
Führen Sie Sie durch die Master-Slave-Replikation, Sentinel und Clustering in Redis

- 青灯夜游nach vorne
- 2021-10-15 11:15:012514Durchsuche
Dieser Artikel führt Sie in die relevanten Kenntnisse der Redis-Verteilung ein und führt Sie durch Master-Slave-Replikation, Sentinel und Clustering, um Ihr Redis-Level auf ein höheres Niveau zu heben!

Redis-Video-Tutorial]
- Konfigurationsdatei – Konfigurieren Sie in der Datei redis.conf den Befehl „slaveof ip port“ – Geben Sie den Redis-Client ein, um „slaveof ip port“ auszuführen. Startparameter – ./redis-server --slaveof ip port
- 2, Die Entwicklung der Master-Slave-ReplikationDer Master-Slave-Replikationsmechanismus von Redis war zu Beginn nicht so perfekt wie die 6.x-Version, wurde aber von Version zu Version iteriert. Es hat im Allgemeinen drei Versionen von Iterationen durchlaufen:
- Vor 2.8
- Nach 4.0
- Mit zunehmender Version verbessert sich der Redis-Master-Slave-Replikationsmechanismus allmählich Im Wesentlichen drehen sie sich um die beiden Vorgänge Synchronisierung (Sync) und Befehlsweitergabe:
- Synchronisierung (Sync): bezieht sich auf die Aktualisierung des Datenstatus des Slave-Servers auf den aktuellen Datenstatus des Hauptservers, was hauptsächlich in erfolgt Initialisierung oder anschließende vollständige Synchronisierung.
- 2.1 Vor Version 2.8 2.1.1 Synchronisierung
- Vor Version 2.8 erfordert die Synchronisierung des Slave-Servers mit dem Master-Server den Abschluss des Synchronisierungsbefehls vom Server zum Master-Server:
Vom Server empfangen Nach dem vom Client gesendeten Befehl „slaveof ip prot“ erstellt der Slave-Server eine Socket-Verbindung zum Master-Server basierend auf ip:port
Nachdem der Socket erfolgreich mit dem Master-Server verbunden wurde, wird der Slave-Server erstellt ordnet dem Master-Server eine dedizierte Socket-Verbindung zu, die für die Verarbeitung von Replikationsarbeiten, die Verarbeitung nachfolgender RDB-Dateien und die vom Master-Server gesendeten weitergegebenen Befehle verwendet wird. 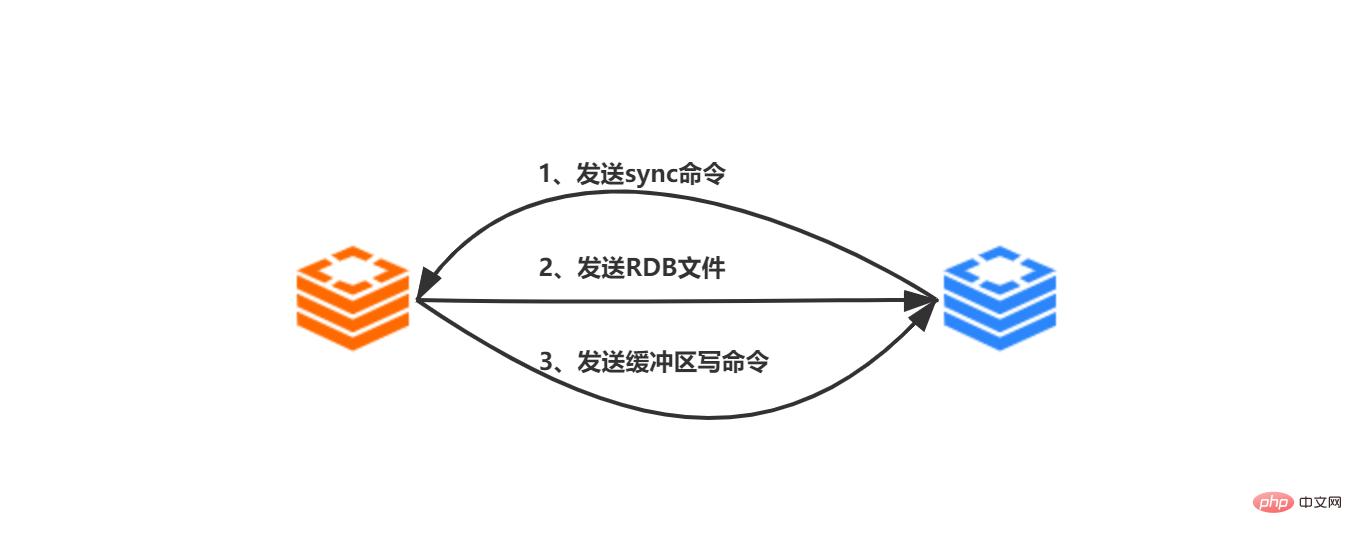
- Replikation starten und Synchronisierungsbefehle vom Server an den Master-Server senden Der Master-Server empfängt den Synchronisierungsbefehl. Führen Sie anschließend den Befehl bgsave aus. Der Unterprozess des Hauptprozesszweigs des Hauptservers generiert eine RDB-Datei und zeichnet gleichzeitig alle Schreibvorgänge nach dem RDB-Snapshot auf wird im Puffer generiert
- Nachdem der Befehl bgsave ausgeführt wurde, generiert der Hauptserver Die RDB-Datei wird an den Slave-Server gesendet. Nach dem Empfang der RDB-Datei vom Slave-Server löscht dieser zunächst alle seine eigenen Daten. Laden Sie dann die RDB-Datei und aktualisieren Sie ihren eigenen Datenstatus auf den Datenstatus der RDB-Datei des Master-Servers
- Der Master-Server sendet den Pufferschreibbefehl an den Slave-Server, empfängt den Befehl vom Server und führt ihn aus Es.
- Der Synchronisierungsschritt der Master-Slave-Replikation ist abgeschlossen
- 2.1.2 Befehlsweitergabe
Nach Abschluss der Synchronisierungsarbeiten muss der Master-Slave die Konsistenz des Datenstatus durch Befehlsweitergabe aufrechterhalten. Wie in der folgenden Abbildung gezeigt, löscht der Master-Dienst nach Abschluss der Synchronisierungsarbeiten zwischen dem aktuellen Master- und Slave-Server K6, nachdem er die DEL K6-Anweisung vom Client erhalten hat. Zu diesem Zeitpunkt ist K6 noch auf dem Slave-Server vorhanden Der Master-Slave-Datenstatus ist inkonsistent. Um den konsistenten Status der Master- und Slave-Server aufrechtzuerhalten, gibt der Master-Server Befehle weiter, die dazu führen, dass sich sein eigener Datenstatus zur Ausführung an den Slave-Server ändert. Wenn der Slave-Server denselben Befehl ebenfalls ausführt, ändert sich der Datenstatus zwischen den Master- und Slave-Server bleiben konsistent.
- 2.1.3 Mängel
Der Master-Server führt BGSAVE aus, um RDB-Dateien zu generieren, die viel CPU-, Festplatten-E/A- und Speicherressourcen beanspruchen
Die Der Master-Server sendet die generierten RDB-Dateien. Wenn Sie sie an den Slave-Server weitergeben, wird viel Netzwerkbandbreite beansprucht.
