
Heim >Datenbank >MySQL-Tutorial >Detaillierte grafische Erläuterung der MySQL-Architekturprinzipien
Detaillierte grafische Erläuterung der MySQL-Architekturprinzipien

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-05-17 17:54:143033Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, das hauptsächlich die relevanten Inhalte zu den Architekturprinzipien vorstellt. Die MySQL-Server-Architektur kann von oben nach unten grob in Netzwerkverbindungsschicht, Serviceschicht, Speicher-Engine-Schicht und System unterteilt werden Werfen Sie einen Blick auf die Dateiebene. Ich hoffe, sie wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
MySQL-Architekturprinzipien
1. MySQL-Architektur
Die MySQL-Server-Architektur kann von oben nach unten grob in Netzwerkverbindungsschicht, Serviceschicht und Speicher-Engine-Schicht unterteilt werden und Systemdateischicht.
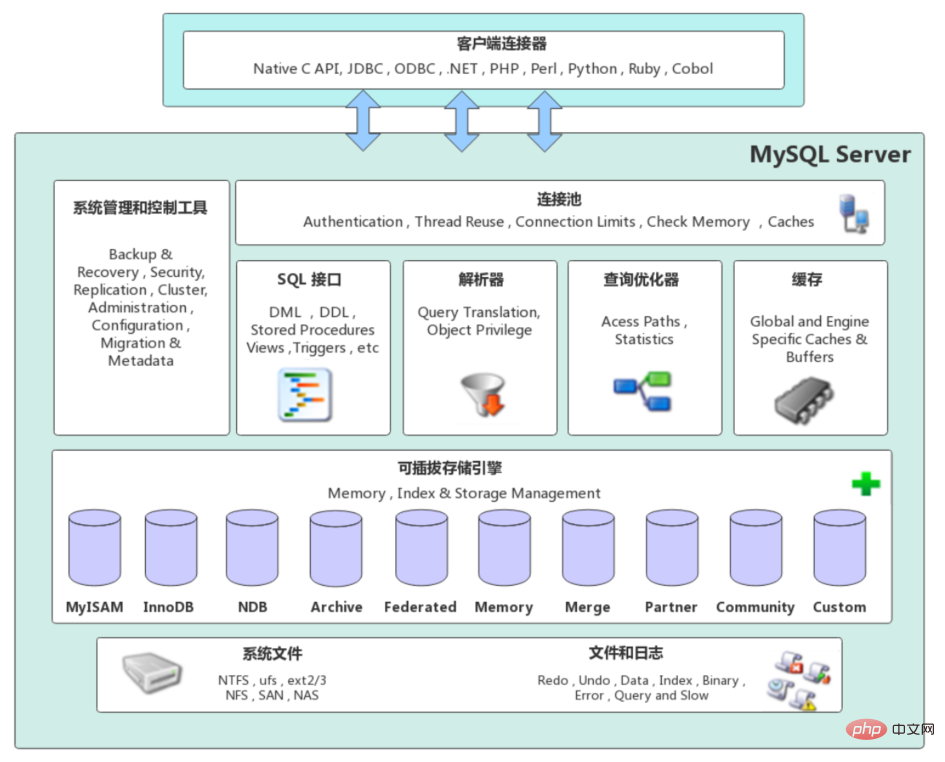
Netzwerkverbindungsschicht
- Client-Anschlüsse: Bietet Unterstützung für die Einrichtung mit dem MySQL-Server. Derzeit unterstützt es fast alle gängigen serverseitigen Programmiertechnologien, wie etwa gängiges Java, C, Python, .NET usw., die über ihre jeweiligen API-Technologien Verbindungen mit MySQL herstellen.
Serviceschicht (MySQL Server)
Die Serviceschicht ist der Kern von MySQL Server und besteht hauptsächlich aus sechs Teilen: Systemverwaltungs- und Kontrolltools, Verbindungspool, SQL-Schnittstelle, Parser, Abfrageoptimierer und Cache.
Verbindungspool: Verantwortlich für die Speicherung und Verwaltung der Verbindung zwischen dem Client und der Datenbank. Ein Thread ist für die Verwaltung einer Verbindung verantwortlich.
Systemverwaltungs- und Kontrolltools (Management Services & Utilities): wie Sicherung und Wiederherstellung, Sicherheitsverwaltung, Clusterverwaltung usw.
SQL-Schnittstelle (SQL-Schnittstelle): Wird zum Akzeptieren verschiedener von der gesendeten SQL-Befehle verwendet Client und gibt die Ergebnisse zurück, die der Benutzer abfragen muss. Wie DML, DDL, gespeicherte Prozeduren, Ansichten, Trigger usw.
Parser (Parser): Verantwortlich für das Parsen des angeforderten SQL, um einen „Analysebaum“ zu generieren. Überprüfen Sie dann weiter, ob der Analysebaum gemäß einigen MySQL-Regeln zulässig ist.
-
Abfrageoptimierer (Optimierer): Wenn der „Analysebaum“ die Parser-Grammatikprüfung besteht, wird er an den Optimierer übergeben, um ihn in einen Ausführungsplan umzuwandeln und dann mit der Speicher-Engine zu interagieren.
select uid, name from user where gender = 1;
Select--"Projection--"Join strategy
- select wählt zuerst basierend auf der where-Anweisung aus, anstatt alle Daten abzufragen und dann zu filtern;
- Die Projektion der ausgewählten Abfrageattribute erfolgt basierend auf UID und Name.
- Verbinden Sie die vorherige Auswahl und Projektion, um schließlich Abfrageergebnisse zu generieren eine Reihe kleiner Caches. Zum Beispiel Tabellencache, Datensatzcache, Berechtigungscache, Enginecache usw. Wenn der Abfrage-Cache ein Treffer-Abfrageergebnis hat, kann die Abfrageanweisung Daten direkt aus dem Abfrage-Cache abrufen.
Storage Engine Layer (Pluggable Storage Engines) - Die Storage Engine ist für die Speicherung und den Abruf von Daten in MySQL verantwortlich und interagiert mit den zugrunde liegenden Systemdateien. Die MySQL-Speicher-Engine ist ein Plug-in. Die Abfrageausführungs-Engine im Server kommuniziert über eine Schnittstelle mit der Speicher-Engine. Mittlerweile gibt es viele Speicher-Engines, jede mit ihren eigenen Eigenschaften. Die häufigsten sind MyISAM und InnoDB.
Systemdateischicht (Dateisystem)
- Diese Schicht ist für die Speicherung von Datenbankdaten und Protokollen im Dateisystem und die Vervollständigung der Interaktion mit der Speicher-Engine verantwortlich. Sie ist die physische Speicherschicht von Dateien. Enthält hauptsächlich Protokolldateien, Datendateien, Konfigurationsdateien, PID-Dateien, Socket-Dateien usw.
-
- Protokolldatei
- Fehlerprotokoll
- Standardmäßig aktiviert, Variablen wie „%log_error%“ anzeigen;
- Allgemeines Abfrageprotokoll (Allgemeines Abfrageprotokoll)
- Allgemeine Abfrageanweisungen aufzeichnen, Variablen wie „%general%“ anzeigen ;
- Binäres Protokoll (Binärprotokoll)
- zeichnet die in der MySQL-Datenbank durchgeführten Änderungsvorgänge auf und zeichnet die Auftrittszeit und Ausführungszeit der Anweisung auf; es zeichnet jedoch keine Auswahl, Anzeige usw. auf. SQL tut dies Ändern Sie die Datenbank nicht. Wird hauptsächlich zur Datenbankwiederherstellung und Master-Slave-Replikation verwendet.
- Variablen wie „%log_bin%“ anzeigen; //Parameteransicht
- Binärprotokolle anzeigen
- Zeichnet alle Abfrage-SQL auf, deren Ausführungszeit abgelaufen ist. Der Standardwert beträgt 10 Sekunden.
- Variablen wie „%slow_query%“ anzeigen; //Ob aktiviert werden soll
- Variablen wie „%long_query_time%“ anzeigen; //Dauer
- Fehlerprotokoll
- wird zum Speichern aller MySQL-Konfigurationsinformationsdateien verwendet. wie my.cnf, my.ini usw.
- db.opt-Datei: Zeichnet den von dieser Bibliothek verwendeten Standardzeichensatz und die Überprüfungsregeln auf.
- FRM-Datei: Speichert Metadaten (Meta)-Informationen zur Tabelle, einschließlich Definitionsinformationen der Tabellenstruktur usw. Jede Tabelle verfügt über eine FRM-Datei.
- MYD-Datei: Sie ist für die MyISAM-Speicher-Engine bestimmt und speichert die Daten der MyISAM-Tabelle. Jede Tabelle verfügt über eine .MYD-Datei.
- MYI-Datei: Dediziert für die MyISAM-Speicher-Engine, die indexbezogene Informationen der MyISAM-Tabelle speichert. Jede MyISAM-Tabelle entspricht einer .MYI-Datei.
