
Heim >Datenbank >MySQL-Tutorial >Wie führe ich eine SQL-Update-Anweisung aus?
Wie führe ich eine SQL-Update-Anweisung aus?

- 醉折花枝作酒筹nach vorne
- 2021-05-11 09:23:132455Durchsuche
In diesem Artikel erfahren Sie, wie Sie eine SQL-Update-Anweisung ausführen. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.

1. Einführung
Zuvor haben wir den Ausführungsprozess einer Abfrageanweisung systematisch verstanden und die am Ausführungsprozess beteiligten Verarbeitungsmodule vorgestellt. Ich glaube, Sie erinnern sich noch daran, dass der Ausführungsprozess einer Abfrageanweisung im Allgemeinen Funktionsmodule wie Konnektoren, Analysatoren, Optimierer und Executoren durchläuft und schließlich die Speicher-Engine erreicht.
Wie sieht also der Ausführungsablauf einer Update-Anweisung aus?
Sie haben vielleicht schon oft von DBA-Kollegen gehört, dass MySQL innerhalb eines halben Monats in jeder Sekunde wiederhergestellt werden kann. Sie sind zwar erstaunt, aber auch neugierig, wie das geht?
2. Anweisungsanalyse
Beginnen wir mit einer Aktualisierungsanweisung für eine Tabelle. Diese Tabelle hat eine Primärschlüssel-ID und ein Ganzzahlfeld c:
rrreeWenn Sie eine ID festlegen möchten =2 Fügen Sie 1 zum Wert dieser Zeile hinzu, und die SQL-Anweisung wird wie folgt geschrieben:
mysql> create table T(ID int primary key, c int);
Ich habe Ihnen bereits den grundlegenden Ausführungslink der SQL-Anweisung vorgestellt. Sie können dies auch tun Schauen Sie sich zunächst kurz diese Bildrezension an. Zunächst lässt sich mit Sicherheit sagen, dass auch bei Query-Anweisungen und Update-Anweisungen die gleichen Abläufe befolgt werden.
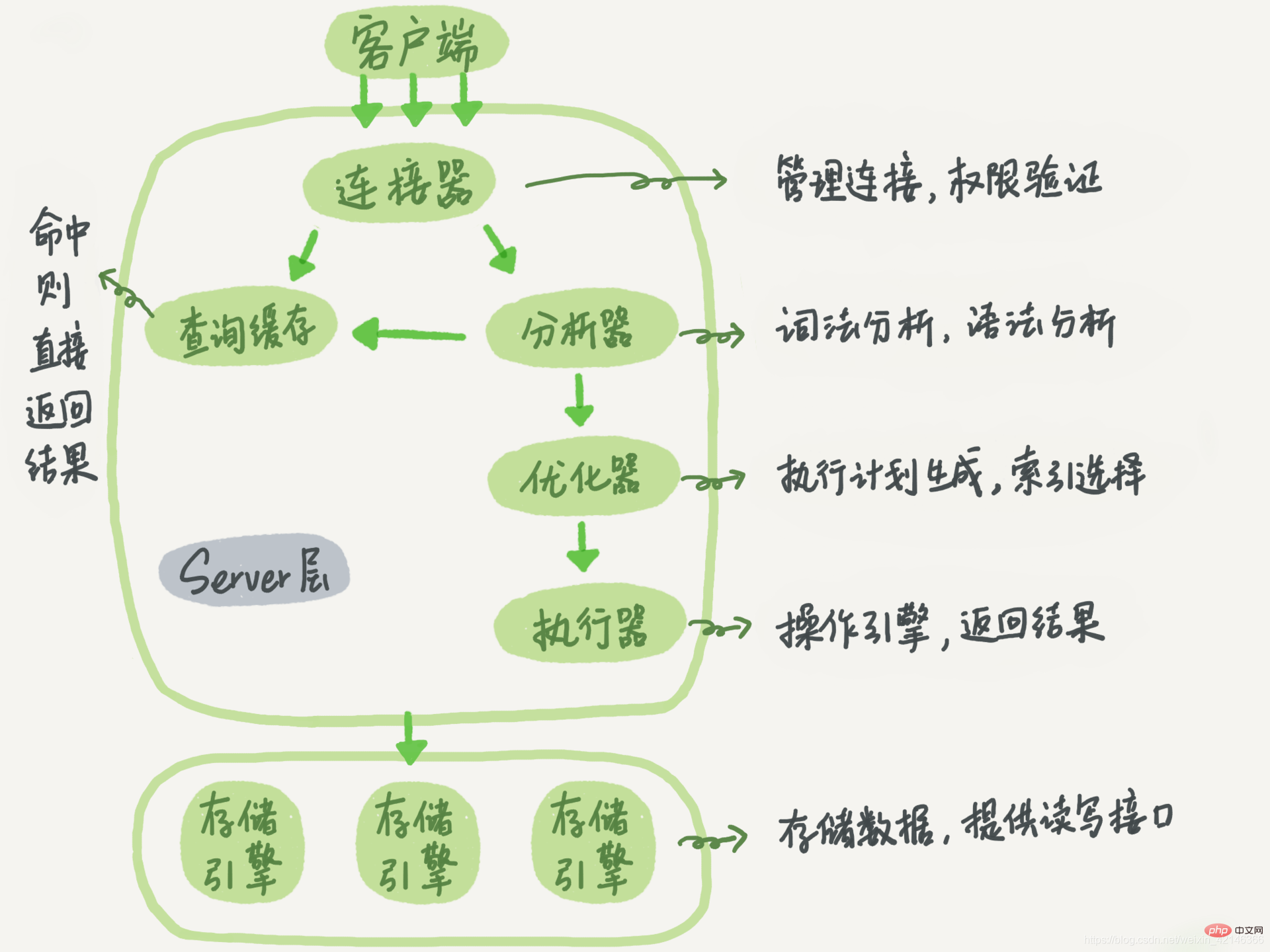
Sie müssen zuerst eine Verbindung zur Datenbank herstellen, bevor Sie die Anweisung ausführen. Dies ist die Aufgabe des Connectors.
