
Heim >Datenbank >MySQL-Tutorial >Lassen Sie uns gemeinsam die Prinzipien des MySQL-Transaktionsworkflows analysieren
Lassen Sie uns gemeinsam die Prinzipien des MySQL-Transaktionsworkflows analysieren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-06-01 11:52:252102Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, in dem hauptsächlich Probleme im Zusammenhang mit den Prinzipien des Transaktionsworkflows vorgestellt werden, einschließlich der Atomizität von Transaktionen, die durch Rückgängig-Protokoll erreicht wird, und der Persistenz von Transaktionen, die durch Wiederherstellen erreicht werden. Werfen wir einen Blick darauf Implementierung von Protokollen usw. Ich hoffe, dass es für alle hilfreich sein wird.

Empfohlenes Lernen: MySQL-Video-Tutorial
- Die Atomarität von Transaktionen wird durch Undo-Log erreicht
- Die Haltbarkeit von Transaktionen wird durch Redo-Log erreicht
- Die Isolierung von Transaktionen wird durch (lesen Sie Schreibsperre +) erreicht MVCC) zu erreichen
- Und die ultimative Big-Boss-Konsistenz von Transaktionen wird durch Atomizität, Persistenz und Isolation erreicht! ! !
1. Redo-Log erreicht Persistenz
Frage 1: Warum brauchen Sie Redo-Log?
InnoDB ist die Speicher-Engine von MySQL. Daten werden auf der Festplatte gespeichert, aber wenn zum Lesen und Schreiben von Daten jedes Mal Festplatten-E/A erforderlich ist, ist die Effizienz sehr gering. Zu diesem Zweck stellt InnoDB einen Cache (Buffer Pool) als Puffer für den Zugriff auf die Datenbank bereit: Beim Lesen von Daten aus der Datenbank werden diese zunächst aus dem Buffer Pool gelesen. Wenn kein Buffer Pool vorhanden ist, werden sie aus dem gelesen Beim Schreiben von Daten in die Datenbank werden diese zuerst in den Pufferpool geschrieben und die geänderten Daten im Pufferpool werden regelmäßig auf die Festplatte aktualisiert.
Die Verwendung des Pufferpools verbessert die Effizienz beim Lesen und Schreiben von Daten erheblich, bringt jedoch auch neue Probleme mit sich: Wenn MySQL ausfällt und die geänderten Daten im Pufferpool nicht auf die Festplatte geleert wurden, führt dies zu Datenverlust. Die Haltbarkeit der Transaktion kann nicht garantiert werden.
Frage 2: Wie stellt Redo Log die Haltbarkeit von Transaktionen sicher?
Redo-Log kann einfach in die folgenden zwei Teile unterteilt werden:
Der erste ist der In-Memory-Redo-Log-Puffer (Redo-Log-Puffer), der flüchtig ist und im Speicher liegt
Der zweite ist der Redo Die Protokolldatei (Redo-Protokolldatei) ist dauerhaft und wird auf der Festplatte gespeichert Auf der Festplatte wird das Redo-Log geschrieben. Beachten Sie, dass die Daten zuerst geändert werden und das Protokoll später geschrieben wird
Das Redo-Protokoll wird vor der Datenseite auf die Festplatte zurückgeschrieben
Änderungen des Clustered-Index, des Sekundärindex und der Rückgängig-Seite müssen alle im Redo aufgezeichnet werden log
