abschlüsse. Aus praktischer Sicht wird eine Funktion, die die folgenden beiden Bedingungen erfüllt, als Abschluss betrachtet
Auch wenn der Kontext, der sie erstellt hat, zerstört wird, existiert sie immer noch. (Zum Beispiel Rückkehr von der übergeordneten Funktion)
Im Code wird auf freie Variablen verwiesen (in der Funktion verwendete Variablen, die weder Funktionsparameter noch lokale Funktionsvariablen sind, werden als freie Variablen bezeichnet)Verwendungsszenarien:
Private Variablen erstellen
Daten in Vue müssen ein Abschluss sein, um sicherzustellen, dass die Daten in jedem Daten eindeutig sind und die gemeinsame Nutzung von Daten durch mehrere Verweise auf die Komponente vermieden wird.
Verlängern Sie den Lebenszyklus von Variablen
🎜Im Allgemeinen wird die lexikalische Umgebung einer Funktion zerstört, nachdem die Funktion zurückgegeben wurde. Durch den Abschluss wird jedoch ein Verweis auf die lexikalische Umgebung gespeichert, in der sie erstellt wurde. Selbst wenn der Ausführungskontext, in dem sie erstellt wurde, zerstört wird, bleibt die lexikalische Umgebung erhalten, in der sie erstellt wurde wurde weiterhin erstellt, um eine Erweiterung des Lebenszyklus von Variablen🎜🎜🎜🎜🎜Anwendung🎜🎜🎜currying-Funktionen🎜🎜wie Zähler, verzögerte Anrufe, Rückruffunktionen usw. zu erreichen.🎜🎜
🎜this Zeigt auf 🎜🎜🎜In den meisten Fällen bestimmt die Methode zum Aufrufen der Funktion den Wert von this(Laufzeitbindung) 🎜🎜1 Das globale this nicht- Der strikte Modus zeigt auf das Fensterobjekt und der strikte Modus zeigt auf das Fensterobjekt undefiniert🎜🎜2 Dies in der Attributmethode des Objekts zeigt auf das Objekt selbst🎜🎜3 Zuerst übergebener Parameter🎜🎜4. Dieser in der Pfeilfunktion zeigt auf seinen übergeordneten Bereich, er existiert nicht in sich selbst🎜🎜Die Ereignisschleife des Browsers? 🎜🎜🎜Während der Ausführung von js-Code wird der entsprechende Ausführungskontext erstellt und in den Ausführungskontextstapel verschoben. 🎜🎜Wenn eine asynchrone Aufgabe auftritt, wird die Aufgabe angehalten und an andere Threads zur Verarbeitung der asynchronen Aufgabe übergeben. Wenn die asynchrone Aufgabe verarbeitet wird, wird das Rückrufergebnis zur Ereigniswarteschlange hinzugefügt. 🎜🎜Wenn alle Aufgaben im Ausführungsstapel ausgeführt wurden, dh wenn der Hauptthread inaktiv ist, wird das zuerst rangierte Ereignisrückrufergebnis aus der Ereigniswarteschlange entnommen und dieser Rückruf dem Ausführungsstapel hinzugefügt Der darin enthaltene Code wird ausgeführt, daher wird dieser Vorgang wiederholt als Ereignisschleife bezeichnet. 🎜🎜Die Ereigniswarteschlange ist in 🎜Makroaufgabenwarteschlange🎜 und Mikroaufgabenwarteschlange unterteilt. Wenn der aktuelle Ausführungsstapel leer ist, prüft der Hauptthread zunächst, ob ein Ereignis in der Mikroaufgabenwarteschlange vorhanden ist Ereignisrückrufe in der Mikrotask-Warteschlange werden nacheinander ausgeführt, bis die Mikrotask-Warteschlange leer ist. Wenn sie nicht vorhanden ist, wird sie in der Makrotask-Warteschlange verarbeitet. 🎜🎜🎜Zu den allgemeinen Makroaufgaben gehören 🎜
setTimeout(),setInterval(),setImmediate(), E/A, Benutzerinteraktionsvorgänge, UI Rendering🎜🎜🎜Zu den üblichen Mikrotasks gehören🎜promise.then(),promise.catch(),new MutationObserver,process.nextTick ()🎜🎜🎜Der wesentliche Unterschied zwischen Makroaufgaben und Mikroaufgaben🎜🎜🎜🎜🎜Makroaufgaben haben klare asynchrone Aufgaben, die ausgeführt werden müssen, und Rückrufe und erfordern Unterstützung durch andere asynchrone Threads🎜🎜🎜🎜Mikroaufgaben sind nicht klar Die asynchronen Aufgaben müssen ausgeführt werden, es sind nur Rückrufe erforderlich und es ist keine andere asynchrone Thread-Unterstützung erforderlich. 🎜🎜🎜🎜🎜Wie Daten im Stapel und Heap in JavaScript gespeichert werden🎜🎜🎜1 Die Größe der Basisdatentypen ist fest und die Bedienung ist einfach, sodass sie im Stapel gespeichert werden🎜🎜2 Da die Datentypen unsicher sind, werden sie in den Heap-Speicher gelegt und ihre Größe bei der Speicherbeantragung bestimmt. 🎜🎜3 Durch einen separaten Speicher kann die Speichernutzung minimiert werden. Die Effizienz des Stapels ist höher als die des Heaps🎜🎜4 Die Variablen im Stapelspeicher werden sofort nach Beendigung der Ausführungsumgebung durch Müll gesammelt, während alle Verweise auf die Variablen im Heap-Speicher beendet werden müssen, bevor sie können 🎜🎜🎜Lassen Sie uns über die Müllsammlung der Version 8 sprechen Verwendet den Scavenge-Algorithmus für Zeit: Der gesamte Raum wird in zwei Blöcke unterteilt. Während des Recyclings werden die überlebenden Variablen in einen anderen Raum kopiert und die nicht überlebenden werden recycelt wird immer wieder wiederholt🎜🎜3. Die alte Generation verwendet Markierungslöschung und Markierungssortierung: Durchqueren Sie alle Objekte und auf die Markierung kann zugegriffen werden, und dann werden die nicht lebenden Objekte als Müll recycelt. Um Speicherunterbrechungen zu vermeiden, müssen lebende Objekte nach dem Recycling durch Markieren und Sortieren an ein Ende des Speichers verschoben werden und nach Abschluss der Bewegung den Grenzspeicher bereinigen🎜Methoden zum Funktionsaufruf
1. Gewöhnliche
functionverwendet direkt(), um Parameter aufzurufen und zu übergeben, wie zum Beispiel:function test(x, y) { return x + y,test(3, 4)function直接使用()调用并传参,如:function test(x, y) { return x + y},test(3, 4)2、作为对象的一个属性方法调用,如:
const obj = { test: function (val) { return val } },obj.test(2)3、使用
call或apply调用,更改函数 this 指向,也就是更改函数的执行上下文4、
new可以间接调用构造函数生成对象实例defer和async的区别
一般情况下,当执行到 script 标签时会进行下载 + 执行两步操作,这两步会阻塞 HTML 的解析;
async 和 defer 能将script的下载阶段变成异步执行(和 html解析同步进行);
async下载完成后会立即执行js,此时会阻塞HTML解析;
defer会等全部HTML解析完成且在DOMContentLoaded 事件之前执行。
浏览器事件机制
DOM 事件流三阶段:
捕获阶段:事件最开始由不太具体的节点最早接受事件, 而最具体的节点(触发节点)最后接受事件。为了让事件到达最终目标之前拦截事件。
比如点击一个div,则 click 事件会按这种顺序触发: document =>
=>=><div>,即由 document 捕获后沿着 DOM 树依次向下传播,<strong>并在各节点上触发捕获事件</strong>,直到到达实际目标元素。<li> <p><strong>目标阶段</strong></p> <p>当事件到达目标节点的,事件就进入了目标阶段。<strong>事件在目标节点上被触发</strong>(执行事件对应的函数),然后会逆向回流,直到传播至最外层的文档节点。</p> </li> <li> <p><strong>冒泡阶段</strong></p> <p>事件在目标元素上触发后,会继续随着 DOM 树一层层往上冒泡,直到到达最外层的根节点。</p> </li> <p>所有事件都要经历捕获阶段和目标阶段,但有些事件会跳过冒泡阶段,比如元素获得焦点 focus 和失去焦点 blur 不会冒泡</p> <p><strong>扩展一</strong></p> <p>e.target 和 e.currentTarget 区别?</p> <ul> <li> <code>e.target指向触发事件监听的对象。e.currentTarget指向添加监听事件的对象。例如:
<ul> <li><span>hello 1</span></li> </ul> let ul = document.querySelectorAll('ul')[0] let aLi = document.querySelectorAll('li') ul.addEventListener('click',function(e){ let oLi1 = e.target let oLi2 = e.currentTarget console.log(oLi1) // 被点击的li console.log(oLi2) // ul console.og(oLi1===oLi2) // false })给 ul 绑定了事件,点击其中 li 的时候,target 就是被点击的 li, currentTarget 就是被绑定事件的 ul
事件冒泡阶段(上述例子),
e.currenttarget和e.target是不相等的,但是在事件的目标阶段,e.currenttarget和e.target是相等的作用:
e.target可以用来实现事件委托,该原理是通过事件冒泡(或者事件捕获)给父元素添加事件监听,e.target指向引发触发事件的元素扩展二
addEventListener 参数
语法:
addEventListener(type, listener); addEventListener(type, listener, options || useCapture);
type: 监听事件的类型,如:'click'/'scroll'/'focus'
listener: 必须是一个实现了
EventListener接口的对象,或者是一个函数。当监听的事件类型被触发时,会执行- 3. Verwenden Sie zum Aufrufen
options:指定 listerner 有关的可选参数对象
- capture: 布尔值,表示 listener 是否在事件捕获阶段传播到 EventTarget 时触发
- once:布尔值,表示 listener 添加之后最多调用一次,为 true 则 listener 在执行一次后会移除
- passive: 布尔值,表示 listener 永远不会调用
preventDefault()- signal:可选,
2 Wird als Attributmethode des Objekts aufgerufen, wie zum Beispiel:AbortSignal,当它的abort()const obj = { test: function (val) { return val },obj.test(2)calloderapplyund ändern Sie die Funktion, auf die dies zeigt, d. 22">- Der Unterschied zwischen „Defer“ und „Async“🎜 Wenn das Skript-Tag unter normalen Umständen ausgeführt wird, werden zweistufige Vorgänge heruntergeladen und ausgeführt. Diese beiden Schritte blockieren das Parsen von HTML; 🎜🎜async und defer können Verwandeln Sie die 🎜Download-Phase🎜 des Skripts in eine asynchrone Ausführung (synchronisiert mit der HTML-Analyse). 🎜🎜async führt js sofort nach Abschluss des Downloads aus, wodurch die HTML-Analyse blockiert wird abgeschlossen und vor dem DOMContentLoaded-Ereignis ausgeführt. 🎜
🎜Browser-Ereignismechanismus🎜🎜🎜DOM-Ereignisfluss in drei Phasen: 🎜
🎜🎜🎜Erfassungsphase🎜: Ereignisse Beginnen Sie mit weniger spezifischen Knoten, die das Ereignis zuerst empfangen, und dem spezifischsten Knoten (dem auslösenden Knoten), der das Ereignis zuletzt empfängt. Um Ereignisse abzufangen, bevor sie ihr endgültiges Ziel erreichen. 🎜🎜Wenn Sie beispielsweise auf ein Div klicken, wird das Klickereignis in dieser Reihenfolge ausgelöst: document =>
=> > =>, das heißt, es wird vom Dokument erfasst und dann entlang des DOM-Baums nach unten weitergegeben 🎜 und löst Erfassungsereignisse auf jedem Knoten aus 🎜, bis es das tatsächliche Zielelement erreicht . 🎜🎜🎜🎜🎜Zielphase🎜🎜🎜Wenn das Ereignis den Zielknoten erreicht, tritt das Ereignis in die Zielphase ein. 🎜Das Ereignis wird auf dem Zielknoten ausgelöst🎜 (führt die dem Ereignis entsprechende Funktion aus) und fließt dann in umgekehrter Richtung zurück, bis es an den äußersten Dokumentknoten weitergegeben wird. 🎜🎜🎜🎜🎜Bubbling-Phase🎜🎜🎜Nachdem das Ereignis auf dem Zielelement ausgelöst wurde, sprudelt es Schicht für Schicht entlang des DOM-Baums weiter, bis es den äußersten Wurzelknoten erreicht. 🎜🎜🎜🎜Alle Ereignisse müssen die Erfassungsphase und die Zielphase durchlaufen, aber einige Ereignisse überspringen die Blasenphase, z. B. das Element gewinnt an Fokus und verliert den Fokus, Unschärfe sprudelt nicht 🎜🎜🎜Erweiterte Phase 🎜🎜🎜e. Unterschied zwischen Ziel und e.currentTarget? 🎜🎜
e.targetzeigt auf das Objekt, das das Abhören von Ereignissen auslöst. 🎜🎜e.currentTargetzeigt auf das hinzugefügte Objekt, um auf Ereignisse zu warten. 🎜🎜🎜Zum Beispiel: 🎜// 比如 <input v-model="sth" /> // 等价于 <input :value="sth" @input="sth = $event.target.value" />🎜 hat ein Ereignis an ul gebunden. Wenn Sie auf das li klicken, ist das Ziel das angeklickte li, und currentTarget ist die ul🎜🎜-Ereignis-Bubbling-Phase des gebundenen Ereignisses (das obige Beispiel), e.currenttarget unde.targetsind nicht gleich, aber in der Zielphase des Ereignisses sinde.currenttargetunde.target>Ist gleich 🎜🎜Funktion: 🎜🎜e.targetkann verwendet werden, um Ereignisdelegation, das Prinzip ist die Verwendung von Event-Bubbling (oder Ereigniserfassung) zum Hinzufügen eines Ereignisses, das auf das übergeordnete Element lauscht. e.target zeigt auf das Element, das das Auslöseereignis ausgelöst hat Listening-Ereignis, wie zum Beispiel: 'click'/'scroll'/'focus'🎜🎜🎜🎜listener: muss eine Implementierung seinEventListener-Objekt der Schnittstelle, oder es ist ein docs/Web/JavaScript/Guide/Functions" ref="nofollow noopener noreferrer">Functions. Wenn der überwachte Ereignistyp ausgelöst wird, wird er ausgeführt 🎜🎜🎜🎜Optionen: Geben Sie das optionale Parameterobjekt für den Listener an 🎜🎜capture: Boolescher Wert, der angibt, ob der Listener ausgelöst wird, wenn er während des an EventTarget weitergegeben wird Ereigniserfassungsphase 🎜🎜once: Boolescher Wert, der angibt, dass der Listener nach dem Hinzufügen höchstens einmal aufgerufen wird. Wenn true, wird der Listener nach einmaliger Ausführung entfernt. 🎜🎜passive: Boolescher Wert, der angibt, dass der Listener niemals aufgerufen wird call
preventDefault()🎜🎜signal: Optional,AbortSignal, wenn seineabort()-Methode aufgerufen wird, wird der Listener entfernt🎜🎜🎜 🎜🎜useCapture: Boolescher Wert, Standardwert ist false. Der Listener wird am Ende der Event-Bubbling-Phase ausgeführt, und true bedeutet, dass er zu Beginn der Capture-Phase ausgeführt wird. Die Funktion besteht darin, den Zeitpunkt des Ereignisses zu ändern, um das Abfangen/Nicht-Abfangen zu erleichtern. 🎜Vue-Artikel
Der Autor beschäftigt sich hauptsächlich mit Vue-bezogener Entwicklung und hat auch reaktionsbezogene Projekte durchgeführt. Natürlich ist Reagieren nur auf der Ebene der Fähigkeit, Projekte durchzuführen, also ist es die Art Dinge, die in einem Lebenslauf erwähnt werden können. Je mehr, desto besser, desto besser macht mich das Erlernen der Vue-Quellcodereihe. Das Gleiche gilt für den Lernprozess. Wenn Sie die Prinzipien eines Frameworks beherrschen, ist das Erlernen anderer Frameworks nur eine Frage der Zeit.
