
Heim >Datenbank >MySQL-Tutorial >Lassen Sie uns darüber sprechen, wie Sie die Order By-Anweisung in SQL optimieren können
Lassen Sie uns darüber sprechen, wie Sie die Order By-Anweisung in SQL optimieren können

- 青灯夜游nach vorne
- 2022-09-27 13:45:272297Durchsuche
Wie optimiere ich die orderBy-Anweisung in SQL? Der folgende Artikel stellt Ihnen die Methode zur Optimierung der orderBy-Anweisung in SQL vor. Er hat einen guten Referenzwert und ich hoffe, er wird Ihnen hilfreich sein.

Wenn Sie eine Datenbank für die Datenabfrage verwenden, werden Sie unweigerlich auf die Notwendigkeit stoßen, die Abfrageergebnismenge basierend auf bestimmten Feldern zu sortieren. In SQL wird dazu normalerweise die Orderby-Anweisung verwendet. Platzieren Sie die zu sortierenden Felder nach dem Schlüsselwort. Wenn mehrere Felder vorhanden sind, verwenden Sie ",", um sie zu trennen.
select * from table t order by t.column1,t.column2;
Die obige SQL bedeutet, die Daten in der Tabelle abzufragen und sie dann nach Spalte 1 zu sortieren. Wenn Spalte 1 gleich ist, wird sie nach Spalte 2 sortiert. Die Standardsortiermethode ist absteigende Reihenfolge. Natürlich kann auch die Sortiermethode angegeben werden. Fügen Sie DESC und ASE nach dem sortierten Feld hinzu, um die absteigende bzw. aufsteigende Reihenfolge anzugeben.
Mit diesem Orderby können Sie problemlos tägliche Sortiervorgänge durchführen. Ich habe es oft verwendet und frage mich, ob Sie jemals auf dieses Szenario gestoßen sind: Manchmal ist die SQL-Ausführungseffizienz nach der Verwendung von orderby sehr langsam und manchmal schneller. Da ich den ganzen Tag von Quark besessen bin, tue ich das nicht. Ich habe keine Zeit, es zu studieren. Ich finde es einfach großartig. Während ich dieses Wochenende frei habe, wollen wir uns ansehen, wie orderby in MySQL implementiert wird.
Zur Vereinfachung der Beschreibung erstellen wir zunächst eine Datentabelle t1 wie folgt:
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
Und fügen Sie die Daten ein:
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
Um den Index wirksam zu machen, fügen Sie 10.000 Zeilen 7, 7, 7, irrelevante Daten ein. und wenn die Datenmenge klein ist, wird die gesamte Tabelle direkt gescannt
insert into t1 (a,b,c) values (7,7,7);
Wir müssen jetzt alle Datensätze mit a=1 finden und sie dann nach dem b-Feld sortieren.
Die Abfrage-SQL ist
select a,b,c from t1 where a = 1 order by b limit 2;
Um den vollständigen Tabellenscan während des Abfragevorgangs zu verhindern, haben wir einen Index für Feld a hinzugefügt.
Zuerst überprüfen wir den SQL-Ausführungsplan anhand der Anweisung
explain select a,b,c from t1 where a = 1 order by b lmit 2;
, wie unten gezeigt:

Zusätzlich können wir sehen, dass „Filesort verwenden“ angezeigt wird, was bedeutet, dass der Sortiervorgang während der Ausführung von SQL ausgeführt wird. Der Sortiervorgang wird in sort_buffer abgeschlossen, einem von MySQL jedem Thread zugewiesenen Speicherpuffer. Die Standardgröße beträgt 1 MB und seine Größe wird durch die Variable sort_buffer_size gesteuert.
Wenn MySQL Orderby implementiert, implementiert es zwei verschiedene Implementierungsmethoden entsprechend den unterschiedlichen Feldinhalten, die in sort_buffer eingefügt werden: vollständige Feldsortierung und Zeilen-ID-Sortierung.
Vollständige Feldsortierung
Betrachten wir zunächst den SQL-Ausführungsprozess als Ganzes anhand eines Bildes:
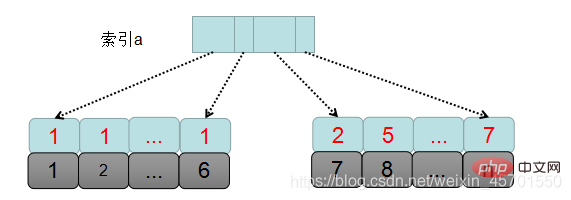
MySQL bestimmt zunächst den Datensatz, der sortiert werden muss, basierend auf den Abfragebedingungen, bei denen es sich um den Datensatz handelt mit a=1 in der Tabelle, d. h. diese Datensätze haben Primärschlüssel-IDs von 1 bis 6.
Der gesamte SQL-Ausführungsprozess ist wie folgt:
1 Erstellen und initialisieren Sie sort_buffer und bestimmen Sie die Felder, die im Puffer platziert werden müssen, dh die drei Felder a, b und c.
2. Finden Sie die erste Primärschlüssel-ID, die a=1 erfüllt, aus dem Indexbaum a, also id=1.
3. Kehren Sie zur Tabelle zum ID-Index zurück, nehmen Sie die gesamte Datenzeile heraus, nehmen Sie dann die Werte von a, b, c aus der gesamten Datenzeile heraus und legen Sie sie in sort_buffer ab.
4. Finden Sie die nächste Primärschlüssel-ID von a=1 in der Reihenfolge von Index a.
5. Wiederholen Sie die Schritte 3 und 4, bis der letzte Datensatz mit a=1 erhalten wurde, also die Primärschlüssel-ID=5.
6. Zu diesem Zeitpunkt werden die Felder a, b und c aller Datensätze, die die Bedingung a = 1 erfüllen, gelesen und im sort_buffer abgelegt. Anschließend werden diese Daten nach dem Wert von b sortiert Methode ist die schnelle Sortierung. Es handelt sich um die schnelle Sortierung, die häufig in Vorstellungsgesprächen anzutreffen ist, und die zeitliche Komplexität der schnellen Sortierung beträgt log2n.
7. Nehmen Sie dann die ersten beiden Datenzeilen aus der sortierten Ergebnismenge heraus.
Das Obige ist der Ausführungsprozess von orderby in msql. Da es sich bei den in sort_buffer abgelegten Daten um alle Felder handelt, die ausgegeben werden müssen, wird diese Sortierung als vollständige Sortierung bezeichnet.
Ich frage mich, ob Sie Fragen haben, nachdem Sie das gesehen haben? Was soll ich tun, wenn die zu sortierende Datenmenge groß ist und der sort_buffer nicht hineinpasst?
Wenn es viele Datenzeilen mit a = 1 gibt und viele Felder in sort_buffer gespeichert werden müssen, müssen einige Unternehmen möglicherweise mehr als drei Felder a, b und c ausgeben mehr Felder. Dann kann der sort_buffer mit einer Standardgröße von nur 1 MB dies möglicherweise nicht aufnehmen.
Wenn sort_buffer es nicht aufnehmen kann, erstellt MySQL einen Stapel temporärer Festplattendateien, um das Sortieren zu unterstützen. Standardmäßig werden 12 temporäre Dateien erstellt und die zu sortierenden Daten werden in 12 Teile unterteilt. Jeder Teil wird separat sortiert, um 12 interne Datendateien zu bilden, und diese 12 geordneten Dateien werden dann zu einer geordneten Datei zusammengeführt . Große Dateien und schließlich die Sortierung der Daten abschließen.
Dateibasierte Sortierung ist viel weniger effizient als speicherbasierte Sortierung. Um die Effizienz der Sortierung zu verbessern, sollte die dateibasierte Sortierung so weit wie möglich vermieden werden Erlauben Sie sort_buffer, das zu sortierende Datenvolumen aufzunehmen.
Daher wurde MySQL für Situationen optimiert, in denen sort_buffer es nicht unterstützen kann. Dies dient dazu, die Anzahl der beim Sortieren in sort_buffer gespeicherten Felder zu reduzieren.
Die spezifische Optimierungsmethode ist die folgende RowId-Sortierung
RowId 排序
在全字段排序实现中,排序的过程中,要把需要输出的字段全部放到sort_buffer中,当输出的字段比较多的时候,可以放到sort_buffer中的数据行就会变少。也就增大了sort_buffer无法容纳数据的风险,直至出现基于文件的排序。
rowId排序对全字段排序的优化手段,主要是减少了放到sort_buffer中字段个数。
在rowId排序中,只会将需要排序的字段和主键Id放到sort_buffer中。
select a,b,c from t1 where a = 1 order by b limit 2;
在rowId的排序中的执行流程如下:
1.初始化并创建sort_buffer,并确认要放入的的字段,id和b。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表主键索引id,取出整行数据,从整行数据中取出id和b,存入sort_buffer中。
4.从索引a中取出下一条满足a=1的 记录的主键id。
5.重复步骤3和4,直到最后一个满足a=1的主键id,也就是a=6。
6.对sort_buffer中的数据,按照字段b排序。
7.从sort_buffer中的有序数据集中,取出前2个,因为此时取出的数据只有id和b,要想获取a和c字段,需要根据id字段,回表到主键索引中取出整行数据,从整行数据中获取需要的数据。
根据rowId排序的执行步骤,可以发现:相比全字段排序,rowId排序的实现方式,减少了存放到sort_buffer中的数据量,降低了基于文件的外部排序的可能性。
那rowid排序有不足的地方吗?肯定有的,要不然全字段排序就没有存在的意义了。rowid排序不足之处在于,在最后的步骤7中,增加了回表的次数,不过这个回表的次数,取决于limit后的值,如果返回的结果集比较小的话,回表的次数还是比较小的。
mysql是如何在全字段排序和rowId排序的呢?其实是根据存放的sort_buffer中每行字段的长度决定的,如果mysql认为每次放到sort_buffer中的数据量很大的话,那么就用rowId排序实现,否则使用全字段排序。那么多大算大呢?这个大小的阈值有一个变量的值来决定,这个变量就是 max_length_for_sort_data。如果每次放到sort_buffer中的数据大小大于该字段值的话,就使用rowId排序,否则使用全字段排序。
orderby的优化
上面讲述了orderby的两种排序的方式,以及一些优化策略,优化的目的主要就是避免基于磁盘文件的外部排序。因为基于磁盘文件的排序效率要远低于基于sort_buffer的内存排序。
但是当数据量比较大的时候,即使sort_buffer比较大,所有数据全部放在内存中排序,sql的整体执行效率也不高,因为排序这个操作,本身就是比较消耗性能的。
试想,如果基于索引a获取到所有a=1的数据,按照字段b,天然就是有序的,那么就不用执行排序操作,直接取出来的数据,就是符合结果的数据集,那么sql的执行效率就会大幅度增长。
其实要实现整个sql执行过程中,避免排序操作也不难,只需要创建一个a和b的联合索引即可。
alter table t1 add index a_b (a,b);
添加a和b的联合索引后,sql执行流程就变成了:
1.从索引树(a,b)中找到第一个满足a=1的主键id,也就是id=1。
2.回表到主键索引树,取出整行数据,并从中取出a,b,c,直接作为结果集的一部分返回。
3.从索引树(a,b)上取出下一个满足a=1的主键id。
4.重复步骤2和3,直到找到第二个满足a=1的主键id,并回表获取字段a,b,c。
此时我们可以通过查看sql的执行计划,来判断sql的执行过程中是否执行了排序操作。
explain select a,b from t1 where a = 1 order by b lmit 2;

