
Kann der Redis-Ganzzahlsatz nicht herabgestuft werden? Warum?

- 醉折花枝作酒筹nach vorne
- 2021-07-28 17:46:472316Durchsuche
Ich glaube, einige Studenten haben noch nie von der Ganzzahlsammlung gehört, da Redis der Außenwelt nur fünf gekapselte Objekte zur Verfügung stellt! Zuvor haben wir die drei Datenstrukturen von Redis analysiert: List, Hash und Zset anhand der internen Struktur von Redis. Heute analysieren wir, wie die eingestellte Datenstruktur intern gespeichert wird.
Grundstruktur
In src/t_set.c haben wir so einen Code gefunden
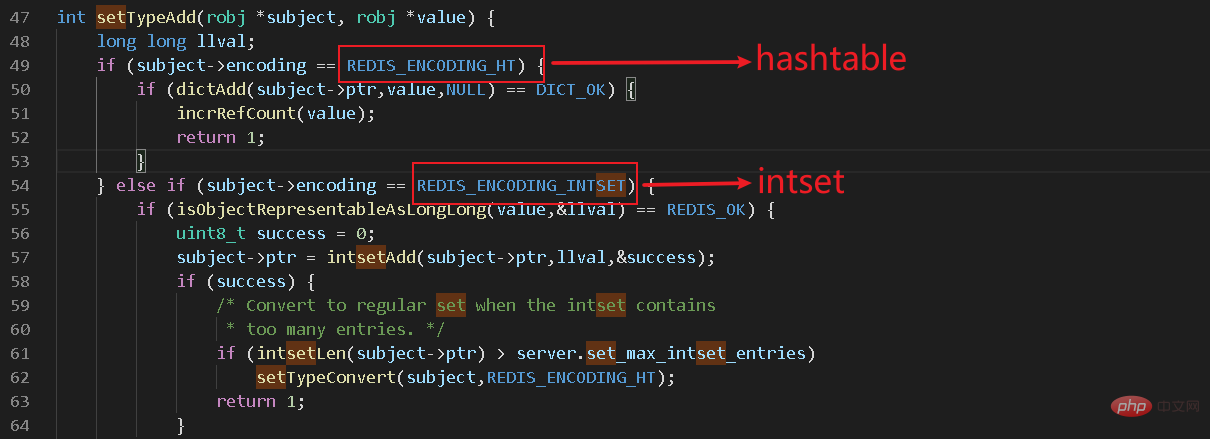
Daraus wissen wir, dass die Menge aus zwei Datenstrukturen besteht: hashtable+intset. Was andere interne Strukturen von Redis betrifft, stelle ich sie speziell in [Redis-Spalte] vor. Hashtable ist heute nicht unser Protagonist. Heute analysieren wir zunächst den Intset, der allgemein als Integer-Set bezeichnet wird.
