
Heim >Backend-Entwicklung >Python-Tutorial >Der Python-Crawler crawlt Webseitendaten und analysiert die Daten
Der Python-Crawler crawlt Webseitendaten und analysiert die Daten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-08-15 18:25:467932Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Python. Er stellt hauptsächlich vor, wie Python-Crawler Webseitendaten crawlen und die Daten analysieren, um Ihnen dabei zu helfen, Crawler besser zum Analysieren von Webseiten zu verwenden hilfreich für alle.

【Verwandte Empfehlung: Python3-Video-Tutorial】
1. Das Grundkonzept des Webcrawlers
Webcrawler (auch bekannt als Webspider, Roboter) besteht darin, den Client zu simulieren, um Netzwerkanfragen zu senden Anforderungsantworten erhalten, ein Programm, das Internetinformationen nach bestimmten Regeln automatisch erfasst.
Solange der Browser alles kann, kann der Crawler im Prinzip alles tun.
2. Funktionen von Webcrawlern
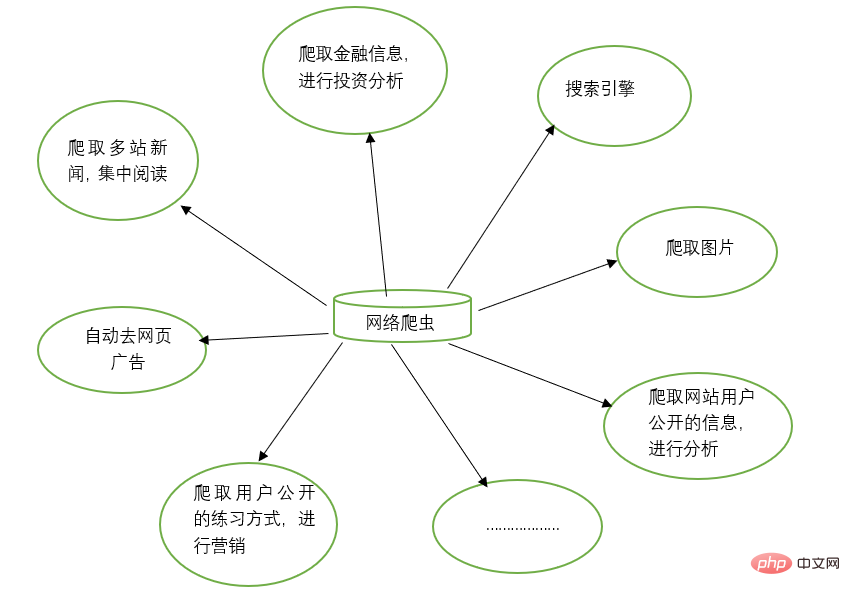
Webcrawler können die manuelle Arbeit bei vielen Dingen ersetzen, z. B. bei der Arbeit mit Suchmaschinen und beim Crawlen von Bildern auf Websites. Alle Bilder werden gecrawlt und durchsucht Gleichzeitig können Webcrawler auch im Bereich Finanzinvestitionen eingesetzt werden, um beispielsweise einige Finanzinformationen automatisch zu crawlen und Investitionsanalysen durchzuführen.
Manchmal haben wir möglicherweise mehrere Lieblingsnachrichten-Websites, und es ist mühsam, diese Nachrichten-Websites jedes Mal einzeln zum Durchsuchen zu öffnen. Zu diesem Zeitpunkt können Sie einen Webcrawler verwenden, um die Nachrichteninformationen von diesen mehreren Nachrichten-Websites zu crawlen und sie gemeinsam zu lesen.
Wenn wir im Internet nach Informationen suchen, stoßen wir manchmal auf jede Menge Werbung. Zu diesem Zeitpunkt können Sie auch einen Crawler verwenden, um die Informationen auf der entsprechenden Webseite zu crawlen, sodass diese Werbung automatisch herausgefiltert werden kann, um das Lesen und Verwenden der Informationen zu erleichtern.
Manchmal müssen wir Marketing betreiben, daher ist es von entscheidender Bedeutung, wie wir Zielkunden und deren Kontaktinformationen finden. Wir können manuell im Internet suchen, aber das wird sehr ineffizient sein. Derzeit können wir Crawler verwenden, um entsprechende Regeln festzulegen und automatisch die Kontaktinformationen und andere Daten der Zielbenutzer für unsere Marketingzwecke aus dem Internet zu sammeln.
Manchmal möchten wir die Benutzerinformationen einer bestimmten Website analysieren, z. B. die Benutzeraktivität, die Anzahl der Kommentare, beliebte Artikel und andere Informationen der Website. Wenn wir nicht der Website-Administrator sind, sind manuelle Statistiken sehr hilfreich Riesenprojekt. Zu diesem Zeitpunkt können Crawler verwendet werden, um diese Daten für die weitere Analyse einfach zu sammeln. Alle Crawling-Vorgänge werden automatisch ausgeführt. Wir müssen nur den entsprechenden Crawler schreiben und die entsprechenden Regeln entwerfen.
