
Heim >Backend-Entwicklung >PHP-Tutorial >Mit „Xiaobai' lernen Sie die Module und Arbeitsprinzipien von Nginx kennen! ! !
Mit „Xiaobai' lernen Sie die Module und Arbeitsprinzipien von Nginx kennen! ! !

- 慕斯nach vorne
- 2021-05-21 17:30:073445Durchsuche
NGINX ist berühmt für seinen leistungsstarken Load Balancer, Cache und Webserver, der mehr als 40 % der weltweit am stärksten frequentierten Websites betreibt, daher hat
einen gewissen Referenzwert, Freunde in Not können sich darauf beziehen, ich Ich hoffe, es wird für alle hilfreich sein. 1. Nginx-Module und Arbeitsprinzipien. Nginx besteht aus Kernel und Modulen. Das Design des Kernels ist sehr klein und einfach. Die abgeschlossene Arbeit ist ebenfalls sehr einfach: Durch Nachschlagen der Konfigurationsdatei wird die Clientanforderung einfach einem Standortblock zugeordnet (Standort ist eine Direktive in der Nginx-Konfiguration, die für den URL-Abgleich verwendet wird), und jede an diesem Standort konfigurierte Direktive wird gestartet ein anderes Modul zur Vervollständigung der entsprechenden Arbeit.
Nginx-Module sind strukturell in Kernmodule, Basismodule und Drittanbietermodule unterteilt: 
Kernmodule:
HTTP-Modul, EVENT-Modul und MAIL-Modul Grundmodule:
HTTP-Zugriffsmodul, HTTP FastCGI Modul, HTTP-Proxy-Modul und HTTP-Rewrite-Modul, Module von Drittanbietern:
HTTP-Upstream-Request-Hash-Modul, Hinweismodul und HTTP-Zugriffsschlüsselmodul. Module, die von Benutzern nach ihren eigenen Bedürfnissen entwickelt werden, sind Module von Drittanbietern. Gerade durch die Unterstützung so vieler Module sind die Funktionen von Nginx so leistungsstark.
Nginx-Module sind funktional in die folgenden drei Kategorien unterteilt. Handler (Prozessormodule). Dieser Modultyp verarbeitet Anforderungen direkt und führt Vorgänge wie die Ausgabe von Inhalten und die Änderung von Header-Informationen aus. Im Allgemeinen kann es nur ein Handler-Prozessormodul geben. Filter (Filtermodul). Dieser Modultyp ändert hauptsächlich den von anderen Prozessormodulen ausgegebenen Inhalt und wird schließlich von Nginx ausgegeben.
Proxies (Proxy-Klassenmodul). Solche Module sind Module wie HTTP Upstream von Nginx. Diese Module interagieren hauptsächlich mit einigen Back-End-Diensten wie FastCGI, um Funktionen wie Service-Proxy und Lastausgleich zu implementieren. Abbildung 1-1 zeigt den normalen HTTP-Anfrage- und Antwortprozess des Nginx-Moduls.
Nginx selbst erledigt eigentlich nur sehr wenig Arbeit. Wenn es eine HTTP-Anfrage empfängt, ordnet es die Anfrage lediglich einem Standortblock zu, indem es die Konfigurationsdatei nachschlägt, und die Konfiguration an diesem Standort startet jeden Befehl anders Module müssen die Arbeit abschließen, sodass die Module als die eigentlichen Arbeitskräfte von Nginx angesehen werden können. Normalerweise umfassen Anweisungen an einem Standort ein Handlermodul und mehrere Filtermodule (natürlich können mehrere Standorte dasselbe Modul wiederverwenden). Das Handler-Modul ist für die Verarbeitung von Anfragen und den Abschluss der Generierung von Antwortinhalten verantwortlich, während das Filtermodul den Antwortinhalt verarbeitet.
Nginx-Module werden direkt in Nginx kompiliert, es handelt sich also um eine statische Kompilierungsmethode. Nach dem Start von Nginx wird das Nginx-Modul automatisch geladen. Im Gegensatz zu Apache wird das Modul zunächst in eine SO-Datei kompiliert und dann in der Konfigurationsdatei angegeben, ob es geladen werden soll. Beim Parsen der Konfigurationsdatei kann jedes Modul von Nginx eine bestimmte Anforderung verarbeiten, aber dieselbe Verarbeitungsanforderung kann nur von einem Modul abgeschlossen werden.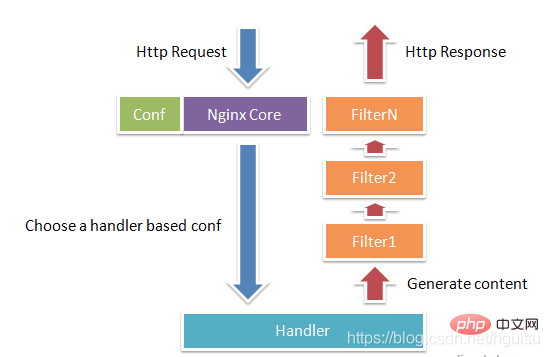
In Bezug auf den Arbeitsmodus ist Nginx in zwei Modi unterteilt: Single-Worker-Prozess und Multi-Worker-Prozess. Im Single-Worker-Prozessmodus gibt es zusätzlich zum Hauptprozess auch einen Single-Threaded-Worker-Prozess. Im Multi-Worker-Prozessmodus enthält jeder Worker-Prozess mehrere Threads. Nginx verwendet standardmäßig den Einzelarbeitsprozessmodus.
Nach dem Start von Nginx gibt es einen Master-Prozess und mehrere Worker-Prozesse.1. Master-Prozess: Managementprozess
Der Master-Prozess wird hauptsächlich zur Verwaltung des Worker-Prozesses verwendet, einschließlich der folgenden 4 Hauptfunktionen:
(1) Empfangen von Signalen von der Außenwelt.
(2) Senden Sie Signale an jeden Arbeitsprozess.
(3) Überwachen Sie den laufenden Status des Woker-Prozesses.
(4) Wenn der Woker-Prozess beendet wird (unter ungewöhnlichen Umständen), wird der neue Woker-Prozess automatisch neu gestartet.
Benutzerinteraktionsschnittstelle: Der Masterprozess dient als interaktive Schnittstelle zwischen der gesamten Prozessgruppe und dem Benutzer und überwacht gleichzeitig den Prozess. Es muss keine Netzwerkereignisse verarbeiten und ist nicht für die Geschäftsausführung verantwortlich. Es verwaltet lediglich Arbeitsprozesse, um Funktionen wie Dienstneustart, reibungsloses Upgrade, Protokolldateiersetzung und Konfigurationsdateien zu implementieren, die in Echtzeit wirksam werden.
Starten Sie den Arbeitsprozess neu: Wenn wir Nginx steuern möchten, müssen wir nur durch Kill ein Signal an den Master-Prozess senden. Beispielsweise weist kill -HUP pid Nginx an, Nginx ordnungsgemäß neu zu starten oder die Konfiguration neu zu laden. Da es ordnungsgemäß neu gestartet wird, wird der Dienst nicht unterbrochen.
Was macht der Masterprozess nach dem Empfang des HUP-Signals?
1) Nach Erhalt des Signals lädt der Master-Prozess zunächst die Konfigurationsdatei neu, startet dann einen neuen Worker-Prozess und sendet Signale an alle alten Worker-Prozesse, um ihnen mitzuteilen, dass sie ordnungsgemäß in den Ruhestand gehen können.
2) Nachdem der neue Worker gestartet ist, empfängt er neue Anfragen, während der alte Worker nach Erhalt des Signals vom Master keine neuen Anfragen mehr empfängt und alle nicht verarbeiteten Anfragen im aktuellen Prozess abgeschlossen sind , Ausfahrt.
Senden Sie Signale direkt an den Master-Prozess. Nach der Nginx-Version 0.8 wurde eine Reihe von Befehlszeilenparametern eingeführt, um unsere Verwaltung zu erleichtern. Zum Beispiel dient ./nginx -s reload dazu, Nginx neu zu starten, und ./nginx -s stop dient dazu, die Ausführung von Nginx zu stoppen. Wie geht das? Nehmen wir als Beispiel Reload. Wir sehen, dass wir beim Ausführen des Befehls einen neuen Nginx-Prozess starten. Nachdem der neue Nginx-Prozess den Reload-Parameter analysiert hat, wissen wir, dass unser Zweck darin besteht, Nginx so zu steuern, dass er die Konfigurationsdatei neu lädt sendet ein Signal an den Master-Prozess, und die nächste Aktion ist dieselbe, als ob wir das Signal direkt an den Master-Prozess senden würden.
2. Worker-Prozess: Verarbeitung von Anfragen
Grundlegende Netzwerkereignisse werden im Worker-Prozess verarbeitet. Mehrere Worker-Prozesse sind Peer-to-Peer. Sie konkurrieren gleichermaßen um Anfragen von Kunden und jeder Prozess ist unabhängig voneinander. Eine Anfrage kann nur in einem Arbeitsprozess verarbeitet werden, und ein Arbeitsprozess kann keine Anfragen von anderen Prozessen verarbeiten. Die Anzahl der Arbeitsprozesse kann im Allgemeinen so eingestellt werden, dass sie mit der Anzahl der CPU-Kerne der Maschine übereinstimmt. Der Grund dafür ist untrennbar mit dem Prozessmodell und dem Ereignisverarbeitungsmodell von Nginx verbunden.
Arbeitsprozesse sind gleich und jeder Prozess hat die gleiche Möglichkeit, Anfragen zu bearbeiten. Wenn wir einen HTTP-Dienst auf Port 80 bereitstellen und eine Verbindungsanfrage eingeht, kann jeder Prozess die Verbindung verarbeiten.
Nginx verwendet eine asynchrone, nicht blockierende Methode zur Verarbeitung von Netzwerkereignissen, ähnlich wie Libevent. Der spezifische Prozess ist wie folgt:
1) Empfangen einer Anfrage: Zunächst verzweigt sich jeder Arbeitsprozess vom Masterprozess und wird eingerichtet Der Master-Prozess Nachdem er den Socket abhören muss (listenfd), verteilt er anschließend mehrere Worker-Prozesse. Der Listenfd aller Worker-Prozesse wird lesbar, wenn eine neue Verbindung eintrifft, und jeder Worker-Prozess kann diesen Socket (listenfd) akzeptieren. Wenn eine Client-Verbindung eintrifft, werden alle akzeptierenden Arbeitsprozesse benachrichtigt, aber nur ein Prozess kann erfolgreich akzeptieren, und die anderen akzeptieren nicht. Um sicherzustellen, dass nur ein Prozess die Verbindung verarbeitet, stellt Nginx eine gemeinsame Sperre „accept_mutex“ bereit, um sicherzustellen, dass nur ein Arbeitsprozess gleichzeitig die Verbindung akzeptiert. Alle Arbeitsprozesse greifen auf „accept_mutex“ zu, bevor sie das Listenfd-Leseereignis registrieren. Der Prozess, der die Mutex-Sperre erfasst, registriert das Listenfd-Leseereignis und ruft „Accept“ im Leseereignis auf, um die Verbindung zu akzeptieren.
2) Anfragen verarbeiten: Wenn ein Arbeitsprozess die Verbindung akzeptiert, beginnt er, die Anfrage zu lesen, die Anfrage zu analysieren, die Anfrage zu verarbeiten, Daten zu generieren und sie dann an den Client zurückzugeben und schließlich die Verbindung zu trennen a vollständig Die Anfrage sieht so aus.