Wir haben zuvor gesagt, dass bei einer Aktualisierung einer Tabelle der Abfrage-Cache für diese Tabelle ungültig wird, sodass diese Anweisung alle zwischengespeicherten Ergebnisse in Tabelle T löscht. Aus diesem Grund raten wir generell davon ab, Abfrage-Caching zu verwenden.
Als nächstes erkennt der Analysator durch lexikalische und syntaktische Analyse, dass es sich um eine Aktualisierungsanweisung handelt. Der Optimierer entscheidet sich für die Verwendung der Index-ID. Der Ausführende ist dann dafür verantwortlich, die Zeile tatsächlich auszuführen, diese Zeile zu finden und zu aktualisieren.
Im Gegensatz zum Abfrageprozess umfasst der Aktualisierungsprozess auch zwei wichtige Protokollmodule, die die Protagonisten sind, die wir heute besprechen werden: Redo Log (Redo-Protokoll) und Binlog (Archivprotokoll). Wenn Sie mit MySQL in Kontakt kommen, werden Sie an diesen beiden Wörtern definitiv nicht vorbeikommen und ich werde sie Ihnen im folgenden Inhalt weiterhin hervorheben. Dennoch gibt es viele interessante Aspekte beim Design von Redo-Log und Binlog, und diese Design-Ideen können auch in Ihren eigenen Programmen verwendet werden.
Wichtiges Protokollmodul: Redo-Protokoll
Ich weiß nicht, ob Sie sich noch an den Artikel „Kong Yiji“ erinnern. Der Hotelmanager hat eine rosa Tafel, die speziell zur Aufzeichnung der Kreditdaten der Gäste dient. Wenn es nicht viele Leute gibt, die auf Kredit bezahlen, kann er den Namen und das Konto des Kunden an die Tafel schreiben. Aber wenn es zu viele Leute mit Guthabenkonten gibt, wird es immer Zeiten geben, in denen die Fangemeinde den Überblick nicht behalten kann. Zu diesem Zeitpunkt muss der Ladenbesitzer ein Hauptbuch speziell für die Erfassung von Guthabenkonten haben.