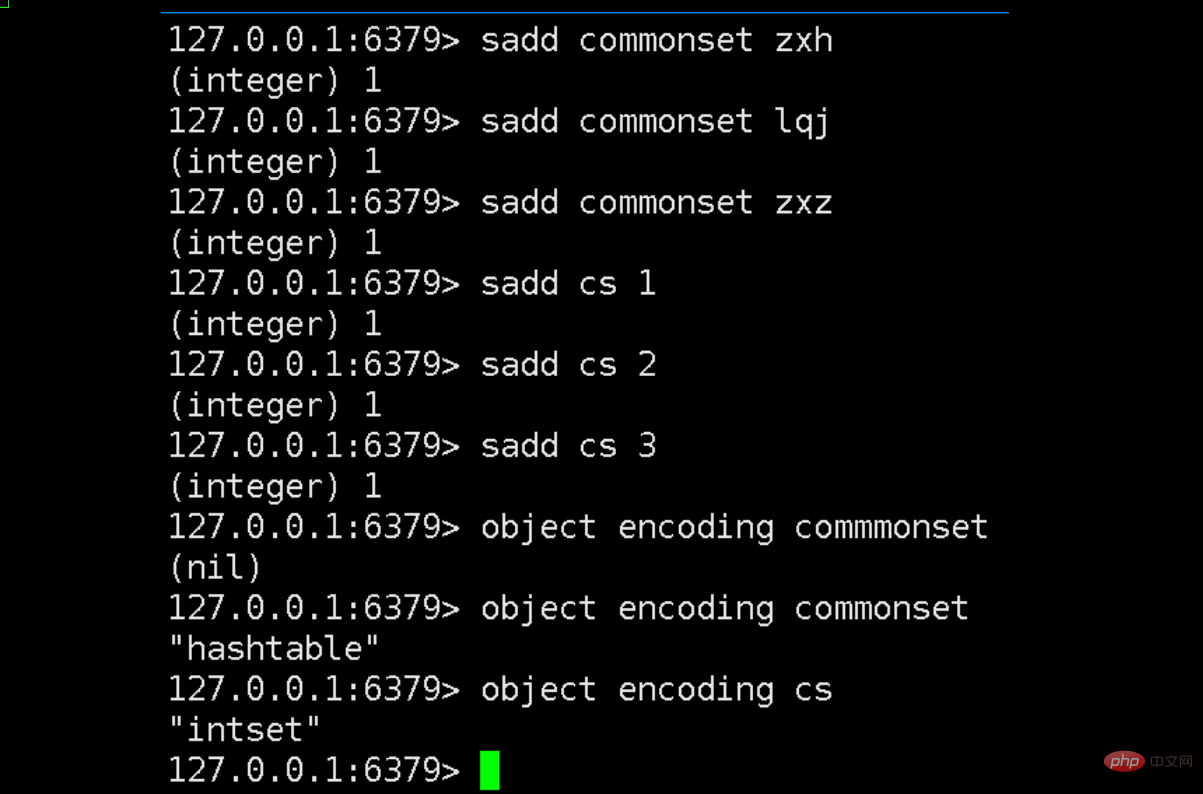
Wie wir auf dem Bild oben sehen können, habe ich zwei Set-Sammlungen namens [commonset] und [cs] erstellt. Ersteres speichert Zeichenfolgen und letzteres Zahlen.
Wir betrachten die zugrunde liegenden Datenstrukturen der nächsten beiden Sammlungen anhand des Objektkodierungsschlüssels und stellen fest, dass es sich bei einer um eine Hashtabelle und bei der anderen um einen Intset handelt. Dies bestätigt auch unsere obige Beschreibung der Grundstruktur der Menge.
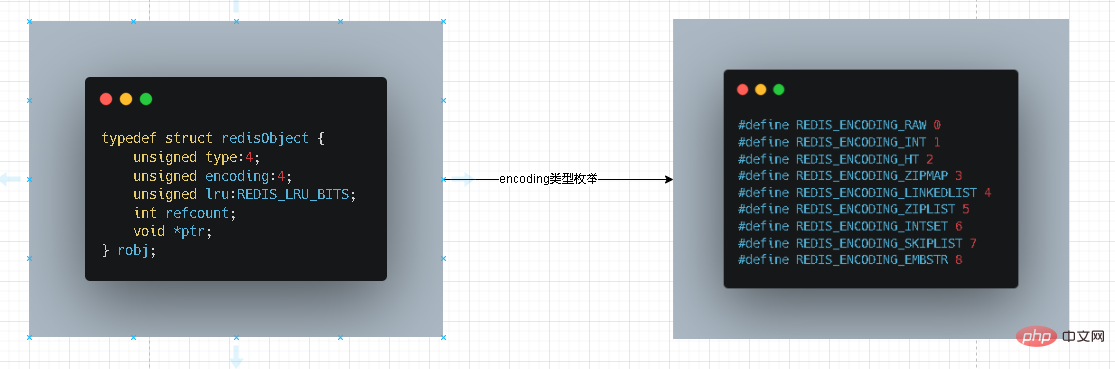
Die fünf Haupttypen, die extern in Redis bereitgestellt werden, sind tatsächlich ein abstraktes Objekt von Redis, das Redisobject genannt wird. Die interne Datenstruktur unseres Redis wird intern abgebildet
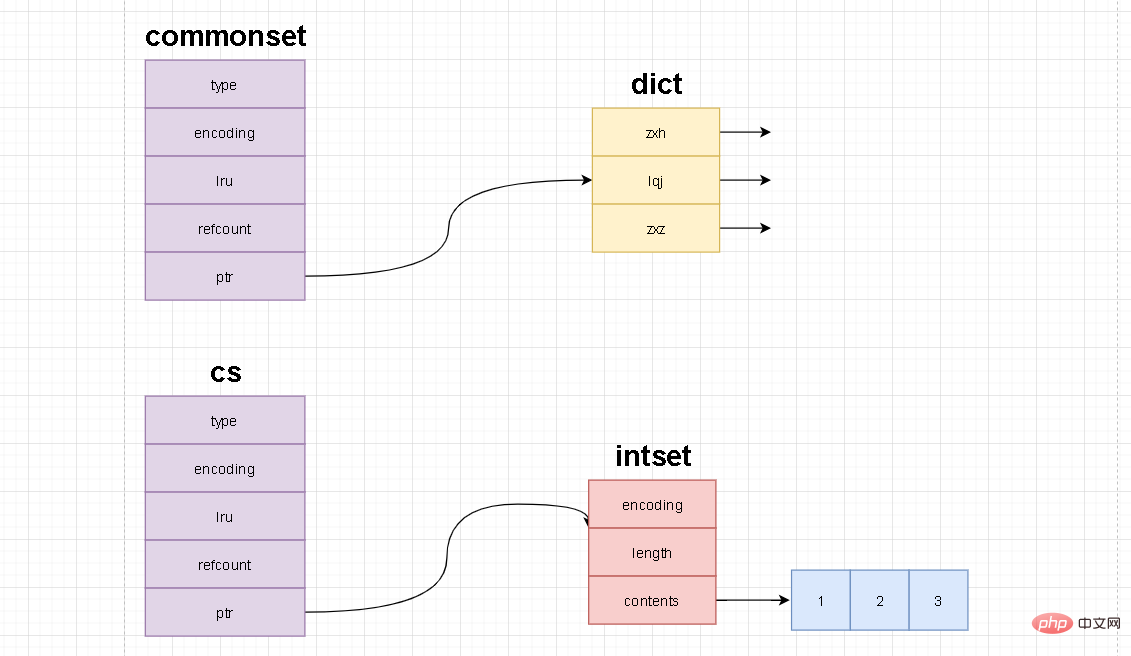
Die interne Datenstruktur der Commonset- und CS-Sammlungen kann so verstanden werden
