
Heim >Datenbank >MySQL-Tutorial >Detailliertes Verständnis von Sperren in MySQL (globale Sperren, Sperren auf Tabellenebene, Zeilensperren)
Detailliertes Verständnis von Sperren in MySQL (globale Sperren, Sperren auf Tabellenebene, Zeilensperren)

- 青灯夜游nach vorne
- 2021-08-31 10:43:552205Durchsuche
Dieser Artikel wird Ihnen helfen, die Sperren in MySQL zu verstehen und die globalen Sperren, Sperren auf Tabellenebene und Zeilensperren von MySQL vorzustellen. Ich hoffe, er wird Ihnen hilfreich sein!

Je nach Sperrumfang lassen sich die Sperren in MySQL grob in drei Kategorien einteilen: globale Sperren, Sperren auf Tabellenebene und Zeilensperren
1. Globale Sperren
Globale Sperren sperren die gesamte Datenbank Beispiel. MySQL bietet eine Methode zum Hinzufügen einer globalen Lesesperre. Der Befehl lautet Tabellen mit Lesesperre leeren. Wenn Sie die gesamte Bibliothek in einen schreibgeschützten Zustand versetzen müssen, können Sie diesen Befehl verwenden. Danach werden die folgenden Anweisungen anderer Threads blockiert: Datenaktualisierungsanweisungen (Daten hinzufügen, löschen und ändern), Datendefinitionsanweisungen (einschließlich Erstellen von Tabellen, Ändern von Tabellenstrukturen usw.) und Aktualisieren von Transaktions-Commit-Anweisungen. [Verwandte Empfehlungen: MySQL-Tutorial (Video)] Flush tables with read lock。当需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。【相关推荐:mysql教程(视频)】
全局锁的典型使用场景是,做全库逻辑备份。也就是把整库每个表都select出来存成文本
但是让整个库都只读,可能出现以下问题:
- 如果在主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆
- 如果在从库上备份,那么在备份期间从库不能执行主库同步过来的binlog,会导致主从延迟
在可重复读隔离级别下开启一个事务能够拿到一致性视图
官方自带的逻辑备份工具是mysqldump。当mysqldump使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的。single-transaction只适用于所有的表使用事务引擎的库
1.既然要全库只读,为什么不使用set global readonly=true的方式?
- 在有些系统中,readonly的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此修改global变量的方式影响面更大
- 在异常处理机制上有差异。如果执行Flush tables with read lock命令之后由于客户端发生异常断开,那么MySQL会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为readonly之后,如果客户端发生异常,则数据库会一直保持readonly状态,这样会导致整个库长时间处于不可写状态,风险较高
二、表级锁
MySQL里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)
表锁的语法是lock tables … read/write。可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放。lock tables语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象
如果在某个线程A中执行lock tables t1 read,t2 wirte;
Wenn Sie ein Backup in der Hauptdatenbank erstellen, sind Aktualisierungen nicht möglich Während des Sicherungszeitraums kann das Geschäft nicht ausgeführt werden. Wenn Sie eine Sicherung auf der Slave-Datenbank durchführen, kann die Slave-Datenbank das von der Master-Datenbank synchronisierte Binlog während des Sicherungszeitraums nicht ausführen, was zu einer Master-Slave-Verzögerung führt Eine Transaktion unter der wiederholbaren Leseisolationsstufe, um Konsistenz zu erreichen. SexView
- Das offizielle logische Sicherungstool ist mysqldump. Wenn mysqldump den Parameter --single-transaction verwendet, wird vor dem Importieren von Daten eine Transaktion gestartet, um sicherzustellen, dass eine konsistente Ansicht erhalten wird. Aufgrund der Unterstützung von MVCC können die Daten während dieses Vorgangs normal aktualisiert werden. Eine Einzeltransaktion gilt nur für alle Tabellen, die Transaktions-Engine-Bibliotheken verwenden
- 1 Da die gesamte Bibliothek schreibgeschützt ist, warum nicht
set global readonly=trueverwenden? - In einigen Systemen wird der schreibgeschützte Wert für andere Logik verwendet, beispielsweise um zu bestimmen, ob eine Bibliothek die Hauptbibliothek oder die Standby-Bibliothek ist. Daher hat die Art und Weise, wie globale Variablen geändert werden, größere Auswirkungen. Es gibt Unterschiede im Ausnahmebehandlungsmechanismus. Wenn die Verbindung des Clients nach der Ausführung des Befehls „Tabellen mit Lesesperre leeren“ ungewöhnlich getrennt wird, gibt MySQL die globale Sperre automatisch frei und die gesamte Bibliothek kehrt in einen Zustand zurück, in dem sie normal aktualisiert werden kann. Nachdem die gesamte Bibliothek auf „schreibgeschützt“ gesetzt wurde und auf dem Client eine Ausnahme auftritt, bleibt die Datenbank im schreibgeschützten Zustand, was dazu führt, dass sich die gesamte Bibliothek für längere Zeit in einem nicht beschreibbaren Zustand befindet, was ein höheres Risiko darstellt. 2. Tabelle Sperren auf -Ebene
