
Heim >Java >javaLernprogramm >Beispielhafte Einführung zur Implementierung eines komplexen relationalen Ausdrucksfilters auf Basis von Java
Beispielhafte Einführung zur Implementierung eines komplexen relationalen Ausdrucksfilters auf Basis von Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-08-01 14:56:321663Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Java. Er stellt hauptsächlich detailliert vor, wie Sie einen komplexen relationalen Ausdrucksfilter auf Java-Basis implementieren. Der Beispielcode im Artikel wird ausführlich erklärt. Schauen wir uns ihn an. Ich hoffe, er wird für alle hilfreich sein.

Empfohlene Studie: „Java-Video-Tutorial“
Hintergrund
Kürzlich gibt es eine neue Anforderung, die das Einrichten eines komplexen relationalen Ausdrucks im Hintergrund und die Analyse erfordert, ob der Benutzer die Bedingung erfüllt Die vom Benutzer angegebene ID ähnelt den Suchbedingungen von ZenTao

Der Unterschied besteht jedoch darin, dass ZenTao nur zwei Gruppen hat und jede Gruppe bis zu drei Bedingungen hat komplexer: Es gibt Gruppen innerhalb von Gruppen und jede Bedingung hat eine UND- oder Beziehung. Aus Gründen der Vertraulichkeit wird der Prototyp nicht veröffentlicht.
Als ich diese Anforderung sah, dachte ich als Erstes an ein Ausdrucksframework wie QLEpress. Solange Sie einen Ausdruck erstellen, können Sie die Zielbenutzer schnell filtern, indem Sie den Ausdruck analysieren Das Der Front-End-Klassenkamerad hat aufgehört, weil es als datengesteuertes Framework mit Vue oder React zu schwierig ist, den Ausdruck in die obige Form umzuwandeln. Deshalb habe ich darüber nachgedacht und beschlossen, selbst eine Datenstruktur zu definieren, um den Ausdruck zu implementieren . analysieren. Praktisch für Front-End-Studenten zur Bearbeitung.
Analysevorbereitung
Obwohl Ausdrücke mithilfe von Klassen implementiert werden, handelt es sich im Wesentlichen immer noch um Ausdrücke: Unter der Annahme, dass die Bedingungen a, b, c, d sind, können wir einen Ausdruck nach Belieben erstellen:
boolean result=a>100 && b=10 ||. (c != 3 && d 4230dca7ec3626e290524540467b918a100 && b=10 || (c != 3 && d 5a1b319c9256b5adbf09f78b85738671100 中的100)。
另外,还有关联关系(且、或)和计算优先级这几个属性组成。
于是我们对表达式进行简化:
令a>100 =>A,b=10 =>B,c!=3=>C ,dc849c18f1683bfc1ac5adfe2d1f542bdD,于是我们得到:
result=A && B || (C && D)
现在问题来了,如何处理优先级呢?
