
Heim >Datenbank >MySQL-Tutorial >Detaillierte Erläuterung gängiger Abfrageoptimierungsstrategien für MySql
Detaillierte Erläuterung gängiger Abfrageoptimierungsstrategien für MySql

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-11-17 16:24:252329Durchsuche
Dieser Artikel bringt Ihnen relevantes Wissen über MySQL, das hauptsächlich verwandte Themen zur allgemeinen Abfrageoptimierung vorstellt. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
Nachdem das Programm eine Zeit lang online ist und ausgeführt wird, werden Sie bei zunehmender Datenmenge mehr oder weniger Verzögerungen, Verzögerungen usw. im System spüren . Diese Art von Problem tritt auf, um Systemoptimierungsarbeiten durchzuführen. Eine große Menge praktischer Erfahrungen zeigt, dass der Inhalt der SQL-Optimierung immer noch ein sehr wichtiger Teil ist , fasst einige SQL-Optimierungsstrategien zusammen, die an der Arbeit beteiligt sein können.
Vorbereitung: Fügen Sie 100.000 Daten zu einer Testtabelle hinzu.Verwenden Sie die folgende gespeicherte Prozedur, um einen Datenstapel für eine einzelne Tabelle zu erstellen. Ersetzen Sie einfach die Tabelle durch Ihre eigene In diesem Artikel wurden 3 Tabellen vorbereitet, nämlich Schülertabelle, Klassentabelle und Kontotabelle mit jeweils 500.000, 10.000 und 100.000 Daten zum Testen Bei der Entwicklung kommt es vor, dass die Abfrage oft sehr zeitaufwändig ist, z. B. die folgende SQL-Abfrage, die 0,2 Sekunden dauert Die praktische Erfahrung zeigt, dass die Effizienz der Paging-Abfrage umso geringer ist, je weiter sie zurückliegt.
Denn wenn Sie bei der Durchführung einer Paging-Abfrage
begrenzen Sie 400000,10
Ich brauche MySQL
4000 vor dem Sortieren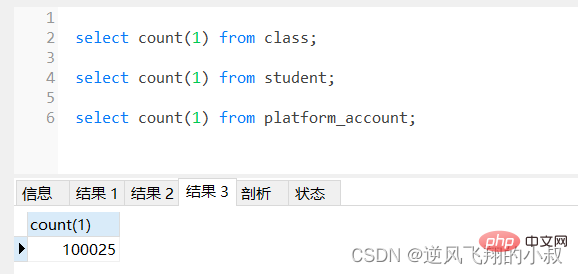
 Datensatz
Datensatz
Datensatz, nur 400000 - 4
00 werden 010 Datensätze zurückgegeben, andere. Die Kosten für das Verwerfen von Datensätzen und das Sortieren von Abfragen sind sehr hoch