Wann ist Intset zu verwenden
Das können Sie einfach denken, solange es so ist ist eine Zahl. Die Intset-Struktur wird zur Speicherung verwendet. Ich fürchte, ich muss Ihnen einen Schlag ins Gesicht geben. Tatsächlich ist dies nicht der Fall
Die folgenden zwei Bedingungen müssen gleichzeitig erfüllt sein:


intset
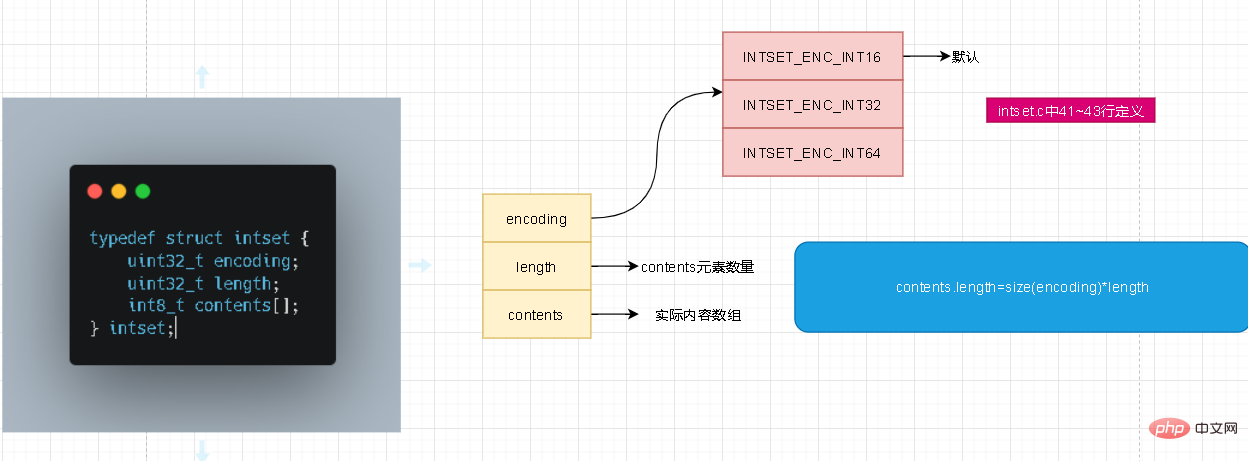
Das Bild zeigt es sehr deutlich. Die Codierung in intset hat drei Werte, die den Datentyp der Inhaltsspeicherung darstellen. Jemand hier hat vielleicht Fragen. Ist die Art des Inhalts nicht einfach int8_t? Warum brauchen Sie eine Kodierung? Die Quellcodeverfolgung hier hat nichts mit int8_t zu tun. Und der Standarddatentyp ist int16_t. Zur Länge muss hier nicht allzu viel erklärt werden. Bedenken Sie, dass die Anzahl der Inhaltselemente nicht die Länge des Inhaltsarrays darstellt!