Wenn in MySQL jeder Aktualisierungsvorgang auf die Festplatte geschrieben werden muss und die Festplatte vor der Aktualisierung den entsprechenden Datensatz finden muss, sind die E/A- und Suchkosten des gesamten Prozesses sehr hoch. Um dieses Problem zu lösen, verwendeten die MySQL-Entwickler Redo-Log, um die Aktualisierungseffizienz zu verbessern. 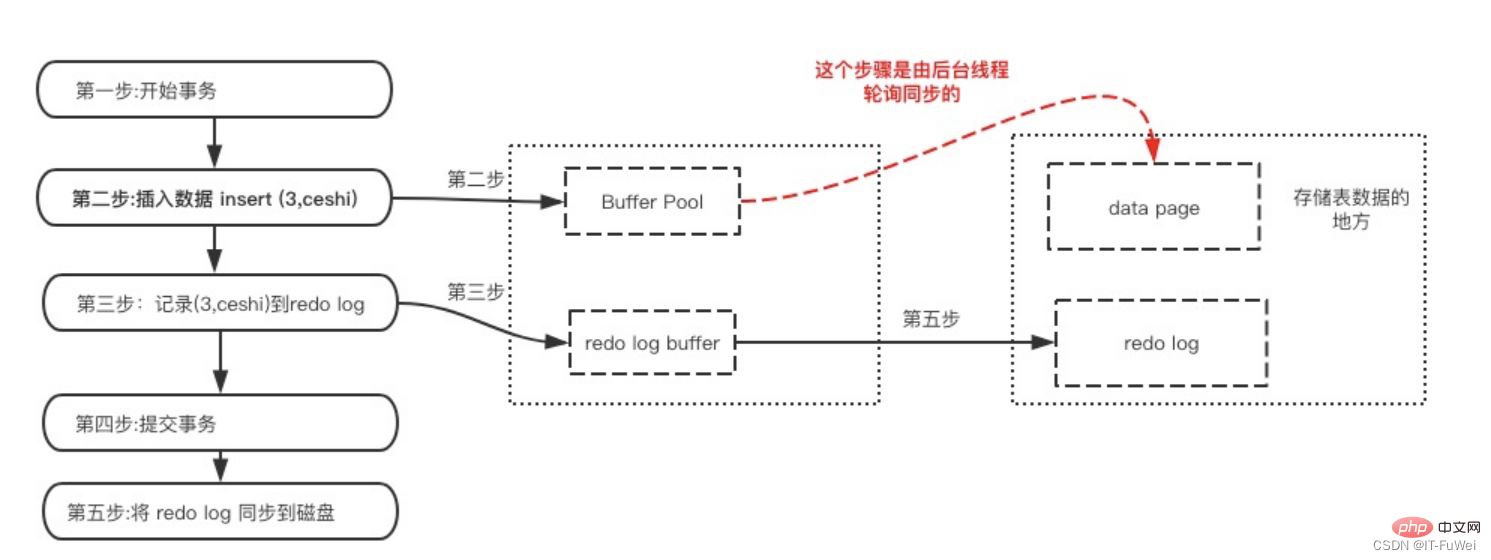
Wenn ein Datensatz aktualisiert werden muss, schreibt die InnoDB-Engine den Datensatz zunächst in das Redo-Log (Redo-Log-Puffer) und aktualisiert den Speicher (Pufferpool). Zu diesem Zeitpunkt ist die Aktualisierung abgeschlossen. Gleichzeitig aktualisiert die InnoDB-Engine diesen Vorgangsdatensatz zum richtigen Zeitpunkt (z. B. wenn das System im Leerlauf ist) auf der Festplatte (löschen schmutzige Seiten).
Mehrere Seiten können in einer Transaktion geändert werden. Das Write-Ahead-Protokoll kann die Konsistenz einer einzelnen Datenseite sicherstellen, kann jedoch nicht die Dauerhaftigkeit der Transaktion garantieren, wenn eine Transaktion festgeschrieben wird generiert alle Das Mini-Transaktionsprotokoll muss auf die Festplatte geleert werden. Wenn die Datenbank nach Abschluss der Protokollleerung abstürzt, bevor die Seiten im Pufferpool auf das persistente Speichergerät geleert werden, wird die Integrität der Datenbank beeinträchtigt Daten können durch das Protokoll sichergestellt werden.
Frage 3: Wie läuft das Umschreiben von Protokollen ab?
Die obige Abbildung zeigt den Redo-Log-Schreibvorgang, z. B. eine Aktualisierungsanweisung, die durch eine Mini-Transaktion garantiert wird. Zuerst wird redo1 generiert ist Schreiben Sie in den privaten Puffer der Minitransaktion, nachdem die Aktualisierungsanweisung beendet ist, kopieren Sie redo1 aus dem privaten Puffer in den öffentlichen Protokollpuffer. Wenn die gesamte externe Transaktion festgeschrieben ist, wird der Redo-Log-Puffer in die Redo-Log-Datei geleert. (Das Redo-Log wird sequentiell geschrieben und das sequentielle Lesen und Schreiben der Festplatte ist viel schneller als das zufällige Lesen und Schreiben)
Frage 4: Wird die endgültige Festplattenplatzierung nach dem Schreiben der Daten anhand des Redo-Logs aktualisiert? Was ist mit der Aktualisierung aus dem Pufferpool?
Tatsächlich zeichnet das Redo-Protokoll nicht die vollständigen Daten der Datenseite auf, sodass es nicht in der Lage ist, die Festplattendatenseite selbst zu aktualisieren, und es gibt keine Situation, in der die Daten von aktualisiert werden Das Redo-Log wird schließlich auf der Festplatte abgelegt.
① Nachdem die Datenseite geändert wurde, stimmt sie nicht mit der Datenseite auf der Festplatte überein, was als schmutzige Seite bezeichnet wird. Das abschließende Löschen der Daten besteht darin, die Datenseiten im Speicher auf die Festplatte zu schreiben. Dieser Vorgang hat nichts mit dem Redo-Log zu tun.
