
Heim >Backend-Entwicklung >C#.Net-Tutorial >Welche Sortiermethoden gibt es in der C-Sprache?
Welche Sortiermethoden gibt es in der C-Sprache?

- 醉折花枝作酒筹Original
- 2021-07-27 11:40:2634636Durchsuche
C-Sprachsortierung: 1. Einfache Auswahlsortierung, ein Sortieralgorithmus basierend auf der O(n2)-Zeitkomplexität; 3. Einfache Einfügungssortierung; 5. Zusammenführungssortierung; Sortieralgorithmus für Zusammenführungsoperationen; 6. Schnelle Sortierung, eine Art Divide-and-Conquer-Methode. 7. Heap-Sortierung usw.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, C++17-Version, Dell G3-Computer.
1. Auswahlsortierung – einfache Auswahlsortierung
Auswahlsortierung ist der einfachste Sortieralgorithmus basierend auf der Zeitkomplexität O(n2). Die Grundidee besteht darin, jedes Mal von der Position i=0 bis i=n-1 zu beginnen findet den kleinsten (größten) Wert von Position i bis Position n-1.
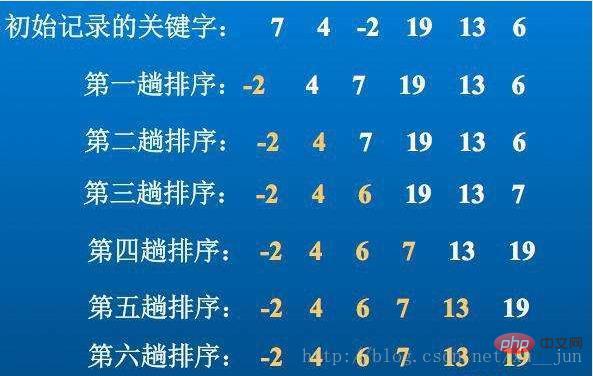
Algorithmusimplementierung:
void selectSort(int arr[], int n)
{ int i, j , minValue, tmp; for(i = 0; i < n-1; i++)
{
minValue = i; for(j = i + 1; j < n; j++)
{ if(arr[minValue] > arr[j])
{
minValue = j;
}
} if(minValue != i)
{
tmp = arr[i];
arr[i] = arr[minValue];
arr[minValue] = tmp;
}
}
}void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n");
}void main()
{ int arr[10] = {2,5,6,4,3,7,9,8,1,0};
printArray(arr, 10);
selectSort(arr, 10);
printArray(arr, 10); return;
}Wie in der Implementierung gezeigt, ist die Komplexität der einfachen Auswahlsortierung auf O(n2) festgelegt. Jede innere Schleife findet den Minimalwert in der unsortierten Sequenz und tauscht ihn dann mit dem aktuellen aus Daten. Da die Auswahlsortierung nach dem Maximalwert erfolgt, ist die Anzahl der Schleifen nahezu festgelegt. Eine Optimierungsmethode besteht darin, in jeder Schleife gleichzeitig den Maximal- und Minimalwert zu ermitteln. Dadurch kann die Anzahl der Schleifen auf (n/2) reduziert werden ), fügen Sie einfach die Schleife hinzu, um den Maximalwert aufzuzeichnen. Das Prinzip ist dasselbe und dieser Artikel wird diese Methode nicht mehr implementieren.