Optimierungsideen: Bei allgemeinen Paging-Abfragen kann die Leistung durch die Erstellung eines Covering-Index und der Unterabfrageform zur Optimierung verbessert werden
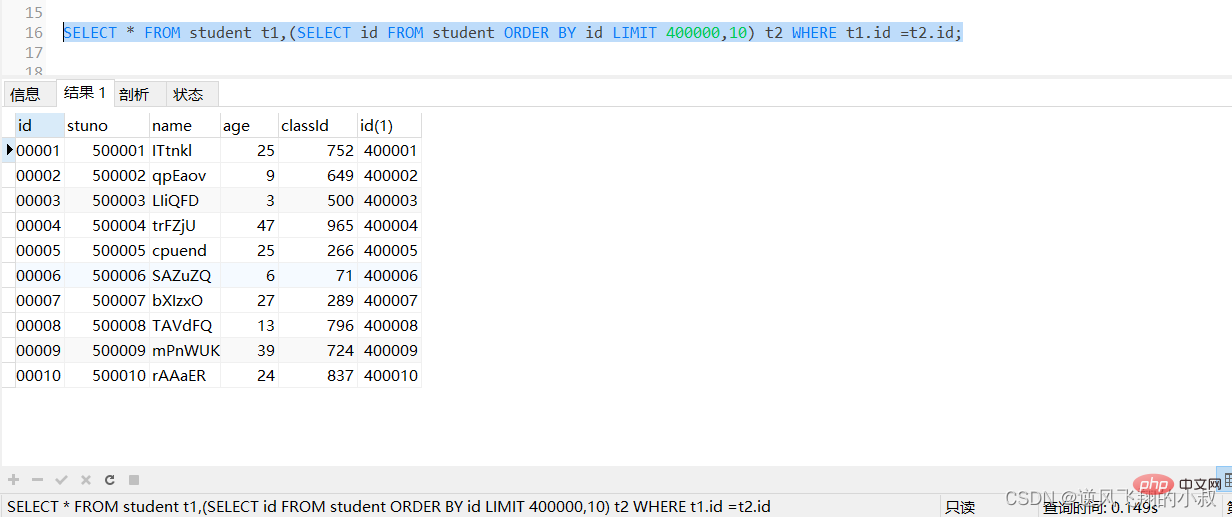
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
执行上面的sql,可以看到响应时间有一定的提升;
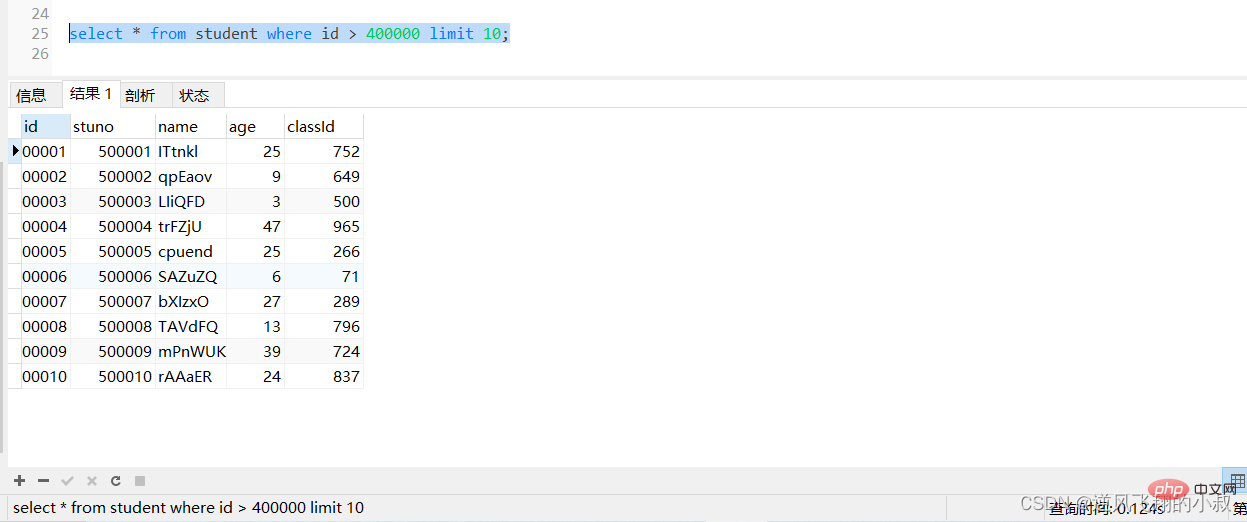
2)对于主键自增的表,可以把Limit 查询转换成某个位置的查询
select * from student where id > 400000 limit 10;
执行上面的sql,可以看到响应时间有一定的提升;
2、关联查询优化
在实际的业务开发过程中,关联查询可以说随处可见,关联查询的优化核心思路是,最好为关联查询的字段添加索引,这是关键,具体到不同的场景,还需要具体分析,这个跟mysql的引擎在执行优化策略的方案选择时有一定关系;
2.1 左连接或右连接
下面是一个使用left join 的查询,可以预想到这条sql查询的结果集非常大
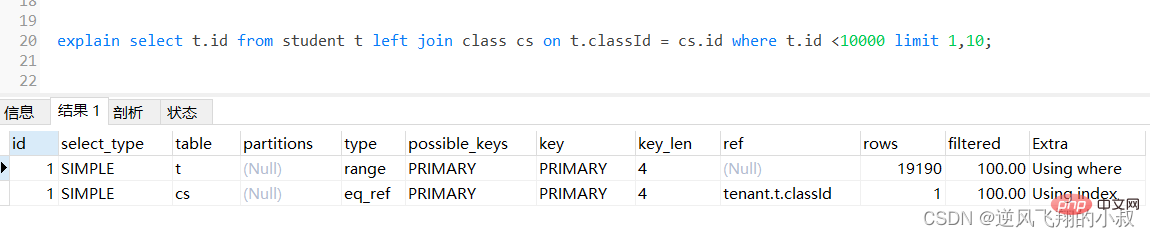
select t.* from student t left join class cs on t.classId = cs.id;
为了检查下sql的执行效率,使用explain做一下分析,可以看到,第一张表即left join左边的表student走了全表扫描,而class表走了主键索引,尽管结果集较大,还是走了索引;

