
Wie löst Redis das Problem der Cache-Inkonsistenz?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-02-25 17:20:452640Durchsuche
In diesem Artikel erfahren Sie, wie Redis das Problem der Cache-Inkonsistenz löst und wie die Dateninkonsistenz zwischen dem Cache und der Datenbank auftritt. Ich hoffe, dass es für alle hilfreich ist.

Empfohlenes Lernen: Redis-Lerntutorial
Wie kommt es zu Dateninkonsistenzen zwischen Cache und Datenbank?
Zuerst müssen wir verstehen, was „Datenkonsistenz“ konkret bedeutet. Tatsächlich umfasst die „Konsistenz“ hier zwei Situationen:
- Es gibt Daten im Cache, dann muss der zwischengespeicherte Datenwert mit dem Wert in der Datenbank übereinstimmen
- Es gibt keine Daten im Cache selbst; Dann muss der Wert in der Datenbank der neueste Wert sein.
Wenn diese beiden Bedingungen nicht erfüllt sind, liegt ein Dateninkonsistenzproblem zwischen dem Cache und der Datenbank vor. Wenn jedoch die Cache-Lese- und Schreibmodi unterschiedlich sind, ist das Auftreten von Cache-Dateninkonsistenzen unterschiedlich, und auch unsere Antwortmethoden sind unterschiedlich. Daher verstehen wir zunächst die Cache-Inkonsistenzen in verschiedenen Modi entsprechend den Cache-Lese- und Schreibmodi. Zustand. Wir können den Cache in Lese-/Schreibcache und Nur-Lese-Cache unterteilen.
Wenn Sie beim Lese-/Schreibcache Daten hinzufügen, löschen oder ändern möchten, müssen Sie dies im Cache tun. Gleichzeitig müssen Sie basierend auf dem Schreibvorgang entscheiden, ob Sie sie synchron in die Datenbank zurückschreiben möchten. Back-Strategie übernommen.
Synchronische Direktschreibstrategie: Beim Schreiben in den Cache wird die Datenbank ebenfalls synchron geschrieben, und die Daten im Cache und in der Datenbank sind konsistent.
Asynchrone Rückschreibstrategie: Beim Schreiben in den Cache wird die Datenbank nicht synchron geschrieben und dann zurückgeschrieben, wenn die Daten aus der Cache-Datenbank entfernt werden. Wenn bei Verwendung dieser Strategie die Daten nicht in die Datenbank zurückgeschrieben wurden, schlägt der Cache fehl und die Datenbank verfügt zu diesem Zeitpunkt nicht über die neuesten Daten.
Wenn Sie also für den Lese-/Schreib-Cache sicherstellen möchten, dass die Daten im Cache und in der Datenbank konsistent sind, müssen Sie eine synchrone Direktschreibstrategie anwenden. Beachten Sie jedoch, dass Sie bei dieser Strategie gleichzeitig den Cache und die Datenbank aktualisieren müssen. Daher müssen wir in Geschäftsanwendungen Transaktionsmechanismen verwenden, um sicherzustellen, dass Cache- und Datenbankaktualisierungen atomar sind. Das heißt, sie werden entweder zusammen aktualisiert oder keines von beiden wird aktualisiert, es wird eine Fehlermeldung zurückgegeben und ein Wiederholungsversuch durchgeführt. Andernfalls können wir kein synchrones direktes Schreiben erreichen.
Natürlich sind unsere Anforderungen an die Datenkonsistenz in einigen Szenarien möglicherweise nicht so hoch. Wenn wir beispielsweise unkritische Attribute von E-Commerce-Produkten oder die Erstellungs- oder Änderungszeit von kurzen Videos zwischenspeichern, können wir diese verwenden Asynchrones Schreiben. Return-Strategie.
Lassen Sie uns über schreibgeschütztes Caching sprechen. Wenn im schreibgeschützten Cache neue Daten vorhanden sind, werden diese direkt in die Datenbank geschrieben. Wenn Daten gelöscht werden, müssen die Daten im schreibgeschützten Cache als ungültig markiert werden. Wenn die Anwendung anschließend auf diese hinzugefügten, gelöschten oder geänderten Daten zugreift, kommt es auf diese Weise zu einem Cache-Fehler, da keine entsprechenden Daten im Cache vorhanden sind. Zu diesem Zeitpunkt liest die Anwendung die Daten aus der Datenbank in den Cache, sodass sie beim späteren Zugriff auf die Daten direkt aus dem Cache gelesen werden können.