Der Unterschied zwischen Vue und React
1. Datenvariabilität
- React befürwortet funktionale Programmierung, unveränderliche Daten und einen einseitigen Datenfluss, der nur über
setStateübergeben werden kann oderonchange, um Ansichtsaktualisierungen zu implementieren Das Formular ist vollständig in jssetState或者onchange来实现视图更新- Vue 基于数据可变,设计了响应式数据,通过监听数据的变化自动更新视图
2、写法
- React 推荐使用 jsx + inline style的形式,就是 all in js
- Vue 是单文件组件(SFC)形式,在一个组件内分模块(tmplate/script/style),当然vue也支持jsx形式,可以在开发vue的ui组件库时使用
3、diff 算法
- Vue2采用双端比较,Vue3采用快速比较
react主要使用diff队列保存需要更新哪些DOM,得到patch树,再统一操作批量更新DOM。,需要使用shouldComponentUpdate()来手动优化react的渲染。扩展:了解 react hooks吗
组件类的写法很重,层级一多很难维护。
函数组件是纯函数,不能包含状态,也不支持生命周期方法,因此无法取代类。
React Hooks 的设计目的,就是加强版函数组件,完全不使用"类",就能写出一个全功能的组件
React Hooks 的意思是,组件尽量写成纯函数,如果需要外部功能和副作用,就用钩子把外部代码"钩"进来。
vue组件通信方式
- props / $emit
- ref / $refs
- root
- attrs / listeners
- eventBus / vuex / pinia / localStorage / sessionStorage / Cookie / window
- provide / inject
vue 渲染列表为什么要加key?
Vue 在处理更新同类型 vnode 的一组子节点(比如v-for渲染的列表节点)的过程中,为了减少 DOM 频繁创建和销毁的性能开销:
对没有 key 的子节点数组更新是通过就地更新的策略。它会通过对比新旧子节点数组的长度,先以比较短的那部分长度为基准,将新子节点的那一部分直接 patch 上去。然后再判断,如果是新子节点数组的长度更长,就直接将新子节点数组剩余部分挂载;如果是新子节点数组更短,就把旧子节点多出来的那部分给卸载掉)。所以如果子节点是组件或者有状态的 DOM 元素,原有的状态会保留,就会出现渲染不正确的问题。
有 key 的子节点更新是调用的
patchKeyedChildrenVue ist ein SFC-Formular (Single File Component), das in Module (tmplate/script/style) innerhalb einer Komponente unterteilt ist. Natürlich unterstützt Vue auch das JSX-Formular, das bei der Entwicklung der Vue-Benutzeroberfläche verwendet werden kann Komponentenbibliothek3. Diff-Algorithmus
🎜🎜Vue2 verwendet einen doppelseitigen Vergleich, Vue3 verwendet einen schnellen Vergleich🎜🎜reactverwendet hauptsächlich die Diff-Warteschlange, um zu speichern, welche DOMs aktualisiert werden müssen, um den Patch zu erhalten Baum, und führen Sie dann einheitliche Vorgänge aus, um die DOMs stapelweise zu aktualisieren. , müssen SieshouldComponentUpdate()verwenden, um das React-Rendering manuell zu optimieren. 🎜🎜🎜🎜Erweiterung: Kennen Sie React Hooks? 🎜🎜🎜Das Schreiben von Komponentenklassen ist sehr umfangreich und bei zu vielen Ebenen schwierig zu pflegen. 🎜🎜Funktionskomponenten sind reine Funktionen, können keinen Status enthalten und unterstützen keine Lebenszyklusmethoden, sodass sie keine Klassen ersetzen können. 🎜🎜🎜Der Designzweck von React Hooks besteht darin, die Funktionskomponente zu verbessern. Sie können eine Komponente mit vollem Funktionsumfang schreiben, ohne „Klassen“ zu verwenden. 🎜🎜🎜🎜React Hooks bedeutet, dass die Komponente als reine Funktion geschrieben werden sollte Wenn eine externe Komponente benötigt wird, verwenden Sie für Funktionen und Nebenwirkungen Hooks, um externen Code einzubinden. 🎜🎜🎜vue-Komponenten-Kommunikationsmethode🎜🎜🎜🎜props / $emit🎜🎜ref / $refs🎜🎜root🎜🎜attrs / listeners🎜🎜eventBus / vuex / pinia / localStorage / sessionStorage / Cookie / window🎜🎜provide / inject🎜🎜
Warum fügt 🎜vue einen Schlüssel zur Rendering-Liste hinzu? 🎜🎜🎜Vue ist dabei, eine Gruppe untergeordneter Knoten desselben Vnode-Typs zu aktualisieren (z. B. den von v-for gerenderten Listenknoten). um die häufige Erstellung und Zerstörung von DOM zu reduzieren: 🎜🎜Die Aktualisierung des untergeordneten Knoten-Arrays ohne Schlüssel erfolgt durch die 🎜In-Place-Update🎜-Strategie. Es vergleicht die Längen des alten und des neuen untergeordneten Knotenarrays, verwendet zunächst die kürzere Länge als Basis und patcht den Teil des neuen untergeordneten Knotens direkt. Beurteilen Sie dann: Wenn die Länge des neuen untergeordneten Knotenarrays länger ist, montieren Sie den verbleibenden Teil des neuen untergeordneten Knotenarrays direkt. Wenn das neue untergeordnete Knotenarray kürzer ist, deinstallieren Sie den zusätzlichen Teil des alten untergeordneten Knotens. 🎜Wenn es sich bei dem untergeordneten Knoten also um eine Komponente oder ein zustandsbehaftetes DOM-Element handelt, bleibt der ursprüngliche Zustand erhalten und es kommt zu einer falschen Darstellung.🎜 🎜🎜Die Aktualisierung von untergeordneten Knoten mit Schlüssel heißt
patchKeyedChildren. Diese Funktion ist der bekannte Ort zum Implementieren des Kern-Diff-Algorithmus. Der allgemeine Prozess besteht darin, den Kopfknoten zu synchronisieren und den Endknoten zu synchronisieren Hinzufügen und Löschen von Knoten und schließlich die Methode zum Lösen der am längsten ansteigenden Teilfolge, um die unbekannte Teilfolge zu behandeln. Dies dient dazu, die Wiederverwendung vorhandener Knoten zu maximieren, den Leistungsaufwand von DOM-Vorgängen zu reduzieren und das Problem von Statusfehlern untergeordneter Knoten zu vermeiden, die durch direkte Aktualisierungen verursacht werden. 🎜🎜Zusammenfassend lässt sich sagen, dass Sie die Schreibmethode verwenden können, ohne einen Schlüssel hinzuzufügen, wenn Sie v-for zum Durchlaufen von Konstanten verwenden oder die untergeordneten Knoten Knoten ohne „Zustand“ wie einfachen Text sind. Im eigentlichen Entwicklungsprozess wird jedoch empfohlen, den Schlüssel einheitlich hinzuzufügen, um eine größere Bandbreite an Szenarien zu realisieren und mögliche Statusaktualisierungsfehler zu vermeiden. Wir können ESlint im Allgemeinen verwenden, um den Schlüssel als erforderliches Element von v-for zu konfigurieren. 🎜想详细了解这个知识点的可以去看看我之前写的文章:v-for 到底为啥要加上 key?
vue3 相对 vue2的响应式优化
vue2使用的是
Object.defineProperty去监听对象属性值的变化,但是它不能监听对象属性的新增和删除,所以需要使用$set、$delete这种语法糖去实现,这其实是一种设计上的不足。所以 vue3 采用了
proxy去实现响应式监听对象属性的增删查改。其实从api的原生性能上
proxy是比Object.defineProperty要差的。而 vue 做的响应式性能优化主要是在将嵌套层级比较深的对象变成响应式的这一过程。
vue2的做法是在组件初始化的时候就递归执行
Object.defineProperty把子对象变成响应式的;而vue3是在访问到子对象属性的时候,才会去将它转换为响应式。这种延时定义子对象响应式会对性能有一定的提升
Vue 核心diff流程
前提:当同类型的 vnode 的子节点都是一组节点(数组类型)的时候,
步骤:会走核心 diff 流程
Vue3是快速选择算法
- 同步头部节点
- 同步尾部节点
- 新增新的节点
- 删除多余节点
- 处理未知子序列(贪心 + 二分处理最长递增子序列)
Vue2是双端比较算法
在新旧字节点的头尾节点,也就是四个节点之间进行对比,找到可复用的节点,不断向中间靠拢的过程
diff目的:diff 算法的目的就是为了尽可能地复用节点,减少 DOM 频繁创建和删除带来的性能开销
vue双向绑定原理
基于 MVVM 模型,viewModel(业务逻辑层)提供了数据变化后更新视图和视图变化后更新数据这样一个功能,就是传统意义上的双向绑定。
Vue2.x 实现双向绑定核心是通过三个模块:Observer监听器、Watcher订阅者和Compile编译器。
首先监听器会监听所有的响应式对象属性,编译器会将模板进行编译,找到里面动态绑定的响应式数据并初始化视图;watchr 会去收集这些依赖;当响应式数据发生变更时Observer就会通知 Watcher;watcher接收到监听器的信号就会执行更新函数去更新视图;
vue3的变更是数据劫持部分使用了porxy 替代 Object.defineProperty,收集的依赖使用组件的副作用渲染函数替代watcher
v-model 原理
vue2 v-model 原理剖析
V-model 是用来监听用户事件然后更新数据的语法糖。
其本质还是单向数据流,内部是通过绑定元素的 value 值向下传递数据,然后通过绑定 input 事件,向上接收并处理更新数据。
单向数据流:父组件传递给子组件的值子组件不能修改,只能通过emit事件让父组件自个改。
// 比如 <input v-model="sth" /> // 等价于 <input :value="sth" @input="sth = $event.target.value" />给组件添加
v-model属性时,默认会把value作为组件的属性,把input作为给组件绑定事件时的事件名:// 父组件 <my-button v-model="number"></my-button> // 子组件 <script> export default { props: { value: Number, // 属性名必须是 value }, methods: { add() { this.$emit('input', this.value + 1) // 事件名必须是 input }, } } </script>如果想给绑定的 value 属性和 input 事件换个名称呢?可以这样:
在 Vue 2.2 及以上版本,你可以在定义组件时通过 model 选项的方式来定制 prop/event:
<script> export default { model: { prop: 'num', // 自定义属性名 event: 'addNum' // 自定义事件名 } }vue3 v-model 原理
实现和 vue2 基本一致
<Son v-model="modalValue"/>等同于
<Son v-model="modalValue"/>自定义 model 参数
<Son v-model:visible="visible"/> setup(props, ctx){ ctx.emit("update:visible", false) }vue 响应式原理
不管vue2 还是 vue3,响应式的核心就是观察者模式 + 劫持数据的变化,在访问的时候做依赖收集和在修改数据的时候执行收集的依赖并更新数据。具体点就是:
vue2 的话采用的是
Object.definePorperty劫持对象的 get 和 set 方法,每个组件实例都会在渲染时初始化一个 watcher 实例,它会将组件渲染过程中所接触的响应式变量记为依赖,并且保存了组件的更新方法 update。当依赖的 setter 触发时,会通知 watcher 触发组件的 update 方法,从而更新视图。Vue3 使用的是 ES6 的 proxy,proxy 不仅能够追踪属性的获取和修改,还可以追踪对象的增删,这在 vue2中需要 delete 才能实现。然后就是收集的依赖是用组件的副作用渲染函数替代 watcher 实例。
性能方面,从原生 api 角度,proxy 这个方法的性能是不如 Object.property,但是 vue3 强就强在一个是上面提到的可以追踪对象的增删,第二个是对嵌套对象的处理上是访问到具体属性才会把那个对象属性给转换成响应式,而 vue2 是在初始化的时候就递归调用将整个对象和他的属性都变成响应式,这部分就差了。
扩展一
vue2 通过数组下标更改数组视图为什么不会更新?
尤大:性能不好
注意:vue3 是没问题的
why 性能不好?