Darüber hinaus können Crawler auch viele leistungsstarke Funktionen erreichen. Kurz gesagt, das Aufkommen von Crawlern kann den manuellen Zugriff auf Webseiten bis zu einem gewissen Grad ersetzen. Daher können Vorgänge, die zuvor einen manuellen Zugriff auf Internetinformationen erforderten, jetzt mithilfe von Crawlern automatisiert werden, sodass effektive Informationen im Internet effizienter genutzt werden können. .
3. Installieren Sie Bibliotheken von Drittanbietern
Bevor Sie Daten crawlen und analysieren, müssen Sie die Bibliotheksanforderungen von Drittanbietern in der Python-Laufumgebung herunterladen und installieren.
Öffnen Sie im Windows-System die cmd-Schnittstelle (Eingabeaufforderung), geben Sie pip-Installationsanforderungen in die Schnittstelle ein und drücken Sie die Eingabetaste, um die Installation durchzuführen. (Achten Sie auf die Netzwerkverbindung) Wie unten gezeigt
Die Installation ist abgeschlossen, wie im Bild gezeigt
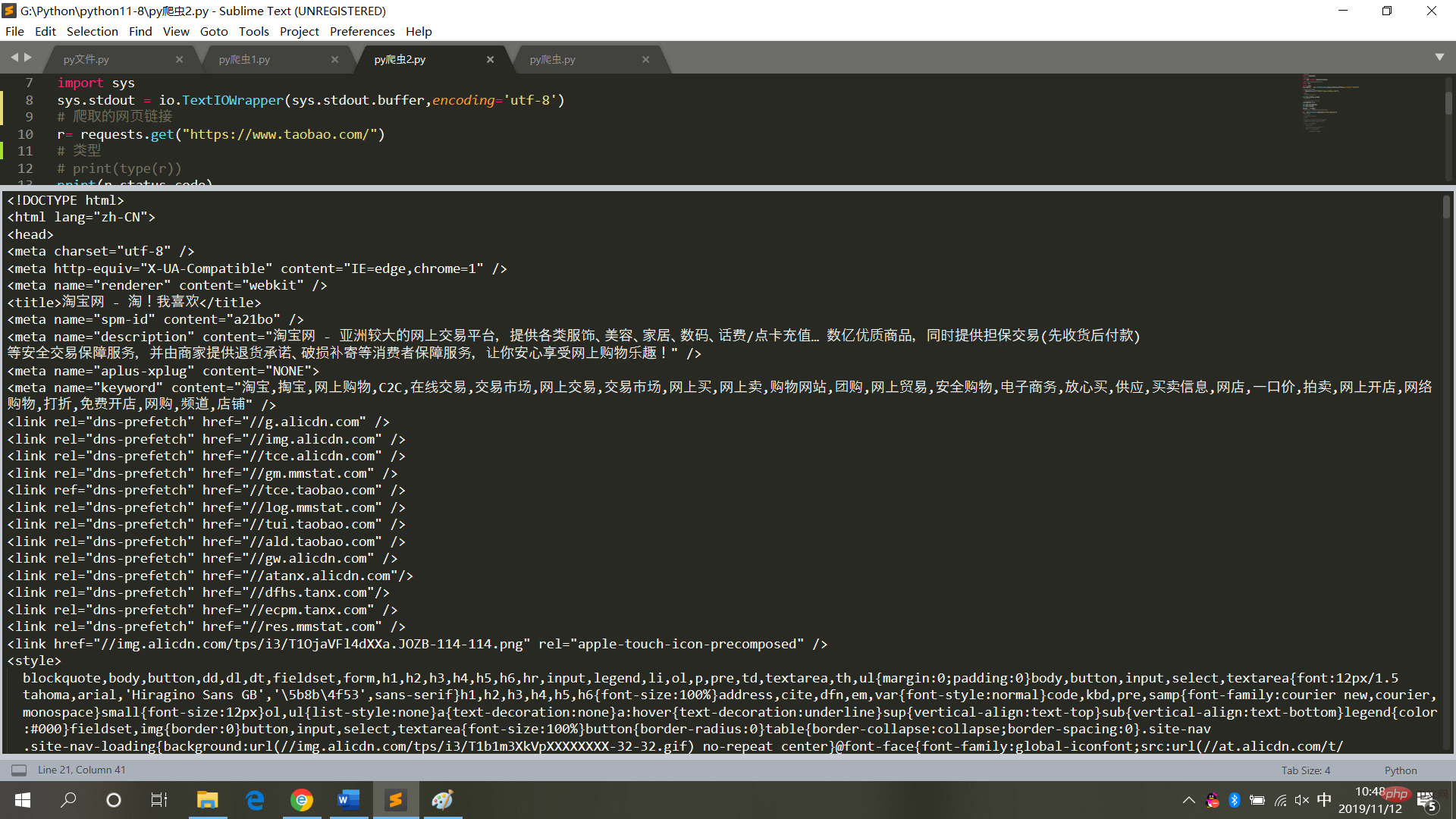
4. Crawlen Sie die Taobao-Homepage
# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.textDie laufenden Ergebnisse sind wie im Bild gezeigt Bild
5. Die laufenden Ergebnisse der Taobao-Homepage
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
