
Heim >Java >javaLernprogramm >Zusammenfassung der Java-Kenntnisse und detaillierte Erklärung von JVM
Zusammenfassung der Java-Kenntnisse und detaillierte Erklärung von JVM

- WBOYnach vorne
- 2022-07-12 17:20:032063Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Java. Er organisiert hauptsächlich JVM-bezogene Probleme, einschließlich der JVM-Speicherbereichsaufteilung, des JVM-Klassenlademechanismus, der VM-Garbage Collection usw. Ich hoffe, es hilft allen .

Empfohlene Studie: „Java-Video-Tutorial“
1. JVM-Speicherbereichsaufteilung
Warum teilt JVM diese Bereiche auf? Um diese in einige kleine Module zu unterteilen, sodass eine große Site in einige kleine Module unterteilt werden kann, und dann ist jedes Modul für seine eigene Funktion verantwortlich. Schauen wir uns dann an, welche Funktionen diese Bereiche haben
1. Programmzähler
Der Programmzähler ist der kleinste Bereich im Speicher. Er speichert hauptsächlich die Adresse des nächsten auszuführenden Befehls (Der Befehl ist der Bytecode. Im Allgemeinen muss das Programm von der JVM ausgeführt werden. Sie müssen den Bytecode in den Speicher laden, und dann entnimmt das Programm die Anweisungen einzeln aus dem Speicher und legt sie zur Ausführung auf der CPU ab. Sie müssen sich also merken, welche Anweisung gerade ausgeführt wird und wo die nächste ist Die CPU stellt nicht nur Dienste für einen Prozess bereit, sondern stellt Dienste für alle Prozesse bereit und führt Programme gleichzeitig aus. Da das Betriebssystem die Ausführung in Thread-Einheiten plant, muss jeder Thread seine eigene Ausführungsposition haben, das heißt, jeder Thread benötigt eine Programmzähler zum Aufzeichnen der Position!)
2. StapelDer Stapel speichert hauptsächlich
lokale Variablen und Methodenaufrufinformationen, solange es sich um den Aufruf einer neuen Methode handelt. Es wird jeden eine „Push“-Operation geben Sobald eine Methode ausgeführt wird, erfolgt eine „Push“-Operation und jeder Thread verfügt über eine Kopie des Stapels. Daher müssen die Rekursionsbedingungen kontrolliert werden, andernfalls ist eine Stapelüberlaufausnahme (StackOverflowException) wahrscheinlich
3. Der Heap ist der größte Speicherplatz im Speicher, und der Heap ist nur eine Kopie für jeden Prozess und wird von mehreren Threads im Prozess gemeinsam genutzt Speichert hauptsächlich neue Objekte und Mitgliedsvariablen von Objekten. Wenn das s hier in der Methode eine lokale Variable auf dem Stapel ist, befindet es sich auf dem Heap. und new String() ist die Ontologie des Objekts, die leicht verwechselt werden kann. Darüber hinaus ist ein weiterer wichtiger Punkt des Heaps, der später ausführlich vorgestellt wird 4. Methodenbereich