我们看一下响应式处理:
export class Observer { this.value = value this.dep = new Dep() this.vmCount = 0 def(value, '__ob__', this) if (Array.isArray(value)) { // 这里对数组进行单独处理 if (hasProto) { protoAugment(value, arrayMethods) } else { copyAugment(value, arrayMethods, arrayKeys) } this.observeArray(value) } else { // 对对象遍历所有键值 this.walk(value) } } walk (obj: Object) { const keys = Object.keys(obj) for (let i = 0; i < keys.length; i++) { defineReactive(obj, keys[i]) } } observeArray (items: Array<any>) { for (let i = 0, l = items.length; i < l; i++) { observe(items[i]) } } }对于对象是通过
Object.keys()遍历全部的键值,对数组只是observe监听已有的元素,所以通过下标更改不会触发响应式更新。理由是数组的键相较对象多很多,当数组数据大的时候性能会很拉胯。所以不开放
computed 和 watch
Computed 的大体实现和普通的响应式数据是一致的,不过加了延时计算和缓存的功能:
在访问computed对象的时候,会触发 getter ,初始化的时候将 computed 属性创建的 watcher (vue3是副作用渲染函数)添加到与之相关的响应式数据的依赖收集器中(dep),然后根据里面一个叫 dirty 的属性判断是否要收集依赖,不需要的话直接返回上一次的计算结果,需要的话就执行更新重新渲染视图。
watchEffect?
watchEffect会自动收集回调函数中响应式变量的依赖。并在首次自动执行
推荐在大部分时候用
watch显式的指定依赖以避免不必要的重复触发,也避免在后续代码修改或重构时不小心引入新的依赖。watchEffect适用于一些逻辑相对简单,依赖源和逻辑强相关的场景(或者懒惰的场景 )$nextTick 原理?
vue有个机制,更新 DOM 是异步执行的,当数据变化会产生一个异步更行队列,要等异步队列结束后才会统一进行更新视图,所以改了数据之后立即去拿 dom 还没有更新就会拿不到最新数据。所以提供了一个 nextTick 函数,它的回调函数会在DOM 更新后立即执行。
nextTick 本质上是个异步任务,由于事件循环机制,异步任务的回调总是在同步任务执行完成后才得到执行。所以源码实现就是根据环境创建异步函数比如 Promise.then(浏览器不支持promise就会用MutationObserver,浏览器不支持MutationObserver就会用setTimeout),然后调用异步函数执行回调队列。
所以项目中不使用$nextTick的话也可以直接使用Promise.then或者SetTimeout实现相同的效果
Vue 异常处理
1、全局错误处理:
Vue.config.errorHandler
Vue.config.errorHandler = function(err, vm, info) {};如果在组件渲染时出现运行错误,错误将会被传递至全局
Vue.config.errorHandler配置函数 (如果已设置)。比如前端监控领域的 sentry,就是利用这个钩子函数进行的 vue 相关异常捕捉处理
2、全局警告处理:
Vue.config.warnHandlerVue.config.warnHandler = function(msg, vm, trace) {};注意:仅在开发环境生效
像在模板中引用一个没有定义的变量,它就会有warning
3、单个vue 实例错误处理:
renderErrorconst app = new Vue({ el: "#app", renderError(h, err) { return h("pre", { style: { color: "red" } }, err.stack); } });和组件相关,只适用于开发环境,这个用处不是很大,不如直接看控制台
4、子孙组件错误处理:
errorCapturedVue.component("cat", { template: `<div><slot></slot></div>`, props: { name: { type: string } }, errorCaptured(err, vm, info) { console.log(`cat EC: ${err.toString()}\ninfo: ${info}`); return false; } });注:只能在组件内部使用,用于捕获子孙组件的错误,一般可以用于组件开发过程中的错误处理
5、终极错误捕捉:
window.onerrorwindow.onerror = function(message, source, line, column, error) {};它是一个全局的异常处理函数,可以抓取所有的 JavaScript 异常
Vuex 流程 & 原理
Vuex 利用 vue 的mixin 机制,在beforeCreate 钩子前混入了 vuexinit 方法,这个方法实现了将 store 注入 vue 实例当中,并注册了 store 的引用属性 store.xxx`去引入vuex中定义的内容。
然后 state 是利用 vue 的 data,通过
new Vue({data: {$$state: state}}将 state 转换成响应式对象,然后使用 computed 函数实时计算 getterVue.use函数里面具体做了哪些事
概念
可以通过全局方法
Vue.use()注册插件,并能阻止多次注册相同插件,它需要在new Vue之前使用。该方法第一个参数必须是
Object或Function类型的参数。如果是Object那么该Object需要定义一个install方法;如果是Function那么这个函数就被当做install方法。
Vue.use()执行就是执行install方法,其他传参会作为install方法的参数执行。所以**
Vue.use()本质就是执行需要注入插件的install方法**。源码实现
export function initUse (Vue: GlobalAPI) { Vue.use = function (plugin: Function | Object) { const installedPlugins = (this._installedPlugins || (this._installedPlugins = [])) // 避免重复注册 if (installedPlugins.indexOf(plugin) > -1) { return this } // 获取传入的第一个参数 const args = toArray(arguments, 1) args.unshift(this) if (typeof plugin.install === 'function') { // 如果传入对象中的install属性是个函数则直接执行 plugin.install.apply(plugin, args) } else if (typeof plugin === 'function') { // 如果传入的是函数,则直接(作为install方法)执行 plugin.apply(null, args) } // 将已经注册的插件推入全局installedPlugins中 installedPlugins.push(plugin) return this } }使用方式
installedPlugins import Vue from 'vue' import Element from 'element-ui' Vue.use(Element)怎么编写一个vue插件
要暴露一个
install方法,第一个参数是Vue构造器,第二个参数是一个可选的配置项对象Myplugin.install = function(Vue, options = {}) { // 1、添加全局方法或属性 Vue.myGlobalMethod = function() {} // 2、添加全局服务 Vue.directive('my-directive', { bind(el, binding, vnode, pldVnode) {} }) // 3、注入组件选项 Vue.mixin({ created: function() {} }) // 4、添加实例方法 Vue.prototype.$myMethod = function(methodOptions) {} }CSS篇
Css直接面试问答的题目相对来说比较少,更多的是需要你能够当场手敲代码实现功能,一般来说备一些常见的布局,熟练掌握flex基本就没有什么问题了。
什么是 BFC
Block Formatting context,块级格式上下文
BFC 是一个独立的渲染区域,相当于一个容器,在这个容器中的样式布局不会受到外界的影响。
比如浮动元素、绝对定位、overflow 除 visble 以外的值、display 为 inline/tabel-cells/flex 都能构建 BFC。
常常用于解决
处于同一个 BFC 的元素外边距会产生重叠(此时需要将它们放在不同 BFC 中);
清除浮动(float),使用 BFC 包裹浮动的元素即可
阻止元素被浮动元素覆盖,应用于两列式布局,左边宽度固定,右边内容自适应宽度(左边float,右边 overflow)
伪类和伪元素及使用场景
伪类
伪类即:当元素处于特定状态时才会运用的特殊类
开头为冒号的选择器,用于选择处于特定状态的元素。比如
:first-child选择第一个子元素;:hover悬浮在元素上会显示;:focus用键盘选定元素时激活;:link+:visted点击过的链接的样式;:not用于匹配不符合参数选择器的元素;:fist-child匹配元素的第一个子元素;:disabled匹配禁用的表单元素伪元素
伪元素用于创建一些不在文档树中的元素,并为其添加样式。比如说,我们可以通过
::before来在一个元素前增加一些文本,并为这些文本添加样式。虽然用户可以看到这些文本,但是这些文本实际上不在文档树中。示例:
::before在被选元素前插入内容。需要使用 content 属性来指定要插入的内容。被插入的内容实际上不在文档树中h1:before { content: "Hello "; }
::first-line匹配元素中第一行的文本src 和 href 区别
href是Hypertext Reference的简写,表示超文本引用,指向网络资源所在位置。href 用于在当前文档和引用资源之间确立联系
src是source的简写,目的是要把文件下载到html页面中去。src 用于替换当前内容
浏览器解析方式
当浏览器遇到href会并行下载资源并且不会停止对当前文档的处理。(同时也是为什么建议使用 link 方式加载 CSS,而不是使用 @import 方式)
当浏览器解析到src ,会暂停其他资源的下载和处理,直到将该资源加载或执行完毕。(这也是script标签为什么放在底部而不是头部的原因)
不定宽高元素的水平垂直居中
flex
<div class="wrapper flex-center"> <p>horizontal and vertical</p> </div> .wrapper { width: 900px; height: 300px; border: 1px solid #ccc; } .flex-center { // 注意是父元素 display: flex; justify-content: center; // 主轴(竖线)上的对齐方式 align-items: center; // 交叉轴(横轴)上的对齐方式 }flex + margin
<div class="wrapper"> <p>horizontal and vertical</p> </div> .wrapper { width: 900px; height: 300px; border: 1px solid #ccc; display: flex; } .wrapper > p { margin: auto; }Transform + absolute
<div class="wrapper"> <img src="/static/imghwm/default1.png" data-src="test.png" class="lazy" alt="Drei Jahre Erfahrungsaustausch im Vorstellungsgespräch: vier Phasen und drei entscheidende Faktoren von Front-End-Interviews" > </div> .wrapper { width: 300px; height: 300px; border: 1px solid #ccc; position: relative; } .wrapper > img { position: absolute; left: 50%; top: 50%; tansform: translate(-50%, -50%) }注:使用该方法只适用于行内元素(a、img、label、br、select等)(宽度随元素的内容变化而变化),用于块级元素(独占一行)会有问题,left/top 的50%是基于图片最左侧的边来移动的,tanslate会将多移动的图片自身的半个长宽移动回去,就实现了水平垂直居中的效果
display: table-cell
<div class="wrapper"> <p>absghjdgalsjdbhaksldjba</p> </div> .wrapper { width: 900px; height: 300px; border: 1px solid #ccc; display: table-cell; vertical-align: middle; text-align: center; }浏览器和网络篇
浏览器和网络是八股中最典型的案例了,无论你是几年经验,只要是前端,总会有问到你的浏览器和网络协议。
最好的学习文章是李兵老师的《浏览器工作原理与实践》
跨页面通信的方法?
这里分了同源页面和不同源页面的通信。
不同源页面可以通过 iframe 作为一个桥梁,因为 iframe 可以指定 origin 来忽略同源限制,所以可以在每个页面都嵌入同一个 iframe 然后监听 iframe 中传递的 message 就可以了。
同源页面的通信大致分为了三类:广播模式、共享存储模式和口口相传模式
第一种广播模式,就是可以通过 BroadCast Channel、Service Worker 或者 localStorage 作为广播,然后去监听广播事件中消息的变化,达到页面通信的效果。
第二种是共享存储模式,我们可以通过Shared Worker 或者 IndexedDB,创建全局共享的数据存储。然后再通过轮询去定时获取这些被存储的数据是否有变更,达到一个的通信效果。像常见cookie 也可以作为实现共享存储达到页面通信的一种方式
最后一种是口口相传模式,这个主要是在使用 window.open 的时候,会返回被打开页面的 window 的引用,而在被打开的页面可以通过 window.opener 获取打开它的页面的 window 点引用,这样,多个页面之间的 window 是能够相互获取到的,传递消息的话通过 postMessage 去传递再做一个事件监听就可以了
详细说说 HTTP 缓存
在浏览器第一次发起请求服务的过程中,会根据响应报文中的缓存标识决定是否缓存结果,是否将缓存标识和请求结果存入到浏览器缓存中。
HTTP 缓存分为强制缓存和协商缓存两类。
强制缓存就是请求的时候浏览器向缓存查找这次请求的结果,这里分了三种情况,没查找到直接发起请求(和第一次请求一致);查找到了并且缓存结果还没有失效就直接使用缓存结果;查找到但是缓存结果失效了就会使用协商缓存。
强制缓存有 Expires 和 Cache-control 两个缓存标识,Expires 是http/1.0 的字段,是用来指定过期的具体的一个时间(如 Fri, 02 Sep 2022 08:03:35 GMT),当服务器时间和浏览器时间不一致的话,就会出现问题。所以在 http1.1 添加了 cache-control 这个字段,它的值规定了缓存的范围(public/private/no-cache/no-store),也可以规定缓存在xxx时间内失效(max-age=xxx)是个相对值,就能避免了 expires带来的问题。
Beim Aushandeln des Caches wird erzwungen, dass das zwischengespeicherte Ergebnis ungültig wird. Der Browser überträgt die Cache-ID, um eine Anfrage an den Server zu initiieren, und der Server entscheidet anhand der Cache-ID, ob er den Cache verwenden möchte.
Die Felder, die den Verhandlungscache steuern, sind last-modified / if-modified-since und Etag / if-none-match, letzteres hat eine höhere Priorität. Der allgemeine Prozess besteht darin, den zuletzt geänderten oder Etag-Wert über die Anforderungsnachricht an den Server zu übergeben und ihn mit dem entsprechenden Wert auf dem Server zu vergleichen. Wenn das Ergebnis mit dem if-modified-since oder if-none- übereinstimmt. Übereinstimmung in der Antwortnachricht, dann verhandeln Der Cache ist gültig, verwenden Sie das zwischengespeicherte Ergebnis und geben Sie 304 zurück. Andernfalls ist es ungültig, fordern Sie das Ergebnis erneut an und geben Sie 200 zurückDer gesamte Prozess der Eingabe der URL zur Seitenanzeige
Nachdem der Benutzer einen Inhalt eingegeben hat, ermittelt der Browser zunächst, ob es sich bei dem Inhalt um eine URL handelt. Wenn es sich um einen Suchinhalt handelt, wird er mit der Standardsuchmaschine kombiniert, um die URL zu generieren Der Google-Browser lautet beispielsweise goole.com/search?xxxx. Wenn es sich um eine URL handelt, wird das Protokoll kombiniert, z. B. http/https. Wenn die Seite die Zeit vor dem Hochladen nicht abhört oder der Fortsetzung des Ausführungsprozesses zustimmt, wechselt die Symbolleiste des Browsers in den Ladezustand. Als nächstes sendet der Browserprozess die URL-Anfrage über die IPC-Interprozesskommunikation. Der Netzwerkprozess sucht zunächst nach der Ressource im Cache, fängt die Anfrage ab und gibt 200 zurück Wenn nicht, wird der Netzwerkanforderungsprozess gestartet. Der Netzwerkanforderungsprozess besteht darin, dass der Netzwerkprozess den DNS-Server auffordert, die dem Domänennamen entsprechende IP- und Portnummer zurückzugeben (wenn diese zuvor zwischengespeichert wurden, wird das zwischengespeicherte Ergebnis direkt zurückgegeben, wenn keine Portnummer vorhanden ist). , http ist standardmäßig 80, https ist standardmäßig 443, wenn es https ist. Es ist auch erforderlich, eine sichere TLS-Verbindung herzustellen, um einen verschlüsselten Datenkanal zu erstellen. Dann stellt der TCP-Drei-Wege-Handshake eine Verbindung zwischen dem Browser und dem Server her und führt dann die Datenübertragung durch. Winken Sie mit der Hand viermal, um die Verbindung zu trennenVerbindung.