Studenten, die sich mit Intset auskennen, wissen alle, dass die drei Wertebereiche der Codierung Upgrade-Vorgänge beinhalten! Bevor wir über das Upgrade sprechen, wollen wir zunächst verstehen, wie der Wertebereich von int in C und C++ definiert ist
Der Wertebereich von int8_t beträgt [-128,127]. Ähnlich wie bei Byte in Java besteht 1 Byte aus 8 Bits. Sein Wertebereich ist
[-2^{7} sim 2^{7}-1 \即 \
-128 sim 127
]

Element hinzufügen
sadd juejin -123 sadd juejin -6 sadd juejin 12 sadd juejin 56 sadd juejin 321
juejin Dieser Schlüssel ist intern festgelegt.
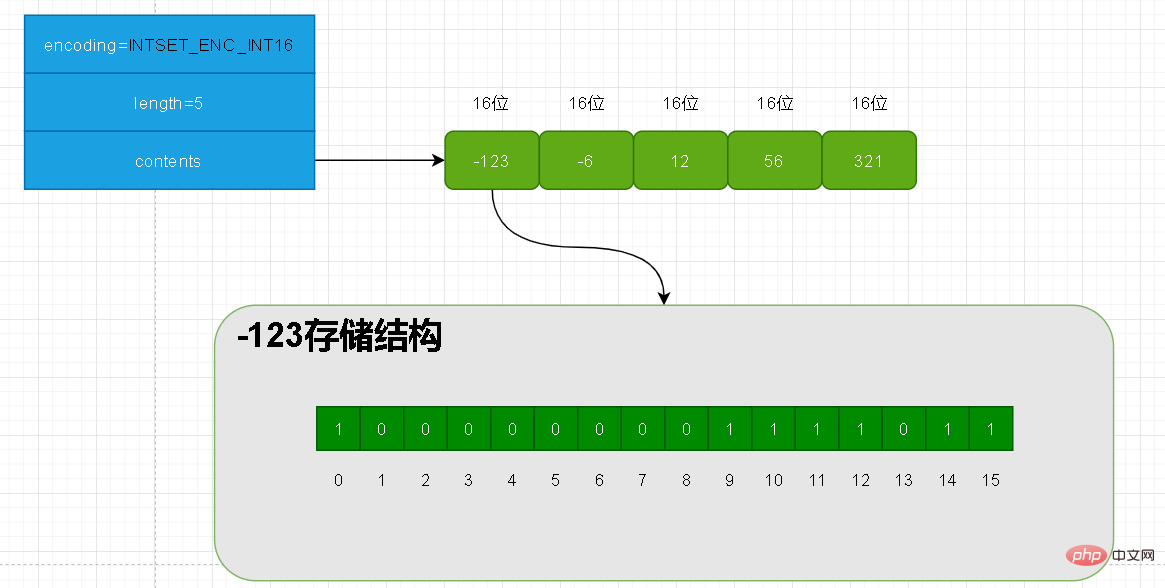
Oben haben wir 5 Elemente hinzugefügt und die Längen dieser fünf Elemente liegen alle innerhalb von 16! Die Codierung des aktuellen Intsets ist also =INTSET_ENC_INT16. -123 belegt inhaltlich die ersten 16 Plätze.
