
Heim >Datenbank >MySQL-Tutorial >JOIN-Betrieb der systematischen MySQL-Analyse
JOIN-Betrieb der systematischen MySQL-Analyse

- WBOYnach vorne
- 2022-07-29 15:02:281909Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL und führt hauptsächlich die systematische Diskussion der problematischen JOIN-Operation ein. In diesem Artikel wird eine systematische und ausführliche Diskussion der JOIN-Operation durchgeführt, basierend auf meiner eigenen Arbeitserfahrung und Referenzen zur Industrie Classics Cases werden verwendet, um Methoden zur grammatikalischen Vereinfachung und Leistungsoptimierung vorzuschlagen. Ich hoffe, dass sie für alle hilfreich sind.

Empfohlenes Lernen: MySQL-Video-Tutorial
Vorwort
- Ich habe Startup-Projekte von Grund auf erlebt, und es gibt auch große Datenprojekte; im Allgemeinen geht es darum, wie man ein sicheres und zuverlässiges Projekt aufbaut Entwickelt sich das Projekt nach und nach? Stabile Datenspeicherung war schon immer der Kern, der wichtigste und kritischste Teil des Projekts. Als nächstes werde ich die Artikelserie zur Speicherung systematisch ausgeben Eine der problematischsten Verbindungen in der Datenverarbeitung – JOIN
- JOIN war schon immer ein schwieriges Problem in SQL. Wenn es etwas mehr verwandte Tabellen gibt, wird das Schreiben von Code sehr fehleranfällig. Aufgrund der Komplexität von JOIN-Anweisungen waren verwandte Abfragen schon immer die Schwäche von BI-Software. Es gibt fast keine BI-Software, die es Geschäftsanwendern ermöglicht, mehrere Tabellen reibungslos abzuschließen -Tabellenzuordnungen. Das Gleiche gilt für die Leistungsoptimierung, wenn viele verknüpfte Tabellen oder große Datenmengen vorhanden sind. Es ist schwierig, die Leistung von JOIN zu verbessern.
- Basierend auf dem oben Gesagten wird in diesem Artikel eine systematische und ausführliche Diskussion von JOIN durchgeführt Basierend auf meiner eigenen Arbeitserfahrung und unter Bezugnahme auf klassische Fälle in der Branche stellen wir die Methodik zur Syntaxvereinfachung und Leistungsoptimierung gezielt vor und hoffen, dass sie für alle hilfreich ist
- Übersicht mit einem Bild
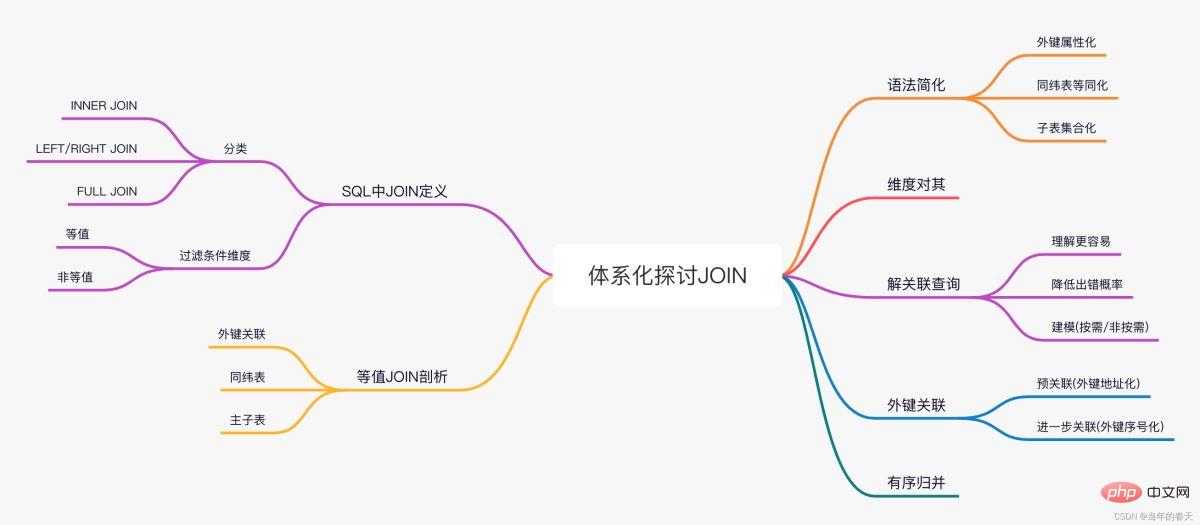 JOIN in SQL
JOIN in SQL
Wie versteht SQL die JOIN-Operation?
SQLs Definition von JOIN
Nach der Erstellung eines kartesischen Produkts aus zwei Mengen (Tabellen) und der anschließenden Filterung nach bestimmten Bedingungen lautet die geschriebene Syntax A JOIN B ON… .
- Theoretisch sollte die Ergebnismenge des kartesischen Produkts ein Tupel sein, das aus zwei Mengenmitgliedern besteht. Da es sich bei einer Menge jedoch um eine Tabelle handelt, verfügen ihre Mitglieder immer über Felddatensätze, und dies wird nicht unterstützt Ein Tupel, dessen Mitglieder Datensätze sind, sodass die Ergebnismenge einfach in eine Sammlung neuer Datensätze verarbeitet wird, die durch Zusammenführen der Felder der Datensätze in den beiden Tabellen gebildet wird.
- Dies ist auch die ursprüngliche Bedeutung des Wortes JOIN im Englischen (d. h. die Verbindung der Felder zweier Datensätze) und bedeutet nicht Multiplikation (kartesisches Produkt). Ob das kartesische Produktmitglied jedoch als Tupel oder als Datensatz eines zusammengeführten Feldes verstanden wird, hat keinen Einfluss auf unsere nachfolgende Diskussion.
JOIN-Definition
- Die Definition von JOIN legt nicht die Form der Filterbedingungen fest. Theoretisch handelt es sich um eine sinnvolle JOIN-Operation, solange die Ergebnismenge eine Teilmenge des kartesischen Produkts zweier Quellmengen ist.
- Beispiel: Angenommen, die Menge A={1,2},B={1,2,3}, das Ergebnis von A JOIN B ON A
JOIN-Klassifizierung
- Wir nennen die Filterbedingung für Gleichheit einen Äquivalenz-JOIN, und der Fall, in dem es sich nicht um eine Äquivalenzverbindung handelt, wird als Nicht-Äquivalenz-JOIN bezeichnet. Von diesen beiden Beispielen ist das erstere ein nicht äquivalenter JOIN und das letztere ein äquivalenter JOIN.
Equal JOIN
- Die Bedingung kann aus mehreren Gleichungen mit AND-Beziehung bestehen. Die Syntaxform lautet A JOIN B ON A.ai=B.bi AND…, wobei ai und bi die Felder von A bzw. B sind .
- Erfahrene Programmierer wissen, dass in Wirklichkeit die überwiegende Mehrheit der JOINs äquivalente JOINs sind, nicht äquivalente JOINs viel seltener sind und die meisten Fälle in äquivalente JOINs umgewandelt werden können. Daher konzentrieren wir uns hier auf die Diskussion äquivalenter JOINs und in den folgenden Diskussionen auf wir Als Beispiele werden hauptsächlich Tabellen und Datensätze anstelle von Mengen und Mitgliedern verwendet.
Klassifizierung nach Nullwert-Verarbeitungsregeln
- Gemäß den Verarbeitungsregeln für Nullwerte wird der strikte äquivalente JOIN auch INNER JOIN genannt und kann auch von LEFT JOIN und FULL JOIN abgeleitet werden. Es gibt drei Situationen (RIGHT JOIN). Wird als umgekehrte Assoziation von LEFT JOIN verstanden und ist kein separater Typ mehr.
- Wenn es um JOIN geht, wird es im Allgemeinen in Eins-zu-Eins-, Eins-zu-Viele-, Viele-zu-Eins- und Viele-zu-Viele-Situationen unterteilt, basierend auf der Anzahl der zugehörigen Datensätze (d. h. der Tupel, die sich treffen). die Filterbedingungen) in den beiden Tabellen. Diese allgemeinen Begriffe werden in SQL- und Datenbankmaterialien eingeführt und werden daher hier nicht wiederholt.