Nehmen Sie als Nächstes das Schreiben und Löschen von Daten von Tomcat in MySQL als Beispiel, um Ihnen zu erklären, wie die Vorgänge zum Hinzufügen, Löschen und Ändern von Daten ausgeführt werden, wie in der folgenden Abbildung dargestellt:
Wie Sie in der Abbildung sehen können, Tomcat-Anwendungen Beim Ausführen in der Datenbank werden Daten direkt in der Datenbank hinzugefügt, geändert und gelöscht, unabhängig davon, ob Daten X hinzugefügt (Einfügevorgang), geändert (Aktualisierungsvorgang) oder gelöscht (Löschvorgang) werden. Wenn die Anwendung einen Änderungs- oder Löschvorgang durchführt, werden natürlich auch die zwischengespeicherten Daten X gelöscht.
Kann es bei diesem Prozess zu Dateninkonsistenzen kommen? Da die Situationen beim Hinzufügen und Löschen von Daten unterschiedlich sind, betrachten wir sie separat.
- Neue Daten
Wenn es sich um neue Daten handelt, werden die Daten direkt in die Datenbank geschrieben, ohne dass eine Operation im Cache erforderlich ist. Zu diesem Zeitpunkt befinden sich keine neuen Daten im Cache selbst, sondern der neueste Wert in der Datenbank. In diesem Fall entspricht es der zweiten Konsistenzsituation, die wir gerade erwähnt haben, sodass zu diesem Zeitpunkt die Daten im Cache und in der Datenbank konsistent sind. - Daten löschen
Wenn ein Löschvorgang erfolgt, muss die Anwendung sowohl die Datenbank aktualisieren als auch die Daten im Cache löschen. Wenn diese beiden Vorgänge keine Atomizität garantieren können, d. h. entweder beide abgeschlossen sind oder keine abgeschlossen ist, kommt es zu Dateninkonsistenzen. Dieses Problem ist komplizierter, lassen Sie es uns analysieren.