Wir können sehen, dass eine Anfrage vollständig vom Worker-Prozess verarbeitet wird und nur in einem Worker-Prozess verarbeitet wird. Worker-Prozesse sind gleich und jeder Prozess hat die gleichen Möglichkeiten, Anfragen zu bearbeiten. Das Prozessmodell von
nginx kann durch die folgende Abbildung dargestellt werden:
3. Warum Nginx eine hohe Leistung hat – Multiprozess-IO-Modell 7&idx= 3&sn=cfa8a70a5fd2a674a91076f67808273c&scene=23&srcid=0401aeJQEraSG6uvLj69Hfve#rd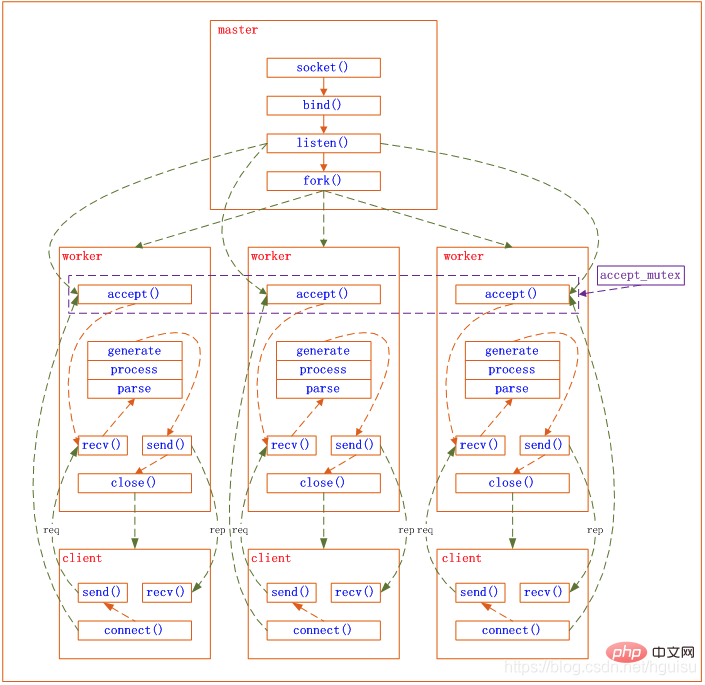
1. Vorteile von Nginx mit Multiprozessmodell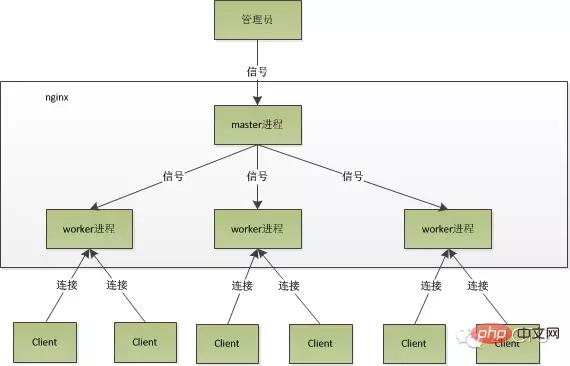
Erstens: Für jeden Arbeitsprozess müssen im Allgemeinen unabhängige Prozesse nicht gesperrt werden, daher die Sperre Der Riemen wird weggelassen, was den Aufwand reduziert und auch die Programmierung und Problemsuche wesentlich erleichtert. Zweitens wirkt sich die Verwendung unabhängiger Prozesse nicht gegenseitig aus. Nachdem ein Prozess beendet wurde, funktionieren andere Prozesse weiterhin, der Dienst wird nicht unterbrochen und der Masterprozess startet schnell einen neuen Arbeitsprozess. Wenn der Worker-Prozess abnormal beendet wird, muss natürlich ein Fehler im Programm vorliegen, der dazu führt, dass alle Anforderungen des aktuellen Workers fehlschlagen. Dies wirkt sich jedoch nicht auf alle Anforderungen aus, sodass das Risiko verringert wird. 2. Nginx-Multiprozess-Ereignismodell: asynchron und nicht blockierend Die Anzahl der Parallelitäten, die es verarbeiten kann, ist sehr begrenzt. Wie viele Arbeiter können so viele Parallelitäten wie möglich verarbeiten? Wie können wir also eine hohe Parallelität erreichen? Nein, das ist die Genialität von Nginx.
Nginx verwendet eine asynchrone und nicht blockierende Methode, um Anfragen zu verarbeiten. Mit anderen Worten: Nginx kann Tausende von Anfragen gleichzeitig verarbeiten.
Die Anzahl der Anfragen, die ein Arbeitsprozess gleichzeitig verarbeiten kann, ist nur durch die Speichergröße begrenzt, und in Bezug auf das Architekturdesign gibt es bei der Verarbeitung gleichzeitiger Anforderungen zwischen verschiedenen Arbeitsprozessen nahezu keine Einschränkungen für Synchronisationssperren Wechselt normalerweise nicht in den Ruhezustand. Wenn also die Anzahl der Prozesse auf Nginx der Anzahl der CPU-Kerne entspricht (es ist am besten, wenn jeder Arbeitsprozess an einen bestimmten CPU-Kern gebunden ist), betragen die Kosten für den Wechsel zwischen Prozessen minimal.Und die übliche Arbeitsweise von Apache (Apache hat auch eine asynchrone, nicht blockierende Version, die jedoch mit einigen seiner eigenen Module in Konflikt steht und daher nicht häufig verwendet wird):
Jeder Prozess verarbeitet jeweils nur eine Anfrage,
AlsoWenn die Anzahl der Parallelitäten Tausende erreicht, werden Tausende von ProzessenAnfragen gleichzeitig verarbeiten. Dies stellt eine große Herausforderung für das Betriebssystem dar. Der durch den
Prozessverursachte Speicherverbrauch ist natürlich nicht verbesserungsfähig völlig bedeutungslos. Einzelheiten finden Sie unter: Verwendung von libevent und libev zur Verbesserung der Netzwerkanwendungsleistung – Geschichte der Entwicklung des I/O-Modells Kehren wir zum ursprünglichen Punkt zurück und betrachten den gesamten Prozess einer Anfrage: Zuerst kommt die Anfrage, die Verbindung Nach der Einrichtung werden die Daten empfangen. Nach dem Empfang der Daten werden die Daten erneut gesendet.
aber Wenn das Lese- und Schreibereignis nicht bereit ist, handelt es sich um Lese- und Schreibereignisse. Wenn Sie warten können, warten Sie, bis das Ereignis bereit ist, bevor Sie fortfahren. Blockierende Aufrufe gelangen in den Kernel und warten, und die CPU wird von anderen verwendet. Dies ist offensichtlich nicht für Single-Threaded-Worker geeignet. Wenn es mehr Netzwerkereignisse gibt, wird niemand die CPU verwenden CPU-Auslastung im Leerlauf Natürlich kann die Rate nicht erhöht werden, geschweige denn eine hohe Parallelität. Nun, Sie sagten, die Erhöhung der Anzahl der Prozesse, was ist der Unterschied zwischen diesem und dem Threading-Modell von Apache? Achten Sie darauf, unnötige Kontextwechsel zu vermeiden. Daher ist das Blockieren von Systemaufrufen in Nginx am tabu. Nicht blockieren, dann ist es nicht blockierend. Nicht blockierend bedeutet, dass, wenn die Veranstaltung noch nicht bereit ist, sofort zu EAGAIN zurückgekehrt wird, um Ihnen mitzuteilen, dass die Veranstaltung noch nicht bereit ist. Warum geraten Sie in Panik? Okay, überprüfen Sie das Ereignis nach einer Weile erneut, bis das Ereignis bereit ist. In diesem Zeitraum können Sie zunächst andere Dinge tun und dann prüfen, ob das Ereignis bereit ist. Obwohl es nicht mehr blockiert ist, müssen Sie von Zeit zu Zeit den Status des Ereignisses überprüfen. Sie können mehr tun, aber der Aufwand ist nicht gering.Über das IO-Modell: http://blog.csdn.net/hguisu/article/details/7453390
Die von Nginx unterstützten Ereignismodelle sind wie folgt (Nginx-Wiki):
Nginx unterstützt die Nach der Verarbeitung von Verbindungsmethoden (E/A-Wiederverwendungsmethoden) können diese Methoden über die use-Direktive angegeben werden.
- select – die Standardmethode. Dies ist die Standardeinstellung zur Kompilierungszeit, wenn es für die aktuelle Plattform keine effizientere Methode gibt. Sie können dieses Modul mit den Konfigurationsparametern –with-select_module und –without-select_module aktivieren oder deaktivieren.
- Umfrage – die Standardmethode. Dies ist die Standardeinstellung zur Kompilierungszeit, wenn es für die aktuelle Plattform keine effizientere Methode gibt. Sie können dieses Modul mit den Konfigurationsparametern –with-poll_module und –without-poll_module aktivieren oder deaktivieren.
- kqueue – Effiziente Methode, die in FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 und MacOS
- epoll – Eine effiziente Methode, die in Linux-Kernel-Versionen 2.6 und späteren Systemen verwendet wird. In einigen Distributionen, wie zum Beispiel SuSE 8.2, gibt es einen Patch zur Unterstützung von Epoll im 2.4-Kernel.
- rtsig – Ausführbares Echtzeitsignal, verwendet auf Systemen mit Linux-Kernel-Version 2.2.19 oder höher. Standardmäßig können im gesamten System nicht mehr als 1024 POSIX-Echtzeitsignale (in der Warteschlange) angezeigt werden. Diese Situation ist für stark ausgelastete Server ineffizient; daher ist es notwendig, die Warteschlangengröße durch Anpassen des Kernel-Parameters /proc/sys/kernel/rtsig-max zu erhöhen. Ab der Linux-Kernel-Version 2.6.6-mm2 wird dieser Parameter jedoch nicht mehr verwendet und es gibt für jeden Prozess eine unabhängige Signalwarteschlange. Die Größe dieser Warteschlange kann mit dem Parameter RLIMIT_SIGPENDING angepasst werden. Wenn diese Warteschlange zu überlastet ist, verlässt Nginx sie und beginnt mit der Poll-Methode zur Verarbeitung von Verbindungen, bis sie wieder normal ist.
- /dev/poll – Effiziente Methode, verwendet auf Solaris 7 11/99+, HP/UX 11.22+ (Eventport), IRIX 6.5.15+ und Tru64 UNIX 5.1A+.
- eventport – Effiziente Methode, Wird unter Solaris 10 verwendet. Um Kernel-Abstürze zu verhindern, ist die Installation dieses Sicherheitspatches erforderlich.
‐ touse and spoll to handle. Um epoll zu verwenden, benötigen Sie nur diese drei Systemaufrufe: epoll_create(2), epoll_ctl(2), epoll_wait(2). Es wurde im 2.5.44-Kernel eingeführt (epoll(4) ist eine neue API, die im Linux-Kernel 2.5.44 eingeführt wurde) und wird im 2.6-Kernel häufig verwendet.