Der Methodenbereich 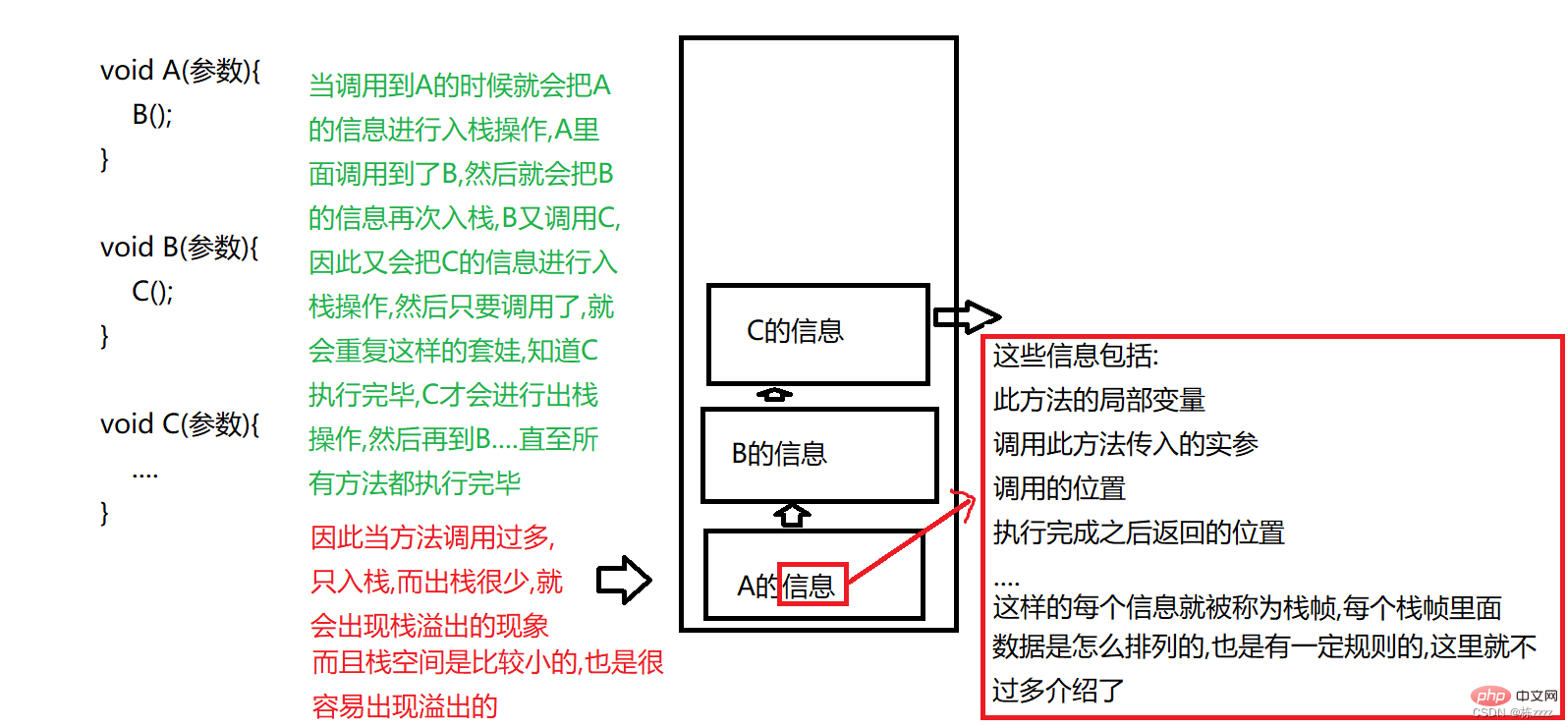 speichert „Klassenobjekte“
speichert „Klassenobjekte“
Der .java-Code, den Sie normalerweise schreiben, wird nach der Übersetzung durch den Compiler in .class umgewandelt und dann in den Speicher geladen Von der JVM in Klassenobjekte konstruiert (der Ladevorgang wird als „Klassenladen“ bezeichnet), und diese Klassenobjekte werden im Methodenbereich gespeichert, der speziell die Klassenlänge beschreibt Klasse und ihre Mitgliedsnamen, Mitgliedstypen, die Methoden der Klasse und ihre Methodennamen, Methodentypen und einige Anweisungen ... Darüber hinaus wird im Klassenobjekt eine sehr wichtige Sache gespeichert, nämlich statische Mitglieder, die im Allgemeinen vorhanden sind Statisch geänderte Mitglieder werden zu Klassenattributen, während gewöhnliche Methoden als Instanzattribute bezeichnet werden, was sehr unterschiedlich ist)!
Das obige ist der spezifische Prozess des Klassenladens. Ich werde sie hier nicht vorstellen
1.Laden
In der Ladephase finden Sie zunächst die entsprechende .class-Datei, öffnen und lesen dann (entsprechend dem Byte-Stream) die .class-Datei und generieren gleichzeitig zunächst ein Klassenobjekt, dieses und das Laden der fertigen Klasse ist anders, lassen Sie sich nicht verwirren! Das spezifische Format der Klassendatei (wenn Sie einen Java-Compiler implementieren möchten, müssen Sie ihn in diesem Format erstellen, und wenn Sie eine JVM implementieren, müssen Sie ihn laden es in diesem Format! ): Wenn Sie dieses Format beobachten, können Sie sehen, dass die .class-Datei alle Kerninformationen in der .java-Datei ausdrückt. Das Organisationsformat hat sich jedoch geändert, sodass der Ladelink das verwendet Leseinformationen. Füllen Sie vorläufig das Klassenobjekt aus Der empfangene Inhalt entspricht genau dem in der Spezifikation festgelegten Format. Wenn festgestellt wird, dass das Format der gelesenen Daten nicht mit der Spezifikation übereinstimmt, schlägt das Laden der Klasse fehl und es wird eine Ausnahme ausgelöst. 2.2.
Wenn Sie dieses Format beobachten, können Sie sehen, dass die .class-Datei alle Kerninformationen in der .java-Datei ausdrückt. Das Organisationsformat hat sich jedoch geändert, sodass der Ladelink das verwendet Leseinformationen. Füllen Sie vorläufig das Klassenobjekt aus Der empfangene Inhalt entspricht genau dem in der Spezifikation festgelegten Format. Wenn festgestellt wird, dass das Format der gelesenen Daten nicht mit der Spezifikation übereinstimmt, schlägt das Laden der Klasse fehl und es wird eine Ausnahme ausgelöst. 2.2.
