
Heim >Java >javaLernprogramm >Ausführliche Erklärung mit Bildern und Text! Was ist das Java-Speichermodell?
Ausführliche Erklärung mit Bildern und Text! Was ist das Java-Speichermodell?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-03-22 18:00:411876Durchsuche
Dieser Artikel bringt Ihnen Java-bezogenes Wissen, das hauptsächlich verwandte Themen zum Speichermodell vorstellt, einschließlich der Frage, warum es ein Speichermodell gibt, gleichzeitiger Programmierung und der Beziehung zwischen Speicherbereich und Hardwarespeicher usw. Ich hoffe, dass es nützlich sein wird Jeder hilfsbereit.

Empfohlene Studie: „Java-Tutorial“
Bei Vorstellungsgesprächen fragen Interviewer oft: „Was ist das Java Memory Model (JMM)?“ 』
Der Interviewer war begeistert. Er hatte gerade diese Frage auswendig gelernt: „Java-Speicher ist hauptsächlich in fünf Hauptteile unterteilt: Heap, Methodenbereich, Stapel virtueller Maschinen, lokaler Methodenstapel, PC-Register, Balabala …“ Der Interviewer lächelte wissend und enthüllte ein Licht: „Okay, das heutige Interview ist zuerst hier, gehen Sie zurück und warten Sie auf Benachrichtigung.“
Wenn Sie den Satz „auf Benachrichtigung warten“ hören, wird dieses Interview im Allgemeinen höchstwahrscheinlich kalt sein. Warum? Da der Interviewer das Konzept missverstand, wollte er sich mit JMM befassen, aber sobald der Interviewer die Schlüsselwörter Java Memory hörte, begann er, den achtbeinigen Aufsatz zu rezitieren. Es gibt einen großen Unterschied zwischen dem Java-Speichermodell (JMM) und dem Java-Laufzeitspeicherbereich. Versprich mir, alles zu lesen.
1. Warum brauchen wir ein Speichermodell?
Um diese Frage zu beantworten, müssen wir zunächst die traditionelle Computer-Hardware-Speicherarchitektur verstehen. Okay, ich werde mit dem Zeichnen beginnen. Java内存这几个关键字就开始背诵八股文了。Java内存模型(JMM)和Java运行时内存区域区别可大了呢,不要走开接着往下看,答应我要看完。
1. 为什么要有内存模型?
要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。好了,我要开始画图了。
1.1. 硬件内存架构

(1)CPU
去过机房的同学都知道,一般在大型服务器上会配置多个CPU,每个CPU还会有多个核,这就意味着多个CPU或者多个核可以同时(并发)工作。如果使用Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
(2)CPU Register
CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
(3)CPU Cache Memory
CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
(4)Main Memory
Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
注意:部分高端机器还有 L3 三级缓存。
1.2. 缓存一致性问题
由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再讲运算结果同步到主存中。
使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
在多CPU的系统中(或者单CPU多核的系统),每个CPU内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个CPU的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等。
1.3. 处理器优化和指令重排序
为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到缓存一致性问题
1.1. Hardware-Speicherarchitektur
CPU-Register ist das CPU-Register. CPU-Register sind in die CPU integriert und die Effizienz der Ausführung von Operationen an Registern ist um mehrere Größenordnungen höher als im Hauptspeicher. (3) CPU-Cache-SpeicherCPU-Cache-Speicher ist der CPU-Cache. Im Vergleich zum Register kann er normalerweise auch zum L2-Level-2-Cache werden. Im Vergleich zur Lesegeschwindigkeit der Festplatte ist die Effizienz des Speicherlesens sehr hoch, unterscheidet sich jedoch immer noch um Größenordnungen von der der CPU. Zu diesem Zweck wird ein mehrstufiger Cache zwischen der CPU und dem Hauptspeicher eingeführt der Pufferung. 🎜🎜(4) Hauptspeicher🎜🎜Hauptspeicher ist der Hauptspeicher, der viel größer ist als die L1- und L2-Caches. 🎜🎜Hinweis: Einige High-End-Maschinen verfügen auch über L3-Level-3-Cache. 🎜1.2. Cache-Konsistenzproblem