Wenn sich jemand Geld leihen oder eine Schuld zurückzahlen möchte, hat der Ladenbesitzer im Allgemeinen zwei Methoden:
- Eine Methode besteht darin, das Kontobuch direkt auszustellen und das Guthaben hinzuzufügen oder abzuziehen.
- Die andere Methode ist: Zuerst aufschreiben Legen Sie das Konto an die rosa Tafel und nehmen Sie nach Geschäftsschluss das Kontobuch heraus.
Wenn das Geschäft boomt und die Theke sehr voll ist, wird sich der Ladenbesitzer definitiv für Letzteres entscheiden, weil Ersteres zu mühsam zu bedienen ist. Zuerst müssen Sie den Datensatz des Gesamtguthabenkontos dieser Person finden. Denken Sie darüber nach, es gibt Dutzende dicht gepackter Seiten. Um den Namen zu finden, muss der Ladenbesitzer möglicherweise eine Lesebrille aufsetzen und langsam suchen. Nachdem er ihn gefunden hat, wird er den Abakus herausnehmen, um ihn zu berechnen, und schließlich das Ergebnis zurückschreiben das Hauptbuch.
Es ist schwierig, über diesen gesamten Prozess nachzudenken. Im Gegensatz dazu ist es einfacher, es zuerst an die rosa Tafel zu schreiben. Denken Sie darüber nach: Wenn der Ladenbesitzer nicht die Hilfe der rosa Tafel hat, muss er das Hauptbuch jedes Mal umdrehen, wenn er Konten aufzeichnet. Ist die Effizienz nicht unerträglich niedrig?
In ähnlicher Weise besteht dieses Problem auch in MySQL. Wenn jeder Aktualisierungsvorgang auf die Festplatte geschrieben werden muss und die Festplatte dann auch den entsprechenden Datensatz finden und dann aktualisieren muss, fallen die E/A-Kosten und die Suchkosten des gesamten Prozesses an sehr hoch. Um dieses Problem zu lösen, verwendeten die Designer von MySQL eine Idee, die der rosa Tafel des Hotelladenbesitzers ähnelt, um die Aktualisierungseffizienz zu verbessern.
Der gesamte Prozess der Zusammenarbeit zwischen dem Pink Board und dem Ledger ist eigentlich die WAL-Technologie, die in MySQL oft erwähnt wird. Der vollständige Name von WAL ist Write-Ahead Logging. Der Kernpunkt besteht darin, zuerst das Protokoll und dann auf die Festplatte zu schreiben Das heißt, ich werde zuerst die rosa Tafel schreiben, wenn ich nicht beschäftigt bin.
Wenn ein Datensatz aktualisiert werden muss, schreibt die InnoDB-Engine den Datensatz zunächst in das Redo-Protokoll (rosa Tafel) und aktualisiert den Speicher. Zu diesem Zeitpunkt ist die Aktualisierung abgeschlossen. Gleichzeitig aktualisiert die InnoDB-Engine den Vorgangsdatensatz zum richtigen Zeitpunkt auf der Festplatte. Diese Aktualisierung erfolgt häufig, wenn das System relativ inaktiv ist, genau wie der Ladenbesitzer es nach dem Schließen tut.
Wenn es heute nicht viele Guthabenkonten gibt, kann der Ladenbesitzer mit der Klärung bis zur Schließung warten. Was aber, wenn es an einem bestimmten Tag viele Guthabenkonten gibt und die rosa Tafel voll ist? Zu diesem Zeitpunkt hatte der Ladenbesitzer keine andere Wahl, als seine Arbeit niederzulegen, einige der Kreditdatensätze auf der rosa Tafel im Hauptbuch zu aktualisieren und diese Datensätze dann von der rosa Tafel zu löschen, um Platz für neue Konten zu schaffen.