Der Empfang und das Laden der RDB-Datei vom Server führt dazu, dass der Slave-Server blockiert wird und keine Dienste bereitstellen kann
Wie aus den oben genannten drei Punkten ersichtlich ist, führt der Synchronisierungsbefehl nicht nur dazu, dass der Master eine Verringerung der Reaktionsfähigkeit des Servers verursacht, sondern auch dazu, dass der Slave-Server während dieser Zeit die Bereitstellung externer Dienste verweigert. - Inkrementell Synchronisierung Für die Replikation nach Trennung und Wiederverbindung werden je nach Situation unterschiedliche Maßnahmen ergriffen. Wenn die Bedingungen dies zulassen, wird nur ein Teil der im Dienst fehlenden Daten gesendet. 2.2.2 So implementieren Sie psync Replikationsrückstand)
- Server-Lauf-ID (Lauf-ID)
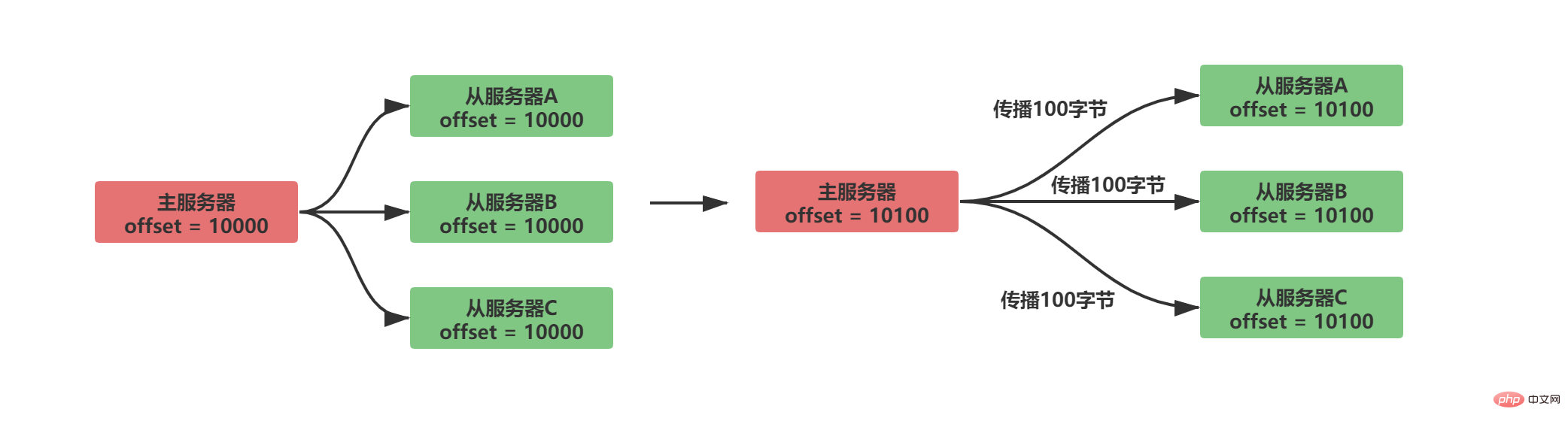
Ein Replikations-Offset wird im Master-Server und Slave-Server beibehalten
-
Der Master-Server sendet Daten an Der Slave-Dienst verteilt N Datenbytes und der Replikationsoffset des Masterdienstes erhöht sich um N
Der Slave-Server empfängt die vom Master-Server gesendeten Daten, empfängt N Datenbytes und der Slave-Server Der Replikationsoffset erhöht sich um N
- Durch den Vergleich, ob die Replikationsoffsets zwischen dem Master- und dem Slave-Server gleich sind, können Sie feststellen, ob der Datenstatus zwischen dem Master- und dem Slave-Server ist ist Sei konsequent.
Angenommen, dass A/B zu diesem Zeitpunkt normal weitergegeben wird und der Slave-Server C getrennt ist, dann wird die folgende Situation eintreten:
- Offensichtlich mit dem Replikationsoffset, nachdem der Slave-Server C getrennt und wieder verbunden wurde Der Master-Server sendet nur die fehlenden 100 Byte Daten vom Server.
Aus dem oben Gesagten können wir keine Mängel in der Master-Slave-Replikation von Versionen vor 2.8 erkennen. Dies liegt daran, dass wir Netzwerkschwankungen nicht berücksichtigt haben. Brüder, die sich mit der Verteilung auskennen, müssen von der CAP-Theorie gehört haben. In der CAP-Theorie muss P (Partitionsnetzwerkpartition) vorhanden sein, und die Redis-Master-Slave-Replikation ist keine Ausnahme. Wenn ein Netzwerkfehler zwischen dem Master- und dem Slave-Server auftritt, führt dies dazu, dass die Kommunikation zwischen dem Slave-Server und dem Master-Server für einen bestimmten Zeitraum ausfällt. Wenn der Slave-Server erneut eine Verbindung zum Master-Server herstellt, ändert sich der Datenstatus des Master-Servers Wenn sich in diesem Zeitraum Änderungen ergeben, kommt es zu Inkonsistenzen im Datenstatus des Master-Slave-Servers zwischen den Servern. In Master-Slave-Replikationsversionen vor Redis 2.8 besteht die Möglichkeit, diese Datenstatusinkonsistenz zu beheben, darin, den Synchronisierungsbefehl erneut zu senden. Obwohl die Synchronisierung sicherstellen kann, dass der Datenstatus der Master- und Slave-Server konsistent ist, ist es offensichtlich, dass die Synchronisierung ein sehr ressourcenintensiver Vorgang ist.