Die Länge der aktuellen fünf Elemente im Inhalt beträgt also 16*5=80.
Beachten Sie, dass beim Speichern von Daten vom Typ int diese intern in der Reihenfolge von klein nach groß gespeichert werden.
Typänderungen

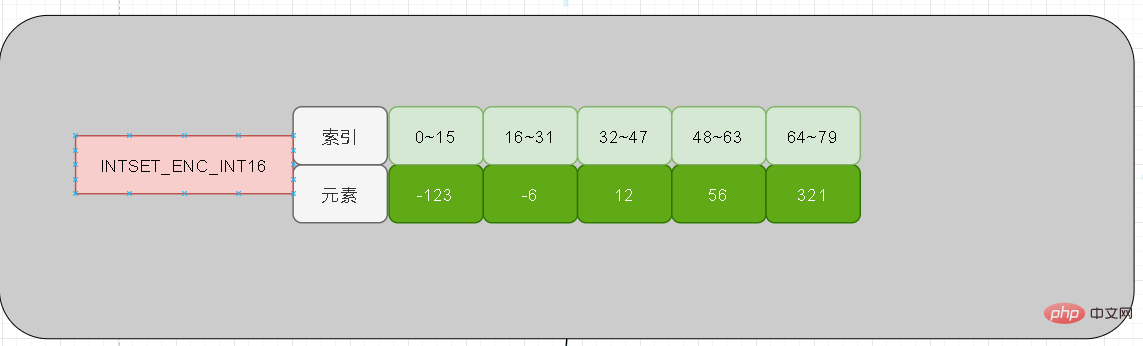
Ich weiß nicht, ob Sie die oben genannten Fragen berücksichtigt haben oder ob Sie auf sie gestoßen sind! Intset ist standardmäßig int16 Bits, genau wie die fünf Elemente, die wir oben hinzugefügt haben. Zu diesem Zeitpunkt ist das sechste Element, das wir hinzufügen, 65535 (32 Bit). Was wird Intset dann tun, wenn die Länge von 16 Bit für die Speicherung nicht ausreicht?
Wenn wir außerdem das 6. Element hinzufügen und 65535 löschen, wird die Struktur dann dieselbe sein wie vor dem Hinzufügen? Werfen wir einen Blick auf diese beiden Fragen unten! ! !
Upgrade
Werfen wir zunächst einen Blick auf die erste Frage. Es stellt sich heraus, dass alle fünf Elemente 16 Bit lang sind und die zu diesem Zeitpunkt hinzugefügten 65535 32 Bit lang sind. Können wir also direkt 32 Bit an 65535 anhängen?
Die Antwort lautet definitiv nicht: Direktes Anhängen kann die Größenreihenfolge der Array-Elemente nicht garantieren! Zweitens: Wenn die ersten fünf jeweils 16 Bit und das sechste 32 Bit lang sind, gibt es in der Intset-Struktur keine zusätzlichen Felder, die markiert werden müssen. Mit anderen Worten, es ist unmöglich zu beurteilen, ob beim Parsen 16-Bit oder 32-Bit analysiert werden soll.
