
40 Redis-Interviewfragen, die Sie nicht verpassen dürfen (einschließlich Antworten und Mindmaps)

- 青灯夜游nach vorne
- 2021-04-02 10:34:258602Durchsuche
In diesem Artikel werden 40 Redis-Interviewfragen mit Ihnen geteilt, einschließlich Antwortanalyse und Mindmaps der Redis-Wissenspunkte. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.

Redis-Interviewfragen
1. Was ist Redis?
Redis ist vollständig Open Source und kostenlos, entspricht dem BSD-Protokoll und ist eine leistungsstarke Schlüsselwertdatenbank.
Redis weist im Vergleich zu anderen Schlüsselwert-Cache-Produkten die folgenden drei Merkmale auf:
(1) Redis unterstützt die Datenpersistenz und kann Daten im Speicher auf der Festplatte speichern und zur Verwendung beim Neustart erneut laden.
(2) Redis unterstützt nicht nur einfache Daten vom Typ Schlüsselwert, sondern bietet auch die Speicherung von Datenstrukturen wie Liste, Satz, Zset und Hash.
(3) Redis unterstützt die Datensicherung, also die Datensicherung im Master-Slave-Modus.
[Verwandte Empfehlungen: Redis-Video-Tutorial]
Vorteile von Redis
(1) Extrem hohe Leistung – Redis kann mit einer Geschwindigkeit von 110.000 Mal/s lesen und mit einer Geschwindigkeit von 81.000 Mal/s schreiben.
(2) Umfangreiche Datentypen – Redis unterstützt Datentypoperationen vom Typ Strings, Listen, Hashes, Mengen und geordnete Mengen für binäre Fälle.
(3) Atomar – Alle Operationen von Redis sind atomar, was bedeutet, dass sie entweder erfolgreich ausgeführt werden oder gar nicht ausgeführt werden, wenn sie fehlschlagen. Einzelne Operationen sind atomar. Mehrere Operationen unterstützen auch Transaktionen, d. h. Atomizität, die durch die Anweisungen MULTI und EXEC umschlossen werden.
(4) Umfangreiche Funktionen – Redis unterstützt auch Publish/Subscribe, Benachrichtigungen, Schlüsselablauf und andere Funktionen.
Wie unterscheidet sich Redis von anderen Key-Value-Stores?
(1) Redis verfügt über komplexere Datenstrukturen und bietet atomare Operationen für diese. Dies ist ein evolutionärer Weg, der sich von anderen Datenbanken unterscheidet. Die Datentypen von Redis basieren auf grundlegenden Datenstrukturen und sind für Programmierer transparent, ohne dass zusätzliche Abstraktionen erforderlich sind.
(2) Redis wird im Speicher ausgeführt, kann jedoch auf der Festplatte gespeichert werden. Daher muss der Speicher abgewogen werden, wenn verschiedene Datensätze mit hoher Geschwindigkeit gelesen und geschrieben werden, da die Datenmenge nicht größer als der Hardwarespeicher sein darf. Ein weiterer Vorteil von In-Memory-Datenbanken besteht darin, dass der Betrieb im Speicher im Vergleich zu denselben komplexen Datenstrukturen auf der Festplatte sehr einfach ist, sodass Redis viele Dinge mit hoher interner Komplexität erledigen kann. Außerdem sind sie im Hinblick auf das Festplattenformat kompakt und werden durch Anhängen generiert, da sie keinen wahlfreien Zugriff erfordern.
2. Was sind die Datentypen von Redis?
Antwort: Redis unterstützt fünf Datentypen: String (String), Hash (Hash), Liste (Liste), Set (Satz) und zsetsorted set: geordneter Satz).
Die in unseren tatsächlichen Projekten am häufigsten verwendeten sind String und Hash. Wenn Sie ein fortgeschrittener Redis-Benutzer sind, müssen Sie auch die folgenden Datenstrukturen hinzufügen: HyperLogLog, Geo und Pub/Sub.
Wenn Sie sagen, dass Sie mit Redis-Modulen wie BloomFilter, RedisSearch und Redis-ML gespielt haben, beginnen die Augen des Interviewers zu leuchten.