Wir gehen davon aus, dass die Anwendung zuerst den Cache löscht und dann die Datenbank aktualisiert. Wenn der Cache erfolgreich gelöscht wird, die Datenbankaktualisierung jedoch fehlschlägt, befinden sich beim erneuten Zugriff der Anwendung auf die Daten keine Daten im Cache und a Es kommt zu einem Cache-Fehler. Anschließend greift die Anwendung erneut auf die Datenbank zu, der Wert in der Datenbank ist jedoch der alte Wert, und die Anwendung greift auf den alten Wert zu.
Lassen Sie mich Ihnen ein Beispiel geben. Schauen Sie sich zunächst das Bild unten an
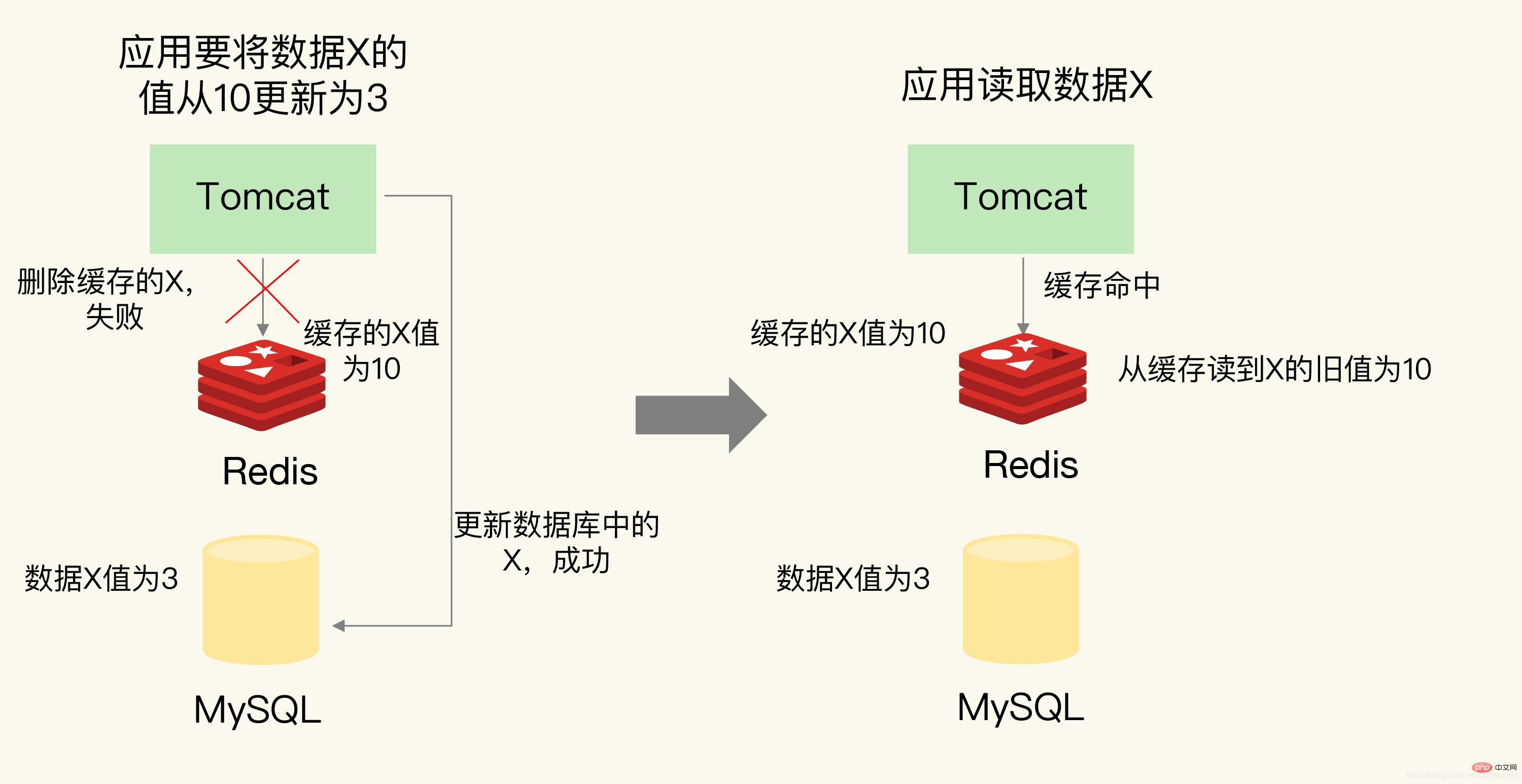
Die Anwendung möchte den Wert von Daten X von 10 auf 3 aktualisieren. Sie löscht zunächst den Cache-Wert von X im Redis-Cache, aber die Aktualisierung der Datenbank schlägt fehl. Wenn andere gleichzeitige Zugriffsanforderungen vorliegen
Sie fragen sich vielleicht: Kann dieses Problem gelöst werden, wenn wir zuerst die Datenbank aktualisieren und dann den Wert im Cache löschen? Analysieren wir es noch einmal.
Wenn die Anwendung die Datenbankaktualisierung zuerst abschließt, beim Löschen des Caches jedoch ein Fehler auftritt, ist der Wert in der Datenbank der neue Wert und der Wert im Cache der alte Wert, was definitiv inkonsistent ist. Wenn zu diesem Zeitpunkt andere gleichzeitige Anforderungen für den Zugriff auf die Daten vorliegen, wird gemäß dem normalen Cache-Zugriffsprozess zuerst der Cache abgefragt, zu diesem Zeitpunkt wird jedoch der alte Wert gelesen.
Lass es mich anhand eines Beispiels erklären.
