
Zusammenfassung und gemeinsame Nutzung der drei Cluster-Modi von Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-08-31 17:54:382081Durchsuche

Empfohlenes Lernen: Redis-Video-Tutorial
Drei Cluster-Modi
- Redis verfügt über drei Cluster-Modi, von denen Master-Slave der häufigste Modus ist.
- Sentinel Der Sentinel-Modus wurde entwickelt, um die Komplexität der Master-Slave-Umschaltung auszugleichen, nachdem der Host im Master-Slave-Replikationscluster ausgefallen ist. Wie der Name schon sagt, wird Sentinel zur Überwachung verwendet. Seine Hauptfunktion besteht darin, den Master-Slave-Cluster zu überwachen, automatisch zwischen Master und Slave umzuschalten und ein Cluster-Failover durchzuführen.
- Cluster-Modus ist der offiziell von Redis bereitgestellte Cluster-Modus. Er nutzt die Sharding-Technologie, um nicht nur eine hohe Verfügbarkeit, Lese- und Schreibtrennung, sondern auch einen echten verteilten Speicher zu erreichen.
1. Master-Slave-Replikation
Redis Master-Slave-Modus
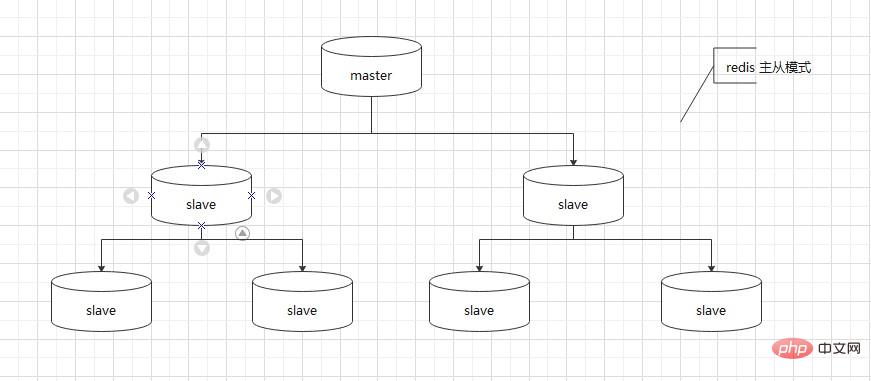 2. Redis-Replikation ist in zwei Teile unterteilt Teile, Operationssynchronisierung (SYNC)) und Befehlsweitergabe
2. Redis-Replikation ist in zwei Teile unterteilt Teile, Operationssynchronisierung (SYNC)) und Befehlsweitergabe
Synchronisierung (SYNC) wird verwendet, um den Status des Slave-Servers so zu aktualisieren, dass er mit dem des Master-Servers übereinstimmt. Die umgangssprachliche Erklärung besteht darin, die Daten des Hauptservers aktiv vom Server abzurufen. Halten Sie Ihre Daten konsistent. Die spezifische Implementierung besteht darin, dass der Master-Server nach Erhalt des SYNC-Befehls eine RDB-Snapshot-Datei generiert und diese dann an den Slave-Server sendet.
Befehlsweitergabe wird zum Weitergeben von Befehlen verwendet, um den Slave-Server mit dem Status des Master-Servers konsistent zu halten, nachdem die Daten des Master-Servers geändert wurden und der Master-Slave inkonsistent ist. Die umgangssprachliche Erklärung lautet: Nachdem der Master-Server den Datenänderungsbefehl des Clients empfangen hat, ändern sich die Datenbankdaten und der Befehl wird zwischengespeichert. Anschließend wird der zwischengespeicherte Befehl an den Slave-Server gesendet. Der Slave-Server erreicht durch Laden die Master-Slave-Datenkonsistenz der zwischengespeicherte Befehl. Dies wird als Befehlsweitergabe bezeichnet.
Warum es zwei Arten von Replikationsvorgängen gibt: Synchronisierung und Befehlsweitergabe: Wenn es nur einen Synchronisierungsvorgang gibt und der Slave-Server den SYNC-Befehl an den Master-Server sendet, empfängt der Master-Server beim Generieren der RDB weiterhin die Befehlsänderung des Clients Snapshot-Datei. Wenn dieser Teil der Daten nicht an den Slave-Server übermittelt werden kann, sind die Master-Slave-Daten inkonsistent. Zu diesem Zeitpunkt erfolgt die Befehlsweitergabe, nachdem der Master-Server den SYNC-Befehl vom Slave-Server empfangen hat, eine RDB-Snapshot-Datei generiert, die in diesem Zeitraum empfangenen Befehle zwischenspeichert und sie dann mithilfe der Befehlsweitergabe an den Slave-Server sendet . Um eine Master-Slave-Datenkonsistenz zu erreichen.