3. Welche Vorteile bietet die Verwendung von Redis?
(1) Es ist schnell, weil die Daten im Speicher gespeichert werden, ähnlich wie bei HashMap. Der Vorteil von HashMap besteht darin, dass die zeitliche Komplexität von Suche und Betrieb O1) ist.
(2) Es unterstützt umfangreiche Datentypen, einschließlich Zeichenfolgen , list und set.
(3) Unterstützungstransaktionen und Operationen sind alle atomar. Die sogenannte Atomizität bedeutet, dass alle Änderungen an den Daten entweder ausgeführt werden oder überhaupt nicht
(4 ) Umfangreiche Funktionen: Kann zum Zwischenspeichern und für Nachrichten verwendet werden. Drücken Sie die Taste, um die Ablaufzeit festzulegen. Nach Ablauf wird es automatisch gelöscht.
4 Was sind die Vorteile von Redis im Vergleich zu Memcached?
(1) Alle Werte in Memcached sind einfache Zeichenfolgen, und Redis als Ersatz unterstützt umfangreichere Datentypen.
(2) Redis ist viel schneller als Memcached.
(3) Redis kann seine Daten dauerhaft transformieren
5. Was sind die Unterschiede zwischen Memcache und Redis?
(1) Speichermethode Memecache speichert alle Daten im Speicher. Nach einem Stromausfall bleibt der Datenspeicher hängen. Redis wird teilweise auf der Festplatte gespeichert, was die Datenpersistenz gewährleistet.
(2) Datenunterstützungstypen Die Unterstützung von Datentypen durch Memcache ist relativ einfach. Redis verfügt über komplexe Datentypen.
(3) Die verwendeten zugrunde liegenden Modelle sind unterschiedlich, die zugrunde liegenden Implementierungsmethoden und die Anwendungsprotokolle für die Kommunikation mit dem Client sind unterschiedlich. Redis baut direkt seinen eigenen VM-Mechanismus auf, denn wenn das allgemeine System Systemfunktionen aufruft, verschwendet es eine gewisse Zeit zum Verschieben und Anfordern.
6. Ist Redis Single-Process und Single-Threaded?
Antwort: Redis ist ein einzelner Prozess und ein einzelner Thread. Redis nutzt die Warteschlangentechnologie, um gleichzeitigen Zugriff in seriellen Zugriff umzuwandeln, wodurch der Overhead der herkömmlichen seriellen Datenbanksteuerung entfällt.
7. Was ist die maximale Kapazität, die ein String-Typ-Wert speichern kann?
Antwort: 512M

8. Was ist der Persistenzmechanismus von Redis? Was sind die Vor- und Nachteile jedes einzelnen?
Redis bietet zwei Persistenzmechanismen: RDB- und AOF-Mechanismen:
1. RDBRedis DataBase) Persistenzmodus:
bezieht sich auf den semipersistenten Modus (unter Verwendung von Datensatz-Snapshots), um alle Schlüssel-Wert-Paare der Redis-Datenbank aufzuzeichnen. Schreiben Sie Daten zu einem bestimmten Zeitpunkt in eine temporäre Datei. Verwenden Sie nach Abschluss der Persistenz diese temporäre Datei, um die letzte persistente Datei zu ersetzen und eine Datenwiederherstellung zu erreichen.
Vorteile:
(1) Es gibt nur eine Datei dump.rdb, was für die Persistenz praktisch ist.
(2) Gute Katastrophentoleranz, eine Datei kann auf einer sicheren Festplatte gespeichert werden.
(3) Um die Leistung zu maximieren, verzweigen Sie den untergeordneten Prozess, um den Schreibvorgang abzuschließen, und lassen Sie den Hauptprozess weiterhin Befehle verarbeiten, sodass die E/A maximiert wird. Verwenden Sie einen separaten Unterprozess für die Persistenz, und der Hauptprozess führt keine E/A-Vorgänge aus, um die hohe Leistung von Redis sicherzustellen.)
(4) Wenn der Datensatz groß ist, ist die Starteffizienz höher als bei AOF.