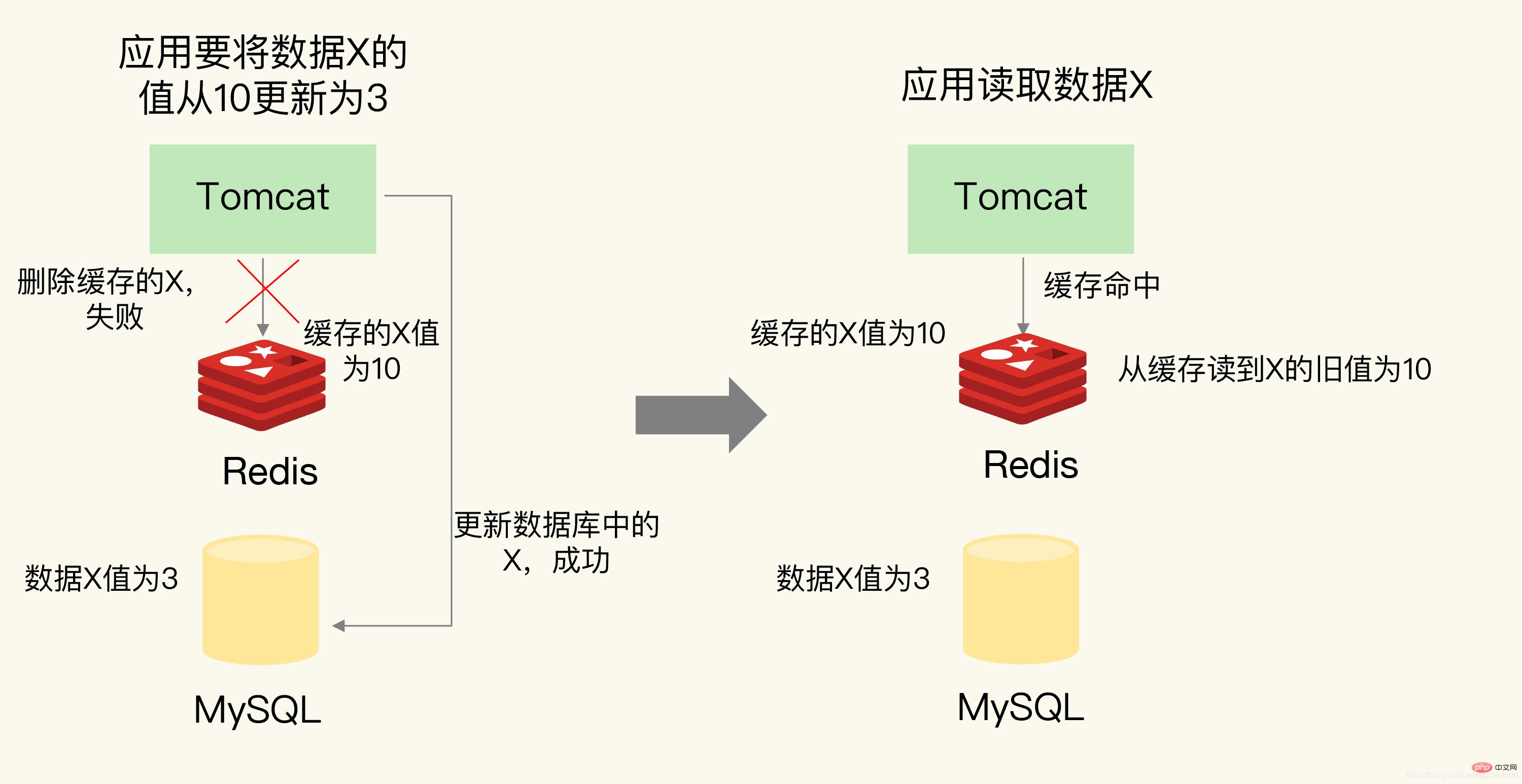
Die Anwendung möchte den Wert der Daten X von 10 auf 3 aktualisieren. Zuerst wird die Datenbank erfolgreich aktualisiert und dann wird der Cache von 3 gelöscht. Der zwischengespeicherte Wert von . Wenn zu diesem Zeitpunkt ein anderer Client eine Anfrage für den Zugriff auf
Okay, hier können wir sehen, dass beim Aktualisieren der Datenbank und beim Löschen zwischengespeicherter Werte, unabhängig von der Reihenfolge, in der die beiden Vorgänge zuerst ausgeführt werden, der Client, solange ein Vorgang fehlschlägt, Get the liest Alter Wert. Ich habe die folgende Tabelle erstellt, um die beiden gerade erwähnten Situationen zusammenzufassen.

Wir kennen die Ursache des Problems, aber wie kann man es lösen?
Wie kann das Problem der Dateninkonsistenz gelöst werden?
Zunächst möchte ich Ihnen eine Methode vorstellen: den Wiederholungsmechanismus.
Konkret können Sie den zu löschenden Cache-Wert oder den zu aktualisierenden Datenbankwert vorübergehend in der Nachrichtenwarteschlange speichern (z. B. mithilfe der Kafka-Nachrichtenwarteschlange). Wenn es einer Anwendung nicht gelingt, zwischengespeicherte Werte erfolgreich zu löschen oder Datenbankwerte zu aktualisieren, kann sie die Werte erneut aus der Nachrichtenwarteschlange lesen und sie erneut löschen oder aktualisieren.