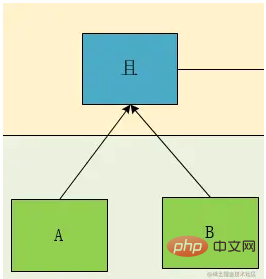
如上表达式,很明显,这是一个大学里学过的标准的中序表达式,于是,我们画一下它的树形图:
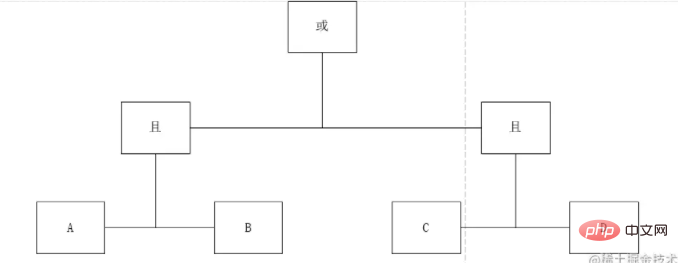
根据这个图,我们可以明显的看到,A且B 和C且D是同一级别,于是,我们按照这个理论设计一个层级的概念Deep,我们标注一下,然后再对节点的类型做一下区分,可得:
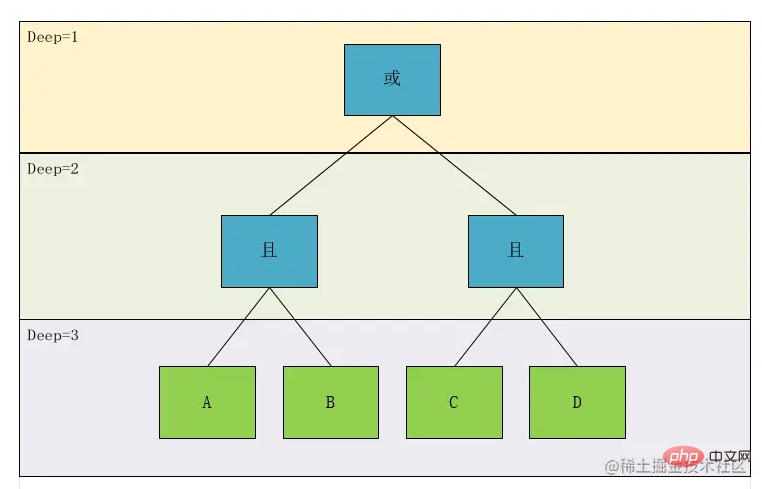
我们可以看到作为叶子节点(上图绿色部分),相对于其计算计算关系,遇到了一定是优先计算的,所以对于深度的优先级,我们仅需要考虑非叶子节点即可,即上图中的蓝色节点部分,于是我们得到了,计算优先级这个概念我们可以转换为表达式的深度。
我们再看上面这个图,Deep1 的关系是Deep2中 A且B 和 C且D两个表达式计算出的结果再进行与或关系的,我们设A 且B 为 G1, C且D为 G2,于是我们发现关系节点关联的类型有两种类型,一种是条件Condition ,一种是组Group
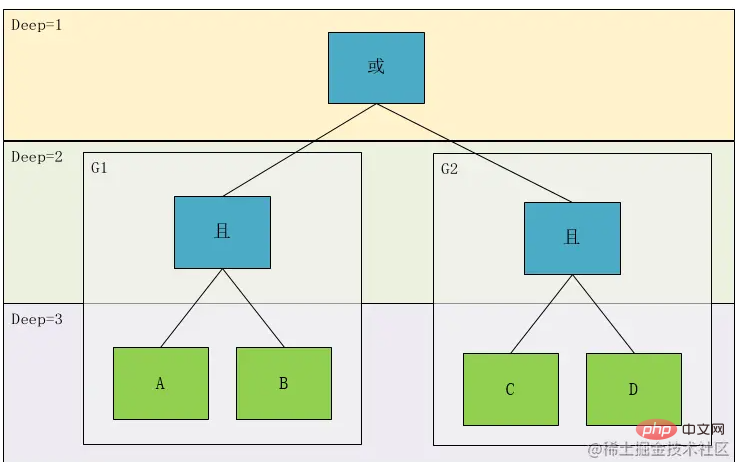
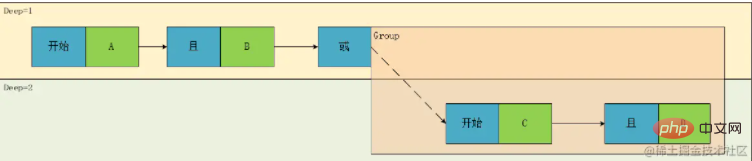
至此,这个类的雏形基本就确定了。这个类包含 关联关系(Relation)、判断字段(Field)、运算符(Operator)、运算值(Values)、类型(Type)、深度(Deep)
但是,有个问题,上面的分析中,我们在将表达式转换成树,现在我们试着将其还原,于是我们一眼可以得到其中一种表达式:
result=(A && B)||(C && D)
result=A && B ||. (C && D)🎜🎜Die Frage ist nun, wie geht man mit Prioritäten um? 🎜🎜Der obige Ausdruck ist offensichtlich ein Standard-Inorder-Ausdruck, den wir im College gelernt haben, also zeichnen wir sein Baumdiagramm: 🎜🎜 🎜🎜Anhand dieses Bildes können wir deutlich erkennen, dass A und B sowie C und D auf derselben Ebene liegen. Wir entwerfen also ein hierarchisches Konzept, das dieser Theorie tief entspricht und dann die Knotentypen unterscheiden, erhalten wir: 🎜🎜
🎜🎜Anhand dieses Bildes können wir deutlich erkennen, dass A und B sowie C und D auf derselben Ebene liegen. Wir entwerfen also ein hierarchisches Konzept, das dieser Theorie tief entspricht und dann die Knotentypen unterscheiden, erhalten wir: 🎜🎜 🎜🎜Wir können sehen, dass ein Blattknoten (der grüne Teil im Bild oben) relativ zu seiner Berechnungsberechnungsbeziehung zuerst berechnet werden muss, wenn er angetroffen wird. Für die Tiefenpriorität müssen wir also nur dies tun Betrachten Sie Nicht-Blattknoten, also den blauen Knotenteil in der obigen Abbildung, sodass wir das Konzept der Berechnung der Priorität erhalten, das wir in einen Ausdruck umwandeln können. 🎜🎜Schauen wir uns das Bild oben noch einmal an. Die Beziehung zwischen Deep1 ist das UND oder die Beziehung zwischen den Ergebnissen, die durch die beiden Ausdrücke A und B und C und D in Deep2 berechnet werden. Nehmen wir an, A und B sind G1 und C und D sind G2 . Wir haben also festgestellt, dass es zwei Arten von Beziehungsknotenzuordnungen gibt: eine ist ConditionCondition und die andere ist GroupGroup🎜🎜🎜🎜An diesem Punkt