Nachteile:
Geringe Datensicherheit. RDB wird in bestimmten Abständen beibehalten, wenn Redis zwischen der Persistenz fehlschlägt. Daher ist diese Methode besser geeignet, wenn die Datenanforderungen nicht streng sind als AOF-Dateien gespeichert.
Vorteile:
(1) Datensicherheit, AOF-Persistenz kann mit dem appendfsync-Attribut konfiguriert werden, wobei jede Befehlsoperation immer in der AOF-Datei aufgezeichnet wird.
(2) Schreiben Sie Dateien im Anhängemodus. Selbst wenn der Server mittendrin ausfällt, können Sie das Datenkonsistenzproblem mit dem Redis-Check-Aof-Tool lösen.
(3) Rewrite-Modus des AOF-Mechanismus. Bevor die AOF-Datei neu geschrieben wird (Befehle werden zusammengeführt und neu geschrieben, wenn die Datei zu groß ist), können Sie einige der Befehle löschen (z. B. „Flushall“ aus Versehen))
Nachteile:
(1) AOF-Dateien sind größer als RDB-Dateien und die Wiederherstellungsgeschwindigkeit ist langsam.
(2) Wenn der Datensatz groß ist, ist die Starteffizienz geringer als bei RDB.
9. Redis häufige Leistungsprobleme und Lösungen:(1) Der Master schreibt am besten keine Speicher-Snapshots. Der Speicherbefehl plant die rdbSave-Funktion, die die Arbeit des Hauptthreads blockiert . Wenn der Snapshot groß ist, ist die Auswirkung auf die Leistung sehr groß und der Dienst wird zeitweise angehalten(2) Wenn die Daten wichtig sind, aktiviert ein Slave AOF-Sicherungsdaten und die Richtlinie ist so eingestellt, dass sie einmal pro Sekunde synchronisiert wird
(3) Um die Master-Slave-Replikation zu beschleunigen. Um die Stabilität der Verbindung zu gewährleisten, ist es am besten, wenn sich Master und Slave im selben LAN befinden.
(4) Versuchen Sie zu vermeiden, dem überlasteten Master Slaves hinzuzufügen Bibliothek
(5) Verwenden Sie keine Diagrammstrukturen für die Master-Slave-Replikation, sondern verwenden Sie einseitig verknüpfte Listen. Die Struktur ist stabiler, das heißt: Master <- Slave1<- Slave2 <- Slave3 ... Diese Struktur ist praktisch, um das Problem des Single-Point-Fehlers zu lösen und den Ersatz des Masters durch den Slave zu realisieren. Wenn der Master auflegt, können Sie Slave1 sofort als Master aktivieren und alles andere unverändert lassen.
10. Was ist die Löschstrategie für abgelaufene Redis-Schlüssel?(1) Geplantes Löschen: Erstellen Sie beim Festlegen der Ablaufzeit des Schlüssels einen Timer (Timer), damit der Timer den Schlüssel sofort löscht, wenn die Ablaufzeit des Schlüssels erreicht ist. (2) Verzögertes Löschen: Lassen Sie den Schlüssel ablaufen, aber prüfen Sie jedes Mal, wenn Sie den Schlüssel aus dem Schlüsselraum erhalten, ob er abgelaufen ist. Wenn er nicht abgelaufen ist, geben Sie ihn zurück Schlüssel.
(3) Regelmäßiges Löschen: Von Zeit zu Zeit überprüft das Programm die Datenbank und löscht die darin enthaltenen abgelaufenen Schlüssel. Es liegt am Algorithmus, zu entscheiden, wie viele abgelaufene Schlüssel gelöscht und wie viele Datenbanken überprüft werden sollen.
