
Heim >Backend-Entwicklung >Python-Tutorial >Super detaillierte Erklärung des Python-Crawlers
Super detaillierte Erklärung des Python-Crawlers

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-07-14 16:58:504226Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, das hauptsächlich Probleme im Zusammenhang mit Crawlern (auch bekannt als Web-Spider, Web-Roboter) organisiert, um Netzwerkanfragen zu senden und Anfrageantworten zu empfangen Schauen wir uns die Informationen nach bestimmten Regeln an. Ich hoffe, dass sie für alle hilfreich sind.

【Verwandte Empfehlung: Python3-Video-Tutorial】
Crawler
Webcrawler (auch bekannt als Web Spider, Netzwerkroboter) simuliert den Browser, um Netzwerkanfragen zu senden und Anfrageantworten zu empfangen crawlt Internetinformationen.
Grundsätzlich gilt: Solange der Browser (Client) alles kann, kann der Crawler es auch.
Warum wir Crawler verwenden sollten
Das Internet-Big-Data-Zeitalter beschert uns die Bequemlichkeit des Lebens und die explosive Erscheinung riesiger Datenmengen im Netzwerk.
Früher nutzten wir Bücher, Zeitungen, Fernsehen, Radio oder Informationen. Die Informationsmenge war begrenzt und musste bis zu einem gewissen Grad durchleuchtet werden. Der Nachteil war jedoch, dass die Informationen zu eng waren. Die asymmetrische Informationsübertragung schränkt unsere Sicht ein und verhindert, dass wir mehr Informationen und Wissen lernen.
Im Zeitalter von Internet-Big-Data haben wir plötzlich freien Zugang zu Informationen. Wir haben eine riesige Menge an Informationen erhalten, aber die meisten davon sind ungültige Junk-Informationen.
Beispielsweise generiert Sina Weibo täglich Hunderte Millionen Statusaktualisierungen, während Sie in der Baidu-Suchmaschine nach nur einer Nachricht suchen können – 100.000.000 Nachrichten zum Thema Abnehmen.
Wie erhalten wir in einer so großen Menge an Informationsfragmenten Informationen, die für uns nützlich sind?
Die Antwort ist Screening!
Sammeln Sie relevante Inhalte durch eine bestimmte Technologie, und erst nach Analyse und Auswahl können wir die Informationen erhalten, die wir wirklich benötigen.
Diese Informationserfassungs-, Analyse- und Integrationsarbeit kann in einem sehr breiten Spektrum von Bereichen angewendet werden, sei es Lebensdienstleistungen, Reisen, Finanzinvestitionen, Produktmarktnachfrage verschiedener Fertigungsindustrien usw. Sie können diese Technologie verwenden, um zu erhalten genauere und effektivere Informationen zu nutzen.
Obwohl die Webcrawler-Technologie einen seltsamen Namen hat, der Nengs erste Reaktion als eine weiche, sich windende Kreatur erscheinen lässt, handelt es sich tatsächlich um ein leistungsstarkes Werkzeug, das in der virtuellen Welt vorankommen kann.
Crawler-Vorbereitung
Wir sprechen normalerweise von Python-Crawlern. Tatsächlich gibt es hier möglicherweise ein Missverständnis. Es gibt viele Sprachen, die zum Crawlen verwendet werden können. JAVA, C#, C++, Python. Der Grund für die Verwendung von Crawlern ist, dass Python relativ einfach ist und über vollständige Funktionen verfügt.
Zuerst müssen wir Python herunterladen, ich habe die neueste offizielle Version 3.8.3 heruntergeladen.
Zweitens benötigen wir eine Umgebung zum Ausführen von Python. Ich verwende Pychram.

Sie können es auch von der offiziellen Version herunterladen.
Wir benötigen auch einige Bibliotheken Um den Betrieb des Crawlers zu unterstützen (einige Bibliotheken werden möglicherweise mit Python geliefert)
Fast diese Bibliotheken habe ich bereits hinten geschrieben