Vorteile von Epoll
Unterstützt einen Prozess zum Öffnen einer großen Anzahl von Socket-Deskriptoren (FD) Verwenden Sie FD_SETSIZE mit FD_SETSIZE FD_SETSIZE, um eine große Anzahl von Socket-Deskriptoren zu öffnen. Für IM-Server, die Zehntausende Verbindungen unterstützen müssen, ist das offensichtlich zu wenig. Zu diesem Zeitpunkt können Sie zunächst dieses Makro ändern und den Kernel neu kompilieren. Die Daten weisen jedoch auch darauf hin, dass dies zu einer Verringerung der Netzwerkeffizienz führt. Zweitens können Sie eine Multiprozesslösung (traditionelle Apache-Lösung) wählen. Obwohl es unter Linux erstellt wird, sind die Kosten des Prozesses relativ gering, können aber dennoch nicht ignoriert werden. Darüber hinaus ist die Datensynchronisation zwischen Prozessen weitaus weniger effizient als die Synchronisation zwischen Threads, sodass sie keine perfekte Lösung darstellt. Bei epoll gibt es diese Einschränkung jedoch nicht. Die maximale Anzahl der Dateien, die geöffnet werden können, liegt im Allgemeinen bei 1 GB . Die spezifische Nummer kann lauten: cat /proc Überprüfen Sie /sys/fs/file-max. Im Allgemeinen hat diese Nummer viel mit dem Systemspeicher zu tun.
- IO-Effizienz nimmt nicht linear ab, wenn die Anzahl der FDs zunimmt
Eine weitere fatale Schwäche der herkömmlichen Auswahl/Abfrage besteht darin, dass bei einem großen Socket-Satz aufgrund der Netzwerklatenz nur einige der Sockets „aktiv“ sind „jedes Mal“, aber jeder Aufruf von „select/poll“ scannt linear die gesamte Sammlung, was zu einer linearen Verringerung der Effizienz führt. Aber epoll hat dieses Problem nicht, es funktioniert nur auf „aktiven“ Sockets – das liegt daran, dass epoll in der Kernel-Implementierung basierend auf der Rückruffunktion auf jedem fd implementiert wird. Dann rufen nur „aktive“ Sockets die Rückruffunktion aktiv auf, andere Sockets im Leerlaufzustand jedoch nicht. Zu diesem Zeitpunkt implementiert epoll ein „Pseudo“-AIO, da die treibende Kraft zu diesem Zeitpunkt im Betriebssystemkernel liegt. Wenn in einigen Benchmarks grundsätzlich alle Sockets aktiv sind – beispielsweise in einer Hochgeschwindigkeits-LAN-Umgebung – ist epoll nicht effizienter als select/poll. Im Gegenteil, wenn epoll_ctl zu oft verwendet wird, sinkt die Effizienz leicht. Sobald jedoch inaktive Verbindungen zur Simulation einer WAN-Umgebung verwendet werden, ist die Effizienz von Epoll weitaus höher als die von Select/Poll.
- Verwenden Sie mmap, um die Nachrichtenübermittlung zwischen Kernel und Benutzerbereich zu beschleunigen.
Dieser Punkt betrifft tatsächlich die spezifische Implementierung von Epoll. Unabhängig davon, ob es sich um Select, Poll oder Epoll handelt, ist es sehr wichtig, dass der Kernel den Benutzerbereich über die FD-Nachricht informiert, um unnötige Speicherkopien zu vermeiden Kernel. Und wenn Sie wie ich Epoll seit dem 2.5-Kernel verfolgen, werden Sie den manuellen mmap-Schritt bestimmt nicht vergessen.
- Kernel-Feinabstimmung
Dies ist eigentlich kein Vorteil von Epoll, sondern ein Vorteil der gesamten Linux-Plattform. Vielleicht können Sie an der Linux-Plattform zweifeln, aber Sie kommen nicht um die Möglichkeit herum, die die Linux-Plattform Ihnen bietet, den Kernel zu optimieren. Beispielsweise verwendet der Kernel-TCP/IP-Protokollstapel einen Speicherpool zur Verwaltung der sk_buff-Struktur. Anschließend kann die Größe dieses Speicherpools (skb_head_pool) während der Laufzeit dynamisch angepasst werden – vervollständigt durch echo XXXX>/proc/sys/net/core /hot_list_length. Ein weiteres Beispiel ist der zweite Parameter der Listen-Funktion (die Länge der Paketwarteschlange, nachdem TCP den Drei-Wege-Handshake abgeschlossen hat), der ebenfalls dynamisch an die Speichergröße Ihrer Plattform angepasst werden kann. Wir haben sogar die neueste NAPI-Netzwerkkartentreiberarchitektur auf einem speziellen System ausprobiert, bei dem die Anzahl der Datenpakete riesig, die Größe jedes Datenpakets selbst jedoch sehr klein ist.
(Epoll-Inhalt, siehe epoll_Interactive Encyclopedia)
Es wird empfohlen, die Anzahl der Worker auf die Anzahl der CPU-Kerne einzustellen. Dies führt nur dazu, dass Prozesse mit der CPU konkurrieren Ressourcen werden verbraucht, was zu unnötigen Kontextwechseln führt. Um die Multi-Core-Funktionen besser nutzen zu können, bietet Nginx außerdem eine CPU-Affinitätsbindungsoption. Wir können einen bestimmten Prozess an einen bestimmten Kern binden, sodass der Cache nicht aufgrund von Prozesswechseln ausfällt. Kleine Optimierungen wie diese sind in Nginx weit verbreitet und verdeutlichen auch die sorgfältigen Bemühungen des Nginx-Autors. Wenn Nginx beispielsweise 4-Byte-Strings vergleicht, konvertiert es die 4 Zeichen in einen int-Typ und vergleicht sie dann, um die Anzahl der CPU-Anweisungen usw. zu reduzieren.
Code zur Zusammenfassung des Nginx-Ereignisverarbeitungsmodells:
while (true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks: /* sorted already */
if (t.time <= now) {
t.timeout_handler();
} else {
timeout = t.time - now;
break;
}
nevents = poll_function(events, timeout);
for i in nevents:
task t;
if (events[i].type == READ) {
t.handler = read_handler;
} else { /* events[i].type == WRITE */
t.handler = write_handler;
}
run_tasks_add(t);
}
IV. Nginx+FastCGI-Funktionsprinzip
1
FastCGI ist eine An-Schnittstelle für skalierbare Hochgeschwindigkeitskommunikation zwischen HTTP-Servern und dynamischen Skriptsprachen. Die meisten gängigen HTTP-Server unterstützen FastCGI, einschließlich Apache, Nginx, lighttpd usw. Gleichzeitig wird FastCGI auch von vielen Skriptsprachen unterstützt, darunter PHP.
FastCGI wurde aus CGI entwickelt und verbessert. Der Hauptnachteil der herkömmlichen CGI-Schnittstellenmethode ist die schlechte Leistung, da der Skriptparser jedes Mal, wenn der HTTP-Server auf ein dynamisches Programm trifft, neu gestartet werden muss, um die Analyse durchzuführen, und die Ergebnisse dann an den HTTP-Server zurückgegeben werden. Dies ist bei hohem gleichzeitigem Zugriff nahezu unbrauchbar. Darüber hinaus weist die traditionelle CGI-Schnittstellenmethode eine geringe Sicherheit auf und wird heutzutage nur noch selten verwendet.
Der FastCGI-Schnittstellenmodus verwendet eine C/S-Struktur, die den HTTP-Server und den Skript-Parsing-Server trennen und einen oder mehrere Skript-Parsing-Daemons auf dem Skript-Parsing-Server starten kann. Jedes Mal, wenn der HTTP-Server auf ein dynamisches Programm trifft, kann es zur Ausführung direkt an den FastCGI-Prozess übermittelt und das Ergebnis dann an den Browser zurückgegeben werden. Mit dieser Methode kann der HTTP-Server ausschließlich statische Anforderungen verarbeiten oder die Ergebnisse des dynamischen Skriptservers an den Client zurückgeben, was die Leistung des gesamten Anwendungssystems erheblich verbessert.
2. Nginx+FastCGI-Funktionsprinzip
Nginx unterstützt keinen direkten Aufruf oder Parsing externer Programme (einschließlich PHP) muss über die FastCGI-Schnittstelle aufgerufen werden. Die FastCGI-Schnittstelle ist ein Socket unter Linux (dieser Socket kann ein Datei-Socket oder ein IP-Socket sein).
Wrapper: Um ein CGI-Programm aufzurufen, wird auch ein FastCGI-Wrapper benötigt (ein Wrapper kann als ein Programm verstanden werden, mit dem ein anderes Programm gestartet wird, z. B. ein Port oder eine Datei). Buchse. Wenn Nginx eine CGI-Anfrage an diesen Socket sendet, empfängt der Wrapper die Anfrage über die FastCGI-Schnittstelle und leitet dann einen neuen Thread ab. Dieser Thread ruft den Interpreter oder das externe Programm auf, um das Skript zu verarbeiten und die Rückgabedaten zu lesen. Der Wrapper leitet dann die zurückgegebenen Daten über die FastCGI-Schnittstelle an Nginx weiter und schließlich sendet Nginx die zurückgegebenen Daten (HTML-Seite oder Bild) an den Client. Dies ist der gesamte Betriebsprozess von Nginx + FastCGI, wie in Abbildung 1-3 dargestellt.我们,
, also brauchen wir zuerst einen Wrapper, dieser Wrapper muss abgeschlossen sein: 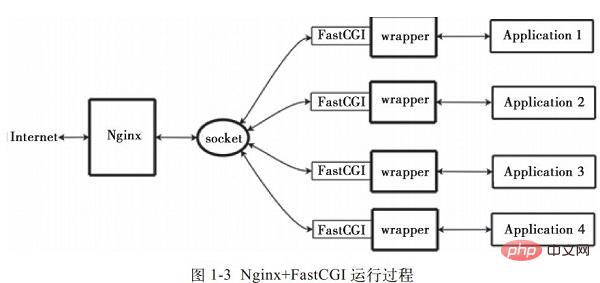 Die Funktion von FastCGI (Bibliothek) heißt , für den Wrapper nicht transparent)
Die Funktion von FastCGI (Bibliothek) heißt , für den Wrapper nicht transparent)
Planung von Thread, Fork und Kill
Kommunikation mit Anwendung (php)
- 3. Spawn-fcgi und PHP-FPM
- FastCGI-Schnittstellenmodus auf dem Skript-Parsing-Server. Starten Sie einen oder mehrere Daemon-Prozesse, um dynamische Skripte zu analysieren FastCGI-Engine. spawn-fcgi und PHP-FPM sind zwei FastCGI-Prozessmanager, die PHP unterstützen.
Somit ist HTTPServer vollständig entlastet und kann besser reagieren und Parallelität besser handhaben.