Wenn wir erfolgreich löschen oder aktualisieren können, entfernen wir diese Werte aus der Nachrichtenwarteschlange, um wiederholte Vorgänge zu vermeiden. Zu diesem Zeitpunkt können wir auch sicherstellen, dass die Datenbank und die zwischengespeicherten Daten konsistent sind. Ansonsten müssen wir es noch einmal versuchen. Wenn der Wiederholungsversuch eine bestimmte Anzahl überschreitet und immer noch fehlschlägt, müssen wir eine Fehlermeldung an die Business-Schicht senden.
Das Bild unten zeigt, dass Sie einen Blick darauf werfen können, wenn zuerst die Datenbank aktualisiert und dann der Cache-Wert gelöscht wird. Wenn das Löschen des Caches fehlschlägt und der Löschvorgang nach einem erneuten Versuch erfolgreich ist.
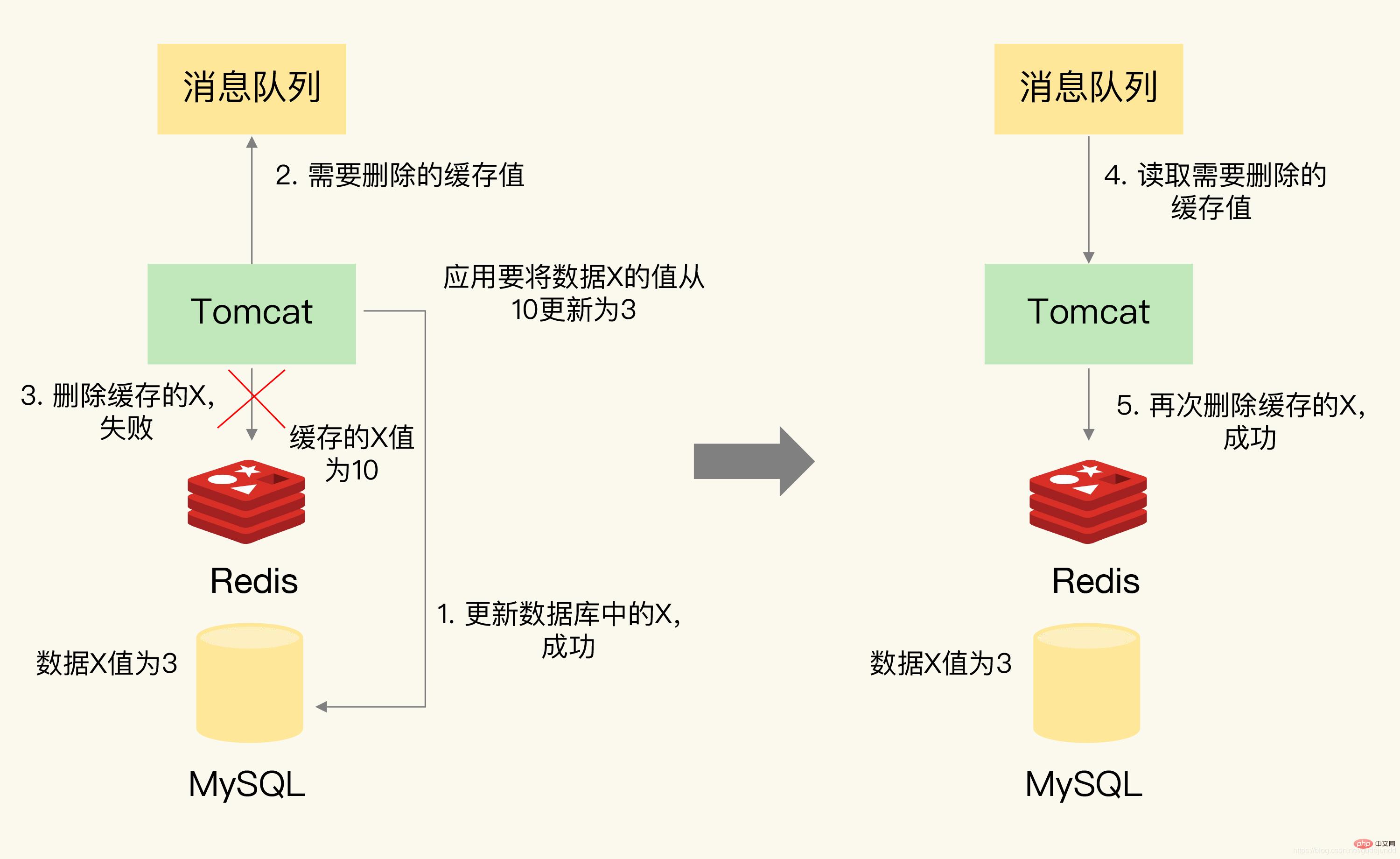
Worüber ich gerade gesprochen habe, ist die Situation, in der einer der Vorgänge während des Prozesses der Aktualisierung der Datenbank und des Löschens zwischengespeicherter Werte fehlschlägt, selbst wenn diese beiden Vorgänge beim ersten Mal nicht fehlschlagen Es gibt eine große Anzahl gleichzeitiger Anforderungen. Die Anwendung liest möglicherweise immer noch inkonsistente Daten.
