
Häufig verwendete Datenstrukturen in Redis (organisiert und gemeinsam genutzt)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-11-07 17:15:502032Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis, das hauptsächlich verwandte Inhalte zu gängigen Datenstrukturen vorstellt, nämlich String, Hash, List, Set und Ordered Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Video-Tutorial
Gemeinsame Redis-Datenstrukturen
Redis stellt einige Datenstrukturen für den Zugriff auf Daten in Redis bereit. Es gibt die 5 am häufigsten verwendeten: String, Hash, List, Set, geordneter Satz (ZSET).
String
Der String-Typ ist die grundlegendste Datenstruktur von Redis. Erstens handelt es sich bei allen Schlüsseln um Zeichenfolgentypen, und auf der Grundlage dieser Zeichenfolgentypen werden mehrere andere Datenstrukturen erstellt, sodass die Zeichenfolgentypen die Grundlage für das Lernen der anderen vier Datenstrukturen bilden können. Der Wert des Zeichenfolgentyps kann tatsächlich eine Zeichenfolge (einfache Zeichenfolge, komplexe Zeichenfolge (z. B. JSON, XML)), eine Zahl (Ganzzahl, Gleitkommazahl) oder sogar eine Binärzahl (Bild, Audio, Video) sein, der Wert ist jedoch vorhanden der größte darf 512 MB nicht überschreiten.
(Obwohl Redis in C geschrieben ist und es Strings in C gibt, die
Operationsbefehl
set Wert festlegen
Schlüsselwert festlegen
Der Befehl „set“ hat mehrere Optionen:
ex Sekunden: Legt die Ablaufzeit der zweiten Ebene für den Schlüssel fest.
px Millisekunden: Legen Sie die Ablaufzeit in Millisekunden für den Schlüssel fest.
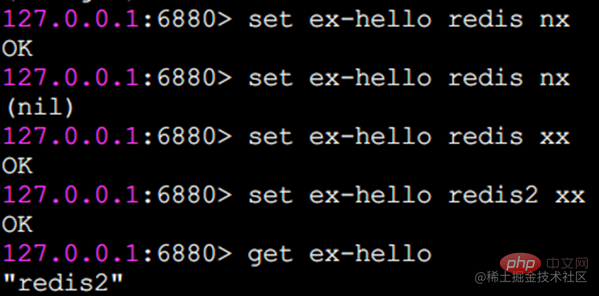
nx: Der Schlüssel darf nicht vorhanden sein, bevor er erfolgreich festgelegt werden kann und zum Hinzufügen verwendet wird (üblicherweise für verteilte Sperren verwendet).
xx: Im Gegensatz zu nx muss der Schlüssel existieren, bevor er erfolgreich gesetzt und für die Aktualisierung verwendet werden kann.
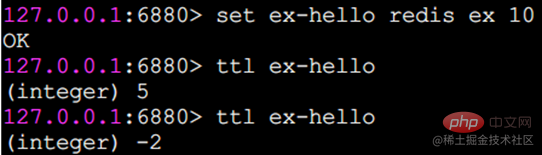
Vom Ausführungseffekt her ist der Ex-Parameter im Grunde derselbe wie der Expire-Befehl. Eine weitere Sache, die besondere Aufmerksamkeit erfordert, ist, dass die Ablaufzeit verschwindet, wenn für eine Zeichenfolge eine Ablaufzeit festgelegt ist und Sie dann die Set-Methode aufrufen, um sie zu ändern.
Die Ausführungseffekte von nx und xx sind wie folgt:
Zusätzlich zur Set-Option bietet Redis auch die Befehle setex und setnx:
setex-Taste Sekundenwert
Setnx-Schlüsselwert
setex und setnx haben die gleiche Funktion wie die Optionen ex und nx. Das heißt, setex legt die Ablaufzeit der zweiten Ebene für den Schlüssel fest. Der Schlüssel darf nicht vorhanden sein, wenn setnx festgelegt ist, bevor er erfolgreich festgelegt werden kann.
setex-Beispiel:

setnx-Beispiel:
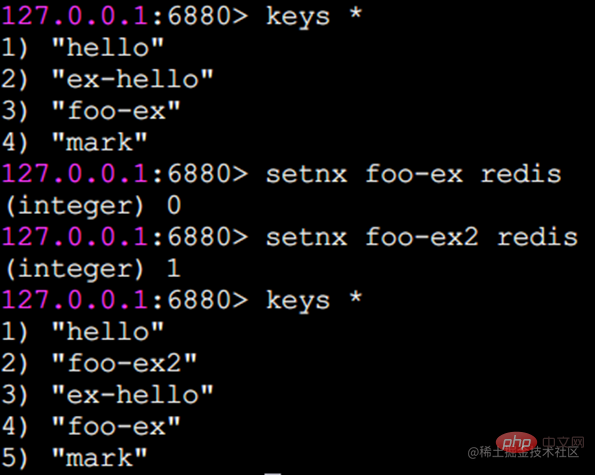
Da der Schlüssel foo-ex bereits existiert, schlägt setnx fehl und das Rückgabeergebnis ist 0. Der Schlüssel foo-ex2 existiert nicht, also ist setnx erfolgreich und das Rückgabeergebnis ist 1 .
Gibt es Anwendungsszenarien? Aufgrund des Single-Thread-Befehlsverarbeitungsmechanismus von Redis kann nur ein Client den Setnx-Schlüsselwert erfolgreich festlegen Eigenschaften von setnx. Setnx kann als Implementierungslösung für verteilte Sperren verwendet werden. Natürlich erfordert verteiltes Sperren nicht nur einen Befehl. Es gibt viele Dinge, auf die man achten muss. Wir werden später ein separates Kapitel verwenden, um verteiltes Sperren basierend auf Redis zu beschreiben.