通过查看执行计划,我们发现extra中已经没有了using filesort了,也就是没有执行排序操作了。
其实还可以通过覆盖索引,对该sql进一步优化,通过在索引中覆盖字段c,来避免回表的操作。
alter table t1 add index a_b_c (a,b,c);
添加索引a_b_c后,sql的执行过程如下:
1.从索引树(a,b,c)中找到第一个满足a=1的索引,从中取出a,b,c。直接作为结果集的一部分直接返回。
2.从索引(a,b,c)中取出下一个,满足a=1的记录作为结果集的一部分。
3.重复执行步骤2,直到查到第二个a=1或者不满足a=1的记录。
此时通过查看执行sql的的还行计划可以发现 extra中只有 Using index。
explain select a,b from t1 where a = 1 order by b lmit 2;

Zusammenfassung
Durch mehrere Optimierungen dieses SQL entspricht die endgültige Ausführungseffizienz von SQL im Wesentlichen der Abfrageeffizienz von gewöhnlichem SQL ohne Sortierung. Der Grund, warum die Orderby-Sortieroperation vermieden werden kann, besteht darin, die natürlich geordneten Eigenschaften des Index zu nutzen.
Aber wir alle wissen, dass Indizes die Abfrageeffizienz beschleunigen können, aber das Hinzufügen und Ändern von Daten in der Datentabelle erfordert Indexänderungen. Je mehr Indizes es gibt, desto besser. Manchmal lohnt es sich nicht, sie hinzuzufügen Zu viele Indizes, nur wegen einiger ungewöhnlicher Abfragen und Sortierungen.
【Verwandte Empfehlung: MySQL-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonLassen Sie uns darüber sprechen, wie Sie die Order By-Anweisung in SQL optimieren können. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ausführliche Erläuterung der Verwendung von MySQL-Deadlocks sowie der Erkennungs- und Vermeidungsmethoden
- SQL Server-Wiederherstellungsprozess für vollständige Sicherung und differenzielle Sicherung
- Zusammenfassung der Verwendung von Sequence Sequence in MySQL
- Ein Artikel über den internen Implementierungsmechanismus der MySQL-Sperre
- Beeinträchtigung der Verwendung des Hash-Joins durch den MySQL-Optimierer