针对这种场景的查询,思路如下:
- 让查询的字段尽量包含在主键索引或者覆盖索引中;
- 查询的时候尽量使用分页查询;
关于左连接(右连接)的explain结果补充说明
- 左连接左边的表一般为驱动表,右边的表为被驱动表;
- 尽可能让数据集小的表作为驱动表,减少mysql内部循环的次数;
- 两表关联时,explain结果展示中,第一栏一般为驱动表;
2.2 关联查询关联的字段建立索引
看下面的这条sql,其关联字段非表的主键,而是普通的字段;
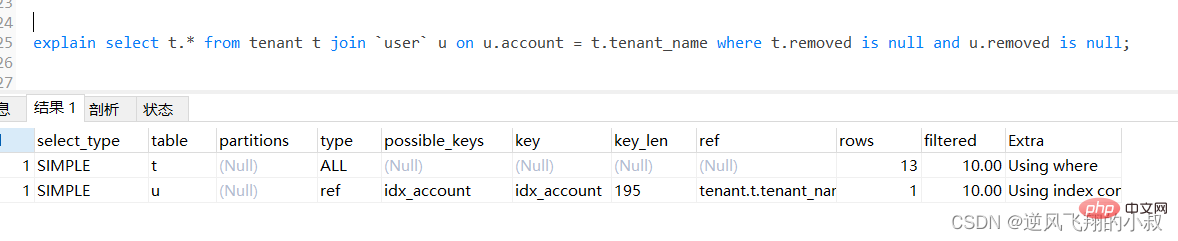
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;

通过explain分析可以发现,左边的表走了全表扫描,可以考虑给左边的表的tenant_name和user表的account 各自创建索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析结果如下

可以看到第二行type变为ref,rows的数量优化比较明显。这是由左连接特性决定的,LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引 。
2.3 内连接关联的字段建立索引
我们知道,左连接和右连接查询的数据分别是完全包含左表数据,完全包含右表数据,而内连接(inner join 或join) 则是取交集(共有的部分),在这种情况下,驱动表的选择是由mysql优化器自动选择的;
在上面的基础上,首先移除两张表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;
使用explain语句进行分析

然后给user表的account字段添加索引,再次执行explain我们发现,user表竟然被当作是被驱动表了;
此时,如果我们给tenant表的tenant_name加索引,并移除user表的account索引,得出的结果竟然都没有走索引,再次说明,使用内连接的情况下,查询优化器将会根据自己的判断进行选择;