Die Syntax der Tabellensperre lautet Sperrtabellen. .. lesen/schreiben. Sie können Entsperrtabellen verwenden, um die Sperre aktiv aufzuheben, oder Sie können sie automatisch aufheben, wenn der Client die Verbindung trennt. Zusätzlich zur Einschränkung des Lesens und Schreibens anderer Threads begrenzt die Syntax der Sperrtabellen auch die nächsten Operationsobjekte dieses Threads. Wenn Sie lock tables t1 read, t2 wirte; in einem bestimmten Thread A ausführen, Mit dieser Anweisung werden die Anweisungen anderer Threads, die t1 schreiben und t2 lesen und schreiben, blockiert. Gleichzeitig kann Thread A nur die Vorgänge Lesen von t1 und Lesen und Schreiben von t2 ausführen, bevor die Entsperrtabelle ausgeführt wird. Selbst das Schreiben auf t1 ist nicht erlaubt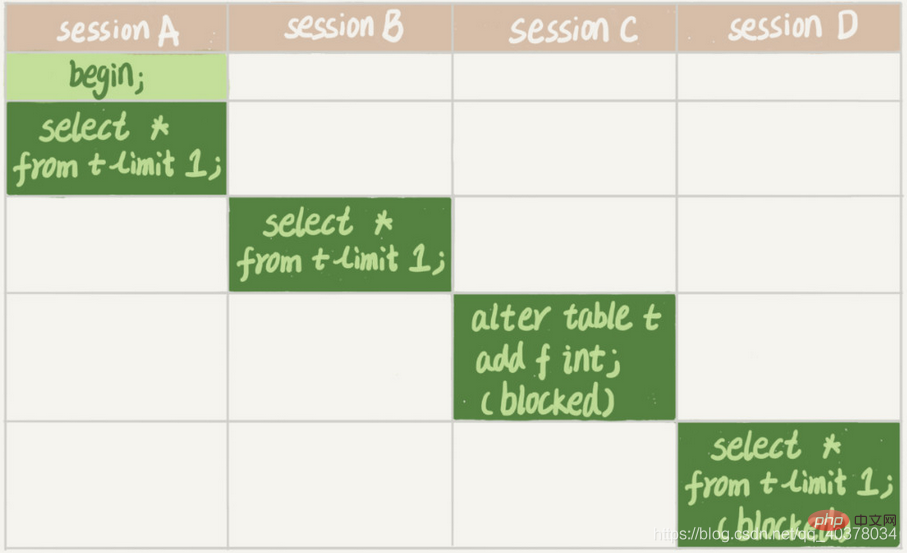
Eine andere Art der Sperre auf Tabellenebene ist MDL. MDL muss nicht explizit verwendet werden, es wird beim Zugriff auf eine Tabelle automatisch hinzugefügt. Die Funktion von MDL besteht darin, die Korrektheit des Lesens und Schreibens sicherzustellen. Wenn eine Abfrage die Daten in einer Tabelle durchläuft und ein anderer Thread während der Ausführung Änderungen an der Tabellenstruktur vornimmt und eine Spalte löscht, stimmen die vom Abfragethread erhaltenen Ergebnisse nicht mit der Tabellenstruktur überein, was definitiv nicht funktionieren wird
Die MDL-Sperre in der Transaktion wird zu Beginn der Anweisungsausführung angewendet, sie wird jedoch nicht sofort nach Ende der Anweisung freigegeben, sondern erst, nachdem die gesamte Transaktion übermittelt wurde
1 So fügen Sie Felder sicher hinzu an einen kleinen Tisch?
Zunächst müssen lange Transaktionen aufgelöst werden. Wenn die Transaktion nicht übermittelt wird, ist die DML-Sperre immer belegt. In der Tabelle innodb_trx der MySQL-Bibliothek information_schema ist die aktuell ausgeführte Transaktion zu finden. Wenn in der von DDL zu ändernden Tabelle gerade eine lange Transaktion ausgeführt wird, sollten Sie zunächst die DDL anhalten oder die lange Transaktion beenden.
2 Wenn es sich bei der zu ändernden Tabelle um eine Hotspot-Tabelle handelt, ist dies bei der Datenmenge jedoch nicht der Fall groß, die obige Anfrage kommt sehr häufig vor, aber ich muss ein Feld hinzufügen.
Legen Sie die Wartezeit in der alter table-Anweisung fest. Es ist am besten, wenn Sie die MDL-Schreibsperre innerhalb der angegebenen Wartezeit erhalten. Blockieren Sie nachfolgende Geschäftsanweisungen nicht und geben Sie zuerst auf. Wiederholen Sie dann den Vorgang, indem Sie den Befehl erneut ausführen
3. Zeilensperre
Die Zeilensperre von MySQL wird von jeder Engine auf Engine-Ebene implementiert. Aber nicht alle Engines unterstützen Zeilensperren. Beispielsweise unterstützt die MyISAM-Engine keine Zeilensperren, also Sperren für Zeilendatensätze in der Datentabelle. Beispielsweise aktualisiert Transaktion A eine Zeile und Transaktion B muss zu diesem Zeitpunkt auch dieselbe Zeile aktualisieren. Sie müssen warten, bis der Vorgang von Transaktion A abgeschlossen ist, bevor Sie 1 aktualisieren. Zweistufiges Sperrprotokoll Von Transaktion A gehaltene Zeilensperren werden nur freigegeben, wenn die Aktualisierungsanweisung von Transaktion B blockiert wird. In InnoDB-Transaktionen sind weiterhin Zeilensperren erforderlich Es wird zu diesem Zeitpunkt hinzugefügt, aber nicht sofort freigegeben, wenn es nicht mehr benötigt wird, sondern bis zum Ende der Transaktion. Dies ist das Zwei-Phasen-Sperrprotokoll
Wenn in einer Transaktion mehrere Zeilen gesperrt werden müssen, sollten die Sperren, die am wahrscheinlichsten Sperrkonflikte verursachen und die Parallelität beeinträchtigen, so weit wie möglich hinten platziert werden
Angenommen, Sie möchten Um ein Online-Transaktionsgeschäft für Kinokarten zu implementieren, möchte Kunde A Kinokarten im Kino B kaufen. Das Unternehmen muss die folgenden Vorgänge umfassen: 1. Den Kinokartenpreis vom Kontostand von Kunde A abziehen
1. Den Kinokartenpreis vom Kontostand von Kunde A abziehen
3 Um sicherzustellen, dass die Transaktion atomar ist, sollten diese drei Vorgänge in einer Transaktion zusammengefasst werden. Wie ordne ich die Reihenfolge dieser drei Anweisungen in der Transaktion an?