- IBD-Datei und IBDATA-Datei: Speichern Sie InnoDB-Datendateien (einschließlich Indizes). Die InnoDB-Speicher-Engine verfügt über zwei Tabellenbereichsmodi: exklusiven Tabellenbereich und gemeinsam genutzten Tabellenbereich. Exklusive Tabellenbereiche verwenden .ibd-Dateien zum Speichern von Daten, und jede InnoDB-Tabelle entspricht einer .ibd-Datei. Gemeinsam genutzte Tabellenbereiche verwenden .ibdata-Dateien und alle Tabellen verwenden eine (oder mehrere, selbst konfigurierte) .ibdata-Dateien.
- ibdata1-Datei: Systemtabellenbereichsdatendatei, in der Tabellenmetadaten, Rückgängig-Protokolle usw. gespeichert werden.
- ib_logfile0, ib_logfile1 Dateien: Redo-Log-Protokolldateien.
- PID-Datei ist eine Prozessdatei der MySQL-Anwendung in der Unix/Linux-Umgebung und speichert wie viele andere Unix/Linux-Serverprogramme ihre eigene Prozess-ID.
- Socket-Datei ist auch in einer Unix/Linux-Umgebung verfügbar. Benutzer können Unix Socket direkt verwenden, um eine Verbindung zu MySQL herzustellen, wenn eine Client-Verbindung in einer Unix/Linux-Umgebung hergestellt wird, ohne über ein TCP/IP-Netzwerk zu gehen.
- Stellen Sie eine Verbindung her (Connectoren und Verbindungspool) und stellen Sie über das Client/Server-Kommunikationsprotokoll eine Verbindung mit MySQL her. Die Kommunikationsmethode zwischen MySQL-Client und Server ist „Halbduplex“. Für jede MySQL-Verbindung gibt es jederzeit einen Thread-Status, um zu identifizieren, was die Verbindung tut.
- Kommunikationsmechanismus:
- Vollduplex: Kann gleichzeitig Daten senden und empfangen, z. B. beim Telefonieren.
- Halbduplex: bezieht sich auf einen bestimmten Zeitpunkt, bei dem entweder Daten gesendet oder Daten empfangen werden, nicht gleichzeitig. Zum Beispiel frühe Walkie-Talkies
- simplex: können nur Daten senden oder nur Daten empfangen. Beispiel: Einbahnstraße;
- Thread-Status: Zeige die Thread-Informationen an, die der Benutzer ausführt. Der Root-Benutzer kann alle Threads anzeigen, andere Benutzer können nur ihre eigenen anzeigen. Thread-ID, Sie können kill xx verwenden;
- user: Der Benutzer, der diesen Thread gestartet hat
- Host: Die IP- und Portnummer des Clients, der die Anfrage gesendet hat
- db: In welcher Bibliothek der aktuelle Befehl ausgeführt wird
- Command : Der Operationsbefehl, der von diesem Thread ausgeführt wird
- Create DB: Derzeitige Bibliotheksoperation erstellen
- Drop DB: Bibliotheksoperation löschen
- Execute: Ein PreparedStatement ausführen
- Close Stmt: Ein PreparedStatement schließen
- Query: Eine Anweisung ausführen
- Ruhezustand: Warten darauf, dass der Client eine Anweisung sendet.
- Beenden: Wird beendet.
- Shutdown: Herunterfahren des Servers.
- Status: Thread-Status
- Aktualisierung: Suche nach übereinstimmenden Datensätzen und Durchführung von Änderungen
- Schlafend: Wartet derzeit darauf, dass der Client eine neue Anfrage sendet
- Beginnt: Anforderungsverarbeitung wird durchgeführt
- Prüftabelle: Die Datentabelle wird überprüft
- Schließtabelle: Die Daten in der Tabelle wird auf der Festplatte aktualisiert
- Gesperrt: Der Datensatz ist durch andere Abfragen gesperrt
- Daten senden: Verarbeiten der Select-Abfrage und gleichzeitiges Senden der Ergebnisse an den Client
- Zwischenspeichern Sie die Ergebnisse der Select-Abfrage und der SQL-Anweisungen.
- Kommunikationsmechanismus:
- Die Abfrageanweisung verwendet SQL_NO_CACHE
- Das Abfrageergebnis ist größer als die Einstellung query_cache_limit
- Es gibt einige Unsicherheiten Parameter in der Abfrage, wie zum Beispiel now()
-
- Variablen wie „%query_cache %“ anzeigen //Überprüfen Sie, ob der Abfragecache aktiviert ist, Speicherplatzgröße, Einschränkungen usw.
- Status anzeigen wie „Qcache%“; //Detailliertere Cache-Parameter, verfügbaren Cache-Speicherplatz, Cache-Blöcke, Cache-Größe usw. anzeigen.
- Der Abfrageoptimierer (Optimizer) generiert den optimalen Ausführungsplan basierend auf dem „Analysebaum“. MySQL verwendet viele Optimierungsstrategien, um optimale Ausführungspläne zu generieren, die in zwei Kategorien unterteilt werden können: statische Optimierung (Kompilierungszeitoptimierung) und dynamische Optimierung (Laufzeitoptimierung).
- Äquivalente Transformationsstrategie
- 5=5 und a>5 wird in a > 5 geändert
- a 5 und a=5 geändert
- Anpassen die Bedingungsposition usw.
- Anzahl, Min, Max und andere Funktionen optimieren
- Die Min-Funktion der InnoDB-Engine muss nur den Index ganz links finden.
- Die Max-Funktion der InnoDB-Engine muss nur den Index ganz rechts finden.
- Anzahl der MyISAM-Engine (*), keine Berechnung erforderlich, direkt Rückkehr
- Beenden Sie die Abfrage vorzeitig
- Verwenden Sie die Limit-Abfrage, um die für das Limit erforderlichen Daten zu erhalten, ohne die nachfolgenden Daten weiter zu durchlaufen
- Optimierung in
- MySQL sortiert zunächst die Abfrage und verwendet dann die binäre Aufteilungsmethode, um Daten zu finden. Beispielsweise wird die ID in (2,1,3) zu (1,2,3);
- Äquivalente Transformationsstrategie
- Die Abfrageausführungs-Engine ist zu diesem Zeitpunkt für die Ausführung der SQL-Anweisung verantwortlich Basierend auf der Speicherung der Tabelle in der SQL-Anweisung interagieren der Engine-Typ und die entsprechende API-Schnittstelle mit dem zugrunde liegenden Speicher-Engine-Cache oder den physischen Dateien, um die Abfrageergebnisse abzurufen und an den Client zurückzugeben. Wenn der Abfragecache aktiviert ist, werden die SQL-Anweisung und die Ergebnisse vollständig im Abfragecache gespeichert (Cache&Buffffer). Wenn dieselbe SQL-Anweisung in Zukunft ausgeführt wird, werden die Ergebnisse direkt zurückgegeben.
- Wenn das Abfrage-Caching aktiviert ist, müssen Sie zuerst die Abfrageergebnisse zwischenspeichern.
- Es sind zu viele zurückgegebene Ergebnisse vorhanden. Verwenden Sie den inkrementellen Modus für die Rückgabe.
- Beim Starten der Ausführung müssen Sie zunächst feststellen, ob Sie berechtigt sind, Abfragen für diese Tabelle T auszuführen. Wenn Wenn dies nicht der Fall ist, wird ein Fehler aufgrund fehlender Berechtigungen zurückgegeben (Wenn der Abfragecache erreicht wird, wird die Berechtigungsüberprüfung durchgeführt, wenn der Abfragecache die Ergebnisse zurückgibt. Die Abfrage ruft außerdem eine Vorprüfung auf, um die Berechtigungen vor dem Optimierer zu überprüfen.)
- Wenn Sie die Erlaubnis haben, öffnen Sie die Tabelle und fahren Sie mit der Ausführung fort. Wenn eine Tabelle geöffnet wird, verwendet der Executor die von der Engine bereitgestellte Schnittstelle basierend auf der Engine-Definition der Tabelle. Der Ausführungsablauf des Executors ist wie folgt:
- select * from test where age >
- Rufen Sie die InnoDB-Engine-Schnittstelle auf, um die erste Zeile dieser Tabelle abzurufen und festzustellen, ob der Alterswert 10 ist. Wenn nicht, überspringen Speichern Sie diese Zeile dann im Ergebnissatz.
- Rufen Sie die Engine-Schnittstelle auf, um die „nächste Zeile“ abzurufen, und wiederholen Sie die gleiche Beurteilungslogik, bis die letzte Zeile dieser Tabelle abgerufen wird.
- Der Executor gibt einen Datensatz, der aus allen Zeilen besteht, die die Bedingungen während des oben genannten Durchlaufvorgangs erfüllen, als Ergebnissatz an den Client zurück.
3. MySQL-Speicher-Engine
Die Speicher-Engine befindet sich auf der dritten Ebene der MySQL-Architektur. Sie ist für die Speicherung und Extraktion von Daten in MySQL verantwortlich Es basiert auf MySQL. Ein Dateizugriffsmechanismus, der durch die bereitgestellte abstrakte Schnittstelle der Dateizugriffsschicht angepasst wird. Dieser Mechanismus wird als Speicher-Engine bezeichnet.