ist der Prototyp dieser Klasse grundsätzlich festgelegt. Diese Klasse umfasst Beziehung (Relation), Urteilsfeld (Feld), Operator (Operator), Operationswerte (Werte), Typ (Typ), Tiefe (Tiefe) 🎜🎜Es gibt jedoch ein Problem. In der obigen Analyse konvertieren wir den Ausdruck in einen Baum und versuchen ihn nun wiederherzustellen it , damit wir einen der Ausdrücke auf einen Blick erhalten: 🎜🎜
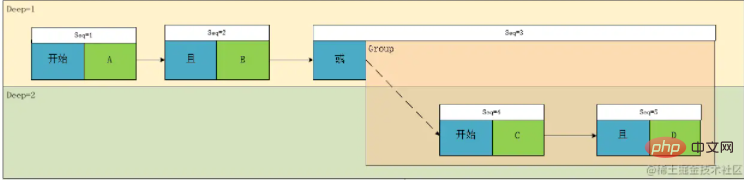
🎜🎜Wir können sehen, dass ein Blattknoten (der grüne Teil im Bild oben) relativ zu seiner Berechnungsberechnungsbeziehung zuerst berechnet werden muss, wenn er angetroffen wird. Für die Tiefenpriorität müssen wir also nur dies tun Betrachten Sie Nicht-Blattknoten, also den blauen Knotenteil in der obigen Abbildung, sodass wir das Konzept der Berechnung der Priorität erhalten, das wir in einen Ausdruck umwandeln können. 🎜🎜Schauen wir uns das Bild oben noch einmal an. Die Beziehung zwischen Deep1 ist das UND oder die Beziehung zwischen den Ergebnissen, die durch die beiden Ausdrücke A und B und C und D in Deep2 berechnet werden. Nehmen wir an, A und B sind G1 und C und D sind G2 . Wir haben also festgestellt, dass es zwei Arten von Beziehungsknotenzuordnungen gibt: eine ist ConditionCondition und die andere ist GroupGroup🎜🎜🎜🎜An diesem Punkt ist der Prototyp dieser Klasse grundsätzlich festgelegt. Diese Klasse umfasst Beziehung (Relation), Urteilsfeld (Feld), Operator (Operator), Operationswerte (Werte), Typ (Typ), Tiefe (Tiefe) 🎜🎜Es gibt jedoch ein Problem. In der obigen Analyse konvertieren wir den Ausdruck in einen Baum und versuchen ihn nun wiederherzustellen it , damit wir einen der Ausdrücke auf einen Blick erhalten: 🎜🎜result=(A && B)||(C && D)🎜Offensichtlich stimmt es nicht mit unserem ursprünglichen Ausdruck überein. Dies liegt daran, dass wir nur die Berechnungsreihenfolge des obigen Ausdrucks aufzeichnen können, diesen Ausdruck jedoch nicht vollständig genau darstellen können haben Tiefe, aber es gibt auch eine zeitliche Beziehung, dh eine sequentielle Darstellung von links nach rechts. Zu diesem Zeitpunkt hat der Inhalt in G1 tatsächlich eine Tiefe von 1 statt 2 im ursprünglichen Ausdruck. Dann führen wir das Konzept von ein Sequenznummern zu Es stellt sich heraus, dass der Baum zu einem gerichteten Graphen wird:
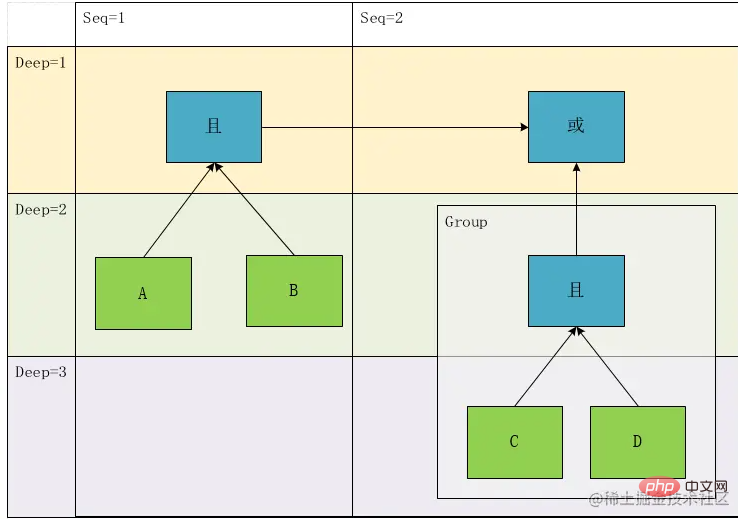
