
Heim >Web-Frontend >Front-End-Fragen und Antworten >Tool-Sharing: Realisierung einer automatisierten Verwaltung vergrabener Front-End-Punkte
Tool-Sharing: Realisierung einer automatisierten Verwaltung vergrabener Front-End-Punkte

- 青灯夜游nach vorne
- 2022-12-07 16:14:382333Durchsuche

Punktverfolgung war schon immer ein wichtiger Teil des H5-Projekts, und Punktverfolgungsdaten sind eine wichtige Grundlage für spätere Geschäftsverbesserungen und technische Optimierungen. [Empfohlenes Lernen: Web-Frontend, Programmierlehre]
Bei der täglichen Arbeit fragen Studenten aus Produkt- oder Geschäftszweigen oft: „Was sind jetzt die verborgenen Punkte in diesem Projekt?“, „Was sind die verborgenen Punkte?“ Dieses Projekt?“ Wo? „Bei Fragen wie dieser wird der Code im Grunde nur einmal abgefragt und überprüft, was sehr ineffizient ist.

Dies könnte etwas mit der Beschaffenheit der vergrabenen Stelle selbst zu tun haben. Vergrabene Punkte sind relativ unabhängige Funktionen. Im Laufe der Iterationen ist es für Entwickler schwierig, sich an den Zweck vergrabener Punkte zu erinnern. Zum Zweck des Selbsttests und der Verifizierung müssen Entwickler auch die versteckten Daten im Projekt aussortieren. Daher kann in Kombination mit dem aktuellen Szenario ein Tool implementiert werden: durch Scannen des Codes, Analysieren des Codes in Bezug auf vergrabene Punkte, Verarbeiten und Konvertieren in spezifische Daten für die spätere Verwendung in anderen Verwaltungsplattformen.
Implementierungsidee
Dieses Tool kann grob in drei Teile unterteilt werden: JSDoc-Extraktion vergrabener Punkte, Routing-Abhängigkeitsanalyse und ESLint-Plug-in.
- JSDoc ist ein Tool zum Generieren von API-Dokumentation basierend auf Annotationsinformationen in JavaScript. In Kombination mit dieser Funktion von JSDoc verwendet dieses Tracking-Tool JSDoc als Kernbestandteil, um die Tracking-Daten im Code auszugeben.
- Das Webpack-Plug-in dient als Hilfsmittel zur Bereitstellung von Routing-Informationen für JSDoc.
- Das ESLint-Plug-in wird als letzte Prüfung verwendet, um sicherzustellen, dass der vergrabene Code in der Datei entsprechende JSDoc-Kommentare enthält.
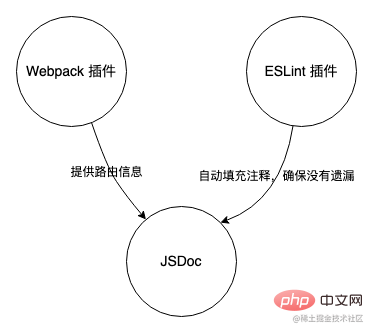
Benutzerdefinierte JSDoc-Markup-Punkte
Wir wissen, dass JSDoc ein Dokument basierend auf Kommentaren im Code ausgeben kann. Zuerst passen wir ein JSDoc-Tag an, um es als versteckten Kommentar zu markieren, sodass die Interferenz anderer Kommentare bei der nachfolgenden Verarbeitung herausgefiltert werden kann. Durch die Kombination des in bestimmten Projekten verwendeten Codes kann ein Flussdiagramm wie dieses erstellt werden:

Das Folgende ist der spezifische Code-Implementierungsprozess.
Schreiben Sie ein JSDoc-Plug-in und passen Sie ein Tag an:
// jsdoc.plugin.js
// 自定义一个 @log,含有 @log 才是埋点的注释
exports.defineTags = function (dictionary) {
dictionary.defineTag('log', {
canHaveName: true,
onTagged: function (doclet, tag) {
doclet.meta.log = tag.text;
},
});
};Parsen Sie .ts- und .vue-Dateien.