In der Phase der formellen Zuweisung von Speicher für die definierten Variablen (statische Variablen, bei denen es sich um durch statische Variablen geänderte Variablen handelt) und dem Festlegen des Anfangswerts der Klassenvariablen
wird jeder statischen Variablen Speicher zugewiesen und auf festgelegt ein Wert von 0! 2.3.Auflösung (Analyse) Die Auflösungsphase ist der Prozess, bei dem die Java Virtual Machine die Symbolreferenzen im Konstantenpool durch direkte Referenzen ersetzt. Dies ist auch der Prozess der Initialisierung der Konstanten in Die .class-Datei wird zentral platziert, und jede Konstante hat eine Nummer. Die anfängliche Situation in der Struktur in der .class-Datei ist nur die Datensatznummer, und dann können Sie den entsprechenden Inhalt basierend auf dieser Nummer finden und ihn dann einfügen das Klassenobjekt! 3. Initialisierung (Initialisierung)Die Initialisierungsphase besteht darin, das Klassenobjekt wirklich zu initialisieren
(gemäß dem geschriebenen Code), insbesondere für statische Mitglieder 4. Typische Interviewfragenclass A {
public A(){
System.out.println("A的构造方法");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}}class B extends A{
public B(){
System.out.println("B的构造方法");
}
{
System.out.println("B的构造代码块");
}
static {
System.out.println("B的静态代码块");
}}public class Test extends B{
public static void main(String[] args) {
new Test();
new Test();
}}
Sie können es versuchen Um die Ausgabeergebnisse zuerst selbst zu schreiben Sie müssen diese Fragen beherrschen. Mehrere Hauptprinzipien:
Der statische Codeblock wird während der Klassenladephase ausgeführt. Wenn Sie eine Instanz erstellen möchten, müssen Sie zuerst die Klasse ausführen Laden
Der statische Codeblock wird während der Klassenladephase nur einmal ausgeführt, alle anderen Phasen werden nicht erneut ausgeführt
Die Konstruktionsmethode und der Konstruktionscodeblock werden bei jeder Instanziierung ausgeführt. und der Konstruktionscodeblock wird vor der Konstruktionsmethode ausgeführt~~
- Das Programm wird von main und der Testmethode von main ausgeführt Um main auszuführen, müssen Sie also zuerst die Testklasse laden.
- Nur wenn diese Klasse beteiligt ist, werden die Dinge in der Klasse geladen Beim Laden der Klasse wird im übergeordneten Delegationsmodell beschrieben, wie der Klassenlader in der JVM verwendet wird die .class-Datei
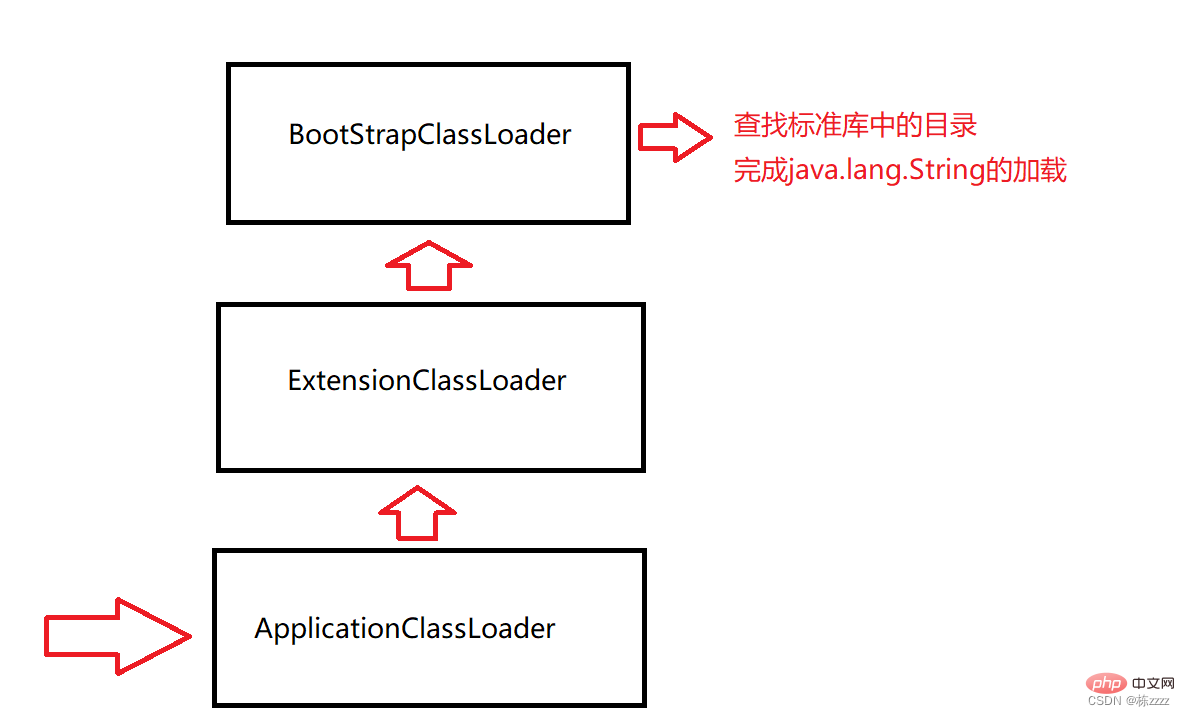
. Der Klassenlader ist hier ein speziell von der JVM bereitgestelltes Objekt, das hauptsächlich für das Laden von Klassen verantwortlich ist. Es gibt also viele Orte, an denen .class-Dateien abgelegt werden können Sie müssen im JDK-Verzeichnis abgelegt werden, einige werden im Projektverzeichnis abgelegt und einige befinden sich an anderen spezifischen Orten, sodass die JVM mehrere Klassenlader bereitstellt, jeder Klassenlader für einen Slice verantwortlich ist und es hauptsächlich drei Standardklassen gibt Lader:
BootStrapClassLoader: Verantwortlich für das Laden von Klassen in der Standardbibliothek (String, ArrayList, Random, Scanner...)
ExtensionClassLoader: Verantwortlich für das Laden von JDK-Erweiterungsklassen (heute selten verwendet)
ApplicationClassLoader : Verantwortlich für das Laden der aktuellen Klassen im Projektverzeichnis
Darüber hinaus können Programmierer auch Klassenlader anpassen, um Klassen in anderen Verzeichnissen zu laden Das Delegationsmodell beschreibt den Prozess des Findens eines Verzeichnisses, d Der Klassenlader „ApplicationClassLoader“ prüft, ob der übergeordnete Klassenlader geladen wurde. Der Klassenlader „ExtensionClassLoader“ prüft auch, ob der übergeordnete Klassenlader geladen wurde wurde geladen und stellt dann fest, dass kein Vater vorhanden ist, also scannt es sich selbst. Verantwortliches Verzeichnis
Dann ist die Klasse java.lang.String in der Standardbibliothek zu finden, und dann ist der BootStrapClassLoader-Loader für den nachfolgenden Ladevorgang verantwortlich, und der Suchvorgang ist beendet
Überlegen Sie, nach etwas zu suchen! Von Ihnen selbst geschriebene Testklasse: Wenn das Programm startet, prüft es zunächst, ob der Klassenlader ApplicationClassLoader geladen wurde. Wenn nicht, ruft es den Klassenlader ExtensionClassLoader auf Überprüfen Sie, ob der übergeordnete Klassenlader geladen wurde. Der Klassenlader prüft auch, ob der übergeordnete Klassenlader geladen wurde, und stellt fest, dass er vorhanden ist ist kein Vater, also scannt es das Verzeichnis, für das es verantwortlich ist, und wenn es nicht gescannt wird, kehrt es zum untergeordneten Loader zurück, um mit dem Scannen fortzufahren
ExtensionClassLoader scannt das Verzeichnis, für das es verantwortlich ist, und es gibt keine Nach dem Scannen , gehen Sie zurück zum Subloader und fahren Sie mit dem Scannen fort
ApplicationClassLoader scannt auch das Verzeichnis, für das es verantwortlich ist. Die von Ihnen geschriebenen Klassen befinden sich in Ihrem eigenen Projektverzeichnis, sodass Sie sie finden können, und das anschließende Laden der Klassen wird von ApplicationClassLoad abgeschlossen. Zu diesem Zeitpunkt ist der Prozess des Durchsuchens des Verzeichnisses abgeschlossen ~~ (Wenn ApplicationClassLoader sie außerdem nicht findet, wird eine ClassNotFoundException-Ausnahme ausgelöst.)
- Dieser Satz von Suchregeln wird als übergeordnete Delegation bezeichnet Modell, also warum braucht die JVM Der Grund für dieses Design ist, dass, sobald die vom Programmierer geschriebene Klasse denselben vollqualifizierten Klassennamen hat, die Klasse in der Standardbibliothek erfolgreich geladen werden kann, anstatt die vom Programmierer geschriebene Klasse!! !
- Wenn es sich außerdem um einen benutzerdefinierten Klassenlader handelt, möchten Sie dieses übergeordnete Delegationsmodell einhalten?