Gemäß diesem Graphen können wir den einzigen Ausdruck wiederherstellen: result= A && B ||(C && D) . result= A && B ||(C && D)。
好了,我们分析了半天,原理说完了,回到最初始的问题:前后端怎么实现?对着上图想象一下,貌似还是无法处理,因为这个结构还是太复杂了。对于前端,数据最好是方便遍历的,对于后端,数据最好是方便处理的,于是这时候我们需要将上面这个图转换成一个数组。
实现方式
上面说到了需要一个数组的结构,我们具体分析一下这个部分
我们发现作为叶子节点,可以始终优先计算,所以我们可以将其压缩,并将关系放置在其中一个表达式中形成 ^A -> &&B或 A&& -> B$ 的形式,这里我用正则的开始(^) 和结束($) 表示了一下开始 和 结束 的概念,这里为了与产品原型保持一致我们用第一种方式,即关系符号表示与前一个元素的关系,于是我们再分析一下:
再对序号进行改造:
于是我们得到最终的数据结构:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class ExpressDto {
/**
* 序号
*/
private Integer seq;
/**
* 深度(运算优先级)
*/
private Integer deep;
/**
* 关系运算符
*/
private String relation;
/**
* 类型
*/
private String type;
/**
* 运算条件
*/
private String field;
/**
* 逻辑运算符
*/
private String operator;
/**
* 运算值
*/
private String values;
/**
* 运算结果
*/
private Boolean result;
}现在数据结构终于完成,既方便存储,又(相对)方便前台展示,现在构造一个稍微复杂的表达式
A &&(( B || C )|| (D && E)) && F
 Wir haben festgestellt, dass er als Blattknoten immer zuerst berechnet werden kann, sodass wir ihn komprimieren und die Beziehung in einen der Ausdrücke einfügen können, um
Wir haben festgestellt, dass er als Blattknoten immer zuerst berechnet werden kann, sodass wir ihn komprimieren und die Beziehung in einen der Ausdrücke einfügen können, um ^A zu bilden - > &&B oder A&& -> ausdrücken Werfen wir einen Blick auf die Konzepte von Anfang und Ende. Um mit dem Produktprototyp übereinzustimmen, verwenden wir die erste Methode, dh das Beziehungssymbol, um die Beziehung zum vorherigen Element auszudrücken, und analysieren es erneut: <p></p>
<img alt="" src="https://img.php.cn/upload/article/000/000/067/3a0ccb02b119fe8c783e43e6144ca882-6.png"><p></p>Reformieren Sie die Seriennummer: <p></p>
<img alt="" src="https://img.php.cn/upload/article/000/000/067/e8b2c46987467f0e9caed910bedaa37f-7.png"><p></p>So erhalten wir die endgültige Datenstruktur:<p><pre class="brush:json;"> [
{"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
{"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
{"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
{"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
{"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
{"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
{"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