Ähnlich wie hier hat das Redo-Protokoll von InnoDB eine feste Größe. Es kann beispielsweise als Satz von 4 Dateien konfiguriert werden, und die Größe jeder Datei beträgt 1 GB. Dann kann dieses „Pink Board“ insgesamt 4 GB Vorgänge aufzeichnen. Beginnen Sie mit dem Schreiben von Anfang an und kehren Sie dann zum Anfang zurück, um in einer Schleife zu schreiben, wie in der Abbildung unten gezeigt.
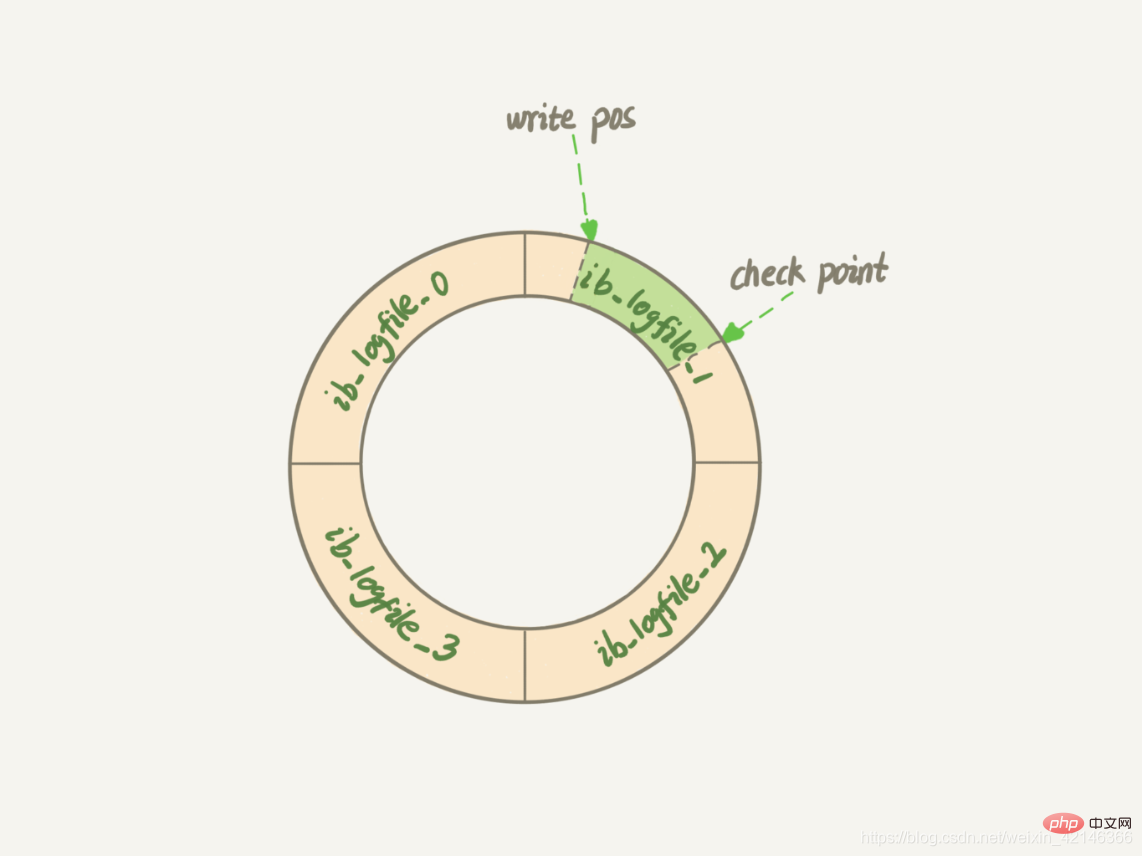
write pos ist die Position des aktuellen Datensatzes. Er bewegt sich beim Schreiben rückwärts (im Uhrzeigersinn). Nach dem Schreiben an das Ende der Datei Nr. 3 kehrt er zum Anfang der Datei Nr. 0 zurück. Der Prüfpunkt ist die aktuelle Position, die gelöscht werden soll, und er bewegt sich auch vorwärts und führt eine Schleife durch. Vor dem Löschen des Datensatzes muss der Datensatz in der Datendatei aktualisiert werden.