JOIN-Implementierung
Dummer Weg
- Der einfachste Weg, den man sich vorstellen kann, besteht darin, eine harte Durchquerung gemäß der Definition durchzuführen, ohne zwischen gleichem JOIN und nicht äquivalentem JOIN zu unterscheiden. Angenommen, Tabelle A hat n Datensätze und Tabelle B hat m Datensätze. Um A JOIN B ON A.a=B.b zu berechnen, beträgt die Komplexität der harten Durchquerung nm, d. h. es werden nm Berechnungen der Filterbedingungen durchgeführt.
- Offensichtlich wird dieser Algorithmus langsamer sein. Berichtstools, die mehrere Datenquellen unterstützen, verwenden jedoch manchmal diese langsame Methode, um eine Zuordnung zu erreichen, da die Zuordnung der Datensätze im Bericht (d. h. die Filterbedingungen im JOIN) aufgelöst und im Berechnungsausdruck von definiert wird Es ist nicht mehr erkennbar, dass es sich um eine JOIN-Operation zwischen mehreren Datensätzen handelt. Daher können wir diese zugehörigen Ausdrücke nur mit der Traversal-Methode berechnen.
Datenbankoptimierung für JOIN
- Für äquivalente JOINs verwendet die Datenbank im Allgemeinen den HASH JOIN-Algorithmus. Das heißt, die Datensätze in der Assoziationstabelle werden entsprechend dem HASH-Wert ihres Assoziationsschlüssels (entsprechend gleichen Feldern in den Filterbedingungen, also A.a und B.b) und den Datensätzen mit demselben HASH in mehrere Gruppen unterteilt Werte werden in einer Gruppe zusammengefasst. Wenn der HASH-Wertebereich 1...k beträgt, werden beide Tabellen A und B in k Teilmengen A1,...,Ak und B1,...,Bk unterteilt. Der in Ai aufgezeichnete HASH-Wert des zugehörigen Schlüssels a ist i, und der in Bi aufgezeichnete HASH-Wert des zugehörigen Schlüssels b ist ebenfalls i. Stellen Sie dann einfach eine Durchlaufverbindung zwischen Ai und Bi her.
- Da die Feldwerte unterschiedlich sein müssen, wenn der HASH unterschiedlich ist, können die Datensätze in Ai bei i! = j nicht mit den Datensätzen in Bj in Beziehung gesetzt werden. Wenn die Anzahl der Datensätze von Ai ni ist und die Anzahl der Datensätze von Bi mi, dann ist die Anzahl der Berechnungen der Filterbedingung SUM(ni*mi). Im durchschnittlichsten Fall ist ni=n/k, mi= m/k, dann insgesamt Die Komplexität beträgt nur 1/k der ursprünglichen Hard-Traversal-Methode, wodurch die Rechenleistung effektiv verbessert werden kann!
- Wenn Sie also den Korrelationsbericht für mehrere Datenquellen beschleunigen möchten, müssen Sie die Korrelation auch in der Datenvorbereitungsphase durchführen, da sonst die Leistung stark abnimmt, wenn die Datenmenge etwas größer ist.
- Allerdings garantiert die HASH-Funktion nicht immer eine gleichmäßige Aufteilung. Wenn Sie Pech haben, ist eine bestimmte Gruppe möglicherweise besonders groß und der Effekt der Leistungsverbesserung ist viel schlechter. Und Sie können keine zu komplexen HASH-Funktionen verwenden, da die Berechnung von HASH sonst mehr Zeit in Anspruch nimmt.
- Wenn die Datenmenge groß genug ist, um den Speicher zu überschreiten, verwendet die Datenbank die HASH-Heaping-Methode, eine Verallgemeinerung des HASH JOIN-Algorithmus. Durchsuchen Sie Tabelle A und Tabelle B, teilen Sie die Datensätze entsprechend dem HASH-Wert des zugehörigen Schlüssels in mehrere kleine Teilmengen auf und speichern Sie sie im externen Speicher, was als „Heaping“ bezeichnet wird. Führen Sie dann Speicher-JOIN-Operationen zwischen entsprechenden Heaps durch. Wenn der HASH-Wert unterschiedlich ist, muss auf die gleiche Weise auch der Schlüsselwert unterschiedlich sein und die Zuordnung muss zwischen den entsprechenden Heaps erfolgen. Auf diese Weise wird der JOIN von Big Data in den JOIN mehrerer kleiner Daten umgewandelt. Aber auch die HASH-Funktion hat ein Glücksproblem. Es kann vorkommen, dass ein bestimmter Heap zu groß ist, um in den Speicher geladen zu werden. Zu diesem Zeitpunkt wird möglicherweise ein zweiter HASH-Heap ausgeführt, dh es wird eine HASH-Funktion verwendet Um mit dieser Gruppe umzugehen, führen Sie den HASH-Heaping-Algorithmus erneut aus. Daher kann der JOIN-Vorgang für den externen Speicher mehrmals zwischengespeichert werden und seine Betriebsleistung ist etwas unkontrollierbar.
JOIN unter einem verteilten System
- Es ist ähnlich, JOIN unter einem verteilten System durchzuführen. Die Datensätze werden entsprechend dem HASH-Wert des zugehörigen Schlüssels, der als Shuffle-Aktion bezeichnet wird, verteilt dann wird jeder JOIN auf einem eigenständigen Computer durchgeführt. Wenn viele Knoten vorhanden sind, wird die durch das Netzwerkübertragungsvolumen verursachte Verzögerung die Vorteile der Aufgabenteilung auf mehreren Maschinen zunichte machen, sodass bei verteilten Datenbanksystemen normalerweise die Anzahl der Knoten begrenzt ist. Nach Erreichen des Limits können mehr Knoten vorhanden sein Ich bekomme keine bessere Leistung.
- Ein bestimmtes Feld von Tabelle A ist mit dem Primärschlüsselfeld von Tabelle B verknüpft (die sogenannte Feldzuordnung ist das, was gesagt wurde). im vorherigen Abschnitt) Die Filterbedingungen von gleichwertigem JOIN müssen gleichen Feldern entsprechen. Tabelle A heißt
- Faktentabelle und Tabelle B heißt Dimensionstabelle. Das Feld in Tabelle A, das dem Primärschlüssel von Tabelle B zugeordnet ist, wird als „Fremdschlüssel“ von A bezeichnet, der auf B zeigt, und B wird auch als Fremdschlüsseltabelle von A bezeichnet. Der hier erwähnte Primärschlüssel bezieht sich auf den logischen Primärschlüssel, dh auf ein Feld (eine Gruppe) mit einem eindeutigen Wert in der Tabelle, mit dem ein bestimmter Datensatz eindeutig erfasst werden kann. Es muss nicht unbedingt einen Primärschlüssel haben in der Datenbanktabelle festgelegt. Die Fremdschlüsseltabelle ist eine Viele-zu-Eins-Beziehung, es gibt nur JOIN und LEFT JOIN, und FULL JOIN ist sehr selten.
- Typische Fälle: Produkttransaktionstabelle und Produktinformationstabelle.
- Offensichtlich sind Fremdschlüsselassoziationen asymmetrisch. Die Speicherorte von Faktentabellen und Dimensionstabellen können nicht vertauscht werden.
- Tabelle mit gleichen Dimensionen
Der Primärschlüssel von Tabelle A hängt mit dem Primärschlüssel von Tabelle B zusammen. A und B heißen einander
Tabelle mit gleichen Dimensionen- . Tabellen derselben Dimension haben eine Eins-zu-Eins-Beziehung, und JOIN, LEFT JOIN und FULL JOIN sind alle vorhanden. In den meisten Lösungen für den Datenstrukturentwurf ist FULL JOIN jedoch relativ selten.
- Typische Fälle: Mitarbeitertisch und Managertisch. Tabellen gleicher Dimension sind symmetrisch und die beiden Tabellen haben den gleichen Status. Tabellen mit derselben Dimension bilden auch eine Äquivalenzbeziehung. A und B sind Tabellen mit derselben Dimension, und B und C sind Tabellen mit derselben Dimension. Dann sind A und C auch Tabellen mit derselben Dimension.
- Master-Untertabelle
Der Primärschlüssel von Tabelle A ist mit einigen Primärschlüsseln von Tabelle B verknüpft. A heißt „Haupttabelle“ und B heißt „Untertabelle“. Die Master-Child-Tabelle hat eine Eins-zu-viele-Beziehung. Es gibt nur JOIN und LEFT JOIN, aber keinen FULL JOIN.
- Typischer Fall: Bestellung und Bestelldetails.