In ähnlicher Weise unterteilen wir es in zwei Situationen entsprechend unterschiedlicher Lösch- und Aktualisierungsreihenfolgen. In beiden Fällen sind auch unsere Lösungen unterschiedlich.
Situation 1: Zuerst den Cache löschen und dann die Datenbank aktualisieren.
Angenommen, nachdem Thread A den Cache-Wert gelöscht hat, beginnt Thread B, die Daten zu lesen, bevor er Zeit hat, die Datenbank zu aktualisieren (z. B. liegt eine Netzwerkverzögerung vor). Cache fehlt und kann nur aus der Datenbank Pick gelesen werden. Dies führt zu zwei Problemen:
- Thread B liest den alten Wert;
- Thread B liest die Datenbank, wenn der Cache fehlt, und schreibt daher auch den alten Wert in den Cache, was dazu führen kann, dass andere Threads alte Werte lesen aus dem Cache.
Nachdem Thread B die Daten aus der Datenbank gelesen und den Cache aktualisiert hat, beginnt Thread A mit der Aktualisierung der Datenbank. Zu diesem Zeitpunkt sind die Daten im Cache der alte Wert, während die Daten in der Datenbank der neueste Wert sind. und die beiden sind inkonsistent.
Ich verwende eine Tabelle, um diese Situation zusammenzufassen. 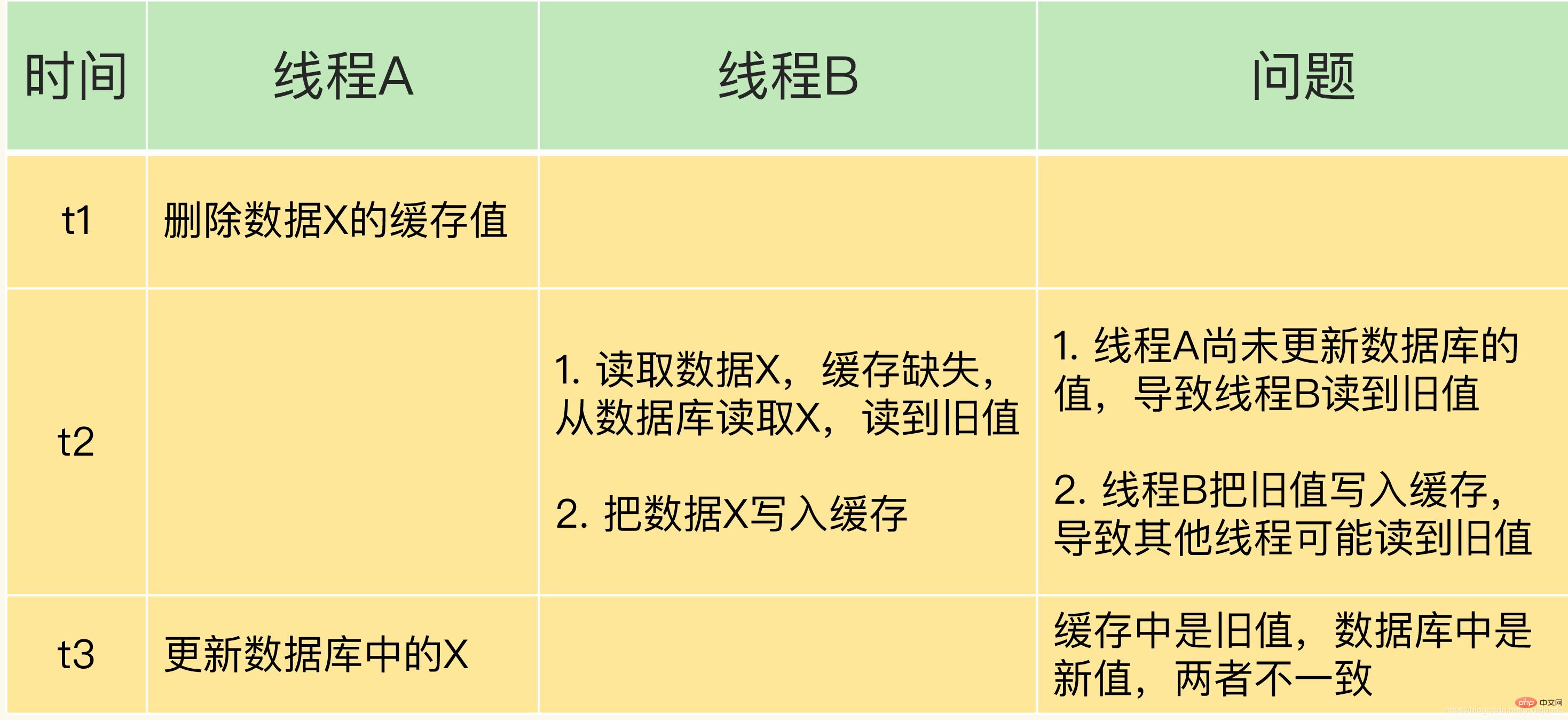
Was soll ich tun? Lassen Sie mich Ihnen eine Lösung anbieten.
Nachdem Thread A den Datenbankwert aktualisiert hat, können wir ihn für eine kurze Zeit ruhen lassen und dann einen Cache-Löschvorgang durchführen.
Der Grund für das Hinzufügen der Ruhephase besteht darin, dass Thread B zuerst Daten aus der Datenbank lesen kann, dann die fehlenden Daten in den Cache schreibt und Thread A sie dann löscht. Daher muss die Zeit, die Thread A zum Ruhen benötigt, länger sein als die Zeit, die Thread B zum Lesen von Daten