Wenn es einen anderen Kunden C gibt, der gleichzeitig Tickets für Theater B kaufen möchte, dann ist der widersprüchliche Teil zwischen diesen beiden Transaktionen Aussage 2. Da sie den Saldo desselben Theaterkontos aktualisieren möchten, müssen sie dieselbe Datenzeile ändern. Gemäß dem Zwei-Phasen-Sperrprotokoll werden alle für Operationen erforderlichen Zeilensperren freigegeben, wenn die Transaktion festgeschrieben wird. Wenn also Kontoauszug 2 am Ende angeordnet ist, beispielsweise in der Reihenfolge 3, 1, 2, ist die Sperrzeit für die Saldozeile des Theaterkontos am geringsten. Dies minimiert das Warten auf Sperren zwischen Transaktionen und verbessert die Parallelität
2. Deadlock und Deadlock-Erkennung In einem gleichzeitigen System treten zirkuläre Ressourcenabhängigkeiten in verschiedenen Threads auf, und alle beteiligten Threads warten darauf, dass andere Threads Ressourcen freigeben Geben Sie einen unendlichen Wartezustand ein, der als Deadlock bezeichnet wirdTransaktion A wartet darauf, dass Transaktion B die Zeilensperre mit der ID = 2 aufhebt, während Transaktion B darauf wartet, dass Transaktion A die Zeilensperre mit der ID = 1 freigibt. Transaktion A und Transaktion B warten darauf, dass die Ressourcen des jeweils anderen freigegeben werden, was bedeutet, dass sie in einen Deadlock-Zustand geraten sind. Wenn ein Deadlock auftritt, gibt es zwei Strategien:
Eine Strategie besteht darin, direkt bis zum Timeout zu warten. Diese Zeitüberschreitung kann über den Parameter innodb_lock_wait_timeout festgelegt werden. Eine andere Strategie besteht darin, die Deadlock-Erkennung einzuleiten und eine Transaktion in der Deadlock-Kette aktiv zurückzusetzen, damit andere Transaktionen weiterhin ausgeführt werden können. Setzen Sie den Parameter innodb_deadlock_detect auf „on“, was bedeutet, dass diese Logik aktiviert wird Denn nach 50 Sekunden tritt eine Zeitüberschreitung ein und das Programm wird beendet. Anschließend können andere Threads mit der Ausführung fortfahren. Bei Online-Diensten ist diese Wartezeit oft nicht akzeptabel. Unter normalen Umständen muss eine aktive Deadlock-Überprüfungsstrategie angewendet werden, und der Standardwert von innodb_deadlock_detect selbst ist aktiviert. Die aktive Deadlock-Überwachung kann auftretende Deadlocks schnell erkennen und behandeln, bringt jedoch zusätzliche Belastungen mit sich. Immer wenn eine Transaktion gesperrt ist, muss überprüft werden, ob der Thread, von dem sie abhängt, von anderen gesperrt ist, und schließlich muss festgestellt werden, ob eine zirkuläre Wartezeit vorliegt, bei der es sich um einen Deadlock handelt, wenn alle Transaktionen dieselbe Zeile aktualisieren müssen In diesem Szenario muss jeder neu blockierte Thread feststellen, ob er aufgrund seiner eigenen Hinzufügung einen Deadlock verursacht. Dies ist ein Vorgang mit einer Zeitkomplexität von O(n)Wie können diese Leistungsprobleme bei der Aktualisierung heißer Zeilen gelöst werden?
1. Wenn Sie sicherstellen, dass es in diesem Unternehmen keinen Deadlock gibt, können Sie die Deadlock-Erkennung vorübergehend deaktivieren2 3. Ändern Sie eine Zeile in mehrere logische Zeilen, um Sperrkonflikte zu reduzieren. Am Beispiel des Theaterkontos können Sie erwägen, es auf mehrere Datensätze aufzuteilen, z. B. 10 Datensätze. Der Gesamtbetrag des Theaterkontos entspricht der Summe der Werte dieser 10 Datensätze. Auf diese Weise können Sie jedes Mal, wenn Sie Geld auf das Theaterkonto einzahlen möchten, zufällig einen der hinzuzufügenden Datensätze auswählen. Auf diese Weise beträgt die Wahrscheinlichkeit jedes Konflikts 1/10 des ursprünglichen Mitglieds, wodurch die Anzahl der Sperrwartezeiten und der CPU-Verbrauch der Deadlock-Erkennung verringert werden können. Erstellen Sie eine Tabelle mit den beiden Feldern id und c und fügen Sie 100.000 Zeilen mit Datensätzen ein. 1), Warten auf MDL-Sperre Wie in der Abbildung unten gezeigt, verwenden Sie den Befehl , um das Diagramm der Tabelle „Warten auf“ anzuzeigen Metadatensperre Dieser Status stellt den aktuellen Status dar. Es gibt einen Thread, der die MDL-Schreibsperre für Tabelle t anfordert oder hält und die Select-Anweisung blockiert. Wiederholung der Szene: Der Weg, mit dieser Art von Problem umzugehen, besteht darin, herauszufinden, wer die MDL-Schreibsperre hält, und sie dann zu beenden. Im Ergebnis von showprocesslist ist die Befehlsspalte von sessionA jedoch „Sleep“, was die Suche umständlich macht. Sie können die Prozess-ID, die die Blockierung verursacht, direkt herausfinden, indem Sie die Tabelle sys.schema_table_lock_waits abfragen und die Verbindung mit dem Kill trennen Befehl (Sie müssen performance_schema=on festlegen, wenn Sie MySQL starten. Verglichen mit der Einstellung „off“ kommt es zu einem Leistungsverlust von etwa 10 %) 4. Warum wird die Anweisung, dass ich nur eine Zeile überprüfe, ausgeführt? so langsam?