Die Antwort lautet, ob Sie einhalten können oder nicht. Dies hängt hauptsächlich von den Anforderungen ab, ob Tomcat die Klassen lädt In der Webanwendung ist es nicht möglich, den Klassenlader zu finden, der den oben genannten Anforderungen entspricht.
3 Der - Garbage Collection-Mechanismus (GC) in JVM Wenn Sie Code verwenden, müssen Sie häufig Speicher beantragen, z. B. eine Variable erstellen, ein neues Objekt erstellen, eine Methode aufrufen, eine Klasse laden usw. Der Zeitpunkt der Speicheranwendung ist im Allgemeinen klar (Sie müssen Speicher beantragen, wenn Sie bestimmte Daten speichern müssen). Daten oder Daten), aber der Zeitpunkt der Speicherfreigabe ist nicht so klar und es funktioniert nicht, wenn Sie ihn zu früh freigeben (wenn er noch verwendet werden muss, aber infolgedessen freigegeben wurde, was bedeutet, dass er dort ist Es ist kein Speicher verfügbar und die Daten können „nirgendwo hingehen“. Wenn sie zu spät freigegeben werden, funktioniert sie nicht (wenn sie zu spät freigegeben wird, ist es wahrscheinlich, dass eine große Menge an Horten sie verfügbar macht). Wird weniger, ist es sehr wahrscheinlich, dass Speicherlecks auftreten (d. h. es ist kein zu verwendender Speicher vorhanden), also
Die Speicherfreigabe muss genau richtig sein
! Die Aufgabe der Speicherbereinigung erfordert eine Menge zusätzlicher Arbeit Durch die Laufzeitumgebung wird der Speicherfreigabevorgang abgeschlossen, was die mentale Belastung des Programmierers erheblich verringert, aber - Garbage Collection hat auch Nachteile
: ① Es verbraucht zusätzlichen Overhead (es werden mehr Ressourcen verbraucht); ② Es kann den reibungslosen Betrieb beeinträchtigen Das Programm (Garbage Collection führt häufig zu STW-Problemen (Stop The World))
Welche Art von Speicher wird durch Müll gesammelt? Muss alles recycelt werden?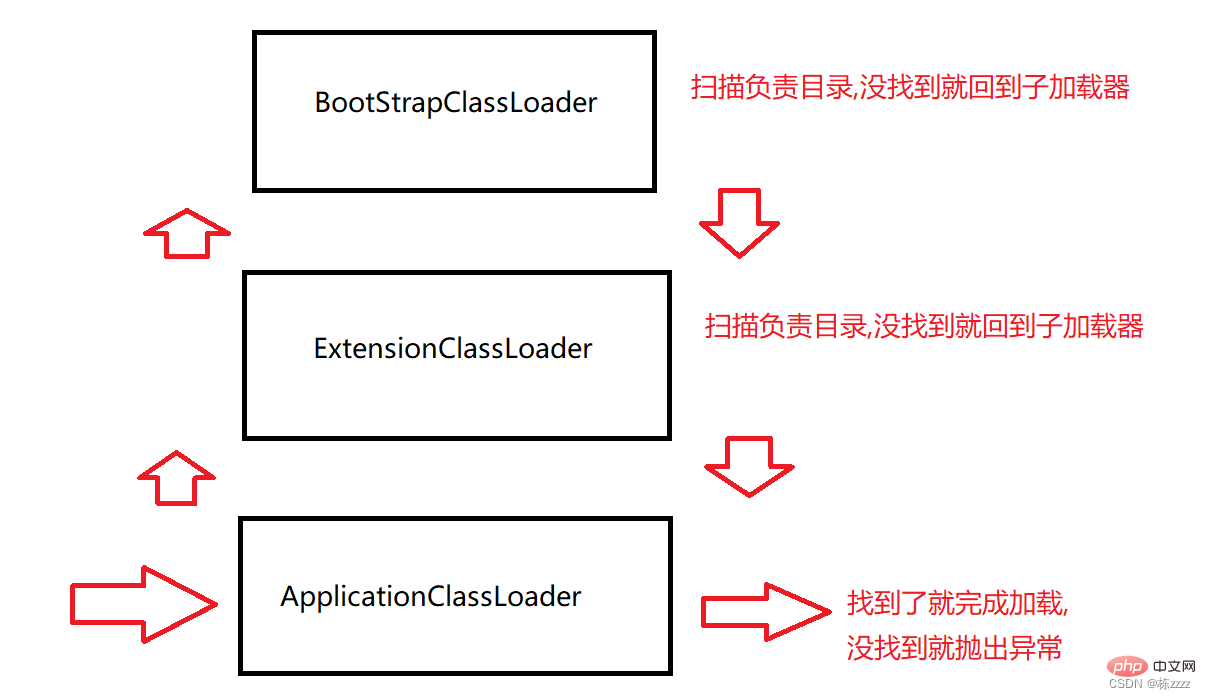 Natürlich nicht, lassen Sie uns die vier oben genannten Bereiche zur Erklärung verwenden:
Natürlich nicht, lassen Sie uns die vier oben genannten Bereiche zur Erklärung verwenden:
Programmzähler: Dieser Speicher hat eine feste Größe und erfordert keine Freigabe, daher ist kein GC erforderlich.