Der Netzwerkprozess analysiert zunächst die über TCP erhaltenen Datenpakete anhand des Inhaltstyps des Antwortheaders. Wenn es sich um einen Bytestream oder Dateityp handelt, wird er an den Download übergeben Navigieren Sie zu diesem Zeitpunkt zum Herunterladen. Der Vorgang ist abgeschlossen. Wenn es vom Typ Text/HTML ist, wird der Browserprozess benachrichtigt, das Dokument zum Rendern abzurufen. Der Browserprozess erhält die Rendering-Benachrichtigung und beurteilt anhand der aktuellen Seite und der neu eingegebenen Seite, ob es sich um dieselbe Site handelt. Wenn ja, wird der von der vorherigen Webseite erstellte Rendering-Prozess wiederverwendet Prozess wird erstellt. Der Browserprozess sendet die Nachricht „Dokument senden“ an den Rendering-Prozess. Wenn der Rendering-Prozess die Nachricht empfängt, richtet er einen Datenübertragungskanal mit dem Netzwerkprozess ein. Nach Abschluss der Datenübertragung wird die Nachricht „Übermittlung bestätigen“ zurückgegeben " Nachricht an den Browserprozess. Nachdem der Browser die Meldung „Übermittlung bestätigen“ vom Rendervorgang erhalten hat, aktualisiert er den Seitenstatus des Browsers: Sicherheitsstatus, Adressleisten-URL, Vorwärts- und Rückwärtsverlaufsmeldungen und aktualisiert die Webseite ist eine leere Seite (weißer Bildschirm).connection: keep-aliveSeiten-Rendering-Prozess (Schlüsselspeicher)
Abschließend führt der Rendering-Prozess eine Seitenanalyse und das Laden von Unterressourcen des Dokuments durch. Der Rendering-Prozess konvertiert HTML in eine DOM-Baumstruktur und konvertiert CSS in styleSeets (CSSOM). Kopieren Sie dann den DOM-Baum und filtern Sie nicht angezeigte Elemente heraus, um einen grundlegenden Rendering-Baum zu erstellen. Berechnen Sie dann den Stil jedes DOM-Knotens und berechnen Sie die Positionslayoutinformationen jedes Knotens, um einen Layoutbaum zu erstellen. Wo es einen Ebenenkontext gibt oder ein Zuschneiden erforderlich ist, werden Ebenen unabhängig voneinander erstellt. Dies ist eine Ebenenstruktur, die schließlich einen Ebenenbaum bildet. Der Renderprozess generiert eine Zeichnungsliste für jede Ebene und übermittelt sie an den Compositing-Thread Der Compositing-Thread wird in Kacheln unterteilt (um zu vermeiden, dass der gesamte Inhalt der Ebene auf einmal gezeichnet wird, und der Ansichtsfensterteil kann entsprechend der Kachelpriorität gerendert werden), und die Kacheln werden im Rasterisierungs-Thread-Pool in Bitmaps konvertiert . Nachdem die Konvertierung abgeschlossen ist, sendet der Synthesethread den Zeichenblockbefehl DrawQuard an den Browserprozess. Der Browser generiert eine Seite basierend auf der DrawQuard-Nachricht und zeigt sie im Browser an.Kurzform:
Der Rendering-Prozess des Browsers analysiert HTML in einen Dom-Baum und CSS in einen CSS-Baum. Anschließend kopiert er zunächst einen DOM-Baum, um nicht angezeigte Elemente herauszufiltern (z. B. display: none). Kombinieren Sie sie dann mit CSS, kombinieren und berechnen Sie die Layoutinformationen jedes DOM-Knotens, um einen Layoutbaum zu erstellen. Nachdem der Layoutbaum generiert wurde, wird er entsprechend dem Stapelkontext oder dem zugeschnittenen Teil der Ebene geschichtet, um einen geschichteten Baum zu bilden. Der Renderprozess generiert dann eine Zeichnungsliste für jede Ebene und übermittelt sie an den Kompositionsthread. Um einmaliges Rendern zu vermeiden, unterteilt der Kompositionsthread die Ebene in Kacheln und wandelt die Kacheln durch die Rasterung um Thread-Pool in Bitmap. Nach Abschluss der Konvertierung sendet der Synthesethread den Befehl zum Zeichnen der Kachel zur Anzeige an den BrowserDer Unterschied zwischen TCP und UDP
UDP ist das User Datagram Protocol (Benutzerdatenprogrammprotokoll). Nachdem IP das Datenpaket über die IP-Adressinformationen an den angegebenen Computer übertragen hat, kann UDP das Datenpaket an den richtigen Computer verteilen über das Portnummerprogramm. UDP kann überprüfen, ob die Daten korrekt sind, verfügt jedoch über keinen Neuübertragungsmechanismus und verwirft nur fehlerhafte Datenpakete. Gleichzeitig kann UDP nach dem Senden nicht bestätigen, ob es das Ziel erreicht hat. UDP kann die Zuverlässigkeit der Daten nicht garantieren, aber die Übertragungsgeschwindigkeit ist sehr hoch. Es wird normalerweise in Bereichen wie Online-Videos und interaktiven Spielen verwendet, in denen die Datenintegrität nicht unbedingt gewährleistet ist.
TCP ist ein Übertragungssteuerungsprotokoll (Transmission Control Protocol), das eingeführt wurde, um das Problem zu lösen, dass UDP-Daten leicht verloren gehen und Datenpakete nicht korrekt zusammensetzen können.Es ist ein verbindungsorientiertes, zuverlässiges, Bytestream-basiertes Transportschicht-Kommunikationsprotokoll . TCP bietet einen Neuübertragungsmechanismus zur Bewältigung von Paketverlusten; und TCP führt einen Paketsortiermechanismus ein, der Datenpakete außerhalb der Reihenfolge zu vollständigen Dateien zusammenfassen kann.
Zusätzlich zum Zielport und der lokalen Portnummer stellt der TCP-Header auch eine Sequenznummer zum Sortieren bereit, sodass der Empfänger die Datenpakete anhand der Sequenznummer neu ordnen kann.Der Unterschied zwischen TCP und UDP
Der Lebenszyklus einer TCP-Verbindung durchläuft drei Phasen: Verbindungsphase, Datenübertragung und Trennungsphase.Verbindungsphase
wird verwendet, um die Verbindung zwischen dem Client und dem Server herzustellen. Der Drei-Wege-Handshake wird verwendet, um die Sende- und Empfangsfunktionen von Datenpaketen zwischen dem Client und dem Server zu bestätigen. 1. Der Client sendet zunächst eine SYN-Nachricht, um zu bestätigen, dass der Server Daten senden kann, und wechselt in den Status SYN_SENT, um auf die Bestätigung vom Server zu warten. 2 Gleichzeitig sendet der Server eine SYN-Nachricht an den Client, um zu bestätigen, ob der Client Daten senden kann. 3 Mit der ACK + SYN-Nachricht wird eine Nachricht an den Server gesendet. Senden Sie das Datenpaket und wechseln Sie in den ESTABLISHED-Status (stellen Sie eine Verbindung her). Wenn der Server das vom Client gesendete ACK-Paket empfängt, wechselt er ebenfalls in den ESTABLISHED-Status und schließt die Verbindung ab der Drei-Wege-HandshakeDatenübertragungsphase
In dieser Phase muss der Empfänger jedes Paket verarbeiten. Führen Sie einen Bestätigungsvorgang durch. Wenn der Absender also ein Datenpaket sendet und keine Bestätigungsnachricht vom empfängt Innerhalb der angegebenen Zeit wird dies als Paketverlust gewertet und der erneute Sendemechanismus ausgelöst. Eine große Datei wird während des Übertragungsvorgangs in viele kleine Datenpakete aufgeteilt Auf der Empfangsseite werden sie nach der Sequenznummer im TCP-Header sortiert, um die Integrität der Daten sicherzustellen.Trennungsphase
Wellen Sie viermal, um sicherzustellen, dass die von beiden Parteien hergestellte Verbindung getrennt werden kann1 Der Client initiiert ein FIN-Paket an den Server und wechselt in den Status FIN_WAIT_12 Paket, senden Sie ein Bestätigungspaket ACK mit seiner eigenen Sequenznummer, und der Server wechselt in den Status CLOSE_WAIT. Zu diesem Zeitpunkt hat der Client keine Daten zum Senden an den Server. Wenn der Server jedoch Daten zum Senden an den Client hat, muss der Client diese dennoch empfangen. Nach Erhalt der Bestätigung wechselt der Client in den Status FIN_WAIT_23. Nachdem der Server das Senden der Daten abgeschlossen hat, wechselt er in den Status LAST_ACK.4 FIN-Paket und sendet ein Bestätigungspaket ACK. Zu diesem Zeitpunkt wechselt der Client in den TIME_WAIT-Status und wartet 2 MSL, bevor der Server in den CLOSED-Status wechselt, nachdem er die ACK des Clients erhalten hat. Da es sich bei TCP um eine Vollduplex-Kommunikation handelt, kann es sein, dass der Empfänger nach dem Senden des FIN-Pakets durch die aktive Abschlusspartei immer noch Daten sendet und der Datenkanal vom Server zum Client nicht sofort geschlossen werden kann, sodass der Server nicht sofort geschlossen werden kann -side kann nicht sein. DasFIN-Paket wird zusammen mit demACK-Paket an den Client gesendet. DasACKkann nur zuerst bestätigt werden und dann Der Server sendet kein-Paket, bis kein FIN-Paket mehr gesendet werden muss, daher müssen vier Wellen vier Datenpaketinteraktionen sein Verstehst du?Content-length ist die HTTP-Nachrichtenlänge, die Anzahl der Bytes, ausgedrückt als Dezimalzahl.
FIN包与对客户端的ACK包合并发送,只能先确认ACK,然后服务器待无需发送数据时再发送FIN包,所以四次挥手时必须是四次数据包的交互Content-length 了解吗?
Content-length 是 http 消息长度,用十进制数字表示的字节的数目。
如果 content-length > 实际长度,服务端/客户端读取到消息队尾时会继续等待下一个字节,会出现无响应超时的情况
如果 content-length
当不确定content-length的值应该使用Transfer-Encoding: chunked,能够将需要返回的数据分成多个数据块,直到返回长度为 0 的终止块
跨域常用方案
什么是跨域?
协议 + 域名 + 端口号均相同时则为同域,任意一个不同则为跨域
解决方案
1、 传统的jsonp:利用
Wenn die Inhaltslänge > die tatsächliche Länge ist, wartet der Server/Client weiterhin auf das nächste Byte, wenn das Ende der Nachrichtenwarteschlange gelesen wird, und es kommt zu einer Zeitüberschreitung ohne Antwort. 🎜🎜Wenn die Inhaltslänge 🎜Gemeinsame domänenübergreifende Lösungen🎜🎜🎜🎜Was ist domänenübergreifend? 🎜🎜🎜Wenn das Protokoll + der Domänenname + die Portnummer gleich sind, handelt es sich um dieselbe Domäne. Wenn eine davon unterschiedlich ist, handelt es sich um eine domänenübergreifende Lösung🎜🎜🎜1 <script> Tags unterliegen keinen domänenübergreifenden Einschränkungen und unterstützen nur die get-Schnittstelle. Niemand sollte dies mehr verwenden<p>2、 一般使用 cors(跨域资源共享)来解决跨域问题,浏览器在请求头中发送origin字段指明请求发起的地址,服务端返回Access-control-allow-orign,如果一致的话就可以进行跨域访问<p>3、 Iframe 解决主域名相同,子域名不同的跨域请求<p>4、 浏览器关闭跨域限制的功能<p>5、 http-proxy-middleware 代理<p><strong>预检<p>补充:http会在跨域的时候发起一次<strong>预检请求,“需预检的请求”要求必须首先使用OPTIONS方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。“预检请求”的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。<p>withCredentials为 true不会产生预请求;content-type为application/json会产生预请求;设置了用户自定义请求头会产生预检请求;delete方法会产生预检请求;<h4 data-id="heading-52"><strong>XSS 和 CSRF</script><script></script>xss基本概念
Xss (Cross site scripting)跨站脚本攻击,为了和 css 区别开来所以叫 xss
Xss 指黑客向 html 或 dom 中注入恶意脚本,从而在用户浏览页面的时候利用注入脚本对用户实施攻击的手段
恶意脚本可以做到:窃取 cookie 信息、监听用户行为(比如表单的输入)、修改DOM(比如伪造登录界面骗用户输入账号密码)、在页面生成浮窗广告等
恶意脚本注入方式:
存储型 xss
黑客利用站点漏洞将恶意 js 代码提交到站点服务器,用户访问页面就会导致恶意脚本获取用户的cookie等信息。
反射性 xss
用户将一段恶意代码请求提交给 web 服务器,web 服务器接收到请求后将恶意代码反射到浏览器端
基于 DOM 的 xss 攻击
通过网络劫持在页面传输过程中更改 HTML 内容
前两种属于服务端漏洞,最后一种属于前端漏洞
防止xss攻击的策略
1、服务器对输入脚本进行过滤或者转码,比如将
code:<script>alert('你被xss攻击了')</script>转换成code:3f1c4e4b6b16bbbd69b2ee476dc4f83aalert('你被xss攻击了')2cacc6d41bbb37262a98f745aa00fbf02、充分利用内容安全策略 CSP(content-security-policy),可以通过 http 头信息的 content-security-policy 字段控制可以加载和执行的外部资源;或者通过html的meta 标签
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https:">3、cookie设置为 http-only, cookie 就无法通过
document.cookie来读取csrf基本概念
Csrf(cross site request forgery)跨站请求伪造,指黑客引导用户访问黑客的网站。
CSRF 是指黑客引诱用户打开黑客的网站,在黑客的网站中,利用用户的登录状态发起的跨站请求。简单来讲,CSRF 攻击就是黑客利用了用户的登录状态,并通过第三方的站点来做一些坏事。
Csrf 攻击场景
自动发起 get 请求
比如黑客网站有个图片:
<img src="/static/imghwm/default1.png" data-src="https://time.geekbang.org/sendcoin?user=hacker&number=100" class="lazy" alt="Drei Jahre Erfahrungsaustausch im Vorstellungsgespräch: vier Phasen und drei entscheidende Faktoren von Front-End-Interviews" >黑客将转账的请求接口隐藏在 img 标签内,欺骗浏览器这是一张图片资源。当该页面被加载时,浏览器会自动发起 img 的资源请求,如果服务器没有对该请求做判断的话,那么服务器就会认为该请求是一个转账请求,于是用户账户上的 100 极客币就被转移到黑客的账户上去了。
自动发起 post 请求
黑客在页面中构建一个隐藏的表单,当用户点开链接后,表单自动提交
引诱用户点击链接
比如页面上放了一张美女图片,下面放了图片下载地址,而这个下载地址实际上是黑客用来转账的接口,一旦用户点击了这个链接,那么他的极客币就被转到黑客账户上了
防止csrf方法
1、设置 cookie 时带上SameSite: strict/Lax选项
2、验证请求的来源站点,通过 origin 和 refere 判断来源站点信息
3、csrf token,浏览器发起请求服务器生成csrf token,发起请求前会验证 csrf token是否合法。第三方网站肯定是拿不到这个token。我们的 csrf token 是前后端约定好后写死的。
websocket
websocket是一种支持双向通信的协议,就是服务器可以主动向客户端发消息,客户端也可以主动向服务器发消息。
Es stellt eine Verbindung basierend auf dem HTTP-Protokoll her. Es ist gut mit dem HTTP-Protokoll kompatibel, sodass es keine Same-Origin-Beschränkung gibt.
