
Heim >Datenbank >MySQL-Tutorial >Eingehende Analyse des Abfrageoptimierers in MySQL (detaillierte Erläuterung des Funktionsprinzips)
Eingehende Analyse des Abfrageoptimierers in MySQL (detaillierte Erläuterung des Funktionsprinzips)

- 青灯夜游nach vorne
- 2022-07-04 20:35:073664Durchsuche
Dieser Artikel bietet Ihnen eine detaillierte Analyse des Abfrageoptimierers in MySQL und hilft Ihnen, das Funktionsprinzip des MySQL-Abfrageoptimierers zu verstehen.

Bei einer SQL-Anweisung prüft der Abfrageoptimierer zunächst, ob sie in einen JOIN umgewandelt werden kann, und optimiert dann den JOIN.
Die Optimierung ist unterteilt in: 1. Bedingte Optimierung, 2. Berechnen der vollständigen Tabellenscankosten , 3. Finden Sie alle Indizes heraus, die verwendet werden können, 4. Berechnen Sie die Kosten verschiedener Zugriffsmethoden für jeden Index, 5. Wählen Sie den Index und die Zugriffsmethode mit den geringsten Kosten aus
1. Aktivieren Sie das Abfrageoptimierungsprotokoll
-- 开启 set optimizer_trace="enabled=on"; -- 执行sql -- 查看日志信息 select * from information_schema.OPTIMIZER_TRACE; -- 关闭 set optimizer_trace="enabled=off";
2. Optimierungskonverterprinzip
-
1. Konstante Ausbreitung (constant_propagation)
2. Äquivalente Übertragung (equality_propagation)
a = 1 AND b > a
Das obige SQL kann umgewandelt werden in:
a = 1 AND b > a = b und b = c und c = 5 - Das obige SQL kann umgewandelt werden in:
a = 5 und b = 5 und c = 5
3. Entfernen Sie nutzlose Bedingungen (trivial_condition_removal) a = 1 und 1 = 1 - Das obige SQL kann wie folgt konvertiert werden:
a = 1
4. Basierend auf den Kosten Eine Abfrage kann verschiedene Ausführungspläne haben. Sie können einen Index für die Abfrage auswählen. Oder Sie können den gesamten Tabellenscan auswählen. Der Abfrageoptimierer wählt dann die Lösung mit den niedrigsten Kosten für die Ausführung der Abfrage. - 1) E/A-Kosten
Die InnoDB-Speicher-Engine speichert sowohl Daten als auch Indizes auf der Festplatte. Wenn wir die Datensätze in der Tabelle abfragen möchten, müssen wir zuerst die Daten oder den Index in den Speicher laden und dann arbeiten. Die Zeit, die beim Ladevorgang von der Festplatte in den Speicher verloren geht, wird als I/O-Kosten bezeichnet CPU-Kosten.
Bevor eine einzelne Tabellenabfrageanweisung tatsächlich ausgeführt wird, ermittelt der Abfrageoptimierer von MySQL alle möglichen Lösungen für die Ausführung der Anweisung und vergleicht sie, um die kostengünstigste Lösung zu finden Die kostengünstigste Lösung ist der sogenannte Ausführungsplan. Anschließend wird die von der Speicher-Engine bereitgestellte Schnittstelle aufgerufen, um die Abfrage tatsächlich auszuführen.
Die InnoDB-Speicher-Engine legt fest, dass die Kosten für das Lesen einer Seite standardmäßig 1,0 betragen und die Kosten für das Lesen und Überprüfen, ob ein Datensatz die Suchbedingungen erfüllt, standardmäßig 0,2 betragen.
3. Kostenbasierte Optimierungsschritte Lassen Sie uns diese Schritte anhand eines Beispiels analysieren:
select * from employees.titles where emp_no > '10101' and emp_no < '20000' and to_date = '1991-10-10';
1. Finden Sie alle möglichen Indizes gemäß den Suchbedingungen
• emp_no > '10101' Verwenden Sie den Primärschlüsselindex PRIMARY. • to_date = „10.10.1991“, diese Suchbedingung kann den Sekundärindex idx_titles_to_date verwenden. Zusammenfassend sind die Indizes, die in der obigen Abfrageanweisung verwendet werden können, d. h. die einzig möglichen Schlüssel, PRIMARY und idx_titles_to_date.