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=100000) do
insert into t values(i,i);
set i=i+1;
end while;
END1. Kategorie 1: Die Abfrage wird für längere Zeit nicht zurückgegeben eine lange Zeit Rückkehr, verwenden Sie den Befehl show Processlist, um den Status der aktuellen Anweisung zu überprüfen
show processlist;
select * from t3 where id=1;
2), auf Flush warten
select blocking_pid from sys.schema_table_lock_waits;Überprüfen Sie den Status eines bestimmten Threads. Warten auf Tabellenlöschung. Dieser Status bedeutet, dass es jetzt einen Thread gibt, der eine Spüloperation für Tabelle t durchführt. Es gibt im Allgemeinen zwei Verwendungsmöglichkeiten für Flush-Operationen für Tabellen in MySQL:
select * from information_schema.processlist where id=1;Diese beiden Flush-Anweisungen bedeuten, dass nur Tabelle t geschlossen wird, wenn kein spezifischer Tabellenname angegeben ist MySQLAber unter normalen Umständen werden diese beiden Anweisungen sehr schnell ausgeführt, es sei denn, sie werden von anderen Threads blockiertDie mögliche Situation, in der der Status „Warten auf Tabellenspülung“ angezeigt wird, ist also: Es gibt eine Spültabelle. Der Befehl wird von anderen blockiert Anweisungen, und dann blockiert es die Select-Anweisung
 Szenenwiederholung:
Szenenwiederholung:
In SitzungA wird Sleep(1) einmal pro Zeile aufgerufen, daher wird diese Anweisung standardmäßig 100.000 Sekunden lang während dieser Periodentabelle t ausgeführt wurde von sessionA geöffnet. Wenn SitzungB dann die Tabellen t leert und dann Tabelle t schließt, muss sie warten, bis die Abfrage von SitzungA beendet ist. Auf diese Weise wird sessionC, wenn es erneut eine Abfrage durchführen möchte, durch den Flush-Befehl blockiert. Wenn zu diesem Zeitpunkt bereits eine Transaktion vorhanden ist. Wenn für diese Datensatzzeile eine Schreibsperre besteht, wird die Select-Anweisung blockiert. Wiederholung des Szenarios: Sitzung A hat die Transaktion gestartet, die Schreibsperre belegt und hat es nicht übermittelt, was dazu geführt hat, dass SitzungB blockiert wurde. Die Gründe