WebSocket ist ein ereignisgesteuertes Protokoll, was bedeutet, dass es für echte Echtzeitkommunikation verwendet werden kann. Im Gegensatz zu HTTP (wo Updates ständig angefordert werden müssen) werden Updates bei WebSockets gesendet, sobald sie verfügbar sind. WebSockets werden nicht automatisch wiederhergestellt, wenn die Verbindung beendet wird. Dies ist ein Mechanismus, der von Ihnen selbst in der Anwendungsentwicklung implementiert werden muss , und es gibt viele Gründe für clientseitige Open-Source-Bibliotheken.
DevServer wie Webpack und Vite verwenden WebSocket, um Hot-Updates zu implementieren Szenarien des Servers, bei denen Ressourcen keine Auswirkungen haben, z. B. das Anfordern von Ressourcen für eine Webseite. (Und Post ist keine
idempotenteAnfrage) Es wird im Allgemeinen in Szenarien verwendet, die sich auf Serverressourcen auswirken, beispielsweise bei Vorgängen wie der Registrierung von Benutzern. (
Idempotenz bedeutet, dass die Auswirkung der mehrmaligen Ausführung einer Anforderungsmethode und der nur einmaligen Ausführung genau gleich ist)
Ob zwischengespeichert werden soll:Da die Anwendungsszenarien der beiden unterschiedlich sind, speichern Browser Get-Anfragen im Allgemeinen zwischen, aber selten Post-Requests Request-Caching.
- Die Parameter werden auf unterschiedliche Weise übergeben: Get übergibt Parameter über die Abfragezeichenfolge und Post übergibt Parameter über den Anforderungstext. Sicherheit: Die Get-Anfrage kann die angeforderten Parameter in die URL einfügen und an den Server senden. Dieser Ansatz ist weniger sicher als die Post-Anfrage, da die angeforderte URL im Verlauf gespeichert wird.
- Anfragelänge: Aufgrund von Browser-Längenbeschränkungen für URLs wirkt sich dies auf die Länge der Abrufanfrage beim Senden von Daten aus. Diese Einschränkung wird vom Browser vorgegeben, nicht vom RFC.
- Parametertyp: Der Get-Parameter erlaubt nur ASCII-Zeichen und die Post-Parameterübertragung unterstützt mehr Datentypen (z. B. Dateien, Bilder).
- Leistungsoptimierung
- Leistungsoptimierung ist ein Punkt, dem mittlere und große Unternehmen große Aufmerksamkeit schenken. Da sie eng mit den KPIs von Front-End-Mitarbeitern zusammenhängt, wird sie natürlich zu einer häufigen Frage im Vorstellungsgespräch. ... Aushandlung) Cache), Inhalte im Speicher oder auf der Festplatte speichern, wodurch Anfragen an den Server reduziert werden.
- Im Netzwerk wird häufiger CDN für statische Ressourcen verwendet. In Bezug auf die Verpackung. Laden von Routen nach Bedarf
Optimierte Verpackung. Die Größe der endgültigen Ressource.Gzip-Komprimierungsressourcen aktivieren -Zeit-JS-Verarbeitung, die die Haupt-Threads blockiert (zeitaufwändig und irrelevant für DOM, kann zur Verarbeitung an Web-Worker übergeben oder in kleine Aufgaben aufgeteilt werden)
Bilder können mit Lazy Loading geladen werden, lange Listen können mit virtuellem Scrollen geladen werden
Verbesserung der Geschwindigkeit des ersten Bildschirms
Codekomprimierung, Reduzierung des Volumens gepackter statischer Ressourcen (Terser-Plugin/MiniCssExtratplugin)
- Verzögertes Laden von Routen, der erste Bildschirm fordert nur verwandte Ressourcen der ersten Route anVerwenden Sie CDN, um die dritte zu beschleunigen -Party-Bibliotheken, wir sind ein Produkt von toB, das Sie benötigen Es wird im Intranet bereitgestellt, daher wird ToC im Allgemeinen nicht verwendet.
vue Gängige Methoden zur Leistungsoptimierung
- ssr serverseitiges Rendering, und der Server gibt das gespleißte HTML direkt zurück Seite
- Lazy Loading von Bildern: vue-lazyLoad
- Virtuelles ScrollenFunktionskomponente
- v-show/keep-alive Reuse dom
- Deffer verzögerte Rendering-Komponente (requestIdleCallback)
- Zeitaufteilung
- Technische Punkte des Front-End-Überwachungs-SDK
erhalten. Die vollständige Front-End-Überwachungsplattform umfasst: Datenerfassung und -berichterstattung, Daten Sortieren und Speichern, Datenanzeige
- Sie können verschiedene Leistungsindikatordaten über
- Leistungsindikatoren für Webseiten:
- FP (First-Paint) Die Zeit vom Laden der Seite bis zum Zeichnen des ersten Pixels auf dem Bildschirm
- FCP (First-Contentful-Paint ), die Zeit vom Laden der Seite bis zum Abschluss der Darstellung eines Teils des Seiteninhalts auf dem Bildschirm
- LCP (largest-contentful-paint), die Zeit vom Laden der Seite bis zum Abschluss der Darstellung des größten Text- oder Bildelements auf dem Bildschirm
- Die oben genannten Indikatoren können über
PerformanceObserver
abgerufen werden
首屏渲染时间计算:通过
MutationObserver监听document对象的属性变化如何减少回流、重绘,充分利用 GPU 加速渲染?
首先应该避免直接使用 DOM API 操作 DOM,像 vue react 虚拟 DOM 让对 DOM 的多次操作合并成了一次。
样式集中改变,好的方式是使用动态 class
读写操作分离,避免读后写,写后又读
// bad 强制刷新 触发四次重排+重绘 div.style.left = div.offsetLeft + 1 + 'px'; div.style.top = div.offsetTop + 1 + 'px'; div.style.right = div.offsetRight + 1 + 'px'; div.style.bottom = div.offsetBottom + 1 + 'px'; // good 缓存布局信息 相当于读写分离 触发一次重排+重绘 var curLeft = div.offsetLeft; var curTop = div.offsetTop; var curRight = div.offsetRight; var curBottom = div.offsetBottom; div.style.left = curLeft + 1 + 'px'; div.style.top = curTop + 1 + 'px'; div.style.right = curRight + 1 + 'px'; div.style.bottom = curBottom + 1 + 'px';原来的操作会导致四次重排,读写分离之后实际上只触发了一次重排,这都得益于浏览器的渲染队列机制:
当我们修改了元素的几何属性,导致浏览器触发重排或重绘时。它会把该操作放进渲染队列,等到队列中的操作到了一定的数量或者到了一定的时间间隔时,浏览器就会批量执行这些操作。
使用
display: none后元素不会存在渲染树中,这时对它进行各种操作,然后更改 display 显示即可(示例:向2000个div中插入一个div)通过 documentFragment 创建 dom 片段,在它上面批量操作 dom ,操作完后再添加到文档中,这样只有一次重排(示例:一次性插入2000个div)
复制节点在副本上操作然后替换它
使用 BFC 脱离文档流,重排开销小
Css 中的
transform、opacity、filter、will-change能触发硬件加速大图片优化的方案
优化请求数
- 雪碧图,将所有图标合并成一个独立的图片文件,再通过
background-url和backgroun-position来显示图标- 懒加载,尽量只加载用户正则浏览器或者即将浏览的图片。最简单使用监听页面滚动判断图片是否进入视野;使用 intersection Observer API;使用已知工具库;使用css的
background-url来懒加载- base64,小图标或骨架图可以使用内联 base64因为 base64相比普通图片体积大。注意首屏不需要懒加载,设置合理的占位图避免抖动。
减小图片大小
- 使用合适的格式比如WebP、svg、video替代 GIF 、渐进式 JPEG
- 削减图片质量
- 使用合适的大小和分辨率
- 删除冗余的图片信息
- Svg 压缩
缓存
代码优化
非响应式变量可以定义在
created钩子中使用 this.xxx 赋值访问局部变量比全局变量块,因为不需要切换作用域
尽可能使用
const声明变量,注意数组和对象使用 v8 引擎时,运行期间,V8 会将创建的对象与隐藏类关联起来,以追踪它们的属性特征。能够共享相同隐藏类的对象性能会更好,v8 会针对这种情况去优化。所以为了贴合”共享隐藏类“,我们要避免”先创建再补充“式的动态属性复制以及动态删除属性(使用delete关键字)。即尽量在构造函数/对象中一次性声明所有属性。属性删除时可以设置为 null,这样可以保持隐藏类不变和继续共享。
避免内存泄露的方式
- 尽可能少创建全局变量
- 手动清除定时器
- 少用闭包
- 清除 DOM 引用
- 弱引用
避免强制同步,在修改 DOM 之前查询相关值
避免布局抖动(一次 JS 执行过程中多次执行强制布局和抖动操作),尽量不要在修改 DOM 结构时再去查询一些相关值
合理利用 css 合成动画,如果能用 css 处理就交给 css。因为合成动画会由合成线程执行,不会占用主线程
避免频繁的垃圾回收,优化存储结构,避免小颗粒对象的产生
感兴趣的可以看看我之前的一篇性能优化技巧整理的文章极意 · 代码性能优化之道
Front-End-Engineering
Front-End-Engineering ist der wichtigste Kompetenzpunkt für das Wachstum von Front-End-ER. Alle Funktionen, die die Effizienz der Front-End-Entwicklung verbessern können können als Teil von Front-End betrachtet werden. Endtechnik. Wer gerade erst anfängt, kann mit dem Bau eines Gerüsts von Grund auf beginnenEin langer Artikel mit 10.000 Wörtern erklärt ausführlich den gesamten Prozess des Aufbaus eines Vue3 + Vite2 + TS4-Frameworks auf Unternehmensebene von Grund auf
Für Interviews ist das Wichtigste Untersuchen ist die Beherrschung von Verpackungswerkzeugen.
Ausführungsprozess und Lebenszyklus von Webpack
Webpack ist ein Bundle, das statische Ressourcenpaketierungsfunktionen für moderne JS-Anwendungen bereitstellt.
Der Kernprozess besteht aus drei Phasen: Initialisierungsphase, Konstruktionsphase und Generierungsphase.
1 In der Initialisierungsphase werden die Initialisierungsparameter aus der Konfigurationsdatei, dem Konfigurationsobjekt und den Shell-Parametern gelesen und mit der Standardkonfiguration kombiniert Die endgültigen Parameter erstellen nicht nur das Compiler-Compiler-Objekt, sondern initialisieren auch seine laufende Umgebung.
2 In der Konstruktionsphase führt der Compiler zunächst die Eingabedatei aus. und beginnen Sie mit der Suche nach und Eingabedateien aus der Eingabedatei. Erstellen Sie abhängige Objekte für alle direkt oder kurzzeitig damit verbundenen Dateien und erstellen Sie dann Modulobjekte basierend auf den abhängigen Objekten. Zu diesem Zeitpunkt wird der Loader zum Konvertieren des Moduls verwendet Standard-JS-Inhalt, und dann wird der JS-Interpreter aufgerufen, um den Inhalt in ein AST-Objekt zu konvertieren, und dann aus dem AST. Suchen Sie die Module, von denen das Modul abhängt, und wiederholen Sie diesen Schritt, bis alle Eintragsabhängigkeitsdateien in diesem Schritt verarbeitet wurden . Schließlich ist die Modulkompilierung abgeschlossen und der übersetzte Inhalt jedes Moduls sowie das Abhängigkeitsdiagramm zwischen ihnen werden erhalten. Dieses Abhängigkeitsdiagramm ist die Zuordnungsbeziehung aller im Projekt verwendeten Module.
3. Kombinieren Sie in der Generierungsphase die kompilierten Module in Blöcke, konvertieren Sie dann jeden Block in eine separate Datei und geben Sie sie in die Dateiliste aus. Bestimmen Sie den Ausgabepfad und den Dateinamen entsprechend der Konfiguration , und fügen Sie dann die Datei hinzu. Der Inhalt wird in das Dateisystem geschrieben. Das Plugin und der Loader des Webpacks. Der Loader kann nur JS- und JSON-Dateien verstehen. Der Loader ist im Wesentlichen ein Konverter, der andere Dateitypen konvertieren kann in Dinge, die vom Webpack erkannt werden.
Loader konvertiert das vom abhängigen Objekt erstellte Modul während der Webpack-Erstellungsphase in Standard-JS-Inhalte. Beispielsweise konvertiert Vue-Loader Vue-Dateien in JS-Module und Bildschriftarten werden über URL-Loader in Daten-URLs konvertiert. Dies sind Dinge, die Webpack erkennen kann. Sie können in module.rules verschiedene Loader konfigurieren, um verschiedene Dateien zu analysieren.
Plugin
Das Plug-in ist im Wesentlichen eine Klasse mit einer Apply-Funktion. Diese Apply-Funktion verfügt über einen Parameter-Compiler, der währenddessen vom Compiler generiert wird In der Initialisierungsphase des Webpack-Objekts können Sie Hooks im Compiler-Objekt aufrufen, um Rückrufe für verschiedene Hooks zu registrieren. Diese Hooks durchlaufen den gesamten Kompilierungslebenszyklus. Daher können Entwickler über Hook-Rückrufe bestimmten Code einfügen, um bestimmte Funktionen zu erreichen.
Das Stylelint-Plugin kann beispielsweise den Dateityp und den Dateibereich angeben, den Stylelint überprüfen muss; HtmlWebpackPlugin wird zum Generieren gepackter Vorlagendateien verwendet; Stylelintplugin kann während der Entwicklungsphase eine Stilprüfungsfunktion bereitstellen .
Webpacks Hash-StrategieMiniCssExtractPlugin Einerseits erwarten sie, dass sie jedes Mal, wenn sie Seitenressourcen anfordern, die neuesten Ressourcen erhalten. Andererseits erwarten sie, dass sie zwischengespeicherte Objekte wiederverwenden können, wenn die Ressourcen verfügbar sind nicht geändert. Zu diesem Zeitpunkt können Sie mithilfe der Methode Dateiname + Datei-Hashwert anhand des Dateinamens unterscheiden, ob die Ressource aktualisiert wurde. Webpack verfügt über eine integrierte Hash-Berechnungsmethode. Für generierte Dateien können Sie der Ausgabedatei ein Hash-Feld hinzufügen.
