
Heim >Backend-Entwicklung >Python-Tutorial >Erste Schritte mit dem Python-Crawler: Webbilder crawlen
Erste Schritte mit dem Python-Crawler: Webbilder crawlen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-07-11 12:06:363056Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, das hauptsächlich die damit verbundenen Probleme des Crawlens von Webbildern organisiert. Wenn Sie Daten effizient abrufen möchten, ist die Verwendung von Python für Crawler ebenfalls sehr nützlich ist einfach und bequem. Schauen wir uns den grundlegenden Prozess zum Schreiben eines Crawlers mit einem einfachen kleinen Crawler-Programm an. Ich hoffe, es wird für alle hilfreich sein.

【Verwandte Empfehlung: Python3-Video-Tutorial】
In Zeiten der Informationsexplosion sind Crawler sehr einfach zu verwenden, wenn Sie Daten effizient abrufen möchten. Es ist auch sehr einfach und bequem, Python zum Erstellen eines Crawlers zu verwenden. Schauen wir uns den grundlegenden Prozess zum Schreiben eines Crawlers mit einem einfachen kleinen Crawler-Programm an:
Vorbereitung
Sprache: Python
IDE: Pycharm
Da es sich um das einfachste Programm für den Einstieg handelt, verwenden wir hauptsächlich die folgenden zwei Bibliotheken:
import requests //用于请求网页 import re //正则表达式,用于解析筛选网页中的信息
Darunter ist re mit Python ausgestattet, und die Anforderungsbibliothek muss einfach von uns selbst installiert werden Installationsanfragen in der Befehlszeile.
Suchen Sie dann eine beliebige Website. Achten Sie darauf, dass Sie nicht versuchen, datenschutzrelevante Informationen zu crawlen. Hier ist eine Emoticon-Website:
Hinweis: Der Inhalt der Emoticon-Website kann kostenlos heruntergeladen werden, sodass der Crawler unseren Prozess lediglich vereinfacht Achten Sie bei diesem Vorgang darauf, keine kostenpflichtigen Ressourcen zu crawlen.
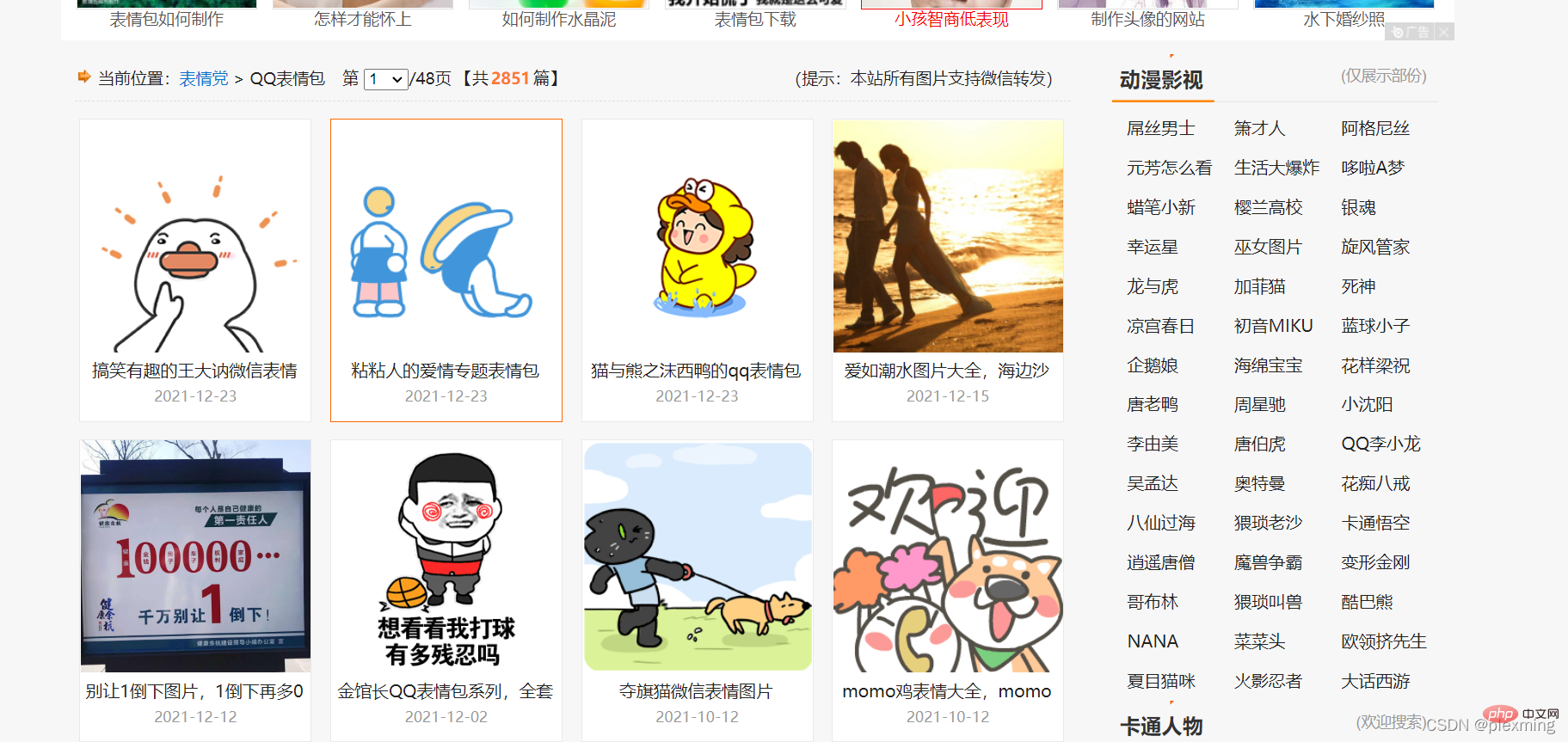
Was wir tun müssen, ist, diese Emoticons über einen Crawler auf unseren Computer herunterzuladen.