2. Die zweite Kategorie: langsame Abfrage
SitzungA verwendet zunächst den Befehl „Transaktion mit konsistentem Snapshot starten“, um eine Transaktion zu öffnen und einen konsistenten Lesevorgang einzurichten Transaktion (auch Snapshot-Lesen genannt. Der MVCC-Mechanismus wird zum Lesen verwendet. Holen Sie sich die übermittelten Daten im Rückgängig-Protokoll. Das Lesen ist also nicht blockierend), und dann führt SitzungB die Aktualisierungsanweisung aus
Nachdem SitzungB 1 Million Aktualisierungsanweisungen ausgeführt hat, wird sie ausgeführt generiert 1 Million Rollback-Protokolle
带lock in share mode的语句是当前读,因此会直接读到1000001这个结果,速度很快;而select * from t where id=1这个语句是一致性读,因此需要从1000001开始,依次执行undo log,执行了100万次以后,才将1这个结果返回
五、间隙锁
建表和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
这个表除了主键id外,还有一个索引c
为了解决幻读问题,InnoDB引入了间隙锁,锁的就是两个值之间的空隙
当执行select * from t where d=5 for update的时候,就不止是给数据库中已有的6个记录加上了行锁,还同时加了7个间隙锁。这样就确保了无法再插入新的记录
行锁分成读锁和写锁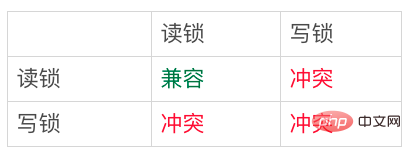
跟间隙锁存在冲突关系的是往这个间隙中插入一个记录这个操作。间隙锁之间不存在冲突关系
这里sessionB并不会被堵住。因为表t里面并没有c=7会这个记录,因此sessionA加的是间隙锁(5,10)。而sessionB也是在这个间隙加的间隙锁。它们用共同的目标,保护这个间隙,不允许插入值。但它们之间是不冲突的
间隙锁和行锁合称next-key lock,每个next-key lock是前开后闭区间。表t初始化以后,如果用select * from t for update要把整个表所有记录锁起来,就形成了7个next-key lock,分别是(-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。因为+∞是开区间,在实现上,InnoDB给每个索引加了一个不存在的最大值supremum,这样才符合都是前开后闭区间
间隙锁和next-key lock的引入,解决了幻读的问题,但同时也带来了一些困扰
间隙锁导致的死锁:
1.sessionA执行select … for update语句,由于id=9这一行并不存在,因此会加上间隙锁(5,10)
2.sessionB执行select … for update语句,同样会加上间隙锁(5,10),间隙锁之间不会冲突
3.sessionB试图插入一行(9,9,9),被sessionA的间隙锁挡住了,只好进入等待
4.sessionA试图插入一行(9,9,9),被sessionB的间隙锁挡住了
两个session进入互相等待状态,形成了死锁
间隙锁的引入可能会导致同样的语句锁住更大的范围,这其实是影响并发度的
在读提交隔离级别下,不存在间隙锁
六、next-key lock
表t的建表语句和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
1、next-key lock加锁规则
