
Heim >Datenbank >MySQL-Tutorial >Führt Sie durch den MySQL-Index
Führt Sie durch den MySQL-Index

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-04-22 11:48:382608Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL. Er stellt hauptsächlich einige Probleme in der erweiterten Version von MySQL vor, einschließlich der Frage, was ein Index ist, die zugrunde liegende Implementierung des Index usw. Schauen wir uns das hoffentlich gemeinsam an wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
MySQL, ein vertrauter und unbekannter Begriff, als wir Javaweb lernten, verwendeten wir zu diesem Zeitpunkt MySQL Ein gutes Tool zum Speichern von Daten. Beim Abfragen handelt es sich auch um eine blinde vollständige Tabellenabfrage (ohne ein wenig Optimierung).
Wir täuschen uns immer selbst und denken, dass wir durch andere Aspekte optimieren können. Wir zögern, uns mit „MySQL Advanced“ auseinanderzusetzen, und lernen stattdessen etwas, das „fortgeschrittener“ zu sein scheint. Lernen Sie Redis und teilen Sie den Druck von MySQL. Lernen Sie Middleware wie MyCat und implementieren Sie Master-Slave-Replikation, Lese-Schreib-Trennung, Unterdatenbank und Untertabelle usw. (Ich spreche von Melo, das ist richtig)
Als ich mich auf das Interview vorbereitete, stellte ich fest, dass ich in den Interviewfragen nicht alle Fragen zu MySQL kannte~
Und über die hochmoderne Middleware, die ich gelernt, ich habe nur sehr wenige Fragen gestellt! ! Ich weiß nur, wie man es verwendet. Beim Schreiben meines Lebenslaufs kann ich nur schwach schreiben, wie man die xxx-Middleware versteht Optimierung ist sehr wichtig, nachdem Sie Serverausfälle erlebt haben, können Sie nur stillschweigend...
Beginnen Sie jetzt, es ist noch zu spät, um an Land zu gehen! ! ! Nutzen Sie die goldene Drei und die silberne Vier, ergänzen Sie die Wissenspunkte des MySQL Advanced-Kapitels und beginnen Sie die Reise des MySQL Advanced-Kapitels unter den folgenden Aspekten:
Es wird empfohlen, durch die Teile zu suchen, die für Sie hilfreich sind
Sidebar-Verzeichnis, darunter
Das Emoji-Präfix ist ein wichtiger Teil. Wenn Sie es hilfreich finden, wird der Herausgeber diesen Artikel und die MySQL-Kolumne weiter verbessern. 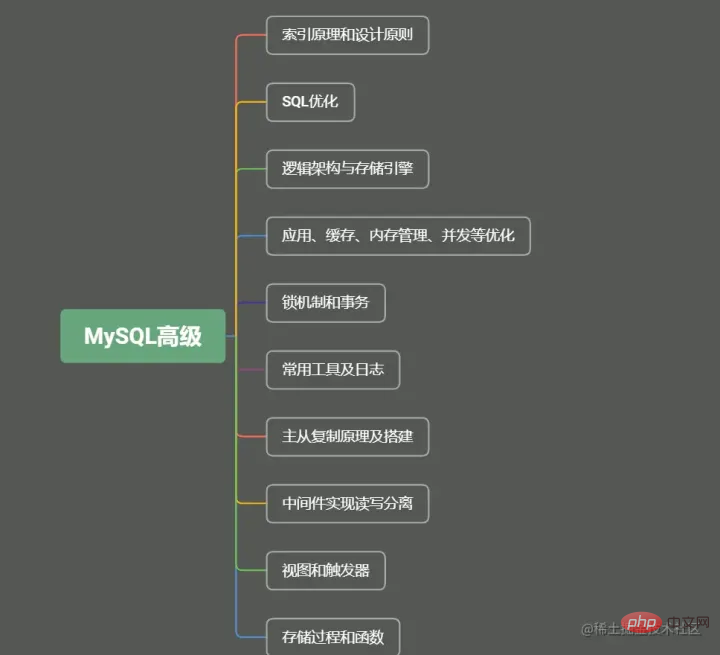
IndexdefinitionMySQLs offizielle Indexdefinition lautet: Index (Index) ist eine Datenstruktur (geordnet), die MySQL dabei hilft, Daten effizient zu erhalten. Feldern in Datenbanktabellen werden Indizes hinzugefügt, um die Abfrageeffizienz zu verbessern. Zusätzlich zu den Daten verwaltet das Datenbanksystem auch Datenstrukturen, die bestimmte Suchalgorithmen erfüllen. Diese Datenstrukturen verweisen auf die Daten, sodass erweiterte Suchalgorithmen auf diesen Datenstrukturen implementiert werden können Index. Wie im Diagramm unten gezeigt:
Tatsächlich ist ein Index, einfach ausgedrückt, eine sortierte Datenstruktur
Die linke Seite ist die Datentabelle mit insgesamt zwei Spalten und sieben Datensätzen und die ganz linke Seite Eine davon ist die physische Struktur der Datensatzadresse (beachten Sie, dass logisch benachbarte Datensätze nicht unbedingt physisch benachbart auf der Festplatte liegen). Um die Suche nach Col2 zu beschleunigen, können Sie einen binären Suchbaum pflegen, wie rechts gezeigt. Jeder Knoten enthält eineneinen Zeiger auf die physische Adresse des entsprechenden DatensatzesIndexschlüsselwert
und
Verwenden Sie die binäre Suche, um schnell an die entsprechenden Daten zu gelangen. 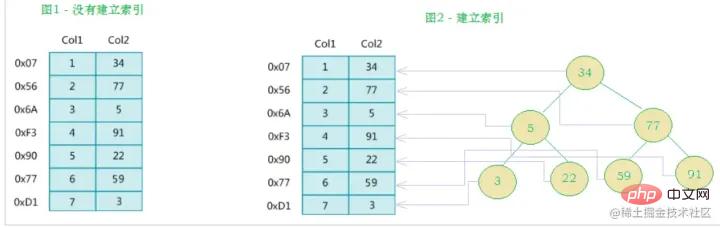
Beschleunigen Sie die Suche und
Sortierraten, reduzieren Sie die Datenbank-IO-Kosten und den CPU-VerbrauchDurch die Erstellung eines eindeutigen Indexes können Sie die Eindeutigkeit jeder Datenzeile in der Datenbanktabelle sicherstellen.- Nachteile des IndexDer Index ist eigentlich eine Tabelle
- , die den Primärschlüssel und das Indexfeld speichert und auf die Datensätze der Entitätsklasse verweist. Er selbst muss Platz belegen
Zeigerung
des mittleren Knotens muss möglicherweise geändert werden- Aber tatsächlich verwenden wir nicht den binären Suchbaum
- , um ihn in MySQL zu speichern . Warum? Sie müssen wissen, dass in einem binären Suchbaum ein Knoten hier nur ein Datenelement speichern kann und ein Knoten einem Festplattenblock in MySQL entspricht. Auf diese Weise können wir jedes Mal einen Festplattenblock lesen Um ein einzelnes Datenelement zu erhalten, ist die Effizienz besonders gering, daher werden wir darüber nachdenken, eine
-Struktur zu verwenden, um es zu speichern.Indexstruktur
Indizes werden in der Speicher-Engine-Schicht von MySQL implementiert, nicht in der Serverschicht. Daher sind die Indizes der einzelnen Speicher-Engines nicht unbedingt identisch und nicht alle Engines unterstützen alle Indextypen.
- BTREE-Index: Der häufigste Indextyp. Die meisten Indizes unterstützen B-Tree-Indizes.
- HASH-Index: Wird nur von der Speicher-Engine unterstützt, das Nutzungsszenario ist einfach.
- R-Tree-Index (räumlicher Index): Der räumliche Index ist ein spezieller Indextyp der MyISAM-Engine. Er wird hauptsächlich für Geodatentypen verwendet. Er wird normalerweise weniger verwendet und nicht speziell eingeführt.
- Volltext (Volltextindex): Der Volltextindex ist ebenfalls ein spezieller Indextyp von MyISAM, der hauptsächlich für den Volltextindex verwendet wird. InnoDB unterstützt den Volltextindex ab der Mysql5.6-Version.