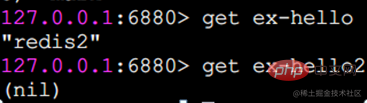
get Holen Sie sich den Wert
Wenn der zu erhaltende Schlüssel nicht existiert, geben Sie Null (leer) zurück:
mset Legen Sie den Wert in Stapeln fest.
Legen Sie 4 Schlüssel-Wert-Paare gleichzeitig fest über den Befehl mset

mget erhält Werte in Stapeln
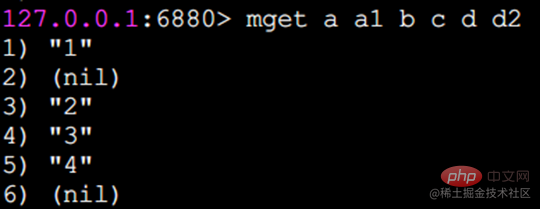
erhält die Werte der Schlüssel a, b, c, d in Stapeln:
Wenn einige Schlüssel nicht vorhanden sind , dann sind ihre Werte Null (leer) und das Ergebnis ist wie in übergeben. Die Reihenfolge, in der die Schlüssel eingegeben werden, wird zurückgegeben.
Batch-Operationsbefehle können die Effizienz effektiv verbessern. Wenn kein Befehl wie mget vorhanden ist, ist die spezifische Zeit, die zum Ausführen von n get-Befehlen erforderlich ist, wie folgt:
n get-Zeiten = n Netzwerkzeiten + n Befehlszeiten
Nach Verwendung von mget Befehl, die spezifische Zeit, die zum Ausführen von n Get-Befehlsvorgängen erforderlich ist, ist wie folgt:
n Get-Zeit = 1 Netzwerkzeit + n Befehlszeit
Redis kann Zehntausende Lese- und Schreibvorgänge pro Sekunde unterstützen, dies bezieht sich jedoch auf die Verarbeitungsfähigkeit des Redis-Servers. Für den Client verfügt ein Befehl zusätzlich zur Befehlszeit auch über Netzwerkzeit beträgt 1 Millisekunde, die Befehlszeit beträgt 0,1 Millisekunden (berechnet basierend auf der Verarbeitung von 10.000 Befehlen pro Sekunde), dann dauert die Ausführung von 1.000 Get-Befehlen 1,1 Sekunden (10001+10000,1=1100 ms) und 1 mget-Befehl dauert 0,101 Sekunden (11+1000 0,1=101ms).
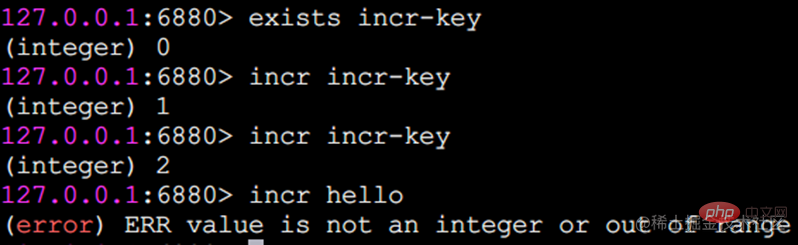
Incr-Zahlenoperation
Incr-Befehl wird verwendet, um den Wert zu erhöhen. Die zurückgegebenen Ergebnisse sind in drei Situationen unterteilt:
Der Wert ist keine Ganzzahl und es wird ein Fehler zurückgegeben.
Der Wert ist eine Ganzzahl und das Ergebnis nach der Erhöhung wird zurückgegeben. Der Schlüssel
existiert nicht. Er wird entsprechend dem Wert 0 erhöht und das zurückgegebene Ergebnis ist 1.
Zusätzlich zum Befehl incr bietet Redis decr (automatische Dekrementierung), incrby (automatische Inkrementierung auf eine angegebene Zahl), decrby (automatische Dekrementierung auf eine angegebene Zahl) und incrbyfloat (automatische Inkrementierung von eine Gleitkommazahl). Bitte probieren Sie die spezifischen Effekte selbst aus.
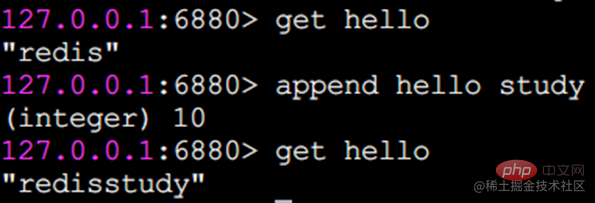
append append command
append kann einen Wert an das Ende der Zeichenfolge anhängen
 getset legt den Originalwert fest und gibt ihn zurück.
getset legt den Originalwert fest und gibt ihn zurück.
getset legt den Wert genau wie set fest, der Unterschied besteht jedoch darin, dass es auch den Originalwert des Schlüssels zurückgibt
Indizes beginnen bei 0.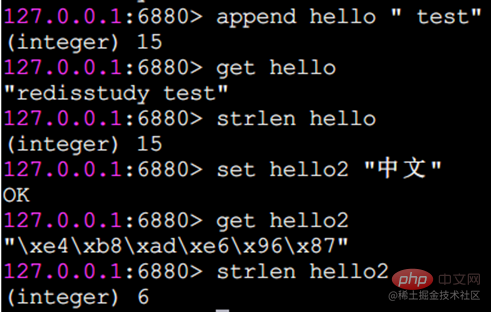
getrange fängt einen Teil des Strings ab, um einen Teilstring zu bilden. Der abgefangene Bereich ist ein geschlossenes Intervall.
Zeitliche Komplexität von Befehlen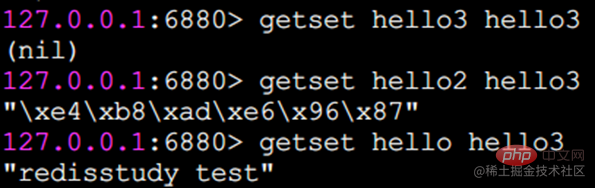
String Unter diesen Befehlen, mit Ausnahme von del, mset und mget, die Stapeloperationen mehrerer Schlüssel unterstützen, hängt die zeitliche Komplexität von der Anzahl der Schlüssel ab, die O(n) ist. getrange hängt von der Länge des Strings ab und ist ebenfalls O(n). Die übrigen Befehle haben grundsätzlich eine Zeitkomplexität von O(1), was immer noch sehr schnell ist.
