
Heim >Web-Frontend >js-Tutorial >Beispiel für Node-Crawling-Daten: Schnappen Sie sich den Pokémon-Bildband und generieren Sie eine Excel-Datei
Beispiel für Node-Crawling-Daten: Schnappen Sie sich den Pokémon-Bildband und generieren Sie eine Excel-Datei

- 青灯夜游nach vorne
- 2022-08-26 20:31:232703Durchsuche
Wie verwende ich Node, um Daten von Webseiten zu crawlen und sie in Excel-Dateien zu schreiben? Der folgende Artikel erläutert anhand eines Beispiels, wie man mit Node.js Webseitendaten crawlt und Excel-Dateien generiert. Ich hoffe, dass es für alle hilfreich ist!

Ich glaube, dass Pokémon die Kindheitserinnerung vieler Menschen ist, die in den 90ern geboren wurden. Als Programmierer wollte ich schon mehr als einmal ein Pokémon-Spiel machen, aber vorher sollte ich zuerst herausfinden, wie viele Pokémon es sind Es gibt und ihre Zahlen, Namen, Attribute und andere Informationen werden aussortiert. In dieser Ausgabe werden wir Node.js verwenden, um einfach ein Crawling von Pokémon-Webdaten zu implementieren, diese Daten in Excel-Dateien zu generieren und dann die Schnittstelle zu verwenden um auf diese Daten zuzugreifen.
Crawling-Daten
Da wir Daten crawlen, suchen wir zunächst eine Webseite mit illustrierten Pokémon-Daten, wie unten gezeigt:
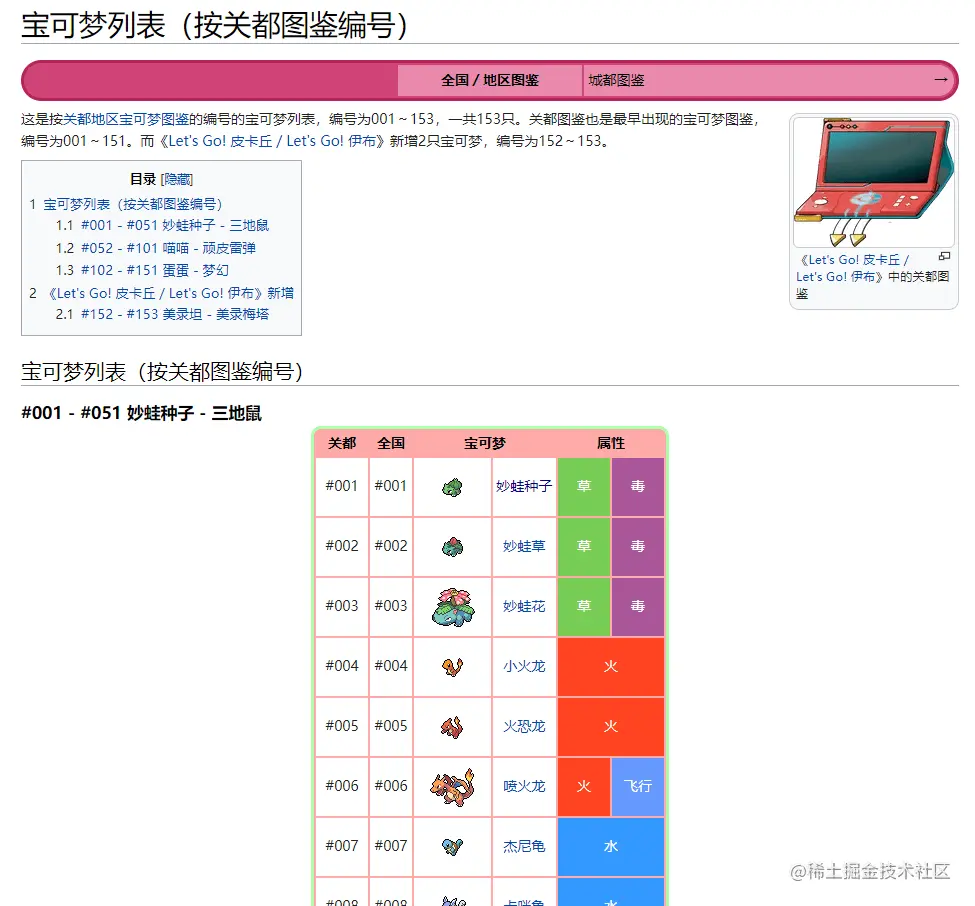
Diese Website ist in PHP geschrieben und es gibt keine Trennung zwischen Vorder- und Rückseite zurück, daher lesen wir die Schnittstelle nicht, um Daten zu erfassen. Wir verwenden die crawler-Bibliothek, um Elemente auf der Webseite zu erfassen, um Daten zu erhalten. Lassen Sie mich vorab erklären, dass der Vorteil der Verwendung der crawler-Bibliothek darin besteht, dass Sie jQuery verwenden können, um Elemente in der Node-Umgebung zu erfassen. crawler 库,来捕获网页中的元素从而得到数据。提前说明一下,用 crawler 库,好处是你可以用 jQuery 的方式在Node环境中捕获元素。
安装:
yarn add crawler
实现:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("\n")[0]
let _name = $td.eq(3).text().split("\n")[0]
let _attr = $td.eq(4).text().split("\n")[0]