3、子查询优化
子查询在日常编写业务的SQL时也是使用非常频繁的做法,不是说子查询不能用,而是当数据量超出一定的范围之后,子查询的性能下降是很明显的,关于这一点,本人在日常工作中深有体会;
比如下面这条sql,由于student表数据量较大,执行起来耗时非常长,可以看到耗费了将近3秒;
select st.* from student st where st.classId in ( select id from class where id > 100 );
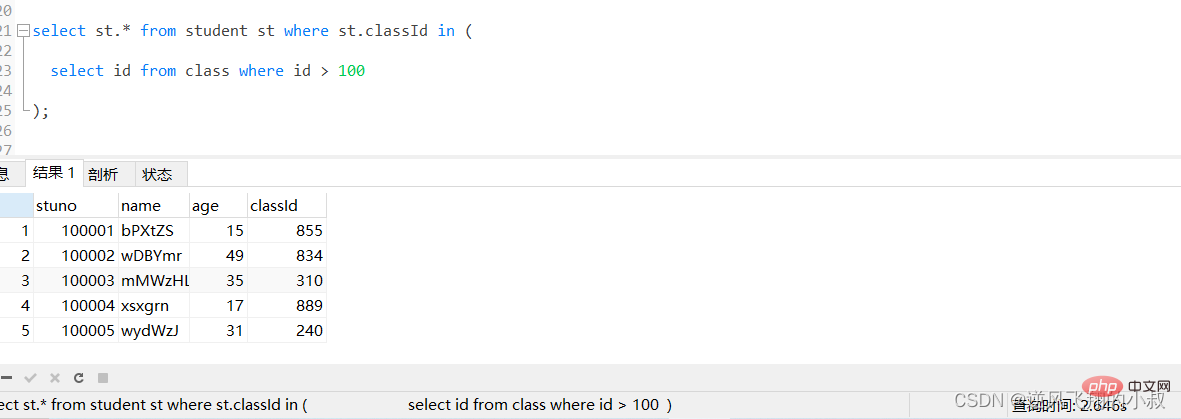
通过执行explain进行分析得知,内层查询 id > 100的子查询尽管用上了主键索引,但是由于结果集太大,带入到外层查询,即作为in的条件时,查询优化器还是走了全表扫描;
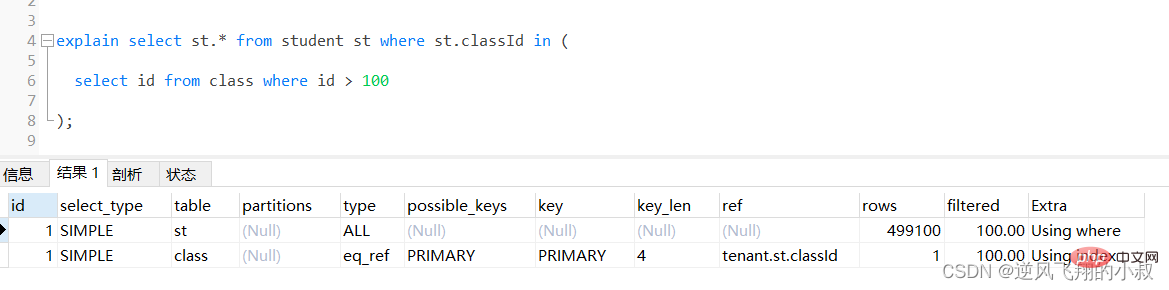
针对上面的情况,可以考虑下面的优化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查询性能低效的原因
- 子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询;
- 子查询结果集存储的临时表,不论是内存临时表还是磁盘临时表都不能走索引 ,所以查询性能会受到一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