Verwendungsszenarien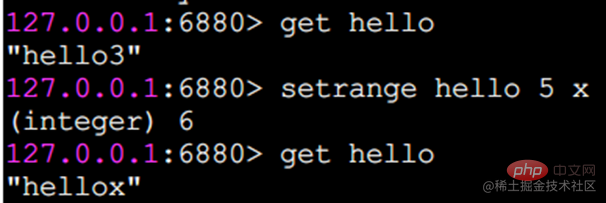
Cache-Funktion
Redis als Cache-Schicht, MySQL als Speicherschicht, die meisten angeforderten Daten werden von Redis abgerufen. Da Redis über die Eigenschaften verfügt, eine hohe Parallelität zu unterstützen, kann Caching normalerweise dazu beitragen, das Lesen und Schreiben zu beschleunigen und den Back-End-Druck zu verringern.Zählen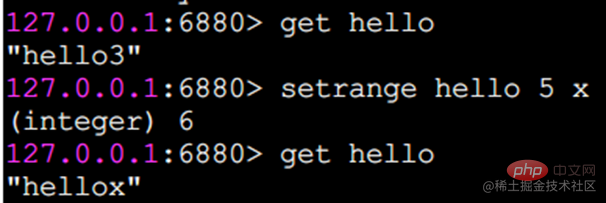
Mit Redis als grundlegendes Tool zum Zählen können die Funktionen des schnellen Zählens und Abfrage-Cachings realisiert werden, und die Daten können asynchron in andere Datenquellen eingespeist werden.
Freigegebene SitzungEin verteilter Webdienst speichert die Sitzungsinformationen des Benutzers (z. B. Benutzeranmeldeinformationen) auf seinen eigenen Servern. Aus Gründen des Lastausgleichs speichert der verteilte Dienst die Sitzungsinformationen des Benutzers. (z. B. Benutzer-Anmeldeinformationen). Der Zugriff wird auf verschiedene Server verteilt. Benutzer, die den Zugriff aktualisieren, müssen sich möglicherweise erneut anmelden. Um dieses Problem zu lösen, kann Redis zur zentralen Verwaltung von Benutzersitzungen verwendet werden. Solange Redis hochverfügbar und skalierbar ist, werden diese jedes Mal, wenn ein Benutzer Anmeldeinformationen aktualisiert oder abfragt, direkt von Redis abgerufen . .
GeschwindigkeitsbegrenzungAus Sicherheitsgründen fordern viele Anwendungen den Benutzer beispielsweise bei jeder Anmeldung auf, einen Mobiltelefon-Verifizierungscode einzugeben, um festzustellen, ob es sich um den Benutzer selbst handelt. Um jedoch einen häufigen Zugriff auf die SMS-Schnittstelle zu vermeiden, wird die Häufigkeit, mit der Benutzer pro Minute Verifizierungscodes erhalten, begrenzt, beispielsweise auf nicht mehr als fünf Mal pro Minute. Einige Websites verhindern, dass eine IP-Adresse mehr als n-mal pro Sekunde abgefragt wird, und können eine ähnliche Idee verwenden.
HashJava stellt HashMap bereit, und Redis verfügt auch über eine ähnliche Datenstruktur, nämlich den Hash-Typ. Beachten Sie jedoch, dass die Zuordnungsbeziehung im Hash-Typ als Feldwert bezeichnet wird. Beachten Sie, dass sich der Wert hier auf den Wert bezieht, der dem Feld entspricht, und nicht auf den Wert, der dem Schlüssel entspricht.
Operationsbefehle
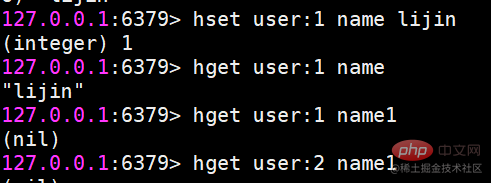
Grundsätzlich sind die Hash-Operationsbefehle den String-Operationsbefehlen sehr ähnlich. Viele Befehle fügen den Buchstaben h vor dem String-Typ-Befehl hinzu, was bedeutet, dass der Hash-Typ gleichzeitig bedient werden soll Zeit muss der Wert des Feldes angegeben werden, das bearbeitet werden soll. hset-Einstellungswert
hset-Benutzer:1 Name Lijin

Wenn die Einstellung erfolgreich ist, wird 1 zurückgegeben, andernfalls wird 0 zurückgegeben. Darüber hinaus stellt Redis den Befehl hsetnx bereit. Ihre Beziehung ist die gleiche wie bei den Befehlen set und setnx, mit der Ausnahme, dass sich der Gültigkeitsbereich von Schlüssel zu Feld ändert.
hget-Wert
hget-Benutzer:1 Name
Wenn der Schlüssel oder das Feld nicht vorhanden ist, wird Null zurückgegeben.
hdel delete field
hdel löscht ein oder mehrere Felder und das Rückgabeergebnis ist die Anzahl der erfolgreich gelöschten Felder.
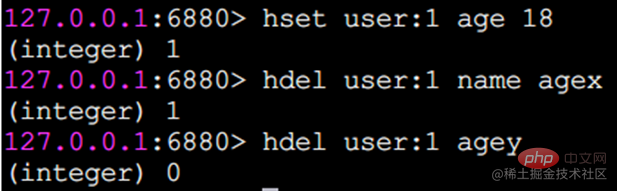
hlen berechnet die Anzahl der Felder.