let _other = $td.eq(5).text().split("\n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}
在生成实例的时候,还需要开启 jQuery 模式,然后,就可以使用 $ 符了。而以上代码的中间部分的业务就是在捕获元素爬取网页中所需要的数据,使用起来和 jQuery API 一样,这里就不再赘述了 。
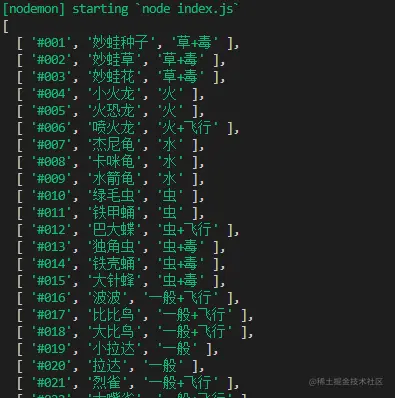
getPokemon().then(async data => {
console.log(data)
})
最后我们可以执行并打印一下传过来的 data 数据,来验证确实爬取到了格式也没有错误。
写入Excel
既然刚才已经爬取到数据了,接下来,我们就将使用 node-xlsx 库,来完成把数据写入并生成一个 Excel 文件中。
首先,我们先介绍一下,node-xlsx 是一个简单的 excel 文件解析器和生成器。由 TS 构建的一个依靠 SheetJS xlsx 模块来解析/构建 excel 工作表,所以,在一些参数配置上,两者可以通用。
安装:
yarn add node-xlsx
实现:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
})
其 name 则是Excel文件中的栏目名,而其中的 data 类型是数组其也要传入一个数组,构成二维数组,其表示从 ABCDE.... 列中开始排序传入文本。同时,可以通过!cols来设置列宽。第一个对象wch:10 则表示 第一列宽度为10 个字符,还有很多参数可以设置,可以参照 xlsx 库 来学习这些配置项。
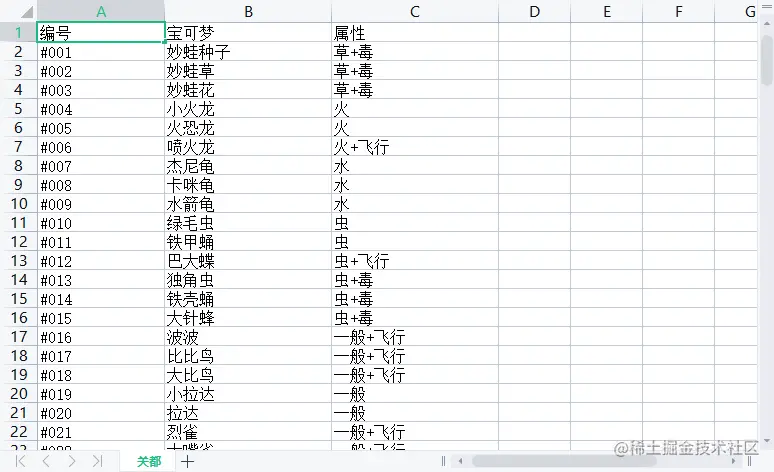
最后,我们通过 xlsx.build 方法来生成 buffer 数据,最后用 fs.writeFileSync 写入或创建一个 Excel 文件中,为了方便查看,我这里存入了 名叫 data 的文件夹里,此时,我们在 data 文件夹 就会发现多出一个叫 pokemon.xlsx 的文件,打开它,数据还是那些,这样把数据写入到Excel的这步操作就完成了。
读取Excel
读取Excel其实非常容易甚至不用写 fs 的读取, 用xlsx.parse 方法传入文件地址就能直接读取到。
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
当然,我们为了验证准确无误,直接写一个接口,看看能不能访问到数据。为了方便我直接用 express 框架来完成这件事。
先来安装一下:
yarn add express
然后,再创建 express 服务,我这里端口号就用3000了,就写一个 GET 请求把读取Excel文件的数据发送出去就好。
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
})
最后,我这里用 postman
rrreee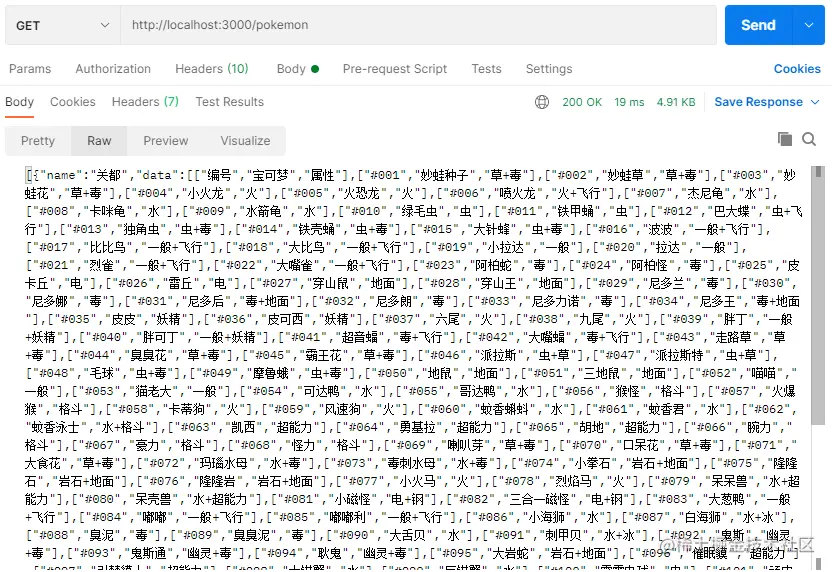 Implementierung:
Implementierung:
jQuery-Modus aktivieren und können dann das $-Symbol verwenden. Der Zweck des mittleren Teils des obigen Codes besteht darin, die in Elementen erforderlichen Daten zu erfassen und Webseiten zu crawlen. Er wird genauso verwendet wie die jQuery-API, daher werde ich hier nicht auf Details eingehen. 🎜rrreee🎜Schließlich können wir die übergebenen data-Daten ausführen und ausdrucken, um zu überprüfen, ob das Format gecrawlt wurde und keine Fehler vorliegen. 🎜🎜🎜🎜In Excel schreiben🎜🎜🎜Da wir nun gerade die Daten gecrawlt haben, verwenden wir als Nächstes den Code node-xlsx > Bibliothek, um das Schreiben von Daten und das Generieren einer Excel-Datei abzuschließen. 