② Wenn InnoDB in einem Crash-Recovery-Szenario feststellt, dass eine Datenseite während der Crash-Recovery möglicherweise Aktualisierungen verloren hat, liest es sie in den Speicher und lässt dann das Redo-Log den Speicherinhalt aktualisieren. Nach Abschluss der Aktualisierung wird die Speicherseite zu einer schmutzigen Seite und kehrt in den Zustand der ersten Situation zurück
Frage 5: Was ist ein Redo-Log-Puffer? Soll ich zuerst den Speicher ändern oder zuerst die Redo-Log-Datei schreiben?
Während des Aktualisierungsprozesses einer Transaktion muss das Protokoll mehrmals geschrieben werden. Zum Beispiel die folgende Transaktion:
Copybegin;
INSERT INTO T1 VALUES ('1', '1');
INSERT INTO T2 VALUES ('1', '1');
commit;
This Die Transaktion erfordert das Einfügen von Datensätzen in zwei Tabellen. Während des Dateneinfügevorgangs müssen die generierten Protokolle zunächst gespeichert werden, sie können jedoch vor dem Festschreiben nicht direkt in die Redo-Protokolldatei geschrieben werden.
Der Redo-Log-Puffer wird also benötigt. Dabei handelt es sich um einen Speicherbereich, der zunächst zum Speichern von Redo-Logs verwendet wird. Mit anderen Worten, wenn die erste Einfügung ausgeführt wird, wird der Datenspeicher geändert und auch der Redo-Log-Puffer in das Protokoll geschrieben.
Das eigentliche Schreiben des Protokolls in die Redo-Log-Datei erfolgt jedoch, wenn die Commit-Anweisung ausgeführt wird.
Redo-Log-Puffer ist im Wesentlichen nur ein Byte-Array, aber um diesen Puffer aufrechtzuerhalten, müssen viele andere Metadaten festgelegt werden, die alle in der log_t-Struktur gekapselt sind.
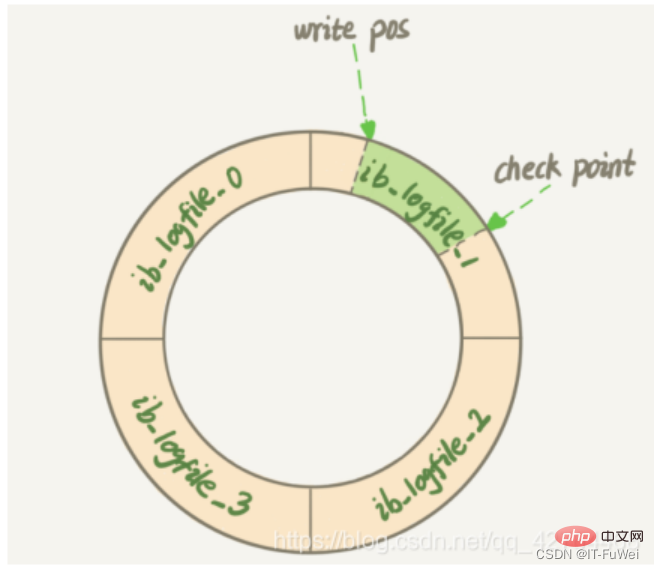
Frage 6: Werden Redo-Logs nacheinander auf die Festplatte geschrieben?
Mit dem Redo-Log kann die Datenbank bei einem abnormalen Neustart basierend auf dem Redo-Log wiederhergestellt werden, was absturzsicher ist.Das Redo-Protokoll schreibt Dateien nacheinander. Wenn alle Dateien voll sind, kehrt es zum Überschreiben an die entsprechende Startposition zurück. Nach jeder Transaktion wird das entsprechende Vorgangsprotokoll geschrieben Die Redo-Log-Datei wird an das Ende der Datei angehängt. Dies ist eine sequentielle E/A. Das Bild zeigt einen Satz von Redo-Log-Protokollen mit 4 Dateien, und der Prüfpunkt muss derzeit gelöscht werden Vor dem Löschen des Datensatzes müssen die entsprechenden Daten auf die Festplatte geschrieben werden (Aktualisieren Sie die Speicherseite und warten Sie, bis die fehlerhafte Seite geleert wird). Der Teil zwischen Schreibposition und Prüfpunkt kann zum Aufzeichnen neuer Vorgänge verwendet werden. Wenn Schreibposition und Prüfpunkt aufeinandertreffen, bedeutet dies, dass die Datenbank die Ausführung der Datenbankaktualisierungsanweisung beendet und stattdessen das Redoprotokoll synchronisiert die Festplatte. Der Teil zwischen Prüfpunkt und Schreibposition wartet darauf, dass die Festplatte beschrieben wird (aktualisieren Sie zuerst die Speicherseite und warten Sie dann, bis die fehlerhafte Seite geleert wird).