- Die Haupt- und Untertabellen sind ebenfalls asymmetrisch und haben klare Richtungen. Im konzeptionellen System von SQL gibt es keinen Unterschied zwischen Fremdschlüsseltabellen und Master-Child-Tabellen. Aus SQL-Sicht haben Many-to-One und One-to-Many nur unterschiedliche Assoziationsrichtungen und sind im Wesentlichen die das Gleiche. Tatsächlich können Bestellungen auch als Fremdschlüsseltabellen mit Bestelldetails verstanden werden. Wir wollen sie hier jedoch unterscheiden und bei der Vereinfachung der Syntax und Optimierung der Leistung werden in Zukunft unterschiedliche Mittel zum Einsatz kommen. Wir sagen, dass diese drei JOIN-Typen die überwiegende Mehrheit der gleichwertigen JOIN-Situationen abdecken. Man kann sogar sagen, dass fast alle gleichwertigen JOINs mit geschäftlicher Bedeutung auf diese drei Situationen beschränkt sind verringert seinen adaptiven Bereich.
- Nachdem wir diese drei JOIN-Typen sorgfältig untersucht haben, stellten wir fest, dass alle Zuordnungen Primärschlüssel beinhalten und es keine Viele-zu-Viele-Situation gibt. Kann diese Situation ignoriert werden?
- Ja! Viele-zu-viele-äquivalente JOINs haben fast keine geschäftliche Bedeutung.
- Wenn die zugehörigen Felder beim Verbinden zweier Tabellen keinen Primärschlüssel beinhalten, tritt eine Viele-zu-Viele-Situation auf, und in diesem Fall wird es mit ziemlicher Sicherheit eine größere Tabelle geben, die diese beiden Tabellen als Dimensionstabellen verwendet. Wenn sich beispielsweise die Schülertabelle und die Fächertabelle in JOIN befinden, gibt es eine Notentabelle, die die Schülertabelle und die Fächertabelle als Dimensionstabellen verwendet. Ein JOIN, bei dem nur die Schülertabelle und die Fächertabelle vorhanden sind, hat keine geschäftliche Bedeutung.
- Wenn Sie beim Schreiben einer SQL-Anweisung auf eine Viele-zu-Viele-Situation stoßen, besteht eine hohe Wahrscheinlichkeit, dass die Anweisung falsch geschrieben ist! Oder es liegt ein Problem mit den Daten vor! Diese Regel ist sehr effektiv zur Beseitigung von JOIN-Fehlern.
- Allerdings haben wir „fast“ gesagt, ohne eine völlig sichere Aussage zu verwenden, das heißt, viele-zu-viele wird in sehr seltenen Fällen auch wirtschaftlich sinnvoll sein. Wenn Sie beispielsweise SQL zum Implementieren einer Matrixmultiplikation verwenden, tritt ein äquivalenter JOIN auf. Die spezifische Schreibmethode kann durch den Leser ergänzt werden.
- Die JOIN-Definition des kartesischen Produkts und die anschließende Filterung sind in der Tat sehr einfach, und die einfache Konnotation hat eine größere Erweiterung und kann viele-zu-viele-äquivalente JOINs und sogar nicht-äquivalente JOINs umfassen. Die zu einfache Konnotation kann jedoch die Betriebsmerkmale des am häufigsten verwendeten äquivalenten JOIN nicht vollständig widerspiegeln. Dies führt dazu, dass diese Funktionen beim Schreiben von Code und beim Implementieren von Vorgängen nicht genutzt werden können. Wenn der Vorgang komplexer ist (mit vielen zugehörigen Tabellen und verschachtelten Situationen), ist es sehr schwierig, ihn zu schreiben oder zu optimieren. Durch die vollständige Nutzung dieser Funktionen können wir einfachere Schreibformen erstellen und eine effizientere Rechenleistung erzielen, was im folgenden Inhalt schrittweise erläutert wird.
- Anstatt eine Operation in einer allgemeineren Form zu definieren, um seltene Fälle einzubeziehen, wäre es sinnvoller, diese Fälle als eine andere Operation zu definieren.
- Vereinfachung der JOIN-Syntax
- Wie nutzt man die Funktion, dass Zuordnungen Primärschlüssel beinhalten, um das Schreiben von JOIN-Code zu vereinfachen?
- Fremdschlüsselzuordnung
employee 员工表
id 员工编号
name 姓名
nationality 国籍
department 所属部门
department 部门表
id 部门编号
name 部门名称
manager 部门经理
- Die Primärschlüssel der Mitarbeitertabelle und der Abteilungstabelle sind beide das ID-Feld. Das Abteilungsfeld der Mitarbeitertabelle ist ein Fremdschlüssel, der auf die Abteilungstabelle zeigt die Mitarbeitertabelle (da der Manager auch ein Mitarbeiter ist). Dies ist ein sehr konventionelles Tischstrukturdesign.
- Jetzt wollen wir fragen: Welche amerikanischen Mitarbeiter haben einen chinesischen Manager? In SQL geschrieben handelt es sich um eine JOIN-Anweisung mit drei Tabellen:
SELECT A.*
FROM employee A
JOIN department B ON A.department=B.id
JOIN employee C ON B.manager=C.id
WHERE A.nationality='USA' AND C.nationality='CHN'
- Zuerst wird FROM Mitarbeiter verwendet, um Mitarbeiterinformationen abzurufen, und dann muss die Mitarbeitertabelle mit der Abteilung verknüpft werden, um die Abteilungsinformationen des Mitarbeiters zu erhalten, und dann die Die Abteilungstabelle muss mit der Mitarbeitertabelle verknüpft werden, um die Informationen des Managers abzurufen. Daher muss die Mitarbeitertabelle zweimal an JOIN teilnehmen. Zur Unterscheidung muss ein Alias in der SQL-Anweisung angegeben werden, wodurch der gesamte Satz kompliziert wird schwer zu verstehen.
- Wenn wir das Fremdschlüsselfeld direkt als den zugehörigen Dimensionstabellendatensatz verstehen, können wir es anders schreiben:
SELECT * FROM employee
WHERE nationality='USA' AND department.manager.nationality='CHN'
Natürlich ist dies keine Standard-SQL-Anweisung.
- Der fettgedruckte Teil im zweiten Satz gibt die „Nationalität des Abteilungsleiters“ des aktuellen Mitarbeiters an. Nachdem wir das Fremdschlüsselfeld als Datensatz der Dimensionstabelle verstanden haben, wird das Feld der Dimensionstabelle als Attribut der Fremdschlüsselabteilung verstanden. Manager ist der „Manager der Abteilung“, und dieses Feld ist immer noch ein Fremdschlüssel Geben Sie die Abteilung ein, dann ist es Das entsprechende Datensatzfeld der Dimensionstabelle kann weiterhin als sein Attribut verstanden werden, und es wird auch eine Abteilung.manager.nationalität geben, dh „die Nationalität des Managers der Abteilung, zu der er gehört“.
- Fremdschlüsselzuordnung: Diese objektartige Art des Verständnisses ist die Fremdschlüsselzuordnung, die offensichtlich viel natürlicher und intuitiver ist als die kartesische Produktfilterungsart des Verständnisses. JOIN von Fremdschlüsseltabellen beinhaltet keine Multiplikation der beiden Tabellen. Das Fremdschlüsselfeld wird nur zum Suchen des entsprechenden Datensatzes in der Dimensionsschlüsseltabelle verwendet und beinhaltet überhaupt keine Operationen mit Multiplikationsmerkmalen wie dem kartesischen Produkt.
- Wir haben zuvor vereinbart, dass der zugehörige Schlüssel in der Dimensionstabelle der Fremdschlüsselzuordnung der Primärschlüssel sein muss. Auf diese Weise ist der mit dem Fremdschlüsselfeld jedes Datensatzes in der Faktentabelle verknüpfte Dimensionstabellendatensatz eindeutig Beispielsweise ist das Abteilungsfeld jedes Datensatzes in der Mitarbeitertabelle eindeutig einem Datensatz in der Abteilungstabelle zugeordnet, und das Managerfeld jedes Datensatzes in der Abteilungstabelle ist ebenfalls eindeutig einem Datensatz in der Mitarbeitertabelle zugeordnet. Dadurch wird sichergestellt, dass „department.manager.nationality“ für jeden Datensatz in der Mitarbeitertabelle einen eindeutigen Wert hat und klar definiert werden kann.
- In der SQL-Definition von JOIN gibt es jedoch keine Primärschlüsselvereinbarung. Wenn es auf SQL-Regeln basiert, können die mit den Fremdschlüsseln in der Faktentabelle verknüpften Dimensionstabellendatensätze nicht als eindeutig bestimmt werden und können mit verknüpft werden Mehrere Datensätze. Für Mitarbeiter. In Bezug auf Tabellendatensätze kann „department.manager.nationality“ nicht verwendet werden, wenn es nicht klar definiert ist.