2. Blasensortierung
Die Blasensortierung wird in einer Gruppe von Arrays verwendet, die sortiert werden müssen. Wenn die Reihenfolge zweier Datenpaare der erforderlichen Reihenfolge entspricht, werden die Daten ausgetauscht, sodass die großen Daten nach hinten verschoben werden . Bei jedem Sortierdurchlauf wird die größte Zahl wie folgt an die letzte Stelle verschoben:
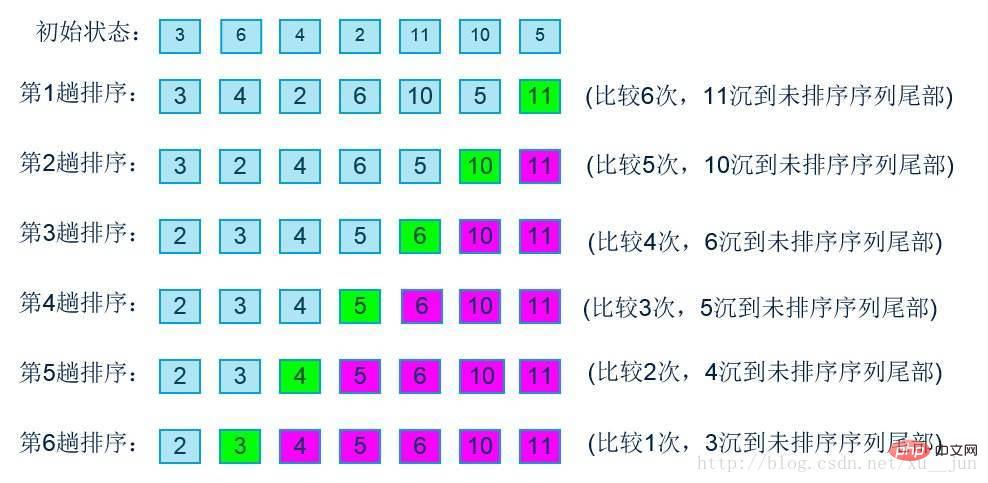
Algorithmusimplementierung:
void bubbleSort(int arr[], int n)
{ int i, j, tmp; for(i = 0; i < n - 1; i++)
{ for(j = 1; j < n; j++)
{ if(arr[j] < arr[j - 1])
{
tmp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = tmp;
}
}
}
}void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n");
}void main()
{ int arr[10] = {2,5,6,4,3,7,9,8,1,0};
printArray(arr, 10);
bubbleSort(arr, 10);
printArray(arr, 10); return;
}Das Obige ist die einfachste Implementierungsmethode, auf die möglicherweise geachtet werden muss von i, j. Diese Methode legt die Anzahl der Zyklen fest. Es kann verschiedene Situationen lösen, aber der Zweck des Algorithmus besteht darin, die Effizienz zu verbessern. Aus dem Prozessdiagramm der Blasensortierung ist ersichtlich, dass dieser Algorithmus dies kann aus mindestens zwei Punkten optimiert werden:
1) Für die äußere Schleife, wenn die aktuelle Sequenz bereits in Ordnung ist, Das heißt, es wird kein Austausch durchgeführt und der nächste Zyklus sollte direkt herausgesprungen werden.
2) Wenn der Maximalwert nach der inneren Schleife bereits in Ordnung ist, sollte die Schleife nicht mehr ausgeführt werden.
Optimierte Code-Implementierung:
void bubbleSort_1(int arr[], int n)
{ int i, nflag, tmp; do
{
nflag = 0; for(i = 0; i < n - 1; i++)
{ if(arr[i] > arr[i + 1])
{
tmp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = tmp;
nflag = i + 1;
}
}
n = nflag;
}while(nflag);
}Wenn nflag wie oben 0 ist, bedeutet dies, dass in diesem Zyklus kein Austausch stattgefunden hat und die Sequenz in Ordnung ist und kein Recycling erforderlich ist. Wenn nflag>0, ist die Position wo Der letzte Austausch wird aufgezeichnet und diese Position wird später verwendet. Die Sequenzen sind alle in Ordnung und die Schleife wird nicht fortgesetzt.
3. Einfügungssortierung – einfache Einfügungssortierung
Einfügungssortierung besteht darin, einen Datensatz in eine bereits geordnete Sequenz einzufügen und eine geordnete Sequenz mit einem neuen Element plus eins zu erhalten. Bei der Implementierung wird das erste Element als geordnete Sequenz betrachtet Beginnen Sie nacheinander mit dem zweiten Element, um eine vollständige geordnete Sequenz zu erhalten:
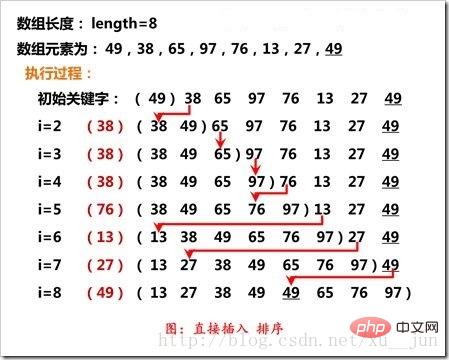
Wie in der Abbildung gezeigt, wird das i-te Element der Einfügungssortierung mit dem benachbarten vorherigen Element verglichen Es wird mit der Sortierreihenfolge verglichen. Im Gegenteil, es tauscht die Position mit dem vorherigen Element aus und führt eine Schleife durch, bis die entsprechende Position erreicht ist.