Befehlsausführung synchronisieren, die vom Master- und Slave-Server benötigten Ressourcen:
2.2 Version 2.8-4.0
2.2.1 VerbesserungenFür Versionen vor 2.8 hat Redis die Datenstatussynchronisierung nach der erneuten Verbindung vom Server nach 2.8 verbessert. Die Verbesserungsrichtung besteht darin, das Auftreten einer vollständigen Neusynchronisierung zu reduzieren und eine teilweise Neusynchronisierung so weit wie möglich zu nutzen. Nach Version 2.8 wird der Befehl psync anstelle des Befehls sync verwendet, um Synchronisierungsvorgänge durchzuführen. Der Befehl psync verfügt sowohl über vollständige als auch inkrementelle Synchronisierungsfunktionen:
- Die vollständige Synchronisierung stimmt mit der vorherigen Version überein (sync)
Die normale Synchronisationssituation ist wie folgt:
2.2.2.2 Kopier-Backlog-Puffer
Um den Offset anzupassen, speichert der Kopierrückstandspuffer nicht nur den Dateninhalt, sondern zeichnet auch den jedem Byte entsprechenden Offset auf: 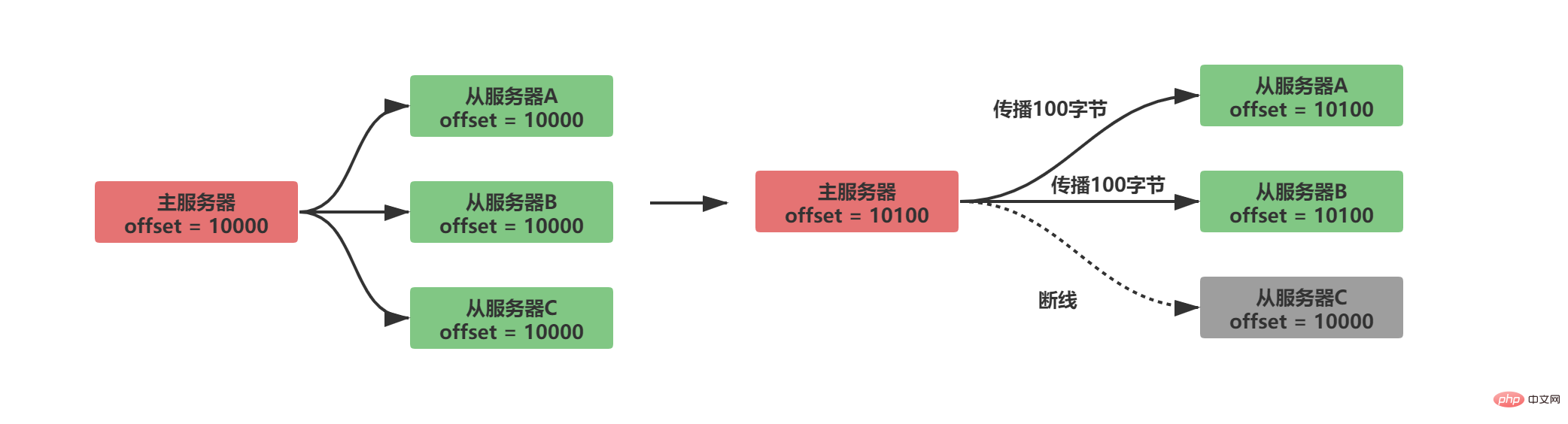
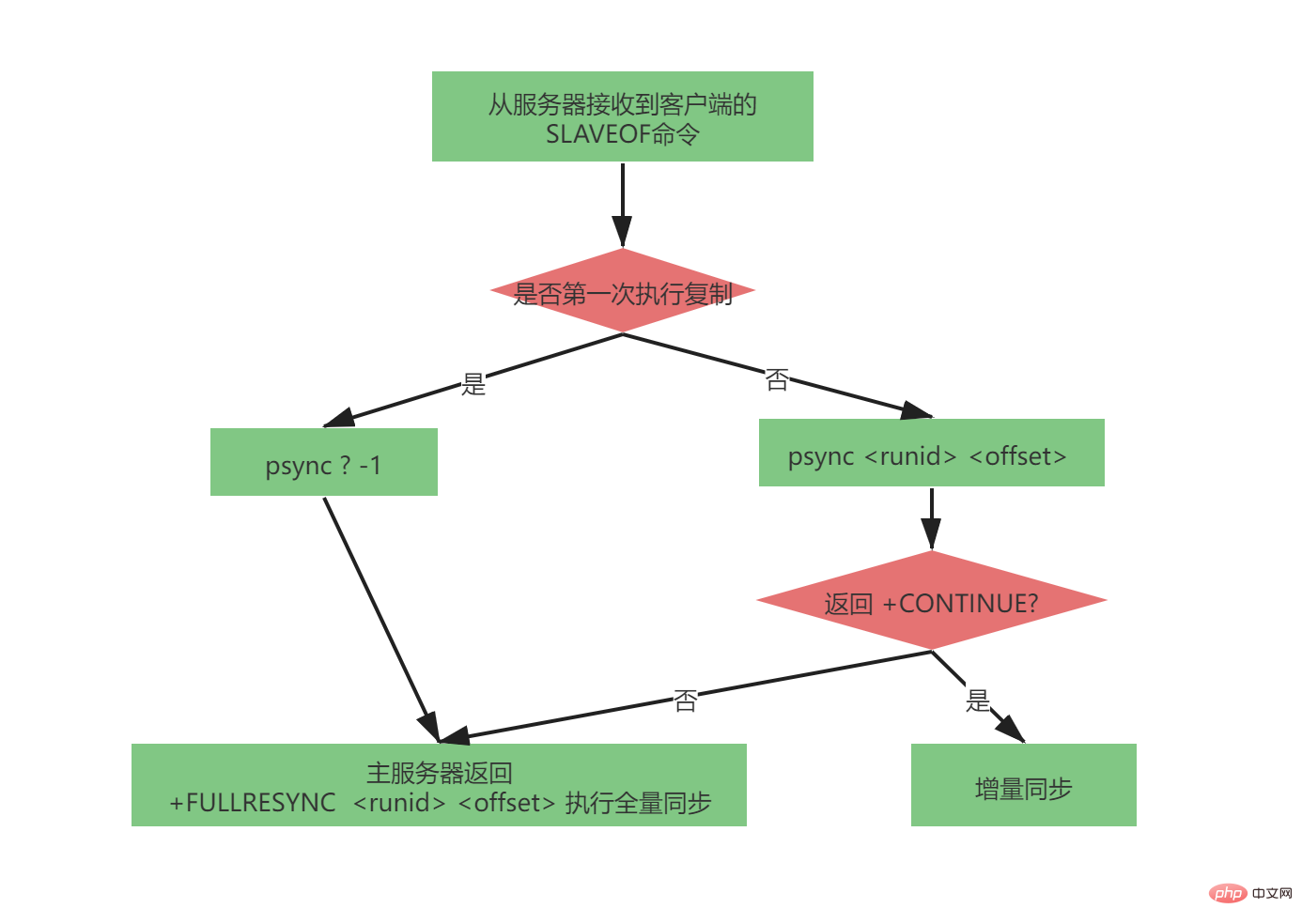
Wenn der Slave-Server getrennt und wieder verbunden wird, schließlich der Slave Der Server sendet über den Befehl psync seinen eigenen Replikationsoffset (Offset) an den Masterserver. Der Masterserver kann diesen Offset verwenden, um zu bestimmen, ob eine inkrementelle Weitergabe oder eine vollständige Synchronisierung durchgeführt werden soll.
Wenn sich die Daten bei Offset + 1 noch im Kopierrückstandspuffer befinden, führen Sie einen inkrementellen Synchronisierungsvorgang aus.
Andernfalls führen Sie einen vollständigen Synchronisierungsvorgang im Einklang mit der Synchronisierung durch.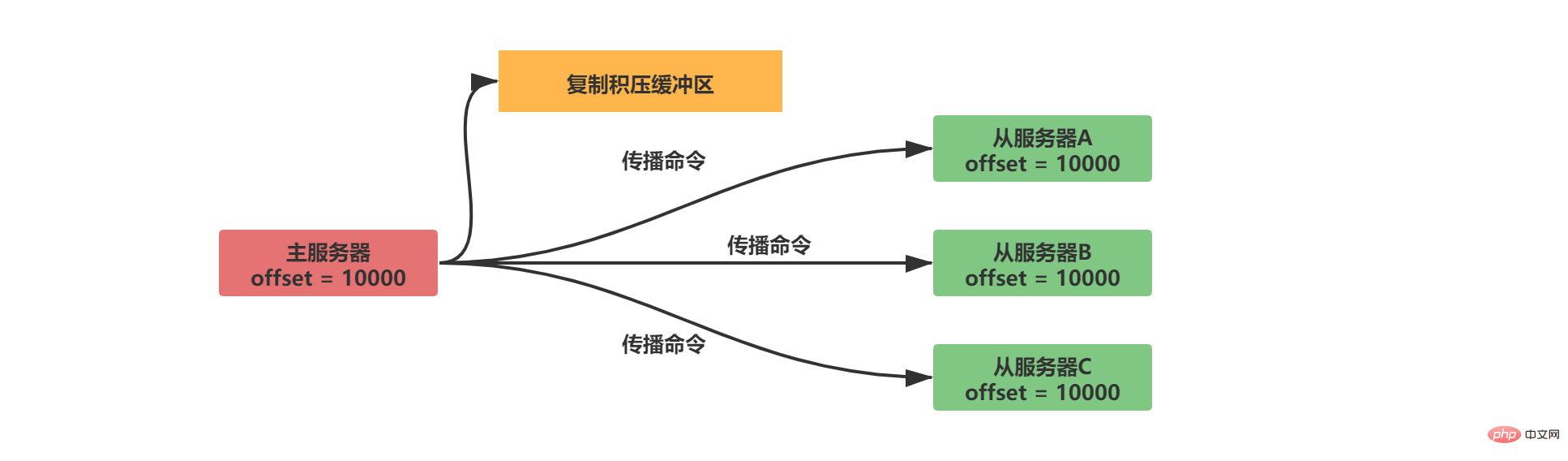
Die Standardpuffergröße für den Kopierrückstand von Redis beträgt 1 MB. Wie wird sie eingestellt, wenn Sie sie anpassen müssen? Natürlich möchten wir so viel wie möglich die inkrementelle Synchronisierung verwenden, aber wir möchten nicht, dass der Puffer zu viel Speicherplatz beansprucht. Dann können wir die Größe des Replikations-Backlog-Puffers S festlegen, indem wir die Wiederverbindungszeit T nach der Trennung des Redis-Slave-Dienstes und die Speichergröße M der vom Redis-Master-Server pro Sekunde empfangenen Schreibbefehle schätzen.