- 3. Prinzip der Redis-Master-Slave-Replikation
- Die beiden Vorgänge der Redis-Replikation werden oben vorgestellt, und die Redis-Master-Slave-Replikation wird offiziell basierend auf Synchronisierung und Befehlsweitergabe implementiert. Die folgenden zwei Bilder zeigen den Prozess der Redis-Replikation:
4. Vor- und Nachteile der Redis-Master-Slave-Replikation
Vorteile: 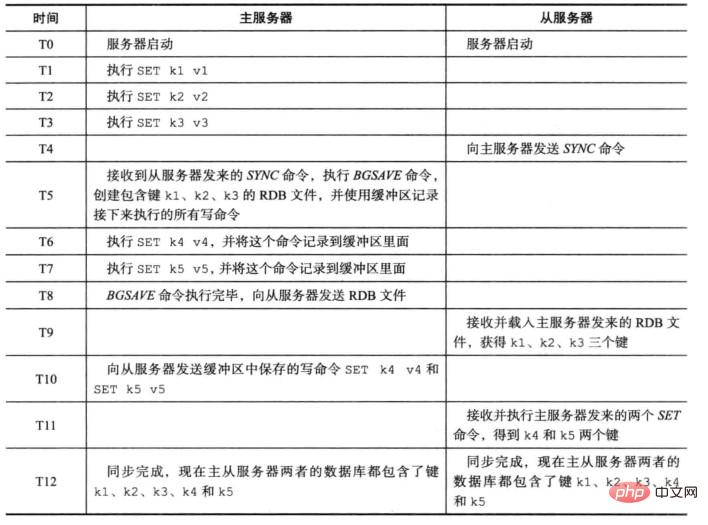
Nachteile:
1. Während der Master-Ausfallzeit müssen Sie den Host manuell wechseln. Gleichzeitig können einige Daten nicht rechtzeitig mit dem Slave-Server synchronisiert werden, was zu Dateninkonsistenzen führt (manuelles Eingreifen ist erforderlich) 2 . Nachdem der Slave ausgefallen ist, verdoppelt eine große Anzahl von SYNC-Synchronisationen den Master-E/A-Druck (die Startzeit kann manuell vermieden werden) 3. Zusammenfassung: Die Vorteile der Redis-Master-Slave-Replikation sind hauptsächlich die verbesserte Verfügbarkeit 2. Sentinel-Modus Sentinel Sentinel Einführung in Sentinel Sentinel ist im Wesentlichen eine Redis-Instanz, die in einem speziellen Modus ausgeführt wird, nur der Initialisierung Der Prozess und die Arbeit unterscheiden sich von gewöhnlichem Redis und es handelt sich im Wesentlichen um einen separaten Prozess. Sentinel ist eine hochverfügbare Lösung für Redis: Ein Sentinel-System (System), das aus einer oder mehreren Sentinel-Instanzen (Instanzen) besteht, kann eine beliebige Anzahl von Master-Servern sowie alle Slave-Server unter diesen Master-Servern überwachen und überwachen Wenn der Server offline geht, kann er automatisch vom Slave-Server zum Master-Server wechseln.1. Sentinel-System
Die folgende Abbildung ist ein einfaches Sentinel-System-Architekturdiagramm. Ein Sentinel-System überwacht einen Master-Slave-Cluster, wobei Server1 der Redis-Master-Server und Server2/3/4 Redis-Slave-Server sind. Die obige Master-Slave-Replikation wird zwischen Master und Slave verwendet, um Master-Slave-Konsistenz zu erreichen. Das Sentinel-System überwacht den gesamten Master-Slave-Cluster.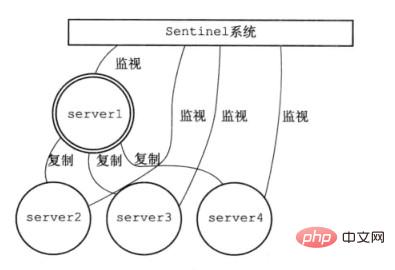
2. Sentinel-Failover
Wenn das Sentinel-System erkennt, dass der Hauptserver von Server1 offline ist, beendet es die Replikation von Server2/3/4.
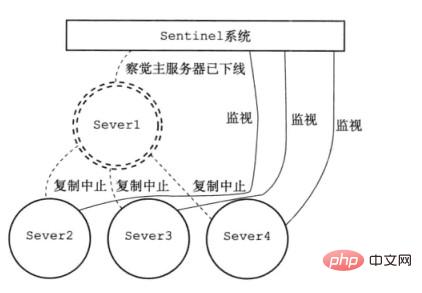
Gleichzeitig aktualisiert Sentinel Server2 zum Hauptserver und Server3/4 repliziert vom neuen Hauptserver. Warten Sie gleichzeitig, bis Server1 wieder online ist.
