
Heim >Backend-Entwicklung >Python-Tutorial >Python-Datenanalyse: Pandas verarbeitet Excel-Tabellen
Python-Datenanalyse: Pandas verarbeitet Excel-Tabellen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-05-13 13:39:224203Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Python. Er stellt hauptsächlich einige Themen zu den Grundlagen der Datenanalyse vor, einschließlich des Lesens anderer Dateien, Pivot-Tabellen und anderer verwandter Inhalte. Ich hoffe, er ist für alle hilfreich. Empfohlenes Lernen: Python-Video-Tutorial Dateitypen verwenden dieselbe Methode, nämlich pd.read_csv(file). Beim Lesen einer Excel-Tabelle müssen Sie auf das Trennzeichen achten und zum Trennen den Parameter sep='' verwenden. Schauen wir uns als Nächstes an, wie man es in Excel und Pandas bedient!
 1. Excel liest andere Dateien
1. Excel liest andere Dateien
Externe Daten aus Excel importieren
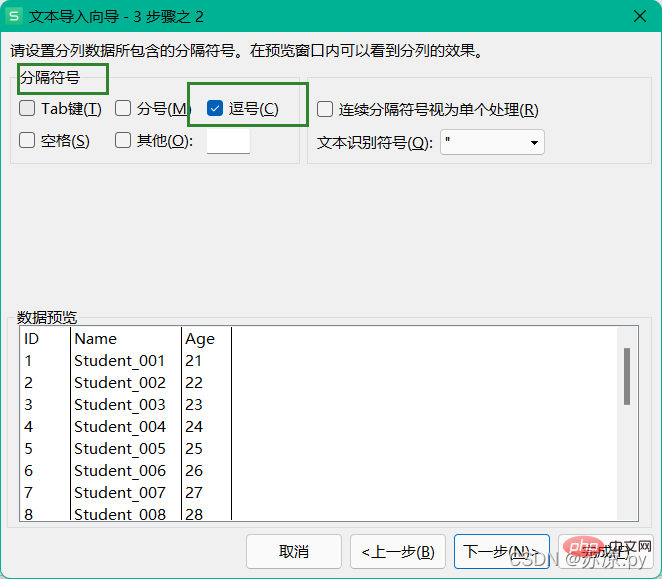
1.1 CSV-Dateien importieren1.2 TSV-Datei importierenWählen Sie beim Importieren von CSV-Dateien einfach Komma als Trennzeichen.
TSV-Datei importieren, Tabulatortaste als Trennzeichen wählen

1.3 TXT-Textdatei importieren
Achten Sie beim Importieren einer TXT-Datei auf was Symbole verwendet werden Um den Text zu trennen, benutzerdefiniertes Trennzeichen.
2.pandas liest andere Dateien
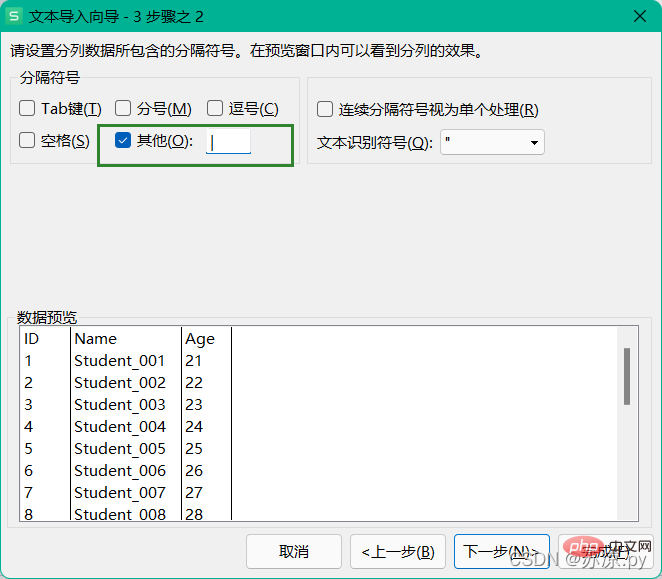
In Pandas wird das Lesen unabhängig davon, ob CSV-Dateien, TSV-Dateien oder TXT-Dateien gelesen werden, mit der Methode read_csv() und dem Parameter sep() zum Trennen gelesen.