S = 2 * M * T
Beachten Sie, dass die 2-fache Erweiterung hier dazu dient, einen gewissen Spielraum zu lassen, um sicherzustellen, dass die meisten Trennungen und Wiederverbindungen eine inkrementelle Synchronisierung verwenden können. 2.2.2.3 Server, auf dem die ID ausgeführt wird Tatsächlich gibt es eine andere Situation, die nicht berücksichtigt wurde: Wenn der Master-Server ausfällt, wird ein Slave-Server als neuer Master-Server ausgewählt. In diesem Fall können wir ihn durch Vergleich der laufenden ID unterscheiden.
Die Lauf-ID (Lauf-ID) besteht aus 40 zufälligen Hexadezimalzeichenfolgen, die beim Starten des Servers automatisch generiert werden. Sowohl der Master-Dienst als auch der Slave-Server generieren die Lauf-ID.
- Wenn der Slave-Server die des Master-Servers synchronisiert Beim ersten Mal, wenn Daten generiert werden, sendet der Master-Server seine eigene laufende ID an den Slave-Server und der Slave-Server speichert sie in der RDB-Datei
- Wenn der Slave-Server getrennt und wieder verbunden wird, sendet der Slave-Server Wenn die Server-Lauf-ID übereinstimmt, beweist dies, dass sich der Hauptserver nicht geändert hat. Sie können eine inkrementelle Synchronisierung versuchen. Wenn die Server-Lauf-ID nicht übereinstimmt, führen Sie eine vollständige Synchronisierung durch Synchronisierung
- 2.2.3 Vollständiger ppsync
Vollständig Der psync-Prozess ist sehr komplex und in der Master-Slave-Replikationsversion 2.8-4.0 sehr vollständig. Die vom psync-Befehl gesendeten Parameter lauten wie folgt:
psync
Wenn der Slave-Server keinen Master-Server repliziert hat (es ist nicht das erste Mal, dass der Master-Slave repliziert, da sich der Master-Server ändern kann), aber die erste vollständige Kopie des Slave-Servers sendet:
psync ? -1
Der vollständige psync-Prozess ist wie folgt:
gibt OK vom Server an den Befehlsinitiator zurück (dies ist ein asynchroner Vorgang, geben Sie zuerst OK zurück und speichern Sie dann die Adress- und Portinformationen)
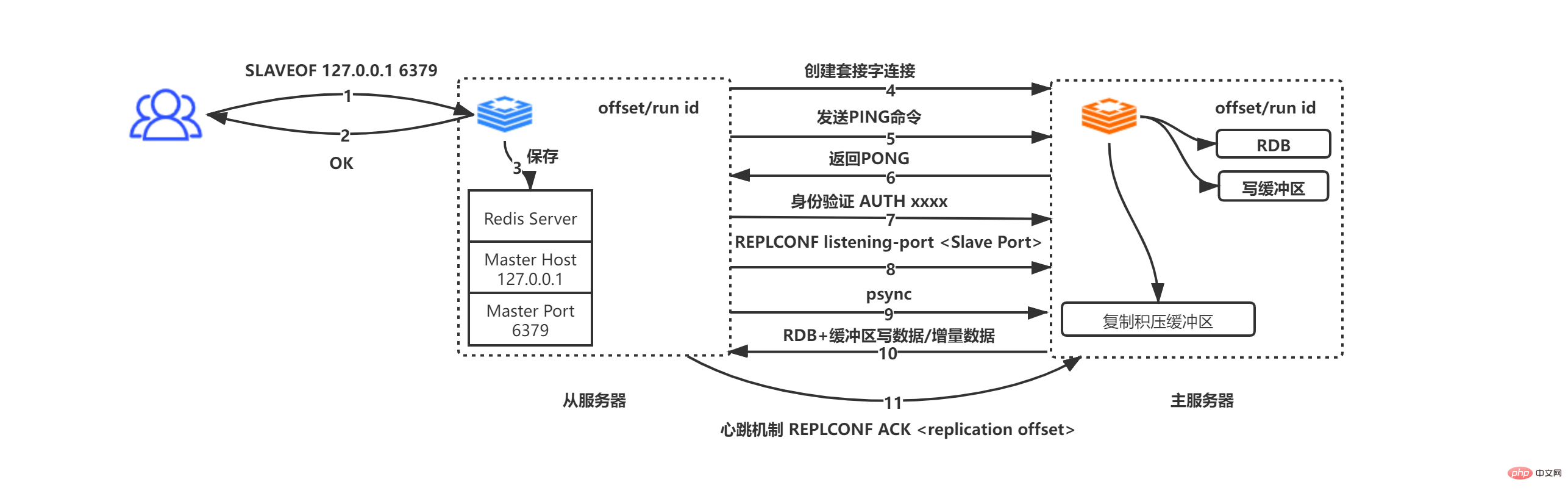
- Speichern Die IP-Adresse und die Portinformationen vom Server zum Master-Host und Master-Port.
- Der Slave-Server initiiert aktiv eine Socket-Verbindung zum Master-Server basierend auf dem Master-Host und dem Master-Port. Gleichzeitig wird der Slave-Dienst aktiviert Verknüpfen Sie einen Dateiereignishandler, der speziell zum Kopieren von Dateien verwendet wird, mit dieser Socket-Verbindung für die spätere Verwendung des Kopierens von RDB-Dateien und anderer Arbeiten. Der Master-Server empfängt die Socket-Verbindungsanforderung vom Slave-Server und erstellt eine entsprechende Socket-Verbindung für die Anforderung. und betrachtet einen Client vom Slave-Server (bei der Master-Slave-Replikation sind der Master-Server und der Slave-Server tatsächlich Clients und Server voneinander)
- Die Socket-Verbindung wird hergestellt. Der Slave-Server sendet aktiv einen PING-Befehl Wenn der Master-Server innerhalb des angegebenen Timeout-Zeitraums PONG zurückgibt, beweist dies, dass die Socket-Verbindung verfügbar ist. Andernfalls wird die Verbindung getrennt und erneut hergestellt. Wenn der Master-Server ein Kennwort festgelegt hat (Masterauth), sendet der Slave-Server Senden Sie den Befehl AUTH masterauth zur Authentifizierung an den Master-Server. Beachten Sie, dass, wenn der Slave-Server ein Passwort sendet, der Master-Server jedoch kein Passwort festlegt, der Master-Server einen Fehler sendet, bei dem kein Passwort festgelegt ist Der Server sendet einen NOAUTH-Fehler. Wenn die Passwörter nicht übereinstimmen, sendet der Master-Server einen Fehler wegen eines ungültigen Passworts.