// jsdoc.plugin.js
exports.handlers = {
beforeParse: function (e) {
// 对文件预处理
if (/.vue/.test(e.filename)) {
// 解析 vue 文件
const component = compiler.parseComponent(e.source);
// 获取 vue 文件的 script 代码
const ast = parse.parse(component.script.content, {
// ...
});
}
if (/.ts/.test(e.filename)) {
// ts 转 js
}
},
};Angepasste JSDoc-Vorlage.
// publish.js
exports.publish = function (taffyData, opts, tutorials) {
// ...
data().each(function (doclet) {
// 有 log 这个 tag 的才是埋点注释
if (doclet.meta && doclet.meta.log) {
doclet.tags?.forEach((item) => {
// 获取对应的路由地址
});
// 拿到埋点数据
logData.push({});
}
});
// 输出 md 文档
fs.writeFileSync(outpath, mdContent, 'utf8');
};An diesem Punkt können alle versteckten Punkte im Code vollständig ausgegeben werden. Werfen wir nun einen Blick auf die aktuellen Funktionen dieses Tools:
- Informationen zu vergrabenen Punkten automatisch extrahieren und Dokumente zu vergrabenen Punkten generieren: ✅
- Automatisch benutzerdefinierte Tags (@log) zu Kommentaren zu vergrabenen Punkten hinzufügen: ❌
- Automatisch Kommentare zu vergrabenen Punkten hinzufügen Gemeldete Informationen zu vergrabenen Punkten hinzufügen: ❌
- Routeninformationen automatisch zu Kommentaren zu vergrabenen Punkten hinzufügen: ❌
- Beschreibungsinformationen zu vergrabenen Punkten automatisch zu Kommentaren zu vergrabenen Punkten hinzufügen: ❌
- Unkommentierte Codes zu vergrabenen Punkten automatisch anzeigen: ❌
Bestanden Aus der obigen Analyse können wir Folgendes erkennen:
- Sie müssen manuell Kommentare zu jedem vergrabenen Punkt hinzufügen
- Sie müssen die Route für jeden vergrabenen Punkt manuell überprüfen
- Was passiert, wenn Sie vergessen, Kommentare zu den vergrabenen Punkten hinzuzufügen? ?
Die ursprüngliche Absicht dieses Tools besteht darin, sich wiederholende und mühsame Arbeit zu ersparen. Wenn dadurch ein weiterer Arbeitsaufwand für die automatische Eingabe eines Dokuments aus dem Code entsteht, ist der Verlust mehr als wert. Durch die Analyse dieser Probleme können die folgenden Lösungen gefunden werden:
- Sie müssen Kommentare zu jedem vergrabenen Punkt manuell hinzufügen um jeden manuell zu überprüfen Die Route, die jedem vergrabenen Punkt entspricht -> Automatisch die Route finden, die der Komponente entspricht -> Webpack-Abhängigkeitsanalyse
- Was soll ich tun, wenn ich vergesse, den versteckten Punkt zu kommentieren? -> Es wird eine Erinnerung angezeigt, wenn Sie vergessen, einen Kommentar zu schreiben -> ESLint-Plugin
- An diesem Punkt ist die Lösung des Problems klar. Schauen wir uns als Nächstes den Implementierungsprozess des Webpack-Plug-Ins und des ESLint-Plug-Ins an.
