

 Backend-EntwicklungPython-TutorialPraktische Aufzeichnungen einiger Probleme beim Speichern und Laden von Pytorch-Modellen
Backend-EntwicklungPython-TutorialPraktische Aufzeichnungen einiger Probleme beim Speichern und Laden von Pytorch-ModellenPraktische Aufzeichnungen einiger Probleme beim Speichern und Laden von Pytorch-Modellen

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python. Er stellt hauptsächlich praktische Aufzeichnungen zu einigen Problemen beim Speichern und Laden von Pytorch-Modellen vor. Ich hoffe, dass er für alle hilfreich ist.

【Verwandte Empfehlungen: Python3-Video-Tutorial
1. So speichern und laden Sie Modelle in Torch1. Speichern und laden Sie Modellparameter und Modellstrukturenrrree
2 Laden des Modells – Diese Methode ist sicherer, aber etwas aufwändiger. 2. Probleme beim Speichern und Laden von Modellen im BrennerModell Beim Speichern wird der Pfad zur Modellstrukturdefinitionsdatei aufgezeichnet, dieser wird entsprechend dem Pfad analysiert und dann mit Parametern geladen. Wenn der Pfad zur Modelldefinitionsdatei geändert wird, wird ein Fehler gemeldet bei Verwendung von Torch.load(path).
Nach dem Ändern des Modellordners in „Modelle“ wird beim erneuten Laden ein Fehler gemeldet. 
torch.save(model,path) torch.load(path)
Damit Sie die vollständige Modellstruktur und die Parameter speichern, achten Sie darauf, den Pfad der Modelldefinitionsdatei nicht zu ändern .
.
2. Nach dem Speichern des Einzelkarten-Trainingsmodells auf einem Computer mit mehreren Karten wird beim Laden auf einem Computer mit einer Karte ein Fehler gemeldet.
Beginnend bei 0 auf einem Computer mit mehreren Karten. Jetzt wird das Modell nach dem Speichern der Grafikkarte auf n>=1 trainiert torch.save(model.state_dict(),path)
model_state_dic = torch.load(path)
model.load_state_dic(model_state_dic)
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)3. Probleme, die auftreten, wenn Multi-Card-Trainingsmodelle die Modellstruktur und -parameter speichern und dann laden.
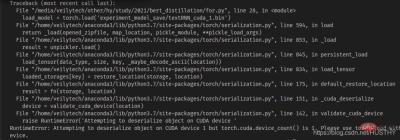 Nach dem Training des Modells mit mehreren GPUs gleichzeitig, unabhängig davon, ob die Modellstruktur und -parameter zusammen oder das Modell gespeichert werden Die Parameter werden separat gespeichert und dann unter einer einzigen Karte. Beim Laden von
Nach dem Training des Modells mit mehreren GPUs gleichzeitig, unabhängig davon, ob die Modellstruktur und -parameter zusammen oder das Modell gespeichert werden Die Parameter werden separat gespeichert und dann unter einer einzigen Karte. Beim Laden von
a treten Probleme auf. Speichern Sie die Modellstruktur und die Parameter zusammen und verwenden Sie dann beim Laden des
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)Modelltrainings die oben beschriebene Mehrprozessmethode, also müssen Sie Deklarieren Sie es auch beim Laden, andernfalls wird ein Fehler gemeldet. b. Das separate Speichern von Modellparametern
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
 führt ebenfalls zu Problemen, aber das Problem besteht darin, dass sich der Schlüssel des Parameterwörterbuchs von dem vom Modell definierten Schlüssel unterscheidet. Der Grund dafür ist, dass unter Multi-GPU Training, verteiltes Training wird verwendet. Das Modell wird irgendwann gepackt, und der Code lautet wie folgt:
führt ebenfalls zu Problemen, aber das Problem besteht darin, dass sich der Schlüssel des Parameterwörterbuchs von dem vom Modell definierten Schlüssel unterscheidet. Der Grund dafür ist, dass unter Multi-GPU Training, verteiltes Training wird verwendet. Das Modell wird irgendwann gepackt, und der Code lautet wie folgt: torch.distributed.init_process_group(backend='nccl')
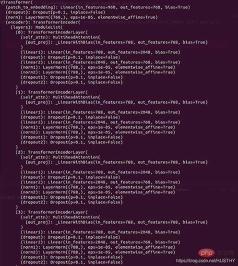
Die Modellstruktur vor dem Packen:
Das gepackte Modell
model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)
 Dies ist ein besseres Paradigma und es treten keine Fehler beim Laden auf.
Dies ist ein besseres Paradigma und es treten keine Fehler beim Laden auf.
【Verwandte Empfehlungen:
Python3-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonPraktische Aufzeichnungen einiger Probleme beim Speichern und Laden von Pytorch-Modellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AMPython zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AMPython eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AMWie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AM
Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AMLaden Sie Gurkendateien in Python 3.6 Umgebungsbericht Fehler: ModulenotFoundError: Nomodulennamen ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