使用mysql查询时,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表 ,其速度比子查询要快 ,如果查询中使用索引的话,性能就会更好,尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
一个真实的案例
在下面的这段sql中,优化前使用的是子查询,在一次生产问题的性能分析中,发现某个tenant_id下的数据达到了35万多,这样直接导致某个列表页面的接口查询耗时达到了5秒左右;
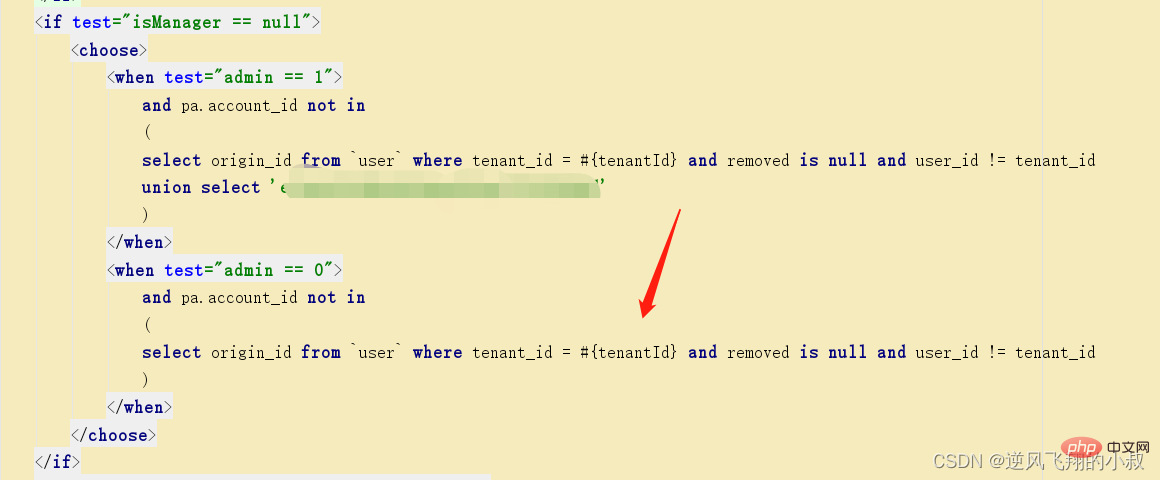
找到了问题的根源后,尝试使用上面的优化思路进行解决即可,优化后的sql大概如下,
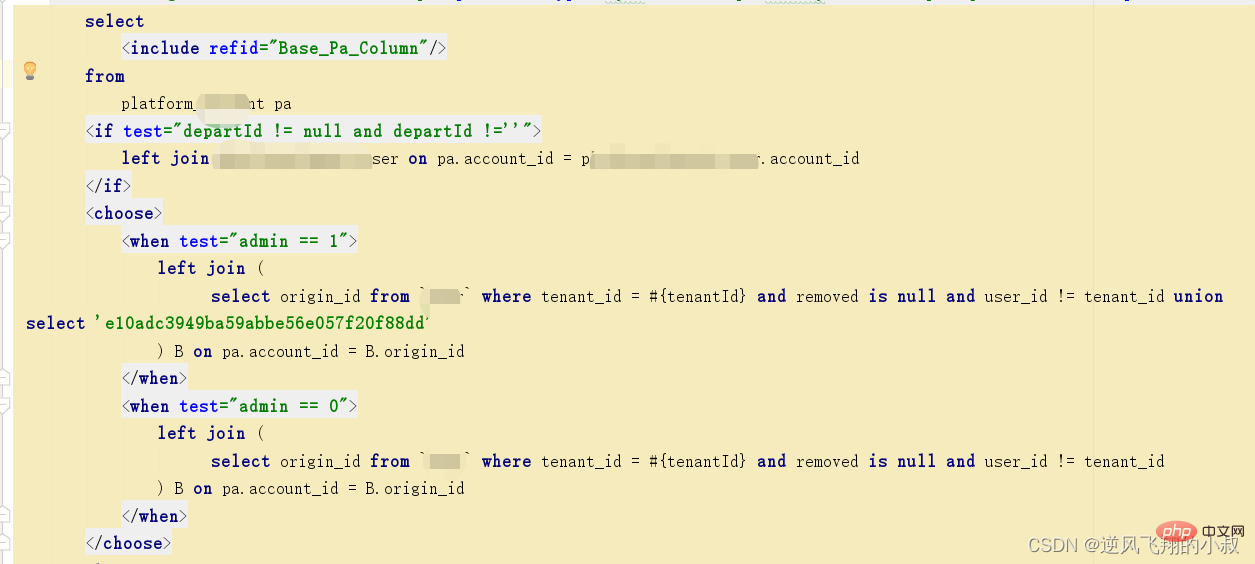
4、排序(order by)优化
在mysql,排序主要有两种方式
- Using filesort : 通过表索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序; - Using index : 通过有序的索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高;
对于以上两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index
4.1 使用age字段进行排序
由于age字段未加索引,查询结果按照age排序的时候发现使用了filesort,排序性能较低;