🎜Aufgrund der Größenordnungslücke zwischen der Rechenleistung des Hauptspeichers und der des CPU-Prozessors wird in der herkömmlichen Computerspeicherarchitektur ein Cache eingeführt, der als Hauptspeicher dient und Prozessor Die CPU legt häufig verwendete Daten im Cache ab und synchronisiert nach Abschluss der Operation die Operationsergebnisse mit dem Hauptspeicher. 🎜🎜Die Verwendung von Cache löst das Problem der Nichtübereinstimmung von CPU- und Hauptspeicherraten, führt aber gleichzeitig zu einem weiteren neuen Problem: dem Problem der Cache-Konsistenz. 🎜🎜 In einem Multi-CPU-System ( Oder ein einzelnes CPU-Mehrkernsystem), jeder CPU-Kern hat seinen eigenen Cache und sie teilen sich den gleichen Hauptspeicher (Hauptspeicher). Wenn die Rechenaufgaben mehrerer CPUs denselben Hauptspeicherbereich betreffen, liest die CPU die Daten zur Berechnung in den Cache, was dazu führen kann, dass die jeweiligen Cache-Daten inkonsistent sind. 🎜🎜Daher muss jede CPU beim Zugriff auf den Cache einem bestimmten Protokoll folgen, beim Lesen und Schreiben von Daten gemäß dem Protokoll arbeiten und gemeinsam die Konsistenz des Caches aufrechterhalten. Zu diesen Protokollen gehören MSI, MESI, MOSI und Dragon Protocol. 🎜
1.3. Prozessoroptimierung und Befehlsneuordnung
🎜Um die Leistung zu verbessern, wird ein Cache zwischen der CPU und dem Hauptspeicher hinzugefügt. In Multithread-Szenarien können jedoch Probleme mit der Cache-Konsistenz auftreten . Gibt es eine Möglichkeit, die Ausführungseffizienz der CPU weiter zu verbessern? Die Antwort lautet: Prozessoroptimierung. 🎜🎜🎜Um die volle Auslastung der Recheneinheit im Prozessor zu maximieren, führt der Prozessor den Eingabecode in der falschen Reihenfolge aus. Dies ist eine Prozessoroptimierung. 🎜🎜🎜Zusätzlich zur Optimierung des Codes durch den Prozessor führen viele moderne Programmiersprachen-Compiler auch ähnliche Optimierungen durch. Beispielsweise führt der Just-in-Time-Compiler (JIT) die Neuordnung von Anweisungen durch. 🎜🎜🎜🎜🎜Prozessoroptimierung ist eigentlich eine Art der Neuordnung. Zusammenfassend kann die Neuordnung in drei Arten unterteilt werden: 🎜
- Compiler-optimierte Neuordnung. Der Compiler kann die Ausführungsreihenfolge von Anweisungen neu anordnen, ohne die Semantik eines Single-Thread-Programms zu ändern.
- Parallele Neuordnung auf Befehlsebene. Moderne Prozessoren nutzen Parallelität auf Befehlsebene, um die Ausführung mehrerer Befehle zu überlappen. Wenn keine Datenabhängigkeiten bestehen, kann der Prozessor die Reihenfolge ändern, in der Anweisungen den Maschinenanweisungen entsprechen.
- Neuordnung des Speichersystems. Da der Prozessor Cache- und Lese- und Schreibpuffer verwendet, kann dies den Eindruck erwecken, dass Lade- und Speichervorgänge nicht in der richtigen Reihenfolge ausgeführt werden.
2. Die oben genannten Dinge im Zusammenhang mit der Hardware sind möglicherweise etwas verwirrt. Haben diese Dinge etwas mit dem Java-Speichermodell zu tun? Keine Sorge, schauen wir langsam nach unten.
Studenten, die mit Java-Parallelität vertraut sind, müssen mit diesen drei Problemen vertraut sein: „Sichtbarkeitsproblem“, „Atomizitätsproblem“ und „Ordnungsproblem“. Wenn Sie diese drei Probleme genauer betrachten, werden sie tatsächlich durch die oben erwähnte „Cache-Konsistenz“, „Prozessoroptimierung“ und „Befehlsneuordnung“ verursacht.
