
Heim >Backend-Entwicklung >Golang >Lassen Sie uns über Golangs eigenen HttpClient-Timeout-Mechanismus sprechen
Lassen Sie uns über Golangs eigenen HttpClient-Timeout-Mechanismus sprechen

- 青灯夜游nach vorne
- 2022-11-18 20:25:452476Durchsuche
Während ich Go schreibe, bin ich oft auf viele Fallstricke gestoßen und habe viele interessante Stellen gefunden. Ich werde über den Timeout-Mechanismus von HttpClient sprechen, der mit Go einhergeht Es wird für alle hilfreich sein.

Das zugrunde liegende Prinzip des Java HttpClient-Timeouts
Bevor wir den HttpClient-Timeout-Mechanismus von Go vorstellen, werfen wir zunächst einen Blick darauf, wie Java Timeout implementiert. [Verwandte Empfehlungen: Go-Video-Tutorial]
Schreiben Sie einen Java-nativen HttpClient, legen Sie das Verbindungszeitlimit und das Lesezeitlimit entsprechend den zugrunde liegenden Methoden fest:
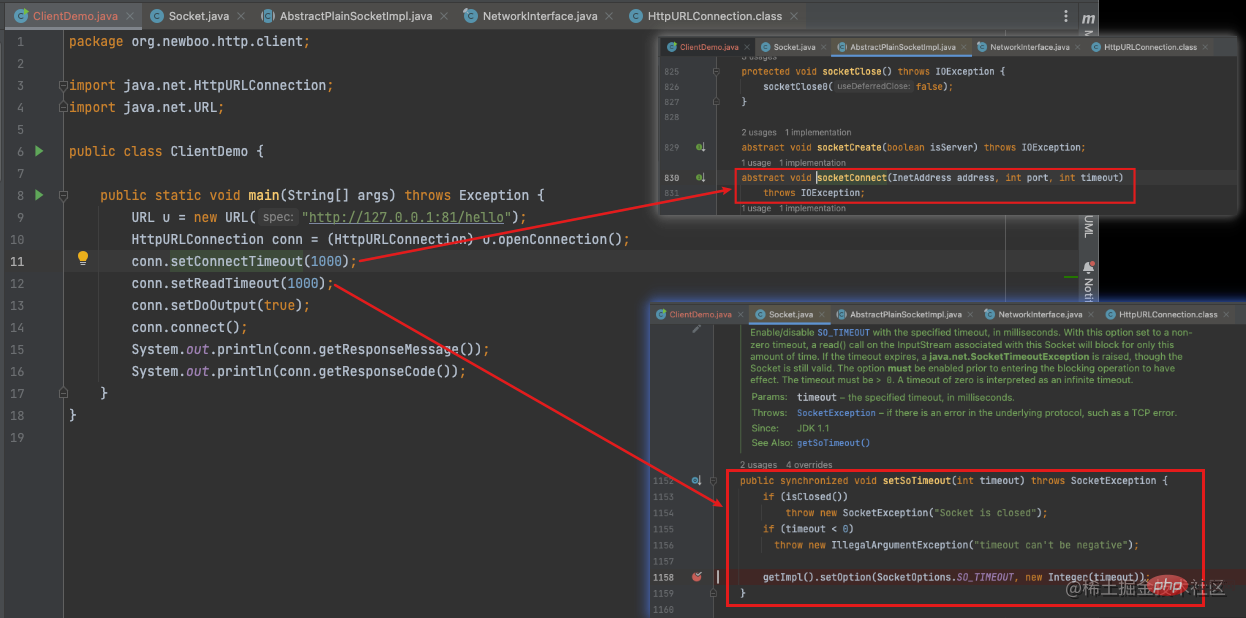
Zurück zum JVM-Quellcode: Ich habe festgestellt, dass er korrekt ist Die Kapselung von Systemaufrufen ist eigentlich nicht nur Java, sondern die meisten Programmiersprachen nutzen die vom Betriebssystem bereitgestellten Timeout-Funktionen.
Der HttpClient von Go bietet jedoch einen weiteren Timeout-Mechanismus, der sehr interessant ist. Aber bevor wir beginnen, wollen wir zunächst den Kontext von Go verstehen.