2.1 CSV-Datei lesen 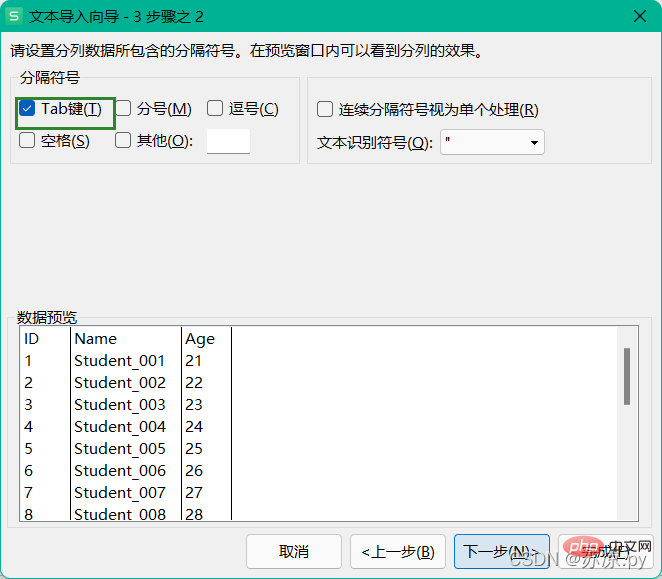
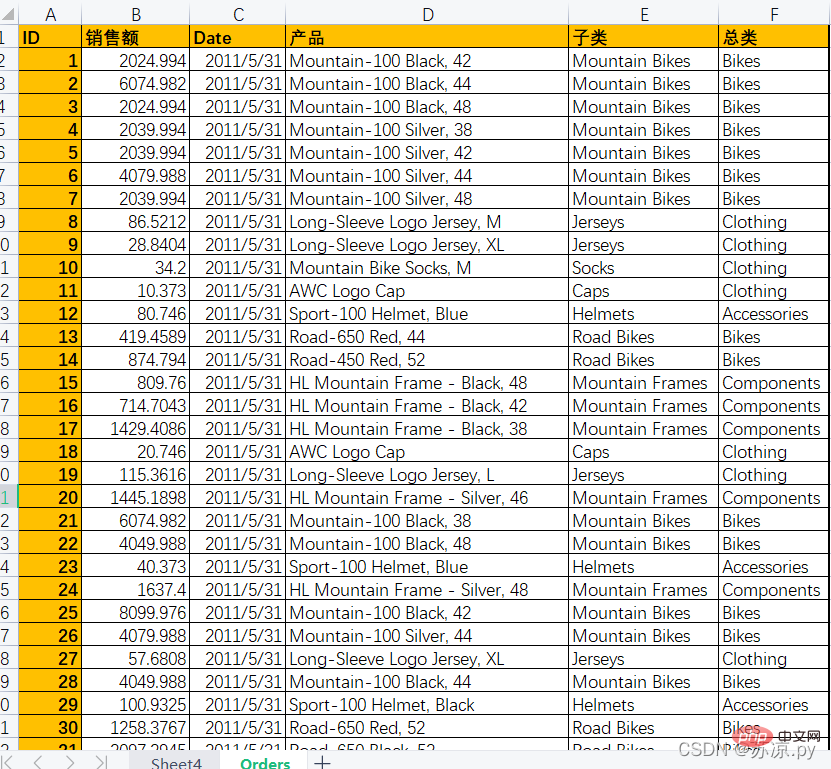
Es gibt viele Arten von Daten in Excel und sie sind in viele Typen unterteilt. Derzeit ist die Verwendung der Pivot-Tabelle sehr praktisch und intuitiv, um die verschiedenen gewünschten Daten zu analysieren. Beispiel: Tragen Sie die folgenden Daten in eine Pivot-Tabelle ein und zeichnen Sie die Jahresverkäufe nach allgemeinen Kategorien auf!