Das Cache-Konsistenzproblem ist tatsächlich ein Sichtbarkeitsproblem. Die Prozessoroptimierung kann zu Atomizitätsproblemen führen, und die Neuordnung von Anweisungen kann zu Sortierproblemen führen. 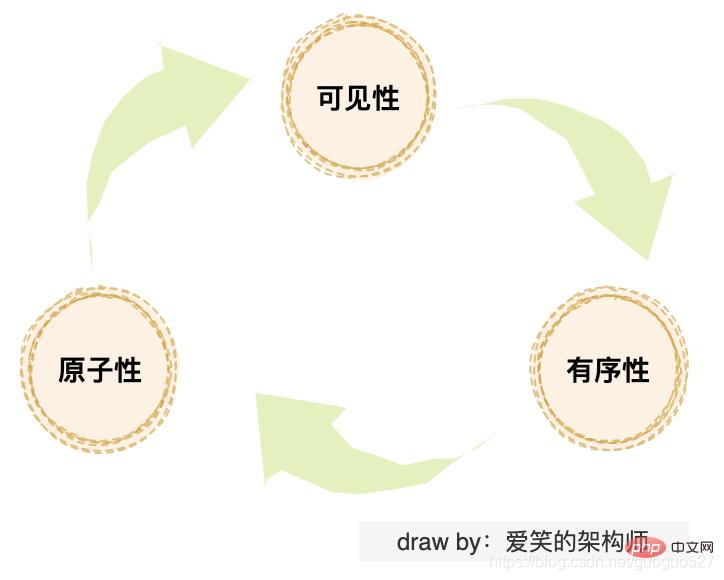
Probleme müssen immer gelöst werden. Was ist also die Lösung? Zunächst habe ich über eine einfache und grobe Möglichkeit nachgedacht, den Cache zu löschen und die CPU direkt mit dem Hauptspeicher interagieren zu lassen. Das Deaktivieren der Prozessoroptimierung und der Befehlsneuordnung löst die Atomizitäts- und Ordnungsprobleme, aber das wird zum Vorherigen zurückkehren Befreiung über Nacht, offensichtlich unerwünscht.
Also dachten die technischen Senioren darüber nach, eine Reihe von Speichermodellen auf physischen Maschinen zu definieren, um Speicherlese- und -schreibvorgänge zu standardisieren. Das Speichermodell verwendet hauptsächlich zwei Methoden zur Lösung von Parallelitätsproblemen:
.限制处理器优化和使用内存屏障3. Java-Speichermodell
Bei den gleichen Speichermodellspezifikationen können verschiedene Sprachen einige Unterschiede in der Implementierung aufweisen. Als nächstes konzentrieren wir uns auf die Implementierungsprinzipien des Java-Speichermodells.
3.1. Die Beziehung zwischen dem Java-Laufzeitspeicherbereich und dem Hardwarespeicher
Studenten, die die JVM kennen, wissen, dass der JVM-Laufzeitspeicherbereich fragmentiert und in Stapel, Heaps usw. unterteilt ist. Tatsächlich handelt es sich dabei um logische Konzepte, die von der JVM definiert werden . In der herkömmlichen Hardware-Speicherarchitektur gibt es kein Stack- und Heap-Konzept.
Aus dem Bild ist ersichtlich, dass der Stapel und der Heap sowohl im Cache als auch im Hauptspeicher vorhanden sind, sodass zwischen beiden keine direkte Beziehung besteht. 
3.2. Die Beziehung zwischen Java-Threads und Hauptspeicher
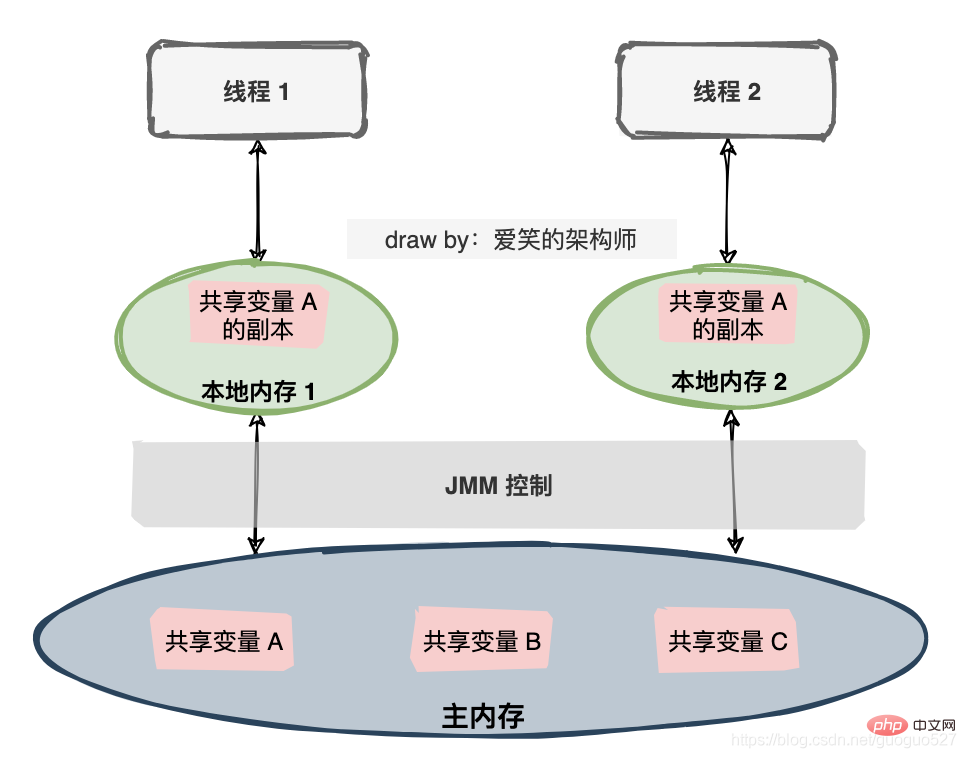
Das Java-Speichermodell ist eine Spezifikation, die viele Dinge definiert:
Alle Variablen werden im Hauptspeicher (Hauptspeicher) gespeichert.- Jeder Thread verfügt über einen privaten lokalen Speicher (lokaler Speicher), und der lokale Speicher speichert eine Kopie der gemeinsam genutzten Variablen, die der Thread lesen/schreiben kann.