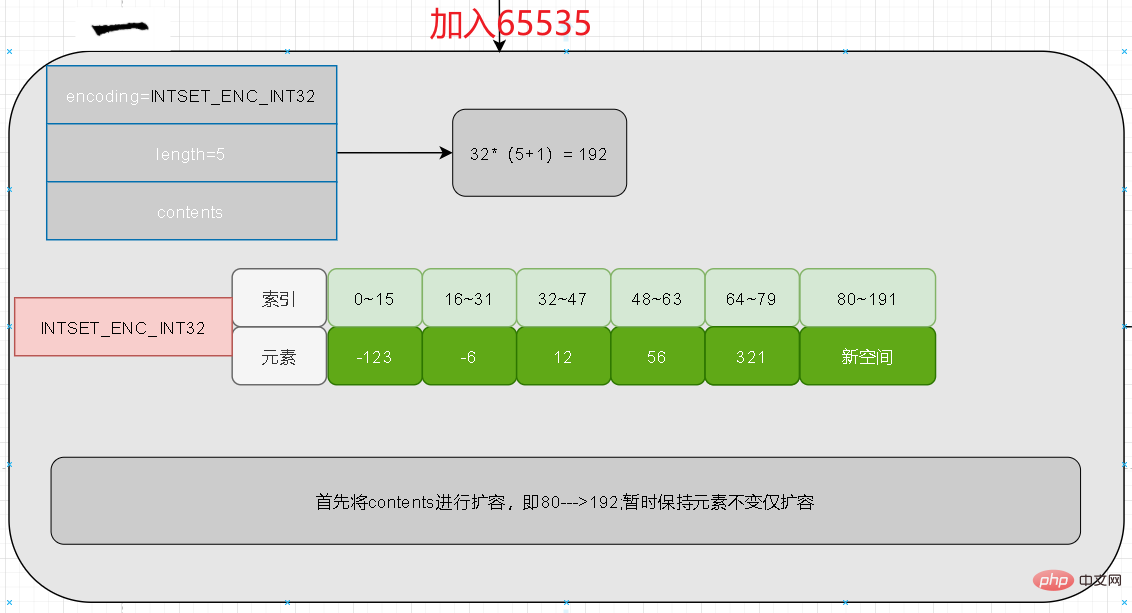
Um das Parsen zu erleichtern, aktualisiert Redis den gesamten Inhalt, wenn eine hohe Länge hinzugefügt wird. Es bedeutet, zuerst den gesamten Inhalt zu erweitern und dann die Daten neu zu füllen
und 65535 hinzuzufügen
Zunächst kann anhand der Länge bestimmt werden, dass die Anzahl der Elemente nach der Erweiterung jeweils 6 beträgt Die Belegung beträgt 32, die Länge des Inhalts beträgt also 32 * 6 = 192. Zu diesem Zeitpunkt bleiben die ersten 80 Bits des Inhalts unverändert
Verschiebung alter Daten
Nachdem genügend Platz frei geworden ist, können wir die alten Daten verschieben. Hier beginnen wir mit der Verschiebung vom Ende des ursprünglichen Arrays , bei Vor dem Verschieben müssen Sie die Sortierposition im neuen Array kennen.
Zu diesem Zeitpunkt vergleichen wir zunächst 321, um festzustellen, dass sein Rang im neuen Array an fünfter Stelle steht. Anschließend wird er im neuen Inhalt den Bereich 128 bis 159 belegen.
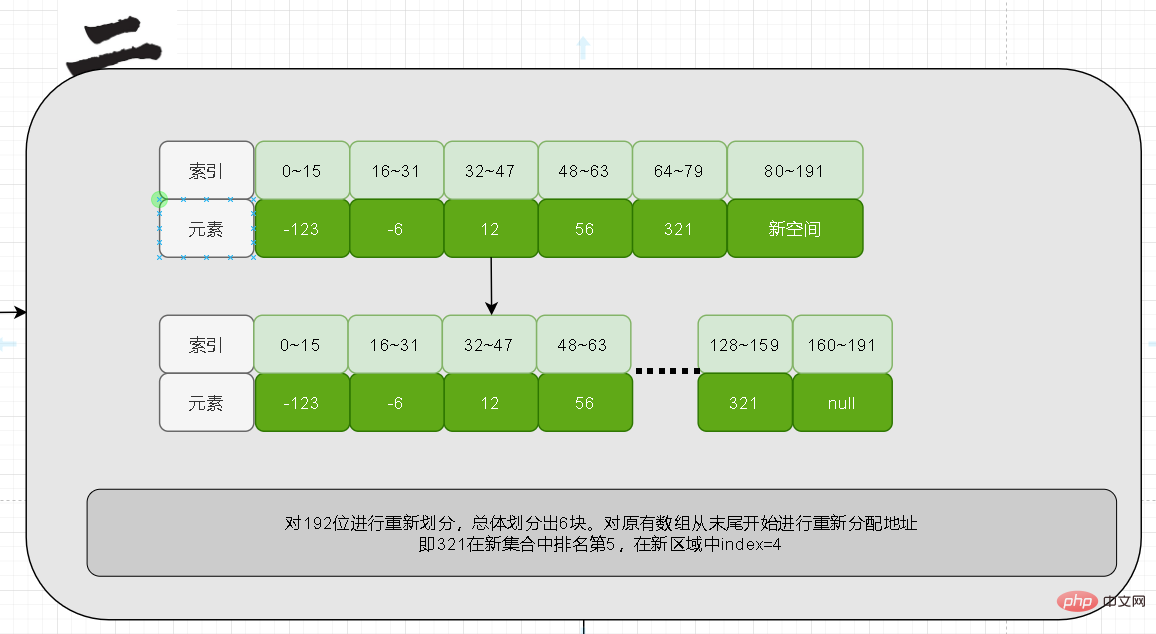
Endlich werden die ersten 5 Elemente verschoben.