{"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
{"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
]</pre></p>Jetzt die Die Datenstruktur ist endlich fertiggestellt, was sowohl praktisch für die Speicherung als auch (relativ) praktisch für die Front-End-Anzeige ist. Erstellen Sie nun einen leicht komplexen Ausdruck <p></p>
<code>A &&(( B || C )|| (D && E) ) && FZu einem Array-Objekt wechseln und starten Es ist mit BEGIN markiert, der Ausdruckstyp wird durch CONDITION dargestellt und die Gruppe wird durch GROUP dargestellt. //关系 栈 Deque<String> relationStack=new LinkedList(); //结果栈 Deque<Boolean> resultStack=new LinkedList(); // 当前深度 Integer nowDeep=1;Jetzt bleibt die letzte Frage: Wie filtert man die Daten durch diesen JSON? Hier gibt es keine große Einführung, einfach ausgedrückt, es durchläuft den Datenstapel und den Symbolstapel gemäß den Klammern (hier Gruppen genannt). Wenn Sie mehr wissen möchten, können Sie es im folgenden Artikel nachlesenAlso definieren wir drei Variablen:
for (ExpressDto expressDto:list) {
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
private void relationOperator(Deque<String> relationStack, Deque<Boolean> resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} Schieben Sie die Beziehung und das Ergebnis durch Durchlaufen des Arrays auf den Stapel. Wenn festgestellt wird, dass eine Prioritätsberechnung erforderlich ist, entfernen Sie zwei Werte aus dem Ergebnisstapel und entfernen Sie den Vergleichsoperator aus dem Beziehungsstapel , schieben Sie es nach der Berechnung erneut in den Stapel und warten Sie auf das nächste Mal. Bei der Berechnung
Schieben Sie die Beziehung und das Ergebnis durch Durchlaufen des Arrays auf den Stapel. Wenn festgestellt wird, dass eine Prioritätsberechnung erforderlich ist, entfernen Sie zwei Werte aus dem Ergebnisstapel und entfernen Sie den Vergleichsoperator aus dem Beziehungsstapel , schieben Sie es nach der Berechnung erneut in den Stapel und warten Sie auf das nächste Mal. Bei der Berechnung /**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}sprechen wir über die Grenzangelegenheiten, auf die wir achten müssen:
1 gleiche Ebene, und, oder, und die Berechnungsprioritäten dieser beiden Typen sind gleich. Daher ist es unter derselben Tiefe einfach, von links nach rechts zu durchlaufen und zu berechnen.