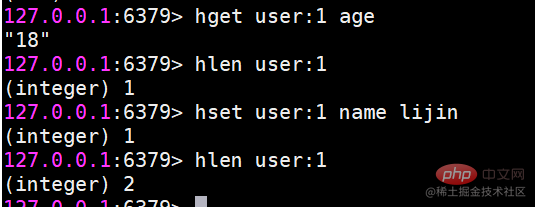
hmset legt den Wert in Stapeln fest.

hmget ermittelt den Wert in Stapeln
 Wenn es existiert, gib 1 zurück, wenn es nicht existiert. Gibt 0 zurück.
Wenn es existiert, gib 1 zurück, wenn es nicht existiert. Gibt 0 zurück.
hkeys ruft alle Felder ab.
Es gibt alle Felder mit dem angegebenen Hash-Schlüssel zurück 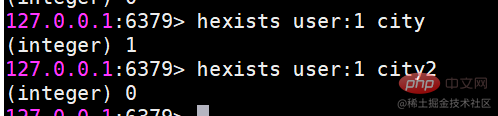
Bei Verwendung von hgetall besteht die Möglichkeit, dass Redis blockiert wird, wenn die Anzahl der Hash-Elemente relativ groß ist. Wenn Sie nur einen Teil des Feldes abrufen müssen, können Sie hmget verwenden. Wenn Sie alle Feldwerte abrufen müssen, können Sie den Befehl hscan verwenden, der den Hash-Typ schrittweise durchläuft .
hincrby fügt
hincrby und hincrbyfloat hinzu, genau wie die Befehle incrby und incrbyfloat, aber ihr Umfang ist archiviert. 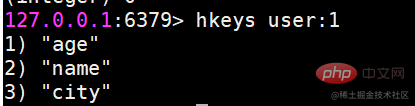
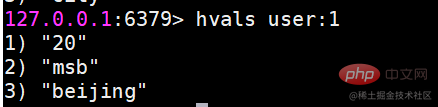 Wie Sie aus den vorherigen Vorgängen ersehen können, sind die Vorgänge von String und Hash sehr ähnlich. Warum müssen Sie also einen Hash für die Speicherung erstellen?
Wie Sie aus den vorherigen Vorgängen ersehen können, sind die Vorgänge von String und Hash sehr ähnlich. Warum müssen Sie also einen Hash für die Speicherung erstellen?
Der Hash-Typ eignet sich besser zum Speichern von Objekttypdaten. Wenn der Benutzer im Tabellendatensatz in der Datenbank lautet:
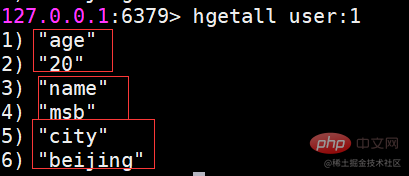
ID
Name
Alter
|
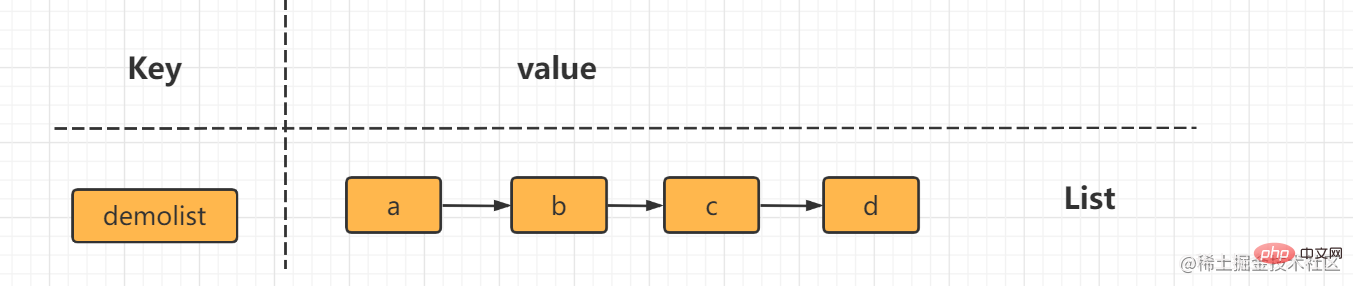
1. Die Verwendung des String-Typs erfordert das Einfügen und Abrufen nacheinander. Benutzer festlegen:1:Name lijin; Benutzer festlegen:1:18 Jahre alt; Benutzer festlegen:2:Name msb; Benutzer festlegen:2:20 Jahre alt; Vorteile: jeweils einfach und intuitiv Der Schlüssel entspricht einem Wert Nachteile: zu viele Schlüssel, viel Speicher beanspruchend, Benutzerinformationen sind zu verstreut, werden nicht in der Produktionsumgebung verwendet 2. Serialisieren Sie das Objekt und speichern Sie es in Redis set user:1 serialize( userInfo); Vorteile: Einfache Programmierung, hoher Speicherverbrauch bei Verwendung der Serialisierung Nachteile: Serialisierung und Deserialisierung haben einen gewissen Overhead, beim Aktualisieren von Attributen müssen alle Benutzerinformationen entfernt werden Zur Deserialisierung. Nach der Aktualisierung zu Redis serialisieren Hash-Typ verwenden hmset-Benutzer:1 Name Lijin Alter 18 hmset-Benutzer:2 Name MSB Alter 20 Vorteile: einfach und intuitiv, vernünftige Verwendung kann den Speicherplatzverbrauch reduzieren Nachteile: Um das interne Codierungsformat zu steuern, verbrauchen ungeeignete Formate mehr Speicher Liste (Liste)Der Listentyp (Liste) wird zum Speichern mehrerer geordneter Zeichenfolgen verwendet, a Die vier Die Elemente b, c, c und b bilden eine geordnete Liste von links nach rechts. Jede Zeichenfolge in der Liste wird als Element bezeichnet. Eine Liste kann bis zu (2^32-1) Elemente (4294967295) speichern.
