
Heim >Datenbank >MySQL-Tutorial >Lassen Sie uns über die MySQL-Indexstruktur sprechen
Lassen Sie uns über die MySQL-Indexstruktur sprechen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-08-31 17:49:262232Durchsuche

Empfohlenes Lernen: MySQL-Video-Tutorial
Einführung
Zusätzlich zu den Daten verwaltet das Datenbanksystem auch Datenstrukturen, die bestimmte Suchalgorithmen erfüllen. Diese Datenstrukturen verweisen auf die Daten in irgendeiner Weise. sodass erweiterte Suchalgorithmen für diese Datenstrukturen implementiert werden können. Diese Datenstruktur ist ein Index.
Im Allgemeinen ist auch der Index selbst sehr groß und kann nicht vollständig im Speicher gespeichert werden. Daher wird der Index häufig in Form einer Indexdatei auf der Festplatte gespeichert.
Vorteile:
1. Ähnlich wie beim Aufbau eines bibliografischen Indexes in einer Universitätsbibliothek verbessert es die Effizienz des Datenabrufs und reduziert die IO-Kosten der Datenbank.
2. Sortieren Sie Daten über Indexspalten, um die Kosten für die Datensortierung zu senken und den CPU-Verbrauch zu reduzieren.
Nachteile:
1. Obwohl der Index die Abfragegeschwindigkeit erheblich verbessert, verringert er auch die Geschwindigkeit der Aktualisierung der Tabelle, z. B. INSERT, UPDATE und DELETE in der Tabelle. Denn beim Aktualisieren der Tabelle muss MySQL nicht nur die Daten, sondern auch die Indexdatei speichern. Jedes Mal, wenn ein Feld aktualisiert wird, das eine Indexspalte hinzufügt, werden die Indexinformationen nach den durch die Aktualisierung verursachten Schlüsselwertänderungen angepasst.
2. Tatsächlich ist der Index auch eine Tabelle, die auf die Datensätze der Entitätstabelle verweist.
Indexbeispiel: (Baum verwenden). Struktur als Index)
Die linke Seite ist die Datentabelle mit insgesamt zwei Spalten und sieben Datensätzen. Die ganz linke Seite ist die physische Adresse des Datensatzes.
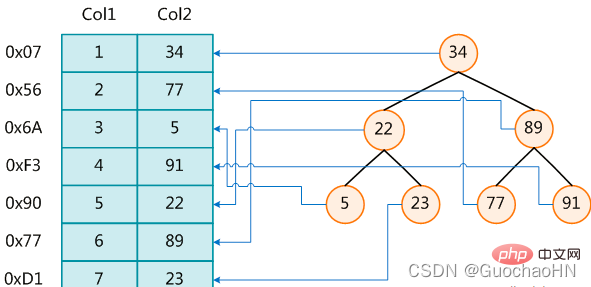
Um die Suche von Col2 zu beschleunigen, können Sie einen binären Suchbaum pflegen, wie rechts gezeigt. Jeder Knoten enthält den Indexschlüsselwert und einen Zeiger auf die physische Adresse des entsprechenden Datensatzes Sie können die binäre Suche verwenden, um entsprechende Daten innerhalb einer bestimmten Komplexität abzurufen und so schnell Datensätze abzurufen, die die Bedingungen erfüllen.
Indexstruktur (Baum)
Wie kann die Abfrage von Datenbanktabellen mithilfe von Indizes beschleunigt werden? Der Einfachheit halber beschränken wir die Datenbanktabelle auf die folgenden zwei Abfrageanforderungen:
1, wählen Sie * vom Benutzer aus, wobei die ID=1234 ist.
2, wählen Sie * vom Benutzer aus, wobei die ID>1234 und die ID< ;2345 ;(nach Intervall)
Warum Bäume anstelle von Hash-Tabellen verwenden?