(Während des Crawler-Laufvorgangs nicht unbedingt Sie Ich benötige die oben genannten Bibliotheken. Es hängt davon ab, wie Sie den Crawler schreiben. Wenn Sie jedoch eine Bibliothek benötigen, können wir diese direkt in der Einstellung installieren Die 250 am besten bewerteten Filme von Douban
Der von uns gecrawlte Inhalt ist:
Link zu Filmdetails, Bildlink, chinesischer Name des Films, ausländischer Name des Films, Bewertung, Anzahl der Rezensionen, Übersicht und verwandte Informationen.
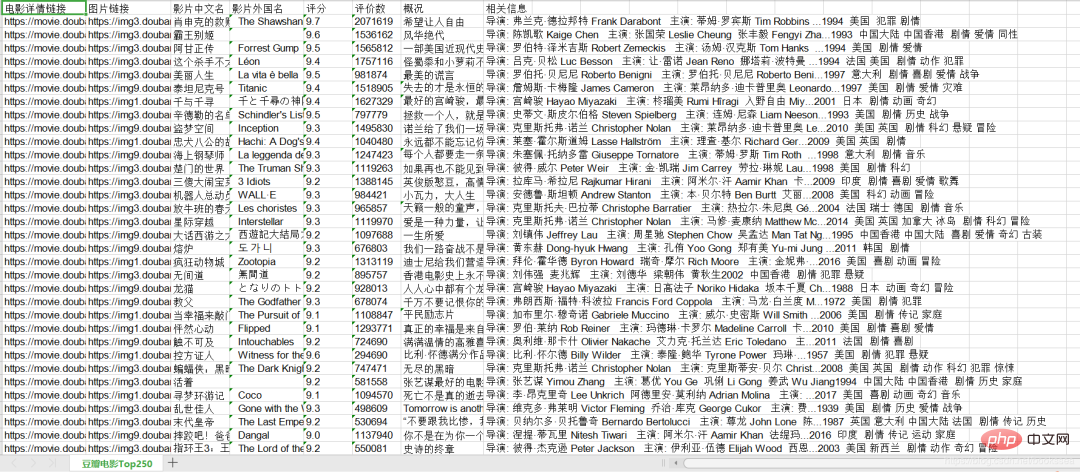
Posten Sie zuerst den Code, und dann werde ich ihn Schritt für Schritt anhand des Codes analysieren# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('p', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")Jetzt werde ich ihn anhand des Codes von unten nach unten erklären und analysieren -- programming = utf -8 -
Einige der folgenden Wörter, die mit find beginnen, sind reguläre Ausdrücke, die wir zum Filtern von Informationen verwenden.
(Reguläre Ausdrücke verwenden die Re-Bibliothek und reguläre Ausdrücke sind nicht erforderlich. Dies ist nicht erforderlich.)Der allgemeine Prozess ist in drei Schritte unterteilt: 1. Durchsuchen Sie die Webseite. 2. Analysieren Sie die Daten einzeln.
3 . Speichern Sie die Webseite先分析流程1,爬取网页,baseurl 就是我们要爬虫的网页网址,往下走,调用了 getData(baseurl) ,
我们来看 getData方法
for i in range(0, 10): # 调用获取页面信息的函数,10次 url = baseurl + str(i * 25)
这段大家可能看不懂,其实是这样的:
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我们只要在baseurl后面加上数字就会跳到相应页面,比如i=1时
https://movie.douban.com/top250?start=25
我放上超链接,大家可以点击看看会跳到哪个页面,毕竟实践出真知。
然后又调用了askURL来请求网页,这个方法是请求网页的主体方法,
怕大家翻页麻烦,我再把代码复制一遍,让大家有个直观感受
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
这个askURL就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?
这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
418
这是一个梗大家可以百度下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一个茶壶
所以我们需要 “装” ,装成我们就是一个浏览器,这样就不会被认出来,
伪装一个身份。
来,我们继续往下走,
html = response.read().decode("utf-8")
这段就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
访问成功后,来到了第二个流程:
2.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) findTitle = re.compile(r'<span class="title">(.*)</span>') findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') findJudge = re.compile(r'<span>(\d*)人评价</span>') findInq = re.compile(r'<span class="inq">(.*)</span>') findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据 saveData(datalist,savepath) #2种存储方式可以只选择一种 # saveData2DB(datalist,dbpath)
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

打开之后看看是不是我们想要的结果
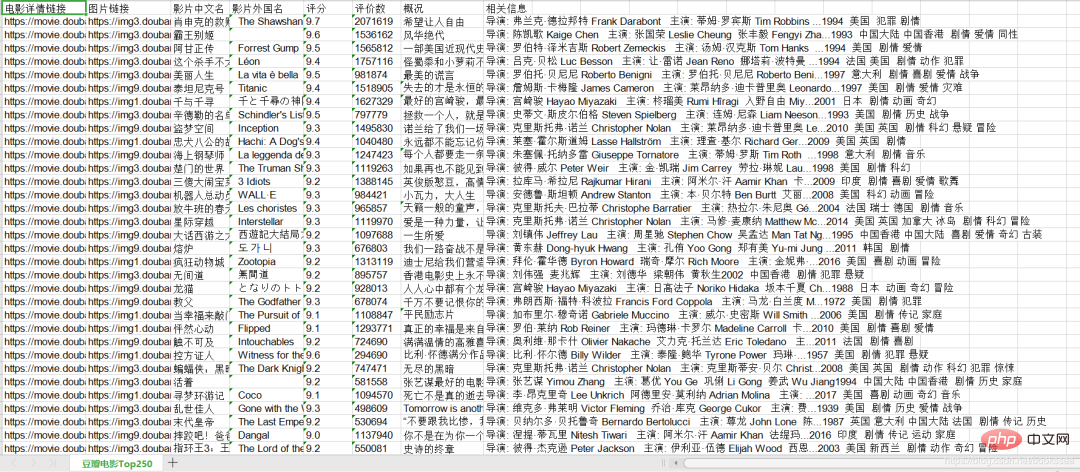
成了,成了!如果我们需要以数据库方式存储,可以先生成 xls 文件,再把 xls 文件导入数据库中,就可以啦!
【相关推荐:Python3视频教程 】
Das obige ist der detaillierte Inhalt vonSuper detaillierte Erklärung des Python-Crawlers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Verstehen Sie die Verwendung von Tkinter in Python in einem Artikel
- Lassen Sie uns darüber sprechen, wie man den Inhalt von Mat-Dateien (Matlab-Daten) mit Python liest
- Was bedeuten Python und JQuery?
- Beherrschen Sie die automatische Python-GUI PyAutoGUI vollständig
- Zusammenstellung von Wissenspunkten zu Python-Codierungsstandards