Stack: Wenn der Funktionsaufruf abgeschlossen ist, wird der entsprechende Stapelrahmen automatisch freigegeben und GC ist nicht erforderlich
Heap: Dies ist der Speicher, der im Allgemeinen den meisten GC benötigt.
Methodenbereich: Klassenobjekte, Klassenladen, und nur wenn die Klasse entladen wird, muss der Speicher freigegeben werden, und der Entladevorgang ist sehr selten, sodass er fast nicht erforderlich ist GC!
Schauen wir uns an, wie man im Detail recycelt:1. Müll finden/Müll bestimmen
Es gibt derzeit zwei gängige Lösungen:
1.1. Basierend auf der ReferenzzählungDies ist nicht der Fall Die in Java übernommene Lösung ist eine Lösung für Python und andere Sprachen, daher werde ich sie hier kurz vorstellen, ohne zu sehr ins Detail zu gehen ~
- Die spezifische Idee der Referenzzählung besteht darin, dass für jedes Objekt ein zusätzlicher kleiner Teil vorhanden ist Es wird ein Speicher eingeführt, um zu speichern, wie viele Referenzen dieses Objekt hat.
- Und es gibt zwei Mängel bei einer solchen Referenzzählung:
Lokale Variablen auf dem Stapel;
- Die Speicherplatznutzung ist relativ gering!!!, jedes neue Objekt muss mit einem Zähler ausgestattet werden, vorausgesetzt, ein Zähler ist 4 Bytes groß, wenn das Objekt selbst relativ groß ist (Hunderte von Bytes), dann ist dies bei diesem Zähler nicht der Fall Materie, und sobald das Objekt selbst relativ klein ist (4 Bytes), entsprechen die zusätzlichen 4 Bytes einer Verdoppelung der Speicherplatznutzung, sodass die Speicherplatznutzung relativ gering ist~
- Es gibt eine Schleife Referenzprobleme
Die GCRoots hier! (Beginnen Sie mit dem Durchlaufen von diesen Orten):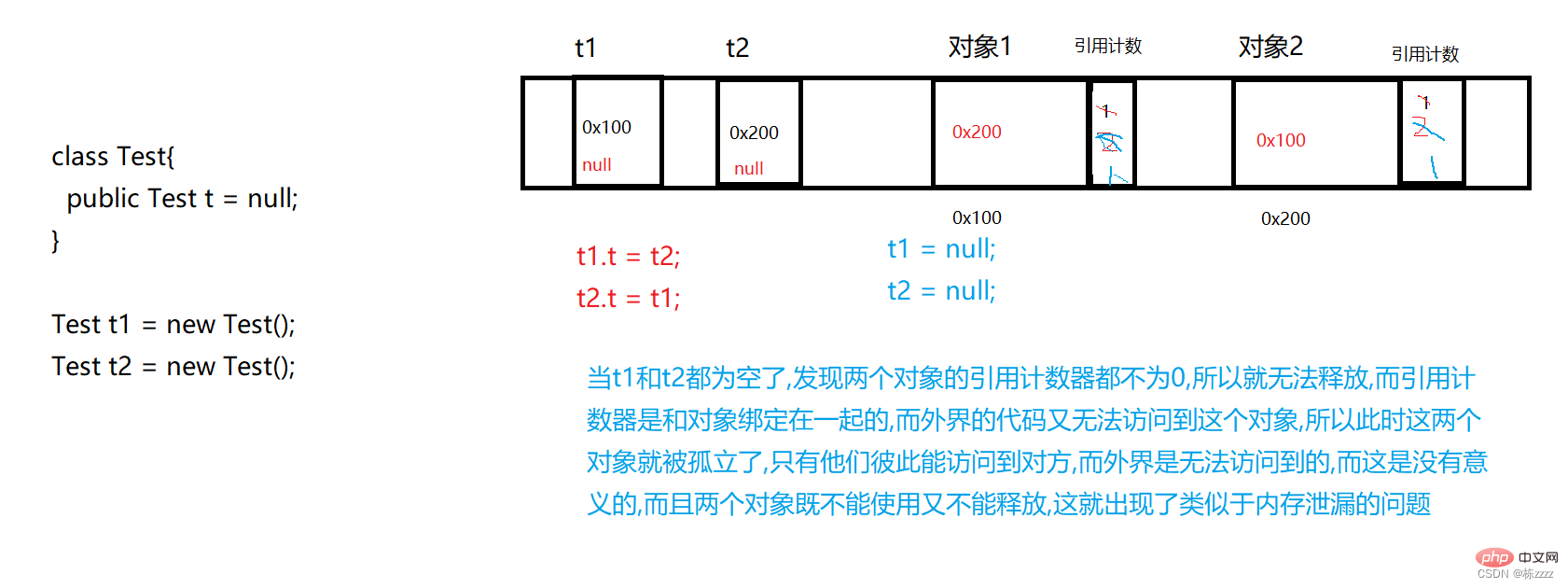
Daher treten bei der Verwendung der Referenzzählung viele Probleme auf. Sprachen wie Python und PHP verwenden nicht nur Referenzzähler, um die GC abzuschließen, sondern auch einige andere Mechanismen, um sie zu vervollständigen Bei der Erreichbarkeitsanalyse handelt es sich um eine von Java übernommene Lösung. Die Erreichbarkeitsanalyse besteht darin, mit einigen Ausnahmen regelmäßig Objekte im gesamten Speicherbereich zu scannen Tiefendurchquerung (kann man sich als Baum vorstellen), markiert alle zugänglichen Objekte auf einer Seite (markierte Objekte sind erreichbare Objekte), aber nicht markierte Objekte sind unerreichbare Objekte, also Müll, und sollten freigegeben werdenObjekte, auf die durch Referenzen im Konstantenpool verwiesen wird;