- Tatsächlich ist diese Art des Schreibens im Objektstil in Hochsprachen (wie C, Java) sehr verbreitet. In solchen Sprachen werden Daten in Form von Objekten gespeichert. Der Wert des Abteilungsfelds in der Mitarbeitertabelle ist einfach ein Objekt, keine Zahl. Tatsächlich hat der Primärschlüsselwert vieler Tabellen selbst keine geschäftliche Bedeutung. Er dient lediglich der Unterscheidung von Datensätzen, und das Fremdschlüsselfeld dient lediglich dazu, den entsprechenden Datensatz in der Dimensionstabelle zu finden. Es ist nicht erforderlich, eine Nummerierung zu verwenden. Allerdings kann SQL diesen Speichermechanismus nicht unterstützen und erfordert die Hilfe von Zahlen.
- Wir haben gesagt, dass die Fremdschlüsselzuordnung asymmetrisch ist, das heißt, die Faktentabelle und die Dimensionstabelle sind nicht gleich, und die Felder der Dimensionstabelle können nur basierend auf der Faktentabelle gefunden werden und nicht umgekehrt.
Entzerrung von Tabellen mit derselben Dimension
Die Situation von Tabellen mit derselben Dimension ist relativ einfach. Es gibt zwei Tabellen:
employee 员工表
id 员工编号
name 姓名
salary 工资
...
manager 经理表
id 员工编号
allowance 岗位津贴
....- Der Primärschlüssel beider Tabellen ist id, der Manager ist auch ein Mitarbeiter, und die beiden Tabellen haben dasselbe. Bei Mitarbeiterzahlen verfügen Manager über mehr Attribute als normale Mitarbeiter und werden in einer anderen Managertabelle gespeichert.
- Nun wollen wir das Gesamteinkommen (plus Zulagen) aller Mitarbeiter (einschließlich Führungskräfte) berechnen. Beim Schreiben in SQL wird weiterhin JOIN verwendet:
SELECT employee.id, employee.name, employy.salary+manager.allowance FROM employee LEFT JOIN manager ON employee.id=manager.id
Für zwei Eins-zu-eins-Tabellen können wir sie eigentlich einfach als eine Tabelle betrachten:
SELECT id,name,salary+allowance FROM employee
- Ebenso gilt gemäß unserer Vereinbarung die gleiche Dimension beim Verbinden von Tabellen , beide Tabellen sind entsprechend dem Primärschlüssel verknüpft, und die entsprechenden Datensätze sind für jeden Datensatz in der Mitarbeitertabelle eindeutig berechenbar, und es besteht keine Mehrdeutigkeit. Diese Vereinfachung wird als „gleichdimensionale Tabellenentzerrung“ bezeichnet. Die Beziehung zwischen Tabellen derselben Dimension ist gleich, und auf Felder anderer Tabellen derselben Dimension kann von jeder Tabelle aus verwiesen werden.
- Sammlung von Untertabellen
Bestellungen und Bestelldetails sind typische Master-Untertabellen:
Orders 订单表
id 订单编号
customer 客户
date 日期
...
OrderDetail 订单明细
id 订单编号
no 序号
product 订购产品
price 价格
...Der Primärschlüssel der Orders-Tabelle ist id, der Primärschlüssel der OrderDetail-Tabelle ist (id, no) und der Primärschlüssel von Ersteres ist Teil von Letzterem.
Jetzt wollen wir den Gesamtbetrag jeder Bestellung berechnen. In SQL geschrieben würde es so aussehen:
SELECT Orders.id, Orders.customer, SUM(OrderDetail.price) FROM Orders JOIN OrderDetail ON Orders.id=OrderDetail.id GROUP BY Orders.id, Orders.customer
- 要完成这个运算,不仅要用到JOIN,还需要做一次GROUP BY,否则选出来的记录数太多。
- 如果我们把子表中与主表相关的记录看成主表的一个字段,那么这个问题也可以不再使用JOIN以及GROUP BY:
SELECT id, customer, OrderDetail.SUM(price) FROM Orders
- 与普通字段不同,OrderDetail被看成Orders表的字段时,其取值将是一个集合,因为两个表是一对多的关系。所以要在这里使用聚合运算把集合值计算成单值。这种简化方式称为子表集合化。
- 这样看待主子表关联,不仅理解书写更为简单,而且不容易出错。
- 假如Orders表还有一个子表用于记录回款情况:
OrderPayment 订单回款表
id 订单编号
date 回款日期
amount 回款金额
....- 我们现在想知道那些订单还在欠钱,也就是累计回款金额小于订单总金额的订单。
- 简单地把这三个表JOIN起来是不对的,OrderDetail和OrderPayment会发生多对多的关系,这就错了(回忆前面提过的多对多大概率错误的说法)。这两个子表要分别先做GROUP,再一起与Orders表JOIN起来才能得到正确结果,会写成子查询的形式:
SELECT Orders.id, Orders.customer,A.x,B.y
FROM Orders
LEFT JOIN ( SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN ( SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x>B.y如果我们继续把子表看成主表的集合字段,那就很简单了:
SELECT id,customer,OrderDetail.SUM(price) x,OrderPayment.SUM(amount) y FROM Orders WHERE x>y
- 这种写法也不容易发生多对多的错误。
- 主子表关系是不对等的,不过两个方向的引用都有意义,上面谈了从主表引用子表的情况,从子表引用主表则和外键表类似。
- 我们改变对JOIN运算的看法,摒弃笛卡尔积的思路,把多表关联运算看成是稍复杂些的单表运算。这样,相当于把最常见的等值JOIN运算的关联消除了,甚至在语法中取消了JOIN关键字,书写和理解都要简单很多。
维度对齐语法
我们再回顾前面的双子表例子的SQL:
SELECT Orders.id, Orders.customer, A.x, B.y
FROM Orders
LEFT JOIN (SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN (SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x > B.y- 那么问题来了,这显然是个有业务意义的JOIN,它算是前面所说的哪一类呢?
- 这个JOIN涉及了表Orders和子查询A与B,仔细观察会发现,子查询带有GROUP BY id的子句,显然,其结果集将以id为主键。这样,JOIN涉及的三个表(子查询也算作是个临时表)的主键是相同的,它们是一对一的同维表,仍然在前述的范围内。
- 但是,这个同维表JOIN却不能用前面说的写法简化,子查询A,B都不能省略不写。
- 可以简化书写的原因:我们假定事先知道数据结构中这些表之间的关联关系。用技术术语的说法,就是知道数据库的元数据(metadata)。而对于临时产生的子查询,显然不可能事先定义在元数据中了,这时候就必须明确指定要JOIN的表(子查询)。
- 不过,虽然JOIN的表(子查询)不能省略,但关联字段总是主键。子查询的主键总是由GROUP BY产生,而GROUP BY的字段一定要被选出用于做外层JOIN;并且这几个子查询涉及的子表是互相独立的,它们之间不会再有关联计算了,我们就可以把GROUP动作以及聚合式直接放到主句中,从而消除一层子查询:
SELECT Orders.id, Orders.customer, OrderDetail.SUM(price) x, OrderParyment.SUM(amount) y FROM Orders LEFT JOIN OrderDetail GROUP BY id LEFT JOIN OrderPayment GROUP BY id WHERE A.x > B.y
- 这里的JOIN和SQL定义的JOIN运算已经差别很大,完全没有笛卡尔积的意思了。而且,也不同于SQL的JOIN运算将定义在任何两个表之间,这里的JOIN,OrderDetail和OrderPayment以及Orders都是向一个共同的主键id对齐,即所有表都向某一套基准维度对齐。而由于各表的维度(主键)不同,对齐时可能会有GROUP BY,在引用该表字段时就会相应地出现聚合运算。OrderDetail和OrderPayment甚至Orders之间都不直接发生关联,在书写运算时当然就不用关心它们之间的关系,甚至不必关心另一个表是否存在。而SQL那种笛卡尔积式的JOIN则总要找一个甚至多个表来定义关联,一旦减少或修改表时就要同时考虑关联表,增大理解难度。
- 维度对齐:这种JOIN称即为维度对齐,它并不超出我们前面说过的三种JOIN范围,但确实在语法描述上会有不同,这里的JOIN不象SQL中是个动词,却更象个连词。而且,和前面三种基本JOIN中不会或很少发生FULL JOIN的情况不同,维度对齐的场景下FULL JOIN并不是很罕见的情况。
- 虽然我们从主子表的例子抽象出维度对齐,但这种JOIN并不要求JOIN的表是主子表(事实上从前面的语法可知,主子表运算还不用写这么麻烦),任何多个表都可以这么关联,而且关联字段也完全不必要是主键或主键的部分。
- 设有合同表,回款表和发票表:
Contract 合同表
id 合同编号
date 签订日期
customer 客户
price 合同金额
...