- 原则1:加锁的基本单位是next-key lock,next-key lock是前开后闭区间
- 原则2:查找过程中访问到的对象才会加锁
- 优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁
- 优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁
- 一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止
这个规则只限于MySQL5.x系列
2、案例一:等值查询间隙锁

1.由于表t中没有id=7的记录,根据原则1,加锁单位是next-key lock,sessionA加锁范围就是(5,10]
2.根据优化2,这是一个等值查询(id=7),而id=10不满足查询条件,next-key lock退化成间隙锁,因此最终加锁的范围是(5,10)
所以,sessionB要往这个间隙里面插入id=8的记录会被锁住,但是sessionC修改id=10这行是可以的
3、案例二:非唯一索引等值锁
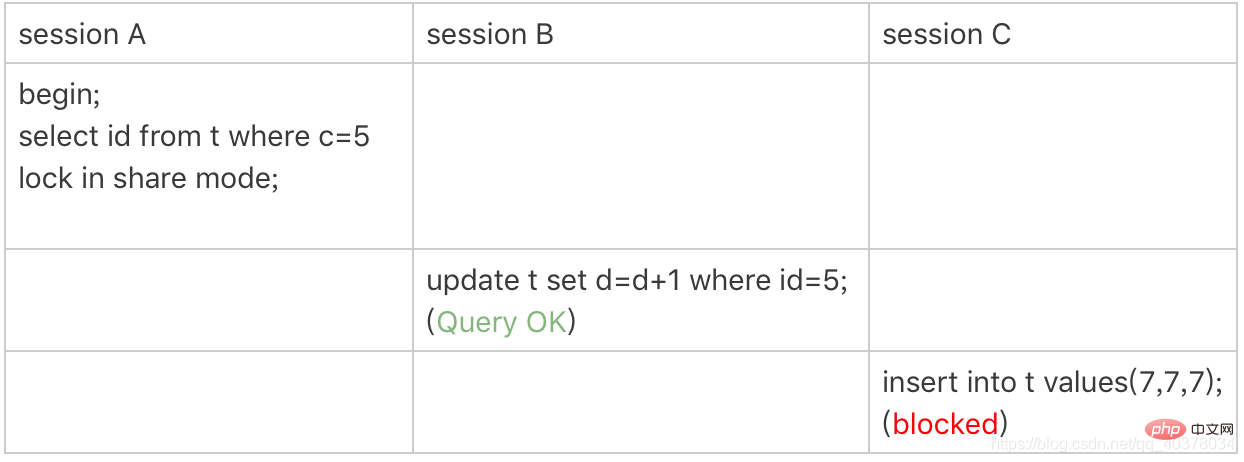
1.根据原则1,加锁单位是next-key lock,因此会给(0,5]加上next-key lock
2.c是普通索引,因此访问c=5这一条记录是不能马上停下来的,需要向右遍历,查到c=10才放弃。根据原则2,访问到的都要加锁,因此要给(5,10]加next-key lock
3.根据优化2,等值判断,向右遍历,最后一个值不满足c=5这个等值条件,因此退化成间隙锁(5,10)
4.根据原则2,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有任何锁,这就是为什么sessionB的update语句可以执行完成
锁是加在索引上的,在这个例子中,lock in share mode只锁覆盖索引,但是如果是for update,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁,这样的话sessionB的update语句会被阻塞住。如果你要用 lock in share mode 来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段
4、案例三:主键索引范围锁

1.开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。根据优化1,主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁
2.范围查询就往后继续找,找到id=15这一行停下来,因此需要加next-key lock(10,15]
所以,sessionA这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15]
5、案例四:非唯一索引范围锁
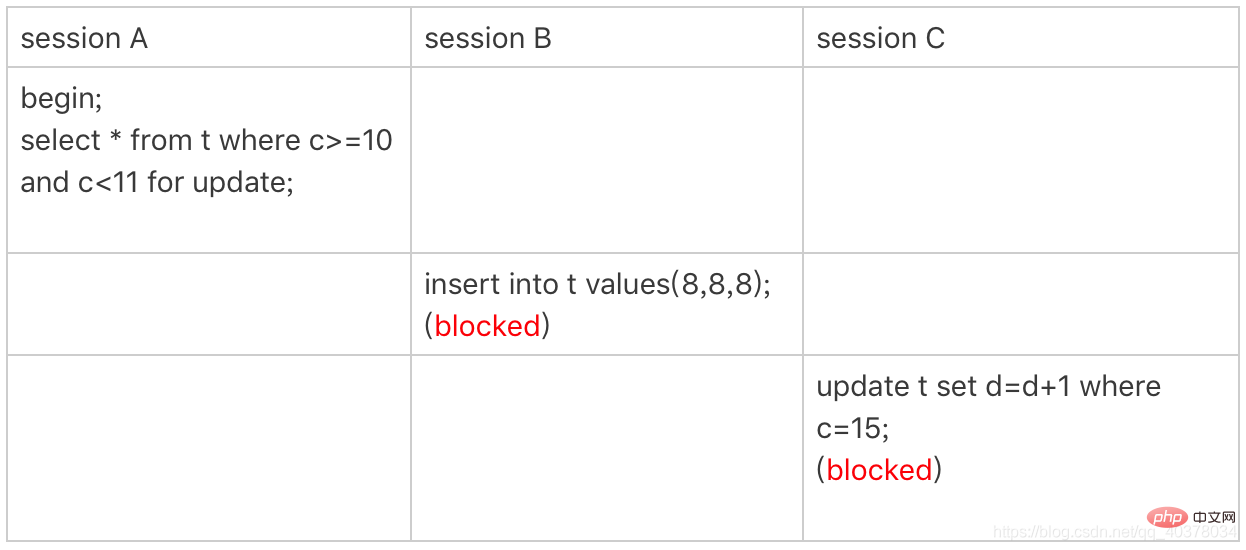
这次sessionA用字段c来判断,加锁规则跟案例三唯一的不同是:在第一次用c=10定位记录的时候,索引c上加上(5,10]这个next-key lock后,由于索引c是非唯一索引,没有优化规则,因此最终sessionA加的锁是索引c上的(5,10]和(10,15]这两个next-key lock
6、案例五:唯一索引范围锁bug
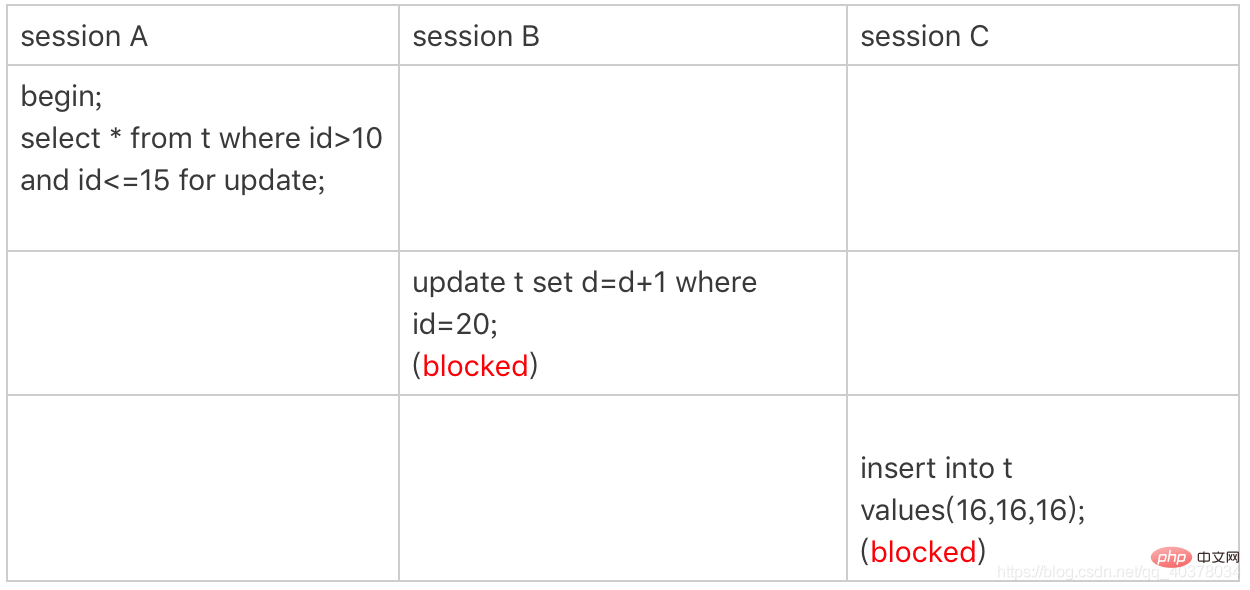
sessionA是一个范围查询,按照原则1的话,应该是索引id上只加(10,15]这个next-key lock,并且因为id是唯一键,所以循环判断到id=15这一行就应该停止了
但是实现上,InnoDB会扫描到第一个不满足条件的行为止,也就是id=20。而且由于这是个范围扫描,因此索引id上的(15,20]这个next-key lock也会被锁上
所以,sessionB要更新id=20这一行是会被锁住的。同样地,sessionC要插入id=16的一行,也会被锁住
7、案例六:非唯一索引上存在等值的例子
insert into t values(30,10,30);
新插入的这一行c=10,现在表里有两个c=10的行。虽然有两个c=10,但是它们的主键值id是不同的,因此这两个c=10的记录之间也是有间隙的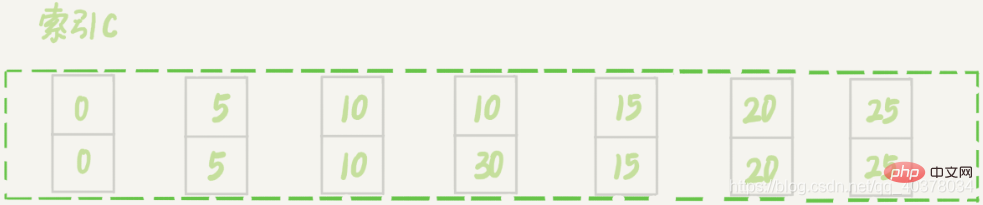