Verwenden Sie den Befehl show engine, um die von der aktuellen Datenbank unterstützten Engine-Informationen anzuzeigen.

Die MyISAM-Speicher-Engine wurde standardmäßig vor Version 5.5 verwendet, und die InnoDB-Speicher-Engine wurde ab 5.5 verwendet.
- InnoDB: unterstützt Transaktionen, verfügt über Commit-, Rollback- und Crash-Recovery-Funktionen, Transaktionssicherheit;
- MyISAM: unterstützt keine Transaktionen und Fremdschlüssel, die Zugriffsgeschwindigkeit ist hoch;
- Speicher: nutzt Speicher zum Erstellen von Tabellen, die Zugriffsgeschwindigkeit ist sehr schnell, weil Die Daten befinden sich im Speicher und der Hash-Index wird standardmäßig verwendet.
- Archive: Archivtyp-Engine, unterstützt nur Insert- und Select-Anweisungen.
- Csv: Datenspeicherung In CSV-Dateien müssen aufgrund von Dateibeschränkungen alle Spalten angegeben werden, nicht null. Darüber hinaus unterstützt die CSV-Engine keine Indizes und Partitionen und ist daher für Zwischentabellen für den Datenaustausch geeignet. nur eingeben, aber nicht beenden, beim Betreten verschwinden und alle eingefügten Daten werden nicht gespeichert
- Föderiert: Kann auf Tabellen in entfernten MySQL-Datenbanken zugreifen. Eine lokale Tabelle speichert keine Daten und greift auf den Inhalt einer Remote-Tabelle zu.
- MRG_MyISAM: Eine Kombination aus einer Gruppe von MyISAM-Tabellen. Die Merge-Tabelle selbst kann auf einer Gruppe von MyISAM-Tabellen ausgeführt werden
- Transaktionen und Fremdschlüssel
InnoDB unterstützt Transaktionen und Fremdschlüssel mit Sicherheit und Integrität und ist für eine große Anzahl von Einfüge- oder Aktualisierungsvorgängen geeignet.
- MyISAM unterstützt keine Transaktionen und Fremdschlüssel, sondern bietet Hochgeschwindigkeitsspeicherung und -abruf , geeignet für eine große Anzahl ausgewählter Abfragevorgänge
- Sperrmechanismus
- InnoDB unterstützt das Sperren auf Zeilenebene und das Sperren bestimmter Datensätze. Die Sperrung erfolgt indexbasiert.
MyISAM unterstützt das Sperren auf Tabellenebene, also das Sperren der gesamten Tabelle. - Indexstruktur
- InnoDB verwendet einen Clustered-Index (Clustered-Index). Der Index und die Datensätze werden zusammen gespeichert, wobei sowohl der Index als auch die Datensätze zwischengespeichert werden.
MyISAM verwendet einen nicht gruppierten Index (nicht gruppierter Index), Index und Datensatz sind getrennt. - Funktion zur Parallelitätsverarbeitung
- MyISAM verwendet Tabellensperren, was zu einer geringen Parallelitätsrate von Schreibvorgängen, keiner Blockierung zwischen Lesevorgängen und einer Blockierung von Lese- und Schreibvorgängen führt.
InnoDB-Lese- und Schreibblockierung kann mit der Isolationsstufe in Zusammenhang stehen, und Multi-Version-Parallelitätskontrolle (MVCC) kann zur Unterstützung hoher Parallelität verwendet werden - Speicherdateien
- Die InnoDB-Tabelle entspricht zwei Dateien, einer .frm Tabellenstrukturdatei und eine .ibd-Datendatei. Die InnoDB-Tabelle unterstützt bis zu 64 TB;
MyISAM-Tabelle entspricht drei Dateien, einer .frm-Tabellenstrukturdatei, einer MYD-Tabellendatendatei und einer .MYI-Indexdatei. Ab - MySQL5.0 beträgt das Standardlimit 256 TB.
- Anwendbare Szenarien
MyISAM
Benötigt keine Transaktionsunterstützung (nicht unterstützt) - Die Parallelität ist relativ gering (Problem mit dem Sperrmechanismus)
- Die Datenänderung ist relativ gering, hauptsächlich beim Lesen
- Die Anforderungen an die Datenkonsistenz sind nicht hoch
- InnoDB
- Erfordert Transaktionsunterstützung (hat bessere Transaktionseigenschaften)
Sperren auf Zeilenebene lässt sich gut an hohe Parallelität anpassen.- Szenarien mit häufigeren Datenaktualisierungen Speicher können Sie die besseren Caching-Funktionen von InnoDB nutzen, um die Speichernutzung zu verbessern und Festplatten-IO zu reduzieren
- Zusammenfassung
- Wie wähle ich zwischen den beiden Engines?
- Benötigen Sie eine Transaktion? Ja, gibt es in InnoDB
gleichzeitige Änderungen? Ja, strebt InnoDB
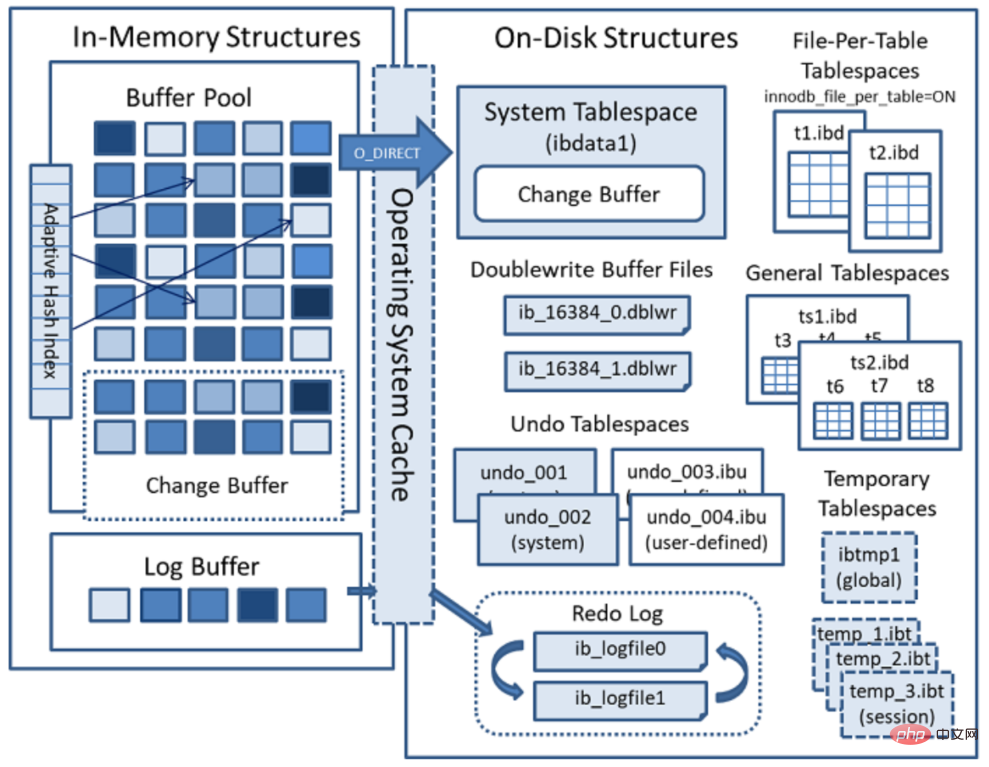
eine schnelle Abfrage und wenige Datenänderungen an? Ja, MyISAM- In den meisten Fällen wird die Verwendung der InnoDB-Speicherstruktur empfohlen. Ab MySQL-Version 5.5 wird InnoDB standardmäßig als Engine verwendet. Es ist gut in der Verarbeitung von Transaktionen und verfügt über automatische Absturzwiederherstellungsfunktionen. Das Folgende ist das offizielle Architekturdiagramm der InnoDB-Engine, das hauptsächlich in zwei Teile unterteilt ist: Speicherstruktur und Festplattenstruktur.
-
- InnoDB-Speicherstruktur
- Die Speicherstruktur umfasst hauptsächlich vier Komponenten: Pufferpool, Änderungspuffer, adaptiver Hash-Index und Protokollpuffer.
- Pufferpool: Pufferpool, als BP bezeichnet. BP basiert auf einer Seite mit einer Standardgröße von 16 KB. Die unterste Ebene von BP verwendet eine verknüpfte Listendatenstruktur zur Verwaltung von Seiten. Wenn InnoDB auf Tabellendatensätze und Indizes zugreift, werden diese auf der Seite zwischengespeichert. Eine spätere Verwendung kann den Festplatten-E/A-Vorgang reduzieren und die Effizienz verbessern.
- Seitenverwaltungsmechanismus
- Seiten können je nach Status in drei Typen unterteilt werden:
- freie Seite: inaktive Seite, nicht verwendet
- saubere Seite: verwendete Seite, Daten wurden nicht geändert
- schmutzige Seite: schmutzige Seite, Die Die Seite wird verwendet, die Daten wurden geändert und die Daten auf der Seite und auf der Festplatte sind inkonsistent.