给age字段添加索引,再次使用order by时就走了索引;

4.2 使用多字段进行排序
通常在实际业务中,参与排序的字段往往不只一个,这时候,就可以对参与排序的多个字段创建联合索引;
如下根据stuno和age排序

给stuno和age添加联合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析时结果如下,此时排序走了索引

关于多字段排序时的注意事项
1)排序时,需要满足最左前缀法则,否则也会出现 filesort;
Die Reihenfolge des oben erstellten gemeinsamen Indexes ist Stuno und Alter, d. h. Stuno steht vorne und Alter hinten. Was passiert, wenn die Sortierreihenfolge während der Abfrage umgekehrt wird? Bei der Analyse der Ergebnisse wurde festgestellt, dass Dateisortierung verwendet wurde;

2) Beim Sortieren bleibt der Sortiertyp konsistent
Bei Beibehaltung der standardmäßigen Sortierreihenfolge der Felder, ob aufsteigend oder absteigend order, order By kann den Index verwenden. Was passiert, wenn einer in aufsteigender Reihenfolge und der andere in absteigender Reihenfolge ist? Die Analyse ergab, dass in diesem Fall auch die Dateisortierung verwendet wird.

5 Die Optimierungsstrategie der Gruppe nach ist der Optimierungsstrategie der Reihenfolge nach sehr ähnlich:
group by kann den Index direkt verwenden, auch wenn keine Filterbedingung vorliegt;
- group by sortiert zuerst und dann gruppiert, wobei die beste linke Präfixregel für die Indexerstellung befolgt wird;
- Wenn die Indexspalte nicht verwendet werden kann, erhöhen Sie max_length_for_sort_data und sort_buffer_size Parametereinstellungen;
- Wo ist effizienter als Haben? Wenn die Bedingungen in Wo geschrieben werden können, schreiben Sie sie nicht in Haben Programm. Anweisungen wie „Order by“, „Group by“ und „Distinct“ verbrauchen mehr CPU und die CPU-Ressourcen der Datenbank sind äußerst wertvoll.
- Wenn die SQL Abfrageanweisungen wie „Order by“, „Group by“ und „Distinct“ enthält, behalten Sie bitte die Ergebnismenge bei gefiltert nach der Where-Bedingung bei 1000 Innerhalb von Zeilen, sonst ist SQL sehr langsam; ist offensichtlich sehr ineffizient. Nach dem Hinzufügen des Index zu Stuno ineffizient
- Die Situation beim Befolgen des optimalen linken Präfixes ist wie folgt
6. Zähloptimierung
 count() ist eine Aggregatfunktion, die zeilenweise beurteilt wird . Wenn der Parameter der Zählfunktion nicht NULL ist, wird der kumulative Wert um 1 addiert, andernfalls wird er nicht addiert und schließlich wird der kumulative Wert zurückgegeben
count() ist eine Aggregatfunktion, die zeilenweise beurteilt wird . Wenn der Parameter der Zählfunktion nicht NULL ist, wird der kumulative Wert um 1 addiert, andernfalls wird er nicht addiert und schließlich wird der kumulative Wert zurückgegeben
Verwendung: count (*), count (Primärschlüssel), count (Feld), count (Zahl)



count (Primärschlüssel)
InnoDB durchläuft die gesamte Tabelle Nehmen Sie den Primärschlüssel-ID-Wert jeder Zeile heraus und geben Sie ihn an die Serviceschicht zurück. Nachdem die Serviceschicht den Primärschlüssel erhalten hat, wird er direkt zeilenweise akkumuliert (der Primärschlüssel darf nicht null sein). (*)
hat keine Nicht-Null-Einschränkung: Die InnoDB-Engine Durchläuft die gesamte Tabelle, entnimmt die Feldwerte jeder Zeile und gibt sie an die Serviceschicht zurück. Die Serviceschicht bestimmt, ob sie null ist oder nicht, und die Anzahl wird akkumuliert, wenn keine Nullbeschränkung vorliegt : Die InnoDB-Engine durchläuft die gesamte Tabelle, wird an die Serviceschicht zurückgegeben und direkt pro Zeile akkumuliert. nimmt aber nicht den Wert an. Für jede zurückgegebene Zeile fügt die Serviceschicht eine Zahl „1“ ein und akkumuliert diese direkt nach Zeile. Primärschlüssel-ID) < count(1) ≈ count(*), also versuchen Sie, count(*) zu verwenden
Empfohlenes Lernen:
MySQL-Video-TutorialDas obige ist der detaillierte Inhalt vonDetaillierte Erläuterung gängiger Abfrageoptimierungsstrategien für MySql. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!