- Der Slave-Server sendet REPLCONF Listening-Port xxxx (xxxx stellt den Port des Slave-Servers dar) an den Master-Server. Nach Erhalt des Befehls speichert der Hauptserver die Daten. Wenn der Client die INFO-Replikation verwendet, um die Master-Slave-Informationen abzufragen, kann er die Daten zurückgeben. Senden Sie den psync-Befehl vom Server Die beiden psync-Situationen im Bild oben
- Der Master-Server und der Slave-Server verwenden den Heartbeat-Paketmechanismus, um festzustellen, ob Die Verbindung wird getrennt. Der Slave-Server sendet alle 1 Sekunde einen Befehl an den Master-Server, REPLCONF ACL-Offset (Replikations-Offset des Slave-Servers). Wenn die Offsets nicht gleich sind, kann der Master sicherstellen Der Server ergreift inkrementelle/vollständige Synchronisierungsmaßnahmen, um einen konsistenten Datenstatus zwischen Master und Slave sicherzustellen (die Wahl von inkrementell/vollständig hängt davon ab, ob sich die Daten bei Offset+1 noch im Replikations-Backlog-Puffer befinden)
2.3 Version 4.0
Redis Version 2.8-4.0 bietet noch Raum für Verbesserungen. Kann eine inkrementelle Synchronisierung durchgeführt werden, wenn der Hauptserver gewechselt wird? Daher wurde die Redis 4.0-Version optimiert, um dieses Problem zu lösen, und psync wurde auf psync2.0 aktualisiert. pync2.0 hat die laufende ID des Servers aufgegeben und stattdessen replid und replid2 verwendet. Replid speichert die laufende ID des aktuellen Hauptservers und replid2 speichert die laufende ID des vorherigen Hauptservers.
Replikationsoffset
Replikationsrückstand
Master-Server-Lauf-ID (Replid)
Letzter Master-Server-Lauf-ID (Replid2)
Durch Replid und Mit replid2 können wir das Problem der Inkrementierung lösen Synchronisierung beim Wechsel des Hauptservers:
Wenn Replid gleich der laufenden ID des aktuellen Hauptservers ist, dann bestimmen Sie die Synchronisierungsmethode inkrementelle/vollständige Synchronisierung
Wenn Replid nicht gleich ist, dann bestimmen Sie, ob Replicad2 ist gleich (unabhängig davon, ob sie zum Slave-Server des vorherigen Master-Servers gehören). Wenn sie gleich sind, können Sie immer noch die inkrementelle/vollständige Synchronisierung wählen. Wenn sie nicht gleich sind, können Sie nur eine vollständige Synchronisierung durchführen.
2. Sentinel
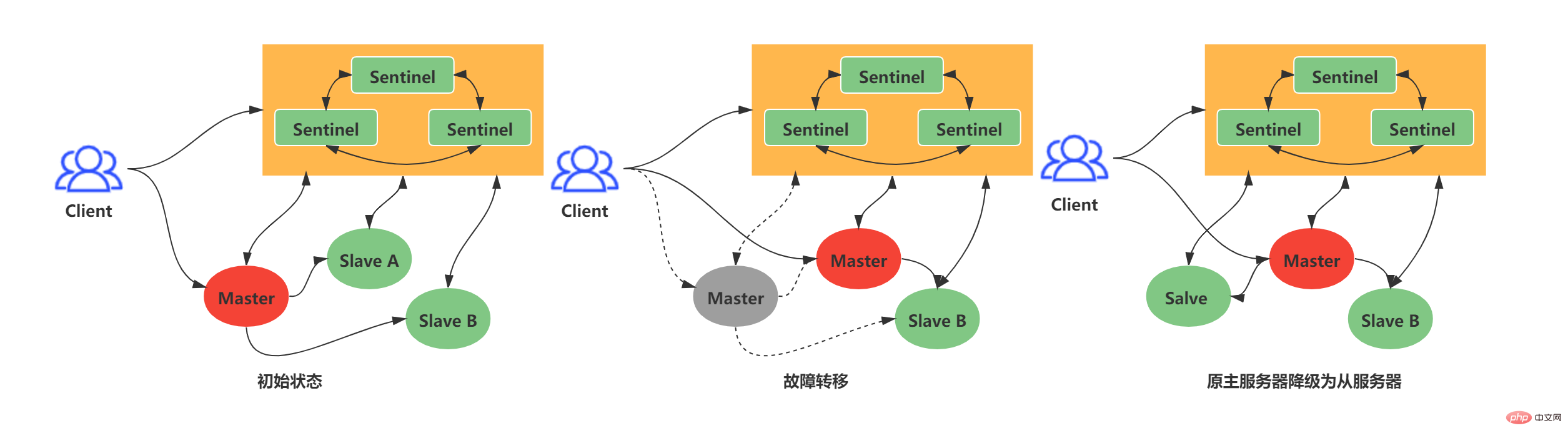
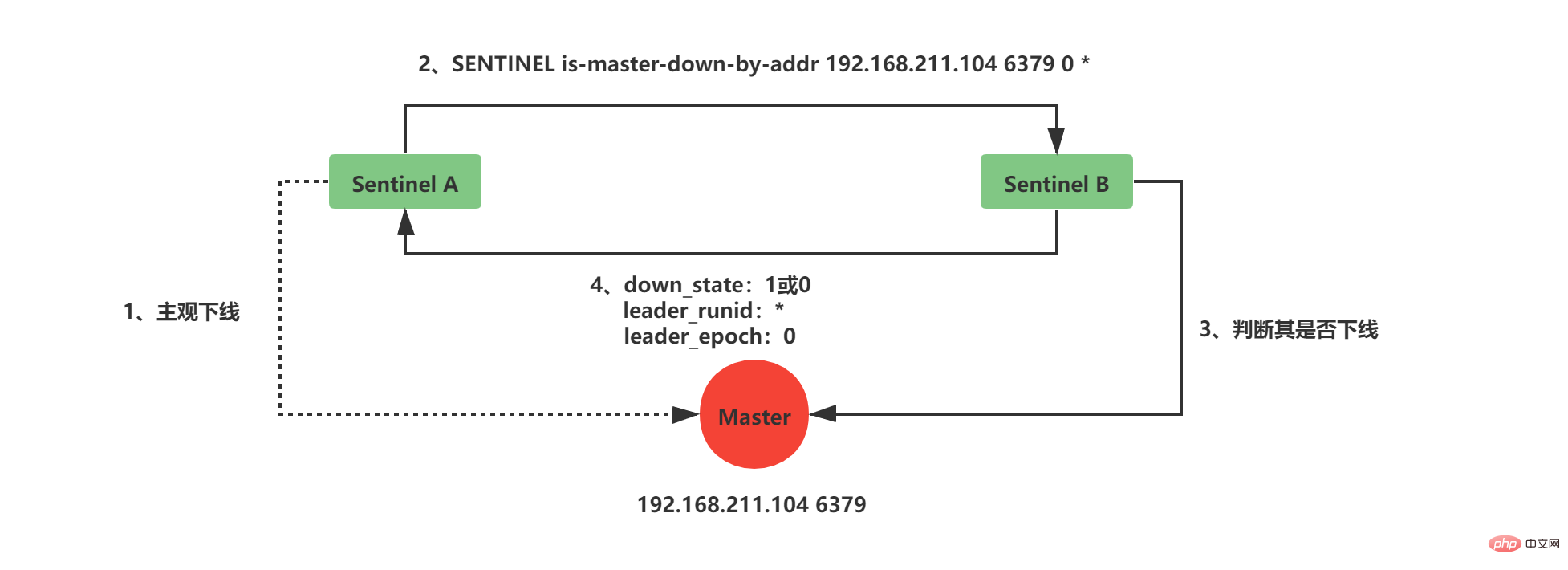
1. Die Master-Slave-Replikation legt den Grundstein für die Redis-Verteilung, aber mit der normalen Master-Slave-Replikation kann keine hohe Verfügbarkeit erreicht werden. Im normalen Master-Slave-Replikationsmodus kann das Betriebs- und Wartungspersonal den Master-Server nur manuell wechseln, wenn der Master-Server ausfällt. Offensichtlich ist diese Lösung nicht ratsam. Als Reaktion auf die oben genannte Situation hat Redis offiziell eine Hochverfügbarkeitslösung eingeführt, die Knotenausfällen widerstehen kann – Redis Sentinel. Redis Sentinel: Ein Sentinel-System, das aus einer oder mehreren Sentinel-Instanzen besteht. Es kann eine beliebige Anzahl von Master- und Slave-Servern überwachen. Wenn der überwachte Master-Server ausfällt, wird der Master-Server automatisch offline geschaltet und der Slave-Server wird auf einen neuen Master aktualisiert Server.