 Redo-Log wird verwendet, um absturzsichere Funktionen sicherzustellen. Wenn der Parameter innodb_flush_log_at_trx_commit auf 1 gesetzt ist, bedeutet dies, dass das Redo-Protokoll jeder Transaktion direkt auf der Festplatte gespeichert wird. Es wird empfohlen, diesen Parameter auf 1 zu setzen, um sicherzustellen, dass nach einem abnormalen MySQL-Neustart keine Daten verloren gehen
Redo-Log wird verwendet, um absturzsichere Funktionen sicherzustellen. Wenn der Parameter innodb_flush_log_at_trx_commit auf 1 gesetzt ist, bedeutet dies, dass das Redo-Protokoll jeder Transaktion direkt auf der Festplatte gespeichert wird. Es wird empfohlen, diesen Parameter auf 1 zu setzen, um sicherzustellen, dass nach einem abnormalen MySQL-Neustart keine Daten verloren gehen
2. Bin-Protokoll
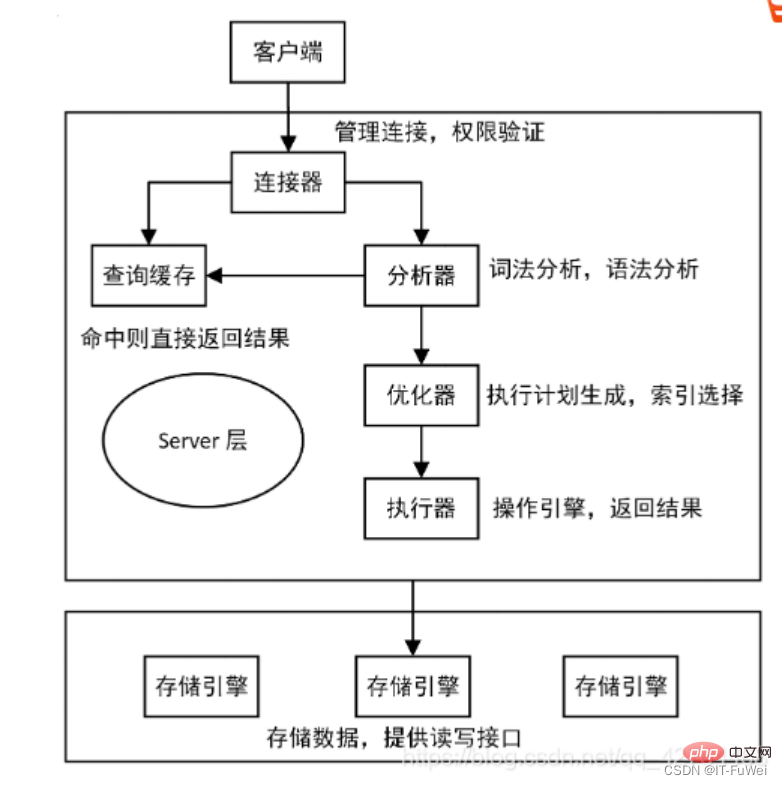
MySQL besteht tatsächlich aus zwei Teilen: Einer ist die Serverschicht, die hauptsächlich Dinge auf der MySQL-Funktionsebene erledigt ; es gibt auch die Engine-Schicht, die für bestimmte Angelegenheiten im Zusammenhang mit der Speicherung zuständig ist. Das Redo-Protokoll, über das wir oben gesprochen haben, ist ein Protokoll, das nur für die InnoDB-Engine gilt, und die Serverschicht verfügt auch über ein eigenes Protokoll namens Binlog (Archivprotokoll).
Warum gibt es zwei Protokolle?