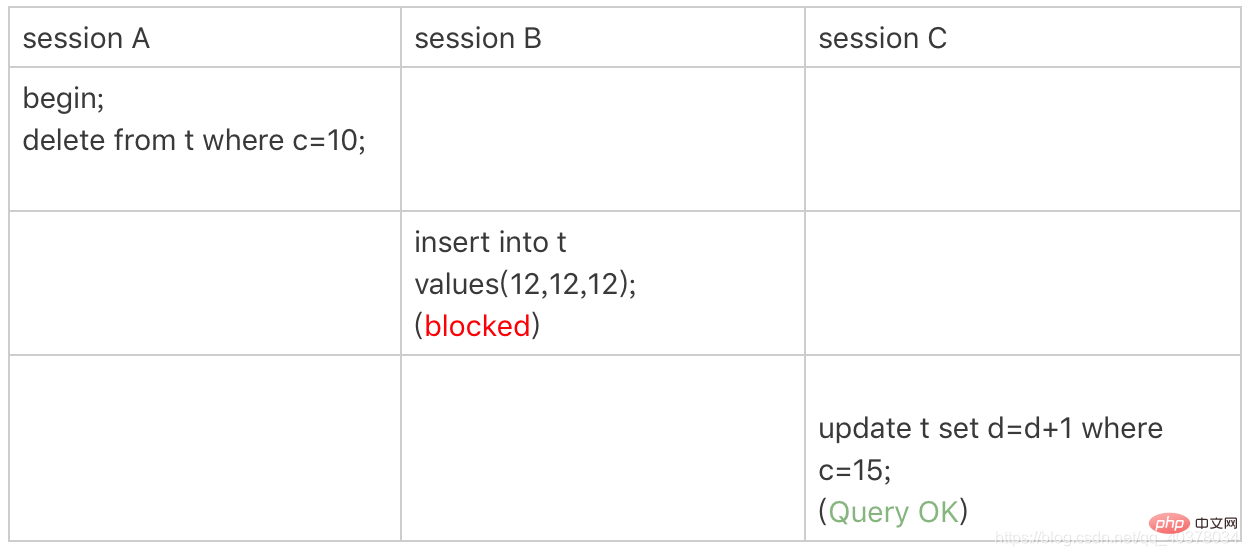
sessionA在遍历的时候,先访问第一个c=10的记录。根据原则1,这里加的是(c=5,id=5)到(c=10,id=10)这个next-key lock。然后sessionA向右查找,直到碰到(c=15,id=15)这一行,循环才结束。根据优化2,这是一个等值查询,向右查找到了不满足条件的行,所以会退化成(c=10,id=10)到(c=15,id=15)的间隙锁
也就是说,这个delete语句在索引c上的加锁范围,就是下图中蓝色区域覆盖的部分,这个蓝色区域左右两边都是虚线,表示开区间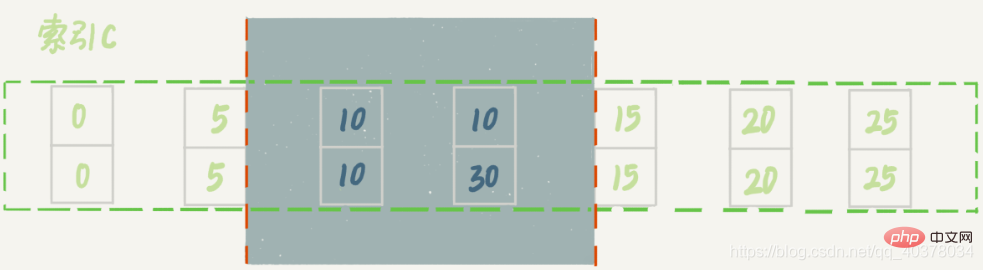
8、案例七:limit语句加锁

加了limit 2的限制,因此在遍历到(c=10,id=30)这一行之后,满足条件的语句已经有两条,循环就结束了。因此,索引c上的加锁范围就变成了从(c=5,id=5)到(c=10,id=30)这个前开后闭区间,如下图所示:
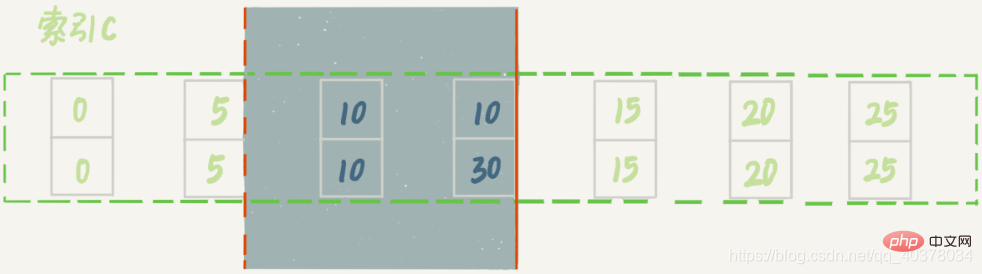
再删除数据的时候尽量加limit,这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围
9、案例八:一个死锁的例子

1.sessionA启动事务后执行查询语句加lock in share mode,在索引c上加了next-key lock(5,10]和间隙锁(10,15)
2.sessionB的update语句也要在索引c上加next-key lock(5,10],进入锁等待
3.然后sessionA要再插入(8,8,8)这一行,被sessionB的间隙锁锁住。由于出现了死锁,InnoDB让sessionB回滚
sessionB的加next-key lock(5,10]操作,实际上分成了两步,先是加(5,10)间隙锁,加锁成功;然后加c=10的行锁,这时候才被锁住的
七、用动态的观点看加锁
表t的建表语句和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
1、不等号条件里的等值查询
begin; select * from t where id>9 and id<12 order by id desc for update;
利用上面的加锁规则,这个语句的加锁范围是主键索引上的(0,5]、(5,10]和(10,15)。加锁单位是next-key lock,这里用到了优化2,即索引上的等值查询,向右遍历的时候id=15不满足条件,所以next-key lock退化为了间隙锁(10,15)

1.首先这个查询语句的语义是order by id desc,要拿到满足条件的所有行,优化器必须先找到第一个id
2.这个过程是通过索引树的搜索过程得到的,在引擎内部,其实是要找到id=12的这个值,只是最终没找到,但找到了(10,15)这个间隙
3.然后根据order by id desc,再向左遍历,在遍历过程中,就不是等值查询了,会扫描到id=5这一行,所以会加一个next-key lock (0,5]
在执行过程中,通过树搜索的方式定位记录的时候,用的是等值查询的方法
2、等值查询的过程
begin; select id from t where c in(5,20,10) lock in share mode;

这条in语句使用了索引c并且rows=3,说明这三个值都是通过B+树搜索定位的
在查找c=5的时候,先锁住了(0,5]。但是因为c不是唯一索引,为了确认还有没有别的记录c=5,就要向右遍历,找到c=10确认没有了,这个过程满足优化2,所以加了间隙锁(5,10)。执行c=10会这个逻辑的时候,加锁的范围是(5,10]和(10,15),执行c=20这个逻辑的时候,加锁的范围是(15,20]和(20,25)
这条语句在索引c上加的三个记录锁的顺序是:先加c=5的记录锁,再加c=10的记录锁,最后加c=20的记录锁
select id from t where c in(5,20,10) order by c desc for update;
由于语句里面是order by c desc,这三个记录锁的加锁顺序是先锁c=20,然后c=10,最后是c=5。这两条语句要加锁相同的资源,但是加锁顺序相反。当这两条语句并发执行的时候,就可能出现死锁
八、insert语句的锁为什么这么多?