- Für die oben genannten drei Seitentypen verwaltet und verwaltet InnoDB sie über drei verknüpfte Listenstrukturen:
- kostenlos Liste: stellt den freien Puffer dar, verwaltet freie Seiten
- Flush-Liste: gibt den Puffer an, der auf die Festplatte geleert werden muss, verwaltet schmutzige Seiten und interne Seiten werden nach Änderungszeit sortiert. Dirty Pages sind sowohl in der Flush-verknüpften Liste als auch in der LRU-verknüpften Liste vorhanden, sie beeinflussen sich jedoch nicht gegenseitig. Die LRU-verknüpfte Liste ist für die Verwaltung der Verfügbarkeit und Speicherung von Seiten verantwortlich, während die Flush-verknüpfte Liste für die Verwaltung des Flush-Vorgangs verantwortlich ist von schmutzigen Seiten.
- lru-Liste: Stellt den verwendeten Puffer dar und verwaltet saubere und schmutzige Seiten. Der Puffer wird als neuer Listenbereich bezeichnet, der 63 % der verknüpften Daten ausmacht Die Liste wird als alt bezeichnet. Der Listenbereich speichert weniger verwendete Daten und macht 37 % aus.
- Seiten können je nach Status in drei Typen unterteilt werden:
-
Verbesserte Wartung des LRU-Algorithmus
- Gewöhnliche LRU: Endeliminierungsmethode, neue Daten werden vom Kopf der verknüpften Liste hinzugefügt und am Ende entfernt, wenn Speicherplatz freigegeben wird.
- Modifizierte LRU: Die verknüpfte Liste ist in zwei Teile unterteilt, neu und alt Beim Hinzufügen von Elementen werden diese nicht vom Kopf der Liste aus eingefügt, sondern von der mittleren Position aus. Wenn schnell auf die Daten zugegriffen wird, wird die Seite zum Kopf der neuen Liste verschoben nicht aufgerufen wurde, wird es nach und nach an das Ende der alten Liste verschoben und wartet auf die Löschung.
- Immer wenn neue Seitendaten in den Pufferpool eingelesen werden, ermittelt die InnoDb-Engine, ob freie Seiten vorhanden sind und ob diese ausreichen. Wenn vorhanden, wird die freie Seite aus der freien Liste gelöscht und in die LRU-Liste eingefügt. Wenn keine freien Seiten vorhanden sind, wird die Standardseite der LRU-verknüpften Liste gemäß dem LRU-Algorithmus entfernt und der Speicherplatz wird freigegeben und neuen Seiten zugewiesen.
- Pufferpool-Konfigurationsparameter
- Variablen wie „%innodb_page_size%“ anzeigen; //Variablen wie „%innodb_old%“ anzeigen; //Alte Listenparameter in der LRU-Liste anzeigen
- Variablen anzeigen wie '%innodb_buffer%'; //Überprüfen Sie die Pufferpoolparameter
- Empfehlung: Setzen Sie innodb_buffer_pool_size auf 60 % - 80 % der Gesamtspeichergröße, innodb_buffer_pool_instances kann auf mehrere eingestellt werden, dies kann Cache-Konflikte vermeiden.
- Seitenverwaltungsmechanismus
- ChangeBuffer belegt den BufferPool-Speicherplatz und der maximal zulässige Wert beträgt 50 %. Er kann entsprechend dem Lese- und Schreibgeschäftsvolumen angepasst werden. Parameter innodb_change_buffer_max_size;
- Wenn ein Datensatz aktualisiert wird, ist der Datensatz im BufferPool vorhanden und wird direkt im BufferPool geändert, eine Speicheroperation. Wenn der Datensatz nicht im BufferPool vorhanden ist (kein Treffer), wird eine Speicheroperation direkt im ChangeBuffer ausgeführt, ohne dass die Festplatte nach Daten abgefragt werden muss und ein Festplatten-IO vermieden wird. Wenn der Datensatz das nächste Mal abgefragt wird, wird er zuerst von der Festplatte gelesen, dann werden die Informationen aus dem ChangeBuffer gelesen und zusammengeführt und schließlich in den BufferPool geladen.
- Schreibpuffer, gilt nur für nicht eindeutige normale Indexseiten
- Wenn Eindeutigkeit im Index festgelegt ist, muss InnoDB beim Vornehmen von Änderungen eine Eindeutigkeitsüberprüfung durchführen, sodass die Festplatte abgefragt und ein E/A-Vorgang ausgeführt werden muss. Der Datensatz wird direkt im BufferPool abgefragt und dann im Pufferpool geändert. Er wird nicht in ChangeBuffer bearbeitet.
- Protokollpuffer: Der Protokollpuffer wird zum Speichern der in die Protokolldatei (Wiederherstellen/Rückgängigmachen) zu schreibenden Daten auf der Festplatte verwendet. Der Inhalt des Protokollpuffers wird regelmäßig in der Protokolldatei der Festplatte aktualisiert. Wenn der Protokollpuffer voll ist, wird er automatisch auf die Festplatte geleert. Bei großen Transaktionsvorgängen wie BLOB oder mehrzeiligen Aktualisierungen kann eine Vergrößerung des Protokollpuffers Festplatten-E/A einsparen.
- LogBuffer wird hauptsächlich zum Aufzeichnen von InnoDB-Engine-Protokollen verwendet, die während DML-Vorgängen generiert werden.
- Wenn der LogBuffer-Speicherplatz voll ist, wird er automatisch auf die Festplatte geschrieben.Sie können die Festplatten-IO-Häufigkeit reduzieren, indem Sie den Parameter innodb_log_buffer_size erhöhen; der Parameter
- innodb_flush_log_at_trx_commit steuert das Protokollaktualisierungsverhalten, der Standardwert ist 1
- 0: Protokolldateien schreiben und Festplattenvorgänge alle 1 Sekunde leeren (Protokolldatei LogBuffer schreiben --> Betriebssystem-Cache, OScache leeren -> Festplattendatei), Daten gehen bis zu 1 Sekunde lang verloren
- 1: Transaktionsübermittlung, Protokolldatei schreiben und Festplatte sofort leeren, Daten gehen nicht verloren, es treten jedoch häufige E/A-Vorgänge auf
- 2: Transaktionsübermittlung, sofort Protokolldateien schreiben und alle 1 Sekunde Festplatten-Flush-Vorgänge durchführen.
Tablespaces: werden zum Speichern von Tabellenstrukturen und Daten verwendet. Tabellenbereiche sind in Systemtabellenbereiche, unabhängige Tabellenbereiche, allgemeine Tabellenbereiche, temporäre Tabellenbereiche, Undo-Tabellenbereiche und andere Typen unterteilt. Der Systemtabellenbereich (der Systemtabellenbereich)
CREATE TABLESPACE ts1 ADD DATAFILE ts1.ibd Engine=InnoDB; //创建表空 间ts1 CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1; //将表添加到ts1 表空间
-
Unabhängiger Tablespace (Datei-pro-Tabelle-Tablespaces)
- ist standardmäßig ein einzelner Tabellen-Tablespace, der in einer eigenen Datendatei erstellt wird der Tischfläche. Wenn die Option innodb_file_per_table aktiviert ist, werden Tabellen im Tablespace erstellt. Andernfalls wird innodb im Systemtabellenbereich erstellt. Jeder Tabellenbereich wird durch eine .ibd-Datendatei dargestellt, die standardmäßig im Datenbankverzeichnis erstellt wird. Tabellenbereichstabellendateien unterstützen dynamische und komprimierte Zeilenformate.
- Allgemeine Tablespaces
-
- Undo-Tablespaces
- Der von InnoDB verwendete Undo-Tablespace wird durch die Konfigurationsoption innodb_undo_tablespaces gesteuert, die standardmäßig auf 0 steht. Ein Parameterwert von 0 bedeutet die Verwendung des Systemtabellenbereichs ibdata1; ein Parameterwert größer als 0 bedeutet die Verwendung der Undo-Tabellenbereiche undo_001, undo_002 usw.
- Temporäre Tabellenbereiche
- werden in zwei Typen unterteilt: temporäre Sitzungstabellenbereiche und globale temporäre Tabellenbereiche: Temporäre Sitzungstabellenbereiche speichern von Benutzern erstellte temporäre Tabellen und temporäre Tabellen auf der Festplatte.
- Globaler temporärer Tablespace speichert Rollback-Segmente temporärer Benutzertabellen (Rollback-Segmente). Wenn der MySQL-Server normal heruntergefahren oder abnormal beendet wird, wird der temporäre Tabellenbereich bei jedem Start entfernt und neu erstellt.
-
- Data Dictionary (InnoDB Data Dictionary)
- InnoDB Data Dictionary besteht aus internen Systemtabellen, die Metadaten für Objekte wie Nachschlagetabellen, Indizes und Tabellenfelder enthalten. Metadaten befinden sich physisch im Tablespace des InnoDB-Systems. Aus historischen Gründen überschneiden sich die Metadaten des Datenwörterbuchs bis zu einem gewissen Grad mit den in InnoDB-Tabellenmetadatendateien (.frm-Dateien) gespeicherten Informationen.