Webpack verfügt über drei integrierte Hashes
class myPlugin { apply(compiler) {} }Hash: Jedes Mal, wenn das Projekt erstellt wird, wird ein Hash generiert, der sich auf das gesamte Projekt bezieht, wenn es irgendwo im Projekt Änderungen gibt
Hash wird basierend auf dem Inhalt jedes Projekts berechnet. Es kann leicht zu unnötigen Hash-Änderungen kommen, was der Versionsverwaltung nicht förderlich ist. Im Allgemeinen gibt es kaum Möglichkeiten, Hashes direkt zu verwenden.
Inhalts-Hash: bezogen auf den Inhalt einer einzelnen Datei. Wenn sich der Inhalt der angegebenen Datei ändert, ändert sich auch der Hash. Der Inhalt bleibt unverändert und der Hash-Wert bleibt unverändert. Bei CSS-Dateien wird im Allgemeinen MiniCssExtractPlugin verwendet, um ihn in eine separate CSS-Datei zu extrahieren.
Sie können zu diesem Zeitpunkt Contenthash zum Markieren verwenden, um sicherzustellen, dass der Hash aktualisiert werden kann, wenn sich der Inhalt der CSS-Datei ändert.Chunk-Hash
- : Bezieht sich auf den Chunk, der durch die Webpack-Verpackung generiert wird. Jeder Eintrag hat einen anderen Hash.
Im Allgemeinen verwenden wir für Ausgabedateien Chunthash.
Da nach dem Packen des Webpacks jede Eintragsdatei und ihre Abhängigkeiten schließlich eine separate js-Datei generieren.
Die Verwendung von Chunkhash zu diesem Zeitpunkt kann die Aktualisierungsgenauigkeit des gesamten verpackten Inhalts sicherstellen.
Erweiterung: File-Loader-Hash Einige Schüler haben möglicherweise die folgenden Fragen.
Es kommt häufig vor, dass bei der Verarbeitung einiger Bilder und beim Packen von Schriftartdatei-Loadern [name]_[hash:8].[ext] verwendet wird
Aber wenn andere Projektdateien geändert werden, wie z. B. index.js, wird die Der generierte Bild-Hash hat sich nicht geändert.
Hier ist zu beachten, dass das Hash-Feld des File-Loaders, der vom Loader selbst definierte Platzhalter, nicht mit dem integrierten Hash-Feld von Webpack übereinstimmt.
Der Hash besteht hier darin, Hash-Algorithmen wie MD4 zu verwenden, um den Dateiinhalt zu hashen.
Solange also der Dateiinhalt unverändert bleibt, bleibt der Hash weiterhin konsistent.
Vite-Prinzip
Vite besteht hauptsächlich aus zwei Teilen
3 Sie können oneOf für Loader verwenden
Entwicklungsumgebung
Vite verwendet den Browser, um Importe zu analysieren, zu kompilieren und bei Bedarf auf der Serverseite zurückzugeben, wobei das Konzept der Verpackung vollständig übersprungen wird Der Server folgt Einfach zu verwenden (entspricht dem Konvertieren der von uns entwickelten Dateien in das ESM-Format und dem direkten Senden an den Browser)
Wenn der Browser den Import von HelloWorld aus „./components/HelloWorld.vue“ analysiert, sendet er eine Anfrage um den aktuellen Domänennamen zu erhalten Für die entsprechenden Ressourcen (ESM unterstützt das Parsen relativer Pfade) lädt der Browser die entsprechenden Dateien direkt herunter und analysiert sie in Moduldatensätze (öffnen Sie das Netzwerkfenster und Sie können sehen, dass die Antwortdaten alle ESM-Typ-JS sind ). Instanziieren Sie dann das Modul, weisen Sie ihm Speicher zu und stellen Sie die Zuordnungsbeziehung zwischen Modul und Speicher gemäß den Import- und Exportanweisungen her. Führen Sie abschließend den Code aus.
vite startet einen Koa-Server, um die ESM-Anfrage des Browsers abzufangen, die entsprechende Datei im Verzeichnis über den Anforderungspfad zu finden, sie in das ESM-Format zu verarbeiten und an den Client zurückzugeben.
Das Hot-Loading von Vite stellt eine Websocket-Verbindung zwischen dem Client und dem Server her. Nachdem der Code geändert wurde, sendet der Server eine Nachricht, um den geänderten Modulcode anzufordern view-Datei wird geändert. Diese Datei stellt sicher, dass die Hot-Update-Geschwindigkeit nicht von der Projektgröße beeinflusst wird.
Die Entwicklungsumgebung verwendet esbuild, um den Cache für Abhängigkeiten vorab zu erstellen. Der erste Start wird langsamer sein, und nachfolgende Starts lesen den Cache direkt.
Die Produktionsumgebung verwendet Rollup, um den Code zu erstellen und Anweisungen bereitzustellen zur Verwendung Optimieren Sie den Build-Prozess. Der Nachteil besteht darin, dass die Entwicklungsumgebung und die Produktionsumgebung möglicherweise inkonsistent sind Es gibt immer mehr Abhängigkeiten, auch wenn Sie nur eine Datei ändern. Theoretisch wird die Geschwindigkeit des Hot-Updates immer langsamer Durch das Konzept der Verpackung kann der Server jederzeit verwendet werden. Das Update besteht darin, eine WebSocket-Verbindung zwischen dem Client und dem Server herzustellen. Nachdem der Code geändert wurde, sendet der Server eine Nachricht, um den Client zu benachrichtigen, den geänderten Modulcode anzufordern. Um das Hot-Update abzuschließen, wird die Datei erneut angefordert. Dadurch wird sichergestellt, dass die Hot-Update-Geschwindigkeit nicht durch die Größe des Projekts beeinträchtigt wird. Das größte Highlight von Vite ist derzeit das Entwicklungserlebnis Schnell und das Hot-Update ist schnell, was offensichtlich die Entwicklererfahrung optimiert. Da die unterste Ebene der Produktionsumgebung Rollup ist, ist die Codebasis in Bezug auf Erweiterung und Funktionalität nicht so gut. Sie können Vite als Entwicklungsserver verwenden und Webpack für die Produktionsverpackung verwenden. 0. Aktualisieren Sie die Webpack-Version, 3 Liter 4, der eigentliche Test besteht darin, die Verpackungsgeschwindigkeit um Dutzende Sekunden zu erhöhen
1. SplitChunksPlugin trennt das gemeinsam genutzte Modul und gibt separate Blöcke aus, um zu verhindern, dass einzelne Blöcke zu groß werden
2 Abhängige Bibliothek ist gleichbedeutend mit einer Trennung vom Geschäftscode. Nur wenn sich die Version der abhängigen Bibliothek selbst ändert, wird die Paketierungsgeschwindigkeit verbessertSolange der entsprechende Loader übereinstimmt, wird der Loader nicht weiterhin ausgeführt. Verwenden Sie happyPack, um die synchrone Ausführung des Loaders in eine parallele Ausführung umzuwandeln -Loader, Less-Loader werden für die Ausführung kombiniert.
a.js)改变,就将这个依赖所处的module的更新,并将新的module发送给浏览器重新执行。每次热更新都会重新生成bundle4 Tag und verwendet Tree-Shaking. 7. Alias gibt den Pfad-Alias anNPM-Ausführungsprozess
0 Das Skriptkonfigurationselement kann in der Datei package.json definiert werden, die den Schlüssel und Wert des ausgeführten Skripts definieren kann
1. Bei der Installation von npm liest npm die Konfiguration Führen Sie es aus Skript-Softlink zum Verzeichnis
node_modules/.bin,node_modules/.bin目录下,同时将./bin加入当环境变量$PATH中,所以如果在全局直接运行该命令会去全局目录里找,可能会找不到该命令就会报错。比如 npm run start,他是执行的webpack-dev-server带上参数2、还有一种情况,就是单纯的执行脚本命令,比如 npm run build,实际运行的是 node build.js,即使用 node 执行 build.js 这个文件
ESM和CJS 的区别
ES6
- ES6模块是引用,重新赋值会编译报错,不能修改其变量的指针指向,但可以改变内部属性的值;
- ES6模块中的值属于动态只读引用。
- 对于只读来说,即不允许修改引入变量的值,import的变量是只读的,不论是基本数据类型还是复杂数据类型。当模块遇到import命令时,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。
- 对于动态来说,原始值发生变化,import 加载的值也会发生变化。不论是基本数据类型还是复杂数据类型。
- 循环加载时,ES6模块是动态引用。只要两个模块之间存在某个引用,代码就能够执行。
CommonJS
- CommonJS模块是拷贝(浅拷贝),可以重新赋值,可以修改指针指向;
- 对于基本数据类型,属于复制。即会被模块缓存。同时,在另一个模块可以对该模块输出的变量重新赋值。
- 对于复杂数据类型,属于浅拷贝。由于两个模块引用的对象指向同一个内存空间,因此对该模块的值做修改时会影响另一个模块。 当使用require命令加载某个模块时,就会运行整个模块的代码。
- 当使用require命令加载同一个模块时,不会再执行该模块,而是取到缓存之中的值。也就是说,CommonJS模块无论加载多少次,都只会在第一次加载时运行一次,以后再加载,就返回第一次运行的结果,除非手动清除系统缓存。
- 当循环加载时,脚本代码在require的时候,就会全部执行。一旦出现某个模块被"循环加载",就只输出已经执行的部分,还未执行的部分不会输出。
设计模式篇
代理模式
代理模式:为对象提供一个代用品或占位符,以便控制对它的访问
例如实现图片懒加载的功能,先通过一张
, Wenn Sie diesen Befehl also direkt global ausführen, wird im globalen Verzeichnis danach gesucht. Wenn der Befehl nicht gefunden werden kann, wird ein Fehler gemeldet. Beispielsweise führt npm run start den webpack-dev-server mit Parametern ausloading图占位,然后通过异步的方式加载图片,等图片加载好了再把完成的图片加载到imgfügen Sie außerdem./binzur Umgebungsvariablen$PATHhinzu2 Es gibt auch eine Situation, in der durch einfaches Ausführen eines Skriptbefehls wie npm run build tatsächlich node build.js ausgeführt wird, d build.js-DateiDer Unterschied zwischen ESM und CJS
ES6
- ES6-Modul ist eine Referenz, eine Neuzuweisung führt zu Kompilierungsfehlern, nicht möglich Ändern Sie den Zeiger seiner Variablen, aber Sie können den Wert der internen Eigenschaft ändern;
- Die Werte im ES6-Modul sind dynamische schreibgeschützte Referenzen.
- Für schreibgeschützt, d. h. der Wert der importierten Variablen darf nicht geändert werden. Die importierte Variable ist schreibgeschützt, unabhängig davon, ob es sich um einen Basisdatentyp oder einen komplexen Datentyp handelt. Wenn ein Modul auf einen Importbefehl trifft, wird eine schreibgeschützte Referenz generiert. Wenn das Skript tatsächlich ausgeführt wird, wird der Wert basierend auf dieser schreibgeschützten Referenz aus dem geladenen Modul abgerufen.
- Wenn sich bei Dynamiken der ursprüngliche Wert ändert, ändert sich auch der durch den Import geladene Wert. Ob es sich um einen Basisdatentyp oder einen komplexen Datentyp handelt.
- Beim Laden in einer Schleife werden ES6-Module dynamisch referenziert. Solange zwischen den beiden Modulen eine Referenz besteht, kann der Code ausgeführt werden.
CommonJS
- Das CommonJS-Modul ist eine Kopie (flache Kopie), die neu zugewiesen werden kann und auf die der Zeiger gezeigt werden kann.
- Für grundlegende Datentypen , es gehört Kopie. Das heißt, es wird vom Modul zwischengespeichert. Gleichzeitig können die von diesem Modul ausgegebenen Variablen in einem anderen Modul neu zugewiesen werden.
- Bei komplexen Datentypen handelt es sich um eine flache Kopie. Da die von den beiden Modulen referenzierten Objekte auf denselben Speicherplatz verweisen, wirken sich Änderungen am Wert des Moduls auf das andere Modul aus. Wenn ein Modul mit dem Befehl require geladen wird, wird der gesamte Code des Moduls ausgeführt.
- Wenn Sie den Befehl require zum Laden desselben Moduls verwenden, wird das Modul nicht erneut ausgeführt, sondern der Wert im Cache wird abgerufen. Mit anderen Worten: Unabhängig davon, wie oft das CommonJS-Modul geladen wird, wird es beim ersten Laden nur einmal ausgeführt. Wenn es später geladen wird, wird das Ergebnis des ersten Laufs zurückgegeben, es sei denn, der Systemcache ist vorhanden manuell gelöscht.
- Beim Laden in einer Schleife werden alle Skriptcodes bei Bedarf ausgeführt. Sobald ein Modul „in einer Schleife geladen“ ist, wird nur der ausgeführte Teil ausgegeben und der nicht ausgeführte Teil wird nicht ausgegeben.
Entwurfsmuster
Agent-Modus
Agent-Modus: Bereitstellen ein Ersatz oder Platzhalter für das Objekt, um den Zugriff darauf zu steuern
Um beispielsweise die Funktion des verzögerten Ladens von Bildern zu implementieren, übergeben Sie zunächst einenloading-Bildplatzhalter und laden Sie das Bild dann asynchron. Warten Sie bis Das Bild wird geladen und dann wird das fertige Bild in dasimg-Tag geladen.Dekorationsmodus
Die Definition des Dekorationsmodus: ohne das Objekt selbst zu ändern, wenn das Programm ausgeführt wird In diesem Zeitraum werden Methoden dynamisch zum Objekt hinzugefügtEs wird normalerweise verwendet, um die ursprüngliche Methode unverändert zu lassen und dann andere Methoden auf der ursprünglichen Methode bereitzustellen, um bestehende Anforderungen zu erfüllen. 🎜🎜Dekoratoren wie Typoskript sind ein typisches Dekoratormuster, und das Mixin-in-Vue-Singleton-Muster🎜🎜🎜 stellt sicher, dass eine Klasse nur eine Instanz hat und bietet einen globalen Zugriffspunkt für den Zugriff darauf. Die Implementierungsmethode besteht darin, zunächst festzustellen, ob die Instanz vorhanden ist. Wenn sie nicht vorhanden ist, wird sie erstellt und zurückgegeben. Dadurch wird sichergestellt, dass eine Klasse nur ein Instanzobjekt hat. Es wird garantiert, dass die Unteranwendung von Ice Stark jeweils eine Unteranwendung rendert Bestimmte Ziele können als Herausgeber betrachtet werden, aber Beobachter Der Modus wird von bestimmten Zielen geplant, während der Veröffentlichungs- / Abonnementmodus vom Planungszentrum einheitlich angepasst wird. Daher besteht eine Abhängigkeit zwischen dem Abonnenten und dem Herausgeber des Beobachtermodus Beim Publish/Subscribe-Modus ist dies nicht der Fall. 🎜🎜2. Beide Muster können für eine lose Kopplung, eine verbesserte Codeverwaltung und eine potenzielle Wiederverwendung verwendet werden. 🎜🎜3. Im Beobachtermodus kennt der Beobachter das Subjekt und das Subjekt führt Aufzeichnungen über den Beobachter. Beim Publish-Subscribe-Modell wissen der Herausgeber und der Abonnent jedoch nichts von der Existenz des anderen. Sie kommunizieren nur über Nachrichtenbroker🎜🎜4. Der Beobachtermodus ist die meiste Zeit synchron. Wenn beispielsweise ein Ereignis ausgelöst wird, ruft das Subjekt die Beobachtermethode auf. Das Publish-Subscribe-Muster ist größtenteils asynchron (unter Verwendung von Nachrichtenwarteschlangen) 🎜Andere
Reguläre Ausdrücke
Welcher Datentyp ist ein regulärer Ausdruck?
ist ein Objekt,
let re = /ab+c/entsprichtlet re = new RegExp('ab+c')let re = /ab+c/等价于let re = new RegExp('ab+c')正则贪婪模式和非贪婪模式?