Die Leistung der Hash-Tabellenabfrage nach Wert ist sehr gut, die Zeitkomplexität beträgt O(1), aber eine schnelle Datensuche kann nicht unterstützt werden nach Intervall , sodass die Anforderung nicht erfüllt werden kann. Auf die gleiche Weise ist die Abfrageleistung des ausgeglichenen binären Suchbaums zwar sehr hoch, die zeitliche Komplexität beträgt jedoch O (logn) und das Durchlaufen des Baums in der richtigen Reihenfolge kann eine geordnete Datensequenz ausgeben, die Anforderung kann jedoch nicht erfüllt werden Finden Sie schnell Daten nach Intervallen.
Um die schnelle Suche von Daten nach Intervallen zu unterstützen, transformieren wir den binären Suchbaum und verketten die Blattknoten des binären Suchbaums mit einer verknüpften Liste. Wenn Sie Daten in einem bestimmten Intervall finden möchten, müssen Sie dies nur tun Verwenden Sie den Startwert des Intervalls. Nachdem Sie einen Knoten in der geordneten verknüpften Liste gefunden haben, beginnen Sie mit diesem Knoten und durchlaufen Sie die geordnete verknüpfte Liste, bis der Knotendatenwert in der geordneten verknüpften Liste größer als das Intervallende ist Wert.
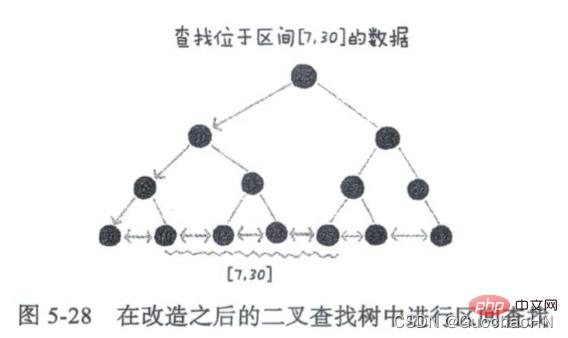
Und da die zeitliche Komplexität vieler Operationen am Baum proportional zur Höhe des Baums ist, kann eine Reduzierung der Baumhöhe die Festplatten-E/A-Operationen reduzieren. Daher bauen wir den Index in einen m-ary-Baum (m>2) ein. Weitere Informationen finden Sie im folgenden Artikel.
BTree-Index
Bevor wir B+-Bäume vorstellen, wollen wir zunächst B-Bäume verstehen.
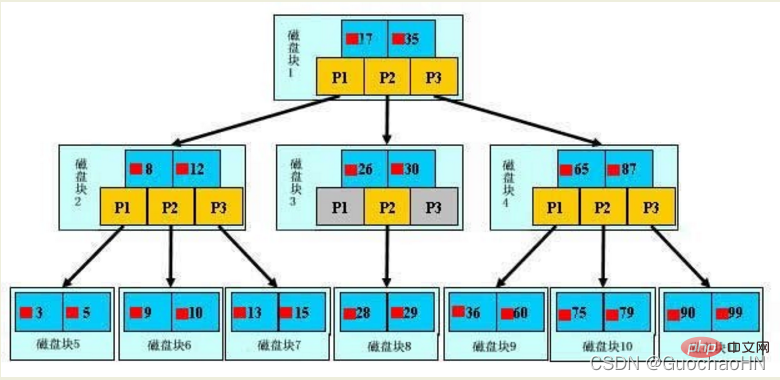
1. Einführung in die Initialisierung
Ein B-Baum, der hellblaue Block wird als Festplattenblock bezeichnet. Sie können sehen, dass jeder Festplattenblock mehrere Datenelemente (dargestellt in Dunkelblau) und Zeiger (dargestellt in) enthält gelb), zum Beispiel enthält Festplattenblock 1 die Datenelemente 17 und 35 sowie die Zeiger P1, P2 und P3. P1 steht für Plattenblöcke mit weniger als 17, P2 für Plattenblöcke zwischen 17 und 35 und P3 für Plattenblöcke mit mehr als 35.