Payment 回款表
seq 回款序号
date 回款日期
source 回款来源
amount 金额
...
Invoice 发票表
code 发票编号
date 开票日期
customer 客户
amount 开票金额
...现在想统计每一天的合同额、回款额以及发票额,就可以写成:
SELECT Contract.SUM(price), Payment.SUM(amount), Invoice.SUM(amount) ON date FROM Contract GROUP BY date FULL JOIN Payment GROUP BY date FULL JOIN Invoice GROUP BY date
- 这里需要把date在SELECT后单独列出来表示结果集按日期对齐。
- 这种写法,不必关心这三个表之间的关联关系,各自写各自有关的部分就行,似乎这几个表就没有关联关系,把它们连到一起的就是那个要共同对齐的维度(这里是date)。
- 这几种JOIN情况还可能混合出现。
- 继续举例,延用上面的合同表,再有客户表和销售员表
Customer 客户表
id 客户编号
name 客户名称
area 所在地区
...
Sales 销售员表
id 员工编号
name 姓名
area 负责地区
...- 其中Contract表中customer字段是指向Customer表的外键。
- 现在我们想统计每个地区的销售员数量及合同额:
SELECT Sales.COUNT(1), Contract.SUM(price) ON area FROM Sales GROUP BY area FULL JOIN Contract GROUP BY customer.area
- 维度对齐可以和外键属性化的写法配合合作。
- 这些例子中,最终的JOIN都是同维表。事实上,维度对齐还有主子表对齐的情况,不过相对罕见,我们这里就不深入讨论了。
- 另外,目前这些简化语法仍然是示意性,需要在严格定义维度概念之后才能相应地形式化,成为可以解释执行的句子。
- 我们把这种简化的语法称为DQL(Dimensional Query Languange),DQL是以维度为核心的查询语言。我们已经将DQL在工程上做了实现,并作为润乾报表的DQL服务器发布出来,它能将DQL语句翻译成SQL语句执行,也就是可以在任何关系数据库上运行。
- 对DQL理论和应用感兴趣的读者可以关注乾学院上发布的论文和相关文章。
解决关联查询
多表JOIN问题
- 我们知道,SQL允许用WHERE来写JOIN运算的过滤条件(回顾原始的笛卡尔积式的定义),很多程序员也习惯于这么写。
- 当JOIN表只有两三个的时候,那问题还不大,但如果JOIN表有七八个甚至十几个的时候,漏写一个JOIN条件是很有可能的。而漏写了JOIN条件意味着将发生多对多的完全叉乘,而这个SQL却可以正常执行,会有以下两点危害:
- 一方面计算结果会出错:回忆一下以前说过的,发生多对多JOIN时,大概率是语句写错了
- 另一方面,如果漏写条件的表很大,笛卡尔积的规模将是平方级的,这极有可能把数据库直接“跑死”!
简化JOIN运算好处:
- 一个直接的效果显然是让语句书写和理解更容易
- 外键属性化、同维表等同化和子表集合化方案直接消除了显式的关联运算,也更符合自然思维
- 维度对齐则可让程序员不再关心表间关系,降低语句的复杂度
- 简化JOIN语法的好处不仅在于此,还能够降低出错率,采用简化后的JOIN语法,就不可能发生漏写JOIN条件的情况了。因为对JOIN的理解不再是以笛卡尔积为基础,而且设计这些语法时已经假定了多对多关联没有业务意义,这个规则下写不出完全叉乘的运算。
- 对于多个子表分组后与主表对齐的运算,在SQL中要写成多个子查询的形式。但如果只有一个子表时,可以先JOIN再GROUP,这时不需要子查询。有些程序员没有仔细分析,会把这种写法推广到多个子表的情况,也先JOIN再GROUP,可以避免使用子查询,但计算结果是错误的。
- 使用维度对齐的写法就不容易发生这种错误了,无论多少个子表,都不需要子查询,一个子表和多个子表的写法完全相同。
关联查询
- 重新看待JOIN运算,最关键的作用在于实现关联查询。
- 当前BI产品是个热门,各家产品都宣称能够让业务人员拖拖拽拽就完成想要的查询报表。但实际应用效果会远不如人意,业务人员仍然要经常求助于IT部门。造成这个现象的主要原因在于大多数业务查询都是有过程的计算,本来也不可能拖拽完成。但是,也有一部分业务查询并不涉及多步过程,而业务人员仍然难以完成。
- 这就是关联查询,也是大多数BI产品的软肋。在之前的文章中已经讲过为什么关联查询很难做,其根本原因就在于SQL对JOIN的定义过于简单。
- 结果,BI产品的工作模式就变成先由技术人员构建模型,再由业务人员基于模型进行查询。而所谓建模,就是生成一个逻辑上或物理上的宽表。也就是说,建模要针对不同的关联需求分别实现,我们称之为按需建模,这时候的BI也就失去敏捷性了。
- 但是,如果我们改变了对JOIN运算的看法,关联查询可以从根本上得到解决。回忆前面讲过的三种JOIN及其简化手段,我们事实上把这几种情况的多表关联都转化成了单表查询,而业务用户对于单表查询并没有理解障碍。无非就是表的属性(字段)稍复杂了一些:可能有子属性(外键字段指向的维表并引用其字段),子属性可能还有子属性(多层的维表),有些字段取值是集合而非单值(子表看作为主表的字段)。发生互相关联甚至自我关联也不会影响理解(前面的中国经理的美国员工例子就是互关联),同表有相同维度当然更不碍事(各自有各自的子属性)。
- 在这种关联机制下,技术人员只要一次性把数据结构(元数据)定义好,在合适的界面下(把表的字段列成有层次的树状而不是常规的线状),就可以由业务人员自己实现JOIN运算,不再需要技术人员的参与。数据建模只发生于数据结构改变的时刻,而不需要为新的关联需求建模,这也就是非按需建模,在这种机制支持下的BI才能拥有足够的敏捷性。
外键预关联
- 我们再来研究如何利用JOIN的特征实现性能优化,这些内容的细节较多,我们挑一些易于理解的情况来举例,更完善的连接提速算法可以参考乾学院上的《性能优化》图书和SPL学习资料中的性能优化专题文章。
全内存下外键关联情况
设有两个表:
customer 客户信息表
key 编号
name 名称
city 城市
...
orders 订单表
seq 序号
date 日期
custkey 客户编号
amount 金额
...- 其中orders表中的custkey是指向customer表中key字段的外键,key是customer表的主键。
- 现在我们各个城市的订单总额(为简化讨论,就不再设定条件了),用SQL写出来:
SELECT customer.city, SUM(orders.amount) FROM orders JOIN customer ON orders.custkey=customer.key GROUP BY customer.city
- 数据库一般会使用HASH JOIN算法,需要分别两个表中关联键的HASH值并比对。
- 我们用前述的简化的JOIN语法(DQL)写出这个运算:
SELECT custkey.city, SUM(amount) FROM orders GROUP BY custkey.city
- 这个写法其实也就预示了它还可以有更好的优化方案,下面来看看怎样实现。
- 如果所有数据都能够装入内存,我们可以实现外键地址化。
- 将事实表orders中的外键字段custkey,转换成维表customer中关联记录的地址,即orders表的custkey的取值已经是某个customer表中的记录,那么就可以直接引用记录的字段进行计算了。
- 用SQL无法描述这个运算的细节过程,我们使用SPL来描述、并用文件作为数据源来说明计算过程:
| A | |
|---|---|
| 1 | =file(“customer.btx”).import@b() |
| 2 | >A1.keys@i(key) |
| 3 | =file(“orders.btx”).import@b() |
| 4 | >A3.switch(custkey,A1) |
| 5 | =A3.groups(custkey.city;sum(amount)) |
- A1 liest die Kundentabelle und A2 legt den Primärschlüssel fest und erstellt einen Index für die Kundentabelle.
- A3 liest die Bestelltabelle. Die Aktion von A4 besteht darin, das Fremdschlüsselfeld custkey von A3 in den entsprechenden Datensatz von A1 umzuwandeln. Nach der Ausführung wird das Bestelltabellenfeld custkey zu einem Datensatz der Kundentabelle. A2 erstellt einen Index, um den Wechsel zu beschleunigen, da die Faktentabelle normalerweise viel größer als die Dimensionstabelle ist und dieser Index viele Male wiederverwendet werden kann.
