
Heim >Backend-Entwicklung >Python-Tutorial >Ein Artikel zum Verständnis des Problems der Sortierung großer Dateien/externer Speicher
Ein Artikel zum Verständnis des Problems der Sortierung großer Dateien/externer Speicher

- 藏色散人nach vorne
- 2021-07-14 14:01:233931Durchsuche
Frage 1: Eine Datei enthält 500 Millionen Zeilen, jede Zeile ist eine zufällige Ganzzahl und alle Ganzzahlen in der Datei müssen sortiert werden.
Divide and Conquer (pide&Conquer), ReferenzBig-Data-Algorithmus: Sortieren von 500 Millionen Daten
Sortieren Sie diese total.txt mit 500.000.000 Zeilen. Die Dateigröße beträgt 4,6G.
Sortieren und schreiben Sie jedes Mal in eine neue Unterdatei, wenn 10.000 Zeilen gelesen werden (hier verwenden wir Schnellsortierung).
1. Teilen und Sortieren
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('\n'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)generiert 50.000 kleine Dateien, jede kleine Datei ist etwa 96 KB groß.
Während der Ausführung des Programms lag die Speichernutzung bei 5424 kB ca.

Es dauerte 94146 Sekunden, um die Aufteilung der gesamten Datei abzuschließen.
2. Während der Ausführung des Zusammenführungsprogramms
rrreebetrug die Speichernutzung etwa 240M
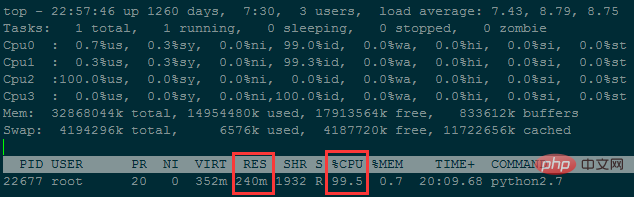