Hinweis:
Echte Daten existieren nur in Blattknoten, nämlich 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. (Und es handelt sich um ein Datenintervall, das aus mehreren Datenelementen besteht: 3~5,...,90~99)
Nicht-Blattknoten speichern keine echten Daten, sondern nur Datenelemente, die die Suchrichtung bestimmen Beispielsweise existieren 17 und 35 nicht wirklich in der Datentabelle.
2. Suchvorgang
Wenn Sie das Datenelement 29 finden möchten, laden Sie zunächst den Datenträgerblock 1 von der Festplatte in den Speicher. Verwenden Sie zu diesem Zeitpunkt eine binäre Suche im Speicher, um festzustellen, ob 29 zwischen 17 und 35 liegt Sperren Sie den P2-Zeiger von Plattenblock 1. Die Speicherzeit ist vernachlässigbar, da sie sehr kurz ist (im Vergleich zu Platten-E/A). Plattenblock 3 wird über die Plattenadresse des P2-Zeigers von Plattenblock 1 von der Platte in den Speicher geladen. Die zweite E/A erfolgt und 29 liegt zwischen 26 und 30. Sperren Sie den P2-Zeiger von Plattenblock 3, laden Sie Plattenblock 8 über den Zeiger in den Speicher und führen Sie gleichzeitig eine binäre Suche durch Der Speicher muss 29 finden und die Abfrage wird insgesamt drei IOs beendet.
B+Tree-Index
Der B+-Baum ähnelt dem B-Baum und der B+-Baum ist eine verbesserte Version des B-Baums. Das heißt: Der durch den M-Fork-Suchbaum und die geordnete verknüpfte Liste gebildete Baum ist der B+-Baum, der der zu speichernde Baumindex ist
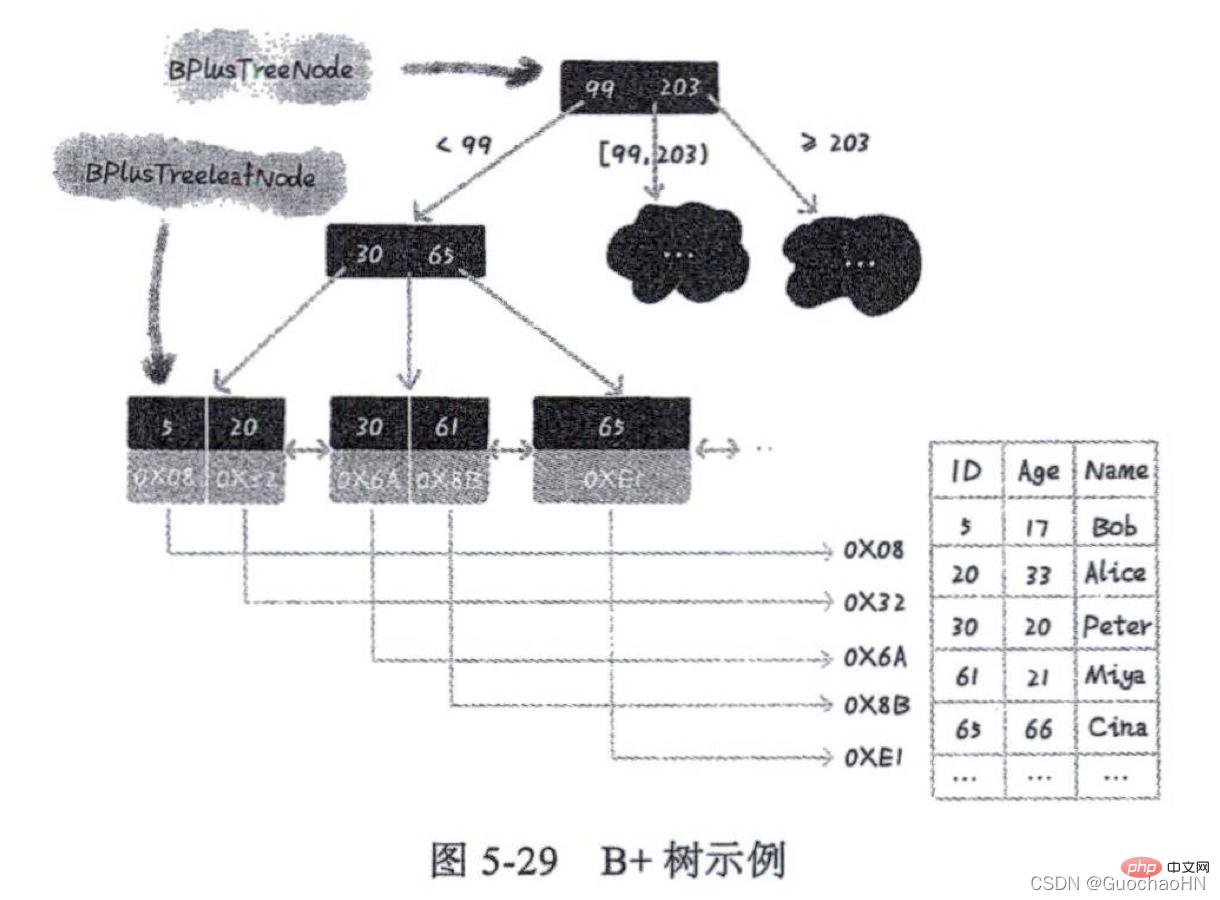
Wie in der Abbildung gezeigt: Die Hauptunterschiede zwischen dem B+-Baum und der B-Baum sind die folgenden zwei Punkte:
1. Die Blattknoten des B+-Baums sind mithilfe einer verknüpften Liste in Reihe verbunden. Um Daten in einem bestimmten Intervall zu finden, müssen Sie nur den Startwert des Intervalls für die Suche im Baum verwenden. Nachdem Sie einen Knoten in der geordneten verknüpften Liste gefunden haben, beginnen Sie bei diesem Knoten und durchlaufen Sie die geordnete verknüpfte Liste rückwärts bis zum Der Knotendatenwert in der geordneten verknüpften Liste ist größer als der Intervallendwert.