1、insert … select语句
表t和t2的表结构、初始化数据语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t;
在可重复读隔离级别下,binlog_format=statement时执行下面这个语句时,需要对表t的所有行和间隙加锁
insert into t2(c,d) select c,d from t;
2、insert循环写入
要往表t2中插入一行数据,这一行的c值是表t中c值的最大值加1,SQL语句如下:
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
这个语句的加锁范围,就是表t索引c上的(3,4]和(4,supermum]这两个next-key lock,以及主键索引上id=4这一行
执行流程是从表t中按照索引c倒序吗,扫描第一行,拿到结果写入到表t2中,因此整条语句的扫描行数是1
但如果要把这一行的数据插入到表t中的话:
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);

explain结果中的Extra字段中Using temporary字段,表示这个语句用到了临时表
执行流程如下:
1.创建临时表,表里有两个字段c和d
2.按照索引c扫描表t,依次取c=4、3、2、1,然后回表,读到c和d的值写入临时表
3.由于语义里面有limit 1,所以只取了临时表的第一行,再插入到表t中
这个语句会导致在表t上做全表扫描,并且会给索引c上的所有间隙都加上共享的next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据
需要临时表是因为这类一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就可能在遍历过程中,读到刚刚插入的记录,新插入的记录如果参与计算逻辑,就跟语义不符
3、insert唯一键冲突

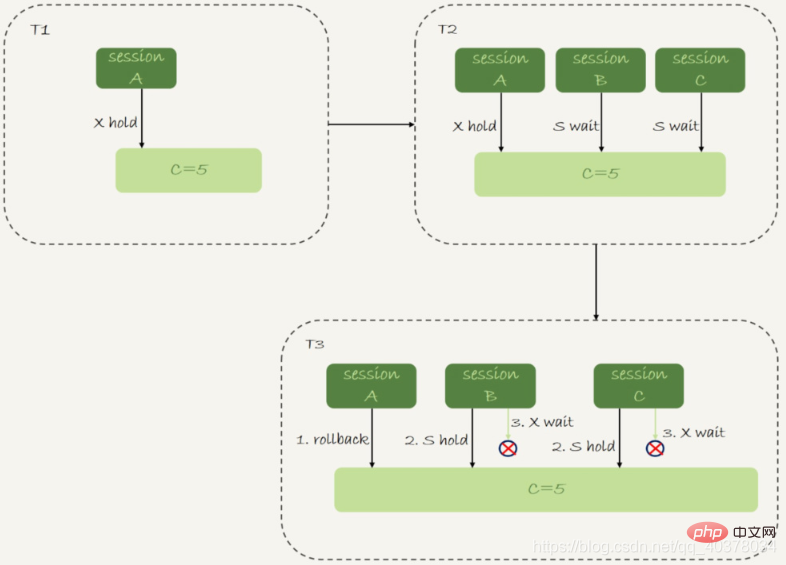
sessionA执行的insert语句,发生唯一键冲突的时候,并不只是简单地报错返回,还在冲突的索引上加了锁,sessionA持有索引c上的(5,10]共享next-key lock(读锁)

在sessionA执行rollback语句回滚的时候,sessionC几乎同时发现死锁并返回
1.在T1时刻,启动sessionA,并执行insert语句,此时在索引c的c=5上加了记录锁。这个索引是唯一索引,因此退化为记录锁
2.在T2时刻,sessionA回滚。这时候,sessionB和sessionC都试图继续执行插入操作,都要加上写锁。两个session都要等待对方的行锁,所以就出现了死锁
4、insert into … on duplicate key update
上面这个例子是主键冲突后直接报错,如果改写成
insert into t values(11,10,10) on duplicate key update d=100;
就会给索引c上(5,10]加一个排他的next-key lock(写锁)
insert into … on duplicate key update的语义逻辑是,插入一行数据,如果碰到唯一键约束,就继续执行后面的更新语句。如果有多个列违反了唯一性索引,就会按照索引的顺序,修改跟第一个索引冲突的行
表t里面已经有了(1,1,1)和(2,2,2)这两行,执行这个语句效果如下:
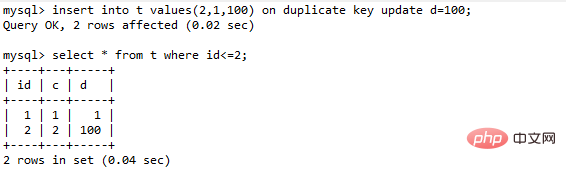
主键id是先判断的,MySQL认为这个语句跟id=2这一行冲突,所以修改的是id=2的行
思考题:
1、如果要删除一个表里面的前10000行数据,有以下三种方法可以做到:
- 第一种,直接执行
delete from T limit 10000; - 第二种,在一个连接中循环执行20次
delete from T limit 500; - 第三种,在20个连接中同时执行
delete from T limit 500;
选择哪一种方式比较好?
参考答案:
第一种方式,单个语句占用时间长,锁的时间也比较长,而且大事务还会导致主从延迟
第三种方式,会人为造成锁冲突
第二种方式相对较好
更多编程相关知识,请访问:编程入门!!
Das obige ist der detaillierte Inhalt vonDetailliertes Verständnis von Sperren in MySQL (globale Sperren, Sperren auf Tabellenebene, Zeilensperren). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!