Algorithmusimplementierung:
void insertSort(int arr[], int n)
{ int i, j, tmp; for(i = 1; i < n; i++)
{ for(j = i; j > 0; j--)
{ if(arr[j] < arr[j-1])
{
tmp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = tmp;
} else
{ break;
}
}
} return;
}void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n"); return;
}void main()
{ int arr[10] = {2,5,6,4,3,7,9,8,1,0};
printArray(arr, 10);
insertSort(arr, 10);
printArray(arr, 10); return;
}Wie oben erwähnt, ist die Auswahlsortierung unter allen Umständen immer ein fester O(n2)-Algorithmus. Obwohl der Einfügungsalgorithmus auch ein O(n2)-Algorithmus ist, kann man sehen, dass er bereits sortiert ist Im Fall von kann die Einfügung direkt aus der Schleife springen. Im Extremfall kann die Einfügungssortierung ein O(n)-Algorithmus sein. In den tatsächlichen Testfällen, die völlig außerhalb der Reihenfolge liegen, wurde jedoch im Vergleich zur Auswahlsortierung in diesem Artikel festgestellt, dass die Laufzeit der Einfügungssortierung länger ist als die der Auswahlsortierung bei derselben Sequenz Da jede äußere Schleife der Auswahlsortierung nur mit den meisten ausgewählten Werten übereinstimmt, muss die Einfügungssortierung einen ständigen Austausch mit benachbarten Elementen erfordern, um die entsprechende Position zu ermitteln. Die drei Zuweisungsoperationen des Austauschs wirken sich daher auch auf die Laufzeit aus Unten optimiert:
Nach der Optimierungsimplementierung:
void insertSort_1(int arr[], int n)
{ int i, j, tmp, elem; for(i = 1; i < n; i++)
{
elem = arr[i]; for(j = i; j > 0; j--)
{ if(elem < arr[j-1])
{
arr[j] = arr[j-1];
} else
{ break;
}
}
arr[j] = elem;
} return;
}Optimierung Der Code speichert den einzufügenden Wert zwischen, verschiebt das Element nach der Einfügeposition um eins nach hinten und ändert die drei Zuweisungen des Austauschs in eine Zuweisung, wodurch die Ausführung reduziert wird Zeit.
4. Einfügungssortierung – Hill-Sortierung