2. Wenn wir auf den Typ GROUP stoßen, ist dies gleichbedeutend mit der Begegnung mit „(“. Wir können feststellen, dass die Elemente dahinter Deep +1 bis Deep -1 sind und mit „)“ enden, und die Elemente in Klammern müssen es sein Zuerst berechnet, und das heißt, die von „()“ generierte Priorität wird gemeinsam von Deep und Type=GROUP gesteuert. Wenn Deep abnimmt, bedeutet dies, dass „)“ auf die Anzahl der Gruppen stößt Diese Zeit entspricht der Anzahl der Tiefenabnahmen. Bei jedem „)“-Ende müssen die Klammern dieser Ebene überprüft werden, um festzustellen, ob Elemente derselben Ebene berechnet wurden. 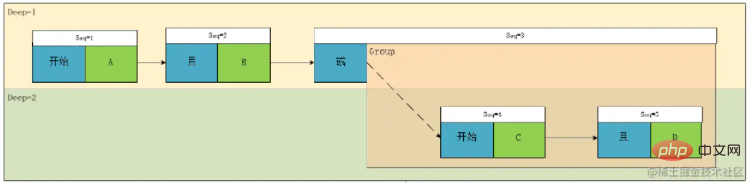
/**
* 表达式解析器
* 表达式规则:
* 关系relation属性有:BEGIN、AND、OR 三种
* 表达式类型 Type 属性有:GROUP、CONDITION 两种
* 深度 deep 属性 根节点为 1,每增加一个括号(GROUP)deep+1,括号结束deep-1
* 序号req:初始值为1,往后依次递增,用于防止表达式解析顺序错误
* exp1:表达式:A &&(( B || C )|| (D && E)) && F
* 分解对象:
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
* {"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
* {"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
* {"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
* {"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
* {"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
* exp2:(A || B && C)||(D && E && F)
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":2,"deep":2,relation:"BEGIN","type":"CONDITION","field":"A"...},
* {"seq":3,"deep":2,relation:"OR","type":"CONDITION","field":"B"...},
* {"seq":4,"deep":2,relation:"AND","type":"CONDITION","field":"C"...},
* {"seq":5,"deep":1,relation:"OR","type":"GROUP","field":""...},
* {"seq":6,"deep":2,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":7,"deep":2,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":8,"deep":2,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
*
* @param list
* @return
*/
public boolean expressProcessor(Listlist){
//关系 栈
Deque relationStack=new LinkedList();
//结果栈
Deque resultStack=new LinkedList();
// 当前深度
Integer nowDeep=1;
Integer seq=0;
for (ExpressDto expressDto:list) {
// 顺序检测,防止顺序错误
int checkReq=expressDto.getSeq()-seq;
if(checkReq!=1){
throw new RuntimeException("表达式异常:解析顺序异常");
}
seq=expressDto.getSeq();
//计算深度(计算优先级),判断当前逻辑是否需要处理括号
int deep=expressDto.getDeep()-nowDeep;
// 赋予当前深度
nowDeep=expressDto.getDeep();
//deep 减小,说明有括号结束,需要处理括号到对应的层级,deep减少数量等于组(")")结束的数量
while(deep++ < 0){
computeBeforeEndGroup(relationStack, resultStack);
}
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
//遍历完毕,处理栈中未进行运算的节点
while(nowDeep-- > 0){ // 这里使用 nowdeep>0 的原因是最后deep=1的关系表达式也需要进行处理
computeBeforeEndGroup(relationStack, resultStack);
}
if(resultStack.size()!=1){
throw new RuntimeException("表达式解析异常:解析结果数量异常解析数量:"+resultStack.size());
}
return resultStack.pop();
}
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}
/**
* 关系运算处理
* @param relationStack
* @param resultStack
*/
private void relationOperator(Deque relationStack, Deque resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} 4. Wenn festgestellt wird, dass das letzte Element Deep am Ende des Durchlaufs nicht gleich 1 ist, bedeutet dies, dass es ein Ende der Klammern gibt. Zu diesem Zeitpunkt muss auch das Ende der Klammern verarbeitet werden 🎜Zum Schluss der vollständige Code: 🎜 /**
* 表达式:A
*/
@Test
public void expTest0(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(false).setSeq(1).setType("CONDITION").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
}
/**
* 表达式:(A && B)||(C || D)
*/
@Test
public void expTest1(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("AND");
ExpressDto E4=new ExpressDto().setDeep(1).setSeq(4).setType("GROUP").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(2).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A && (B || C && D)
*/
@Test