Das folgende Beispiel: Wenn der alte Master länger als die vom Benutzer festgelegte Obergrenze der Offline-Zeit offline ist, führt das Sentinel-System einen Failover-Vorgang auf dem alten Master durch. Der Failover-Vorgang umfasst drei Schritte:
- Wählen Sie Daten im Slave aus. Der neueste dient als neuer Master.
- Sendet neue Replikationsanweisungen an andere Slaves, sodass andere Slave-Server zu Slaves des neuen Masters werden können.
- Überwachen Sie weiterhin den alten Master und prüfen Sie ggf geht online, setzt den alten Master auf den neuen Master Slave
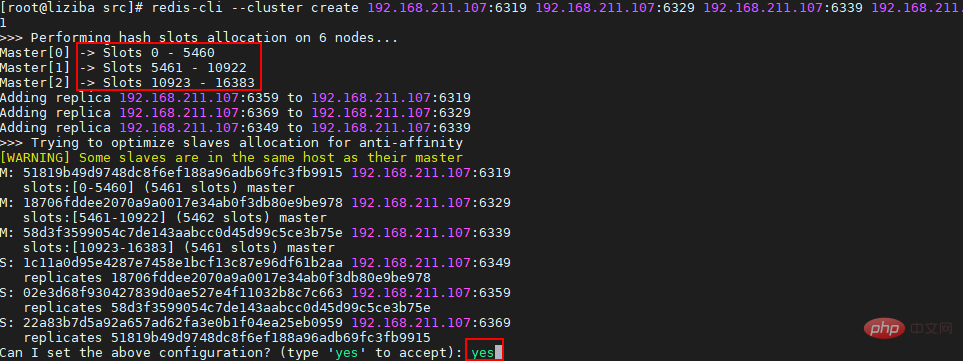
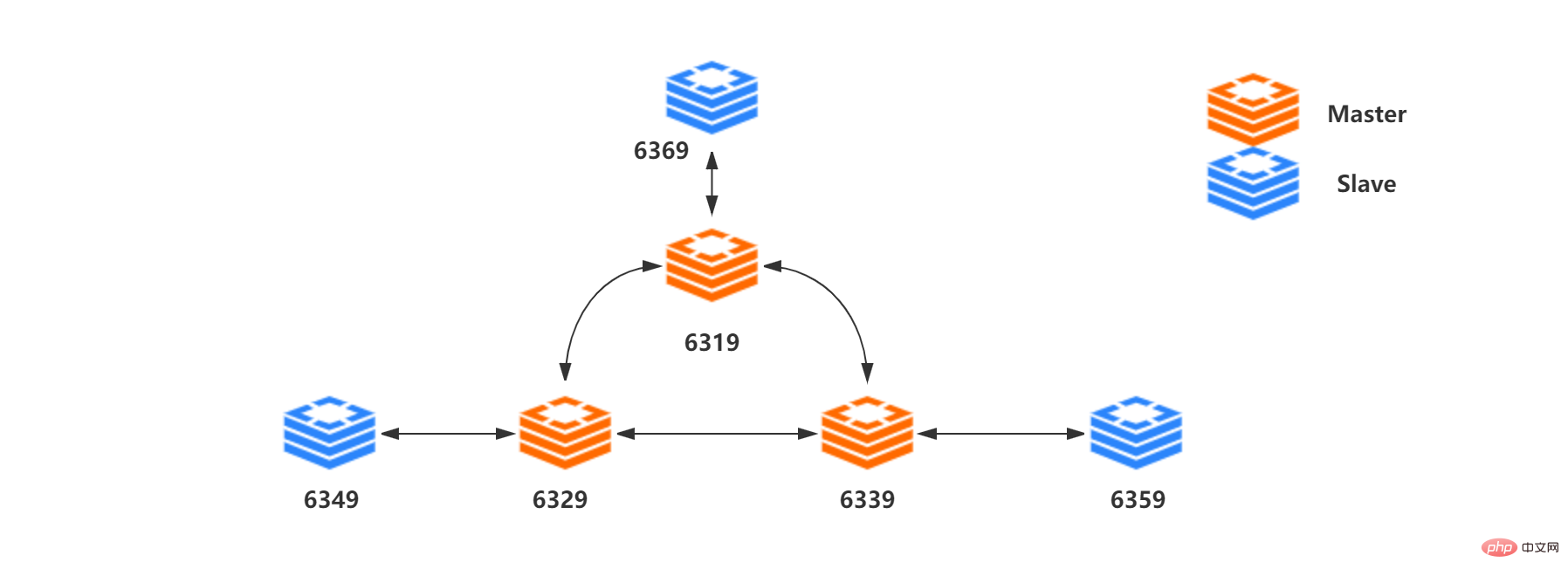
| Knotenrolle | Port | 192.168.211.104 192.168.211.105 | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
6 379/ 263792. Sentinel-Initialisierung und Netzwerkverbindung: Es gibt nichts Besonderes an Sentinel. Es handelt sich um einen einfacheren Redis-Server, der beim Start verschiedene Befehlstabellen und Konfigurationsdateien lädt weniger Befehle und einige Sonderfunktionen. Wenn ein Sentinel gestartet wird, muss er die folgenden Schritte durchlaufen:
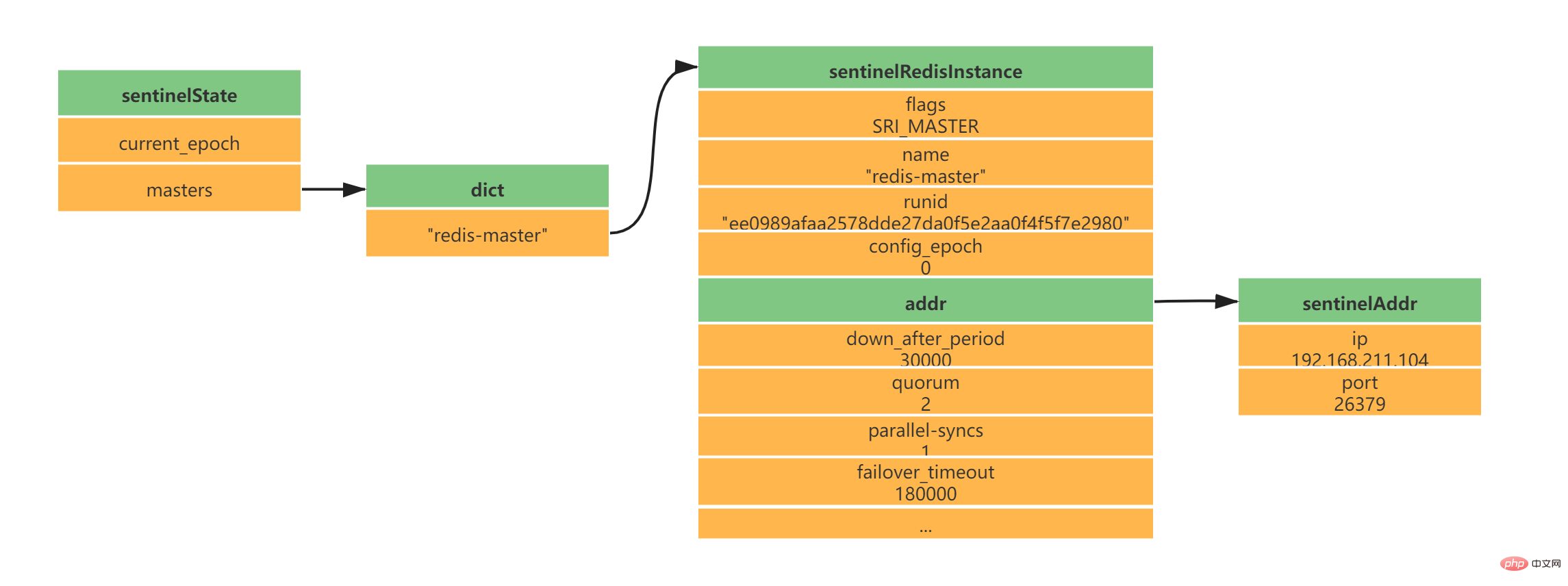
daemonize yes port 26379 protected-mode no dir "/usr/local/soft/redis-6.2.4/sentinel-tmp" sentinel monitor redis-master 192.168.211.104 6379 2 sentinel down-after-milliseconds redis-master 30000 sentinel failover-timeout redis-master 180000 sentinel parallel-syncs redis-master 1 sentinelRedisInstance-Instanz speichert die Informationen des Redis-Servers (der Master-Server, der Slave-Server und die Sentinel-Informationen werden alle in dieser Instanz gespeichert). .typedef struct sentinelRedisInstance {
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
char *name;
// 服务器运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
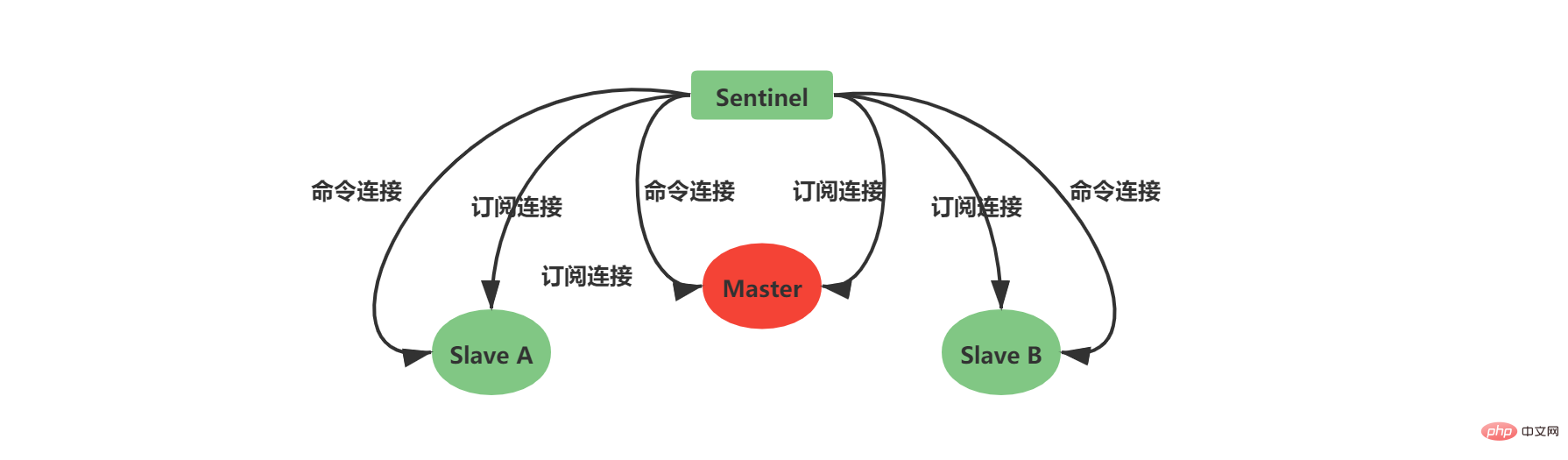
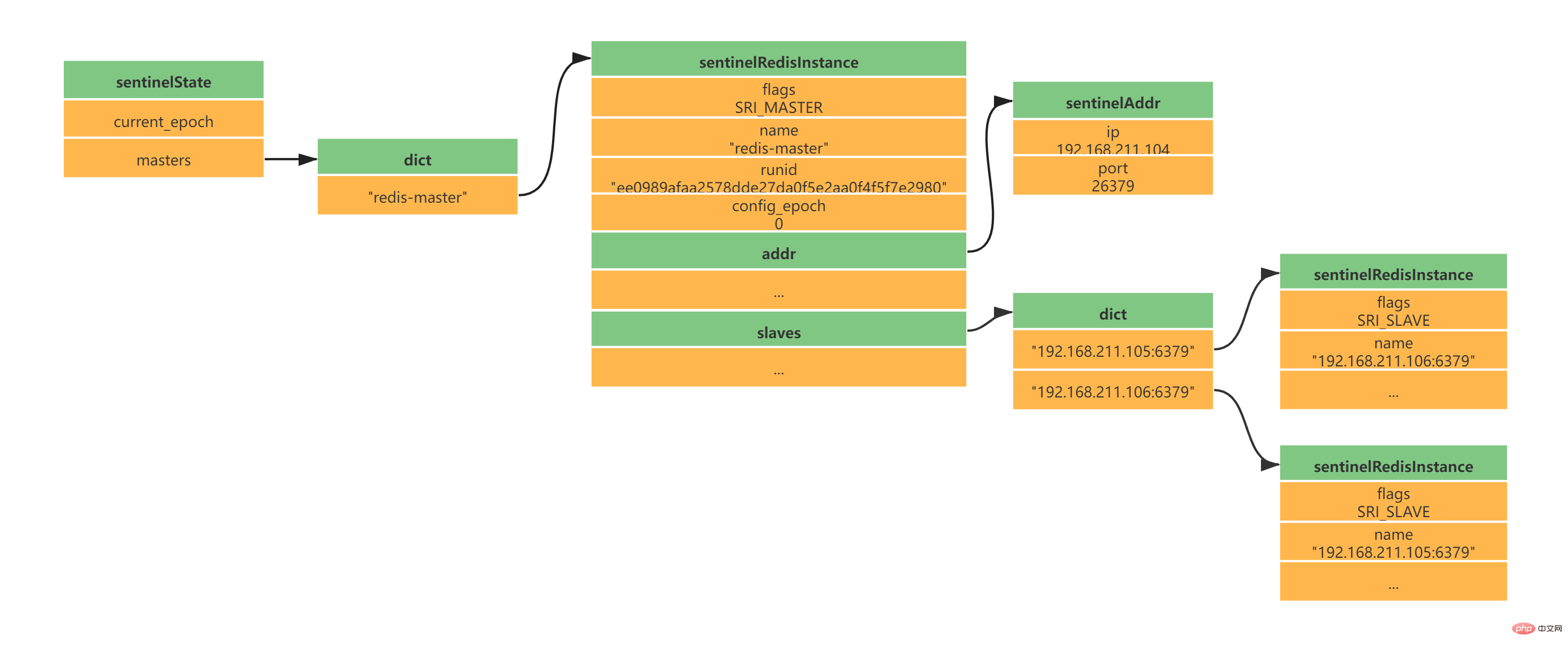
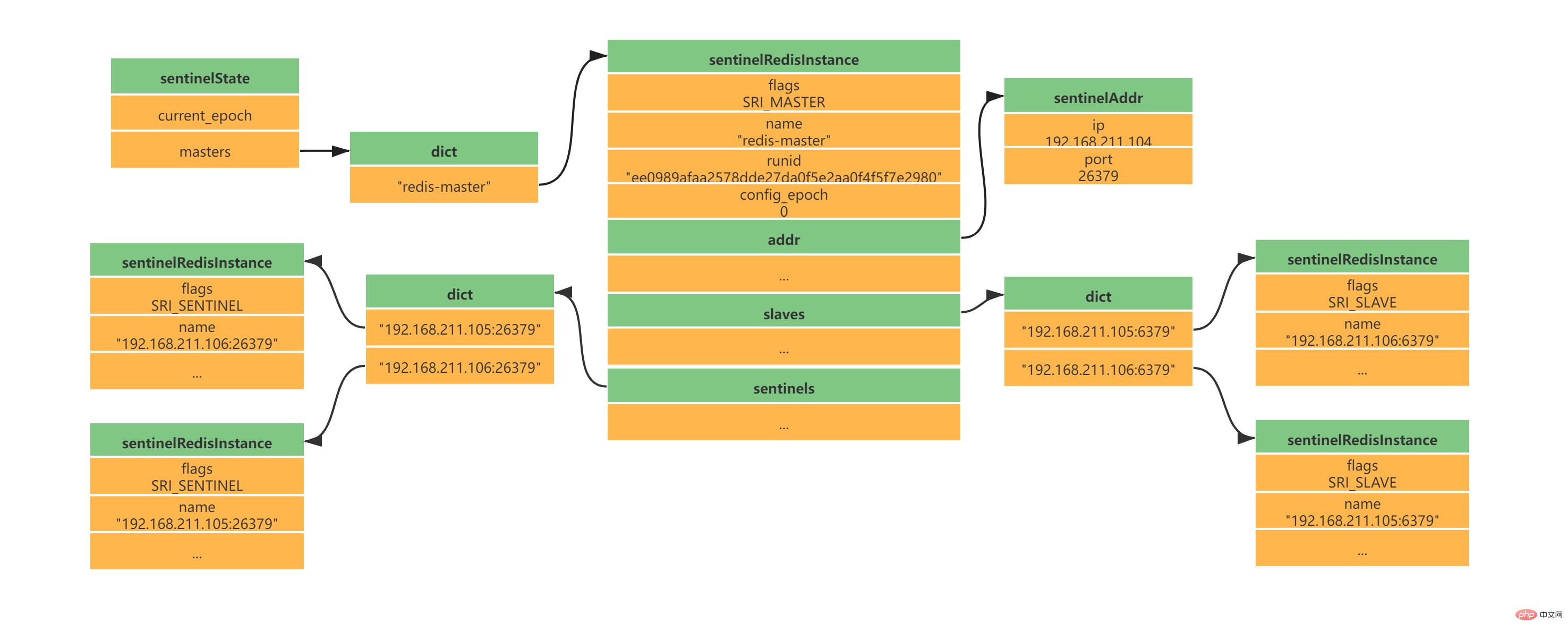
} sentinelRedisInstance;Gemäß der obigen Konfiguration von einem Master und zwei Slaves erhalten Sie die folgende Instanzstruktur: 2.5 Erstellen Sie eine Netzwerkverbindung zum Master-ServerNachdem die Instanzstruktur initialisiert wurde, beginnt Sentinel damit Erstellen Sie eine Netzwerkverbindung zum Master. In diesem