Die Grundidee der Hill-Sortierung besteht darin, zunächst eine Ganzzahl d1 kleiner als n als erstes Inkrement zu nehmen und alle Elemente zu gruppieren. Alle Datensätze, deren Abstand ein Vielfaches von d1 ist, werden in derselben Gruppe platziert. Führen Sie zuerst eine direkte Einfügungssortierung innerhalb jeder Gruppe durch. Nehmen Sie dann das zweite Inkrement d2
1) Die Einfügungssortierung arbeitet mit fast bereits sortierten Daten. Die Effizienz ist hoch Effizienz der linearen Sortierung erreicht werden.
2)但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
排序过程如下:
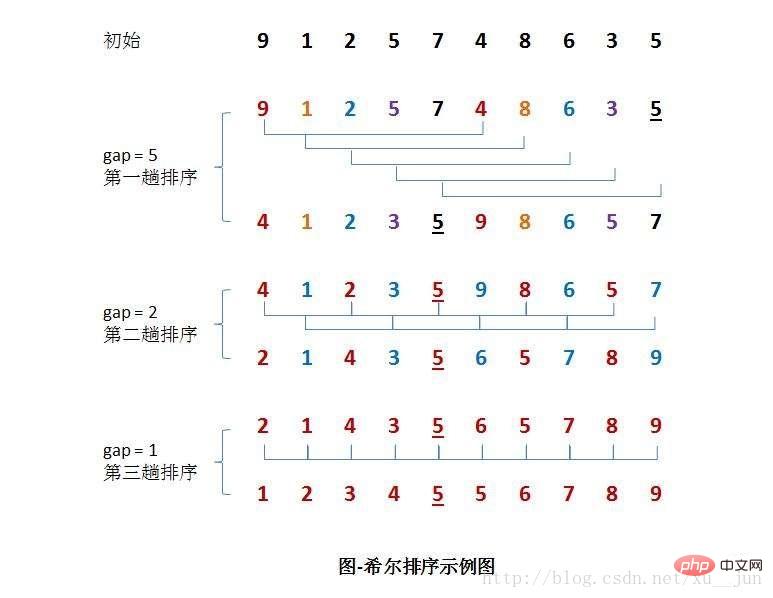
算法实现:基于一种简单的增量分组方式{n/2,n/4,n/8……,1}
void shellSort(int arr[], int n)
{ int i, j, elem; int k = n/2; while(k>=1)
{ for(i = k; i < n; i ++)
{
elem = arr[i]; for(j = i; j >= k; j-=k)
{ if(elem < arr[j-k])
{
arr[j] = arr[j-k];
} else
{ break;
}
}
arr[j] = elem;
}
k = k/2;
}
}void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n"); return;
}void main()
{ int arr[10] = {2,5,6,4,3,7,9,8,1,0};
printArray(arr, 10);
shellSort(arr, 10);
printArray(arr, 10); return;
}5.归并排序
归并排序是基于归并操作的一种排序算法,归并操作的原理就是将一组有序的子序列合并成一个完整的有序序列,即首先需要把一个序列分成多个有序的子序列,通过分解到每个子序列只有一个元素时,每个子序列都是有序的,在通过归并各个子序列得到一个完整的序列。
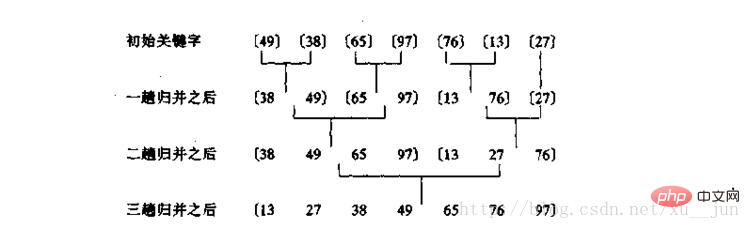
合并过程:
把序列中每个单独元素看作一个有序序列,每两个单独序列归并为一个具有两个元素的有序序列,每两个有两个元素的序列归并为一个四个元素的序列依次类推。两个序列归并为一个序列的方式:因为两个子序列都是有序的(假设由小到大),所有每个子序列最左边都是序列中最小的值,整个序列最小值只需要比较两个序列最左边的值,所以归并的过程不停取子序列最左边值中的最小值放到新的序列中,两个子序列值取完后就得到一个有序的完整序列。
归并的算法实现:
void merge(int arr[], int l, int mid, int r)
{ int len,i, pl, pr; int *tmp = NULL;
len = r - l + 1;
tmp = (int*)malloc(len * sizeof(int)); //申请存放完整序列内存
memset(tmp, 0x0, len * sizeof(int));
pl = l;
pr = mid + 1;
i = 0; while(pl <= mid && pr <= r) //两个子序列都有值,比较最小值
{ if(arr[pl] < arr[pr])
{
tmp[i++] = arr[pl++];
} else
{
tmp[i++] = arr[pr++];
}
} while(pl <= mid) //左边子序列还有值,直接拷贝到新序列中
{
tmp[i++] = arr[pl++];
} while(pr <= r) //右边子序列还有值
{
tmp[i++] = arr[pr++];
} for(i = 0; i < len; i++)
{
arr[i+l] = tmp[i];
} free(tmp); return;
}归并的迭代算法:
迭代算法如上面所说,从单个元素开始合并,子序列长度不停增加直到得到一个长度为n的完整序列。
#include<stdio.h>#include<stdlib.h>#include<string.h>void merge(int arr[], int l, int mid, int r)