- A5 kann eine Gruppenzusammenfassung durchführen, da der Wert des Custkey-Felds jetzt ein Datensatz ist, Sie können den Operator direkt verwenden, um auf sein Feld zu verweisen, und custkey.city kann normal ausgeführt werden.
- Nach Abschluss der Wechselaktion in A4 ist der im Custkey-Feld der Faktentabelle A3 im Speicher gespeicherte Inhalt bereits die Adresse eines Datensatzes in der Dimensionstabelle A1. Diese Aktion wird als Fremdschlüsseladressierung bezeichnet. Wenn auf die Dimensionstabellenfelder verwiesen wird, können diese zu diesem Zeitpunkt direkt abgerufen werden, ohne den Fremdschlüsselwert für die Suche in A1 zu verwenden. Dies entspricht dem Abrufen der Dimensionstabellenfelder in einer konstanten Zeit, wodurch die Berechnung und der Vergleich von HASH-Werten vermieden werden.
- Allerdings verwendet A2 im Allgemeinen die HASH-Methode, um den Primärschlüsselindex zu erstellen und den HASH-Wert für den Schlüssel zu berechnen. Wenn A4 die Adresse konvertiert, berechnet es auch den HASH-Wert des Custkeys und vergleicht ihn mit der HASH-Indextabelle von A2 . Wenn nur eine Korrelationsoperation durchgeführt wird, ist der Berechnungsaufwand des Adressschemas und des herkömmlichen HASH-Segmentierungsschemas grundsätzlich gleich und es gibt keinen grundsätzlichen Vorteil.
- Aber der Unterschied besteht darin, dass diese Adresse nach der Konvertierung wiederverwendet werden kann, wenn die Daten im Speicher abgelegt werden können. Das heißt, A1 bis A4 müssen nur einmal durchgeführt werden und es besteht keine Notwendigkeit, den zugehörigen Vorgang auszuführen Durch die Berechnung und den Vergleich dieser beiden Felder kann die Leistung erheblich verbessert werden.
- Die Möglichkeit, dies zu tun, nutzt die Eindeutigkeit der Fremdschlüsselzuordnung in der zuvor erwähnten Dimensionstabelle. Ein Fremdschlüsselfeldwert entspricht nur einem Dimensionstabellendatensatz, und jeder Custkey kann in seinen eindeutigen entsprechenden umgewandelt werden A1-Rekord. Wenn wir jedoch weiterhin die Definition von JOIN in SQL verwenden, können wir nicht davon ausgehen, dass der Fremdschlüssel auf die Eindeutigkeit des Datensatzes verweist, und diese Darstellung kann nicht verwendet werden. Darüber hinaus erfasst SQL nicht den Datentyp der Adresse. Daher muss der HASH-Wert für jede Zuordnung berechnet und verglichen werden.
- Wenn außerdem mehrere Fremdschlüssel in der Faktentabelle vorhanden sind, die auf mehrere Dimensionstabellen verweisen, kann die herkömmliche HASH-segmentierte JOIN-Lösung nur einen nach dem anderen analysieren. Wenn mehrere JOINs vorhanden sind, müssen nach jeder Zuordnung mehrere Aktionen ausgeführt werden. Zwischenergebnisse müssen für die nächste Runde aufbewahrt werden, der Berechnungsprozess ist viel komplexer und die Daten werden mehrfach durchlaufen. Bei mehreren Fremdschlüsseln muss das Fremdschlüsseladressierungsschema die Faktentabelle nur einmal und ohne Zwischenergebnisse durchlaufen, und der Berechnungsprozess ist viel klarer.
- Ein weiterer Punkt ist, dass Speicher ursprünglich sehr gut für paralleles Rechnen geeignet ist, der HASH-segmentierte JOIN-Algorithmus jedoch nicht einfach zu parallelisieren ist. Selbst wenn die Daten segmentiert sind und HASH-Werte parallel berechnet werden, müssen Datensätze mit demselben HASH-Wert für die nächste Vergleichsrunde gruppiert werden, und es kommt zu einer gemeinsamen Ressourcenpräemption, wodurch viele Vorteile der parallelen Berechnung verloren gehen. Unter dem Fremdschlüssel-JOIN-Modell ist der Status der beiden zugehörigen Tabellen nicht gleich. Nachdem die Dimensionstabelle und die Faktentabelle klar unterschieden wurden, können parallele Berechnungen durchgeführt werden, indem die Faktentabelle einfach segmentiert wird.
- Nach der Transformation der HASH-Segmentierungstechnologie unter Bezugnahme auf das Fremdschlüsselattributschema kann auch die Fähigkeit verbessert werden, mehrere Fremdschlüssel gleichzeitig zu analysieren und bis zu einem gewissen Grad zu parallelisieren. Einige Datenbanken können diese Optimierung auf technischer Ebene implementieren. Diese Optimierung stellt jedoch kein großes Problem dar, wenn nur zwei JOIN-Tabellen vorhanden sind. Wenn viele Tabellen und verschiedene JOINs miteinander vermischt sind, ist es für die Datenbank nicht einfach zu identifizieren, welche Tabelle als Faktentabelle für die parallele Durchquerung verwendet werden soll. und andere Tabellen sollten parallel durchlaufen werden. Beim Erstellen eines HASH-Index als Dimensionstabelle ist die Optimierung nicht immer effektiv. Daher stellen wir häufig fest, dass die Leistung stark abnimmt, wenn die Anzahl der JOIN-Tabellen zunimmt (dies tritt häufig auf, wenn vier oder fünf Tabellen vorhanden sind und die Ergebnismenge nicht wesentlich zunimmt). Nach der Einführung des Fremdschlüsselkonzepts aus dem JOIN-Modell kann bei der spezifischen Verarbeitung dieser Art von JOIN immer zwischen Faktentabelle und Dimensionstabelle unterschieden werden. Weitere JOIN-Tabellen führen nur zu einem linearen Leistungsabfall.
- In-Memory-Datenbanken sind derzeit eine heiße Technologie, aber die obige Analyse zeigt, dass es für eine In-Memory-Datenbank, die das SQL-Modell verwendet, schwierig ist, JOIN-Vorgänge schnell auszuführen!
Weitere Fremdschlüsselzuordnung
- Wir besprechen weiterhin Fremdschlüssel-JOIN und verwenden weiterhin das Beispiel aus dem vorherigen Abschnitt.
- Wenn die Datenmenge zu groß ist, um in den Speicher zu passen, ist die oben genannte Adressierungsmethode nicht mehr wirksam, da die vorberechnete Adresse nicht im externen Speicher gespeichert werden kann.
- Im Allgemeinen hat die Dimensionstabelle, auf die der Fremdschlüssel verweist, eine geringere Kapazität, während die wachsende Faktentabelle viel größer ist. Wenn der Speicher noch Platz für die Dimensionstabelle bietet, können wir die temporäre Zeigemethode verwenden, um Fremdschlüssel zu verarbeiten.
| A | |
|---|---|
| 1 | =file("customer.btx").import@b() |
| 2 | =file("orders.btx"). Cursor@b() |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2.groups(custkey.city;sum(amount)) |
- Die ersten beiden Schritte sind die gleichen wie im Vollspeicher. Die Adresskonvertierung in Schritt 4 wird beim Lesen durchgeführt und die Konvertierungsergebnisse können nicht beibehalten und wiederverwendet werden. Der HASH und der Vergleich müssen bei der nächsten Zuordnung erneut berechnet werden Zeit und die Leistung wird schlechter sein als bei der Lösung mit vollem Speicher. In Bezug auf den Berechnungsaufwand gibt es im Vergleich zum HASH JOIN-Algorithmus eine Berechnung weniger für den HASH-Wert der Dimensionstabelle. Wenn diese Dimensionstabelle häufig wiederverwendet wird, ist dies etwas vorteilhaft, da die Dimensionstabelle jedoch relativ klein ist. Der Gesamtvorteil ist nicht groß. Dieser Algorithmus verfügt jedoch auch über die Eigenschaften eines Vollspeicheralgorithmus, der alle Fremdschlüssel auf einmal analysieren kann und leicht zu parallelisieren ist. In tatsächlichen Szenarien bietet er immer noch einen größeren Leistungsvorteil als der HASH JOIN-Algorithmus.
Fremdschlüssel-Serialisierung
Basierend auf diesem Algorithmus können wir auch eine Variante erstellen: Fremdschlüssel-Serialisierung.