2. Jeder Knoten im B+-Baum speichert keine echten Daten, sondern wird nur zur Indizierung verwendet. Der B-Baum erhält Daten direkt über die Blattknoten; während jeder Blattknoten des B+-Baums die Schlüsselwert- und Adressinformationen der Datenzeile speichert, werden die tatsächlichen Dateninformationen über die Adresse des Blattknotens ermittelt .
Clustered-Index und Nicht-Clustered-Index
Clustered-Index ist kein separater Indextyp, sondern eine Datenspeichermethode. Der Begriff „geclustert“ bezieht sich auf die gemeinsame Speicherung von Datenzeilen und benachbarten Schlüsselwertclustern.
Vorteile des Clustered-Index:
Gemäß der Clustered-Index-Anordnungsreihenfolge muss die Datenbank beim Abfragen und Anzeigen eines bestimmten Datenbereichs keine Daten aus mehreren Datenblöcken extrahieren, da die Daten eng miteinander verbunden sind, wodurch eine Zeitersparnis entsteht viele IO-Operationen.
Einschränkungen des Clustered-Index:
1 Für MySQL-Datenbanken unterstützt derzeit nur die Innodb-Daten-Engine Clustered-Index, während Myisam keinen Clustered-Index unterstützt.
2. Da es nur eine physische Speichersortiermethode für Daten geben kann, kann jede MySQL-Tabelle nur einen Clustered-Index haben. Normalerweise ist es der Primärschlüssel der Tabelle.
3. Um die Clustering-Eigenschaften des Clustered-Index voll auszunutzen, ist es am besten, geordnete sequentielle IDs für die Primärschlüsselspalten der Innodb-Tabelle zu verwenden. Es wird nicht empfohlen, ungeordnete IDs wie uuid zu verwenden.
Wie in der Abbildung unten gezeigt, ist der Index links ein Clustered-Index, da die Anordnung der Datenzeilen auf der Festplatte mit der Indexsortierung übereinstimmt.