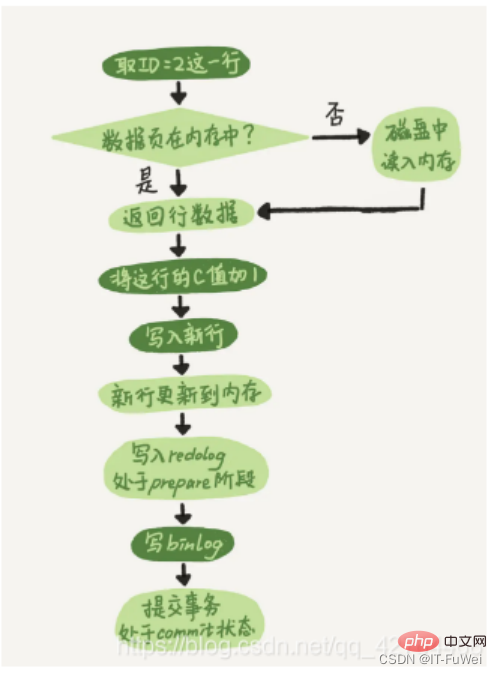
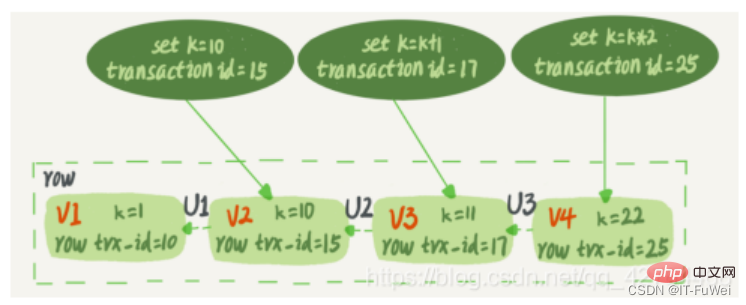
Weil es zu Beginn keine InnoDB-Engine in MySQL gab. Die eigene Engine von MySQL ist MyISAM, aber MyISAM verfügt nicht über Absturzsicherungsfunktionen und Binlog-Protokolle können nur zur Archivierung verwendet werden. InnoDB wurde von einem anderen Unternehmen in Form eines Plug-Ins in MySQL eingeführt. Da die alleinige Verwendung von Binlog keine absturzsicheren Funktionen bietet, verwendet InnoDB ein anderes Protokollsystem, nämlich Redo Log, um absturzsichere Funktionen zu erreichen. Diese beiden Protokolle weisen die folgenden drei Unterschiede auf. ① Redo-Log ist einzigartig für die InnoDB-Engine; binlog wird von der Serverschicht von MySQL implementiert und kann von allen Engines verwendet werden. ② Redo-Log ist ein physisches Protokoll, das aufzeichnet, „welche Änderungen auf einer bestimmten Datenseite vorgenommen wurden“. Binlog ist ein logisches Protokoll, das die ursprüngliche Logik dieser Anweisung aufzeichnet, z. B. „Geben Sie das c-Feld der Zeile an“. ID=2“ 1 hinzufügen. ③ Das Redo-Log wird in einer Schleife geschrieben und der Speicherplatz wird immer aufgebraucht; das Binlog kann zusätzlich geschrieben werden. „Schreiben anhängen“ bedeutet, dass die Binlog-Datei nach Erreichen einer bestimmten Größe zur nächsten wechselt und das vorherige Protokoll nicht überschreibt. Mit einem konzeptionellen Verständnis dieser beiden Protokolle schauen wir uns die internen Prozesse des Executors und der InnoDB-Engine bei der Ausführung dieser Update-Anweisung an. ① Der Executor sucht zunächst nach der Engine, um die Zeilen-ID=2 zu erhalten. Die ID ist der Primärschlüssel, und die Engine verwendet direkt die Baumsuche, um diese Zeile zu finden. Wenn sich die Datenseite, auf der sich die Zeile mit der ID=2 befindet, bereits im Speicher befindet, wird sie direkt an den Executor zurückgegeben. Andernfalls muss sie zuerst von der Festplatte in den Speicher gelesen und dann zurückgegeben werden. ② Der Executor ruft die von der Engine bereitgestellten Zeilendaten ab, addiert 1 zu diesem Wert, zum Beispiel war er früher N, aber jetzt ist er N+1, ruft eine neue Datenzeile ab und ruft dann die Engine-Schnittstelle auf um diese neue Datenzeile zu schreiben. ③ Die Engine aktualisiert diese neue Datenzeile im Speicher (InnoDB-Pufferpool) und zeichnet den Aktualisierungsvorgang im Redo-Log auf. Zu diesem Zeitpunkt befindet sich das Redo-Log im Vorbereitungszustand. Informieren Sie anschließend den Testamentsvollstrecker darüber, dass die Ausführung abgeschlossen ist und die Transaktion jederzeit eingereicht werden kann. ④ Der Executor generiert das Binlog dieses Vorgangs und schreibt das Binlog auf die Festplatte. ⑤ Der Executor ruft die Commit-Transaktionsschnittstelle der Engine auf, und die Engine ändert das gerade geschriebene Redo-Protokoll in den Commit-Status, und die Aktualisierung ist abgeschlossen Das Schreiben des Redo-Logs ist in zwei Schritte unterteilt: Vorbereiten und Commit, das ist ein zweiphasiges Commit (2PC) Frage 1: Was ist das Prinzip des zweiphasigen Commits? MySQL verwendet zweiphasiges Commit, um hauptsächlich das Problem der Datenkonsistenz zwischen Binlog und Redo-Log zu lösen. Beschreibung des Zwei-Phasen-Commit-Prinzips: ① Das Redo-Protokoll wird auf die Festplatte geschrieben und die InnoDB-Transaktion wechselt in den Vorbereitungsstatus. ② Wenn die vorherige Vorbereitung erfolgreich war und