Wenn wir die Primärschlüssel der Dimensionstabelle in natürliche Zahlen ab 1 umwandeln können, können wir die Seriennummer verwenden, um den Datensatz der Dimensionstabelle direkt zu lokalisieren, ohne den HASH-Wert berechnen und vergleichen zu müssen Erhalten Sie eine ähnliche Adresse bei voller Speicherleistung.
| A | |
|---|---|
| 1 | =file(“customer.btx”).import@b() |
| 2 | =file(“orders.btx”).cursor@b () |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2.groups(custkey.city;sum(amount)) |
- Wenn der Primärschlüssel der Dimensionstabelle die Seriennummer ist, ist der zweite Schritt zum Erstellen des HASH-Index nicht erforderlich.
- Die Serialisierung von Fremdschlüsseln entspricht im Wesentlichen der Adressierung im externen Speicher. Diese Lösung erfordert die Umwandlung der Fremdschlüsselfelder in der Faktentabelle in Seriennummern, was dem Adressierungsprozess bei Vollspeicheroperationen ähnelt. Diese Vorberechnung kann auch wiederverwendet werden. Es ist zu beachten, dass bei größeren Änderungen in der Dimensionstabelle die Fremdschlüsselfelder der Faktentabelle synchron organisiert werden müssen, da sonst die Korrespondenz möglicherweise falsch ausgerichtet ist. Die Häufigkeit allgemeiner Dimensionstabellenänderungen ist jedoch gering und bei den meisten Aktionen handelt es sich eher um Hinzufügungen und Änderungen als um Löschungen, sodass es nicht viele Situationen gibt, in denen die Faktentabelle neu organisiert werden muss. Einzelheiten zum Ingenieurwesen können Sie auch den Informationen in der Cadre Academy entnehmen.
- SQL verwendet das Konzept ungeordneter Mengen. Selbst wenn wir Fremdschlüssel im Voraus serialisieren, kann die Datenbank diese Funktion nicht nutzen. Der Mechanismus zur schnellen Positionierung von Seriennummern kann nicht für ungeordnete Mengen verwendet werden. und die Datenbank weiß nicht, dass die Fremdschlüssel serialisiert sind, aber der HASH-Wert und der Vergleich werden trotzdem berechnet.
- Was passiert, wenn die Dimensionstabelle zu groß ist, um in den Speicher zu passen?
- Wenn wir den obigen Algorithmus sorgfältig analysieren, werden wir feststellen, dass der Zugriff auf die Faktentabelle kontinuierlich erfolgt, der Zugriff auf die Dimensionstabelle jedoch zufällig. Als wir zuvor die Leistungsmerkmale von Festplatten besprochen haben, haben wir erwähnt, dass der externe Speicher nicht für den Direktzugriff geeignet ist, sodass die Dimensionstabellen im externen Speicher den oben genannten Algorithmus nicht mehr verwenden können.
- Dimensionstabellen im externen Speicher können vorab nach Primärschlüssel sortiert und gespeichert werden, sodass wir weiterhin die Funktion nutzen können, dass der zugehörige Schlüssel der Dimensionstabelle der Primärschlüssel ist, um die Leistung zu optimieren.
- Wenn die Faktentabelle klein ist und in den Speicher geladen werden kann, wird die Verwendung von Fremdschlüsseln zum Zuordnen von Dimensionstabellendatensätzen tatsächlich zu einem (Batch-)Suchvorgang im externen Speicher. Solange ein Index für den Primärschlüssel in der Dimensionstabelle vorhanden ist, kann dieser schnell durchsucht werden. Dadurch kann das Durchlaufen großer Dimensionstabellen vermieden und eine bessere Leistung erzielt werden. Dieser Algorithmus kann auch mehrere Fremdschlüssel gleichzeitig auflösen. SQL unterscheidet nicht zwischen Dimensionstabellen und Faktentabellen. Bei zwei Tabellen, einer großen und einer kleinen, führt der optimierte HASH JOIN normalerweise kein Heap-Caching mehr durch. Die kleine Tabelle wird normalerweise in den Speicher eingelesen Dies wird immer noch dazu führen, dass die Leistung beim Durchlaufen einer großen Dimensionstabelle viel schlechter ist als beim gerade erwähnten externen Speichersuchalgorithmus.
- Wenn die Faktentabelle ebenfalls sehr groß ist, können Sie den einseitigen Heaping-Algorithmus verwenden. Da die Dimensionstabelle nach dem zugehörigen Schlüssel (d. h. Primärschlüssel) geordnet wurde, kann sie leicht logisch in mehrere Segmente unterteilt werden und der Grenzwert jedes Segments (der Maximal- und Minimalwert des Primärschlüssels jedes Segments) entnommen werden. Anschließend wird die Faktentabelle gemäß diesen Grenzwerten in Stapel unterteilt. Jeder Stapel kann jedem Segment der Dimensionstabelle zugeordnet werden. Dabei muss nur die Faktentabellenseite physisch zwischengespeichert werden, und die Dimensionstabelle muss nicht physisch zwischengespeichert werden. Darüber hinaus wird die HASH-Funktion nicht verwendet, und die Segmentierung kann nicht direkt verwendet werden Wenn Sie Pech haben und eine sekundäre Heap-Segmentierung verursachen, ist die Leistung kontrollierbar. Der HASH-Heaping-Algorithmus der Datenbank führt einen physischen Heaping-Cache für beide großen Tabellen durch, d. Zu viel und immer noch unkontrollierbar.
Nutzen Sie die Leistungsfähigkeit von Clustern, um großdimensionale Tabellenprobleme zu lösen.
- Wenn der Speicher einer Maschine nicht untergebracht werden kann, können Sie mehrere weitere Maschinen dazu besorgen und die Dimensionstabellen segmentiert nach Primärschlüsselwerten auf mehreren Maschinen speichern, um eine Cluster-Dimensionstabelle zu bilden, und dann Sie Der Algorithmus der Speicherdimensionstabelle kann weiterhin den oben genannten Algorithmus verwenden und die Vorteile des gleichzeitigen Parsens mehrerer Fremdschlüssel und der einfachen Parallelisierung nutzen. Ebenso können Cluster-Dimensionstabellen auch Serialisierungstechnologie verwenden. Bei diesem Algorithmus muss die Faktentabelle nicht übertragen werden, der Umfang der generierten Netzwerkübertragung ist nicht groß und es besteht keine Notwendigkeit, Daten lokal auf dem Knoten zwischenzuspeichern. Allerdings können Dimensionstabellen im SQL-System nicht unterschieden werden. Die HASH-Aufteilungsmethode erfordert das Mischen beider Tabellen, und der Umfang der Netzwerkübertragung ist viel größer.
- Die Details dieser Algorithmen sind noch etwas kompliziert und können hier aus Platzgründen nicht im Detail erläutert werden. Interessierte Leser können die Informationen auf der Qian Academy nachlesen.
Geordnete Zusammenführung
Join-Optimierungsbeschleunigungsmethode für gleichdimensionale Tabellen und Master-Child-Tabellen
- Wir haben zuvor besprochen, dass die rechnerische Komplexität des HASH JOIN-Algorithmus (d. h. die Anzahl der Vergleiche der zugehörigen Schlüssel) ist SUM (nimi), was höher ist als die vollständige Durchquerung nm. Die Komplexität ist viel geringer, hängt jedoch vom Glück der HASH-Funktion ab.
- Wenn beide Tabellen nach den zugehörigen Schlüsseln sortiert sind, können wir den Zusammenführungsalgorithmus verwenden, um die Zuordnung zu verarbeiten. Die Komplexität beträgt zu diesem Zeitpunkt n + m; der Funktion) wird diese Zahl auch viel kleiner sein als die Komplexität des HASH JOIN-Algorithmus. Es gibt viele Materialien, in denen die Details des Zusammenführungsalgorithmus vorgestellt werden, daher werde ich hier nicht auf Details eingehen.
- Diese Methode kann jedoch nicht verwendet werden, wenn Fremdschlüssel-JOIN verwendet wird, da die Faktentabelle möglicherweise mehrere Fremdschlüsselfelder enthält, die an der Zuordnung teilnehmen müssen, und es unmöglich ist, dieselbe Faktentabelle für mehrere Felder gleichzeitig zu bestellen Zeit.