Doublewrite Buffer
- ist standardmäßig ein einzelner Tabellen-Tablespace, der in einer eigenen Datendatei erstellt wird der Tischfläche. Wenn die Option innodb_file_per_table aktiviert ist, werden Tabellen im Tablespace erstellt. Andernfalls wird innodb im Systemtabellenbereich erstellt. Jeder Tabellenbereich wird durch eine .ibd-Datendatei dargestellt, die standardmäßig im Datenbankverzeichnis erstellt wird. Tabellenbereichstabellendateien unterstützen dynamische und komprimierte Zeilenformate.
- Der innodb_flush_method-Parameter von MySQL steuert den Öffnungs- und Löschmodus von innodb-Datendateien und Redo-Protokollen. Es gibt drei Werte: fdatasync (Standard), O_DSYNC, O_DIRECT. Das Festlegen von O_DIRECT bedeutet, dass der Datendatei-Schreibvorgang das Betriebssystem benachrichtigt, die Daten nicht zwischenzuspeichern, kein Vorlesen zu verwenden und direkt von InnodbBuffer in die Festplattendatei zu schreiben. Der Standardwert von fdatasync bedeutet, dass zuerst in den Cache des Betriebssystems geschrieben und dann die Funktion fsync() aufgerufen wird, um die Cache-Informationen der Datendatei und des Redo-Protokolls asynchron zu leeren.
-
Redo-Log
- Das Redo-Log ist eine festplattenbasierte Datenstruktur, die zur Korrektur von Daten verwendet wird, die durch unvollständige Transaktionen während der Wiederherstellung nach einem Absturz geschrieben wurden. MySQL schreibt Redo-Log-Dateien zirkulär und zeichnet alle Änderungen am Pufferpool in InnoDB auf. Wenn ein Instanzfehler auftritt (z. B. ein Stromausfall) und die Daten nicht in der Datendatei aktualisiert werden können, muss die Datenbank beim Neustart erneut erstellt werden, um die Daten erneut in der Datendatei zu aktualisieren. Während der Ausführung von Lese- und Schreibtransaktionen werden weiterhin Redo-Logs generiert. Standardmäßig wird das Redo-Log physisch auf der Festplatte durch zwei Dateien mit den Namen ib_logfile0 und ib_logfile1 dargestellt.
-
Rückgängig-Protokolle
- Rückgängig-Protokolle sind Sicherungen geänderter Daten, die vor dem Start einer Transaktion gespeichert werden und dazu dienen, Transaktionen in Ausnahmefällen rückgängig zu machen. Das Rückgängig-Protokoll ist ein logisches Protokoll und wird zeilenweise aufgezeichnet. Undo-Protokolle sind in System-Tablespaces, Undo-Tablespaces und temporären Tablespaces vorhanden.
Entwicklung der neuen Versionsstruktur
- MySQL 5.7-Version
- trennt den Undo-Log-Tabellenbereich von der ibdata-Datei des gemeinsam genutzten Tabellenbereichs, und der Benutzer kann die Dateigröße und -menge bei der Installation von MySQL angeben.
- Temporärer Tabellenbereich hinzugefügt, der Daten von temporären Tabellen oder temporären Abfrageergebnissätzen speichert.
- Die Größe des Pufferpools kann dynamisch geändert werden, ohne die Datenbankinstanz neu zu starten.
- MySQL 8.0-Version
- trennt das Datenwörterbuch und das Rückgängigmachen der InnoDB-Tabelle vollständig vom gemeinsam genutzten Tabellenbereich ibdata. In der Vergangenheit musste das Datenwörterbuch in ibdata mit dem Datenwörterbuch im unabhängigen Tabellenbereich ibd konsistent sein Datei. Version 8.0 Es ist nicht notwendig.
- Temporärer temporärer Tabellenbereich kann auch mit mehreren physischen Dateien konfiguriert werden. Sie sind alle InnoDB-Speicher-Engines und können Indizes erstellen, was die Verarbeitung beschleunigt.
- Benutzer können einige Tabellenbereiche wie eine Oracle-Datenbank einrichten. Jeder Tabellenbereich kann von mehreren Tabellen verwendet werden, eine Tabelle kann jedoch nur in einem Tabellenbereich gespeichert werden.
- Der Doublewrite Buffer ist auch vom gemeinsam genutzten Tabellenbereich ibdata getrennt.
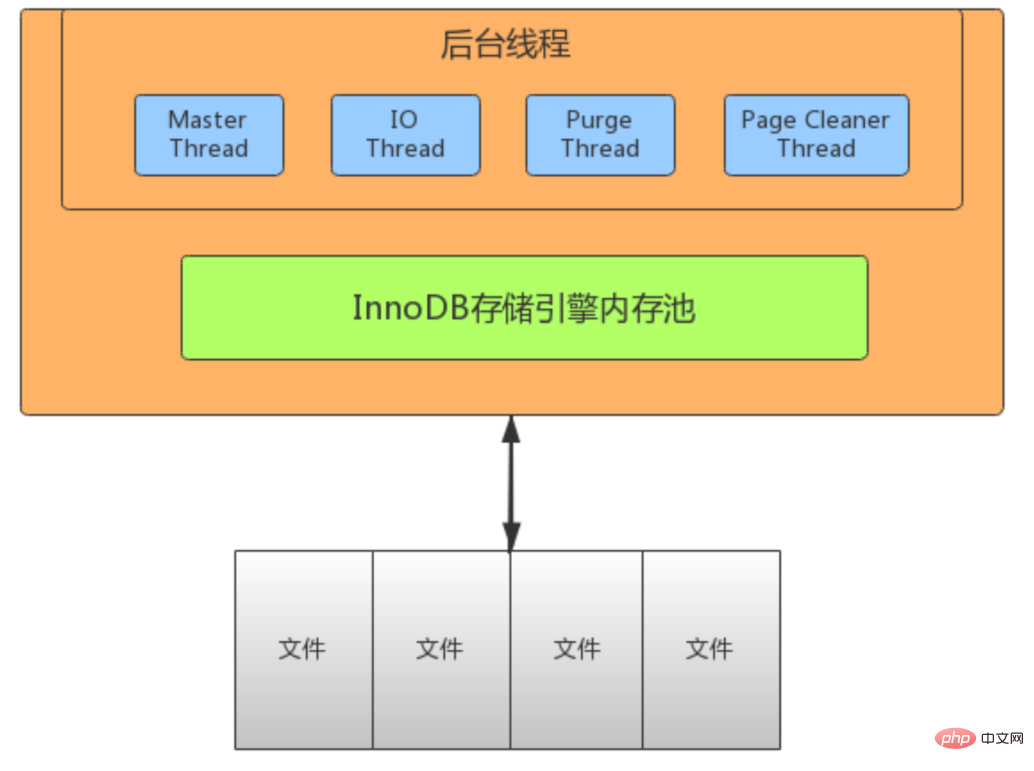
InnoDB-Thread-Modell
- IO Thread
- verwendet eine große Menge AIO (Async IO) in InnoDB für die Lese- und Schreibverarbeitung, was die Leistung der Datenbank erheblich verbessern kann. Es gibt 10 E/A-Threads in InnoDB, darunter 4 Schreibvorgänge, 4 Lesevorgänge, 1 Einfügepuffer und 1 Protokollthread.
- Thread lesen: Verantwortlich für Lesevorgänge und das Laden von Daten von der Festplatte auf die Cache-Seite. 4
- Schreibthreads: Verantwortlich für Schreibvorgänge und das Leeren zwischengespeicherter schmutziger Seiten auf die Festplatte. 4
- Protokollthreads: Verantwortlich für das Leeren des Protokollpufferinhalts auf die Festplatte. 1
- Puffer-Thread einfügen: Verantwortlich für das Leeren des Schreibpufferinhalts auf die Festplatte. Nachdem eine
Purge Thread - verwendet eine große Menge AIO (Async IO) in InnoDB für die Lese- und Schreibverarbeitung, was die Leistung der Datenbank erheblich verbessern kann. Es gibt 10 E/A-Threads in InnoDB, darunter 4 Schreibvorgänge, 4 Lesevorgänge, 1 Einfügepuffer und 1 Protokollthread.
- -Transaktion festgeschrieben wurde, wird das von ihr verwendete Rückgängig-Protokoll nicht mehr benötigt, sodass Purge Thread die zugewiesenen Rückgängig-Seiten wiederverwenden muss.
- Variablen wie „%innodb_purge_threads%“ anzeigen;
Page Cleaner Thread- Die Funktion besteht darin, die schmutzigen Daten auf die Festplatte zu leeren. Nachdem die schmutzigen Daten geleert wurden, kann das entsprechende Redo-Protokoll überschrieben werden Die Daten können synchronisiert und
- den Zweck des Redo-Log-Recyclings erreichen. Die Thread-Verarbeitung des Schreibthreads wird aufgerufen.
Variablen wie „%innodb_page_cleaners%“ anzeigen;
Master-Thread- den Zweck des Redo-Log-Recyclings erreichen. Die Thread-Verarbeitung des Schreibthreads wird aufgerufen.