Schreiben Sie ein Crawler-Programm
Zunächst müssen Sie über Python auf diese Website zugreifen. Der Code lautet wie folgt:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) //请求网页
Der Grund, warum der Header-Bereich hinzugefügt wird, liegt darin, dass einige Webseiten erkennen, dass Sie eine Anfrage über Python stellen und lehnen Sie ab, daher wechseln wir zu einem normalen Anfrageheader. Sie können einen zufällig finden oder mit f12 einen aus den Netzwerkinformationen kopieren.
 ... Verwenden Sie reguläre Ausdrücke, um die Zeichenfolge in der Mitte abzugleichen. Ersetzen Sie sie. Die einfachste ist .*?
... Verwenden Sie reguläre Ausdrücke, um die Zeichenfolge in der Mitte abzugleichen. Ersetzen Sie sie. Die einfachste ist .*?
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
und zwar so.
Dann können Sie die Findall-Methode in der Re-Bibliothek aufrufen, um den relevanten Inhalt zu durchsuchen: 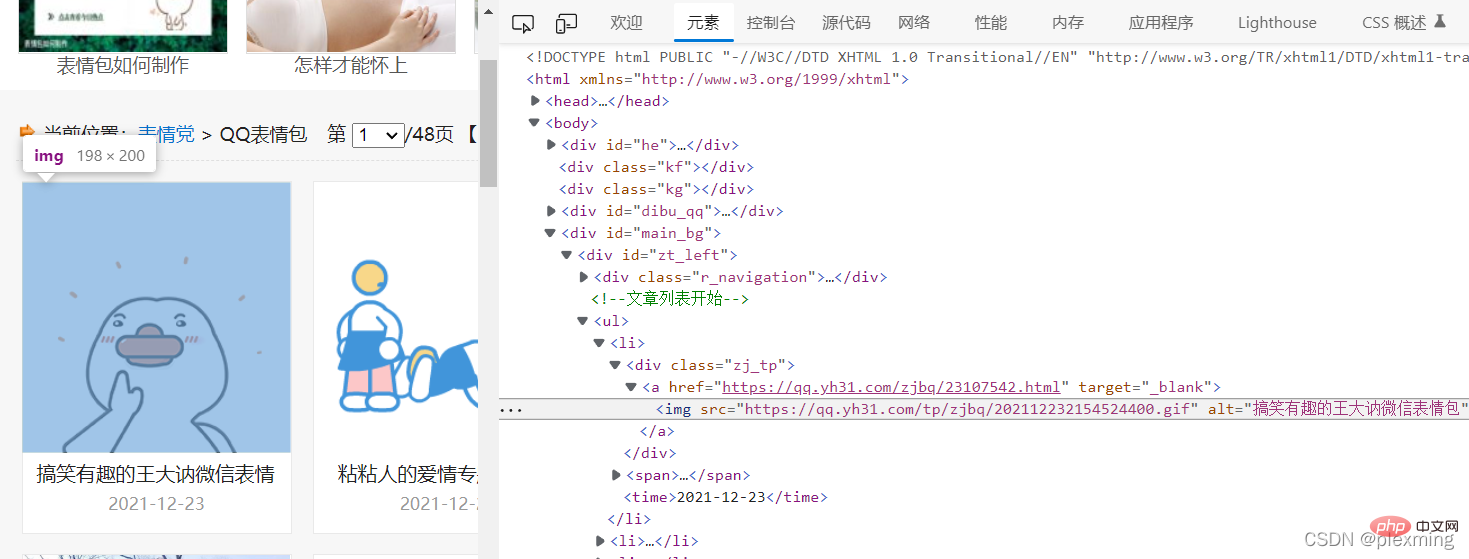
result = re.findall(t, response.text)Der zurückgegebene Inhalt ist eine Liste bestehend aus Zeichenfolgen. Schließlich laden wir das Bild herunter und speichern es über die Python-Anweisung in einer Datei Legen Sie die gecrawlte Adresse einfach in den Ordner. Programmcode
import requests
import re
import os
image = '表情包'
if not os.path.exists(image):
os.mkdir(image)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers)
response.encoding = 'GBK'
response.encoding = 'utf-8'
print(response.request.headers)
print(response.status_code)
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
result = re.findall(t, response.text)
for img in result:
print(img)
res = requests.get(img[0])
print(res.status_code)
s = img[0].split('.')[-1] #截取图片后缀,得到表情包格式,如jpg ,gif
with open(image + '/' + img[1] + '.' + s, mode='wb') as file:
file.write(res.content)Das Endergebnis sieht so aus:
[Verwandte Empfehlungen:
Python3-Video-Tutorial]
Das obige ist der detaillierte Inhalt vonErste Schritte mit dem Python-Crawler: Webbilder crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Lassen Sie uns über Ideen zur Python-Programmierung sprechen
- Kann Python JavaScript ersetzen?
- Detaillierte Erläuterung der Grundparameter von matplotlib.pyplot in der Zusammenfassung der Python-Visualisierung
- Tiefes Verständnis der Code-Einrückungsregeln in Python
- Detaillierte Erläuterung der Beispiele für Python-Random-Forest-Modelle