das Binlog auf die Festplatte geschrieben wurde, wird das Transaktionsprotokoll weiterhin im Binlog gespeichert. Wenn die Persistenz erfolgreich ist, wechselt die InnoDB-Transaktion in den Commit-Status. Redo-Log und Binlog haben ein gemeinsames Datenfeld namens XID. Während der Wiederherstellung nach einem Absturz werden Redo-Protokolle in der folgenden Reihenfolge gescannt: ① Wenn Sie auf ein Redo-Protokoll mit Vorbereitung und Festschreibung stoßen, senden Sie es direkt. ② Wenn Sie auf ein Redo-Protokoll mit nur Vorbereitung und keinem Festschreiben stoßen, senden Sie es direkt . Nehmen Sie die XID und gehen Sie zu binlog, um die entsprechende Transaktion zu finden. Binlog hat keinen Datensatz, Rollback-Transaktion Binlog hat Datensatz, Transaktion festschreiben Frage 2: Warum ist ein „zweiphasiges Festschreiben“ erforderlich? Wenn kein zweiphasiges Commit verwendet wird, gehen Sie davon aus, dass der Wert von Feld c in der aktuellen Zeile mit ID=2 0 ist, und gehen Sie davon aus, dass nach dem Schreiben des ersten Protokolls während der Ausführung der Update-Anweisung , das zweite Protokoll ist immer noch Wenn ein Absturz auftritt, bevor der Schreibvorgang abgeschlossen ist, was passiert dann? **Schreiben Sie zuerst das Redo-Protokoll und dann das Binlog. **Angenommen, der MySQL-Prozess startet abnormal neu, wenn das Redo-Log fertig ist, aber bevor das Binlog fertig ist. Wie bereits erwähnt, können die Daten nach dem Schreiben des Redo-Protokolls auch bei einem Systemabsturz wiederhergestellt werden. Daher beträgt der Wert von c in dieser Zeile nach der Wiederherstellung 1. Aber da das Binlog vor seiner Fertigstellung abstürzte, wurde diese Aussage zu diesem Zeitpunkt nicht im Binlog aufgezeichnet. Wenn das Protokoll später gesichert wird, wird diese Anweisung daher nicht in das gespeicherte Binlog aufgenommen. Dann werden Sie feststellen, dass, wenn Sie dieses Binlog zum Wiederherstellen der temporären Bibliothek verwenden müssen, die temporäre Bibliothek dieses Update verpasst, da das Binlog dieser Anweisung verloren geht und der Wert von c in der wiederhergestellten Zeile 0 ist ist derselbe wie die Originalbibliothek. Die Werte sind unterschiedlich. **Schreiben Sie zuerst das Binlog und dann das Redo-Log. **Wenn es nach dem Schreiben des Binlogs zu einem Absturz kommt, ist die Transaktion nach der Wiederherstellung nach dem Absturz ungültig, da das Redo-Log noch nicht geschrieben wurde, sodass der Wert von c in dieser Zeile 0 ist. Aber das Protokoll „Change c from 0 to 1“ wurde im Binlog aufgezeichnet. Wenn daher später Binlog zum Wiederherstellen verwendet wird, wird eine weitere Transaktion ausgegeben. Der Wert von c in der wiederhergestellten Zeile ist 1, was sich vom Wert in der ursprünglichen Datenbank unterscheidet. Sie können sehen, dass der Status der Datenbank möglicherweise nicht mit dem Status der mithilfe ihres Protokolls wiederhergestellten Bibliothek übereinstimmt, wenn „Zwei-Phasen-Commit“ nicht verwendet wird. Einfach ausgedrückt können sowohl Redo-Log als auch Binlog verwendet werden, um den Commit-Status einer Transaktion darzustellen, und das zweiphasige Commit dient dazu, die beiden Zustände logisch konsistent zu halten. 