MyISAM-, InnoDB- und Memory-Speicher-Engines unterstützen verschiedene Indextypen
| BTREE Index | Unterstützt | Unterstützt Nicht unterstützt |
Unterstützt |
|||||||||
R-Tree-Index |
Nicht unterstützt |
Unterstützt |
Nicht unterstützt |
|||||||||
Volltext |
Unterstützt nach Version 5.6 |
Unterstützt |
Nicht unterstützt |
|||||||||
|
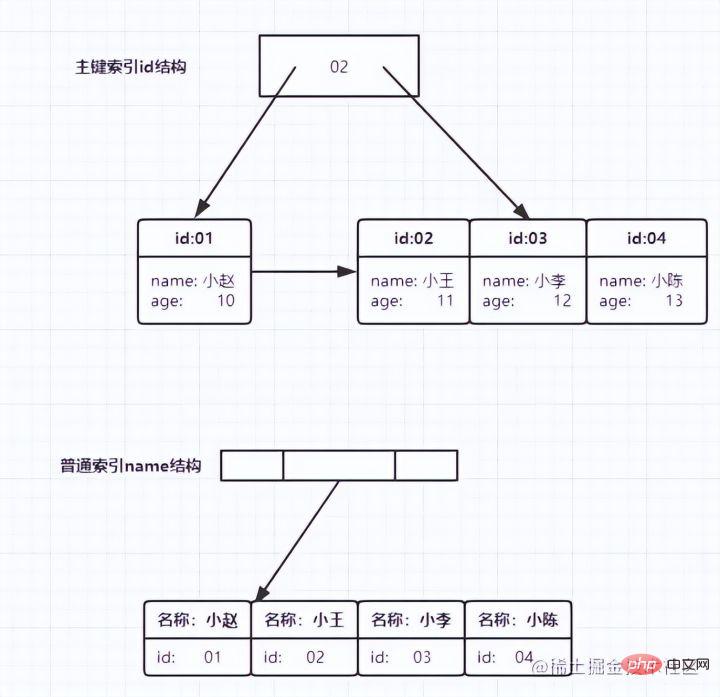
Was wir normalerweise als Indizes bezeichnen, bezieht sich, sofern nicht anders angegeben, auf Indizes, die in einer B+-Baumstruktur (Mehrwege-Suchbaum, nicht unbedingt binär) organisiert sind. Unter diesen verwenden Clustered-Index, Compound-Index, Präfix-Index und Unique-Index standardmäßig alle den B+Tree-Index, der gemeinsam als Index bezeichnet wird. BTREE m/2)-1 bis m-1 ceil bedeutet Aufrunden, ceil(2.3)=3
, um sicherzustellen, dass die Eigenschaften des B-Baums m-Ordnung vorliegen nicht zerstört Da Level 3 höchstens 2 Knoten haben kann, sind 26 und 30 am Anfang zusammen, und dann beginnt 85, sich zu teilen, 26 bleibt übrig und 85 geht an rechts Das heißt: Wenn 70 erneut in das Bild eingefügt wird, ist zufällig 70 drin In der mittleren Position wird 62 beibehalten und 85 wird in einen neuen Knoten unterteilt Vorteile B+-Baum hat zwei Arten von Knoten: interne Knoten (auchIndexknoten genannt) und klein bis großJeder Blattknoten speichert Zeiger auf benachbarte Blattknoten. Die Blattknoten selbst sind in der Reihenfolge von klein nach groß Der übergeordnete Knoten speichert den Indexdes ersten Elements desrechten untergeordneten Knotens.