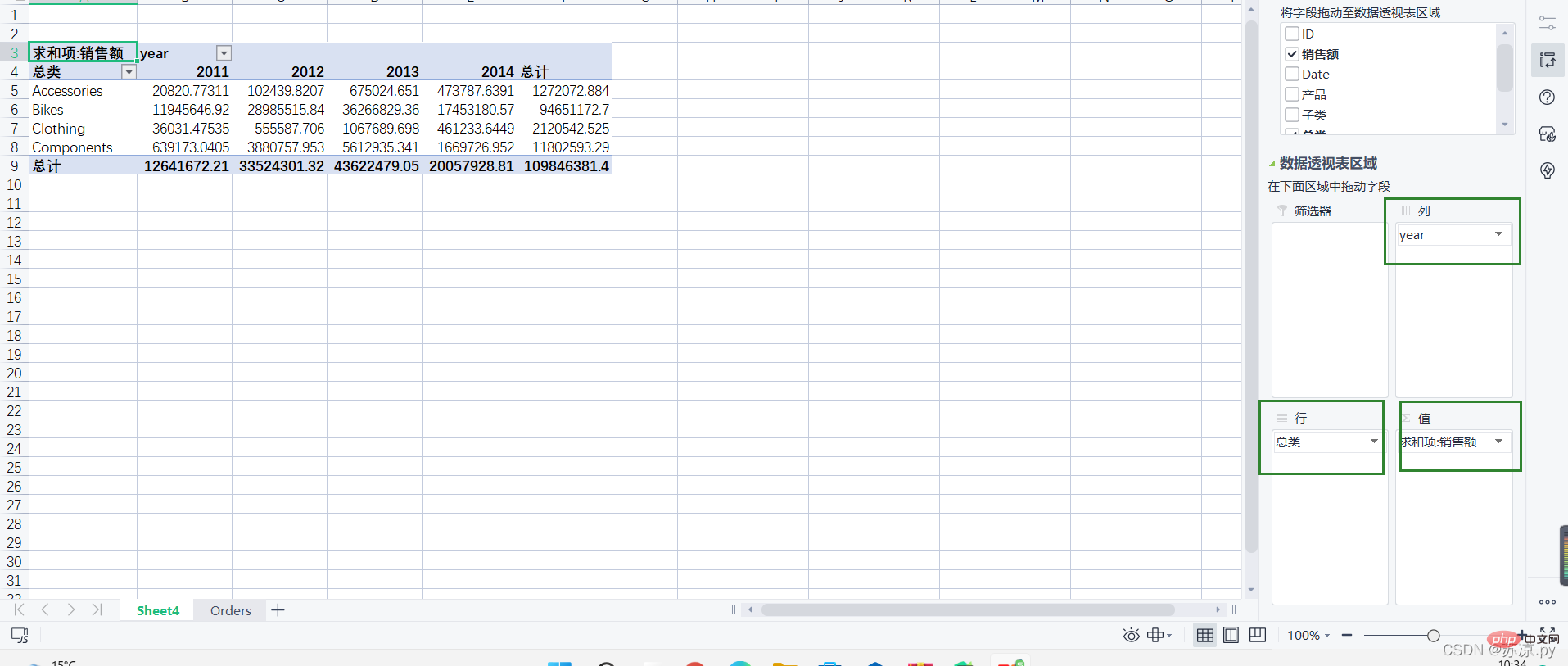
1. Beim Erstellen einer Pivot-Tabelle in Excel
müssen wir nach Jahr teilen, dann müssen wir die Datumsspalte aufteilen und das Jahr aufteilen. Wählen Sie dann die PivotTable unter der Datenspalte aus und wählen Sie den Bereich aus.
Ziehen Sie dann jeden Teil der Daten in jeden Bereich.
Damit ist die Erstellung der Pivot-Tabelle in Excel abgeschlossen. Wie erreicht man diesen Effekt bei Pandas?Ergebnis:
2. Zeichnen Sie eine Pivot-Tabelle in Pandas 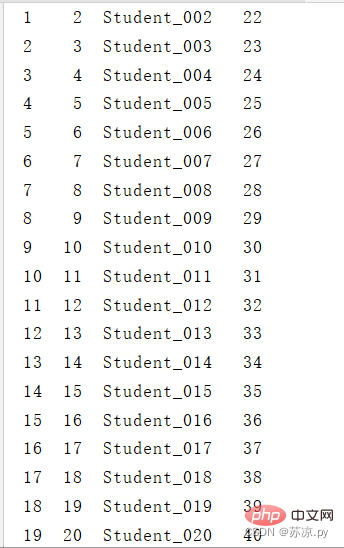
Die Funktion zum Zeichnen einer Pivot-Tabelle lautet: df.pivot_lable(Index, Spalten, Werte) und schließlich die Daten summieren.
import pandas as pd # 导入csv文件 test1 = pd.read_csv('./excel/test12.csv',index_col="ID") df1 = pd.DataFrame(test1) print(df1)Ergebnis:
Darüber hinaus können Sie auch die Groupby-Funktion verwenden, um die Datentabelle zu zeichnen. Hier werden die Gesamtkategorie und das Jahr gruppiert, um den Gesamtumsatz und die Verkaufsmenge zu berechnen.
import pandas as pd
# 导入tsv文件
test3 = pd.read_csv("./excel/test11.tsv",sep='\t')
df3 = pd.DataFrame(test3)
print(df3)
Ergebnis:
Empfohlenes Lernen:
Python-Video-Tutorial
Das obige ist der detaillierte Inhalt vonPython-Datenanalyse: Pandas verarbeitet Excel-Tabellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!