Der Raum zwischen Schreibposition und Kontrollpunkt ist der leere Teil der „rosa Tafel“, der zum Aufzeichnen neuer Vorgänge verwendet werden kann. Wenn die Schreibposition den Prüfpunkt einholt, bedeutet dies, dass das „Pink Board“ voll ist und zu diesem Zeitpunkt keine neuen Aktualisierungen durchgeführt werden können. Sie müssen zuerst anhalten und einige Datensätze löschen, um den Prüfpunkt voranzutreiben.
Mit dem Redo-Log kann InnoDB sicherstellen, dass zuvor übermittelte Datensätze nicht verloren gehen, auch wenn die Datenbank abnormal neu gestartet wird. Diese Funktion wird als absturzsicher bezeichnet.
Um das Konzept der Crash-Sicherheit zu verstehen, können Sie sich unser vorheriges Beispiel für eine Kreditaufnahme vorstellen. Solange die Kreditaufzeichnung auf der rosa Tafel oder im Hauptbuch vermerkt ist, kann der Ladenbesitzer das Kreditkonto anhand der Daten im Hauptbuch klären, auch wenn er sie später vergisst, z. B. weil er sein Geschäft plötzlich für ein paar Tage einstellt Pinke Tafel nach Wiederaufnahme des Geschäftsbetriebs.
Wichtiges Protokollmodul: binlog
Wie bereits erwähnt, besteht MySQL als Ganzes eigentlich aus zwei Teilen: Der eine ist die Serverschicht, die hauptsächlich Dinge auf der Funktionsebene von MySQL erledigt, und der andere ist die Engine-Schicht, die dafür verantwortlich ist für spezifische Fragen im Zusammenhang mit der Lagerung. Das Pink-Board-Redo-Protokoll, über das wir oben gesprochen haben, ist ein Protokoll, das nur für die InnoDB-Engine gilt, und die Serverschicht verfügt auch über ein eigenes Protokoll, das Binlog (archiviertes Protokoll) genannt wird.
Ich denke, Sie werden sich fragen, warum es zwei Protokolle gibt?
Weil es zu Beginn keine InnoDB-Engine in MySQL gab. Die eigene Engine von MySQL ist MyISAM, aber MyISAM verfügt nicht über Absturzsicherungsfunktionen und Binlog-Protokolle können nur zur Archivierung verwendet werden. InnoDB wurde von einem anderen Unternehmen in Form eines Plug-Ins in MySQL eingeführt. Da die alleinige Verwendung von Binlog keine absturzsicheren Funktionen bietet, verwendet InnoDB ein anderes Protokollsystem, nämlich Redo Log, um absturzsichere Funktionen zu erreichen.
Diese beiden Protokolle weisen die folgenden drei Unterschiede auf.
- Redo-Log ist einzigartig für die InnoDB-Engine; binlog wird von der Serverschicht von MySQL implementiert und kann von allen Engines verwendet werden.
- Redo-Protokoll ist ein physisches Protokoll, das aufzeichnet, „welche Änderungen auf einer bestimmten Datenseite vorgenommen wurden“. Binlog ist ein logisches Protokoll, das die ursprüngliche Logik dieser Anweisung aufzeichnet, z. B. „Fügen Sie das c-Feld der Zeile mit der ID hinzu.“ =2 1".
- Redo-Log wird in einer Schleife geschrieben und der Speicherplatz wird immer aufgebraucht; Binlog kann zusätzlich geschrieben werden. „Schreiben anhängen“ bedeutet, dass die Binlog-Datei nach Erreichen einer bestimmten Größe zur nächsten wechselt und das vorherige Protokoll nicht überschreibt.
Mit einem konzeptionellen Verständnis dieser beiden Protokolle schauen wir uns die internen Prozesse des Executors und der InnoDB-Engine bei der Ausführung dieser einfachen Update-Anweisung an.