Schritt wird Sentinel zum Client des Masters. Zwischen Sentinel und Master werden eine Befehlsverbindung und eine Abonnementverbindung erstellt: Die Befehlsverbindung wird verwendet, um Master-Slave-Informationen zu erhalten.
Master-eigene Informationen Slave-Informationen unter dem Master
|




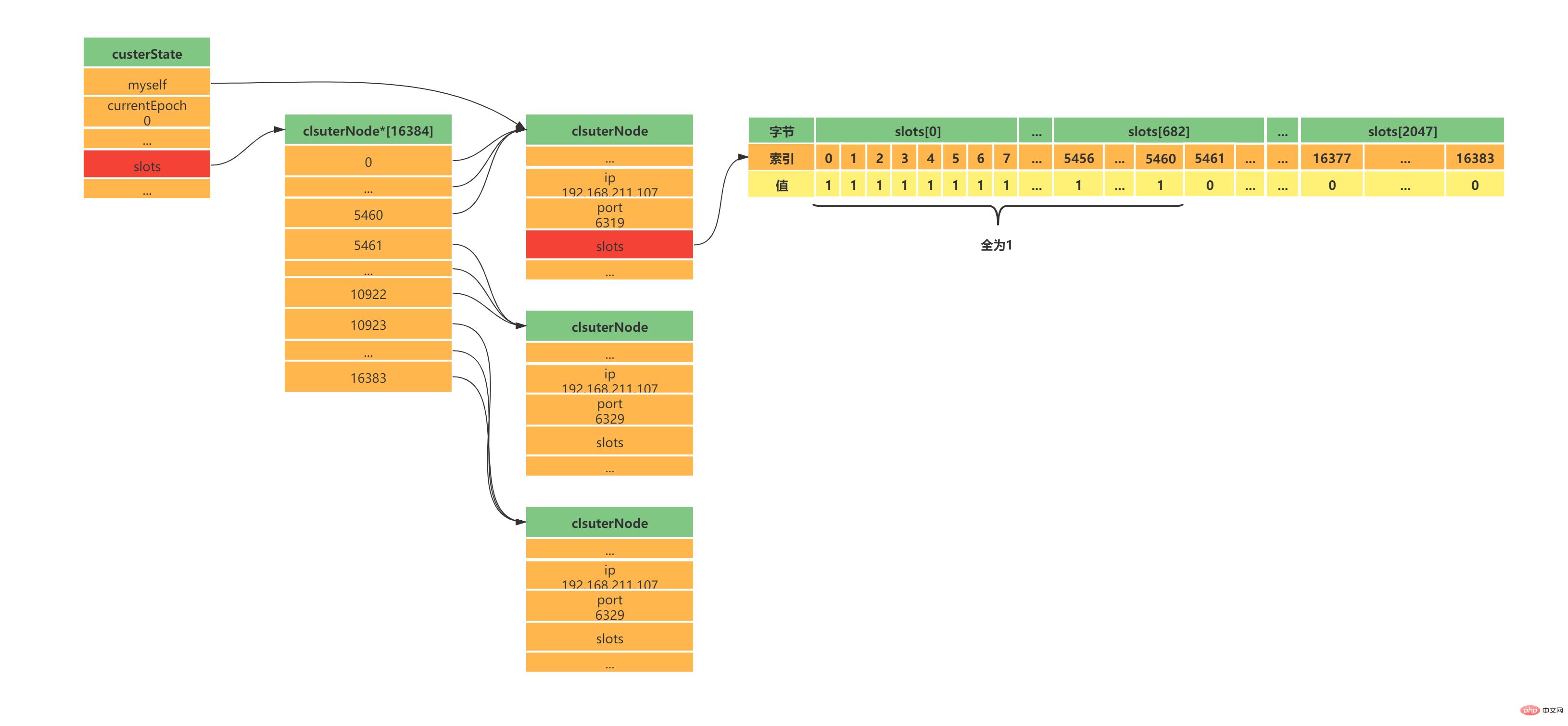


Das obige ist der detaillierte Inhalt vonFühren Sie Sie durch die Master-Slave-Replikation, Sentinel und Clustering in Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Vertiefendes Verständnis des Datenkonsistenzsynchronisationsprinzips der Master-Slave-Architektur in Redis
- So erreichen Sie eine schnelle Wiederherstellung und Beständigkeit ohne Angst vor Ausfallzeiten in Redis
- Führen Sie Sie Schritt für Schritt durch die Verwendung von Redis + Bitmap, um umfangreiche Datenstatistiken auf Milliardenebene zu erstellen
- Erfahren Sie in einem Artikel mehr über die RDB- und AOP-Persistenz in Redis
- Lassen Sie uns über die Master-Slave-Replikation in Redis sprechen
- Eine kurze Diskussion über die Installations- und Konfigurationsmethoden von Bloom-Filtern in Redis