- Alle Operationen an Variablen durch Threads müssen im lokalen Speicher ausgeführt werden und können den Hauptspeicher nicht direkt lesen oder schreiben.
- Verschiedene Threads können nicht direkt auf Variablen im lokalen Speicher des anderen zugreifen.
- Text zu lesen ist zu langweilig, ich habe ein anderes Bild gezeichnet:
 3.3. Kommunikation zwischen Threads
3.3. Kommunikation zwischen Threads
Wenn zwei Threads mit einer gemeinsam genutzten Variablen arbeiten, ist der Anfangswert der gemeinsam genutzten Variablen 1 und jeder Thread beide Variablen werden um 1 erhöht und der erwartete Wert der gemeinsam genutzten Variablen beträgt 3. Die JMM-Spezifikation umfasst eine Reihe von Operationen.
Um die Interaktion zwischen Hauptspeicher und lokalem Speicher besser steuern zu können, definiert das Java-Speichermodell acht Operationen, um Folgendes zu erreichen: 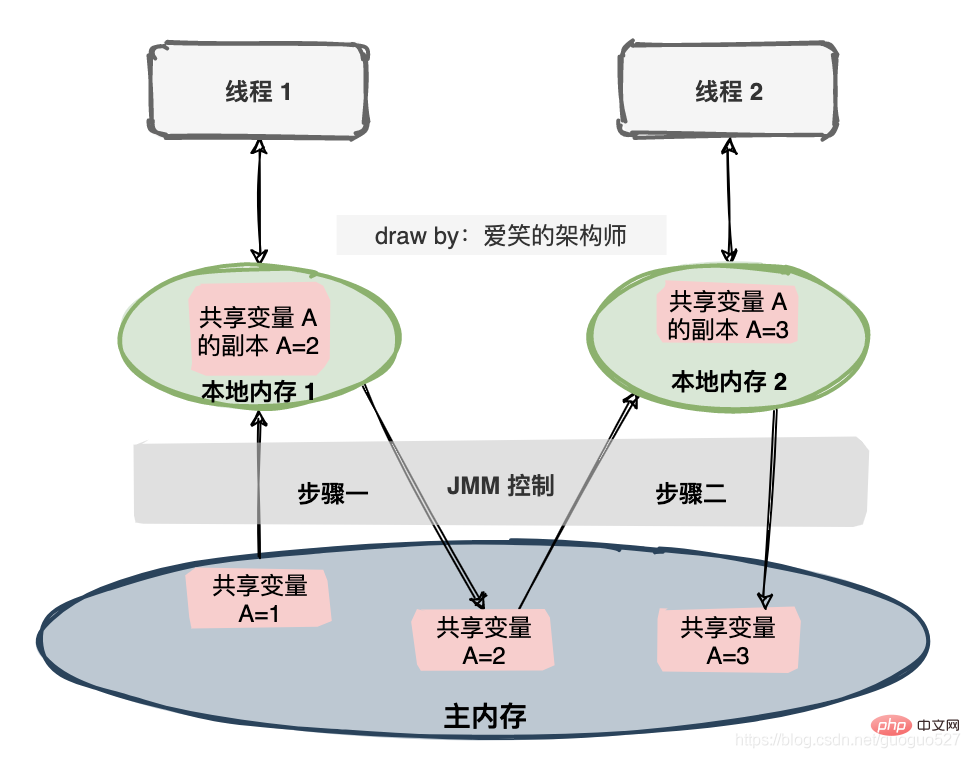
- Sperre: Sperre. Wirkt auf Variablen im Hauptspeicher und markiert eine Variable als exklusiv für einen Thread.