- Der Executor sucht zunächst nach der Engine, um die Zeilen-ID=2 zu erhalten. Die ID ist der Primärschlüssel, und die Engine verwendet direkt die Baumsuche, um diese Zeile zu finden. Wenn sich die Datenseite, auf der sich die Zeile ID=2 befindet, bereits im Speicher befindet, wird sie direkt an den Executor zurückgegeben. Andernfalls muss sie von der Festplatte in den Speicher gelesen und dann zurückgegeben werden.
- Der Executor ruft die von der Engine bereitgestellten Zeilendaten ab, addiert 1 zu diesem Wert, zum Beispiel war er früher N, aber jetzt ist er N+1, ruft eine neue Datenzeile ab und ruft dann die Engine-Schnittstelle auf Schreiben Sie diese neue Datenzeile.
- Die Engine aktualisiert diese neue Datenzeile im Speicher und zeichnet den Aktualisierungsvorgang im Redo-Log auf. Zu diesem Zeitpunkt befindet sich das Redo-Log im Vorbereitungsstatus. Informieren Sie anschließend den Testamentsvollstrecker darüber, dass die Ausführung abgeschlossen ist und die Transaktion jederzeit eingereicht werden kann.
- Der Executor generiert das Binlog dieses Vorgangs und schreibt das Binlog auf die Festplatte.
- Der Executor ruft die Commit-Transaktionsschnittstelle der Engine auf, und die Engine ändert das gerade geschriebene Redo-Protokoll in den Commit-Status, und die Aktualisierung ist abgeschlossen.
Hier gebe ich das Ausführungsflussdiagramm dieser Update-Anweisung an. Das helle Kästchen in der Abbildung zeigt an, dass es in InnoDB ausgeführt wird, und das dunkle Kästchen zeigt an, dass es im Executor ausgeführt wird.
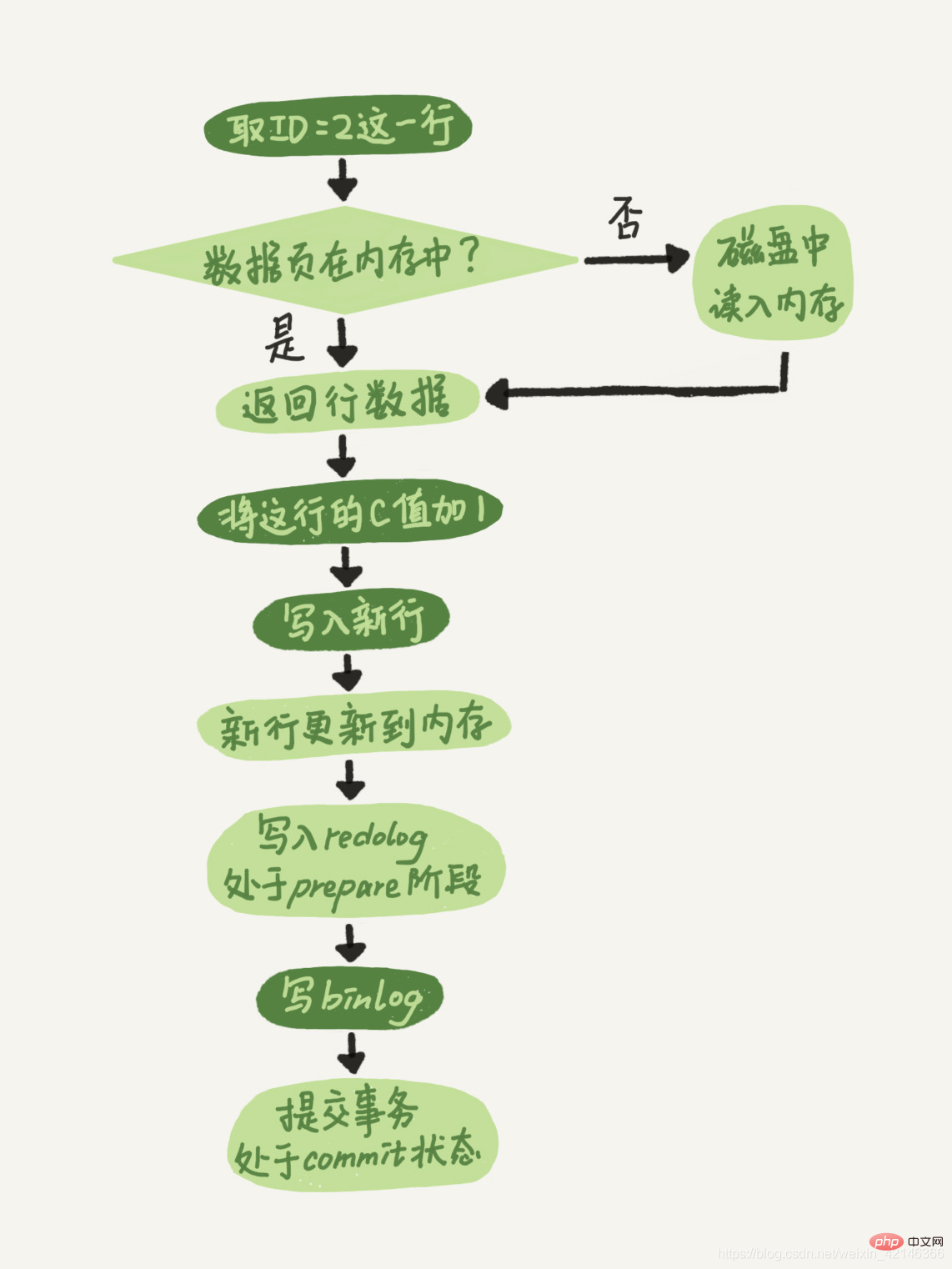
Sie haben vielleicht bemerkt, dass die letzten drei Schritte etwas „zirkulär“ erscheinen. Das Schreiben des Redo-Logs ist in zwei Schritte unterteilt: Vorbereiten und Festschreiben. Dies ist ein „Zwei-Phasen-Commit“.