3. Undo-Protokoll erreicht Atomizität zeichnet auch das entsprechende Rückgängigmachen auf. Das Rückgängigmachen-Protokoll zeichnet hauptsächlich die logischen Änderungen der Daten auf. Um die vorherigen Vorgänge rückgängig zu machen, ist es notwendig, alle vorherigen Vorgänge aufzuzeichnen und dann rückgängig zu machen, wenn ein Fehler auftritt. In der InnoDB-Speicher-Engine ist das Rückgängig-Protokoll unterteilt in: Rückgängig-Protokoll einfügenRückgängig-Protokoll aktualisierenRückgängig-Protokoll einfügen bezieht sich auf das Rückgängig-Protokoll, das beim Einfügevorgang generiert wird, da der Datensatz des Einfügevorgangs nur sichtbar ist für die Transaktion selbst, für andere Transaktionen nicht sichtbar. Daher kann das Rückgängig-Protokoll direkt nach der Übermittlung der Transaktion gelöscht werden und es ist kein Löschvorgang erforderlich. Ergänzung: Die beiden Hauptfunktionen des Bereinigungsthreads sind: Bereinigen der Rückgängig-Seite und Löschen der Datenzeilen mit dem Flag „Delete_Bit“ auf der Seite. In InnoDB löscht die Löschoperation in einer Transaktion nicht tatsächlich die Datenzeile, sondern eine Löschmarkierungsoperation, die das Delete_Bit im Datensatz markiert, ohne den Datensatz zu löschen. Es handelt sich um eine Art „falsche Löschung“, die nur markiert wird. Die eigentliche Löscharbeit muss vom Hintergrundbereinigungsthread abgeschlossen werden. Innodb verwendet den B+-Baum als Indexdatenstruktur, und der Index, in dem sich der Primärschlüssel befindet, ist ClusterIndex (Clustered-Index), und der entsprechende Dateninhalt wird in den Blattknoten in ClusterIndex gespeichert. Eine Tabelle kann nur einen Primärschlüssel haben, daher kann es nur einen Clustered-Index geben. Wenn die Tabelle keinen Primärschlüssel definiert, wird der erste eindeutige Index ungleich NULL als Clustered-Index ausgewählt als Clustered-Index generiert. Andere Indizes als der Cluster-Index sind Sekundärindizes (Hilfsindizes). Die Blattknoten im Hilfsindex speichern die Werte der Blattknoten des Clustered-Index. Zusätzlich zu der gerade erwähnten Zeilen-ID enthalten InnoDB-Zeilendatensätze auch trx_id und db_roll_ptr, die die ID der kürzlich geänderten Transaktion darstellen, und db_roll_ptr verweist auf das Rückgängig-Protokoll im Rückgängig-Segment. Wenn eine neue Transaktion hinzugefügt wird, wird die Transaktions-ID erhöht und trx_id kann die Reihenfolge angeben, in der die Transaktionen gestartet werden. Das Rückgängigmachen-Protokoll ist in zwei Typen unterteilt: Einfügen und Aktualisieren. Löschen kann als spezielle Aktualisierung betrachtet werden, dh als Änderung der Löschmarkierung im Datensatz. Update-Rückgängig-Protokoll zeichnet die vorherigen Dateninformationen auf, wodurch der Status der vorherigen Version wiederhergestellt werden kann. Beim Ausführen eines Einfügevorgangs kann das generierte Einfüge-Rückgängig-Protokoll gelöscht werden, nachdem die Transaktion festgeschrieben wurde, da andere Transaktionen dieses Rückgängig-Protokoll nicht benötigen. Beim Löschen und Ändern von Vorgängen wird das entsprechende Rückgängig-Protokoll generiert und der db_roll_ptr im aktuellen Datensatz verweist auf das neue Rückgängig-Protokoll. MVCC (MultiVersion Concurrency Control) wird aufgerufen Parallelitätskontrolle mehrerer Versionen. InnoDBs MVCC wird implementiert, indem zwei versteckte Spalten hinter jeder Datensatzzeile gespeichert werden. Von diesen beiden Spalten speichert eine die Erstellungszeit der Zeile und die andere die Ablaufzeit der Zeile. Natürlich wird nicht der tatsächliche Zeitwert, sondern die Systemversionsnummer gespeichert. Die Hauptidee der Implementierung besteht darin, das Lesen und Schreiben durch mehrere