Für die InnoDB-Speicher-Engine bedeutet der vollständige Tabellenscan, die Datensätze im Clustered-Index nacheinander mit den angegebenen Suchbedingungen zu vergleichen und die Datensätze abzugleichen Dem Ergebnissatz werden Suchbedingungen hinzugefügt. Daher muss die Seite, die dem Clustered-Index entspricht, in den Speicher geladen werden. Anschließend wird überprüft, ob der Datensatz die Suchbedingungen erfüllt. Da Abfragekosten = E/A-Kosten + CPU-Kosten sind, sind zwei Informationen erforderlich, um die Kosten eines vollständigen Tabellenscans zu berechnen: 1) Die Anzahl der vom Clustered-Index belegten Seiten
2) Die Anzahl der Datensätze in Die Tabelle MySQL verwaltet für jede Tabelle eine Reihe statistischer Informationen. Verwenden Sie die SHOW TABLE STATUS-Anweisung, um die statistischen Informationen der Tabelle anzuzeigen.SHOW TABLE STATUS LIKE 'titles';
Rows
stellt die Anzahl der Datensätze in der Tabelle dar. Dieser Wert ist für Tabellen, die die MyISAM-Speicher-Engine verwenden, genau und ist eine Schätzung für Tabellen, die die InnoDB-Speicher-Engine verwenden.
Datenlänge
gibt die Anzahl der Bytes an Speicherplatz an, die von der Tabelle belegt werden. Bei Tabellen, die die MyISAM-Speicher-Engine verwenden, entspricht dieser Wert der Größe der Datendatei. Bei Tabellen, die die InnoDB-Speicher-Engine verwenden, entspricht dieser Wert dem vom Clustered-Index belegten Speicherplatz, was bedeutet, dass der Wert wie folgt berechnet werden kann Größe:
Data_length = 聚簇索引的页面数量 x 每个页面的大小
Unsere Titel verwenden die Standardseitengröße von 16 KB, und die obigen Abfrageergebnisse zeigen, dass der Wert von Data_length 20512768 ist, sodass wir die Anzahl der Seiten im Clustered-Index umgekehrt ableiten können: 聚簇索引的页面数量 = Data_length ÷ 16 ÷ 1024 = 20512768 ÷ 16 ÷ 1024 = 1252
Wir haben jetzt Clustering Die Anzahl der vom Index belegten Seiten und eine Schätzung der Anzahl der Datensätze in der Tabelle, sodass die Kosten für einen vollständigen Tabellenscan berechnet werden können. Bei der tatsächlichen Berechnung der Kosten nimmt MySQL jedoch einige Feinabstimmungen vor.
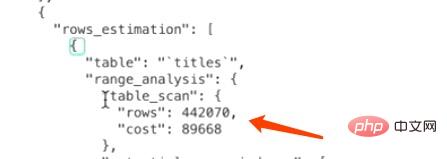
1 = 1252. 1252 bezieht sich auf die Anzahl der vom Clustered-Index belegten Seiten und 1,0 bezieht sich auf die Kostenkonstante für das Laden einer Seite.
CPU-Kosten: 4420700,2=88414. 442070 bezieht sich auf die Anzahl der Datensätze in der Tabelle in der Statistik, was eine Schätzung für die InnoDB-Speicher-Engine ist, und 0,2 bezieht sich auf die Kostenkonstante, die für den Zugriff auf einen Datensatz erforderlich ist
Gesamtkosten: 1252+88414 = 89666.Zusammenfassend belaufen sich die Gesamtkosten für das Scannen des vollständigen Titelverzeichnisses auf 89666.