Einführung in Go Context
Was ist Kontext?
Laut den Kommentaren des Go-Quellcodes:
// Ein Kontext trägt eine Frist, ein Stornierungssignal und andere Werte // API-Grenzen. // Die Methoden von Context können von mehreren Goroutinen gleichzeitig aufgerufen werden.
Context ist einfach eine Schnittstelle, die Zeitüberschreitungen, Abbruchsignale und andere Daten übertragen kann.
Context ähnelt in gewisser Weise dem ThreadLocal von Java, ist jedoch nicht genau das Gleiche. Es handelt sich um eine implizite Übertragung, bei der es auch zu Zeitüberschreitungen kommen kann und Löschsignale.
Context definiert nur die Schnittstelle, und in Go werden mehrere spezifische Implementierungen bereitgestellt:
- Hintergrund: Leere Implementierung, bewirkt nichts
- TODO: Ich weiß noch nicht, welchen Kontext ich verwenden soll, also verwende stattdessen TODO cancelCtx: Stornierbarer Kontext
- timerCtx: Aktiver Timeout-Kontext
Context Drei Funktionsbeispiele
Dieser Teil des Beispiels stammt aus dem Quellcode von Go, der sich insrc/context/example_test.go
src/context/example_test.go携带数据
使用 context.WithValue 来携带,使用 Value 来取值,源码中的例子如下:
// 来自 src/context/example_test.go
func ExampleWithValue() {
type favContextKey string
f := func(ctx context.Context, k favContextKey) {
if v := ctx.Value(k); v != nil {
fmt.Println("found value:", v)
return
}
fmt.Println("key not found:", k)
}
k := favContextKey("language")
ctx := context.WithValue(context.Background(), k, "Go")
f(ctx, k)
f(ctx, favContextKey("color"))
// Output:
// found value: Go
// key not found: color
}取消
先起一个协程执行一个死循环,不停地往 channel 中写数据,同时监听 ctx.Done() 的事件
// 来自 src/context/example_test.go
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
}然后通过 context.WithCancel 生成一个可取消的 Context,传入 gen 方法,直到 gen 返回 5 时,调用 cancel 取消 gen 方法的执行。
// 来自 src/context/example_test.go
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // cancel when we are finished consuming integers
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
break
}
}
// Output:
// 1
// 2
// 3
// 4
// 5这么看起来,可以简单理解为在一个协程的循环中埋入结束标志,另一个协程去设置这个结束标志。
超时
有了 cancel 的铺垫,超时就好理解了,cancel 是手动取消,超时是自动取消,只要起一个定时的协程,到时间后执行 cancel 即可。
设置超时时间有2种方式:context.WithTimeout 与 context.WithDeadline,WithTimeout 是设置一段时间后,WithDeadline 是设置一个截止时间点,WithTimeout 最终也会转换为 WithDeadline。
// 来自 src/context/example_test.go
func ExampleWithTimeout() {
// Pass a context with a timeout to tell a blocking function that it
// should abandon its work after the timeout elapses.
ctx, cancel := context.WithTimeout(context.Background(), shortDuration)
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err()) // prints "context deadline exceeded"
}
// Output:
// context deadline exceeded
}Go HttpClient 的另一种超时机制
基于 Context 可以设置任意代码段执行的超时机制,就可以设计一种脱离操作系统能力的请求超时能力。
超时机制简介
看一下 Go 的 HttpClient 超时配置说明:
client := http.Client{
Timeout: 10 * time.Second,
}
// 来自 src/net/http/client.go
type Client struct {
// ... 省略其他字段
// Timeout specifies a time limit for requests made by this
// Client. The timeout includes connection time, any
// redirects, and reading the response body. The timer remains
// running after Get, Head, Post, or Do return and will
// interrupt reading of the Response.Body.
//
// A Timeout of zero means no timeout.
//
// The Client cancels requests to the underlying Transport
// as if the Request's Context ended.
//
// For compatibility, the Client will also use the deprecated
// CancelRequest method on Transport if found. New
// RoundTripper implementations should use the Request's Context
// for cancellation instead of implementing CancelRequest.