-
- Master-Thread ist der Haupt-Thread von InnoDB, verantwortlich für die Planung anderer Threads, mit der höchsten Priorität. Seine Funktion besteht darin, die Daten im Pufferpool asynchron auf der Festplatte zu aktualisieren, um die Datenkonsistenz sicherzustellen. Einschließlich: Aktualisierung schmutziger Seiten (Seitenbereinigungsthread), Rückgängigmachen des Seitenrecyclings (Purge-Thread), Redo-Log-Aktualisierung (Log-Thread), zusammengeführter Schreibpuffer usw. Es gibt zwei Hauptprozesse im Inneren, einen alle 1 Sekunde und einen alle 10 Sekunden.
- Vorgänge alle 1 Sekunde:
- Aktualisieren Sie den Protokollpuffer und leeren Sie ihn auf die Festplatte.
- Fügen Sie Schreibpufferdaten zusammen. Entscheiden Sie, ob der Vorgang basierend auf dem E/A-Lese- und Schreibdruck ausgeführt werden soll.
- Aktualisieren Sie fehlerhafte Seitendaten auf der Festplatte, basierend auf dem Verhältnis der fehlerhaften Seiten Erreichen von 75 % nur Vorgang (innodb_max_dirty_pages_pct,
- innodb_io_capacity)
Vorgang alle 10 Sekunden: -
- Verschmutzte Seitendaten auf Festplatte aktualisieren
- Schreibpufferdaten zusammenführen
- Protokollpuffer aktualisieren
- Unbrauchbar löschen. Rückgängig machen Seiten
-
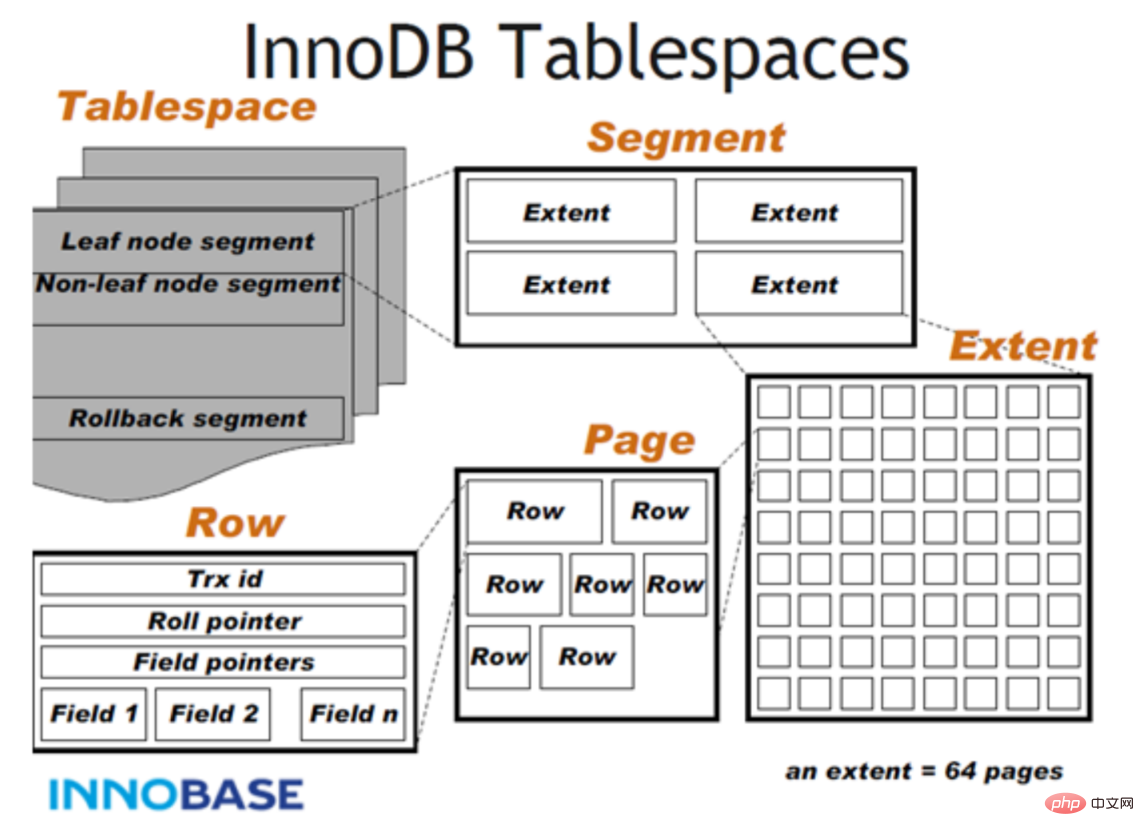
InnoDB-Datendateispeicherstruktur
-
分为 ibd数据文件 --> Segment(段)–>Extent(区)–> Page(页)–>Row(行)
- Tablesapce表空间,用于存储多个ibd数据文件,用于存储表的记录和索引。一个文件包含多个段。
- Segment段,用于管理多个Extent,分为数据段(Leaf node segment)、索引段(Non-leaf node
segment)、回滚段(Rollback segment)。一个表至少会有两个segment,一个管理数据,一个管理索引。每多创建一个索引,会多两个segment。 - Extent区,一个区固定包含64个连续的页,大小为1M。当表空间不足,需要分配新的页资源,不会
一页一页分,直接分配一个区。 - Page页,用于存储多个Row行记录,大小为16K。包含很多种页类型,比如数据页,undo页,系统页,事务数据页,大的BLOB对象页。
- Row行,包含了记录的字段值,事务ID(Trx id)、滚动指针(Roll pointer)、字段指针(Field
pointers)等信息。
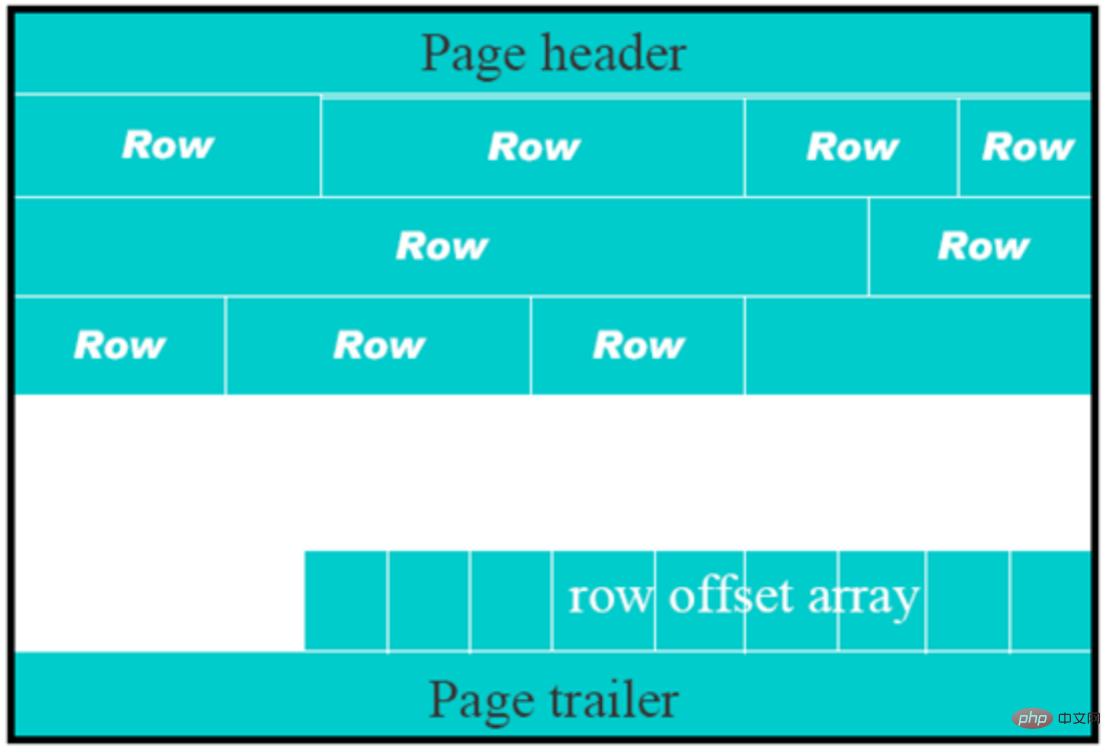
Page是文件最基本的单位,无论何种类型的page,都是由page header,page trailer和page body组成。如下图所示
-
分为 ibd数据文件 --> Segment(段)–>Extent(区)–> Page(页)–>Row(行)
-
InnoDB文件存储格式
-
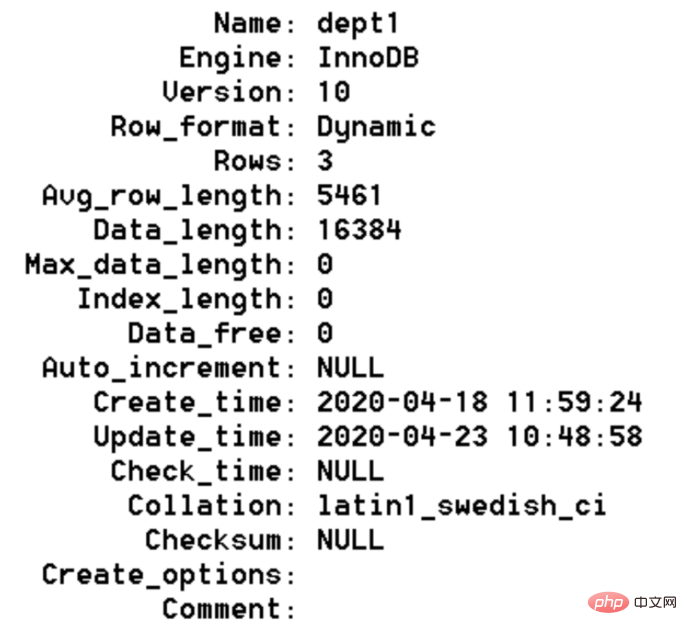
通过 SHOW TABLE STATUS 命令 查看
一般情况下,如果row_format为REDUNDANT、COMPACT,文件格式为Antelope;如果row_format为DYNAMIC和COMPRESSED,文件格式为Barracuda。
-
通过 information_schema 查看指定表的文件格式
select * from information_schema.innodb_sys_tables;
-
-
File文件格式(File-Format)
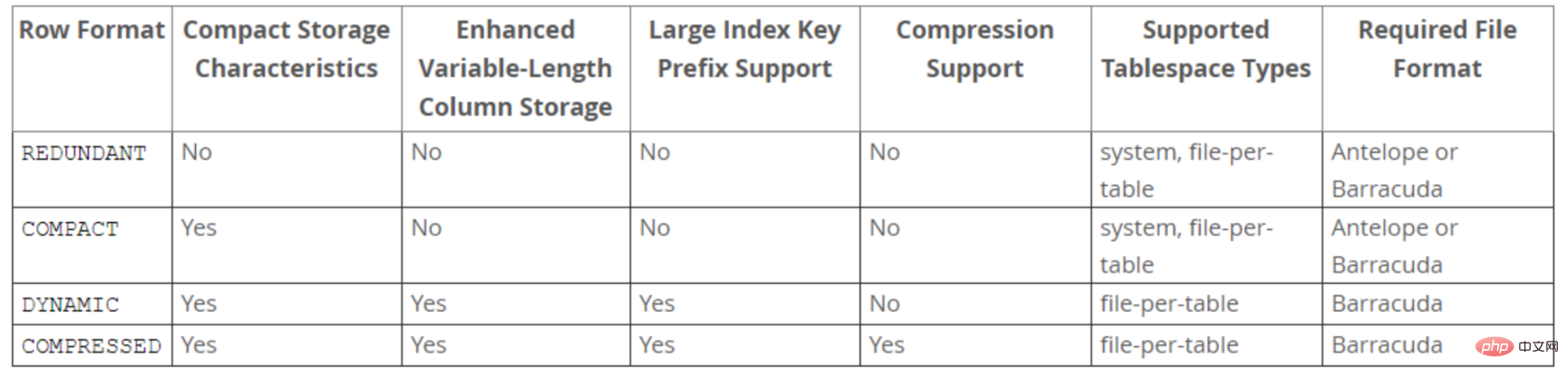
- 在早期的InnoDB版本中,文件格式只有一种,随着InnoDB引擎的发展,出现了新文件格式,用于支持新的功能。目前InnoDB只支持两种文件格式:Antelope 和 Barracuda。
- Antelope: 先前未命名的,最原始的InnoDB文件格式,它支持两种行格式:COMPACT和REDUNDANT,MySQL 5.6及其以前版本默认格式为Antelope。
- Barracuda: 新的文件格式。它支持InnoDB的所有行格式,包括新的行格式:COMPRESSED和 DYNAMIC。
- 通过innodb_file_format 配置参数可以设置InnoDB文件格式,之前默认值为Antelope,5.7版本开始改为Barracuda。
- 在早期的InnoDB版本中,文件格式只有一种,随着InnoDB引擎的发展,出现了新文件格式,用于支持新的功能。目前InnoDB只支持两种文件格式:Antelope 和 Barracuda。
Row行格式(Row_format)
表的行格式决定了它的行是如何物理存储的,这反过来又会影响查询和DML操作的性能。如果在单个page页中容纳更多行,查询和索引查找可以更快地工作,缓冲池中所需的内存更少,写入更新时所需的I/O更少。
InnoDB存储引擎支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
DYNAMIC和COMPRESSED新格式引入的功能有:数据压缩、增强型长列数据的页外存储和大索引前缀。
每个表的数据分成若干页来存储,每个页中采用B树结构存储;
-
如果某些字段信息过长,无法存储在B树节点中,这时候会被单独分配空间,此时被称为溢出页,该字段被称为页外列。
- REDUNDANT 行格式
