
Verstehen Sie die Fensterfunktion in SQL in einem Artikel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-09-02 16:55:483886Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über SQL-Server. Es gibt zwei Arten von Fensterfunktionen, die auch als Aggregationsfensterfunktionen bezeichnet werden, und die andere ist die Sortierfensterfunktion, die ich hauptsächlich vorgestellt habe Der Artikel stellt die relevanten Informationen zur Fensterfunktion in SQL ausführlich anhand von Beispielcode vor.

Empfohlene Studie: „SQL-Tutorial“
Definition von OVER
OVER wird verwendet, um ein Fenster für eine Zeile zu definieren, das mit einer Reihe von Werten arbeitet. Es ist nicht erforderlich, die GROUP BY-Klausel zu verwenden zum Gruppieren von Daten. Möglichkeit, sowohl Basiszeilenspalten als auch aggregierte Spalten in derselben Zeile zurückzugeben.
OVER-Syntax
OVER ( [ PARTITION BY-Spalte ] [ ORDER BY-Klausel ] )
PARTITION BY-Klausel zum Gruppieren;
ORDER BY-Klausel zum Sortieren.
Die Fensterfunktion OVER() gibt eine Reihe von Zeilen an, und die Fensterfunktion berechnet den Wert jeder Zeile in der von der Fensterfunktion ausgegebenen Ergebnismenge.
Die Fensterfunktion kann Daten ohne Verwendung von GROUP BY gruppieren und gleichzeitig die Spalten der Basiszeile und der aggregierten Spalte zurückgeben.
Verwendung der OVER-Fensterfunktion muss zusammen mit der Aggregationsfunktion oder der Sortierfunktion verwendet werden. Die Aggregationsfunktion bezieht sich im Allgemeinen auf allgemeine Funktionen wie SUM(), MAX(), MIN, COUNT(), AVG() usw. Sortierfunktionen beziehen sich im Allgemeinen auf RANK(), ROW_NUMBER(), DENSE_RANK(), NTILE() usw.
Beispiele für die Verwendung von OVER in Aggregatfunktionen
Wir verwenden die Funktionen SUM und COUNT als Beispiele, um es Ihnen zu demonstrieren.
--建立测试表和测试数据
CREATE TABLE Employee
(
ID INT PRIMARY KEY,
Name VARCHAR(20),
GroupName VARCHAR(20),
Salary INT
)
INSERT INTO Employee
VALUES(1,'小明','开发部',8000),
(4,'小张','开发部',7600),
(5,'小白','开发部',7000),
(8,'小王','财务部',5000),
(9, null,'财务部',NULL),
(15,'小刘','财务部',6000),
(16,'小高','行政部',4500),
(18,'小王','行政部',4000),
(23,'小李','行政部',4500),
(29,'小吴','行政部',4700);Die Fensterfunktion nach SUM
SELECT *,
SUM(Salary) OVER(PARTITION BY Groupname) 每个组的总工资,
SUM(Salary) OVER(PARTITION BY groupname ORDER BY ID) 每个组的累计总工资,
SUM(Salary) OVER(ORDER BY ID) 累计工资,
SUM(Salary) OVER() 总工资
from Employee(Tipp: Sie können den Code nach links und rechts schieben)
Die Ergebnisse sind wie folgt:
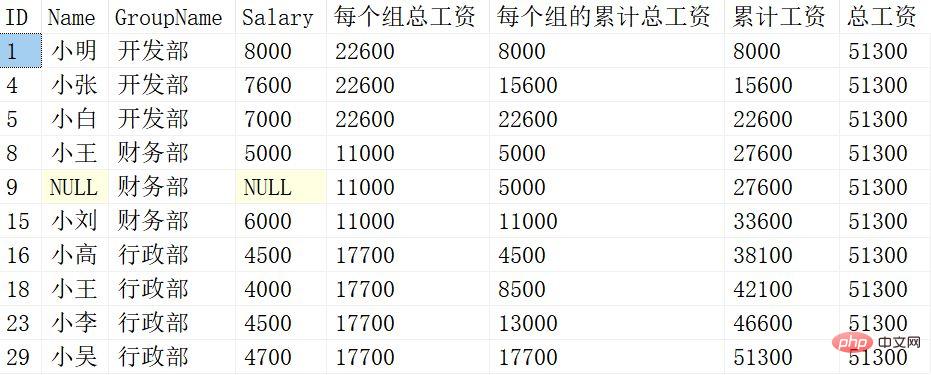 Die Bedeutung jeder Fensterfunktion ist unterschiedlich. Lassen Sie uns sie im Detail erklären :
Die Bedeutung jeder Fensterfunktion ist unterschiedlich. Lassen Sie uns sie im Detail erklären :
Gruppieren Sie nur die Spalte Gruppenname nach PARTITION BY und lösen Sie die Summe des Gehalts nach der Gruppierung.