Webpack selbst verfügt über eine
Abhängigkeitsanalyse, und Sie können problemlos die Eltern-Kind-Beziehung zwischen Komponenten ermitteln. compiler.hooks.normalModuleFactory.tap('routeAnalysePlugin', (nmf) => {
nmf.hooks.afterResolve.tapAsync('routeAnalysePlugin', (result, callback) => {
const { resourceResolveData } = result;
// 子组件
const path = resourceResolveData.path;
// 父组件
const fatherPath = resourceResolveData.context.issuer;
// 只获取 vue 文件的依赖关系
if (/.vue/.test(path) && /.vue/.test(fatherPath)) {
// 将组件间的父子关系存到变量中
}
});
});Übertragen Sie die Abhängigkeiten zwischen Komponenten in das gewünschte Datenformat
[
{
"path": "src/views/register-v2/index.vue",
"deps": [
{
"path": "src/components/landing-banner/index.vue",
"deps": []
}
]
}
// ...
]组件之间的依赖关系有了,接下来就是找到组件和路由的对应关系,这里我们用 AST 来解析路由文件,获取路由和组件的对应关系。
// 遍历路由文件
for (let i = 0; i < this.routePaths.length; i++) {
// ...
traverse(ast, {
enter(path) {
// 找出组件和路由的对应关系
path.node.properties.forEach((item) => {
// 组件
if (item.key.name === 'component') {
}
// 路由地址
if (item.key.name === 'path') {
}
});
},
});
}同样地,把组件与路由的映射关系拼成合适的数据格式。
{
"src/views/register-v3/index.vue": "/register"
// ...
}再将路由的映射关系和组件间的依赖关系整合到一起,得出每个组件与路由的对应关系。
{
"src/components/landing-banner/index.vue": [
"/register_v2",
"/register"
//...
]
// ...
}因为使用 AST 遍历的方式来解析路由文件,目前支持的解析的路由文件写法有以下四种,基本上满足了当前的场景:
const page1 = (resolve) => {
require.ensure(
[],
() => {
resolve(require('page1.vue'));
},
'page1',
);
};
const page2 = () =>
import(
/* webpackChunkName: "page2" */
'page2.vue'
);
export default [
{ path: '/page1', component: page1 },
{ path: '/page2', component: page2 },
{
path: '/page3',
component: (resolve) => {
require.ensure(
[],
() => {
resolve(require('page3.vue'));
},
'page3',
);
},
},
{
path: '/page4',
component: () =>
import(
/* webpackChunkName: "page4" */
'page4.vue'
),
},
];
再得到了上面的对应关系之后,可以把埋点数据放到传到埋点管理平台上,从而实现一键查询:
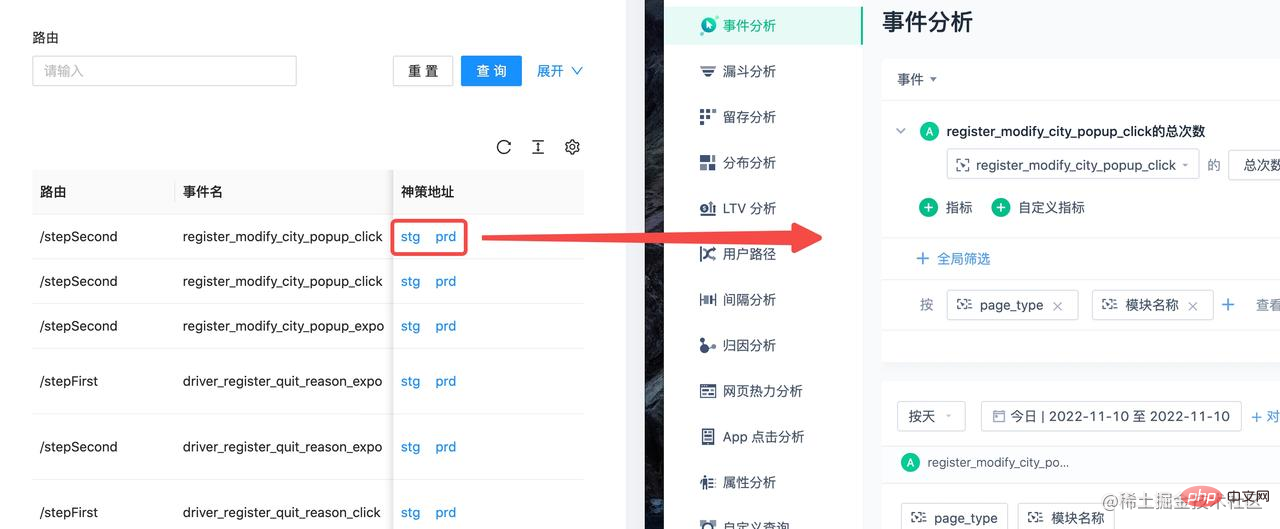
编写 ESLint 插件
先来看看代码中埋点上报的三种方式:
// 神策 sdk
sensors.track('xxx', {});
// 挂载到 Vue 实例中
this.$sa.track('xxx', {});
// 装饰器
@SensorTrack('xxx', {})观察上面三种方式,可以知道埋点上报是通过 track 函数和 SensorTrack 函数,所以我们的 ESLint 插件对这两个函数进行校验。
function create(context) {
// 调用 track 函数的对象
const checkList = ['sensor', 'sensors', '$sa', 'sa'];
return {
Literal: function (node) {
// ...