Zwei-Phasen-Einreichung
Warum ist eine „Zwei-Phasen-Einreichung“ notwendig? Dadurch soll die Logik zwischen den beiden Protokollen konsistent gemacht werden. Um dieses Problem zu erklären, müssen wir mit der Frage am Anfang des Artikels beginnen: Wie kann die Datenbank innerhalb eines halben Monats auf den Zustand jeder Sekunde zurückgesetzt werden?
Wie bereits erwähnt, zeichnet Binlog alle logischen Vorgänge auf und übernimmt die Form des „Schreibens anhängen“. Wenn Ihr DBA verspricht, dass es innerhalb eines halben Monats wiederhergestellt werden kann, speichert das Backup-System auf jeden Fall alle Binlogs im letzten halben Monat und das System sichert regelmäßig die gesamte Datenbank. Das „Regelmäßige“ hängt hier von der Wichtigkeit des Systems ab, das einmal am Tag oder einmal in der Woche sein kann.
Wenn Sie eine bestimmte Sekunde wiederherstellen müssen, zum Beispiel eines Tages um zwei Uhr nachmittags, stellen Sie fest, dass die Tabelle mittags versehentlich gelöscht wurde, und Sie müssen die Daten abrufen, dann Sie Sie können Folgendes tun:
- Suchen Sie zunächst die aktuellste vollständige Sicherung. Wenn Sie Glück haben, handelt es sich möglicherweise um eine Sicherung von gestern Abend, und stellen Sie sie von dieser Sicherung in der temporären Datenbank wieder her.
- Beginnen Sie dann mit der Sicherung Nehmen Sie an diesem Punkt das Backup-Binlog nacheinander heraus und spielen Sie es erneut ab, bis die Tabelle mittags versehentlich gelöscht wurde. In diesem Moment zuvor.
Auf diese Weise ist Ihre temporäre Datenbank dieselbe wie die Online-Datenbank, bevor Sie sie versehentlich gelöscht haben. Anschließend können Sie die Tabellendaten aus der temporären Datenbank entfernen und bei Bedarf in der Online-Datenbank wiederherstellen.