Die Gemeinsamkeiten und Unterschiede zwischen spawn-fcgi und PHP-FPM: 1) spawn-fcgi ist Teil des HTTP-Servers lighttpd und wird im Allgemeinen in Verbindung mit lighttpd zur Unterstützung von PHP verwendet. Allerdings kann spwan-fcgi von ligttpd Speicherverluste verursachen oder FastCGI bei hohem gleichzeitigem Zugriff sogar automatisch neu starten. Das heißt: Der PHP-Skriptprozessor stürzt ab. Wenn der Benutzer zu diesem Zeitpunkt darauf zugreift, wird möglicherweise eine weiße Seite angezeigt (d. h. PHP kann nicht analysiert werden oder es tritt ein Fehler auf). 2) Nginx ist ein leichtgewichtiger HTTP-Server und muss zum Parsen von PHP einen FastCGI-Prozessor eines Drittanbieters verwenden. Es scheint also, dass
nginx
sehr flexibel ist und mit jedem Drittanbieter interagieren kann, der einen Parsing-Prozessor bereitstellt um eine Verbindung herzustellen, um das Parsen von
PHP zu erreichen ( lässt sich einfach in nginx.conf einrichten). nginx kann auch spwan-fcgi verwenden ( muss zusammen mit lighttpd installiert werden, aber Sie müssen Ports für nginx vermeiden, einige ältere Blog habe das Installation Das Tutorial ), aber weil spawn-fcgi die oben erwähnten Fehler nach und nach von Benutzern entdeckt wurden, wird die Kombination von nginx+spawn-fcgi jetzt langsam reduziert. Aufgrund der Mängel von spawn-fcgi gibt es jetzt einen PHP-FastCGI-Prozessor eines Drittanbieters (derzeit zum PHP-Kern hinzugefügt), der im Vergleich zu spawn-fcgi die folgenden Vorteile hat: Weil es so ist Da es als PHP-Patch entwickelt wurde, muss es während der Installation zusammen mit dem PHP-Quellcode kompiliert werden, was bedeutet, dass es in den PHP-Kern kompiliert wird, sodass es hinsichtlich der Leistung besser ist Gleichzeitig ist es auch besser als spawn im Umgang mit hoher Parallelität, zumindest wird der Fastcgi-Prozessor nicht automatisch neu gestartet. Daher wird empfohlen, zum Parsen von PHP die Kombination aus Nginx+PHP/PHP-FPM zu verwenden. Im Vergleich zu Spawn-FCGI verfügt PHP-FPM über eine bessere CPU- und Speicherkontrolle. Ersteres stürzt leicht ab und muss mit crontab überwacht werden, während PHP-FPM solche Probleme nicht hat. Der Hauptvorteil von FastCGI besteht darin, dynamische Sprachen vom HTTP-Server zu trennen, sodass Nginx und PHP/PHP-FPM oft auf verschiedenen Servern bereitgestellt werden, um den Druck auf den Front-End-Nginx-Server zu verteilen, sodass Nginx exklusiv arbeiten kann Behandelt statische Anfragen und leitet dynamische Anfragen weiter, und der PHP/PHP-FPM-Server analysiert ausschließlich dynamische PHP-Anfragen.
4. Nginx+PHP-FPM
PHP-FPM ist ein Manager zur Verwaltung von FastCGI. Es existiert als Plug-in für PHP, Sie müssen das alte installieren Version von PHP (php5.3.3 Vorher), Sie müssen PHP-FPM in Form eines Patches in PHP installieren, und PHP muss mit der PHP-FPM-Version konsistent sein, was ein Muss ist)
PHP-FPM ist tatsächlich Ein Patch des PHP-Quellcodes zur Integration des FastCGI-Prozessmanagements ist in das PHP-Paket integriert. Es muss in Ihren PHP-Quellcode gepatcht werden und kann nach dem Kompilieren und Installieren von PHP verwendet werden.
PHP5.3.3 hat PHP-FPM integriert und ist kein Drittanbieterpaket mehr. PHP-FPM bietet eine bessere PHP-Prozessverwaltungsmethode, kann Speicher und Prozesse effektiv steuern und die PHP-Konfiguration reibungslos neu laden. Es bietet mehr Vorteile als spawn-fcgi und ist daher offiziell in PHP enthalten. Sie können PHP-FPM aktivieren, indem Sie den Parameter –enable-fpm in ./configure übergeben.
Fastcgi ist bereits im Kern von php5.3.5 enthalten, es ist nicht erforderlich, bei der Konfiguration --enable-fastcgi hinzuzufügen. Ältere Versionen wie PHP5.2 müssen dieses Element hinzufügen.
Wenn wir Nginx und PHP-FPM installieren, sind die Konfigurationsinformationen:
PHP-FPMs Standardkonfiguration php-fpm.conf:
listen_address 127.0.0.1:9000 #Dies stellt den Fastcgi-Prozess von PHP dar, der die IP-Adresse überwacht und Port
Start_Serversmin_spare_servers
max_spare_servers
nginx-Konfiguration PHP: Editor nginx.conf Fügen Sie die folgenden Anweisungen hinzu:
Standort ~ .php $ { Root-HTML ; FastCGI_PASS 127.0.0.1:9000; der Port des FastCGI-Prozesses ist angegeben, FastCGI_INDEX.PHP; _ FASTCGI_PARAM SCRIPT_FILENAME/USR/LOCAL/ nginx/html$fastcgi_script_name; }
Nginx
verwendet den Standortbefehl, um alle Dateien mit PHP als Suffix an 127.0.0.1:9000 zur Verarbeitung zu übergeben, und die IP-Adresse und der Port hier sind die IP-Adressen und Ports, die der FastCGI-Prozess abhört.
1) FastCGI-Prozessmanager php-fpm initialisiert sich selbst, startet den Hauptprozess php-fpm und startet start_servers CGI-Unterprozesse. H p Der Hauptprozess PHP-FPM verwaltet hauptsächlich FastCGI-Unterprozesse und überwacht 9000 Ports. GFastcgi-Ersatz
Warten auf die Verbindung vom Webserver. 2) Wenn die Client-Anfrage den Webserver Nginx erreicht, verwendetNginx die Standortanweisung, um alle Dateien mit PHP als Suffix an 127.0.0.1:9000 zur Verarbeitung zu übergeben, d. h.
Nginxdurch Standort Anweisung, alle Dateien mit PHP als Suffix an 127.0.0.1:9000 zur Verarbeitung zu übergeben.
3) Der FastCGI-Prozessmanager PHP-FPM wählt einen untergeordneten Prozess-CGI-Interpreter aus und stellt eine Verbindung zu ihm her. Der Webserver sendet CGI-Umgebungsvariablen und Standardeingaben an den untergeordneten FastCGI-Prozess. 4) Nachdem der FastCGI-Unterprozess die Verarbeitung abgeschlossen hat, gibt er über dieselbe Verbindung Standardausgabe- und Fehlerinformationen an den Webserver zurück. Wenn der untergeordnete FastCGI-Prozess die Verbindung schließt, wird die Anfrage verarbeitet.
5). Der untergeordnete FastCGI-Prozess wartet dann auf die nächste Verbindung vom FastCGI-Prozessmanager (der im WebServer ausgeführt wird).5. Richtige Konfiguration von Nginx + PHP
Im Allgemeinen hat das Web einen einheitlichen Eingang: Senden Sie alle PHP-Anfragen an dieselbe Datei und implementieren Sie dann das Routing, indem Sie „REQUEST_URI“ in dieser Datei analysieren.
Die Nginx-Konfigurationsdatei ist von außen nach innen in viele Blöcke unterteilt: „http“, „Server“, „Standort“ usw. Die Standardvererbungsbeziehung ist von außen nach innen, das heißt innerer Block Der Wert des äußeren Blocks wird automatisch als Standardwert übernommen. Zum Beispiel:server {
listen 80;
server_name foo.com;
root /path;
location / {
index index.html index.htm index.php;
if (!-e $request_filename) {
rewrite . /index.php last;
}
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /path$fastcgi_script_name;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
}
}1) 不应该在location 模块定义index
一旦未来需要加入新的「location」,必然会出现重复定义的「index」指令,这是因为多个「location」是平级的关系,不存在继承,此时应该在「server」里定义「index」,借助继承关系,「index」指令在所有的「location」中都能生效。
2) 使用try_files
接下来看看「if」指令,说它是大家误解最深的Nginx指令毫不为过:
if (!-e $request_filename) {
rewrite . /index.php last;
}
很多人喜欢用「if」指令做一系列的检查,不过这实际上是「try_files」指令的职责:
try_files $uri $uri/ /index.php;
除此以外,初学者往往会认为「if」指令是内核级的指令,但是实际上它是rewrite模块的一部分,加上Nginx配置实际上是声明式的,而非过程式的,所以当其和非rewrite模块的指令混用时,结果可能会非你所愿。
3)fastcgi_params」配置文件:
include fastcgi_params;
Nginx有两份fastcgi配置文件,分别是「fastcgi_params」和「fastcgi.conf」,它们没有太大的差异,唯一的区别是后者比前者多了一行「SCRIPT_FILENAME」的定义:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
注意:$document_root 和 $fastcgi_script_name 之间没有 /。
原本Nginx只有「fastcgi_params」,后来发现很多人在定义「SCRIPT_FILENAME」时使用了硬编码的方式,于是为了规范用法便引入了「fastcgi.conf」。
不过这样的话就产生一个疑问:为什么一定要引入一个新的配置文件,而不是修改旧的配置文件?这是因为「fastcgi_param」指令是数组型的,和普通指令相同的是:内层替换外层;和普通指令不同的是:当在同级多次使用的时候,是新增而不是替换。换句话说,如果在同级定义两次「SCRIPT_FILENAME」,那么它们都会被发送到后端,这可能会导致一些潜在的问题,为了避免此类情况,便引入了一个新的配置文件。
此外,我们还需要考虑一个安全问题:在PHP开启「cgi.fix_pathinfo」的情况下,PHP可能会把错误的文件类型当作PHP文件来解析。如果Nginx和PHP安装在同一台服务器上的话,那么最简单的解决方法是用「try_files」指令做一次过滤:
try_files $uri =404;
依照前面的分析,给出一份改良后的版本,是不是比开始的版本清爽了很多:
server {
listen 80;
server_name foo.com;
root /path;
index index.html index.htm index.php;
location / {
try_files $uri $uri/ /index.php;
}
location ~ \.php$ {
try_files $uri =404;
include fastcgi.conf;
fastcgi_pass 127.0.0.1:9000;
}
}
六. Nginx优化
1. 编译安装过程优化
1).减小Nginx编译后的文件大小
在编译Nginx时,默认以debug模式进行,而在debug模式下会插入很多跟踪和ASSERT之类的信息,编译完成后,一个Nginx要有好几兆字节。而在编译前取消Nginx的debug模式,编译完成后Nginx只有几百千字节。因此可以在编译之前,修改相关源码,取消debug模式。具体方法如下:
在Nginx源码文件被解压后,找到源码目录下的auto/cc/gcc文件,在其中找到如下几行:
# debug
CFLAGS=”$CFLAGS -g”
注释掉或删掉这两行,即可取消debug模式。
2.为特定的CPU指定CPU类型编译优化
在编译Nginx时,默认的GCC编译参数是“-O”,要优化GCC编译,可以使用以下两个参数:
- --with-cc-opt='-O3'
-
--with-cpu-opt=CPU #Kompilieren für eine bestimmte CPU :
pentium, pentiumpro, pentium3, # pentium4, athlon, opteron, amd64, sparc32, sparc64, ppc64
Um den CPU-Typ zu ermitteln, können Sie den folgenden Befehl verwenden: #cat /proc/cpuinfo |. grep "model Name"
2. Verwenden Sie TCMalloc, um die Leistung von Nginx zu optimieren
TCMallocs vollständiger Name ist Thread-Caching Malloc, ein Mitglied des von Google entwickelten Open-Source-Tools google-perftools. Verglichen mit Malloc der Standard-Glibc-Bibliothek ist die TCMalloc-Bibliothek viel effizienter und schneller bei der Speicherzuweisung, was die Leistung des Servers in Situationen mit hoher Parallelität erheblich verbessert und dadurch die Belastung des Systems verringert. Im Folgenden finden Sie eine kurze Einführung zum Hinzufügen der TCMalloc-Bibliotheksunterstützung zu Nginx.