// 调用埋点函数而缺少注释时
if (
isNoComment &&
((isTrack && isSensor) || (is$Track && isThisExpression))
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
// 使用修饰器但没有注释时
if (
callee.name === 'SensorTrack' &&
sourceCode.getCommentsBefore(node).length === 0
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
},
};
}看下完成后的效果:
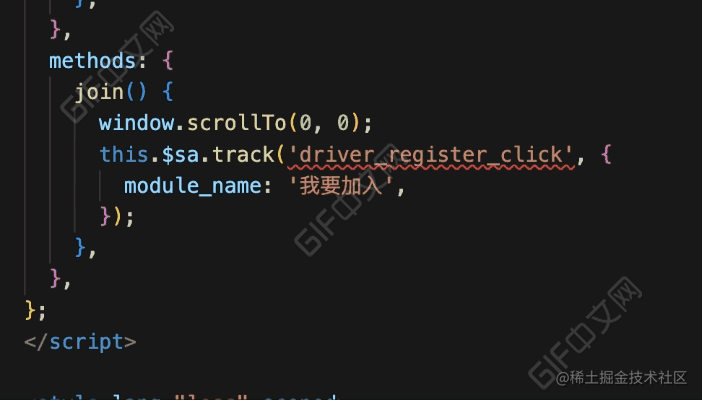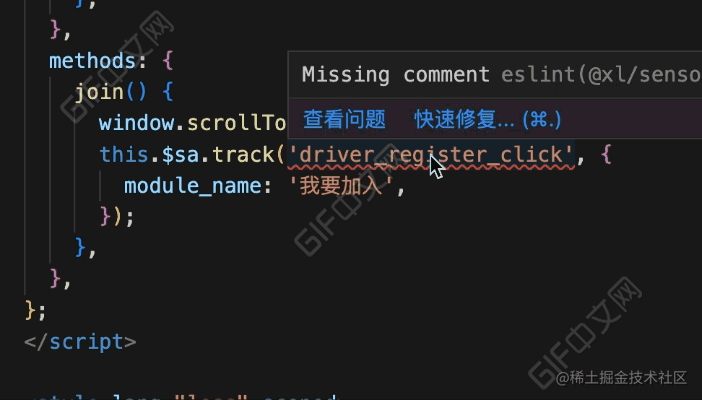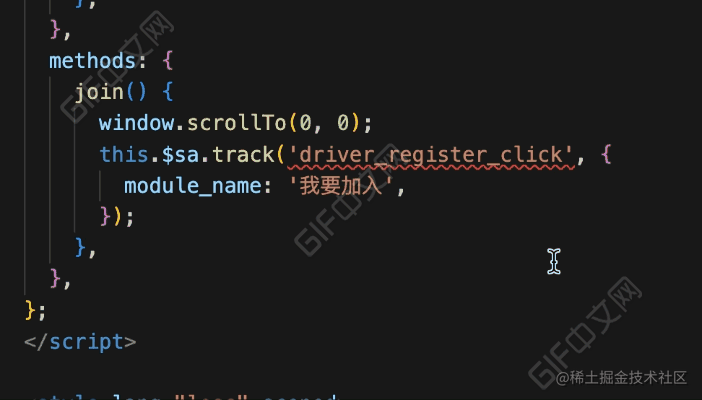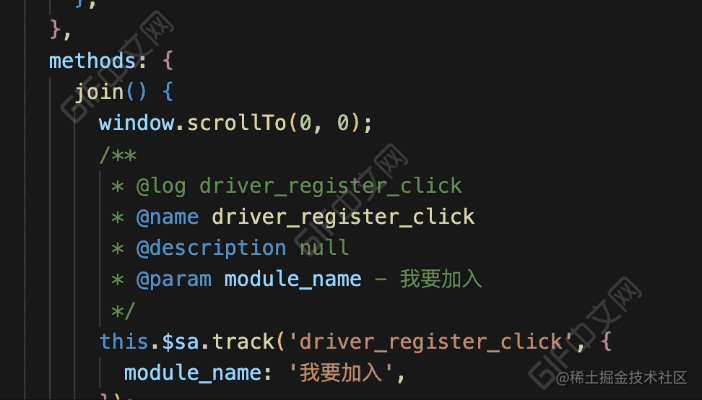
效果对比
我们再来对比下优化前后的区别:
| 优化前 | 优化后 | |
|---|---|---|
| 自动提取埋点信息,生成埋点文档 | ✅ | ✅ |
| 自动给埋点注释添加自定义 tag(@log) | ❌ | ✅ |
| 自动给埋点注释添加上报的埋点信息 | ❌ | ✅ |
| 自动给埋点注释添加路由信息 | ❌ | ✅ |
| 自动给埋点注释添加埋点描述信息 | ❌ | ❌ |
| 自动提示没有注释的埋点代码 | ❌ | ✅ |
优化之后除了整个流程基本都由工具自动完成,剩下一个埋点描述信息。因为埋点的描述信息只是为了让我们更好地理解这个埋点,本身并不在上报的代码中,所以工具没有办法自动生成,但是我们可以直接在产品提供的埋点文档中拷贝过来完成这一步。
总结
在项目中接入这个工具之后,可以快速地知道项目的埋点有哪些以及各个埋点所在的页面,也方便我们对埋点的梳理,同时利用导出的埋点数据开发后台应用,有效地提升了开发者效率。