🎜🎜Lassen Sie uns zunächst vorstellen, dass <code>node-xlsx ein einfacher Excel-Dateiparser und -Generator ist. Eine von TSSheetJS xlsx 🎜 Modul zum Parsen/Erstellen von Excel-Arbeitsblättern, daher können in einigen Parameterkonfigurationen beide gemeinsam sein. 🎜🎜Installation: 🎜rrreee🎜Implementierung: 🎜rrreee🎜Der name ist der Spaltenname in der Excel-Datei und der Typ data ist ein Array, das ebenfalls übergeben werden muss in Array, das ein zweidimensionales Array bildet, das den eingehenden Text sortiert ab der Spalte ABCDE... darstellt. Gleichzeitig kann die Spaltenbreite über !cols eingestellt werden. Das erste Objekt wch:10 bedeutet, dass die Breite der ersten Spalte 10 Zeichen beträgt. Es gibt viele Parameter, die eingestellt werden können. Sie können sich auf xlsx-Bibliothek🎜, um diese Konfigurationselemente kennenzulernen. 🎜🎜Schließlich verwenden wir die Methode xlsx.build, um die Daten des Puffer zu generieren, und schließlich verwenden wir fs.writeFileSync, um ein Excel zu schreiben oder zu erstellen Zur Vereinfachung der Anzeige habe ich sie in einem Ordner namens data gespeichert. Zu diesem Zeitpunkt finden wir eine zusätzliche Datei namens pokemon.xlsx. Öffnen Sie sie und die Daten sind immer noch dieselben Auf diese Weise ist dieser Schritt zu Excel abgeschlossen. 🎜🎜 🎜
🎜🎜Excel lesen🎜🎜🎜Das Lesen von Excel ist eigentlich sehr einfach und Sie müssen zum Lesen nicht einmal fs schreiben , verwenden Sie die Methode xlsx.parse, die durch Übergabe der Dateiadresse direkt gelesen werden kann. 🎜rrreee🎜Um die Richtigkeit zu überprüfen, schreiben wir natürlich direkt eine Schnittstelle, um zu sehen, ob wir auf die Daten zugreifen können. Der Einfachheit halber verwende ich dazu direkt das express-Framework. 🎜🎜Installieren Sie es zuerst: 🎜rrreee🎜Dann erstellen Sie den express-Dienst. Ich verwende hier 3000 als Portnummer, also schreibe ich eine GET-Anfrage, um die Excel-Datei zu lesen . Senden Sie einfach die Daten raus. 🎜rrreee🎜Abschließend verwende ich hier die Zugriffsschnittstelle postman, und Sie können deutlich sehen, dass alle Pokémon-Daten, die wir vom Crawlen bis zum Speichern in der Tabelle erhalten haben. 🎜🎜🎜🎜Fazit
