
Heim >Betrieb und Instandhaltung >Betrieb und Wartung von Linux >Was ist das Pipe-Zeichen unter Linux?
Was ist das Pipe-Zeichen unter Linux?

- 青灯夜游Original
- 2022-06-17 15:42:019675Durchsuche
Unter Linux ist das Pipe-Zeichen „|“, das hauptsächlich verwendet wird, um zwei oder mehr Befehle miteinander zu verbinden und die Ausgabe eines Befehls als Eingabe des nächsten Befehls zu verwenden. Die Syntax lautet „Befehl1 | Befehl2 [ | BefehlN“. .. ]“ wird die Ausgabe des Befehls auf der linken Seite des Zeichens „|“ als Eingabe des Befehls auf der rechten Seite des Zeichens „|“ verwendet. Das Pipe-Zeichen kann fortlaufend verwendet werden. Die Ausgabe des ersten Befehls wird als Eingabe des zweiten Befehls verwendet, und die Ausgabe des zweiten Befehls wird als Eingabe des dritten Befehls verwendet, und so weiter.

Die Betriebsumgebung dieses Tutorials: Linux7.3-System, Dell G3-Computer.
Shell hat auch eine Funktion, die darin besteht, zwei oder mehr Befehle (Programme oder Prozesse) miteinander zu verbinden und die Ausgabe eines Befehls als Eingabe des nächsten Befehls zu verwenden. Auf diese Weise wird eine Pipe gebildet .
Linux-Pipes verwenden vertikale Balken |, um mehrere Befehle zu verbinden, die als Pipe-Zeichen bezeichnet werden.
command1 | command2 command1 | command2 [ | commandN... ]
Wenn eine Pipe zwischen zwei Befehlen gesetzt wird, wird die Ausgabe des Befehls links vom Pipe-Symbol | zur Eingabe des Befehls rechts. Solange der erste Befehl in die Standardausgabe schreibt und der zweite Befehl von der Standardeingabe liest, können die beiden Befehle eine Pipe bilden. Die meisten Linux-Befehle können zum Bilden von Pipes verwendet werden.
Das Pipe-Zeichen kann fortlaufend verwendet werden. Die Ausgabe des ersten Befehls wird als Eingabe des zweiten Befehls verwendet, und die Ausgabe des zweiten Befehls wird als Eingabe des dritten Befehls verwendet, und so weiter.