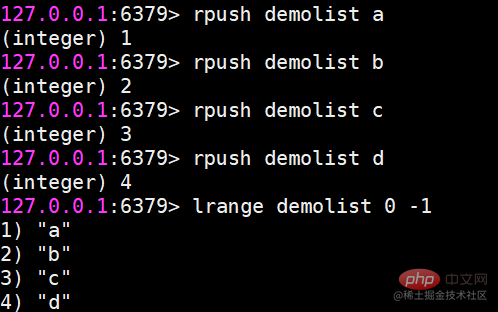
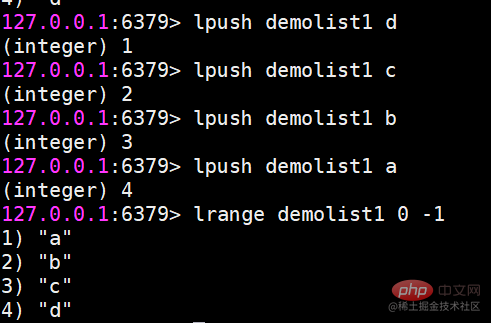
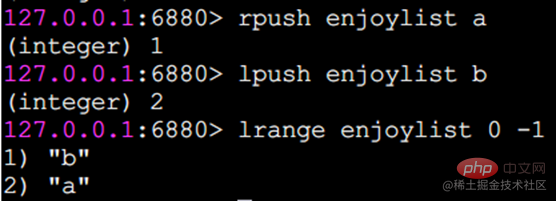
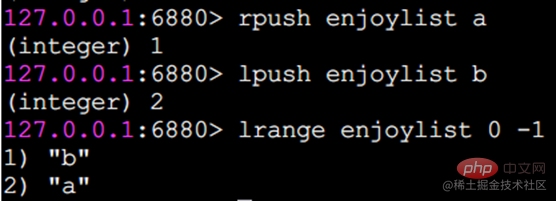
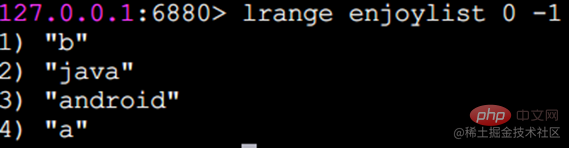
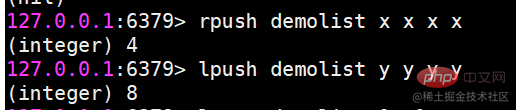
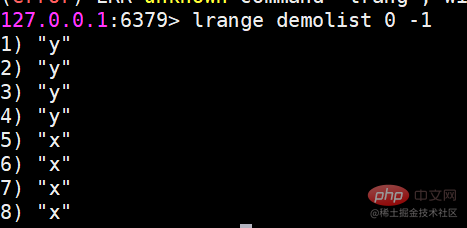
In Redis können Sie beide Enden der Liste einfügen (push) und Pop (pop), Sie können auch eine Liste von Elementen in einem angegebenen Bereich abrufen, Elemente mit einem angegebenen Indexindex abrufen usw. Liste ist eine relativ flexible Datenstruktur, die als Stapel und Warteschlange fungieren kann und in der tatsächlichen Entwicklung viele Anwendungsszenarien aufweist. Der Listentyp weist zwei Merkmale auf: Erstens sind die Elemente in der Liste geordnet, was bedeutet, dass Sie über den Indexindex ein Element oder eine Liste von Elementen in einem bestimmten Bereich erhalten können. Zweitens können Elemente in der Liste wiederholt werden. Operationsbefehllrange Ruft eine Liste der Elemente innerhalb des angegebenen Bereichs ab (Elemente werden nicht gelöscht)Tastenanfang Ende Index-Indexfunktionen: 0 bis N-1 von links nach rechts lrange 0 -1-Befehl can Holen Sie sich alle Elemente der Liste von links nach rechts rpush Einfügen nach rechts
lpush Einfügen nach links
linsert Einfügen eines neuen Elements vor oder nach einem Element
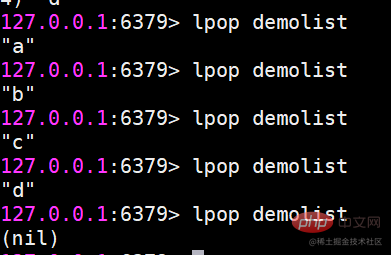
Diese drei Rückgabeergebnisse sind die Länge der aktuellen Liste nach Abschluss des Befehls, also die Anzahl der in der Liste enthaltenen Elemente. Gleichzeitig unterstützen sowohl rpush als auch lpush das Einfügen mehrerer Elemente gleichzeitig. lpop erscheint auf der linken Seite der Liste (Elemente werden gelöscht)
Bitte beachten Sie, dass die Elemente nach dem Auftauchen verschwinden. rpop Pop von der rechten Seite der Listerpop blendet das Element d ganz rechts in der Liste ein.
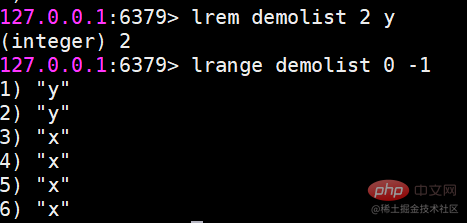
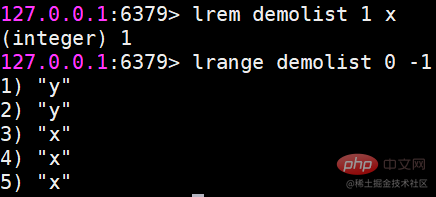
lrem Das angegebene Element löschen
Der Befehl lrem findet das Element, das dem Wert entspricht, aus der Liste und löscht es entsprechend der Anzahl in drei Situationen: count>0, von links nach rechts, höchstens count Elemente löschen. count count=0, alle löschen.