public void expTest2(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setResult(false).setSeq(4).setType("Condition").setField("C").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("D").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
E4.setResult(true);
list.set(3,E4);
re=expressProcessor(list);
Assertions.assertTrue(re);
E1.setResult(false);
list.set(0,E1);
re=expressProcessor(list);
Assertions.assertFalse(re);
}
@Test
public void expTest3(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("OR");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(true).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setSeq(4).setType("GROUP").setRelation("AND");
ExpressDto E5=new ExpressDto().setDeep(3).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(3).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A &&(( B || C )|| (D && E))
*/
@Test
public void expTest4(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("CONDITION").setResult(true).setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setSeq(3).setType("GROUP").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(3).setSeq(4).setType("CONDITION").setResult(true).setField("B").setRelation("BEGIN");
ExpressDto E5=new ExpressDto().setDeep(3).setSeq(5).setType("CONDITION").setResult(true).setField("C").setRelation("OR");
ExpressDto E6=new ExpressDto().setDeep(2).setSeq(6).setType("GROUP").setRelation("OR");
ExpressDto E7=new ExpressDto().setDeep(3).setSeq(7).setType("CONDITION").setResult(false).setField("D").setRelation("BEGIN");
ExpressDto E8=new ExpressDto().setDeep(3).setSeq(8).setType("CONDITION").setResult(false).setField("E").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
list.add(E7);
list.add(E8);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:(A)
*/
@Test
public void expTest5(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
E2.setResult(false);
list.set(1,E2);
Assertions.assertFalse(expressProcessor(list));
}🎜Ich habe einfach ein paar Testfälle geschrieben:🎜rrreee🎜Testergebnis:🎜🎜🎜🎜🎜Am Ende geschrieben🎜🎜An diesem Punkt ist eine Ausdrucksanalyse abgeschlossen. Gehen wir zurück und Schauen Sie sich dieses Bild noch einmal an:🎜🎜🎜🎜Wir können feststellen, dass die Funktion von Seq3 tatsächlich nur darin besteht, den Anfang einer Gruppe zu identifizieren und die Assoziation zwischen der Gruppe und anderen Elementen derselben Ebene aufzuzeichnen. Tatsächlich kann hier eine Optimierung durchgeführt werden: Wir finden das wann immer Der Anfang einer Gruppe. Die Vorassoziationsbeziehung des ersten Knotens muss Begin, Deep+1 sein. Tatsächlich können wir erwägen, die Gruppenassoziation auf diesem Knoten zu platzieren und dann die Beziehung der Gruppe nur durch die Erhöhung oder Verringerung von Deep zu steuern Auf diese Weise ist dieses Feld vom Typ „Ausdruck“ oder „Gruppe“ nicht erforderlich, und die Array-Länge wird entsprechend reduziert, aber ich persönlich denke, dass es etwas schwieriger zu verstehen sein wird. Hier ist eine allgemeine Idee der Transformation, und der Code wird nicht veröffentlicht:
- Ändern Sie die Beurteilung von Type="GROUP" im Code, um anhand der Differenz von deep = 1 zu beurteilen.
- Die Logik des Tiefenbeurteilungsstapels Änderung
- Beim Speichern des Beziehungssymbols müssen Sie auch die Tiefe speichern, die dem Beziehungssymbol entspricht. Bei der Verarbeitung von Legacy-Elementen mit derselben Tiefe, das heißt: In der Methode besteht die ursprüngliche Methode darin, das Begin-Element zu verwenden Unterscheiden Sie, ob die Gruppe verarbeitet wurde. Jetzt muss auf die folgende Methode umgestellt werden: Bestimmen Sie, ob die Tiefe eines Symbols mit der aktuellen Tiefe übereinstimmt, und löschen Sie die Popup-Logik zum BEGIN-Element
computeBeforeEndGroup()Empfohlenes Lernen : „
Das obige ist der detaillierte Inhalt vonBeispielhafte Einführung zur Implementierung eines komplexen relationalen Ausdrucksfilters auf Basis von Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!