{ int len,i, pl, pr; int *tmp = NULL;
len = r - l + 1;
tmp = (int*)malloc(len * sizeof(int)); //申请存放完整序列内存
memset(tmp, 0x0, len * sizeof(int));
pl = l;
pr = mid + 1;
i = 0; while(pl <= mid && pr <= r) //两个子序列都有值,比较最小值
{ if(arr[pl] < arr[pr])
{
tmp[i++] = arr[pl++];
} else
{
tmp[i++] = arr[pr++];
}
} while(pl <= mid) //左边子序列还有值,直接拷贝到新序列中
{
tmp[i++] = arr[pl++];
} while(pr <= r) //右边子序列还有值
{
tmp[i++] = arr[pr++];
} for(i = 0; i < len; i++)
{
arr[i+l] = tmp[i];
} free(tmp); return;
}int min(int x, int y)
{ return (x > y)? y : x;
}/*
归并完成的条件是得到子序列长度等于n,用sz表示当前子序列的长度。从1开始每次翻倍直到等于n。根据上面归并的方法,从i=0开始分组,下一组坐标应该i + 2*sz,第i组第一个元素为arr[i],最右边元素应该为arr[i+2*sz -1],遇到序列最右边元素不够分组的元素个数时应该取n-1,中间的元素为arr[i+sz -1],依次类推进行归并得到完整的序列
*/void mergeSortBu(int arr[], int n)
{ int sz, i, mid,l, r; for(sz = 1; sz < n; sz+=sz)
{ for(i = 0; i < n - sz; i += 2*sz)
{
l = i;
r = i + sz + sz;
mid = i + sz -1;
merge(arr, l, mid, min(r-1, n-1));
}
} return;
}void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n"); return;
}void main()
{ int arr[10] = {2,5,6,4,3,7,9,8,1,0};
printArray(arr, 10);
mergeSortBu(arr, 10);
printArray(arr, 10); return;
}另一种是通过递归的方式,递归方式可以理解为至顶向下的操作,即先将完整序列不停分解为子序列,然后在将子序列归并为完整序列。
递归算法实现:
void mergeSort(int arr[], int l, int r)
{ if(l >= r)
{
return;
} int mid = (l + r)/2;
mergeSort(arr, l, mid);
mergeSort(arr, mid+1, r);
merge(arr, l, mid, r);
return;
}对于归并算法大家可以考虑到由于子序列都是有序的,所有如果左边序列的最大值都比右边序列的最小值小,那么整个序列就是有序的,不需要进行merge操作,因此可以在每次merge操作加一个if(arr[mid] > arr[mid+1])判断进行优化,这种优化对于近乎有序的序列非常有效果,不过对于一般的情况会有一次判断的额外开销,可以根据具体情况处理。
6.快速排序
快速排序跟归并排序类似属于分治法的一种,基本思想是通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
排序过程如图:
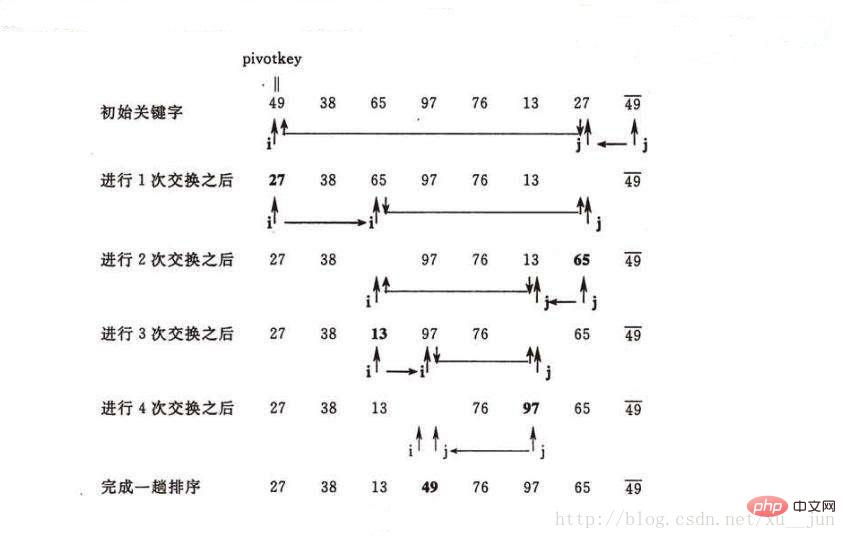
因此,快速排序每次排序将一个序列分为两部分,左边部分都小于等于右边部分,然后在递归对左右两部分进行快速排序直到每部分元素个数为1时则整个序列都是有序的,因此快速排序主要问题在怎样将一个序列分成两部分,其中一部分所有元素都小于另一部分,对于这一块操作我们叫做partition,原理是先选取序列中的一个元素做参考量,比它小的都放在序列左边,比它大的都放在序列右边。
算法实现:
快速排序-单路快排:
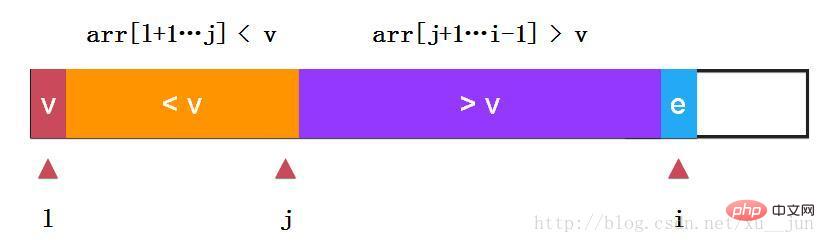
如上:我们选取第一个元素v作为参考量及arr[l],定义j变量为两部分分割哨兵,变量i从l+1开始遍历每个变量,如果当前变量e > v则i++检测下一个元素,如果当前变量e v
代码实现:
#include <stdio.h>void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n"); return;
}void swap(int *a, int *b)
{ int tmp;
tmp = *a;
*a = *b;
*b = tmp; return;
}//arr[l+1...j] < arr[l], arr[j+1,..i)>arr[l]static int partition(int arr[], int l, int r)
{ int i, j;
i = l + 1;
j = l; while(i <= r)
{ if(arr[i] > arr[l])
{
i++;
} else
{
swap(&arr[j + 1], &arr[i]);
i++;
j++;
}
}
swap(&arr[l], &arr[j]); return j;
}static void _quickSort(int arr[], int l, int r)
{ int key; if(l >= r)
{ return;
}
key = partition(arr, l, r);
_quickSort(arr, l, key - 1);
_quickSort(arr, key + 1, r);
}void quickSort(int arr[], int n)
{
_quickSort(arr, 0, n - 1); return;
}void main()
{ int arr[10] = {1,5,9,8,7,6,3,4,0,2};
printArray(arr, 10);
quickSort(arr, 10);
printArray(arr, 10);
}因为有变量i从左到右依次遍历序列元素,所有这种方式叫单路快排,不过细心的同学可以发现我们忽略了考虑e等于v的情况,这种快排方式一大缺点就是对于高重复率的序列即大量e等于v的情况会退化为O(n2)算法,原因在大量e等于v的情况划分情况会如下图两种情况:
 解决这种问题的一另种方法:
解决这种问题的一另种方法:
快速排序-两路快排:
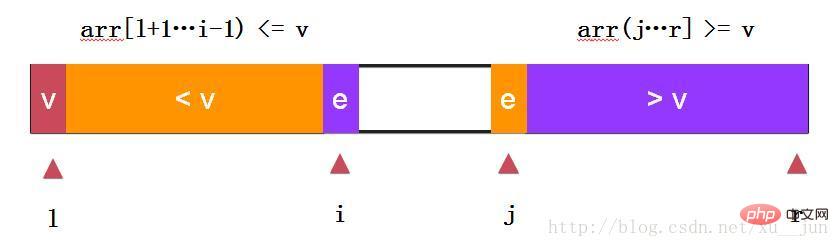
两路快排通过i和j同时向中间遍历元素,e==v的元素分布在左右两个部分,不至于在多重复元素时划分严重失衡。依旧去第一个元素arr[l]为参考量,始终保持arr[l+1….i) =arr[l]原则.
代码实现:
//arr[l+1....i) <=arr[l], arr(j...r] >=arr[l]static int partition2(int arr[], int l, int r)
{ int i, j;
i = l + 1 ;
j = r; while(i <= j)
{ while(i <= j && arr[j] > arr[l]) /*注意arr[j] >arr[l] 不是arr[j] >= arr[l]*/
{
j--;
} while(i <= j && arr[i] < arr[l])
{
i++;
} if(i < j)
{
swap(&arr[i], &arr[j]);
i++;
j--;
}
}
swap(&arr[j],&arr[l]); return j;
}针对重复元素比较多的情况还有一种实现方式:
快速排序-三路快排:
三路快排是在两路快排的基础上对e==v的情况做单独的处理,对于重复元素非常多的情况优势很大:
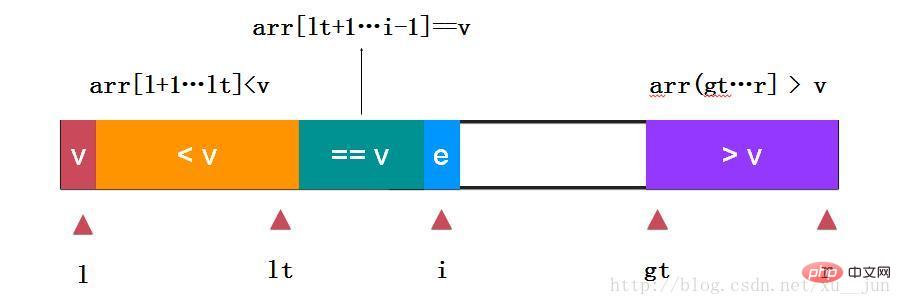
如上:取arr[l]为参考量,定义变量lt为小于v和等于v的分割点,变量i为遍历指针,gt为大于v和未遍历元素分割点,gt指向未遍历元素,边界条件跟个人定义有关本文始终保持arr[l+1…lt] v的状态。
代码实现:
#include <stdio.h>void printArray(int arr[], int n)
{ int i; for(i = 0; i < n; i++)
{ printf("%d ", arr[i]);
} printf("\n"); return;
}
void swap(int *a, int *b)
{ int tmp;
tmp = *a; *a = *b; *b = tmp; return;
}
static void _quickSort3(int arr [ ],int l,int r)
{ int i, lt, gt; if(l >= r)
{ return;
}
i = l + 1; lt = l; gt = r ; while(i <= gt)
{ if(arr[i] < arr[l])
{