Um die TCMalloc-Bibliothek zu installieren, müssen Sie die beiden Softwarepakete libunwind (keine Installation für 32-Bit-Betriebssysteme erforderlich) und google-perftools installieren. Die libunwind-Bibliothek stellt grundlegende Funktionsaufrufketten und Funktionsaufrufregister für Programme bereit, die auf 64 basieren -Bit-CPUs und Betriebssysteme. Im Folgenden wird der spezifische Vorgang der Verwendung von TCMalloc zur Optimierung von Nginx beschrieben.
1) Installieren Sie die libunwind-Bibliothek
Sie können die entsprechende libunwind-Version von http://download.savannah.gnu.org/releases/libunwind herunterladen. gz. Der Installationsprozess ist wie folgt
#tar zxvf libunwind-0.99-alpha.tar.gz
# cd libunwind-0.99-alpha/
#CFLAGS=-fPIC ./configure
#make CFLAGS=-fPIC
#make CFLAGS= -fPIC install
2). Installieren Sie google-perftools
Sie können die entsprechende google-perftools-Version von http://google-perftools.googlecode.com herunterladen .gz. Der Installationsprozess ist wie folgt:
[root@localhost home]#tar zxvf google-perftools-1.8.tar.gz
[root@localhost home]#cd google-perftools-1.8/
[root@localhost google-perftools -1.8] # ./configure
[root@localhost google-perftools-1.8]#make && make install
[root@localhost google-perftools-1.8]#echo "/usr/
local/lib" /etc/ ld.so .conf.d/usr_local_lib.conf
[root@localhost google-perftools-1.8]# ldconfig
An diesem Punkt ist die Installation von google-perftools abgeschlossen.
3) Nginx neu kompilieren
Damit Nginx Google-Perftools unterstützt, müssen Sie während des Installationsprozesses die Option „–with-google_perftools_module“ hinzufügen, um Nginx neu zu kompilieren. Der Installationscode lautet wie folgt:
[root@localhostnginx-0.7.65]#./configure
>--with-google_perftools_module --with-http_stub_status_module --prefix=/opt/nginx
[root@localhost nginx- 0.7.65 ]#make
[root@localhost nginx-0.7.65]#make install
Die Nginx-Installation ist hier abgeschlossen.
4) Fügen Sie ein Thread-Verzeichnis für google-perftools hinzu
Erstellen Sie ein Thread-Verzeichnis und platzieren Sie die Datei unter /tmp/tcmalloc. Der Vorgang ist wie folgt:
[root@localhost home]#mkdir /tmp/tcmalloc
[root@localhost home]#chmod 0777 /tmp/tcmalloc
5). Ändern Sie die Nginx-Hauptkonfigurationsdatei
Modify Fügen Sie in der Datei nginx.conf den folgenden Code unter der PID-Zeile hinzu:
#pid logs/nginx.pid;
google_perftools_profiles /tmp/tcmalloc;
Starten Sie dann Nginx neu, um das Laden von google-perftools abzuschließen.
6). Überprüfen Sie den Ausführungsstatus
Um zu überprüfen, ob google-perftools normal geladen wurde, können Sie es mit dem folgenden Befehl überprüfen:
[root@ localhost home]# lsof -n |. grep tcmalloc
nginx 2395 Nobody 9w REG 8,8 0 1599440 /tmp/tcmalloc.2395
Nginx 2396 Nobody 11w REG 8,8 0 1599443 /tmp/tcmalloc.2396
Nginx 2397 Nobody 13w REG 8,8 0 1599441 /tmp/tcmalloc.2397
Nginx 2398 Nobody 15w REG 8,8 0 1599442 /tmp/tcmalloc.2398
Da der Wert von worker_processes in der Nginx-Konfigurationsdatei auf 4 gesetzt ist, ist es Wenn 4 Nginx-Threads aktiviert sind, verfügt jeder Thread über eine Reihe von Datensätzen. Der numerische Wert nach jeder Thread-Datei ist der PID-Wert des gestarteten Nginx.
An diesem Punkt ist die Optimierung von Nginx mithilfe von TCMalloc abgeschlossen.
3. Nginx-Kernel-Parameteroptimierung
Die Optimierung von Kernel-Parametern ist hauptsächlich die Optimierung von Systemkernel-Parametern für Nginx-Anwendungen in Linux-Systemen.
Ein Optimierungsbeispiel finden Sie unten als Referenz.
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_ syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_synack_retries = 1
. net.ipv4.tcp_syn_ret ries = 1
net.ipv4.tcp_fin_timeout = 1
net .ipv4.tcp_keepalive_time = 30
Fügen Sie die oben genannten Kernel-Parameterwerte zur Datei /etc/sysctl.conf hinzu und führen Sie dann den folgenden Befehl aus, um sie wirksam zu machen:
[root@ localhost home]#/sbin/sysctl -p
Im Folgenden wird die Bedeutung der Optionen im Beispiel vorgestellt:
TCP-Parametereinstellungen:
net.ipv4.tcp_max_tw_buckets: Option wird verwendet Legen Sie die Anzahl der Wartezeiten fest. Der Standardwert ist 180.000 und wird hier auf 6.000 eingestellt. Mit der Option
net.ipv4.ip_local_port_range: wird der Portbereich festgelegt, den das System öffnen darf. In Situationen mit hoher Parallelität andernfalls reicht die Portnummer nicht aus. Wenn NGINX als Proxy fungiert, verwendet jede Verbindung zum Upstream-Server einen kurzlebigen oder kurzlebigen Port.
net.ipv4.tcp_tw_recycle: Die Option wird verwendet, um eine schnelle Wiederverwertung der Wartezeit für neue TCP-Verbindungen zu ermöglichen.
net.ipv4.tcp_syncookies: Die Option wird zum Einrichten von SYN-Cookies verwendet. Wenn die SYN-Warteschlange überläuft, werden Cookies für die Verarbeitung aktiviert.
net.ipv4.tcp_max_orphans: Option wird verwendet, um die maximale Anzahl von TCP-Sockets im System festzulegen, die keinem Benutzerdatei-Handle zugeordnet sind. Wenn diese Zahl überschritten wird, werden verwaiste Verbindungen sofort zurückgesetzt und eine Warnmeldung ausgegeben. Diese Einschränkung dient lediglich der Verhinderung einfacher DoS-Angriffe. Sie können sich nicht zu sehr auf diese Grenze verlassen oder diesen Wert sogar künstlich verringern. In den meisten Fällen sollten Sie diesen Wert erhöhen.
net.ipv4.tcp_max_syn_backlog: Option wird verwendet, um den Maximalwert von Verbindungsanfragen aufzuzeichnen, die noch keine Client-Bestätigungsinformationen erhalten haben. Der Standardwert dieses Parameters ist 1024 für Systeme mit 128 MB Speicher und 128 für Systeme mit kleinem Speicher.
Der Wert des Parameters net.ipv4.tcp_synack_retries bestimmt die Anzahl der gesendeten SYN+ACK-Pakete, bevor der Kernel die Verbindung aufgibt. Die Option net.ipv4.tcp_syn_retries gibt die Anzahl der gesendeten SYN-Pakete an, bevor der Kernel den Verbindungsaufbau aufgibt. Die Option net.ipv4.tcp_fin_timeout bestimmt, wie lange der Socket im FIN-WAIT-2-Zustand bleibt. Der Standardwert beträgt 60 Sekunden. Es ist sehr wichtig, diesen Wert richtig einzustellen. Manchmal kann sogar ein leicht ausgelasteter Webserver eine große Anzahl toter Sockets aufweisen und das Risiko eines Speicherüberlaufs eingehen. Die Option
net.ipv4.tcp_syn_retries gibt die Anzahl der gesendeten SYN-Pakete an, bevor der Kernel den Verbindungsaufbau aufgibt.
Wenn der Absender verlangt, dass der Socket geschlossen wird, bestimmt die Option net.ipv4.tcp_fin_timeout, wie lange der Socket im FIN-WAIT-2-Zustand bleibt. Der Empfänger kann Fehler machen und die Verbindung niemals schließen oder sogar unerwartet abstürzen.
Der Standardwert von net.ipv4.tcp_fin_timeout beträgt 60 Sekunden. Es ist zu beachten, dass auch bei einem Webserver mit geringer Auslastung aufgrund einer großen Anzahl toter Sockets die Gefahr eines Speicherüberlaufs besteht. FIN-WAIT-2 ist weniger gefährlich als FIN-WAIT-1, da es nur bis zu 1,5 KB Speicher verbrauchen kann, aber seine Lebensdauer ist länger. Die Option
net.ipv4.tcp_keepalive_time gibt an, wie oft TCP Keepalive-Nachrichten sendet, wenn Keepalive aktiviert ist. Der Standardwert ist 2 (Einheiten sind Stunden).
Pufferwarteschlange:
net.core.somaxconn:Der Standardwert der Option ist 128. Dieser Parameter wird verwendet, um die Anzahl der vom System initiierten TCP-Verbindungen anzupassen Gleichzeitig kann der Standardwert bei vielen gleichzeitigen Anfragen zu einem Link-Timeout oder einer erneuten Übertragung führen, sodass dieser Wert basierend auf der Anzahl gleichzeitiger Anfragen angepasst werden muss.
Bestimmt durch die von NGINX akzeptierte Nummer. Der Standardwert ist normalerweise niedrig, aber akzeptabel, da NGINX Verbindungen sehr schnell empfängt. Sie sollten diesen Wert jedoch erhöhen, wenn Ihre Website viel Verkehr hat. Fehlermeldungen im Kernel-Protokoll erinnern Sie daran, dass dieser Wert zu klein ist. Erhöhen Sie den Wert, bis die Fehlermeldung verschwindet.
Hinweis: Wenn Sie diesen Wert auf mehr als 512 festlegen, müssen Sie auch den Backlog-Parameter des NGINX-Listen-Befehls entsprechend ändern. Die Option
net.core.netdev_max_backlog: stellt die maximale Anzahl von Paketen dar, die an die Warteschlange gesendet werden dürfen, wenn jede Netzwerkschnittstelle Pakete schneller empfängt, als der Kernel sie verarbeiten kann.
4. Optimierung von PHP-FPM
Wenn Ihre Hochlast-Website PHP-FPM zur Verwaltung von FastCGI verwendet, können diese Tipps für Sie nützlich sein:
1) Erhöhen Sie die Anzahl der FastCGI-Prozesse
Setzen Sie PHP FastCGI. Passen Sie die Anzahl der untergeordneten Prozesse auf 100 oder mehr an. Auf einem Server mit 4G-Speicher können 200 verwendet werden, um den besten Wert durch Stresstests zu erhalten.
2) Erhöhen Sie das Limit für PHP-FPM-Deskriptoren für offene Dateien.