Wie Sie sehen können, verwendet dieser Artikel Pokémon als Beispiel, um zu erfahren, wie Sie mit Node.js Daten von Webseiten crawlen, Daten in Excel-Dateien schreiben und Daten aus Excel-Dateien lesen Drei Fragen sind eigentlich nicht schwer umzusetzen, aber manchmal sind sie ziemlich praktisch. Wenn Sie Angst haben, sie zu vergessen, können Sie sie speichern ~
Weitere Informationen zu Knoten finden Sie unter: nodejs-Tutorial!
fs schreiben , verwenden Sie die Methode xlsx.parse, die durch Übergabe der Dateiadresse direkt gelesen werden kann. 🎜rrreee🎜Um die Richtigkeit zu überprüfen, schreiben wir natürlich direkt eine Schnittstelle, um zu sehen, ob wir auf die Daten zugreifen können. Der Einfachheit halber verwende ich dazu direkt das express-Framework. 🎜🎜Installieren Sie es zuerst: 🎜rrreee🎜Dann erstellen Sie den express-Dienst. Ich verwende hier 3000 als Portnummer, also schreibe ich eine GET-Anfrage, um die Excel-Datei zu lesen . Senden Sie einfach die Daten raus. 🎜rrreee🎜Abschließend verwende ich hier die Zugriffsschnittstelle postman, und Sie können deutlich sehen, dass alle Pokémon-Daten, die wir vom Crawlen bis zum Speichern in der Tabelle erhalten haben. 🎜🎜🎜🎜Fazit
Das obige ist der detaillierte Inhalt vonBeispiel für Node-Crawling-Daten: Schnappen Sie sich den Pokémon-Bildband und generieren Sie eine Excel-Datei. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Lassen Sie uns darüber sprechen, wie Nodejs gm und imageMagick zum Verarbeiten von Bildern verwendet
- Lassen Sie uns darüber sprechen, wie Sie mit Node.js einen statischen Webserver erstellen
- Lassen Sie uns darüber sprechen, wie Node die Verschlüsselung und Entschlüsselung der Front-End- und Back-End-Datenübertragung implementiert.
- Ein Artikel, der das Modulsystem in node analysiert
- [Kompilierung und Freigabe] Einige Test-Frameworks, die in Node.js verwendet werden können