- 使用REDUNDANT行格式,表会将变长列值的前768字节存储在B树节点的索引记录中,其余
的存储在溢出页上。对于大于等于786字节的固定长度字段InnoDB会转换为变长字段,以便
能够在页外存储。
- 使用REDUNDANT行格式,表会将变长列值的前768字节存储在B树节点的索引记录中,其余
- COMPACT 行格式
- 与REDUNDANT行格式相比,COMPACT行格式减少了约20%的行存储空间,但代价是增加了
某些操作的CPU使用量。如果系统负载是受缓存命中率和磁盘速度限制,那么COMPACT格式
可能更快。如果系统负载受到CPU速度的限制,那么COMPACT格式可能会慢一些。
- 与REDUNDANT行格式相比,COMPACT行格式减少了约20%的行存储空间,但代价是增加了
- DYNAMIC 行格式
- 使用DYNAMIC行格式,InnoDB会将表中长可变长度的列值完全存储在页外,而索引记录只包含指向溢出页的20字节指针。大于或等于768字节的固定长度字段编码为可变长度字段。DYNAMIC行格式支持大索引前缀,最多可以为3072字节,可通过innodb_large_prefix参数控制。
- COMPRESSED 行格式
- COMPRESSED行格式提供与DYNAMIC行格式相同的存储特性和功能,但增加了对表和索引
数据压缩的支持。
- COMPRESSED行格式提供与DYNAMIC行格式相同的存储特性和功能,但增加了对表和索引
- REDUNDANT 行格式
-
在创建表和索引时,文件格式都被用于每个InnoDB表数据文件(其名称与*.ibd匹配)。修改文件格式的方法是重新创建表及其索引,最简单方法是对要修改的每个表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT=格式类型;
Undo Log
Undo Log介绍
Undo:意为撤销或取消,以撤销操作为目的,返回指定某个状态的操作。
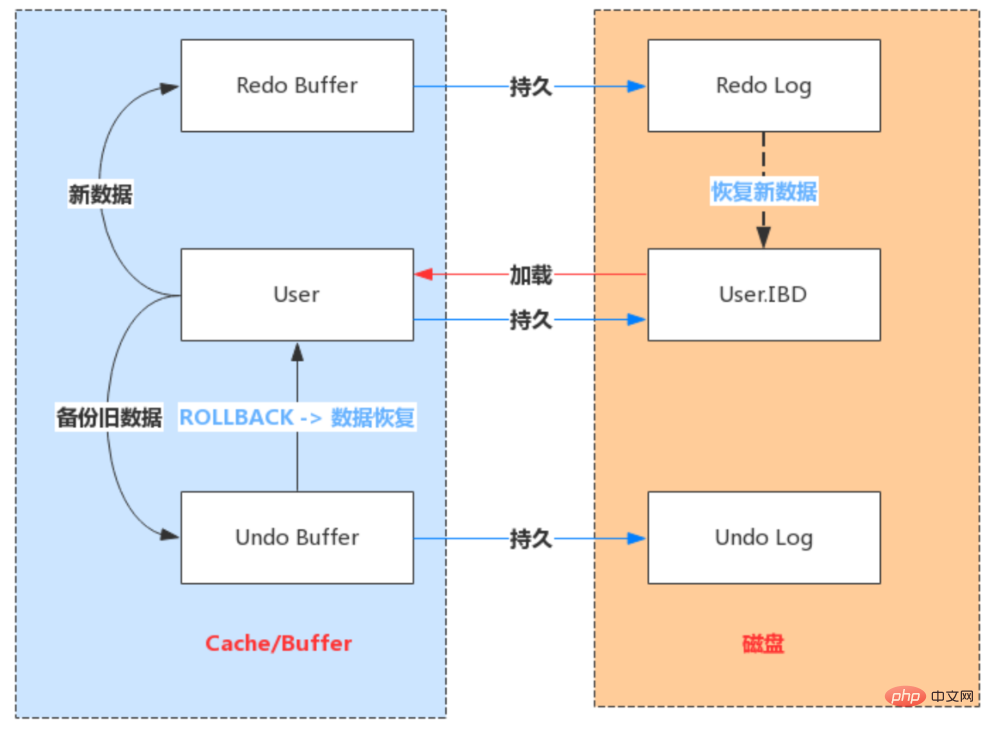
Undo Log:数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响。
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
Undo Log存储:undo log采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。可以通过下面一组参数来控制Undo log存储。
#相关参数命令 show variables like '%innodb_undo%';
Undo Log作用
- 实现事务的原子性
- Undo Log 是为了实现事务的原子性而出现的产物。事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。
-
实现多版本并发控制(MVCC)
Undo Log 在 MySQL InnoDB 存储引擎中用来实现多版本并发控制。事务未提交之前,Undo Log保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。
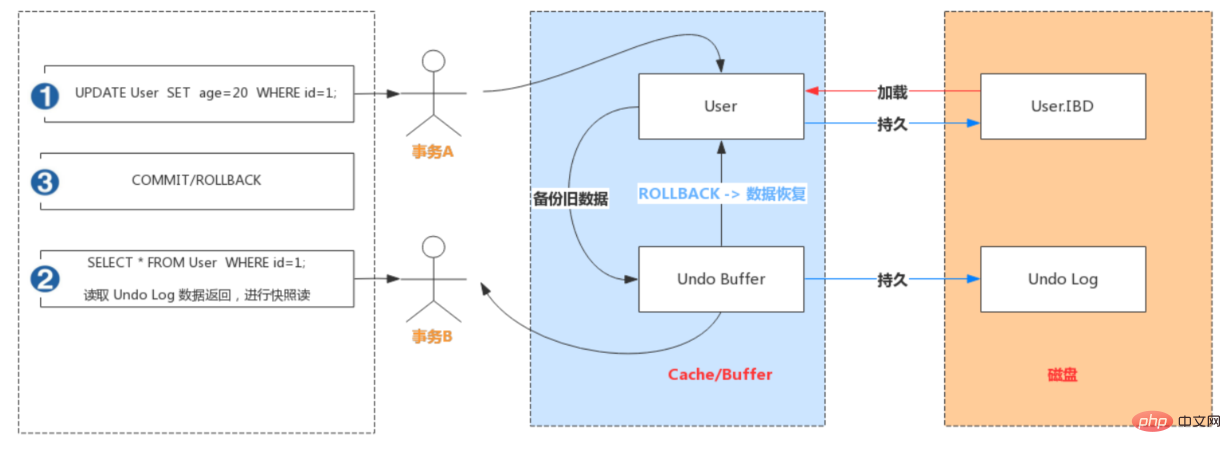
- 事务A手动开启事务,执行更新操作,首先会把更新命中的数据备份到 Undo Buffer 中;
事务B手动开启事务,执行查询操作,会读取 Undo 日志数据返回,进行快照读;
Redo Log 和 Binlog
Redo Log 日志
-
Redo Log 介绍
- Redo:顾名思义就是重做。以恢复操作为目的,在数据库发生意外时重现操作。
- Redo Log:指事务中修改的任何数据,将最新的数据备份存储的位置(Redo Log),被称为重做日志。
- Redo Log 的生成和释放:随着事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer,并不是随着事务的提交就立刻写入磁盘文件。等事务操作的脏页写入到磁盘之后,Redo Log 的使命也就完成了,Redo Log占用的空间就可以重用(被覆盖写入)。
Redo Log工作原理
- Redo Log 是为了实现事务的持久性而出现的产物。防止在发生故障的时间点,尚有脏页未写入表
的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘
数据进行持久化这一特性。
-
Redo Log写入机制
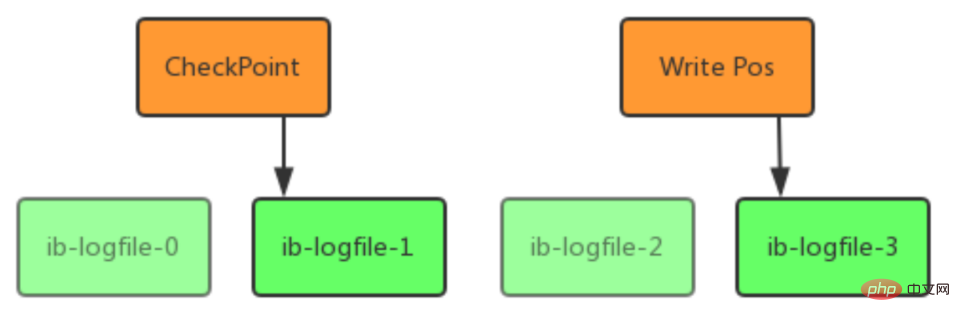
Redo Log 文件内容是以顺序循环的方式写入文件,写满时则回溯到第一个文件,进行覆盖写。
- write pos 是当前记录的位置,一边写一边后移,写到最后一个文件末尾后就回到 0 号文件开头;
- checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件;
- write pos 和 checkpoint 之间还空着的部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示写满,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint推进一下。
-
Redo Log相关配置参数
-
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,默认为ib_logfile0和ib_logfile1。可以通过下面一组参数控制Redo Log存储:
show variables like '%innodb_log%';
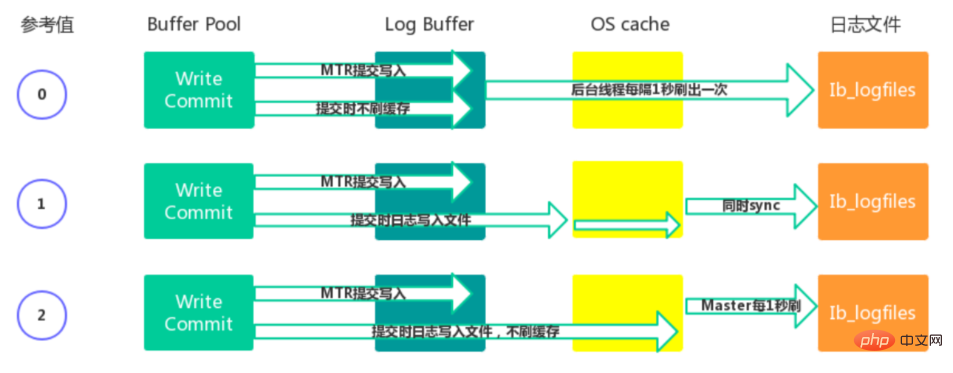
Redo Buffer 持久化到 Redo Log 的策略,可通过 Innodb_flush_log_at_trx_commit 设置:
-
- 0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔 1秒执行一次操作。
- 1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
- 2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache -> flush cache to disk 的操作。
- 一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数
据。
Binlog日志
-
Binlog 记录模式
- Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过mysqlbinlog工具来恢复数据。
- Binlog文件名默认为“主机名_binlog-序列号”格式,例如oak_binlog-000001,也可以在配置文件中指定名称。文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
- ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
- 优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
- 缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。
- STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
- 优点:日志量小,减少磁盘IO,提升存储和恢复速度
- 缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。
- MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
- ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
- Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
-
Binlog 文件结构
- MySQL的binlog文件中记录的是对数据库的各种修改操作,用来表示修改操作的数据结构是Log event。不同的修改操作对应的不同的log event。比较常用的log event有:Query event、Row event、Xid event等。binlog文件的内容就是各种Log event的集合。
Binlog文件中Log event结构如下图所示:
-
Binlog写入机制
- 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
- 不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在binlog文件中是连续的,中间不会插入其他事务的log event。
-
Binlog文件操作
- 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
- 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区
- Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
- 事务在提交阶段会将产生的log event写入到外部binlog文件中。
- 不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在
binlog文件中是连续的,中间不会插入其他事务的log event。
-
Binlog文件操作
-
Binlog状态查看
show variables like 'log_bin';
-
开启Binlog功能
set global log_bin = mysqllogbin; ERROR 1238 (HY000): Variable 'log_bin' is a read only variable
需要修改my.cnf或my.ini配置文件,在[mysqld]下面增加log_bin=mysql_bin_log,重启MySQL服务。
#log-bin=ON #log-bin-basename=mysqlbinlog binlog-format=ROW log-bin=mysqlbinlog
-
使用show binlog events命令
show binary logs; //等价于show master logs; show master status; show binlog events; show binlog events in 'mysqlbinlog.000001';
-
使用 mysqlbinlog 命令
mysqlbinlog "文件名" mysqlbinlog "文件名" > "test.sql"
-
使用 binlog 恢复数据
//按指定时间恢复 mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stop- datetime="2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234 //按事件位置号恢复 mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002 | mysql -uroot -p1234
mysqldump:定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
-
删除Binlog文件
purge binary logs to 'mysqlbinlog.000001'; //删除指定文件 purge binary logs before '2020-04-28 00:00:00'; //删除指定时间之前的文件 reset master; //清除所有文件
可以通过设置expire_logs_days参数来启动自动清理功能。默认值为0表示没启用。设置为1表示超出1天binlog文件会自动删除掉。
-
-
Redo Log和 Binlog区别
- Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
- Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
- Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用。
- Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash-safe能力。
推荐学习:mysql视频教程
-
- Protokolldatei


Das obige ist der detaillierte Inhalt vonDetaillierte grafische Erläuterung der MySQL-Architekturprinzipien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So legen Sie die absteigende Reihenfolge in einer MySQL-Abfrage fest
- So fragen Sie Fremdschlüsseleinschränkungen in MySQL ab
- So fragen Sie MySQL-Benutzer unter Linux ab
- Was soll ich tun, wenn die sich selbst erhöhende ID von MySQL nicht kontinuierlich ist?
- So fragen Sie den aktuell angemeldeten Benutzer in MySQL ab