量词
*:0或多次;?:0或1次;+:1到多次;{m}:出现m次;{m,}:出现至少m次;{m, n}:出现m到n次贪婪模式
正则中,表示次数的量词默认是贪婪的,会尽可能匹配最大长度,比如
a*会从第一个匹配到a的时候向后匹配尽可能多的a,直到没有a为止。非贪婪模式
在量词后面加
?就能变成非贪婪模式,非贪婪即找出长度最小且满足条件的贪婪& 非贪婪特点
贪婪模式和非贪婪模式,都需要发生回溯才能完成相应的功能
独占模式
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。
写法:量词后面使用
+优缺点:独占模式性能好,可以减少匹配的时间和 cpu 资源;但是某些情况下匹配不到,比如:
正则 文本 结果 贪婪模式 a{1,3}ab aaab 匹配 非贪婪模式 a{1,3}?ab aaab 匹配 独占模式 a{1,3}+ab aaab 不匹配 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯
常见正则匹配
🎜🎜Gieriger Modus🎜🎜🎜In regulären Regeln ist der Quantifizierer, der die Anzahl angibt, standardmäßig gierig und entspricht so weit wie möglich der maximalen Länge. Beispielsweise wird
操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单个字符给出范围 [abc]表示 a、b、c,[a-z]表示 a-z 的单个字符[^ ] 非字符集,对单个字符给出排除范围 [^abc]表示非a或b或c的单个字符_ 前一个字符零次或无限次扩展 abc_表示 ab、abc、abcc、abccc 等` ` 左右表达式的任意一个 `abc def`表示 abc、def $ 匹配字符串结尾 abc$表示 abc 且在一个字符串结尾( ) 分组标记内部只能使用 (abc)表示 abc,`(abcdef)`表示 abc、def D 非数字 d 数字,等价于0-9 S 可见字符 s 空白字符(空格、换行、制表符等等) W 非单词字符 w 单词字符,等价于[a-z0-9A-Z_] 匹配字符串开头 ^abc表示 abc 且在一个字符串的开头{m,n} 扩展前一个字符 m 到 n 次 ab{1,2}c表示 abc、abbc{m} 扩展前一个字符 m 次 ab{2}c表示 abbc{m,} 匹配前一个字符至少m 次 ? 前一个字符 0 次或 1 次扩展 abc?regulärer Greedy-Modus und Non-Greedy-Modus?
Quantifier*: 0 oder mehr Mal;?: 0 oder 1 Mal;+: 1 bis mehrfach;{m: erscheint m-mal;{m,}: erscheint mindestens m-mal;{m, n}: erscheint m bis n mala*rückwärts abgeglichen Vom ersten Spiel bis zum A. So viele A's wie möglich, bis keine A's mehr übrig sind. 🎜🎜🎜Nicht-gieriger Modus🎜🎜🎜Fügen Sie?nach dem Quantifizierer hinzu, um zum nicht-gierig-Modus zu wechseln, um die Mindestlänge zu finden und die Bedingungen zu erfüllen 🎜🎜🎜Gierig und nicht-gierig Eigenschaften🎜🎜 🎜Der gierige Modus und der nicht gierige Modus benötigen beide 🎜Backtracking🎜, um die entsprechende Funktion abzuschließen. 🎜🎜🎜Der exklusive Modus ist dem gierigen Modus sehr ähnlich Wenn die Übereinstimmung fehlschlägt, wird kein Backtracking durchgeführt, was Zeit spart. 🎜🎜Schreiben: Verwenden Sie+nach dem Quantifizierer🎜🎜Vor- und Nachteile: Der Exklusivmodus bietet eine gute Leistung und kann die Abgleichzeit und CPU-Ressourcen reduzieren, aber in einigen Fällen kann der Abgleich nicht erreicht werden, wie zum Beispiel: 🎜
🎜 Regulärer Text Ergebnis 🎜🎜Greedy-Modus🎜🎜a{1,3}ab🎜🎜aaab🎜🎜match🎜🎜 🎜Nicht-Greedy-Modus🎜🎜a{1,3}?ab🎜🎜aaab🎜🎜 match🎜🎜 🎜Exklusivmodus🎜🎜a{1,3}+ab🎜🎜aaab🎜🎜passt nicht zusammen🎜🎜🎜🎜🎜a{1,3}+ab entspricht der aaab-Zeichenfolge, a{1,3 }+ ersetzt das vorherige Alle drei a werden verwendet und es erfolgt kein Backtracking🎜🎜🎜Gemeinsamer regulärer Abgleich🎜🎜
Operator Beschreibung Instanz 🎜 🎜 🎜🎜.🎜🎜 steht für ein beliebiges einzelnes Zeichen 🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜 🎜[ ]🎜🎜Zeichensatz, der einen Bereich für ein einzelnes Zeichen angibt🎜🎜 [abc]steht für a, b, c, [a-z] Stellt ein einzelnes Zeichen von a-z dar ein einzelnes Zeichen, das nicht a oder b oder c ist🎜 🎜🎜🎜🎜🎜🎜🎜🎜_🎜🎜Das vorherige Zeichen wird null oder unendlich oft erweitert 🎜🎜 abc_bedeutet ab, abc, abcc, abccc usw. 