Das Tag rlimit_files wird verwendet, um das Limit für PHP-FPM für offene Dateideskriptoren festzulegen. Der Wert dieser Bezeichnung muss mit der Anzahl der geöffneten Dateien im Linux-Kernel verknüpft sein. Um diesen Wert beispielsweise auf 65.535 festzulegen, müssen Sie „ulimit -HSn 65536“ in der Linux-Befehlszeile ausführen. H Dann 加 Fügen Sie PHP-FPM hinzu, um das Dateideskriptorlimit zu öffnen:
# vi /path/to/php-fpm.conf Finden Sie "& lt; value =" rlimit_files "& gt; 1024 & lt;/value & gt;" " Ändern Sie 1024 in 4096 oder höher
. Starten Sie PHP-FPM neu.
ulimit -n zur Anpassung an
65536 oder noch größer. Wie Sie diesen Parameter anpassen, können Sie einigen Artikeln im Internet entnehmen. Führen Sie ulimit -n 65536 in der Befehlszeile aus, um es zu ändern. Wenn es nicht geändert werden kann, müssen Sie /etc/security/limits.conf festlegen und * Hard Nofile65536
* Soft Nofile 65536
hinzufügen. 3) Erhöhen Sie max_re entsprechend quests
Das Tag max_requests gibt die maximale Anzahl von Anfragen an, die jedes Kind bearbeiten kann, bevor es geschlossen wird. Die Standardeinstellung ist 500.
4fc7992c3724972844061c7a73af9076 500 4b175f9a50d57c75316becd702e959dc
5.nginx.conf Parameteroptimierung
nginx Die Anzahl der zu startenden Prozesse entspricht im Allgemeinen der Gesamtzahl der Tatsächlich sind es im Allgemeinen 4 oder 8 Kerne. Der von jedem Nginx-Prozess verbrauchte Speicher beträgt 10 Megabyte.
worker_cpu_affinity
Gilt nur für Linux. Verwenden Sie diese Option, um den Arbeitsprozess und die CPU zu binden (nicht verfügbar für Maschinen mit 2.4-Kernel)
Bei 8 CPUs ist die Zuordnung wie folgt:
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000
00100000 01000000 10000000
Nginx kann aus folgenden Gründen mehrere Worker-Prozesse verwenden:
um SMP zu verwenden
um die Latenz zu verringern, wenn Worker die Festplatten-E/A blockieren.
um die Anzahl der Verbindungen pro Prozess zu begrenzen, wenn select()/poll() verwendet wird. Mit den worker_processes und worker_connections aus den Ereignisabschnitten können Sie den maxclients-Wert berechnen: k max_clients = worker_processes * worker_connections
worker_rlimit_nofile 102400;
Die Konfiguration der maximalen Anzahl offener Dateideskriptoren für jeden Nginx-Prozess muss mit der Anzahl geöffneter Dateien für einen einzelnen Prozess im System übereinstimmen 2.6-Kernel ist 65535, daher sollte worker_rlimit_nofile mit 65535 gefüllt werden. Die Anzahl der Anforderungen an den Prozess ist nicht so ausgeglichen. Wenn der Grenzwert überschritten wird, wird ein 502-Fehler zurückgegeben. Was ich hier schreibe, ist etwas größer
Epoll verwenden
Nginx verwendet das neueste Netzwerk-E/A-Modell von Epoll (Linux 2.6-Kernel) und Kqueue (FreeBSD), während Apache das traditionelle Auswahlmodell verwendet. Um das Lesen und Schreiben einer großen Anzahl von Verbindungen zu bewältigen, ist das von Apache verwendete ausgewählte Netzwerk-E/A-Modell sehr ineffizient. Bei Servern mit hoher Parallelität ist das Abfragen von E/A der zeitaufwändigste Vorgang. Sowohl Squid als auch Memcached verwenden das Epoll-Netzwerk-E/A-Modell.
worker_processes
Anzahl der NGINX-Worker-Prozesse (Standardwert ist 1). In den meisten Fällen ist es am besten, einen Arbeitsprozess pro CPU-Kern auszuführen, und es wird empfohlen, diese Anweisung auf „Automatisch“ zu setzen. Manchmal möchten Sie diesen Wert möglicherweise erhöhen, beispielsweise wenn der Arbeitsprozess viele Festplatten-E/A-Vorgänge ausführen muss.
worker_connections 65535;
Die maximal zulässige Anzahl gleichzeitiger Verbindungen pro Worker-Prozess (Maxclient = work_processes * worker_connections)
keepalive_timeout 75
Keepalive-Timeout
Hier gibt es einen offiziellen Satz, den es zu beachten gilt. : Die Parameter können unterscheiden sich voneinander. Line Keep-Alive:
timeout=time versteht, dass Mozilla und Konqueror die Keep-Alive-Verbindung ungefähr nach 60 Sekunden schließen Um den Header-Wert zu lesen, werden große_client_header_buffers zum Lesen verwendet. Wenn der HTTP-Header/Cookie zu klein eingestellt ist, wird eine 400-Fehler-Nginx-400-Fehlermeldung gemeldet. Es wird ein HTTP-Fehler 414 (URI Too Long) gemeldet. Die längste von Nginx akzeptierte HTTP-Header-Größe muss größer als einer der Puffer sein, andernfalls wird ein HTTP-Fehler 400 (Bad Request) gemeldet.
open_file_cache max 102400
Verwenden Sie die Felder: http, Server, Standort. Diese Anweisung gibt an, ob der Cache aktiviert ist. Wenn diese Option aktiviert ist, werden die folgenden Informationen über die Datei aufgezeichnet: ·Deskriptor der geöffneten Datei, Größeninformationen und Änderungszeit. ·Vorhandenes Verzeichnis-Meldung. · Fehlermeldung während der Suche nach der Datei – ohne diese Datei kann sie nicht korrekt gelesen werden, siehe Optionen der open_file_cache_errors-Direktive:
· max – gibt die maximale Anzahl von Caches an, wenn der Cache überläuft, die am längsten verwendete Datei (LRU) Wird entfernt Beispiel: open_file_cache max=1000 inactive=20s; open_file_cache_errors on;
open_file_cache_errors on |. off Standardwert: open_file_cache_errors s aus Verwenden Sie die folgenden Felder: http, server, location This Die Direktive gibt an, ob Cache-Fehler bei der Suche nach einer Datei protokolliert werden sollen.
open_file_cache_min_uses
Syntax: open_file_cache_min_uses Zahl Standardwert: open_file_cache_min_uses 1 Verwendungsfelder: http, Server, Standort Diese Direktive gibt einen bestimmten Zeitbereich in den ungültigen Parametern der an open_file_cache-Direktive. Wenn ein größerer Wert verwendet wird, ist der Dateideskriptor immer im Cache geöffnet.
open_file_cache_valid. Standardwert: open_file_cache_valid. location Diese Anweisung gibt an, wann die gültigen Informationen von zwischengespeicherten Elementen überprüft werden müssen.
gzip_length 1k; gzip_comp_level 2;
gzip_types text/ plain application/x- javascript text/ css
application/xml; gzip_vary on;
Statische Dateien zwischenspeichern:
location ~* ^.+.(swf|gif|png|jpg|js|css)$ {
root /usr/local/ku6 /ktv/show.ku6.com/; läuft 1 Minute ab;
}
Antwortpuffer:
Zum Beispiel kann unser Nginx+Tomcat-Proxy-Zugriffs-JS nicht vollständig geladen werden . Diese Parameter beeinflussen:
proxy_buffer_size 128k;
proxy_buffers 32 128k;
proxy_busy_buffers_size 128k;
Nginx erhält die entsprechende Datei nach der Weiterleitung des entsprechenden Dienstes oder basierend auf dem von uns konfigurierten UpStream und Speicherort. Zuerst wird die Datei in den Speicher oder das temporäre Dateiverzeichnis von nginx geparst. , und dann antwortet Nginx. Wenn dann „proxy_buffers“, „proxy_buffer_size“ und „proxy_busy_buffers_size“ zu klein sind, wird der Inhalt gemäß der Nginx-Konfiguration in einer temporären Datei generiert, aber die Größe der temporären Datei hat auch einen Standardwert. Wenn diese vier Werte zu klein sind, wird daher nur ein Teil einiger Dateien geladen. Daher müssen „proxy_buffers“, „proxy_buffer_size“, „proxy_busy_buffers_size“ und „proxy_temp_file_write_size“ entsprechend unseren Serverbedingungen entsprechend angepasst werden. Die Details der spezifischen Parameter lauten wie folgt:
proxy_buffers 32 128k; 32 Pufferbereiche sind jeweils 128k groß;
proxy_buffer_size 128k; die Größe jedes Pufferbereichs beträgt 128k; inkonsistent, es werden keine spezifischen Informationen gefunden. Welche ist wirksam? Es wird empfohlen, die oben genannten Einstellungen einzuhalten.
proxy_busy_buffers_size 128k; Legen Sie die Größe des verwendeten Pufferbereichs fest und steuern Sie die maximale
proxy_temp_file_write_size-Cache-Dateigröße
6. Optimieren Sie Zugriffsprotokolle
Zeichnen Sie jede Anfrage auf es CPU und I/O Eine Möglichkeit, diese Auswirkungen zu reduzieren, besteht darin, Zugriffsprotokolle zu puffern. Anstatt für jeden Protokolldatensatz einen separaten Schreibvorgang durchzuführen, puffert NGINX eine Reihe von Protokolldatensätzen und schreibt sie in einem einzigen Vorgang zusammen in eine Datei.
Um den Cache von Zugriffsprotokollen zu aktivieren, ist der Parameter buffer=size in der Anweisung access_log erforderlich. Wenn der Puffer den Größenwert erreicht, schreibt NGINX den Inhalt des Puffers in das Protokoll. Damit NGINX nach einem bestimmten Zeitraum in den Cache schreibt, schließen Sie den Parameter „flush=time“ ein. Wenn beide Parameter festgelegt sind, schreibt NGINX den Eintrag in die Protokolldatei, wenn der nächste Protokolleintrag den Pufferwert überschreitet oder der Protokolleintrag im Puffer den eingestellten Zeitwert überschreitet. Dies wird auch protokolliert, wenn der Arbeitsprozess seine Protokolldatei erneut öffnet oder beendet wird. Um die Zugriffsprotokollierung vollständig zu deaktivieren, setzen Sie die access_log-Direktive auf den Parameter off.
7. Strombegrenzung
Sie können mehrere Grenzwerte festlegen, um zu verhindern, dass Benutzer zu viele Ressourcen verbrauchen, und um eine Beeinträchtigung der Systemleistung, Benutzererfahrung und Sicherheit zu vermeiden. Hier sind die relevanten Anweisungen:
limit_conn und limit_conn_zone: NGINX akzeptiert eine Begrenzung der Anzahl der Kundenverbindungen, beispielsweise Verbindungen von einer einzelnen IP-Adresse. Durch das Festlegen dieser Anweisungen wird verhindert, dass ein einzelner Benutzer zu viele Verbindungen öffnet und mehr Ressourcen verbraucht, als er verwenden kann.
limit_rate: Die Begrenzung der Antwortgeschwindigkeit der Übertragung zum Client (jeder Client, der mehrere Verbindungen öffnet, verbraucht mehr Bandbreite). Das Festlegen dieses Grenzwerts verhindert eine Überlastung des Systems und gewährleistet eine einheitlichere Servicequalität für alle Clients.
limit_req und limit_req_zone: Das Ratenlimit für NGINX-Verarbeitungsanforderungen, das dieselbe Funktion wie limit_rate hat. Sie können die Sicherheit, insbesondere für Anmeldeseiten, verbessern, indem Sie einen angemessenen Wert für die Benutzerlimit-Anfragerate festlegen, um zu verhindern, dass zu langsame Programme Ihre Anwendungsanfragen überschreiben (z. B. DDoS-Angriffe).
max_conns: Serverbefehlsparameter im Upstream-Konfigurationsblock. Die maximale Anzahl von Parallelitäten, die ein einzelner Server in einer Upstream-Servergruppe akzeptieren kann. Verwenden Sie dieses Limit, um eine Überlastung des Upstream-Servers zu verhindern. Wenn Sie den Wert 0 (Standardeinstellung) festlegen, gibt es keine Begrenzung. Warteschlange (NGINX Plus):
Erstellen Sie eine Warteschlange, um die Anzahl der Anforderungen auf dem Upstream-Server zu speichern, die ihr maximales max_cons-Limit überschreiten. Diese Direktive legt die maximale Anzahl von Anfragen in der Warteschlange fest und legt optional die maximale Wartezeit fest, bevor ein Fehler zurückgegeben wird (Standard ist 60 Sekunden). Wenn diese Anweisung weggelassen wird, wird die Anforderung nicht in die Warteschlange gestellt.