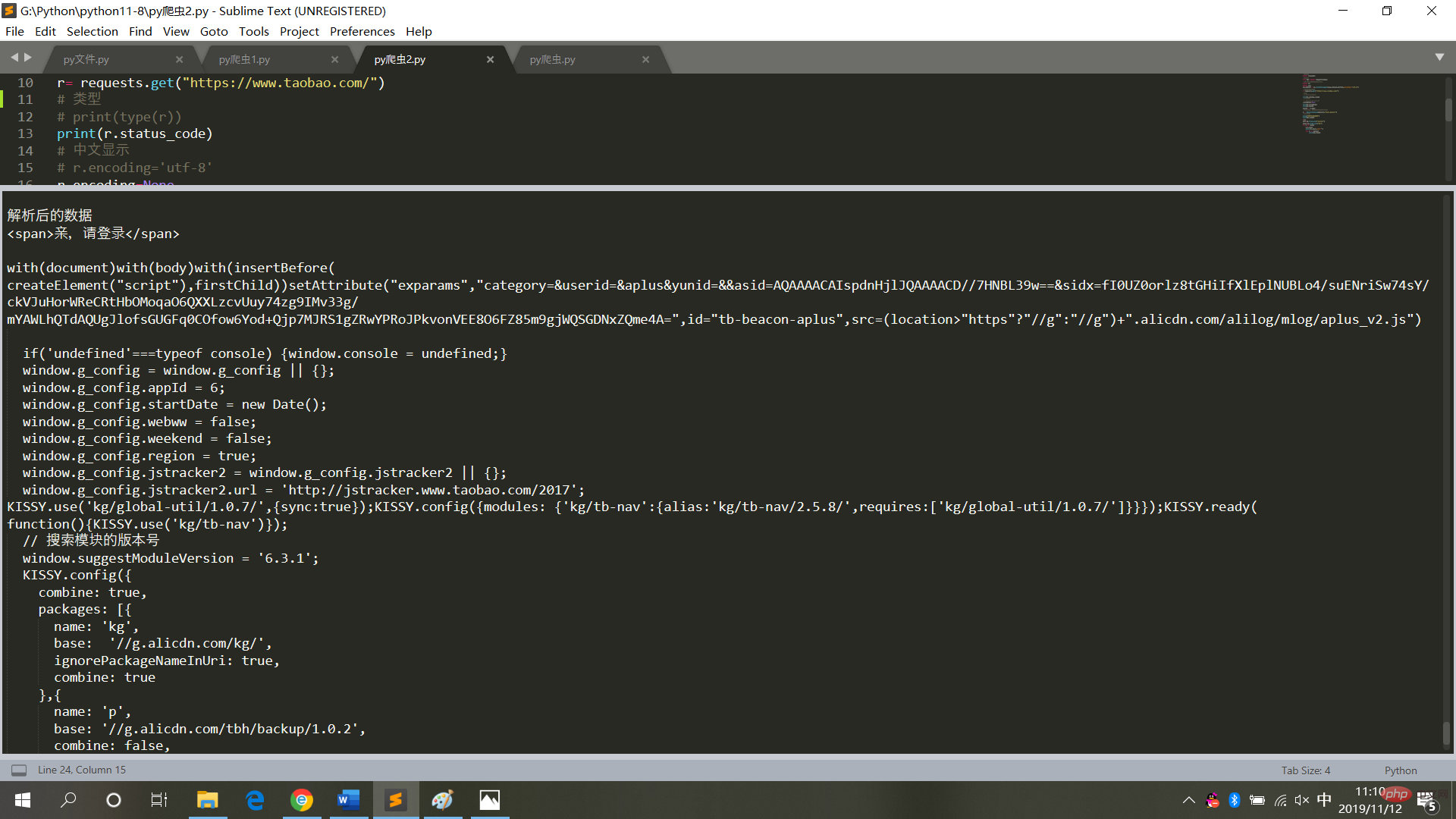
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)sind wie in der Abbildung dargestellt
6. Zusammenfassung
Führen Sie beim Crawlen des Webseitencodes keine Operationen aus es häufig, geschweige denn, es in einen Endlosschleifenmodus zu versetzen (jedes Mal, wenn Crawling sich auf den Zugriff auf Webseiten bezieht. Häufige Vorgänge führen zum Absturz des Systems und es wird eine rechtliche Haftung eingeleitet).
Nachdem Sie die Webseitendaten erhalten haben, speichern Sie sie im lokalen Textmodus und analysieren Sie sie dann (Sie müssen nicht mehr auf die Webseite zugreifen).
【Verwandte Empfehlung: Python3-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonDer Python-Crawler crawlt Webseitendaten und analysiert die Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Beherrschen Sie die Double-Down-Methode in Python vollständig
- So implementieren Sie einen überlappenden Abgleich mit regulären Python-Ausdrücken
- Die Verwendung des Python-Lightweight-Suchtools Whoosh (Zusammenfassungsfreigabe)
- Zusammenfassung der Verwendung des Functools-Moduls von Python
- Machen Sie sich mit dem Python-Prozessmanagement-Artefakt Supervisor vertraut