Es dauerte etwa 38 Stunden, um weniger als 50 Millionen Datenzeilen zusammenzuführen. ..
Obwohl die Speichernutzung reduziert wird, ist die zeitliche Komplexität zu hoch. Die Speichernutzung kann weiter reduziert werden, indem die Anzahl der Dateien verringert wird (die Anzahl der in jeder kleinen Datei gespeicherten Zeilen erhöht sich).
Frage 2: Eine Datei enthält 100 Milliarden Datenzeilen, jede Zeile ist eine IP-Adresse und die IP-Adressen müssen sortiert werden. IP-Adresse in Zahlen umwandeln#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('\n'.join([ str(i) for i in nums ]) + '\n')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
wf.write('Runtime : {}'.format(time.time()-now))
Frage 3: Es gibt eine 1,3-GB-Datei (insgesamt 100 Millionen Zeilen). Bitte finden Sie die Zeichenfolge mit den meisten Wiederholungen in der Datei.
Grundidee: Große Dateien iterativ lesen, die großen Dateien in mehrere kleine Dateien aufteilen und diese kleinen Dateien schließlich zusammenführen.
Aufteilungsregeln:
Große Dateien iterativ lesen und ein Wörterbuch im Speicher verwalten. Der Schlüssel ist eine Zeichenfolge und der Wert ist die Anzahl der Vorkommen der Zeichenfolge. Wenn die Anzahl der im Wörterbuch verwalteten Zeichenfolgentypen erreicht ist 10.000 (kann beim Definieren angepasst werden), sortieren Sie das Wörterbuchnach Schlüssel von klein nach groß und schreiben Sie es dann in eine kleine Datei. Jede Zeile ist der Schlüsselwert
Löschen Sie dann das Wörterbuch und lesen Sie weiter, bis die große Datei vorhanden ist fertig.Merge-Regeln:
Rufen Sie zunächstdie Dateideskriptoren aller kleinen Dateien ab und lesen Sie dann die erste Zeile (d. h. die Zeichenfolge mit dem kleinsten ASCII-Wert jeder kleinen Dateizeichenfolge) zum Vergleich aus.
Suchen Sie die Zeichenfolge mit dem kleinsten ASCII-Wert, addieren Sie die Anzahl der Vorkommen und speichern Sie dann die aktuelle Zeichenfolge und die Gesamtzahl in einer Liste im Speicher. Bewegen Sie dann den Lesezeiger der Datei, in der sich die kleinste Zeichenfolge befindet, nach unten, dh lesen Sie eine weitere Zeile aus der entsprechenden kleinen Datei für die nächste Vergleichsrunde. Wenn die Anzahl der Listen im Speicher 10.000 erreicht, wird der Inhalt der Liste sofort in eine endgültige Datei geschrieben und auf der Festplatte gespeichert. Löschen Sie gleichzeitig die Liste für spätere Vergleiche. Bis alle kleinen Dateien gelesen wurden, ist die endgültigeDatei eine große Datei, die in aufsteigender Reihenfolge nach dem ASCII-Wert der Zeichenfolge sortiert ist. Der Inhalt jeder Zeile ist die Anzahl der Wiederholungen der Zeichenfolge t,
endgültige Iteration zum Lesen Suchen Sie für diese endgültige Datei einfach die Datei mit den meisten Wiederholungen. 1. Teilen# 方法一:手动计算
In [62]: ip
Out[62]: '10.3.81.150'
In [63]: ip.split('.')[::-1]
Out[63]: ['150', '81', '3', '10']
In [64]: [ '{}-{}'.format(idx,num) for idx,num in enumerate(ip.split('.')[::-1]) ]
Out[64]: ['0-150', '1-81', '2-3', '3-10']
In [65]: [256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])]
Out[65]: [150, 20736, 196608, 167772160]
In [66]: sum([256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])])
Out[66]: 167989654
In [67]:
# 方法二:使用C扩展库来计算
In [71]: import socket,struct
In [72]: socket.inet_aton(ip)
Out[72]: b'\n\x03Q\x96'
In [73]: struct.unpack("!I", socket.inet_aton(ip))
# !表示使用网络字节顺序解析, 后面的I表示unsigned int, 对应Python里的integer or long
Out[73]: (167989654,)
In [74]: struct.unpack("!I", socket.inet_aton(ip))[0]
Out[74]: 167989654
In [75]: socket.inet_ntoa(struct.pack("!I", 167989654))
Out[75]: '10.3.81.150'
In [76]:
2. Zusammenführendef readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def split_bfile(bfile):
count = 0
d = {}
for line in readline_by_yield(bfile):
line = line.strip()
if line not in d:
d[line] = 0
d[line] += 1
if 10000 == len(d):
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write(text.strip())
d.clear()
count += 1
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile_end.txt','w') as wf:
wf.write(text.strip())
split_bfile('bigfile.txt')
Zusammenführungsergebnisanalyse:
| Wörterbuchgröße bleibt während der Aufteilung im Speicher erhalten | Anzahl der kleinen Dateien, die aufgeteilt werden sollen | Dateibeschreibung, die während der Zusammenführung beibehalten werden soll Anzahl der Symbole | Speicherverbrauch beim Zusammenführen | Zusammenführungszeit | |
| 10000 | 9000 | 9000 ~ 0 | 200M | Die Zusammenführungsgeschwindigkeit ist langsam und die Abschlusszeit nicht wurde schon berechnet | |
| 100000 | 900 | 900 ~ 0 | 27m | ist schnell, nur 2572 Sekunden |
3. Finden Sie die Zeichenfolge mit den meisten Vorkommen Anzahl der Sekunden Die endgültige Datei hat insgesamt 9999788 Zeilen und ist 256 MB groß. Die Suche dauert 27 Sekunden und belegt 6480 KB Speicher.
Das obige ist der detaillierte Inhalt vonEin Artikel zum Verständnis des Problems der Sortierung großer Dateien/externer Speicher. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!