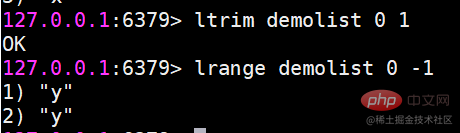
Der Rückgabewert ist die Anzahl der tatsächlich gelöschten Elemente. ltirm schneidet die Liste entsprechend dem Indexbereich zuWenn Sie beispielsweise das 0. bis 1. Element in der Liste behalten möchten
lset ändert das Element mit dem angegebenen Indexindex
lindex Ruft das Element mit dem angegebenen Indexindex der Liste ab
llen Ruft die Listenlänge ab
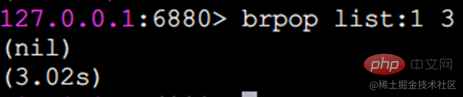
blpop und brpop blockierende Popup-Elementeblpop und brpop sind zusätzlich blockierende Versionen von lpop und rpop , sie unterstützen auch mehrere Listentypen und unterstützen auch die Einstellung der Blockierungszeit in Sekunden. Wenn die Blockierungszeit 0 ist, bedeutet dies, dass sie weiterhin blockiert wird. Nehmen wir als Beispiel brpop.
Ein Client ist blockiert (weil er blockiert wird, wenn kein Element vorhanden ist)
Ein Client ist immer blockiert. Zu diesem Zeitpunkt führen wir
A-Client von einem anderen Client B aus und geben
aus. Hinweis: Wenn nach brpop mehrere Schlüssel vorhanden sind, durchläuft brpop die Schlüssel von links nach rechts , Pop das Element und der Client kehrt sofort zurück. VerwendungsszenarienDer Listentyp kann beispielsweise verwendet werden: Nachrichtenwarteschlange, die Redis-Befehlskombination lpush+brpop kann die Blockierungswarteschlange realisieren, der Producer-Client verwendet lrpush, um Elemente von der linken Seite der Liste einzufügen, mehrere Verbraucher-Clients Mithilfe des Befehls brpop zum „Ergreifen“ von Elementen am Ende der Liste auf blockierende Weise stellen mehrere Clients einen Lastausgleich und eine hohe Verfügbarkeit des Verbrauchs sicher. Artikelliste Jeder Benutzer hat seine eigene Artikelliste, und jetzt muss die Artikelliste in Seiten angezeigt werden. Zu diesem Zeitpunkt können Sie die Verwendung einer Liste in Betracht ziehen, da die Liste nicht nur geordnet ist, sondern auch das Abrufen von Elementen gemäß dem Indexbereich unterstützt. Andere Datenstrukturen implementieren lpush+lpop =Stack (Stack) lpush +rpop =Queue (Warteschlange) lpsh+ ltrim =Capped Collection (begrenzte Sammlung) lpush+brpop=Message Queue (Nachrichtenwarteschlange) Set
Der Set-Typ wird auch zum Speichern mehrerer Zeichenfolgenelemente verwendet. Im Gegensatz zum Listentyp sind jedoch keine doppelten Elemente im Set zulässig, und die Elemente im Set sind keine. In der Reihenfolge können Elemente nicht abgerufen werden Indexindizes. Eine Sammlung kann bis zu 2 hoch 32 - 1 Element speichern. Redis unterstützt nicht nur das Hinzufügen, Löschen, Ändern und Abfragen innerhalb einer Sammlung, sondern unterstützt auch Schnittmengen, Vereinigungen und Differenzmengen mehrerer Sammlungen. Durch die ordnungsgemäße Verwendung von Sammlungstypen können viele praktische Probleme in der tatsächlichen Entwicklung gelöst werden. In-Set-Operationsbefehlsadd Element hinzufügenermöglicht das Hinzufügen mehrerer Elemente, das Rückgabeergebnis ist die Anzahl der erfolgreich hinzugefügten Elemente
srem Elemente löschenermöglicht das Löschen mehrerer Elemente, das Rückgabeergebnis ist die Anzahl der erfolgreich gelöschten Elemente
scard Berechnen Sie die Anzahl der Elemente
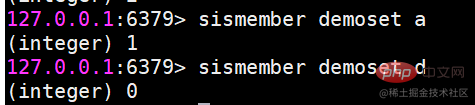
sismember Bestimmen Sie, ob das Element in der Menge istWenn das angegebene Elementelement in der Menge ist, geben Sie 1 zurück, andernfalls geben Sie 0 zurück
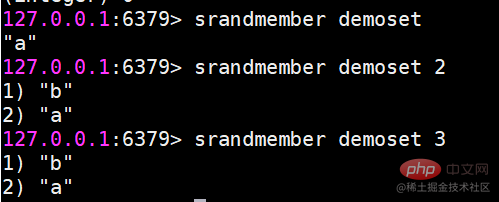
srandmember Gibt die angegebene Person aus dem Set Count-Element nach dem Zufallsprinzip zurück.Geben Sie die Zahl an. Wenn nicht geschrieben, ist der Standardwert 1
spop entfernt zufällig Elemente aus der SammlungSie können auch die Anzahl angeben. Wenn nicht angegeben, ist der Standardwert 1. Beachten Sie, dass die Elemente nach der Ausführung des spop-Befehls aus der Sammlung gelöscht werden srandmember wird nicht.