Timeout time.Duration
}翻译一下注释:TimeoutDaten übertragen
Verwenden Sie context.WithValue, um sie zu übertragen, und verwenden Sie Value, um den Wert abzurufen. Das Beispiel im Quellcode lautet wie folgt folgt: client := http.Client{
Timeout: 10 * time.Minute,
}
resp, err := client.Get("http://127.0.0.1:81/hello")Abbrechen
Starten Sie zunächst eine Coroutine, um eine Endlosschleife auszuführen, kontinuierlich Daten in den Kanal zu schreiben und gleichzeitig zuzuhören Ereignis von ctx.Done()
// 来自 src/net/http/client.go deadline = c.deadline()
Dann generieren Sie einen abbrechbaren Kontext durch context.WithCancel, übergeben Sie die Methode gen, bis gen gibt 5 zurück, rufen Sie cancel auf. Bricht die Ausführung der gen-Methode ab. // 来自 src/net/http/client.go
stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
Es scheint, dass es einfach so verstanden werden kann, dass das Endflag in der Schleife einer Coroutine vergraben wird und eine andere Coroutine das Endflag setzt. Timeout
Mit der Vorahnung von Abbrechen ist Timeout eine manuelle Stornierung und Timeout eine automatische Stornierung gestartet wird, führen Sie nach Ablauf der Zeit einfach „cancel“ aus.
🎜Es gibt zwei Möglichkeiten, das Timeout festzulegen:context.WithTimeout und context.WithDeadline wird nach einem bestimmten Zeitraum festgelegt, WithDeadline wird auf einen Deadline-Zeitpunkt gesetzt Und WithTimeout wird schließlich in WithDeadline konvertiert. 🎜// 来自 src/net/http/client.go
var cancelCtx func()
if oldCtx := req.Context(); timeBeforeContextDeadline(deadline, oldCtx) {
req.ctx, cancelCtx = context.WithDeadline(oldCtx, deadline)
}🎜🎜Ein weiterer Timeout-Mechanismus von Go HttpClient🎜🎜🎜Basierend auf dem Kontext können Sie den Timeout-Mechanismus für die Ausführung eines beliebigen Codesegments festlegen und eine Anforderungs-Timeout-Funktion entwerfen, die unabhängig von den Funktionen des Betriebssystems ist. 🎜🎜🎜🎜Einführung in den Timeout-Mechanismus🎜🎜🎜🎜Sehen Sie sich die Konfigurationsanweisungen für das HttpClient-Timeout an:🎜// 来自 src/net/http/client.go
timer := time.NewTimer(time.Until(deadline))
var timedOut atomicBool
go func() {
select {
case <-initialReqCancel:
doCancel()
timer.Stop()
case <-timer.C:
timedOut.setTrue()
doCancel()
case <-stopTimerCh:
timer.Stop()
}
}()🎜Übersetzen Sie die Kommentare: Timeout umfasst die Zeit für Verbindung, Umleitung und Datenlesen unterbricht das Lesen der Daten nach Ablauf der Timeout-Zeit. Bei der Einstellung 0 gibt es keine Timeout-Grenze. 🎜🎜Das heißt, dieses Timeout ist das 🎜Gesamt-Timeout einer Anfrage🎜, ohne dass das Verbindungs-Timeout, das Lese-Timeout usw. separat festgelegt werden müssen. 🎜🎜Dies ist möglicherweise die bessere Wahl für Benutzer. In den meisten Szenarien müssen sich Benutzer nicht darum kümmern, welcher Teil die Zeitüberschreitung verursacht, sondern möchten nur wissen, wann die HTTP-Anfrage als Ganzes zurückgegeben werden kann. 🎜🎜🎜🎜Das Grundprinzip des Timeout-Mechanismus🎜🎜🎜🎜Veranschaulichen Sie anhand des einfachsten Beispiels das Grundprinzip des Timeout-Mechanismus. 🎜这里我起了一个本地服务,用 Go HttpClient 去请求,超时时间设置为 10 分钟,建议使 Debug 时设置长一点,否则可能超时导致无法走完全流程。