swap(&arr[lt + 1], &arr[i]); lt ++;
i++;
} else if(arr[i] > arr[l])
{
swap(&arr[i], &arr[gt]); gt--;
} else
{
i++;
}
}
swap(&arr[l], &arr[gt]);
_quickSort3(arr, l, lt);
_quickSort3(arr, gt + 1, r); return;
}
void quickSort(int arr[], int n)
{
_quickSort3(arr, 0, n - 1); return;
}
void main()
{ int arr[10] = {1,5,9,8,7,6,3,4,0,2};
printArray(arr, 10);
quickSort(arr, 10);
printArray(arr, 10);
}三路快排在重复率比较高的情况下比前两种有较大优势,但就完全随机情况略差于两路快排,可以根据具体情况进行合理选择,另外本文在选取参考值时为了方便一直选择第一个元素为参考值,这种方式对于近乎有序的序列算法会退化到O(n2),因此一般选取参考值可以随机选择参考值或者其他选择参考值的方法然后再与arr[l]交换,依旧可以使用相同的算法。
7.堆排序
堆其实一种树形结构,以二叉堆为例,是一颗完全二叉树(即除最后一层外每个节点都有两个子节点,且非满的二叉树叶节点都在最后一层的左边位置),二叉树满足每个节点都大于等于他的子节点(大顶堆)或者每个节点都小于等于他的子节点(小顶堆),根据堆的定义可以得到堆满足顶点一定是整个序列的最大值(大顶堆)或者最小值(小顶堆)。如下图:
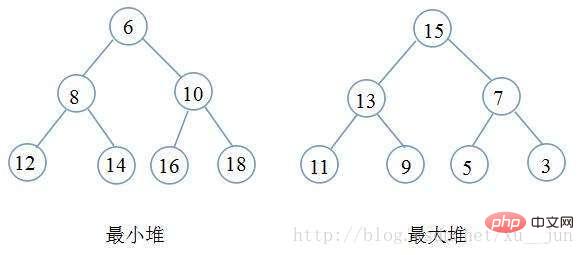
堆排序就是一种基于堆得选择排序,先将需要排序的序列构建成堆,在每次选取堆顶点的最大值和最小值知道完成整个堆的遍历。
用数组表示堆:
二叉堆作为树的一种,通常用结构体表示,为了排序的方便,我们通常使用数组来表示堆,如下图:
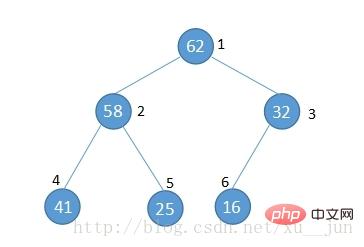
将一个堆按图中的方式按层编号可以得到如下结论:
1)节点的父节点编号满足parent(i) = i/2
2)节点的左孩子编号满足 left child (i) = 2*i
3)节点右孩子满足 right child (i) = 2*i + 1
由于数组编号是从0开始对上面结论修改得到:
parent(i) = (i-1)/2
left child (i) = 2*i + 1
right child (i) = 2*i + 2
堆的两种操作方式:
根据堆的主要性质(父节点大于两个子节点或者小于两个子节点),可以得到堆的两种主要操作方式,以大顶堆为例:
a)如果子节点大于父节点将子节点上移(shift up)
b)如果父节点小于两个子节点中的最大值则父节点下移(shift down)
shift up:
如果往已经建好的堆中添加一个元素,如下图,此时不再满足堆的性质,堆遭到破坏,就需要执行shift up 操作将添加的元素上移调整直到满足堆的性质。
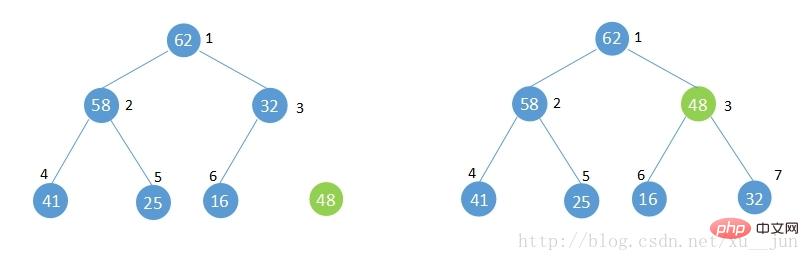
调整堆的方法:
1)7号位新增元素48与其父节点[i/2]=3比较大于父节点的32不满足堆性质,将其与父节点交换。
2)此时新增元素在3号位,再与3号位父节点[i/2]=1比较,小于1号位的62满足堆性质,不再交换,如果此步骤依旧不满足堆性质则重复1步骤直到满足堆的性质或者到根节点。
3)堆调整完成。
代码实现:
代码中基于数组实现,数组下表从0开始,父子节点关系如用数组表示堆
/*parent(i) = (i-1)/2
left child (i) = 2*i + 1
right child (i) = 2*i + 2*/void swap(int *a, int *b)
{ int tmp;
tmp = *a; *a = *b; *b = tmp; return;
}
void shiftUp(int arr[], int n, int k)
{ while((k - 1)/2 >= 0 && arr[k] > arr[(k - 1)/2])
{
swap(&arr[k], &arr[(k-1)/2]);
k = (k - 1)/2;
} return;
}shift down:
与shift up相反,如果从一个建好的堆中删除一个元素,此时不再满足堆的性质,此时应该怎样来调整堆呢? 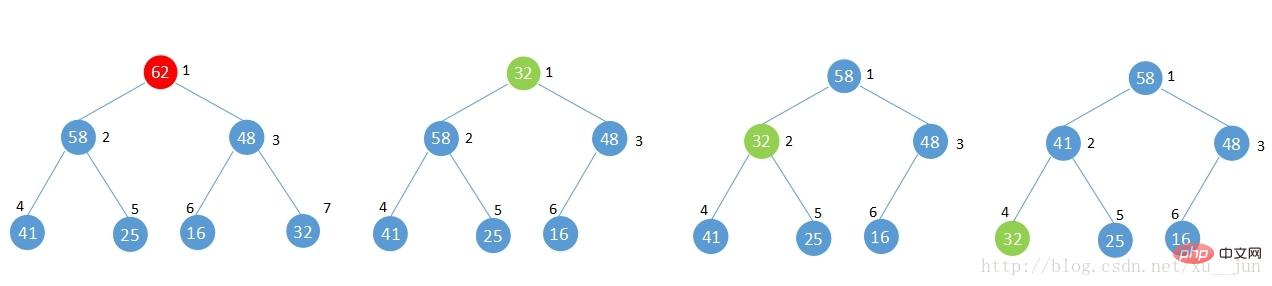
如上图,将堆中根节点元素62删除调整堆的步骤为:
1)将最后一个元素移到删除节点的位置