VII. Fehlerbehebung
1. Nginx 502 Bad Gateway:
Wenn ein Server, der als Gateway oder Proxy arbeitet, versucht, eine Anfrage auszuführen, erhält er eine ungültige Antwort vom Upstream-Server. Häufige Gründe:
1. Wenn der Backend-Dienst aufhängt, erscheint ein direkter 502 (Nginx-Fehlerprotokoll: connect() fehlgeschlagen (111: Verbindung abgelehnt)) 2. Der Backend-Dienst wird neu gestartet
Beispiel: Ersetzen Sie den Backend-Dienst Schalten Sie es aus und senden Sie dann eine Anfrage an die Backend-Schnittstelle von Nginx. Im Nginx-Protokoll wird ein 502-Fehler angezeigt.
Wenn 502 in Nginx + PHP auftritt, Fehleranalyse:
Die Anzahl der PHP-CGI-Prozesse reicht nicht aus, die PHP-Ausführungszeit ist lang (MySQL ist langsam) oder der PHP-CGI-Prozess stirbt ab, es kommt zu einem 502-Fehler auftreten
Im Allgemeinen hängt Nginx 502 Bad Gateway mit den Einstellungen von php-fpm.conf zusammen, während Nginx 504 Gateway Timeout mit den Einstellungen von nginx.conf zusammenhängt
1) Überprüfen Sie, ob die aktuelle Anzahl der PHP FastCGI-Prozesse vorhanden ist ausreichend:
netstat -anpo |. grep "php-cgi" |. wc -l
Wenn die tatsächliche Anzahl der verwendeten „FastCGI-Prozesse“ nahe an der standardmäßigen „Anzahl der FastCGI-Prozesse“ liegt, bedeutet dies, dass die „Anzahl der „FastCGI-Prozesse“ reichen nicht aus und müssen erhöht werden. groß.
2). Die Ausführungszeit einiger PHP-Programme überschreitet die Wartezeit von Nginx. Sie können die Timeout-Zeit von FastCGI in der Konfigurationsdatei nginx.conf entsprechend erhöhen, zum Beispiel:
http {
... fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
......
}
2, 504 Gateway-Timeout:
nginx Wenn ein Server als Gateway fungiert oder der Proxy versucht auszuführen eine Anfrage, Fehler beim Empfang einer rechtzeitigen Antwort vom Upstream-Server (dem durch den URI identifizierten Server, z. B. HTTP, FTP, LDAP). Häufige Gründe:
Diese Schnittstelle ist zu zeitaufwändig. Der Back-End-Dienst empfängt die Anfrage und beginnt mit der Ausführung, kann jedoch innerhalb der festgelegten Zeit keine Daten an Nginx zurückgeben. Die Gesamtlast des Back-End-Servers ist zu hoch . Nach Erhalt der Anfrage konnte die Schnittstelle für die Anfrage nicht eingerichtet werden, was dazu führte, dass Daten nicht zum festgelegten Zeitpunkt an Nginx zurückgegeben werden konnten.
2, 413 Anforderungsentität zu groß
Lösung: Erhöhen Sie client_max_body_size. Der Client erhält den Fehler „Request Entity Too Large“ (413). Denken Sie daran, dass der Browser nicht weiß, wie er diesen Fehler anzeigen soll. post_max_size und upload_max_filesize
erscheint:
Upstream hat beim Lesen des Antwortheaders vom Upstream einen zu großen Header gesendet. Fehler
1) Wenn es sich um einen Nginx-Reverse-Proxy handelt.
Der Proxy wird von Nginx bei der Weiterleitung als Client verwendet Wenn es zu groß ist und den Standardwert von 1 KB überschreitet, wird der oben genannte Upstream zu einem zu großen Header (um es klar auszudrücken). Dies wird dadurch verursacht, dass Nginx externe Anforderungen an den Back-End-Server sendet und der vom Back-End-Server zurückgegebene Header ist zu groß für Nginx.
server_name *. large_client_header_buffers 4 16k; Proxy_buffers 32 32k; Proxy_busy_buffers_size 7.0 .0.1:9000". Sie sollten mehr hinzufügen:
fastcgi_buffer_size 128k; fastcgi_buffers 4 128k;
server {
server_name ddd.com;
index index.html index.htm index.php;
client_header_buffer_size 128k; Standort / {
… Wird es häufig als Reverse-Proxy verwendet und kann auch den Betrieb von PHP sehr gut unterstützen. 80sec hat festgestellt, dass ein schwerwiegendes Sicherheitsproblem vorliegt. Standardmäßig kann der Server jede Art von Datei in PHP falsch analysieren. Dies führt zu schwerwiegenden Sicherheitsproblemen und ermöglicht es böswilligen Angreifern, Nginx zu kompromittieren.
Schwachstellenanalyse: Nginx unterstützt standardmäßig die Ausführung von PHP im CGI-Modus. In der Konfigurationsdatei können Sie beispielsweise location ~ .php$ {<!-- -->
root html; fastcgi_pass 127.0“ verwenden. 0,1:9000 ;
fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params; unterstützt das Parsen von PHP. Bei der Auswahl des Speicherorts wird die URI-Umgebungsvariable zur Auswahl der Anforderung verwendet . Die an das Backend-Fastcgi übergebene Schlüsselvariable SCRIPT_FILENAME wird durch den von nginx generierten $fastcgi_script_name bestimmt. Hier entsteht das Problem. Um die Extraktion von PATH_INFO besser zu unterstützen, gibt es in den PHP-Konfigurationsoptionen die Option cgi.fix_pathinfo. Ihr Zweck besteht darin, den tatsächlichen Skriptnamen aus SCRIPT_FILENAME zu extrahieren. Angenommen, es gibt http://www.80sec.com/80sec.jpg, greifen wir wie folgt auf
http://www.80sec.com/80sec.jpg/80sec.php
zu und erhalten eine URI/80sec.jpg/80sec.php
Nach dem Standortbefehl wird die Anfrage zur Verarbeitung an das Back-End-Fastcgi übergeben, und Nginx setzt die Umgebungsvariable SCRIPT_FILENAME dafür mit der Inhalt von location ~ .php$ {<!-- -->
root html;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params;
}
的方式支持对php的解析,location对请求进行选择的时候会使用URI环境变量进行选择,其中传递到后端Fastcgi的关键变量SCRIPT_FILENAME由nginx生成的$fastcgi_script_name决定,而通过分析可以看到$fastcgi_script_name是直接由URI环境变量控制的,这里就是产生问题的点。而为了较好的支持PATH_INFO的提取,在PHP的配置选项里存在cgi.fix_pathinfo选项,其目的是为了从SCRIPT_FILENAME里取出真正的脚本名。
那么假设存在一个http://www.80sec.com/80sec.jpg,我们以如下的方式去访问
http://www.80sec.com/80sec.jpg/80sec.php
将会得到一个URI
/80sec.jpg/80sec.php
经过location指令,该请求将会交给后端的fastcgi处理,nginx为其设置环境变量SCRIPT_FILENAME,内容为
/scripts/80sec.jpg/80sec.php
而在其他的webserver如lighttpd当中,我们发现其中的SCRIPT_FILENAME被正确的设置为
/scripts/80sec.jpg
所以不存在此问题。
后端的fastcgi在接受到该选项时,会根据fix_pathinfo配置决定是否对SCRIPT_FILENAME进行额外的处理,一般情况下如果不对fix_pathinfo进行设置将影响使用PATH_INFO进行路由选择的应用,所以该选项一般配置开启。Php通过该选项之后将查找其中真正的脚本文件名字,查找的方式也是查看文件是否存在,这个时候将分离出SCRIPT_FILENAME和PATH_INFO分别为
/scripts/80sec.jpg和80sec.php
最后,以/scripts/80sec.jpg作为此次请求需要执行的脚本,攻击者就可以实现让nginx以php来解析任何类型的文件了。
POC: 访问一个nginx来支持php的站点,在一个任何资源的文件如robots.txt后面加上/80sec.php,这个时候你可以看到如下的区别:
访问http://www.80sec.com/robots.txt
HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:05:30 GMT<br> Content-Type: text/plain<br> Content-Length: 18<br> Last-Modified: Thu, 20 May 2010 06:26:34 GMT<br> Connection: keep-alive<br> Keep-Alive: timeout=20<br> Accept-Ranges: bytes
访问访问http://www.80sec.com/robots.txt/80sec.php
HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:06:49 GMT<br> Content-Type: text/html<br> Transfer-Encoding: chunked<br> Connection: keep-alive<br> Keep-Alive: timeout=20<br> X-Powered-By: PHP/5.2.6
其中的Content-Type的变化说明了后端负责解析的变化,该站点就可能存在漏洞。
漏洞厂商:http://www.nginx.org
解决方案:
我们已经尝试联系官方,但是此前你可以通过以下的方式来减少损失
关闭cgi.fix_pathinfo为0
或者
if ( $fastcgi_script_name ~ ..*/.*php ) {<!-- --><br> return 403;<br> }/scripts /80sec.jpg/80sec.php
In anderen Webservern wie lighttpd haben wir festgestellt, dass SCRIPT_FILENAME korrekt auf /scripts/80sec.jpggesetzt ist >
also existiert dieses Problem nicht. Wenn das Backend-Fastcgi diese Option empfängt, entscheidet es basierend auf der fix_pathinfo-Konfiguration, ob eine zusätzliche Verarbeitung für SCRIPT_FILENAME durchgeführt werden soll. Wenn fix_pathinfo nicht festgelegt ist, wirkt sich dies im Allgemeinen auf Anwendungen aus, die PATH_INFO für das Routing verwenden. Daher ist diese Option im Allgemeinen so konfiguriert eingeschaltet sein. Nach Übergabe dieser Option sucht PHP auch nach dem tatsächlichen Namen der Skriptdatei. Zu diesem Zeitpunkt werden SCRIPT_FILENAME und PATH_INFO in
/scripts/80sec.jpg und 80sec unterteilt .php🎜 Schließlich kann der Angreifer mit /scripts/80sec.jpg als Skript, das für diese Anfrage ausgeführt werden muss, nginx jede Art von Datei mit PHP analysieren lassen. 🎜🎜POC: Besuchen Sie eine Website, auf der nginx PHP unterstützt, nach einer beliebigen Ressourcendatei wie robots.txt. Zu diesem Zeitpunkt können Sie den folgenden Unterschied erkennen: 🎜🎜Besuchen Sie http://www /robots.txt🎜🎜HTTP/1.1 200 OK🎜 Server: nginx/0.6.32🎜 Datum: Do, 20. Mai 2010 10:05:30 GMT🎜 Inhaltstyp: text/plain🎜 Inhaltslänge: 18 🎜 Letzte Änderung: Do, 20. Mai 2010 06:26:34 GMT🎜 Verbindung: Keep-Alive🎜 Keep-Alive: Timeout=20🎜 Accept-Ranges: Bytes🎜🎜 Besuchen Sie http:// /www. 80sec.com/robots.txt/80sec.php🎜🎜HTTP/1.1 200 OK🎜 Server: nginx/0.6.32🎜 Datum: Do, 20. Mai 2010 10:06:49 GMT🎜 Inhaltstyp: Text/ html🎜 Transfer-Encoding: chunked🎜 Connection: keep-alive🎜 Keep-Alive: timeout=20🎜 Beim Parsen von Änderungen ist die Site möglicherweise anfällig. 🎜🎜Vulnerability-Anbieter: http://www.nginx.org🎜🎜Lösung: 🎜🎜Wir haben versucht, den Beamten zu kontaktieren, aber vorher können Sie den Verlust durch die folgenden Methoden reduzieren🎜🎜<code>Cgi.fix_pathinfo schließen 0🎜🎜 oder 🎜🎜<code>if ( $fastcgi_script_name ~ ..*/.*php ) {<!-- -->🎜 return 403;🎜 }🎜🎜PS: Danke an laruence Daniel Hilfe während des Analyseprozesses🎜🎜🎜