Beim Übergang vom
IndexprinzipBBaumindex:
|
 Die obere Position in der Mitte
Die obere Position in der Mitte 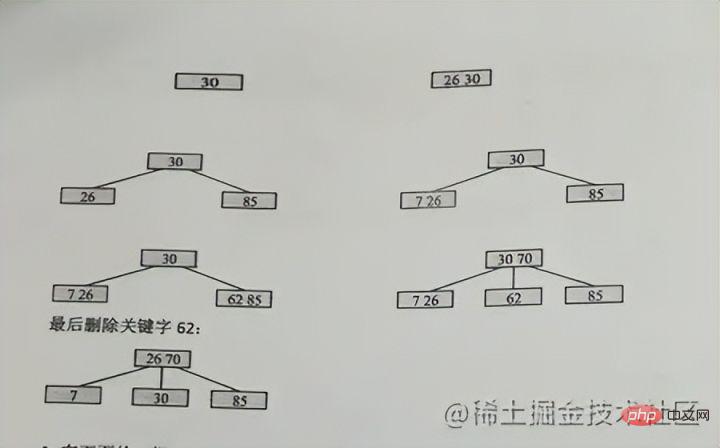 Blattknoten
Blattknoten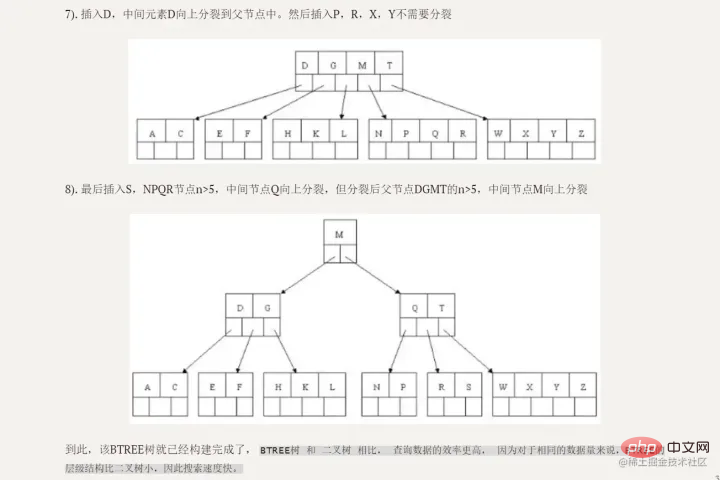 entsprechend der Größe der Schlüsselwörter verbunden.
entsprechend der Größe der Schlüsselwörter verbunden. 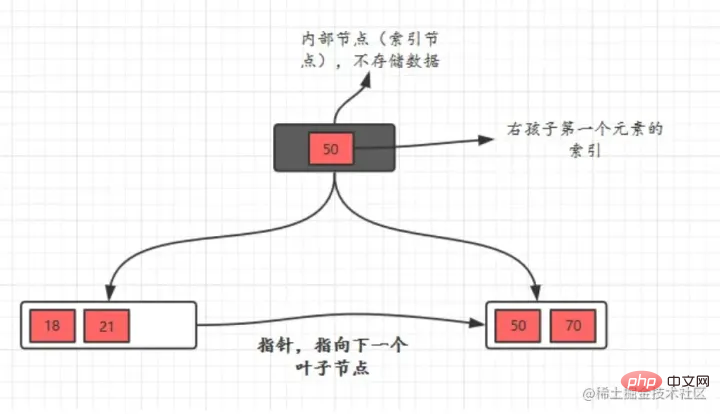 binären Suchbaum zum B-Baum
binären Suchbaum zum B-Baum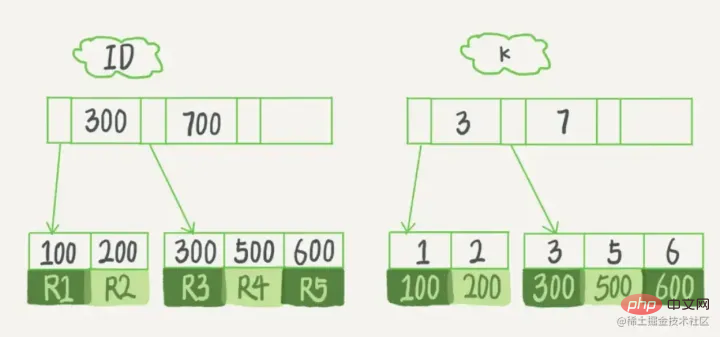


Das obige ist der detaillierte Inhalt vonFührt Sie durch den MySQL-Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!