client := http.Client{
Timeout: 10 * time.Minute,
}
resp, err := client.Get("http://127.0.0.1:81/hello")1. 根据 timeout 计算出超时的时间点
// 来自 src/net/http/client.go deadline = c.deadline()
2. 设置请求的 cancel
// 来自 src/net/http/client.go stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
这里返回的 stopTimer 就是可以手动 cancel 的方法,didTimeout 是判断是否超时的方法。这两个可以理解为回调方法,调用 stopTimer() 可以手动 cancel,调用 didTimeout() 可以返回是否超时。
设置的主要代码其实就是将请求的 Context 替换为 cancelCtx,后续所有的操作都将携带这个 cancelCtx:
// 来自 src/net/http/client.go
var cancelCtx func()
if oldCtx := req.Context(); timeBeforeContextDeadline(deadline, oldCtx) {
req.ctx, cancelCtx = context.WithDeadline(oldCtx, deadline)
}同时,再起一个定时器,当超时时间到了之后,将 timedOut 设置为 true,再调用 doCancel(),doCancel() 是调用真正 RoundTripper (代表一个 HTTP 请求事务)的 CancelRequest,也就是取消请求,这个跟实现有关。
// 来自 src/net/http/client.go
timer := time.NewTimer(time.Until(deadline))
var timedOut atomicBool
go func() {
select {
case <-initialReqCancel:
doCancel()
timer.Stop()
case <-timer.C:
timedOut.setTrue()
doCancel()
case <-stopTimerCh:
timer.Stop()
}
}()Go 默认 RoundTripper CancelRequest 实现是关闭这个连接
// 位于 src/net/http/transport.go
// CancelRequest cancels an in-flight request by closing its connection.
// CancelRequest should only be called after RoundTrip has returned.
func (t *Transport) CancelRequest(req *Request) {
t.cancelRequest(cancelKey{req}, errRequestCanceled)
}3. 获取连接
// 位于 src/net/http/transport.go
for {
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
// ...
pconn, err := t.getConn(treq, cm)
// ...
}代码的开头监听 ctx.Done,如果超时则直接返回,使用 for 循环主要是为了请求的重试。
后续的 getConn 是阻塞的,代码比较长,挑重点说,先看看有没有空闲连接,如果有则直接返回
// 位于 src/net/http/transport.go
// Queue for idle connection.
if delivered := t.queueForIdleConn(w); delivered {
// ...
return pc, nil
}如果没有空闲连接,起个协程去异步建立,建立成功再通知主协程
// 位于 src/net/http/transport.go // Queue for permission to dial. t.queueForDial(w)
再接着是一个 select 等待连接建立成功、超时或者主动取消,这就实现了在连接过程中的超时
// 位于 src/net/http/transport.go
// Wait for completion or cancellation.
select {
case <-w.ready:
// ...
return w.pc, w.err
case <-req.Cancel:
return nil, errRequestCanceledConn
case <-req.Context().Done():
return nil, req.Context().Err()
case err := <-cancelc:
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
}4. 读写数据
在上一条连接建立的时候,每个链接还偷偷起了两个协程,一个负责往连接中写入数据,另一个负责读数据,他们都监听了相应的 channel。
// 位于 src/net/http/transport.go go pconn.readLoop() go pconn.writeLoop()
其中 wirteLoop 监听来自主协程的数据,并往连接中写入
// 位于 src/net/http/transport.go
func (pc *persistConn) writeLoop() {
defer close(pc.writeLoopDone)
for {
select {
case wr := <-pc.writech:
startBytesWritten := pc.nwrite
err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
// ...