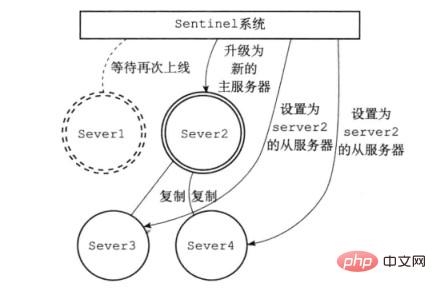
Das Sentinel-System kann den Hauptdienst auch aktiv auf einen Slave-Server herabstufen und den Slave-Server auf den Master-Server hochrüsten.
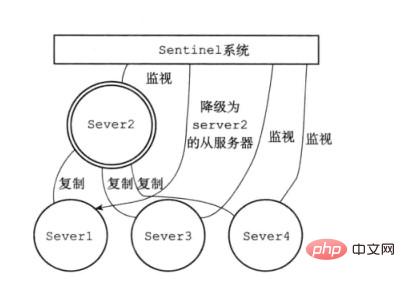
2.1. Sentinel-Überwachungsprozess
Sentinel-Überwachungsclusterprozess:
- Befehl Sentinel sendet einen Befehl, um den Redis-Server wieder in den Betriebszustand zu versetzen. Veröffentlichen und abonnieren Wenn sich der Status des Master-Servers ändert, benachrichtigt Sentinel andere Slave-Server über den
- Veröffentlichungs- und Abonnementmodus.
2.2. Sentinel-Failover:
1. Die Sentinel-Instanz im Sentinel-System sendet jede Sekunde einen PING-Befehl 2. Wenn eine Antwort an Sentinel vorliegt Instanz im Cluster Wenn die Instanzzeit länger als Millisekunden ist, ist die Sentinel-Instanz, die den PING-Befehl sendet, subjektiv offline- 3. Wann wird sie also objektiv offline sein? Andere Instanzen im Sentinel-System müssen bestätigen, dass der Instanz-Supervisor im Cluster offline ist.
- Wenn der Master-Server als subjektiv offline markiert ist, muss der Sentinel-Prozess, der den Master im Sentinel-System überwacht, einmal pro Sekunde bestätigen, ob der Master in den Supervisor-Offline-Status wechselt
- 4. Wenn genügend Sentinel-Instanzen vorhanden sind (abhängig von der Konfiguration). ) Bestätigen Sie, dass der Master den Überwachungsmodus offline betreten hat. Anschließend wird der Master als objektiv offline markiert.
3. Vor- und Nachteile von Sentinel: 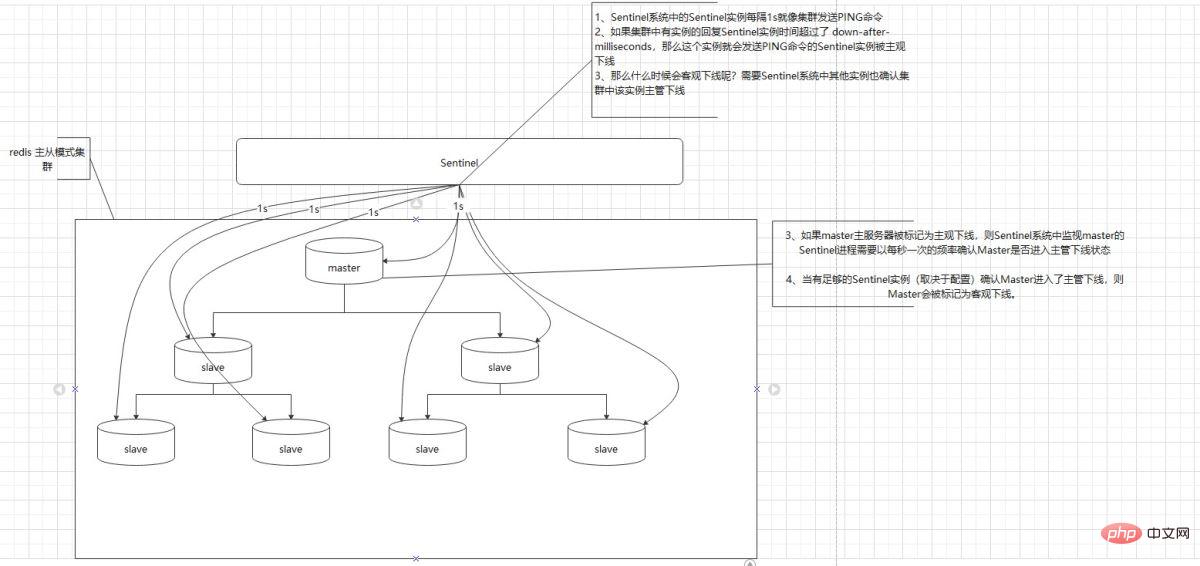
Nachteile:
1. Die Online-Erweiterung ist schwieriger zu unterstützen.
Zusammenfassung:
Sentinel wird hauptsächlich zur Überwachung des Redis-Master-Slave-Clusters und zur Verbesserung der Verfügbarkeit des Redis-Master-Slave-Clusters verwendet. 3. Cluster-ModusRedis-Cluster1. Redis-Cluster ist eine Server-Sharding-Technologie und Redis-Version 3.0 ist offiziell verfügbar.
Sentinel hat grundsätzlich eine hohe Verfügbarkeit erreicht, aber jede Maschine speichert den gleichen Inhalt, was Speicher verschwendet, sodass Redis Cluster verteilten Speicher implementiert. Auf jedem Maschinenknoten werden unterschiedliche Inhalte gespeichert.
2. Redis-Cluster-Daten-Sharding-Prinzip: Der Redis-Cluster verfügt über 16384 Hash-Slots, nachdem die CRC16-Verifizierung bestanden wurde. Beim Zugriff auf den Redis-Schlüssel erhält Redis ein Ergebnis basierend auf dem CRC16-Algorithmus, berechnet dann den Rest des Ergebnisses und 16384 und verwendet diesen Wert, um die Daten vom entsprechenden Knoten abzurufen. Zu diesem Zeitpunkt muss der Anwendungsclient tatsächlich nur eine Verbindung zu einem der Knoten herstellen, und dann speichert jeder Knoten im Redis-Cluster die Slot-Informationen anderer Knoten. Auf diese Weise werden nach der Berechnung des Steckplatzes durch den Zugriffsschlüssel die Knoteninformationen aus der Konfiguration durch Speichern der Steckplatzinformationen abgerufen und anschließend der entsprechende Knoten abgerufen, um die Daten zu erhalten.
3. Redis-Cluster-Replikationsprinzip: Ein Master-Knoten entspricht einem oder mehreren Slave-Knoten. Wenn andere Master-Knoten einen Master-Knoten A anpingen und mehr als die Hälfte der Master-Knoten mit A kommunizieren, kommt es zu einer Zeitüberschreitung, dann gilt der Master-Knoten A als ausgefallen. Wenn sowohl Master-Knoten A als auch sein Slave-Knoten A1 ausfallen, kann der Cluster keine Dienste mehr bereitstellen
Redis-Video-Tutorial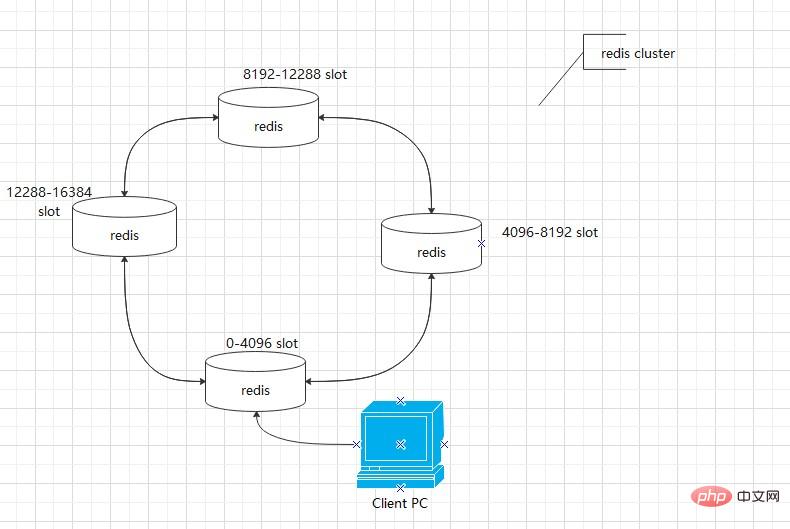
Das obige ist der detaillierte Inhalt vonZusammenfassung und gemeinsame Nutzung der drei Cluster-Modi von Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wird die Installation von Redis auf Docker unterstützt?
- Der Unterschied zwischen der Strategie zur Speicherbeseitigung von Redis und der Strategie zur abgelaufenen Löschung
- Lassen Sie uns darüber sprechen, wie Sie Redis in ThinkPHP6 verwenden
- Lassen Sie uns kurz über zwei Lösungen für Redis sprechen, um mit Schnittstellen-Idempotenz umzugehen.
- Ursachenanalyse: verzögertes doppeltes Löschen des Redis-Cache