我们前边说过表中的记录其实都存储在聚簇索引对应B+树的叶子节点中,所以只要我们通过根节点获得了最左边的叶子节点,就可以沿着叶子节点组成的双向链表把所有记录都查看一遍。也就是说全表扫描这个过程其实有的B+树内节点是不需要访问的,但是MySQL在计算全表扫描成本时直接使用聚簇索引占用的页面数作为计算I/O成本的依据,是不区分内节点和叶子节点的。
3、计算PRIMARY需要成本
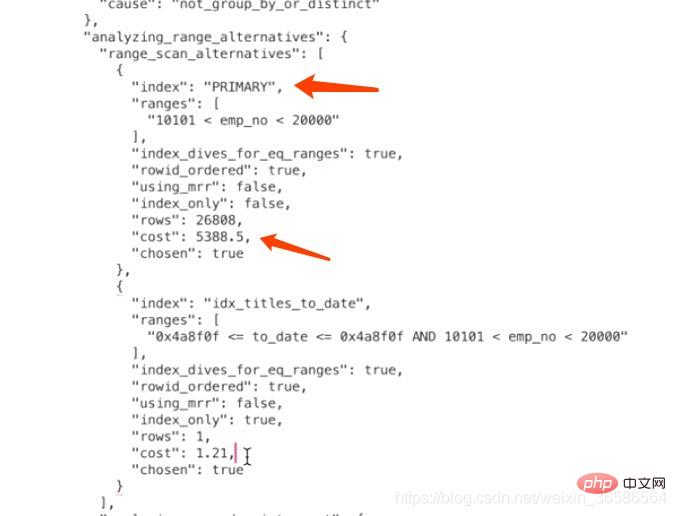
计算PRIMARY需要多少成本的关键问题是:需要预估出根据对应的where条件在主键索引B+树中存在多少条符合条件的记录。
范围区间数
当我们从索引中查询记录时,不管是=、in、>、 本例中使用PRIMARY的范围区间只有一个:(10101, 20000),所以相当于访问这个范围区间的索引付出的I/O成本就是:1 x 1.0 = 1.0
预估范围内的记录数
优化器需要计算索引的某个范围区间到底包含多少条记录,对于本例来说就是要计算PRIMARY在(10101, 20000)这个范围区间中包含多少条数据记录,计算过程是这样的:
步骤1:先根据emp_no > 10101这个条件访问一下PRIMARY对应的B+树索引,找到满足emp_no > 10101这个条件的第一条记录,我们把这条记录称之为区间最左记录。
步骤2:然后再根据emp_no
步骤3:如果区间最左记录和区间最右记录相隔不太远(只要相隔不大于10个页面即可),那就可以精确统计出满足emp_no > '10101' and emp_no
根据上面的步骤可以算出来PRIMARY索引的记录条数,所以读取记录的CPU成本为:26808*0.2=5361.6,其中26808是预估的需要读取的数据记录条数,0.2是读取一条记录成本常数。
PRIMARY的总成本
确定访问的IO成本+过滤数据的CPU成本=1+5361.6=5362.6
4、计算idx_titles_to_date需要成本
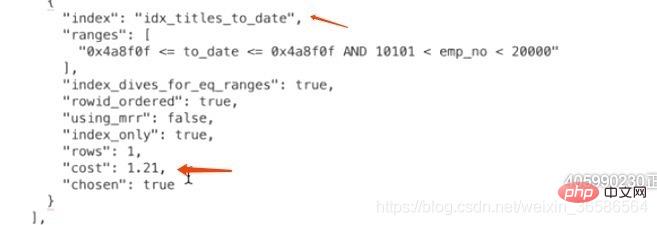
因为通过二级索引查询需要回表,所以在计算二级索引需要成本时还要加上回表的成本,而回表的成本就相当于下面这个SQL执行:
select * from employees.titles where 主键字段 in (主键值1,主键值2,。。。,主键值3);
所以idx_titles_to_date的成本 = 辅助索引的查询成本 + 回表查询的成本
5、比较各成本选出最优者
选择成本最小的索引
四、基于索引统计数据的成本计算
有时候使用索引执行查询时会有许多单点区间,比如使用IN语句就很容易产生非常多的单点区间,比如下边这个查询:
select * from employees.titles where to_date in ('a','b','c','d', ..., 'e');
很显然,这个查询可能使用到的索引就是idx_titles_to_date,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。计算方式我们上边已经介绍过了,就是先获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。这种通过直接访问索引对应的B+树来计算某个范围区间对应的索引记录条数的方式称之为index pe。
如果只有几个单点区间的话,使用index pe的方式去计算这些单点区间对应的记录数也不是什么问题,可是如果很多呢,比如有20000次,MySQL的查询优化器为了计算这些单点区间对应的索引记录条数,要进行20000次index pe操作,那么这种情况下是很耗性能的,所以MySQL提供了一个系统变量eq_range_index_pe_limit,我们看一下这个系统变量的默认值:SHOW VARIABLES LIKE ‘%pe%’;为200。
也就是说如果我们的IN语句中的参数个数小于200个的话,将使用index pe的方式计算各个单点区间对应的记录条数,如果大于或等于200个的话,可就不能使用index pe了,要使用所谓的索引统计数据来进行估算。像会为每个表维护一份统计数据一样,MySQL也会为表中的每一个索引维护一份统计数据,查看某个表中索引的统计数据可以使用SHOW INDEX FROM 表名的语法。
Cardinality属性表示索引列中不重复值的个数。比如对于一个一万行记录的表来说,某个索引列的Cardinality属性是10000,那意味着该列中没有重复的值,如果Cardinality属性是1的话,就意味着该列的值全部是重复的。不过需要注意的是,对于InnoDB存储引擎来说,使用SHOW INDEX语句展示出来的某个索引列的Cardinality属性是一个估计值,并不是精确的。可以根据这个属性来估算IN语句中的参数所对应的记录数:
1)使用SHOW TABLE STATUS展示出的Rows值,也就是一个表中有多少条记录。
2)使用SHOW INDEX语句展示出的Cardinality属性。
3)根据上面两个值可以算出idx_key1索引对于的key1列平均单个值的重复次数:Rows/Cardinality
4)所以总共需要回表的记录数就是:IN语句中的参数个数*Rows/Cardinality。
NULL值处理
上面知道在统计列不重复值的时候,会影响到查询优化器。
对于NULL,有三种理解方式:
NULL值代表一个未确定的值,每一个NULL值都是独一无二的,在统计列不重复值的时候应该都当作独立的。
NULL值在业务上就是代表没有,所有的NULL值代表的意义是一样的,所以所有的NULL值都一样,在统计列不重复值的时候应该只算一个。
NULL完全没有意义,在统计列不重复值的时候应该忽略NULL。
innodb提供了一个系统变量:
show global variables like '%innodb_stats_method%';
这个变量有三个值:
nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。
nulls_unequal:认为所有NULL值都是不相等的。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。
nulls_ignored:直接把NULL值忽略掉。
最好不在索引列中存放NULL值才是正解
五、统计数据
InnoDB提供了两种存储统计数据的方式:
• 统计数据存储在磁盘上。
• 统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了。
MySQL给我们提供了系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
不过InnoDB默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。我们可以在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式。
- 1、基于磁盘的永久性统计数据
当我们选择把某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
• innodb_table_stats存储了关于表的统计数据,每一条记录对应着一个表的统计数据
• innodb_index_stats存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据 - 2、定期更新统计数据
• 系统变量innodb_stats_auto_recalc决定着服务器是否自动重新计算统计数据,它的默认值是ON,也就是该功能默认是开启的。每个表都维护了一个变量,该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表大小的10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新innodb_table_stats和innodb_index_stats表。不过自动重新计算统计数据的过程是异步发生的,也就是即使表中变动的记录数超过了10%,自动重新计算统计数据也不会立即发生,可能会延迟几秒才会进行计算。
•如果innodb_stats_auto_recalc系统变量的值为OFF的话,我们也可以手动调用ANALYZE TABLE语句来重新计算统计数据。ANALYZE TABLE single_table; - 3、控制执行计划
Index Hints
•USE INDEX:限制索引的使用范围,在数据表里建立了很多索引,当MySQL对索引进行选择时,这些索引都在考虑的范围内。但有时我们希望MySQL只考虑几个索引,而不是全部的索引,这就需要用到USE INDEX对查询语句进行设置。
•IGNORE INDEX :限制不使用索引的范围
•FORCE INDEX:我们希望MySQL必须要使用某一个索引(由于 MySQL在查询时只能使用一个索引,因此只能强迫MySQL使用一个索引)。这就需要使用FORCE INDEX来完成这个功能。
基本语法格式:
SELECT * FROM table1 USE|IGNORE|FORCE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3
【相关推荐:mysql视频教程】
Das obige ist der detaillierte Inhalt vonEingehende Analyse des Abfrageoptimierers in MySQL (detaillierte Erläuterung des Funktionsprinzips). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So fragen Sie die Zeichensatzkodierung einer Tabelle in MySQL ab
- Wie wird eine SQL-Anweisung in MySQL Learning ausgeführt? Lassen Sie uns über den Ausführungsprozess sprechen
- Eingehende Analyse von Indizes in MySQL (ausführliche Erläuterung der Prinzipien)
- Was ist die MySQL-Spaltenkonvertierungsfunktion?
- Wie löst MySQL das Problem, dass nach dem Löschen einer großen Datenmenge kein Speicherplatz freigegeben wird?