🎜🎜🎜🎜🎜🎜🎜🎜🎜`🎜🎜`🎜🎜Jeder der linken und rechten Ausdrücke 🎜🎜`abc🎜🎜def` bedeutet abc, def🎜🎜 🎜 $🎜🎜entspricht dem Ende der Zeichenfolge🎜🎜 abc$ code> bedeutet abc und am Ende einer Zeichenfolge 🎜🎜🎜🎜🎜🎜🎜🎜<tr>🎜( )🎜🎜 kann nur im Inneren verwendet werden Das Gruppierungs-Tag 🎜🎜<code>(abc)bedeutet abc, „(abc 🎜🎜def)“ bedeutet abc, def🎜🎜🎜🎜🎜🎜D🎜🎜non-number🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜d🎜🎜Zahl, entspricht 0- 9🎜 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜S🎜🎜sichtbar 🎜🎜🎜🎜🎜🎜🎜🎜 🎜 🎜s🎜🎜Leerzeichen (Leerzeichen, Zeilenumbrüche, Tabulatoren usw.) 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜W🎜🎜Nicht-Wort-Zeichen 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜 w 🎜🎜Wortzeichen usw. Preis: [a-z0-9A-Z_]🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜entspricht dem Anfang der Zeichenfolge🎜🎜 ^abcbedeutet abc und steht am Anfang einer Zeichenfolge 🎜🎜🎜🎜🎜🎜🎜🎜🎜{m,n}🎜🎜Erweitern Sie das vorherige Zeichen m zu n-mal🎜🎜 ab{1,2}cbedeutet abc, abbc🎜🎜🎜 🎜🎜🎜🎜🎜🎜{m}🎜🎜Erweitern Sie das vorherige Zeichen m-mal 🎜🎜 ab{2}cbedeutet abbc🎜🎜🎜🎜🎜🎜🎜🎜🎜{m ,}🎜🎜mindestens m-mal mit dem vorherigen Zeichen übereinstimmen 🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 🎜? 🎜🎜Das vorherige Zeichen wird 0-mal oder 1-mal erweitert🎜🎜 abc?bedeutet ab, abc🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜单元测试
概念:前端自动化测试领域的, 用来验证独立的代码片段能否正常工作
1、可以直接用 Node 中自带的 assert 模块做断言:如果当前程序的某种状态符合 assert 的期望此程序才能正常执行,否则直接退出应用。
function multiple(a, b) { let result = 0; for (let i = 0; i < b; ++i) result += a; return result; } const assert = require('assert'); assert.equal(multiple(1, 2), 3));2、常见单测工具:Jest,使用示例
const sum = require('./sum'); describe('sum function test', () => { it('sum(1, 2) === 3', () => { expect(sum(1, 2)).toBe(3); }); // 这里 test 和 it 没有明显区别,it 是指: it should xxx, test 是指 test xxx test('sum(1, 2) === 3', () => { expect(sum(1, 2)).toBe(3); }); })babel原理和用途
babel 用途
- 转义 esnext、typescript 到目标环境支持 js (高级语言到到低级语言叫编译,高级语言到高级语言叫转译)
- 代码转换(taro)
- 代码分析(模块分析、tree-shaking、linter 等)
bebel 如何转换的?
对源码字符串 parse 生成 AST,然后对 AST 进行增删改,然后输出目标代码字符串
转换过程
parse 阶段:首先使用
@babel/parser将源码转换成 ASTtransform 阶段:接着使用
@babel/traverse遍历 AST,并调用 visitor 函数修改 AST,修改过程中通过@babel/types来创建、判断 AST 节点;使用@babel/template来批量创建 ASTgenerate 阶段:使用
@babel/generate将 AST 打印为目标代码字符串,期间遇到代码错误位置时会用到@babel/code-frame
好的,以上就是我对三年前端经验通过面试题做的一个总结了,祝大家早日找到心仪的工作~
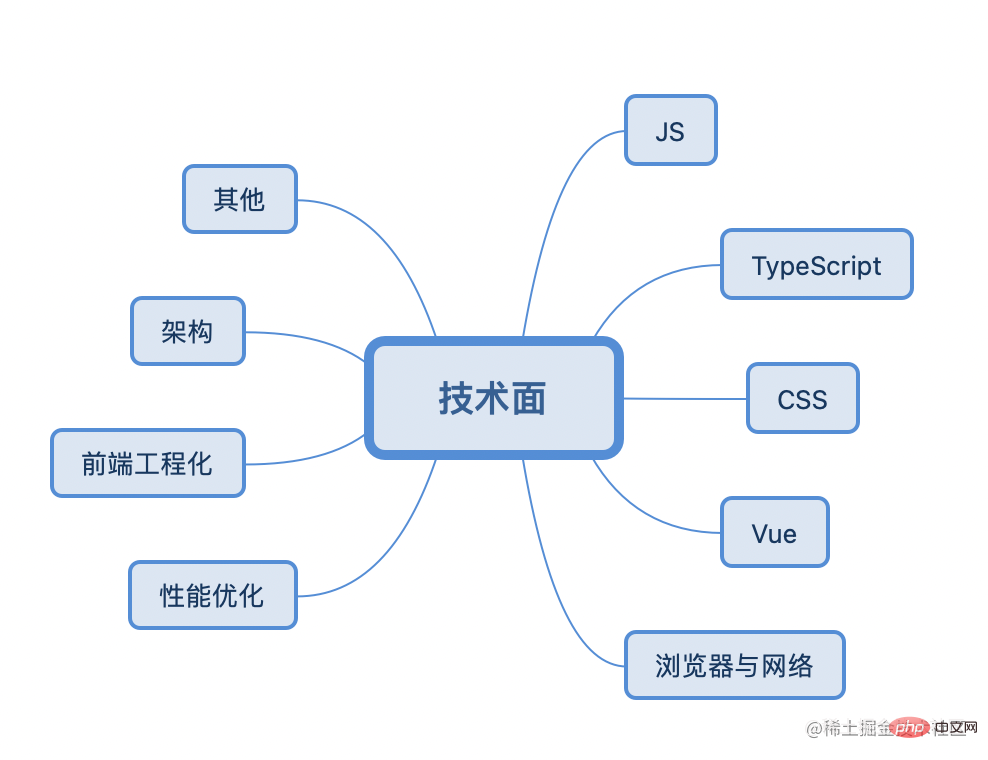
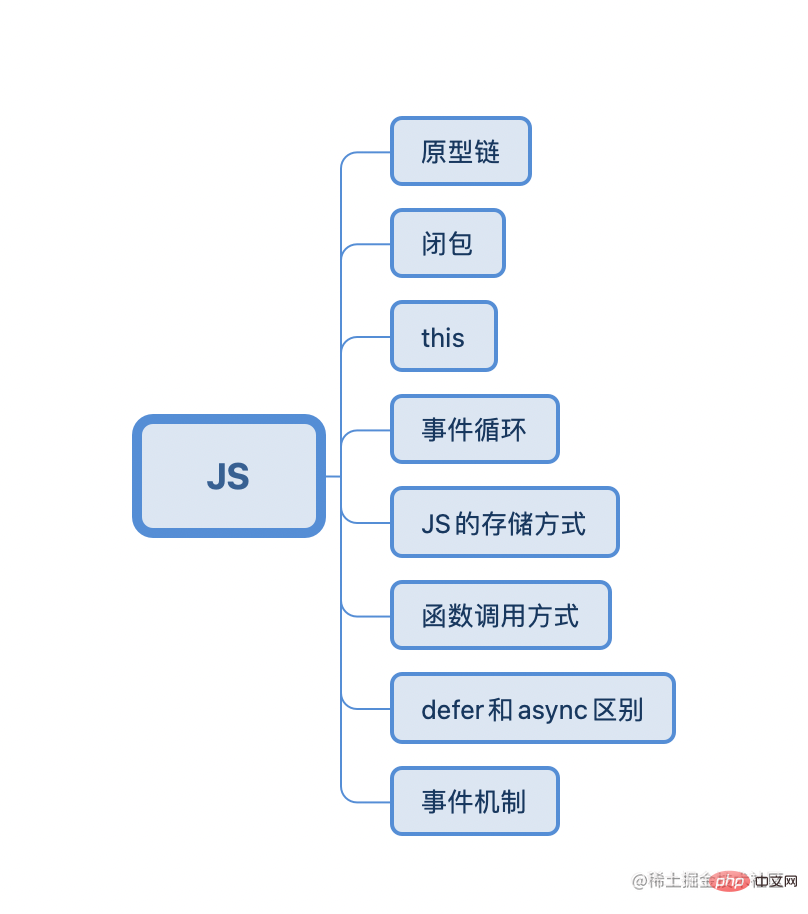
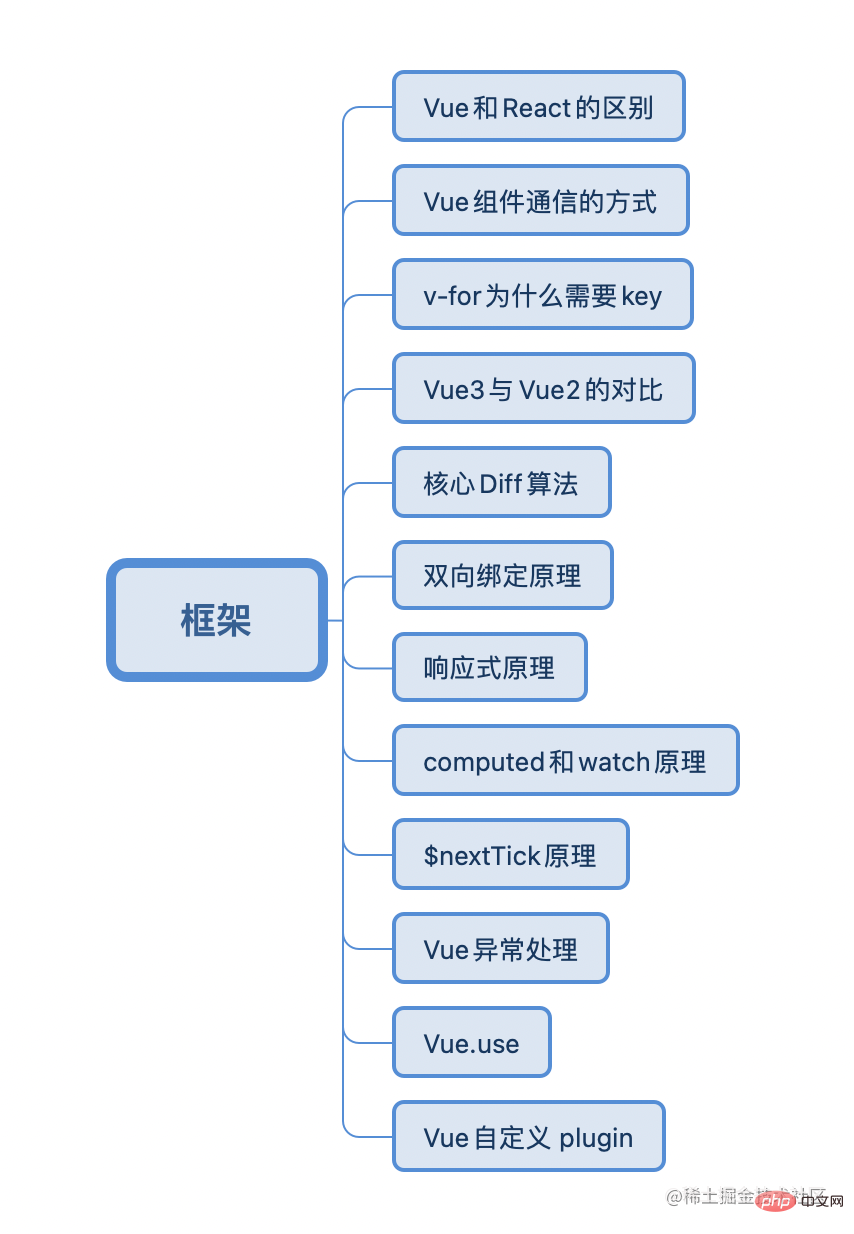
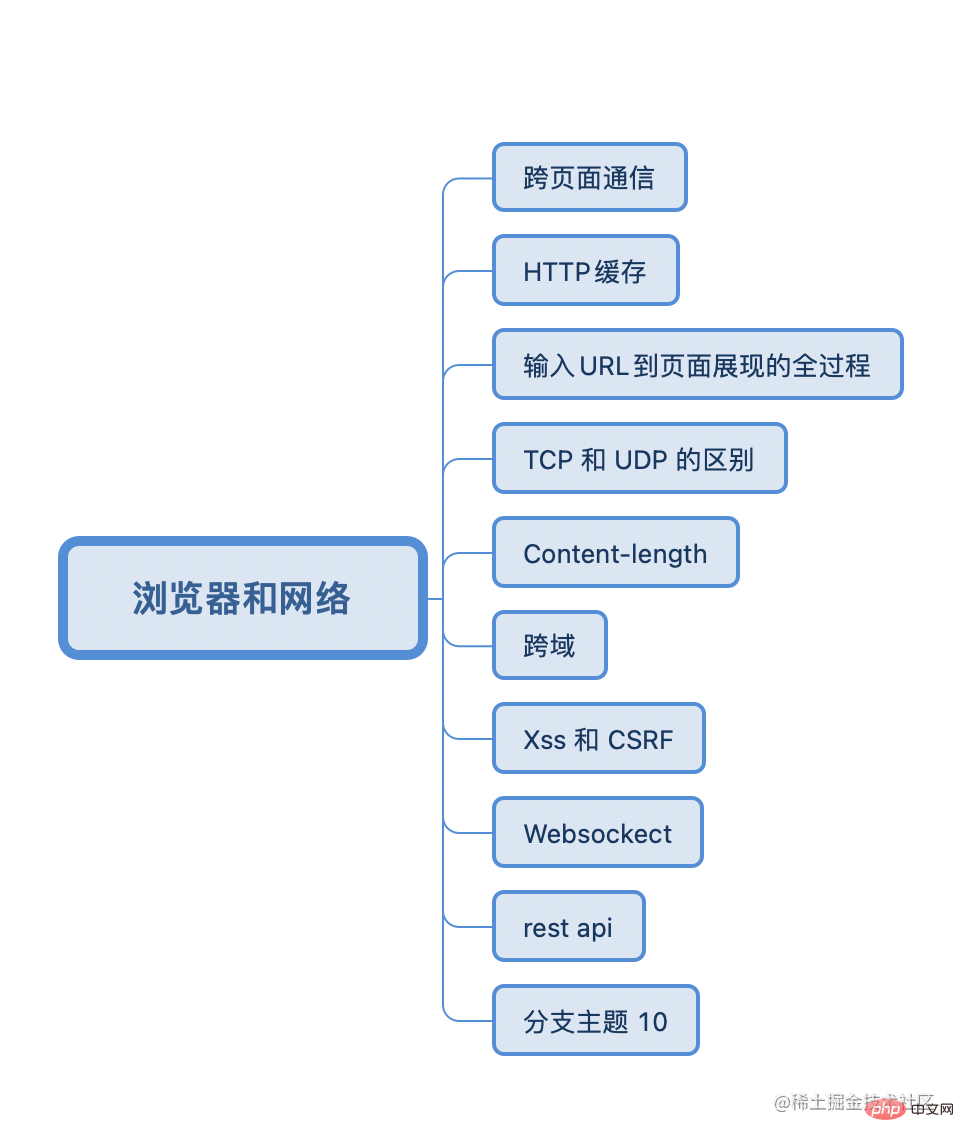
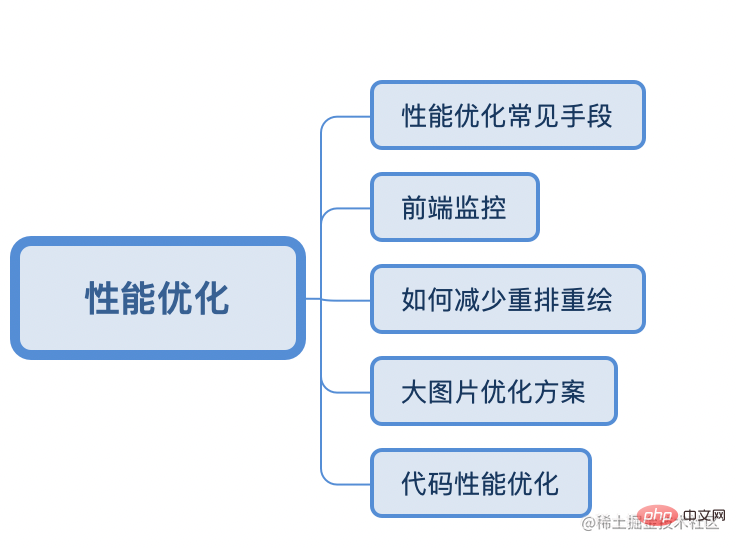
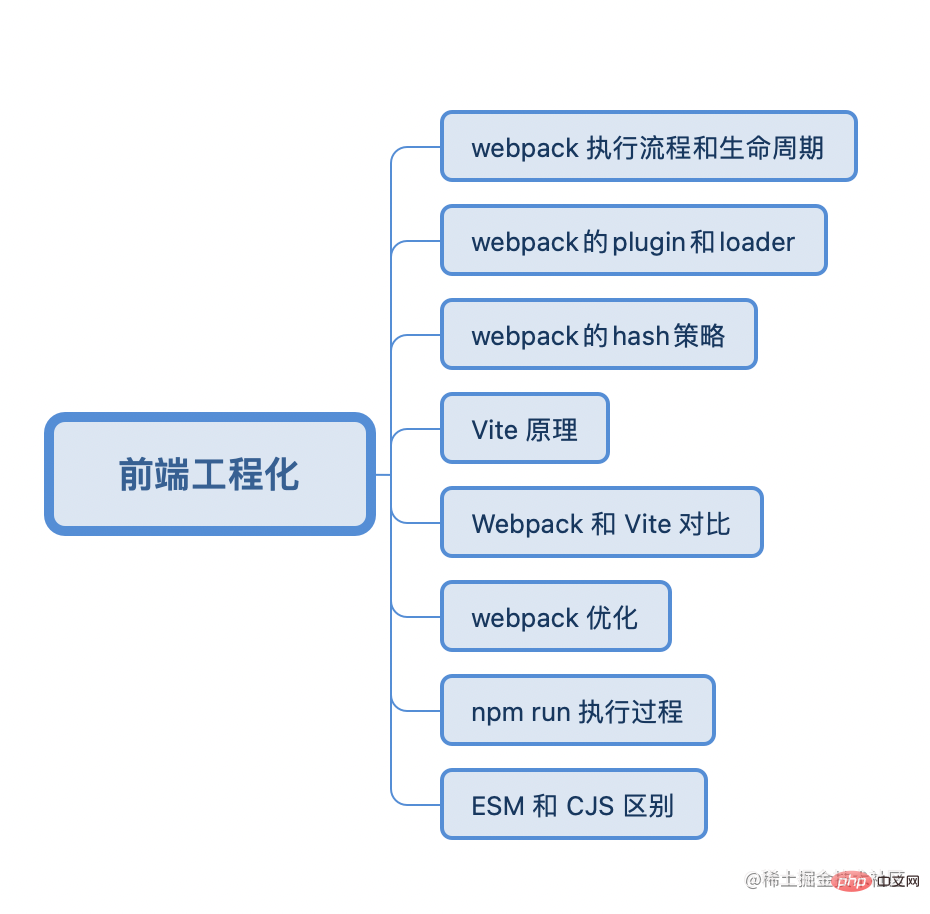
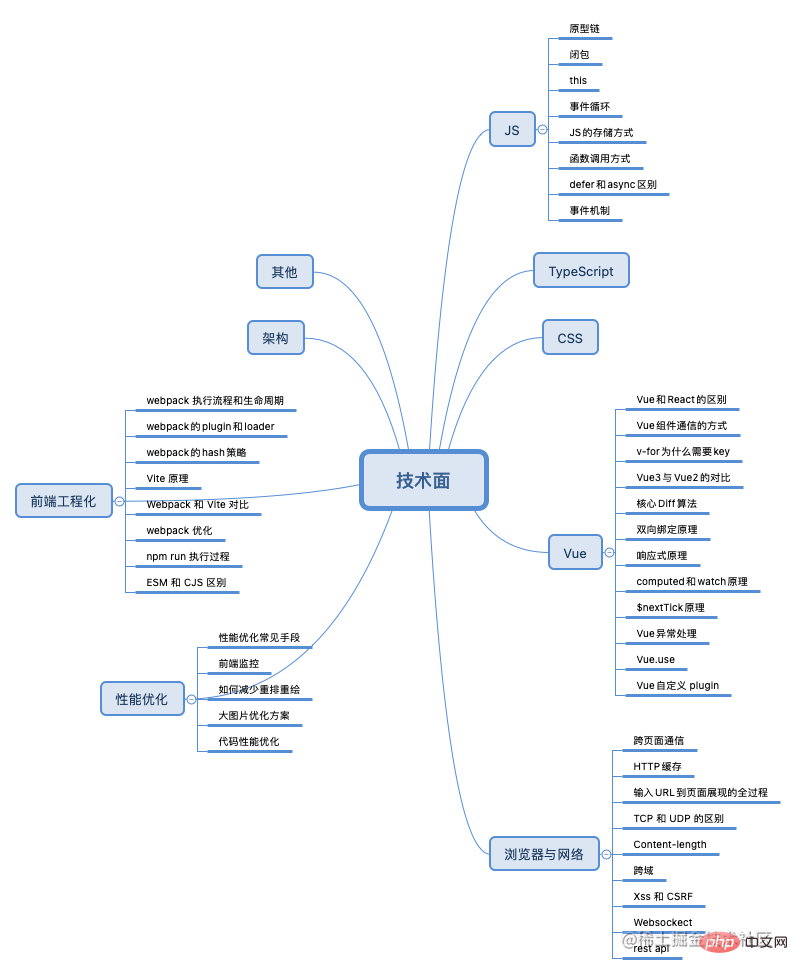
In Verbindung stehende Artikel
Mehr sehen- Fassen Sie einige häufig gestellte Front-End-Interviewfragen (mit Antworten) zusammen, um Ihr Wissen zu festigen!
- Teilen von hochfrequenten Vue-Interviewfragen im Jahr 2023 (mit Antwortanalyse)
- Schauen Sie sich diese 3 Fragen an, die Sie im Vorstellungsgespräch unbedingt stellen müssen, um Ihre Vue-Kenntnisse zu testen!
- [Front-End-Grundlagen] 16 praktische Tools/Website-Sharing
- [Zusammenstellung und Zusammenfassung] 20 hochfrequente Vue-Interviewfragen
- [Fortgeschrittene Fähigkeiten] Neun Front-End-Interviewfragen, die Ihnen helfen, Ihr Wissen zu festigen!
- [Zusammenstellung und Weitergabe] 75 Hochfrequenztestpunkte in CSS für Front-End-Interviews