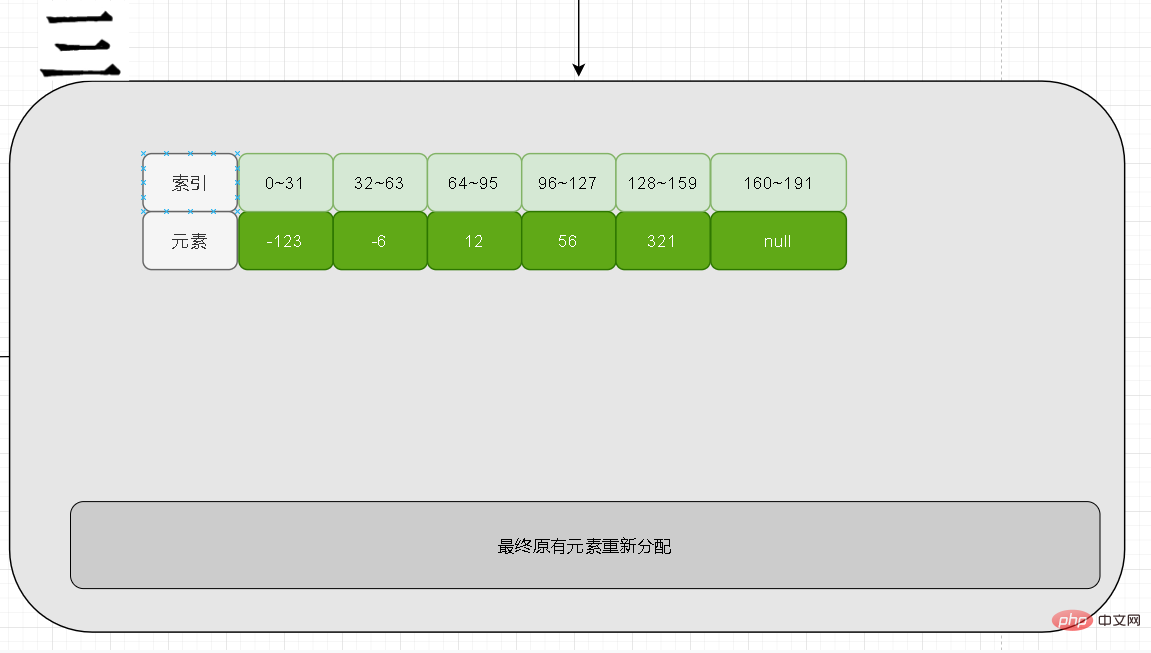
Füllen Sie abschließend die neu hinzugefügten Elemente aus. Wenn eine Aktualisierung erfolgt, muss dies daran liegen, dass die Länge des neuen Elements größer als die ursprüngliche Länge ist. Dann muss sein Wert an beiden Enden des neuen Arrays stehen. Negative Zahlen stehen ganz links, positive Zahlen ganz rechts
Downgrade
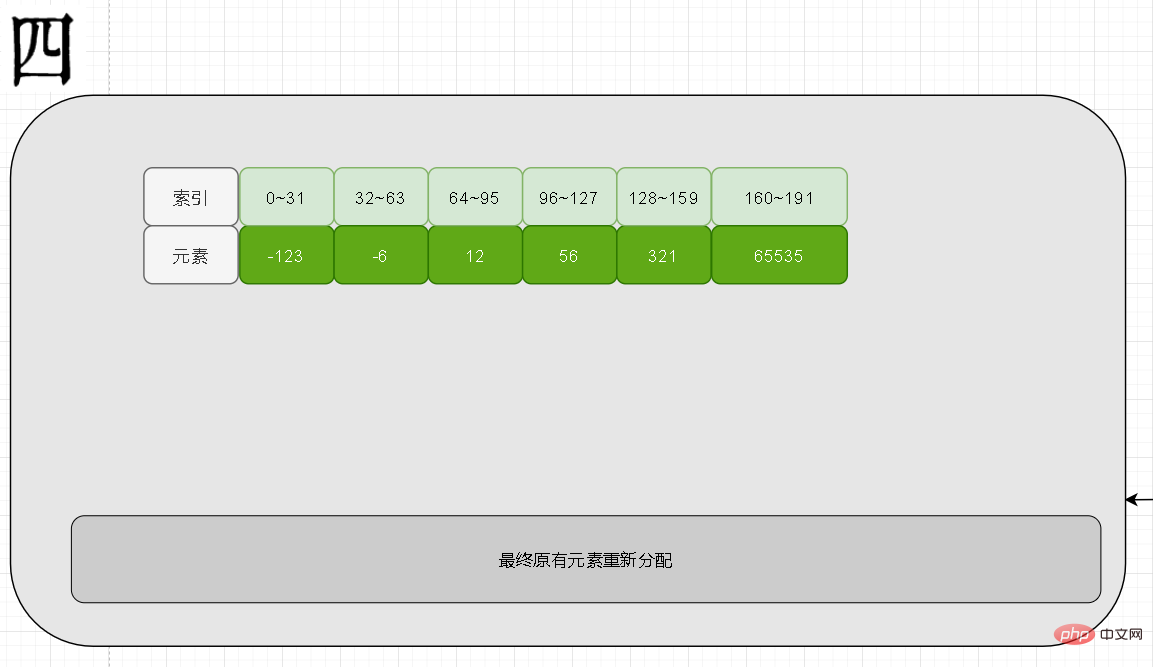
Dann ist die zweite Frage, was Redis tun soll, wenn der neu hinzugefügte 65535 wieder gelöscht wird. Zu diesem Zeitpunkt beträgt die tatsächliche Elementlänge 16 Bit zufrieden, aber die Kodierung ist derzeit 32 Bit. Meiner Meinung nach sollte es herabgestuft werden!
Aber leider hat Redis es nicht, also denken Sie bitte darüber nach, warum es das nicht hat? Wenn Sie gebeten würden, es zu implementieren, wie würden Sie es implementieren? Warum nicht ein Downgrade implementieren? Wenn das hinzugefügte Element die aktuelle Länge überschreitet, können wir zu diesem Zeitpunkt leicht erkennen, dass ein Upgrade-Vorgang erforderlich ist Wie können wir beurteilen, ob es schwierig ist, ein Datenelement zu löschen? Wir müssen erneut durchlaufen, um festzustellen, ob die verbleibenden Elemente kleiner als die aktuelle Länge sind und die Komplexität O (N) erreichen. Dies ist einer der Gründe, warum das Downgrade nicht durchgeführt wird. Man könnte sagen, dass das Zurücksetzen schnell ist und es sowieso im Speicher ist. Haben Sie jemals darüber nachgedacht, dass, wenn Sie nach dem Downgrade auf eine Upgrade-Situation stoßen, solche Hin- und Her-Upgrades auftreten? Downgrades verringern die Leistung unseres Programms. Wir wissen, dass ein Upgrade erforderlich ist, daher besteht die Strategie zum Downgrade von Redis hier darin, es zu ignorieren
Das obige ist der detaillierte Inhalt vonKann der Redis-Ganzzahlsatz nicht herabgestuft werden? Warum?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Interpretieren Sie die PHP-basierte Redis-Counter-Klasse in einer Minute
- Lassen Sie uns über Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration in Redis sprechen
- Wie betreibe ich Redis mit PHP? Einführung in grundlegende Operationsmethoden
- So installieren Sie Redis mit PHP unter Windows
- Think-Queue analysieren (Analyse rund um Redis)