Hier ist zu beachten, dass Befehl1 eine korrekte Ausgabe haben muss und Befehl2 das Ausgabeergebnis von Befehl2 verarbeiten kann. Befehl2 kann nur das korrekte Ausgabeergebnis von Befehl1 verarbeiten, kann jedoch die Fehlermeldung von nicht verarbeiten Befehl1.
Zum Beispiel: Sortieren Sie die Datei hello.sh und finden Sie die Zeile, die „better“ enthält. Der Befehl lautet: cat hello.sh |
SortierenDuplikate entfernen
Filter- 【1】Der erste Schritt – Text anzeigen
- Verwenden Sie zunächst den Befehl cat, um den Text anzuzeigen. Der auf dem Bildschirm gedruckte Inhalt ist die Ausgabe des Befehls cat
-
[root@linuxforliuhj test]# cat hello.sh hello this is linux be better be better i am lhj hello this is linux i am lhj i am lhj be better i am lhj have a nice day have a nice day hello this is linux hello this is linux have a nice day zzzzzzzzzzzzzz dddddddd gggggggggggggggggggg [root@linuxforliuhj test]#
【2】Der zweite Prozess – Sortieren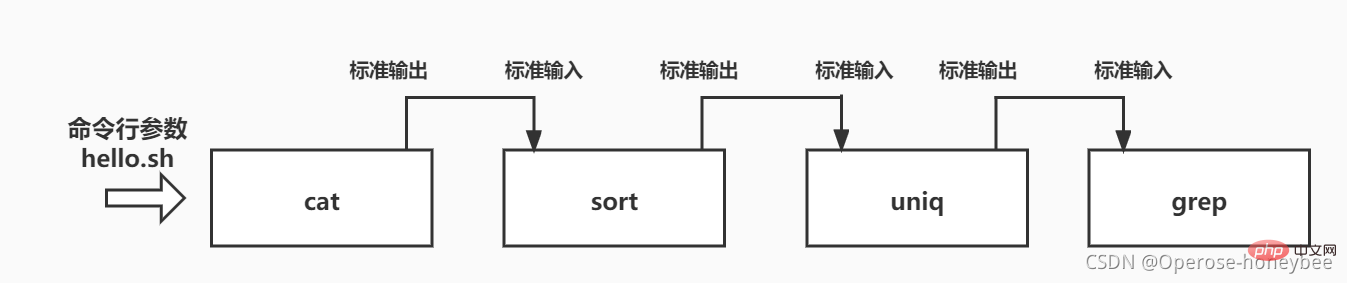 Die vom vorherigen Cat-Befehl ausgegebenen Ergebnisse werden über die Pipeline an den Sortierbefehl übergeben, sodass der Sortierbefehl den vom vorherigen Cat-Befehl ausgegebenen Text sortiert
Die vom vorherigen Cat-Befehl ausgegebenen Ergebnisse werden über die Pipeline an den Sortierbefehl übergeben, sodass der Sortierbefehl den vom vorherigen Cat-Befehl ausgegebenen Text sortiert
[root@linuxforliuhj test]# cat hello.sh | sort be better be better be better dddddddd gggggggggggggggggggg have a nice day have a nice day have a nice day hello this is linux hello this is linux hello this is linux hello this is linux i am lhj i am lhj i am lhj i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
【3】 Der dritte Prozessprozess – Deduplizierung
Wie im vorherigen Artikel zur Einführung von Uniq erwähnt, kann Sort in Kombination mit Uniq effektiv dedupliziert werden, sodass der von Sort ausgegebene Text zur Verarbeitung über die Pipeline an Uniq gesendet wird, sodass Uniq die Sortierung verarbeitet Text. , kann Duplikate effektiv entfernen
[root@linuxforliuhj test]# cat hello.sh | sort | uniq be better dddddddd gggggggggggggggggggg have a nice day hello this is linux i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
【4】Der vierte Prozess – Filtern
Der letzte Schritt des Filterns besteht auch darin, die Textausgabe nach der Verarbeitung des vorherigen Befehls, des Uniq-Befehls, zu filtern
[root@linuxforliuhj test]# cat hello.sh | sort | uniq | grep 'better' be better [root@linuxforliuhj test]#Hier kommt der entscheidende Punkt ! Hier kommt der wichtige Punkt!
Hier kommt der wichtige Punkt!
Die oben genannten Befehle cat, sort, uniq, grep und andere unterstützen alle das Pipe-Zeichen, da diese Befehle den Text lesen können von der Standardeingabe verarbeitet werden (d. h. das Lesen von Parametern von der Standardeingabe); bei einigen Befehlen wie rm, kill und anderen Befehlen wird das Lesen von Parametern von der Standardeingabe nicht unterstützt, sondern nur das Lesen von Parametern von der Befehlszeile (Das heißt, delete muss nach der rm-Befehlsdatei oder dem rm-Befehlsverzeichnis angegeben werden, die abzubrechende Prozessnummer muss nach dem Kill-Befehl angegeben werden usw.)
Welche Befehle unterstützen also Pipes und welche Befehle? unterstützen keine Rohre? Im Allgemeinen unterstützen Befehle, die Text verarbeiten, wie z. B. sort, uniq, grep, awk, sed usw., keine Pipes. Befehle, die keinen Text verarbeiten, wie z. B. rm und ls, unterstützen keine Pipes Wenn nach sort keine Parameter vorhanden sind, wird die Ausgabe des vorherigen Befehls verarbeitet, die durch das Pipe-Zeichen an ihn geworfen wurde (d. h. die Standardausgabe des vorherigen Befehls wird als Standardeingabe dieses Befehls verwendet).
[root@linuxforliuhj test]# cat hello.sh | sort be better be better be better dddddddd gggggggggggggggggggg have a nice day have a nice day have a nice day hello this is linux hello this is linux hello this is linux hello this is linux i am lhj i am lhj i am lhj i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
Wenn die Datei sein soll Wird nach rm nicht gelöscht, wird ein Fehler gemeldet. Parameter gehen verloren, daher unterstützen Befehle wie rm das Lesen von Parametern aus der Standardeingabe nicht. Sie unterstützen nur die Angabe von Parametern in der Befehlszeile, d. h. die Angabe von zu löschenden Dateien.Was hat Vorrang zwischen Standardeingabe- und Befehlszeilenparametern?
Führen Sie den Befehl aus: cat a.txt |. sort
Es gibt die folgenden zwei Dateien[root@linuxforliuhj test]# ls beifen.txt hello.sh mk read.ln read.sh read.txt sub.sh [root@linuxforliuhj test]# ls | grep read.sh read.sh [root@linuxforliuhj test]# ls | grep read.sh | rm rm: missing operand Try 'rm --help' for more information. [root@linuxforliuhj test]#
[root@linuxforliuhj test]# cat a.txt aaaa dddd cccc bbbb [root@linuxforliuhj test]# cat b.txt 1111 3333 4444 2222 [root@linuxforliuhj test]#Wenn der Befehlszeilenparameter von sort leer ist, wird die Ausgabe des vorherigen Befehls als Eingabe dieses Befehls verwendet standardmäßigAusführungsbefehl: cat a.txt |. sort b.txt
[root@linuxforliuhj test]# cat a.txt | sort
aaaa
bbbb
cccc
dddd
[root@linuxforliuhj test]#
Sie können sehen, dass sort die Parameter in der Standardeingabe nicht liest, wenn der Befehlszeilenparameter von sort (hier b.txt) nicht leer ist , und wann Lesen Sie die Befehlszeilenparameter
Führen Sie den Befehl aus: cat a.txt |. sort b.txt -[root@linuxforliuhj test]# cat a.txt | sort b.txt 1111 2222 3333 4444 [root@linuxforliuhj test]#" - "Gibt die Standardeingabe an, d. h. die Ausgabe des Befehls cat a.txt, der ist entspricht der Datei b.txt und der Standardeingabe zusammen. Die Sortierung entspricht der Sortierung a.txt b.txt
[root@linuxforliuhj test]# sort a.txt b.txt 1111 2222 3333 4444 aaaa bbbb cccc dddd [root@linuxforliuhj test]#
思考:对于rm、kill等命令,我们写脚本时常常会遇到需要查询某个进程的进程号然后杀掉该进程,查找某个文件然后删除它这样的需求,该怎么办呢?那就用xargs吧!
相关推荐:《Linux视频教程》
Das obige ist der detaillierte Inhalt vonWas ist das Pipe-Zeichen unter Linux?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!