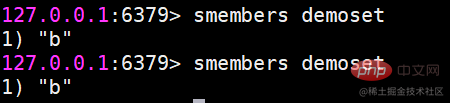
smembers Holen Sie sich alle Elemente (es werden keine Elemente herausspringen)Das zurückgegebene Ergebnis ist ungeordnet
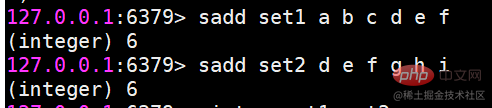
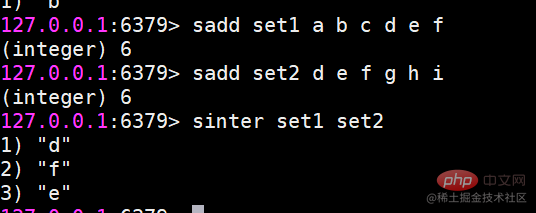
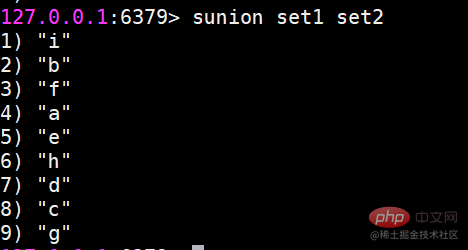
Inter-Set-OperationsbefehlJetzt gibt es zwei Sätze, sie sind Set1 und Set2
sinter Findet den Schnittpunkt mehrerer Mengen.
suinon Findet die Vereinigung mehrerer Mengen.
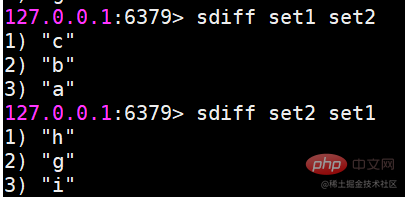
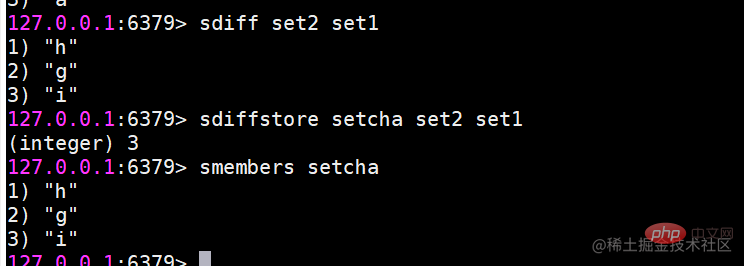
sdiff Findet die Differenz mehrerer Mengen Operationen zwischen Sätzen sind zeitaufwändiger, wenn viele Elemente vorhanden sind. Daher stellt Redis die oben genannten drei Befehle (ursprünglicher Befehl + Speicher) bereit, um die Ergebnisse von Schnittmenge, Vereinigung und Differenz zwischen Sätzen im Zielschlüssel zu speichern, zum Beispiel:
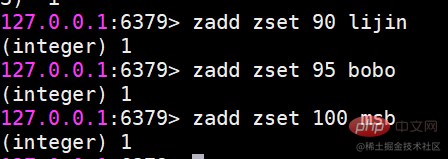
NutzungsszenarienEin typisches Nutzungsszenario für Sammlungstypen sind Tags. Beispielsweise könnte ein Benutzer an Unterhaltung und Sport interessiert sein, während ein anderer Benutzer an Geschichte und Nachrichten interessiert sein könnte. Diese Points of Interest sind Tags. Mit diesen Daten können wir die Personen ermitteln, denen das gleiche Tag gefällt, und die Tags, die den Benutzern gemeinsam gefallen. Diese Daten sind wichtig für die Benutzererfahrung und die Verbesserung der Benutzerbindung. Zum Beispiel gibt eine E-Commerce-Website Benutzern mit unterschiedlichen Labels verschiedene Arten von Empfehlungen. Beispielsweise empfehlen Personen, die sich mehr für digitale Produkte interessieren, die neuesten digitalen Produkte auf verschiedenen Seiten oder per E-Mail, normalerweise für Die Website bringt weitere Vorteile. Ordered Sets sind im Vergleich zu Hashes, Listen und Sets etwas ungewohnt, aber da sie geordnete Sets genannt werden, müssen sie mit Sets verknüpft sein und behalten bei. Sets dürfen keine doppelten Mitglieder haben , aber der Unterschied besteht darin, dass die Elemente in einer geordneten Menge sortiert werden können. Aber im Gegensatz zur Liste, die Indexindizes als Grundlage für die Sortierung verwendet, legt sie für jedes Element eine Bewertung als Grundlage für die Sortierung fest. Die Elemente im geordneten Satz können nicht wiederholt werden, aber die Punktzahl kann wiederholt werden, genauso wie die Schülerzahlen von Klassenkameraden in derselben Klasse nicht wiederholt werden können, aber die Testergebnisse können gleich sein.Geordnete Sätze bieten Funktionen wie das Erhalten bestimmter Bewertungen und Elementbereichsabfragen, die Berechnung von Mitgliederrankings usw. Die ordnungsgemäße Verwendung geordneter Sätze kann uns bei der Lösung vieler Probleme in der tatsächlichen Entwicklung helfen. Das Rückgabeergebnis stellt die Anzahl der erfolgreich hinzugefügten Mitglieder darBitte beachten Sie:
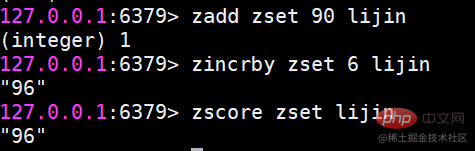
Der Befehl zadd verfügt außerdem über die vier Optionen nx, xx, ch, incr vier Optionen nx: Mitglied darf nicht existieren, bevor es erfolgreich zum Hinzufügen festgelegt werden kann. xx: Mitglied muss vorhanden sein, bevor es erfolgreich festgelegt und für Aktualisierungen verwendet werden kann. zscore-Berechnung Der Score eines Mitglieds
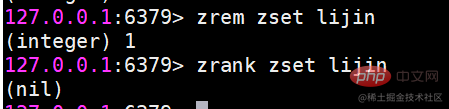
zrank berechnet den Rang des Mitglieds
zrank是从分数从低到高返回排名 zrevrank反之 很明显,排名从0开始计算。 zrem 删除成员
允许一次删除多个成员。 返回结果为成功删除的个数。 zincrby 增加成员的分数
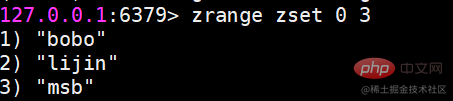
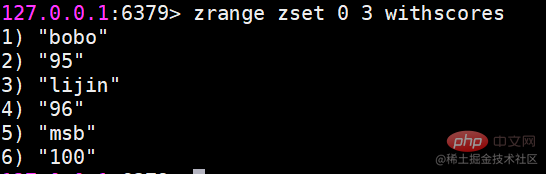
zrange和zrevrange返回指定排名范围的成员有序集合是按照分值排名的,zrange是从低到高返回,zrevrange反之。如果加上 withscores选项,同时会返回成员的分数
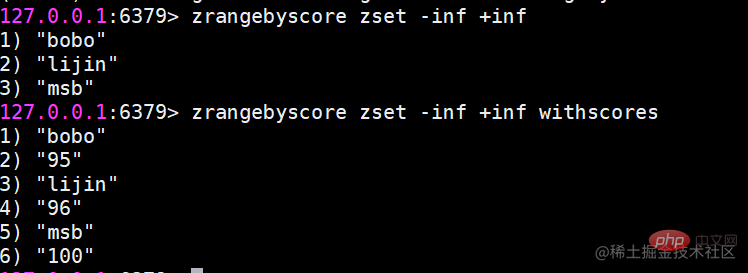
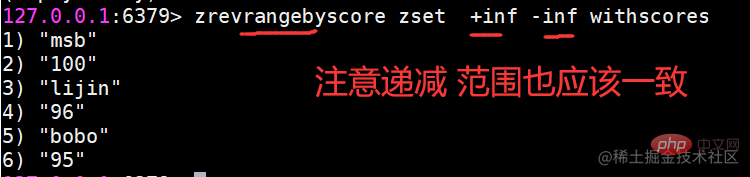
zrangebyscore返回指定分数范围的成员zrangebyscore key min max [withscores] [limit offset count] zrevrangebyscore key max min [withscores][limit offset count]复制代码 其中zrangebyscore按照分数从低到高返回,zrevrangebyscore反之。例如下面操作从低到高返回200到221分的成员,withscores选项会同时返回每个成员的分数。 同时min和max还支持开区间(小括号)和闭区间(中括号),-inf和+inf分别代表无限小和无限大:
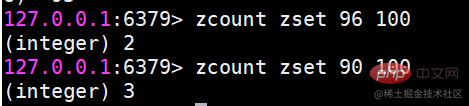
zcount 返回指定分数范围成员个数zcount key min max
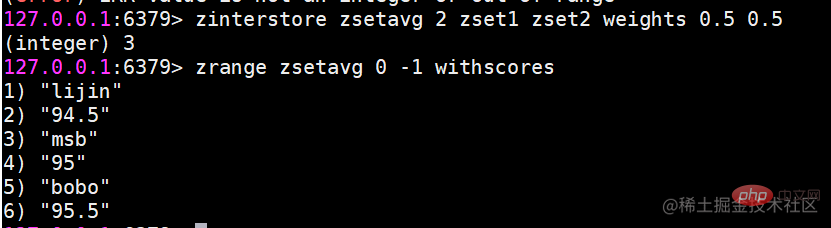
zremrangebyrank 按升序删除指定排名内的元素zremrangebyrank key start end zremrangebyscore 删除指定分数范围的成员zremrangebyscore key min max 集合间操作命令zinterstore 交集zinterstore 这个命令参数较多,下面分别进行说明 destination:交集计算结果保存到这个键。 numkeys:需要做交集计算键的个数。 key [key ...]:需要做交集计算的键。 weights weight [weight ...]:每个键的权重,在做交集计算时,每个键中的每个member 会将自己分数乘以这个权重,每个键的权重默认是1。 aggregate sum/ min |max:计算成员交集后,分值可以按照sum(和)、min(最小值)、max(最大值)做汇总,默认值是sum。 不太好理解,我们用一个例子来说明。(算平均分)
zunionstore 并集该命令的所有参数和zinterstore是一致的,只不过是做并集计算,大家可以自行实验。 使用场景有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。 持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第26天,点击查看活动详情 推荐学习:Redis视频教程 |
|---|

 r
r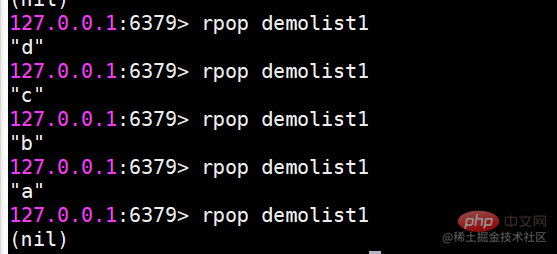

 ls
ls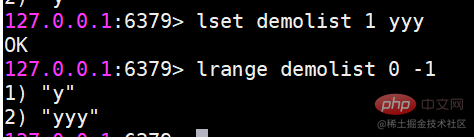
 l
l










 Wenn das Mitglied nicht existiert, gib Null zurück
Wenn das Mitglied nicht existiert, gib Null zurück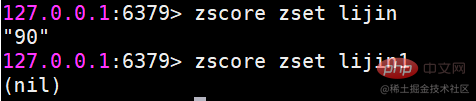



Das obige ist der detaillierte Inhalt vonHäufig verwendete Datenstrukturen in Redis (organisiert und gemeinsam genutzt). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine kurze Diskussion über die Gründe, warum Redis langsam ist, und wie man das Problem beheben kann
- Ein Artikel zum Verständnis der Ereignisverarbeitung der Redis-Quellcode-Designanalyse
- Ausführliche Erläuterung der Redis-Schlüsseldurchquerung und Datenbankverwaltung
- Redis-Spezialdatentyp-Stream
- Gemeinsame Nutzung von Techniken mit hoher Parallelität mithilfe von Redis und lokalem Cache