- Entsperren: Entsperren. Wirkt auf Hauptspeichervariablen, um eine gesperrte Variable freizugeben, sodass die freigegebene Variable von anderen Threads gesperrt werden kann.
- lesen: lesen. Wirkt auf die Hauptspeichervariable und überträgt einen Variablenwert aus dem Hauptspeicher in den Arbeitsspeicher des Threads zur anschließenden Verwendung der Ladeaktion
- load:load. Wirkt auf Variablen im Arbeitsspeicher, wodurch der durch den Lesevorgang aus dem Hauptspeicher erhaltene Variablenwert in eine Kopie der Variablen im Arbeitsspeicher kopiert wird.
- Verwendung: Verwendung. Variablen, die auf den Arbeitsspeicher einwirken, übergeben einen Variablenwert im Arbeitsspeicher an die Ausführungs-Engine. Dieser Vorgang wird immer dann ausgeführt, wenn die virtuelle Maschine auf eine Bytecode-Anweisung trifft, die den Wert der Variablen erfordert.
- assign: Aufgabe. Wirkt auf eine Variable im Arbeitsspeicher, die einer Variablen im Arbeitsspeicher einen von der Ausführungs-Engine empfangenen Wert zuweist. Dieser Vorgang wird jedes Mal ausgeführt, wenn die virtuelle Maschine auf eine Bytecode-Anweisung trifft, die der Variablen einen Wert zuweist.
- Speicher: Lagerung. Wirkt auf Variablen im Arbeitsspeicher und überträgt den Wert einer Variablen im Arbeitsspeicher für nachfolgende Schreibvorgänge in den Hauptspeicher.
- schreiben: schreiben. Wirkt auf Variablen im Hauptspeicher und überträgt den Speichervorgang vom Wert einer Variablen im Arbeitsspeicher auf eine Variable im Hauptspeicher.
Hinweis: Arbeitsgedächtnis bedeutet auch lokales Gedächtnis.
4. Eine Einstellungszusammenfassung
Aufgrund des Geschwindigkeitsunterschieds zwischen der CPU und dem Hauptspeicher dachte ich darüber nach, die traditionelle Hardware-Speicherarchitektur des Multi-Level-Cache einzuführen, um das Problem zu lösen Dient als Lücke zwischen der CPU und dem Hauptspeicher und verbessert die Gesamtleistung. Es löst das Problem der schlechten Geschwindigkeit, bringt aber auch das Problem der Cache-Konsistenz mit sich.
Daten sind sowohl im Cache als auch im Hauptspeicher vorhanden. Wenn sie nicht standardisiert sind, führt dies unweigerlich zu einer Katastrophe, sodass das Speichermodell auf herkömmlichen Maschinen abstrahiert wird.
Die Java-Sprache hat die JMM-Spezifikation basierend auf dem Speichermodell eingeführt. Der Zweck besteht darin, das Problem der Inkonsistenz lokaler Speicherdaten, der Anweisungen zum Neuordnen des Compilers und des Prozessors beim Neuordnen von Code zu lösen, wenn Multithreads über den gemeinsam genutzten Speicher kommunizieren durch Ausführung außerhalb der Reihenfolge usw.
Um die Interaktion zwischen Arbeitsspeicher und Hauptspeicher genauer zu steuern, definiert JMM außerdem acht Operationen: lock, unlock, read, load,use,assign, store, write.
Empfohlenes Lernen: „Java-Lern-Tutorial“
Das obige ist der detaillierte Inhalt vonAusführliche Erklärung mit Bildern und Text! Was ist das Java-Speichermodell?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie erhalte ich URL-Parameter in JavaScript? Detaillierte Erläuterung von 4 gängigen Methoden
- Fassen Sie die Prozesssteuerung des JAVA-Lernens zusammen und organisieren Sie sie
- Wie lautet der Code für die Teilbarkeit von Javascript durch fünf?
- Helfen Sie beim Abrufen von JavaScript-Objekten
- Detaillierte grafische Erläuterung der Java-Datenstrukturen und -Algorithmen