SUM(Gehalt) OVER (PARTITION BY Gruppenname ORDER BY ID)Gruppieren Sie die Spalte Gruppenname nach PARTITION BY, sortieren Sie dann nach der ID nach ORDER BY und führen Sie dann die kumulative Verarbeitung des Gehalts innerhalb der Gruppe durch.
SUM(Gehalt) OVER (ORDER BY ID)Sortieren Sie den ID-Inhalt nur nach ORDER BY und akkumulieren Sie das sortierte Gehalt.
SUM(Gehalt) OVER ()Die Fensterfunktion nach dem Zusammenfassen des Gehalts
COUNT
SELECT *,
COUNT(*) OVER(PARTITION BY Groupname ) 每个组的个数,
COUNT(*) OVER(PARTITION BY Groupname ORDER BY ID) 每个组的累积个数,
COUNT(*) OVER(ORDER BY ID) 累积个数 ,
COUNT(*) OVER() 总个数
from EmployeeDas zurückgegebene Ergebnis ist wie folgt:
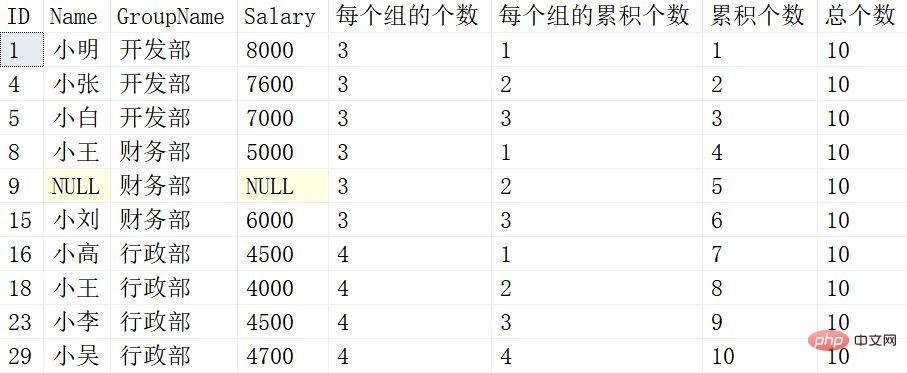 Bei jeder weiteren Fensterung werden die Funktionen nicht mehr angezeigt sein einzeln interpretiert. Sie können sie einzeln mit der Fensterfunktion nach SUM oben vergleichen.
Bei jeder weiteren Fensterung werden die Funktionen nicht mehr angezeigt sein einzeln interpretiert. Sie können sie einzeln mit der Fensterfunktion nach SUM oben vergleichen.
Beispiele für die Verwendung von OVER in Sortierfunktionen
Wir demonstrieren die vier Sortierfunktionen einzeln
--先建立测试表和测试数据 WITH t AS (SELECT 1 StuID,'一班' ClassName,70 Score UNION ALL SELECT 2,'一班',85 UNION ALL SELECT 3,'一班',85 UNION ALL SELECT 4,'二班',80 UNION ALL SELECT 5,'二班',74 UNION ALL SELECT 6,'二班',80 ) SELECT * INTO Scores FROM t; SELECT * FROM Scores
ROW_NUMBER()
Definition: Die Funktion der Funktion ROW_NUMBER() besteht darin, die von SELECT abgefragten Daten zu sortieren Eine fortlaufende Nummer zu einem Datenelement kann nicht zur Einstufung der Schülerergebnisse verwendet werden. Sie wird im Allgemeinen für Seitenabfragen verwendet, z. B. für die Abfrage der Top 10 und der Abfrage von 10 bis 100 Schülern. ROW_NUMBER() muss zusammen mit ORDER BY verwendet werden, sonst wird ein Fehler gemeldet. Studentenergebnisse sortieren
SELECT *, ROW_NUMBER() OVER (PARTITION BY ClassName ORDER BY SCORE DESC) 班内排序, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores;
Die Ergebnisse sind wie folgt:
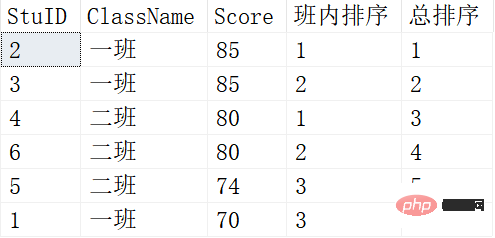 Die Funktionen von PARTITION BY und ORDER BY sind hier dieselben wie die Aggregatfunktionen, die wir oben gesehen haben, und sie werden zum Gruppieren und Sortieren verwendet.
Die Funktionen von PARTITION BY und ORDER BY sind hier dieselben wie die Aggregatfunktionen, die wir oben gesehen haben, und sie werden zum Gruppieren und Sortieren verwendet.
Darüber hinaus kann die Funktion ROW_NUMBER() auch Daten in einer bestimmten Reihenfolge übernehmen.