if err != nil {
pc.close(err)
return
}
case <-pc.closech:
return
}
}
}同理,readLoop 读取响应数据,并写回主协程。读与写的过程中如果超时了,连接将被关闭,报错退出。
超时机制小结
Go 的这种请求超时机制,可随时终止请求,可设置整个请求的超时时间。其实现主要依赖协程、channel、select 机制的配合。总结出套路是:
- 主协程生成 cancelCtx,传递给子协程,主协程与子协程之间用 channel 通信
- 主协程 select channel 和 cancelCtx.Done,子协程完成或取消则 return
- 循环任务:子协程起一个循环处理,每次循环开始都 select cancelCtx.Done,如果完成或取消则退出
- 阻塞任务:子协程 select 阻塞任务与 cancelCtx.Done,阻塞任务处理完或取消则退出
以循环任务为例
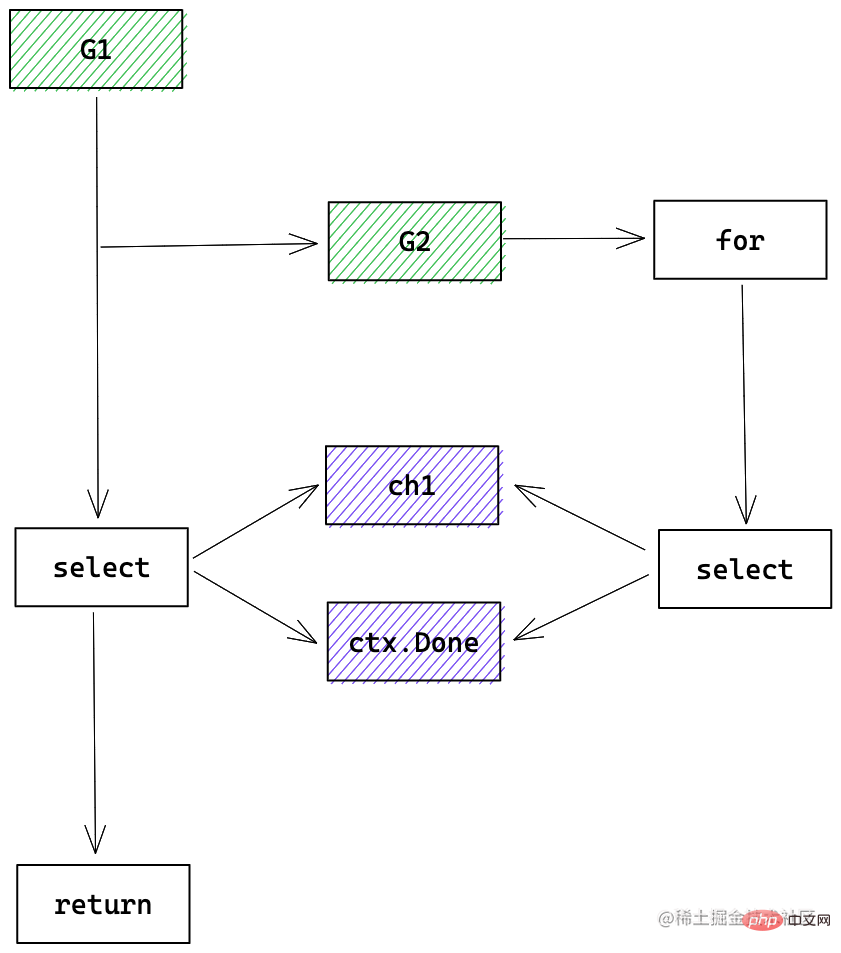
Java 能实现这种超时机制吗
直接说结论:暂时不行。
首先 Java 的线程太重,像 Go 这样一次请求开了这么多协程,换成线程性能会大打折扣。
其次 Go 的 channel 虽然和 Java 的阻塞队列类似,但 Go 的 select 是多路复用机制,Java 暂时无法实现,即无法监听多个队列是否有数据到达。所以综合来看 Java 暂时无法实现类似机制。
总结
本文介绍了 Go 另类且有趣的 HTTP 超时机制,并且分析了底层实现原理,归纳出了这种机制的套路,如果我们写 Go 代码,也可以如此模仿,让代码更 Go。
原文地址:https://juejin.cn/post/7166201276198289445
更多编程相关知识,请访问:编程视频!!
Das obige ist der detaillierte Inhalt vonLassen Sie uns über Golangs eigenen HttpClient-Timeout-Mechanismus sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine kurze Analyse der Implementierung der Aufzählung in Golang (mit Code)
- Informationen zu .gitignore-Dateien, die häufig in Golang-Projekten verwendet werden (Notizen)
- Eine detaillierte Erklärung der Bitoperationen in Golang
- Geboren für Geschwindigkeit: die Kombination aus PHP und Golang – RoadRunner
- Ein Artikel, der die init()-Funktion in Golang analysiert