Datenversionen zu trennen. Dies ermöglicht entsperrtes Lesen und paralleles Lesen und Schreiben. Die Implementierung von MVCC in MySQL basiert auf dem Rückgängig-Protokoll und der Leseansicht. InnoDB verwendet bei der Implementierung von MVCC eine konsistente Leseansicht, d. h. konsistentes Lesen view , wird zur Unterstützung der Implementierung der Isolationsstufen RC (Read Committed, Read Committed) und RR (Repeatable Read, Repeatable Read) verwendet. Unter der wiederholbaren Leseisolationsstufe erstellt eine Transaktion beim Start „einen Snapshot“. Im gepunkteten Feld im Bild befinden sich 4 Versionen derselben Datenzeile. Die neueste Version ist V4 und der Wert von k ist 22. Sie wurde durch die Transaktion mit der Transaktions-ID 25 aktualisiert seine Zeile trx_id Auch 25. Erzeugt die Anweisungsaktualisierung ein Rückgängig-Protokoll (Rollback-Protokoll)? Wo ist also das Rückgängig-Protokoll? Tatsächlich sind die drei gepunkteten Pfeile in Abbildung 2 die Rückgängig-Protokolle V1, V2 und V3, die nicht physisch vorhanden sind, sondern bei Bedarf auf der Grundlage der aktuellen Version und des Rückgängig-Protokolls berechnet werden. Wenn beispielsweise V2 benötigt wird, wird dies berechnet, indem U3 und U2 nacheinander bis V4 ausgeführt werden. 5. MySQL-Sperrtechnologie Wenn es mehrere Anfragen zum Lesen der Daten in der Tabelle gibt, kann keine Aktion ergriffen werden, aber wenn es unter den mehreren Anfragen Leseanfragen und Änderungsanfragen gibt, muss eine Maßnahme vorhanden sein Mach es. Parallelitätskontrolle. Andernfalls kann es zu Inkonsistenzen kommen. Es ist sehr einfach, die oben genannten Probleme mit Lese-/Schreibsperren zu lösen. Sie müssen lediglich eine Kombination aus zwei Sperren verwenden, um Lese- und Schreibanforderungen zu steuern. Diese beiden Sperren heißen: Exklusive Sperre Empfohlenes Lernen: MySQL-Video-Tutorial
undo log stellt die Datenbank nur logisch in ihren ursprünglichen Zustand zurück. Beispielsweise entspricht ein INSERT einem DELETE, und für jedes UPDATE entspricht es einem umgekehrten UPDATE Zeile vor der Änderung. Das Rückgängig-Protokoll wird für Transaktions-Rollback-Vorgänge verwendet, um die Atomizität der Transaktion sicherzustellen. Der Schlüssel zum Erreichen der Atomizität besteht darin, alle erfolgreich ausgeführten SQL-Anweisungen rückgängig machen zu können, wenn die Transaktion zurückgesetzt wird. InnoDB implementiert ein Rollback, indem es sich auf das Rückgängig-Protokoll verlässt: Wenn eine Transaktion die Datenbank ändert, generiert InnoDB das entsprechende Rückgängig-Protokoll. Wenn die Transaktionsausführung fehlschlägt oder ein Rollback aufgerufen wird, kann dies zu einem Rollback der Transaktion führen verwendet werden, um die Daten auf den Zustand vor der Änderung zurückzusetzen.
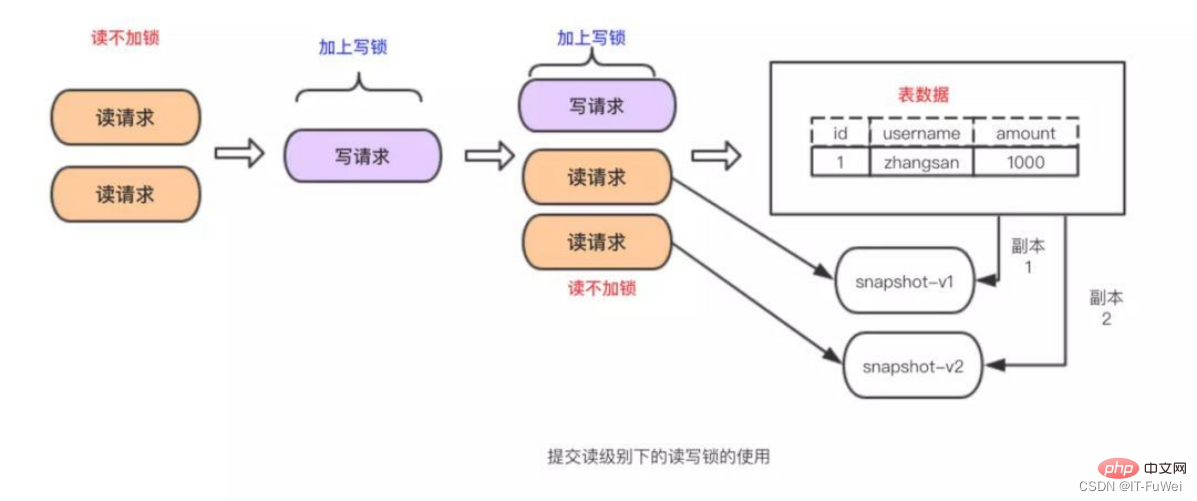

Gemeinsame Sperre. , auch als „Lesesperre“ bekannt, kann eine Lesesperre gemeinsam genutzt werden, oder mehrere Leseanforderungen können eine Sperre gemeinsam nutzen, um Daten zu lesen, ohne eine Blockierung zu verursachen.
Zusammenfassung: Durch Lese-/Schreibsperren können Lesen und Lesen parallel erfolgen, Schreiben und Lesen können jedoch nicht parallel erfolgen. Die Isolierung von Transaktionen wird durch Lese-/Schreibsperren erreicht! ! !
Das obige ist der detaillierte Inhalt vonLassen Sie uns gemeinsam die Prinzipien des MySQL-Transaktionsworkflows analysieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!