und zum anschließenden Schreiben in den Cache benötigt. Wie kann man diese Zeit bestimmen? Es wird empfohlen, die Betriebszeit der Threads zum Lesen von Daten und zum Schreiben des Caches während der Ausführung des Geschäftsprogramms zu zählen und auf dieser Grundlage eine Schätzung vorzunehmen.
Auf diese Weise stellen andere Threads beim Lesen von Daten fest, dass der Cache fehlt, und lesen daher den neuesten Wert aus der Datenbank. Da diese Lösung das Löschen nach dem ersten Löschen des zwischengespeicherten Werts um einen bestimmten Zeitraum verzögert, nennen wir sie auch „verzögertes doppeltes Löschen“.
Der folgende Pseudocode ist ein Beispiel für die Lösung „verzögertes doppeltes Löschen“, Sie können einen Blick darauf werfen.
redis.delKey(X) db.update(X) Thread.sleep(N) redis.delKey(X)
Szenario 2: Aktualisieren Sie zuerst den Datenbankwert und löschen Sie dann den Cache-Wert.
Wenn Thread A den Wert in der Datenbank löscht, aber bevor er Zeit hat, den Cache-Wert zu löschen, beginnt Thread B, die Daten zu lesen. Wenn Thread B zu diesem Zeitpunkt den Cache abfragt und einen Cache-Treffer findet, wird dies der Fall sein Lesen Sie die Daten direkt aus dem Cache. Lesen Sie den alten Wert. Wenn jedoch in diesem Fall nicht viele gleichzeitige Anforderungen von anderen Threads zum Lesen des Caches vorliegen, gibt es auch nicht viele Anforderungen zum Lesen des alten Werts. Außerdem löscht Thread A den zwischengespeicherten Wert normalerweise sehr schnell, sodass es beim erneuten Lesen eines anderen Threads zu einem Cache-Fehler kommt und der neueste Wert aus der Datenbank gelesen wird. Daher hat diese Situation weniger Auswirkungen auf das Geschäft.