- Es können die gleiche Dimensionstabelle und die gleiche Master-Child-Tabelle verwendet werden! Da sich die gleichdimensionalen Tabellen und Master-Child-Tabellen immer auf den Primärschlüssel oder einen Teil des Primärschlüssels beziehen, können wir die Daten in diesen verwandten Tabellen vorab nach ihren Primärschlüsseln sortieren. Obwohl die Sortierkosten höher sind, fallen sie einmalig an. Sobald die Sortierung abgeschlossen ist, können Sie in Zukunft jederzeit den Zusammenführungsalgorithmus verwenden, um JOIN zu implementieren, und die Leistung kann erheblich verbessert werden.
- Dabei wird weiterhin die Funktion ausgenutzt, dass der zugehörige Schlüssel der Primärschlüssel (und seine Teile) ist.
- Geordnete Zusammenführung ist besonders effektiv für Big Data.Master- und Untertabellen wie Bestellungen und deren Details sind wachsende Faktentabellen, die sich mit der Zeit oft sehr groß ansammeln und leicht die Speicherkapazität überschreiten können.
- Der HASH-Heaping-Algorithmus für große Datenmengen im externen Speicher muss viel Cache generieren. Die Daten werden zweimal gelesen und einmal in den externen Speicher geschrieben, was zu einem hohen E/A-Overhead führt. Beim Zusammenführungsalgorithmus müssen die Daten in beiden Tabellen nur einmal gelesen werden, ohne dass sie geschrieben werden müssen. Es wird nicht nur der Rechenaufwand der CPU reduziert, sondern auch der IO-Anteil des externen Speichers deutlich reduziert. Darüber hinaus ist für die Ausführung des Zusammenführungsalgorithmus nur sehr wenig Speicher erforderlich. Solange für jede Tabelle mehrere Cache-Datensätze gespeichert werden, hat dies kaum Auswirkungen auf den Speicherbedarf anderer gleichzeitiger Aufgaben. Das HASH-Heaping erfordert einen größeren Speicher und liest jedes Mal mehr Daten, um die Anzahl der Heapvorgänge zu reduzieren.
- SQL verwendet die durch das kartesische Produkt definierte JOIN-Operation und unterscheidet nicht zwischen JOIN-Typen. Ohne davon auszugehen, dass einige JOINs immer auf den Primärschlüssel abzielen, gibt es keine Möglichkeit, diese Funktion auf Algorithmusebene zu nutzen auf technischer Ebene optimiert werden. Einige Datenbanken prüfen, ob die Datentabelle für die zugehörigen Felder physisch geordnet ist, und verwenden in diesem Fall den Zusammenführungsalgorithmus. Allerdings stellen relationale Datenbanken, die auf dem Konzept ungeordneter Mengen basieren, die physische Ordnung der Daten und vieler Vorgänge nicht sicher wird die Zusammenführungsbedingungen des Algorithmus zerstören. Durch die Verwendung von Indizes kann eine logische Reihenfolge der Daten erreicht werden, die Durchlaufeffizienz wird jedoch immer noch erheblich verringert, wenn die Daten physisch ungeordnet sind.
- Die Voraussetzung für die geordnete Zusammenführung besteht darin, die Daten nach dem Primärschlüssel zu sortieren. Diese Art von Daten wird häufig kontinuierlich angehängt. Im Prinzip müssen sie nach jedem Anhängen erneut sortiert werden, und wir wissen, dass das Sortieren großer Datenmengen teuer ist ist normalerweise sehr hoch. Wird dies dazu führen, dass die Daten sehr schwierig sind? Tatsächlich ist das Anhängen und anschließende Hinzufügen von Daten auch eine geordnete Zusammenführung. Die neuen Daten werden separat sortiert und mit den geordneten historischen Daten zusammengeführt. Die Komplexität ist linear, was im Gegensatz zu herkömmlichen Big-Daten dem einmaligen Umschreiben entspricht Die Datensortierung erfordert zwischengespeichertes Schreiben und Lesen. Durch einige Optimierungsmaßnahmen im Engineering kann auch die Notwendigkeit entfallen, jedes Mal alles neu zu schreiben, was die Wartungseffizienz weiter verbessert. Diese werden in der Cadre Academy eingeführt.
Segmentierte Parallelität
- Der Vorteil der geordneten Zusammenführung besteht darin, dass die Parallelisierung in Segmenten einfach ist.
- Moderne Computer verfügen über Multi-Core-CPUs und SSD-Festplatten verfügen auch über starke Parallelitätsfunktionen. Durch die Verwendung von Multithread-Parallel-Computing kann die Leistung erheblich verbessert werden. Es ist jedoch schwierig, Parallelität mit der herkömmlichen HASH-Heaping-Technologie zu erreichen. Wenn Multithreads HASH-Heaping durchführen, müssen sie gleichzeitig Daten auf einen bestimmten Heap schreiben, was zu Konflikten mit gemeinsam genutzten Ressourcen führt Durch die Zuordnung einer bestimmten Gruppe von Heaps wird eine große Menge an Speicher verbraucht, was die Implementierung größerer Mengen an Parallelität nicht zulässt.
- Wenn Sie eine geordnete Zusammenführung verwenden, um eine parallele Berechnung zu erreichen, müssen die Daten in mehrere Segmente unterteilt werden. Die Segmentierung einzelner Tabellen ist jedoch relativ einfach. Bei der Segmentierung müssen jedoch zwei verwandte Tabellen gleichzeitig ausgerichtet werden Während der Zusammenführung kann das korrekte Ergebnis nicht erzielt werden. Die Berechnungsergebnisse und die Datenreihenfolge können eine leistungsstarke synchrone Ausrichtungssegmentierung gewährleisten.
- Teilen Sie zunächst die Haupttabelle (für Tabellen mit derselben Dimension verwenden Sie die größere Tabelle, andere Diskussionen sind davon nicht betroffen) in mehrere Segmente, lesen Sie den Primärschlüsselwert des ersten Datensatzes in jedem Segment und verwenden Sie dann diese Schlüsselwerte zur Untertabelle Verwenden Sie die Bisektionsmethode, um die Positionierung zu ermitteln (da sie auch geordnet ist), um den Segmentierungspunkt der Untertabelle zu erhalten. Dadurch wird sichergestellt, dass die Segmente der Haupt- und Untertabellen synchron ausgerichtet sind.
- Da die Schlüsselwerte in Ordnung sind, gehören die Datensatzschlüsselwerte in jedem Segment der Haupttabelle zu einem bestimmten kontinuierlichen Intervall. Datensätze mit Schlüsselwerten außerhalb des Intervalls befinden sich nicht in diesem Segment Schlüsselwerte innerhalb des Intervalls müssen in diesem Segment liegen. Die Datensatzschlüsselwerte, die der Segmentierung der Tabelle entsprechen, verfügen ebenfalls über diese Funktion, sodass keine Fehlausrichtung auftritt und die Schlüsselwerte auch in Ordnung sind , kann eine effiziente binäre Suche in der Untertabelle durchgeführt werden, um den Segmentierungspunkt schnell zu lokalisieren. Das heißt, die Reihenfolge der Daten stellt die Rationalität und Effizienz der Segmentierung sicher, sodass parallele Algorithmen sicher ausgeführt werden können.
- Ein weiteres Merkmal der Primärschlüsselzuordnung zwischen Haupt- und Untertabellen besteht darin, dass die Untertabelle nur einer Haupttabelle im Primärschlüssel zugeordnet wird (tatsächlich gibt es auch Tabellen mit derselben Dimension, aber das ist einfacher (um dies anhand der Haupt-Untertabelle zu erklären), und es wird keine mehrfachen gegenseitigen Beziehungen zwischen der Haupttabelle und der Haupttabelle geben (es kann eine Haupttabelle mit Haupttabellen geben). Zu diesem Zeitpunkt können Sie auch den integrierten Speichermechanismus verwenden, um die Datensätze der Untertabelle als Feldwerte der Haupttabelle zu speichern. Auf diese Weise wird einerseits die Speichermenge reduziert (der zugehörige Schlüssel muss nur einmal gespeichert werden) und es entspricht einer vorherigen Zuordnung, sodass kein erneuter Vergleich erforderlich ist. Für Big Data kann eine bessere Leistung erzielt werden.
- Wir haben die oben genannten Methoden zur Leistungsoptimierung in esProc SPL implementiert und in tatsächlichen Szenarien angewendet und sehr gute Ergebnisse erzielt. SPL ist jetzt Open Source. Leser können die offiziellen Websites und Foren von Shusu Company oder Runqian Company besuchen, um weitere Informationen herunterzuladen.
Empfohlenes Lernen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonJOIN-Betrieb der systematischen MySQL-Analyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!