这个工具的实现是在 JSDoc、webpack 和 ESLint 插件的加持下水到渠成的,说是水到渠成是因为一开始的想法只是做到第一步,先有个一键查询功能和能够输出一份文档用着先。但是第一版出来后发现要手动去处理这些埋点注释还是比较繁琐,恰巧平常开发中常见的 webpack 插件和 ESLint 插件可以很好地解决这些问题,于是便有路由依赖分析和 ESLint 插件。像是《牧羊少年奇幻之旅》中所说的,“如果你下定决心要做一件事情,整个宇宙都会合力帮助你。”
Das obige ist der detaillierte Inhalt vonTool-Sharing: Realisierung einer automatisierten Verwaltung vergrabener Front-End-Punkte. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Teilen Sie zwei Vue-Frontend-Bibliotheken, die Flowable-Flussdiagramme zeichnen können
- [Fortgeschrittene Fähigkeiten] Neun Front-End-Interviewfragen, die Ihnen helfen, Ihr Wissen zu festigen!
- [Zusammenstellung und Weitergabe] 75 Hochfrequenztestpunkte in CSS für Front-End-Interviews
- Lassen Sie uns ausführlich über die Idee des Frontends sprechen, Benutzer-Screenshots einzuschränken
- Web3.0 kommt! Ist es Frontend-freundlich?