Ich werde eine weitere Tabelle zeichnen, um Ihnen die Situation zu zeigen, in der zuerst die Datenbank aktualisiert und dann der zwischengespeicherte Wert gelöscht wird. 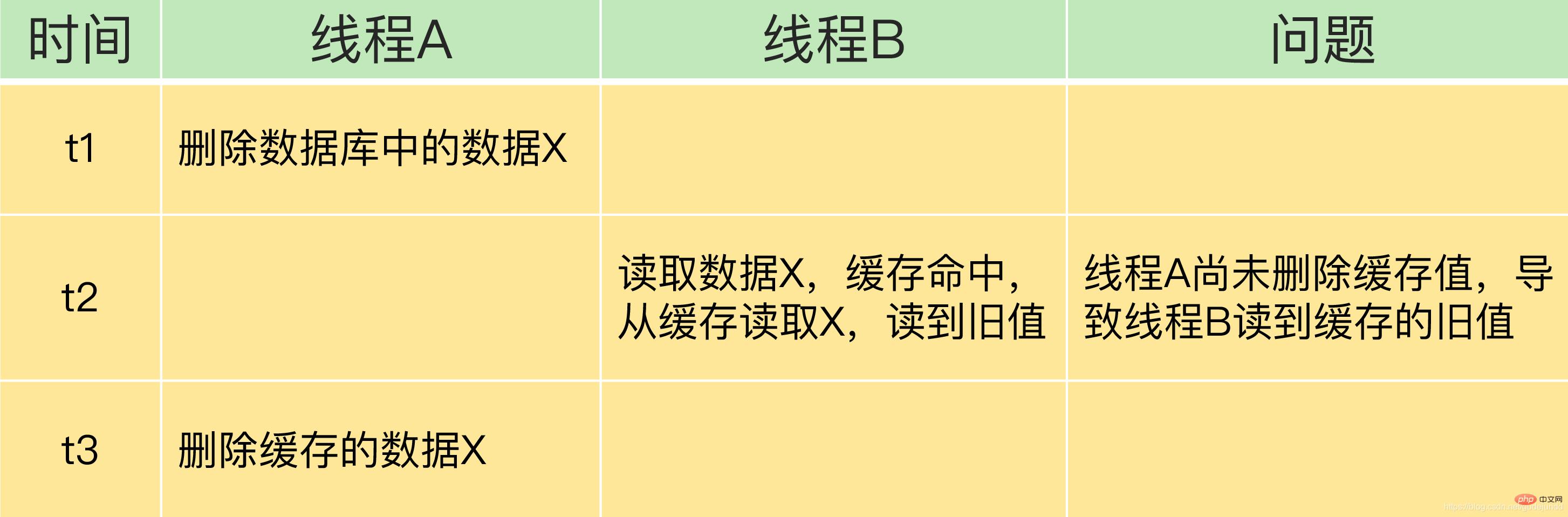
Okay, hier haben wir erfahren, dass die Dateninkonsistenz zwischen Cache und Datenbank im Allgemeinen zwei Gründe hat, und ich habe Ihnen die entsprechende Lösung bereitgestellt.
- Wenn das Löschen zwischengespeicherter Werte oder das Versäumnis, die Datenbank zu aktualisieren, zu Dateninkonsistenzen führt, können Sie den Wiederholungsmechanismus verwenden, um sicherzustellen, dass der Lösch- oder Aktualisierungsvorgang erfolgreich ist.
- In den beiden Schritten Löschen zwischengespeicherter Werte und Aktualisieren der Datenbank gibt es gleichzeitige Lesevorgänge von anderen Threads, was dazu führt, dass andere Threads die alten Werte lesen. Die Lösung besteht darin, das doppelte Löschen zu verzögern.
Empfohlenes Lernen: Redis-Video-Tutorial
Das obige ist der detaillierte Inhalt vonWie löst Redis das Problem der Cache-Inkonsistenz?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist der Unterschied zwischen Swoole und Redis?
- Lassen Sie uns darüber sprechen, wie man mit dem Cache-Hotkey-Problem in Redis umgeht. Häufig verwendete Lösungsfreigabe
- 12 wichtige Punkte, die in Redis-Interviews häufig gefragt werden (mit Antworten)
- Was ist die Verwendung von Incr in der PHP-Verbindung zu Redis?
- Eingehende Analyse des Redis-Einstiegs in die Praxis und der Persistenz (Zusammenfassungsfreigabe)