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores ) t WHERE t.总排序=2;
Die Ergebnisse sind wie folgt:
 RANK()
RANK()
Definition: Die RANK()-Funktion ist, wie der Name schon sagt, eine Ranking-Funktion, die ein bestimmtes Feld bewerten kann ROW_NUMBER()? ROW_NUMBER() sortiert. Wenn es Schüler mit denselben Noten gibt, sortiert ROW_NUMBER() sie der Reihe nach. Ihre Seriennummern sind unterschiedlich, aber Rank() ist unterschiedlich. Wenn sie gleich aussehen, sind ihre Rankings gleich. Schauen wir uns das folgende Beispiel an:
Beispiel
SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
Ergebnis:
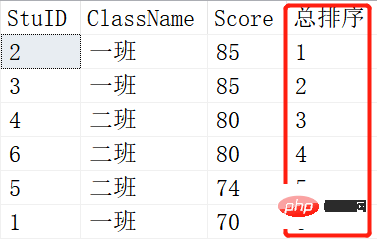
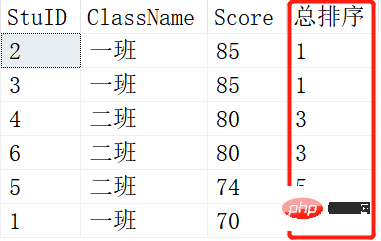 Das obere Bild ist das Ergebnis von ROW_NUMBER() und das untere Bild ist das Ergebnis von RANK(). Wenn zwei Schüler die gleichen Noten haben, gibt es eine Änderung. RANK() ist 1-1-3-3-5-6, während ROW_NUMBER() immer noch 1-2-3-4-5-6 ist. Dies ist der Unterschied zwischen RANK() und ROW_NUMBER().
Das obere Bild ist das Ergebnis von ROW_NUMBER() und das untere Bild ist das Ergebnis von RANK(). Wenn zwei Schüler die gleichen Noten haben, gibt es eine Änderung. RANK() ist 1-1-3-3-5-6, während ROW_NUMBER() immer noch 1-2-3-4-5-6 ist. Dies ist der Unterschied zwischen RANK() und ROW_NUMBER().
DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?特别是对于有成绩相同的情况,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,一般情况下用的排名函数就是RANK() 我们看例子:
示例
SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT DENSE_RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果如下:
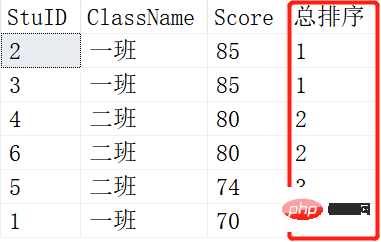
上面是RANK()的结果,下面是DENSE_RANK()的结果
NTILE()
定义:NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的'分区'一样 ,分为几个区,一个区会有多少个。
SELECT *,NTILE(1) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(2) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(3) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores;
结果如下:
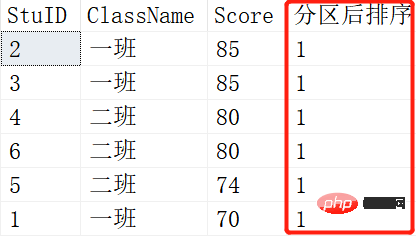
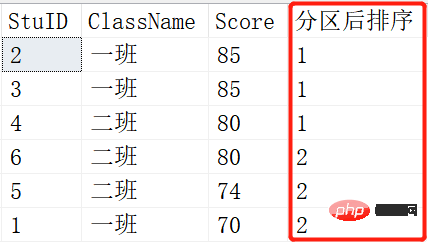
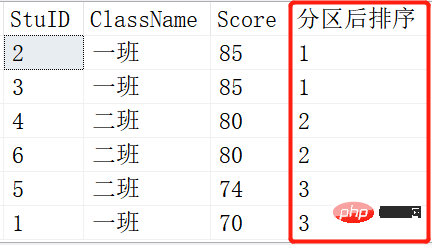
就是将查询出来的记录根据NTILE函数里的参数进行平分分区。
总结
OVER开窗函数是我们工作中经常要使用到的,特别是在做数据分析计算的时候,经常要对数据进行分组排序。上面我们额外介绍了聚合函数和排序函数的与OVER结合的使用方法,此外还有很多与OVER一起使用的函数,比如LEAD函数,LAG函数,STRING_AGG函数等等都会使用到开窗函数OVER,其使用方法也要务必掌握。
推荐学习:《SQL教程》
Das obige ist der detaillierte Inhalt vonVerstehen Sie die Fensterfunktion in SQL in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- SQL Server verwendet CROSS APPLY und OUTER APPLY, um Verbindungsabfragen zu implementieren
- Was ist der Unterschied zwischen MySQL-Speicher-Engines?
- Beispiele für Methoden für SQL Server zum Parsen/Bearbeiten von Felddaten im Json-Format
- So zeigen Sie den Ausführungsplan in MySQL an
- Was ist der 10061-Fehler von MySQL?