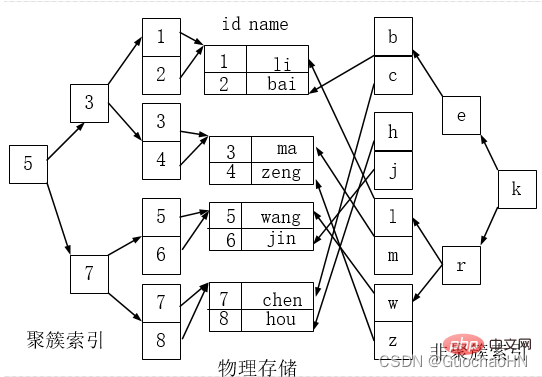
Indexklassifizierung
Einzelwertindex
Das heißt, ein Index enthält nur eine einzelne Spalte und eine Tabelle kann mehrere Einzelspaltenindizes haben
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); 单独建单值索引: CREATE INDEX idx_customer_name ON customer(customer_name); 删除索引: DROP INDEX idx_customer_name on customer;
Einzigartiger Index
Der Wert der Indexspalte muss eindeutig sein , aber Nullwerte sind zulässig
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); 单独建唯一索引: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); 删除索引: DROP INDEX idx_customer_no on customer ;
Primärschlüsselindex
Nach dem Festlegen des Primärschlüssels erstellt die Datenbank automatisch einen Index.
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); CREATE TABLE customer2 ( id INT(10) UNSIGNED , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); 单独建主键索引: ALTER TABLE customer add PRIMARY KEY customer(customer_no); 删除建主键索引: ALTER TABLE customer drop PRIMARY KEY ; 修改建主键索引: 必须先删除掉(drop)原索引,再新建(add)索引
Zusammengesetzter Index
Das heißt, ein Index enthält mehrere Spalten
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); 单独建索引: CREATE INDEX idx_no_name ON customer(customer_no,customer_name); 删除索引: DROP INDEX idx_no_name on customer ;
Leistungsanalyse
Indexerstellungsszenario
In welchen Situationen ist es notwendig, einen Index zu erstellen
1. Der Primärschlüssel erstellt automatisch einen eindeutigen Index
2 indiziert
3. Felder, die mit anderen Tabellen in der Abfrage und Fremdschlüsselbeziehungen verknüpft sind, werden indiziert
4. Das Problem der Schlüssel-/Kombinationsindexauswahl ist kostengünstiger
5 , wenn auf das Sortierfeld über den Index zugegriffen wird, wird die Sortiergeschwindigkeit erheblich verbessert
6. Statistiken oder Gruppierungsfelder in der Abfrage
In diesem Fall ist es nicht erforderlich, einen Index zu erstellen
1
2. Tabellen oder Felder, die häufig hinzugefügt, gelöscht oder geändert werden. Gründe: Es verbessert die Abfragegeschwindigkeit, verringert jedoch gleichzeitig die Geschwindigkeit der Aktualisierung der Tabelle, z. B. INSERT, UPDATE und DELETE in der Tabelle. Denn beim Aktualisieren der Tabelle muss MySQL nicht nur die Daten speichern, sondern auch die Indexdatei3. Felder, die nicht in der Where-Bedingung verwendet werden, erstellen keine Indizes4. Felder mit schlechter Filterbarkeit sind nicht zum Erstellen geeignet IndizesEmpfohlenes Lernen:Das obige ist der detaillierte Inhalt vonLassen Sie uns über die MySQL-Indexstruktur sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Lassen Sie uns den Unterschied zwischen Ersetzen in und Ersetzen in MySQL analysieren
- Was ist ein Deadlock? Lassen Sie uns über das Verständnis des MySQL-Deadlocks sprechen
- Spezielle Anordnung von MySQL-Protokollen: Redo-Log und Undo-Log
- Was ist der Unterschied zwischen MySQL und Myisam?
- Was ist der Unterschied zwischen MySQL-Speicher-Engines?