Das Objekt, auf das die statischen Mitglieder im Methodenbereich zeigen;2.1 Markieren ist der Prozess von Die Erreichbarkeitsanalyse und das Löschen dienen dazu, Speicher freizugeben. Gehen Sie davon aus, dass es sich bei dem oben genannten Speicher um einen Speicher handelt. Wenn Sie ihn zu diesem Zeitpunkt direkt freigeben, wird er nicht an das System zurückgegeben Der Speicher ist diskret und nicht kontinuierlich, und das dadurch verursachte Problem ist möglicherweise viel freier Speicher. Wenn Sie zu diesem Zeitpunkt 500 MB Speicherplatz beantragen möchten. Sie können sich bewerben, aber die Anwendung kann hier fehlschlagen (da es sich bei den 500 MB, die beantragt werden müssen, um kontinuierlichen Speicher handelt, handelt es sich bei dem für jedes Mal angewendeten Speicher um kontinuierlichen Speicherplatz, und 1 GB kann hier die Summe mehrerer Fragmente sein). Ein Problem wirkt sich tatsächlich stark auf die Ausführung des Programms aus Die Strategie des Kopieralgorithmus besteht darin, die Hälfte des Speichers zu verwenden, die andere Hälfte wegzuwerfen und nicht den gesamten Speicher in die andere Hälfte zu kopieren (diese Kopie wird intern von der JVM verarbeitet). Keine Sorge), und dann wird der gesamte verwendete Speicher freigegeben, sodass das Problem der Speicherfragmentierung gelöst ist.
- Der Vorteil Der Vorteil der Erreichbarkeitsanalyse besteht darin, dass sie die Mängel der Referenzzählung behebt: geringe Raumnutzung und Zirkelverweise. Die Mängel der Erreichbarkeitsanalyse liegen ebenfalls auf der Hand: Der Systemaufwand ist hoch und das einmalige Durchlaufen kann langsam sein Das Finden von Müll ist auch sehr einfach. Der Kern besteht darin, zu bestätigen, ob dieses Objekt in Zukunft verwendet wird, und zu sehen, ob es Hinweise darauf gibt und ob es freigegeben werden sollte!
- 2. Geben Sie den Müll frei
- Jetzt Wir haben geklärt, was Müll ist. Der nächste Schritt besteht darin, den Müll zu recyceln. Schauen wir uns das an
Der Kopieralgorithmus weist also zwei große Probleme auf: Geringe Speicherplatzauslastung (nur allgemeiner Speicher). verwendet);
Wenn viele Objekte beibehalten und nur wenige Objekte freigegeben werden müssen, sind die Kosten für das Kopieren sehr hoch2.3 Dies ist eine weitere
weitere Verbesserung des Kopieralgorithmus!
Markieren und Organisieren Die Strategie besteht darin,den Speicher, der kein Müll ist, zusammenzufassen und dann den gesamten nachfolgenden Speicher freizugeben. Dies ähnelt dem Vorgang des Löschens mittlerer Elemente in einer Sequenztabelle Prozess!