2)与删除节点两个子节点中较大的子节点比较,如果节点小于较大的子节点,与子节点交换,否则满足堆性质,完成调整。
3)重复步骤2,直到满足堆性质或者已经为叶节点。
4)完成堆调整
代码实现:
void shiftDown(int arr[], int n, int k)
{ int j = 0 ; while(2*k + 1 < n)
{
j = 2 *k + 1; //标记两个子节点较大的节点,初始为左节点
if (j + 1 < n && arr[j] < arr[j+1])
{
j ++;
} if(arr[k] < arr[j])
{
swap(&arr[k], &arr[j]);
k = j;
} else
{ break;
}
} return;
}知道了上面两种堆的操作后,堆排序的过程就非常简单了
1)首先将待排序序列建成堆,由于最后一层即叶节点没有子节点所以可以看成满足堆性质的节点,第一个可能出现不满足堆性质的节点在第一个父节点的位置,假设最后一个叶子节点为(n - 1) 则第一个父节点位置为(n-1-1)/2,只需要依次对第一个父节点之前的节点执行shift down操作到根节点后建堆完成。
2)建堆完成后(以大顶堆为例)第一个元素arr[0]必定为序列中最大值,将最大值提取出来(与数组最后一个元素交换),此时堆不再满足堆性质,再对根节点进行shift down操作,依次循环直到根节点,排序完成。
代码实现:
#include/*parent(i) = (i-1)/2 left child (i) = 2*i + 1 right child (i) = 2*i + 2*/void swap(int *a, int *b) { int tmp; tmp = *a; *a = *b; *b = tmp; return; } void shiftUp(int arr[], int n, int k) { while((k - 1)/2 >= 0 && arr[k] > arr[(k - 1)/2]) { swap(&arr[k], &arr[(k-1)/2]); k = (k - 1)/2; } return; } void shiftDown(int arr[], int n, int k) { int j = 0 ; while(2*k + 1 < n) { j = 2 *k + 1; if (j + 1 < n && arr[j] < arr[j+1]) { j ++; } if(arr[k] < arr[j]) { swap(&arr[k], &arr[j]); k = j; } else { break; } } return; } void heapSort(int arr[], int n) { int i = 0; for(i = (n - 1 -1)/2; i >=0; i--) { shiftDown(arr, n, i); } for(i = n - 1; i > 0; i--) { swap(&arr[0], &arr[i]); shiftDown(arr, i, 0); } return; } void printArray(int arr[], int n) { int i; for(i = 0; i < n; i++) { printf("%d ", arr[i]); } printf("\n"); return; } void main() { int arr[10] = {1,5,9,8,7,6,3,4,0,2}; printArray(arr, 10); heapSort(arr, 10); printArray(arr, 10); }
推荐教程:《C#》
Das obige ist der detaillierte Inhalt vonWelche Sortiermethoden gibt es in der C-Sprache?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So konfigurieren Sie die C-Sprachumgebung mit VSCode
- Welche drei Möglichkeiten gibt es, Funktionen in der C-Sprache aufzurufen?
- Wie ist die Rangfolge der Operatoren in der Sprache C?
- In welcher Reihenfolge werden zweidimensionale Arrays in der C-Sprache im Speicher gespeichert?
- So initialisieren Sie ein Array in der Sprache C