Okay, nachdem wir nun mit dem Gespräch über den Datenwiederherstellungsprozess fertig sind, kommen wir zurück und sprechen darüber, warum Protokolle ein „Zwei-Phasen-Commit“ benötigen. Hier könnten wir zur Erklärung genauso gut einen Widerspruchsbeweis verwenden.
Verwende immer noch die vorherige Update-Anweisung als Beispiel. Nehmen Sie an, dass der Wert von Feld c in der aktuellen Zeile mit ID=2 0 ist, und nehmen Sie an, dass während der Ausführung der Update-Anweisung nach dem Schreiben des ersten Protokolls ein Absturz auftritt, bevor das zweite Protokoll geschrieben wird.
- Schreiben Sie zuerst das Redo-Protokoll und dann das Binlog. Angenommen, der MySQL-Prozess startet abnormal neu, wenn das Redo-Log geschrieben wird, aber bevor das Binlog geschrieben wird. Wie bereits erwähnt, können die Daten nach dem Schreiben des Redo-Protokolls auch bei einem Systemabsturz wiederhergestellt werden. Daher beträgt der Wert von c in dieser Zeile nach der Wiederherstellung 1. Da das Binlog jedoch vor seiner Fertigstellung abstürzte, wurde diese Aussage zu diesem Zeitpunkt nicht im Binlog aufgezeichnet. Wenn das Protokoll später gesichert wird, wird diese Anweisung daher nicht in das gespeicherte Binlog aufgenommen. Dann werden Sie feststellen, dass, wenn Sie dieses Binlog zum Wiederherstellen der temporären Bibliothek verwenden müssen, die temporäre Bibliothek dieses Mal nicht aktualisiert wird, da das Binlog dieser Anweisung verloren geht. Der Wert von c in der wiederhergestellten Zeile ist 0 derselbe wie der Wert der Originalbibliothek.
- Schreiben Sie zuerst das Binlog und dann das Redo-Log. Wenn nach dem Schreiben des Binlogs ein Absturz auftritt, ist die Transaktion nach der Wiederherstellung nach dem Absturz ungültig, da das Redo-Log noch nicht geschrieben wurde. Daher ist der Wert von c in dieser Zeile 0. Aber das Protokoll „Change c from 0 to 1“ wurde im Binlog aufgezeichnet. Wenn daher später Binlog zum Wiederherstellen verwendet wird, wird eine weitere Transaktion ausgegeben. Der Wert von c in der wiederhergestellten Zeile ist 1, was sich vom Wert in der ursprünglichen Datenbank unterscheidet.
Sie können sehen, dass der Status der Datenbank möglicherweise nicht mit dem Status der mithilfe ihres Protokolls wiederhergestellten Bibliothek übereinstimmt, wenn „Zwei-Phasen-Commit“ nicht verwendet wird.
Sie sagen vielleicht, ist diese Wahrscheinlichkeit nicht sehr gering? Es gibt keine Situationen, in denen die temporäre Bibliothek zu irgendeinem Zeitpunkt wiederhergestellt werden muss?
Eigentlich nein, dieser Vorgang ist nicht nur erforderlich, um Daten nach einer Fehlbedienung wiederherzustellen. Wenn Sie die Kapazität erweitern müssen, das heißt, wenn Sie mehr Standby-Datenbanken erstellen müssen, um die Lesekapazität des Systems zu erhöhen, ist es mittlerweile üblich, eine vollständige Sicherung zu verwenden und Binlog anzuwenden, um dies zu erreichen. Diese „Inkonsistenz“ führt zu Ihrem Problem eine Inkonsistenz zwischen den Master- und Slave-Datenbanken online.
Einfach ausgedrückt können sowohl Redo-Log als auch Binlog verwendet werden, um den Commit-Status einer Transaktion darzustellen, und das zweiphasige Commit dient dazu, die beiden Zustände logisch konsistent zu halten.
Verwandte Empfehlungen: „MySQL-Tutorial“
Das obige ist der detaillierte Inhalt vonWie führe ich eine SQL-Update-Anweisung aus?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!