Diese Lösung hat eine hohe Speicherplatzauslastung.
Obwohl die oben genannten drei Lösungen das Problem lösen können, haben sie alle ihre eigenen Mängel Tatsächlich wird die Implementierung in der JVM mehrere Lösungen kombinieren, das heißt „Generationsrecycling“!!! Das Alter bedeutet hier, dass ein Objekt eine Runde des GC-Scannens überstanden hat (wird als „ein Jahr älter“ bezeichnet) und für Objekte unterschiedlichen Alters werden unterschiedliche Pläne angenommen!!!
Das ist der gesamte generationsübergreifende Recyclingprozess!
3. Garbage Collector
Die obige Garbage Collection und Garbage Release sind nur algorithmische Ideen, kein echter Implementierungsprozess. Was das obige Algorithmusmodul wirklich implementiert, ist der „Garbage Collector“:
3.1. Serial Collector und Serial Old Collector
Der Serial Collector ist ein Garbage Collector für die neue Generation, und der Serial Old Collector ist ein Garbage Collector für die alte Generation. Diese beiden Collectors werden seriell gesammelt, und wenn der Müll gescannt und freigegeben wird , der Geschäftsthread muss aufhören zu funktionieren, daher ist der Scan voll und die Veröffentlichung ist auf diese Weise langsam, und es kann auch zu ernsthaften
3.2-Sammlern von ParNew, Parallel-Scavenge-Sammlern und ParNew-Sammlern kommen Der Parallel Scavenge-Kollektor wird im Vergleich zum ParNew-Kollektor mit einigen leistungsfähigeren Funktionen ausgestattet Alle Sammler sammeln parallel, was Multithreading einführt, um die Funktionen des Müllscannens und der Müllfreigabe zu lösen.
Oben sind diese Sammler ein Überbleibsel aus der Geschichte, bei dem es sich um ältere Müllsammelmethoden handelt
3.3. CMS-Kollektor
Die ursprüngliche Absicht seines Designs besteht darin, die STW-Zeit so kurz wie möglich zu halten. Hier ist eine kurze Einführung in den Prozess der CMS-Kollektor:
Anfangsmarkierung: Die Geschwindigkeit ist sehr hoch und führt zu einem kurzen STW (nur GCRoots suchen);
Gleichzeitige Markierung: Es ist sehr schnell, kann aber gleichzeitig mit dem Geschäftsthread ausgeführt werden und wird dies nicht tun STW generieren;
- Anmerkung: 2 Geschäftscodes können sich auf die Ergebnisse der gleichzeitigen Markierung auswirken (wenn der Geschäftsthread ausgeführt wird, wird möglicherweise neuer Müll generiert), daher dient dieser Schritt der Feinabstimmung der Ergebnisse von 2. Obwohl es Wird STW verursachen, ist es nur eine Feinabstimmung und die Geschwindigkeit ist sehr hoch.
Die oben genannten drei Schritte basieren alle auf der Erreichbarkeitsanalyse Markierungssortierung;- 3.4.G1-Kollektor
G1-Kollektor ist
- der einzige vollregionale Garbage Collector
, und G1 wird seit Java11 verwendet. Dieser Collector unterteilt den gesamten Speicher in viele kleine Regionen und markiert diese Regionen unterschiedlich In einigen Regionen werden Objekte der neuen Generation und in einigen Regionen Objekte der alten Generation eingefügt. Scannen Sie dann mehrere Regionen gleichzeitig (Sie möchten den Scan nicht in einer GC-Runde abschließen, sondern müssen mehrere Male scannen). Die Auswirkungen auf den Geschäftscode sind ebenfalls minimal. Die Kernidee dieser beiden neuen Kollektoren besteht darin, sie in Teile aufzuteilen. G1 kann derzeit so optimiert werden, dass die STW-Pausenzeit weniger als 1 ms beträgt Beim Sammeln geht es hier hauptsächlich um das Verständnis, und die oben genannten Garbage-Collection-Ideen sind sehr wichtig!!!
Das obige ist der detaillierte Inhalt vonZusammenfassung der Java-Kenntnisse und detaillierte Erklärung von JVM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ist float ein JavaScript-Schlüsselwort?
- Vier Möglichkeiten zur Implementierung von Multithreading in Java
- Detaillierte Erläuterung der Wissenspunkte zu JavaScript-Prototypen und Prototypketten
- [Hämatemesis-Zusammenstellung] 2023 Java grundlegende Fragen und Antworten zu Hochfrequenzinterviews (Sammlung)
- Was ist eine Schließung? Lassen Sie uns über Abschlüsse in JavaScript sprechen und sehen, welche Funktionen sie haben.