rewrite . /index.php last;
}
注意:$document_root 和 $fastcgi_script_name 之间没有 /。
try_files $uri =404;
pentium, pentiumpro, pentium3, # pentium4, athlon, opteron, amd64, sparc32, sparc64, ppc64
# cd libunwind-0.99-alpha/
#CFLAGS=-fPIC ./configure
#make CFLAGS=-fPIC
#make CFLAGS= -fPIC install
[root@localhost home]#cd google-perftools-1.8/
[root@localhost google-perftools -1.8] # ./configure
[root@localhost google-perftools-1.8]#make && make install
[root@localhost google-perftools-1.8]#echo "/usr/
local/lib" /etc/ ld.so .conf.d/usr_local_lib.conf
[root@localhost google-perftools-1.8]# ldconfig
>--with-google_perftools_module --with-http_stub_status_module --prefix=/opt/nginx
[root@localhost nginx- 0.7.65 ]#make
[root@localhost nginx-0.7.65]#make install
[root@localhost home]#chmod 0777 /tmp/tcmalloc
google_perftools_profiles /tmp/tcmalloc;
nginx 2395 Nobody 9w REG 8,8 0 1599440 /tmp/tcmalloc.2395
Nginx 2396 Nobody 11w REG 8,8 0 1599443 /tmp/tcmalloc.2396
Nginx 2397 Nobody 13w REG 8,8 0 1599441 /tmp/tcmalloc.2397
Nginx 2398 Nobody 15w REG 8,8 0 1599442 /tmp/tcmalloc.2398
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_ syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_synack_retries = 1
. net.ipv4.tcp_syn_ret ries = 1
net.ipv4.tcp_fin_timeout = 1
net .ipv4.tcp_keepalive_time = 30
Hinweis: Wenn Sie diesen Wert auf mehr als 512 festlegen, müssen Sie auch den Backlog-Parameter des NGINX-Listen-Befehls entsprechend ändern. Die Option
. Starten Sie PHP-FPM neu.
ulimit -n zur Anpassung an
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000
um die Latenz zu verringern, wenn Worker die Festplatten-E/A blockieren.
um die Anzahl der Verbindungen pro Prozess zu begrenzen, wenn select()/poll() verwendet wird. Mit den worker_processes und worker_connections aus den Ereignisabschnitten können Sie den maxclients-Wert berechnen: k max_clients = worker_processes * worker_connections
Keepalive-Timeout
open_file_cache_min_uses
Syntax: open_file_cache_min_uses Zahl Standardwert: open_file_cache_min_uses 1 Verwendungsfelder: http, Server, Standort Diese Direktive gibt einen bestimmten Zeitbereich in den ungültigen Parametern der an open_file_cache-Direktive. Wenn ein größerer Wert verwendet wird, ist der Dateideskriptor immer im Cache geöffnet.
open_file_cache_valid. Standardwert: open_file_cache_valid. location Diese Anweisung gibt an, wann die gültigen Informationen von zwischengespeicherten Elementen überprüft werden müssen.
gzip_types text/ plain application/x- javascript text/ css
location ~* ^.+.(swf|gif|png|jpg|js|css)$ {
}
proxy_buffers 32 128k;
proxy_busy_buffers_size 128k;
Um den Cache von Zugriffsprotokollen zu aktivieren, ist der Parameter buffer=size in der Anweisung access_log erforderlich. Wenn der Puffer den Größenwert erreicht, schreibt NGINX den Inhalt des Puffers in das Protokoll. Damit NGINX nach einem bestimmten Zeitraum in den Cache schreibt, schließen Sie den Parameter „flush=time“ ein. Wenn beide Parameter festgelegt sind, schreibt NGINX den Eintrag in die Protokolldatei, wenn der nächste Protokolleintrag den Pufferwert überschreitet oder der Protokolleintrag im Puffer den eingestellten Zeitwert überschreitet. Dies wird auch protokolliert, wenn der Arbeitsprozess seine Protokolldatei erneut öffnet oder beendet wird. Um die Zugriffsprotokollierung vollständig zu deaktivieren, setzen Sie die access_log-Direktive auf den Parameter off.
limit_conn und limit_conn_zone: NGINX akzeptiert eine Begrenzung der Anzahl der Kundenverbindungen, beispielsweise Verbindungen von einer einzelnen IP-Adresse. Durch das Festlegen dieser Anweisungen wird verhindert, dass ein einzelner Benutzer zu viele Verbindungen öffnet und mehr Ressourcen verbraucht, als er verwenden kann.
limit_rate: Die Begrenzung der Antwortgeschwindigkeit der Übertragung zum Client (jeder Client, der mehrere Verbindungen öffnet, verbraucht mehr Bandbreite). Das Festlegen dieses Grenzwerts verhindert eine Überlastung des Systems und gewährleistet eine einheitlichere Servicequalität für alle Clients.
limit_req und limit_req_zone: Das Ratenlimit für NGINX-Verarbeitungsanforderungen, das dieselbe Funktion wie limit_rate hat. Sie können die Sicherheit, insbesondere für Anmeldeseiten, verbessern, indem Sie einen angemessenen Wert für die Benutzerlimit-Anfragerate festlegen, um zu verhindern, dass zu langsame Programme Ihre Anwendungsanfragen überschreiben (z. B. DDoS-Angriffe).
max_conns: Serverbefehlsparameter im Upstream-Konfigurationsblock. Die maximale Anzahl von Parallelitäten, die ein einzelner Server in einer Upstream-Servergruppe akzeptieren kann. Verwenden Sie dieses Limit, um eine Überlastung des Upstream-Servers zu verhindern. Wenn Sie den Wert 0 (Standardeinstellung) festlegen, gibt es keine Begrenzung. Warteschlange (NGINX Plus):
Erstellen Sie eine Warteschlange, um die Anzahl der Anforderungen auf dem Upstream-Server zu speichern, die ihr maximales max_cons-Limit überschreiten. Diese Direktive legt die maximale Anzahl von Anfragen in der Warteschlange fest und legt optional die maximale Wartezeit fest, bevor ein Fehler zurückgegeben wird (Standard ist 60 Sekunden). Wenn diese Anweisung weggelassen wird, wird die Anforderung nicht in die Warteschlange gestellt.
Beispiel: Ersetzen Sie den Backend-Dienst Schalten Sie es aus und senden Sie dann eine Anfrage an die Backend-Schnittstelle von Nginx. Im Nginx-Protokoll wird ein 502-Fehler angezeigt.
Wenn 502 in Nginx + PHP auftritt, Fehleranalyse:
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
......
}
erscheint:
server_name ddd.com;
index index.html index.htm index.php;
location ~ .php$ {<!-- -->/80sec.jpg/80sec.phpNach dem Standortbefehl wird die Anfrage zur Verarbeitung an das Back-End-Fastcgi übergeben, und Nginx setzt die Umgebungsvariable SCRIPT_FILENAME dafür mit der Inhalt von
location ~ .php$ {<!-- -->
root html;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params;
}的方式支持对php的解析,location对请求进行选择的时候会使用URI环境变量进行选择,其中传递到后端Fastcgi的关键变量SCRIPT_FILENAME由nginx生成的$fastcgi_script_name决定,而通过分析可以看到$fastcgi_script_name是直接由URI环境变量控制的,这里就是产生问题的点。而为了较好的支持PATH_INFO的提取,在PHP的配置选项里存在cgi.fix_pathinfo选项,其目的是为了从SCRIPT_FILENAME里取出真正的脚本名。
那么假设存在一个http://www.80sec.com/80sec.jpg,我们以如下的方式去访问
将会得到一个URI
/80sec.jpg/80sec.php经过location指令,该请求将会交给后端的fastcgi处理,nginx为其设置环境变量SCRIPT_FILENAME,内容为
/scripts/80sec.jpg/80sec.php而在其他的webserver如lighttpd当中,我们发现其中的SCRIPT_FILENAME被正确的设置为
/scripts/80sec.jpg所以不存在此问题。
后端的fastcgi在接受到该选项时,会根据fix_pathinfo配置决定是否对SCRIPT_FILENAME进行额外的处理,一般情况下如果不对fix_pathinfo进行设置将影响使用PATH_INFO进行路由选择的应用,所以该选项一般配置开启。Php通过该选项之后将查找其中真正的脚本文件名字,查找的方式也是查看文件是否存在,这个时候将分离出SCRIPT_FILENAME和PATH_INFO分别为
/scripts/80sec.jpg和80sec.php最后,以/scripts/80sec.jpg作为此次请求需要执行的脚本,攻击者就可以实现让nginx以php来解析任何类型的文件了。
HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:05:30 GMT<br> Content-Type: text/plain<br> Content-Length: 18<br> Last-Modified: Thu, 20 May 2010 06:26:34 GMT<br> Connection: keep-alive<br> Keep-Alive: timeout=20<br> Accept-Ranges: bytes访问访问http://www.80sec.com/robots.txt/80sec.php
HTTP/1.1 200 OK<br> Server: nginx/0.6.32<br> Date: Thu, 20 May 2010 10:06:49 GMT<br> Content-Type: text/html<br> Transfer-Encoding: chunked<br> Connection: keep-alive<br> Keep-Alive: timeout=20<br> X-Powered-By: PHP/5.2.6其中的Content-Type的变化说明了后端负责解析的变化,该站点就可能存在漏洞。
关闭cgi.fix_pathinfo为0或者
if ( $fastcgi_script_name ~ ..*/.*php ) {<!-- --><br> return 403;<br> }/scripts /80sec.jpg/80sec.php/scripts/80sec.jpggesetzt ist >Das obige ist der detaillierte Inhalt vonMit „Xiaobai' lernen Sie die Module und Arbeitsprinzipien von Nginx kennen! ! !. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!