11. Redis-Recyclingstrategie (Eliminierungsstrategie)?volatile-lru: Wählen Sie die zuletzt verwendeten Daten aus dem Datensatz (server.db[i].expires) mit einer festgelegten Ablaufzeit aus, um sie zu entfernen volatile -ttl: Wählen Sie die abzulaufenden Daten aus dem Datensatz mit festgelegter Ablaufzeit (server.db[i].expires) aus und entfernen Sie sie
volatile-random: Wählen Sie den Datensatz mit festgelegter Ablaufzeit aus (server.db[i].expires) .db[i]. läuft ab)
allkeys-lru: Wählen Sie die zuletzt verwendeten Daten aus dem Datensatz (server.db[i].dict) aus, um sie zu entfernen
allkeys-random: Aus dem Datensatz (server.db [i] .dict) No-Enviction (Räumung): Verbietet die Räumung von Daten
Beachten Sie die 6 Mechanismen hier: Volatile und Allkeys geben an, ob Daten aus dem Datensatz mit einer festgelegten Ablaufzeit oder aus allen Datensätzen entfernt werden sollen Daten, die folgenden lru, ttl und random sind drei verschiedene Eliminierungsstrategien sowie eine No-Enviction-Strategie, die niemals recycelt wird.
Verwenden Sie Richtlinienregeln:
(1) Wenn die Daten eine Potenzgesetzverteilung aufweisen, d stellt eine Gleichverteilung dar, d. h. wenn alle Datenzugriffshäufigkeiten gleich sind, verwenden Sie allkeys-random
12. Warum muss Edis alle Daten im Speicher ablegen?
Antwort: Um die schnellste Lese- und Schreibgeschwindigkeit zu erreichen, liest Redis alle Daten in den Speicher und schreibt die Daten asynchron auf die Festplatte. Redis zeichnet sich also durch hohe Geschwindigkeit und Datenpersistenz aus. Wenn die Daten nicht im Speicher abgelegt werden, beeinträchtigt die E/A-Geschwindigkeit der Festplatte die Leistung von Redis erheblich. Heutzutage, da Speicher immer billiger wird, wird Redis immer beliebter. Wenn der maximal verwendete Speicher eingestellt ist, können keine neuen Werte eingefügt werden, nachdem die Anzahl der vorhandenen Datensätze das Speicherlimit erreicht hat.
13. Verstehen Sie den Synchronisierungsmechanismus von Redis?
Antwort: Redis kann Master-Slave-Synchronisation und Slave-Slave-Synchronisation verwenden. Während der ersten Synchronisierung führt der Primärknoten eine BGSAVE durch und zeichnet nachfolgende Änderungsvorgänge im Speicherpuffer auf. Nach Abschluss wird die gesamte RDB-Datei mit dem Replikatknoten synchronisiert. Nachdem der Replikatknoten die Daten akzeptiert hat, wird das RDB-Image geladen in die Erinnerung. Nach Abschluss des Ladevorgangs wird der Masterknoten benachrichtigt, die während des Zeitraums geänderten Vorgangsdatensätze zur Wiedergabe mit dem Replikatknoten zu synchronisieren, und der Synchronisierungsprozess ist abgeschlossen.
14. Was sind die Vorteile von Pipeline?
Antwort: Die Zeit mehrerer IO-Roundtrips kann auf einen reduziert werden, sofern kein kausaler Zusammenhang zwischen den von der Pipeline ausgeführten Anweisungen besteht. Bei der Verwendung von Redis-Benchmark für Stresstests kann festgestellt werden, dass die Anzahl der Pipeline-Batch-Anweisungen ein wichtiger Faktor ist, der den QPS-Spitzenwert von Redis beeinflusst.
15. Haben Sie jemals Redis-Cluster verwendet?
(1) Redis Sentinal konzentriert sich auf hohe Verfügbarkeit. Wenn der Master ausfällt, wird der Slave automatisch zum Master befördert und stellt weiterhin Dienste bereit.
(2) Redis-Cluster konzentriert sich auf Skalierbarkeit. Wenn ein einzelner Redis-Speicher nicht ausreicht, wird Cluster für Shard-Speicher verwendet.
16. Unter welchen Umständen führt die Redis-Clusterlösung dazu, dass der gesamte Cluster nicht verfügbar ist?
Antwort: Wenn in einem Cluster mit drei Knoten A, B und C ohne Replikationsmodell Knoten B ausfällt, geht der gesamte Cluster davon aus, dass ihm Steckplätze im Bereich von 5501–11000 fehlen und er nicht verfügbar ist.
17. Welche Java-Clients werden von Redis unterstützt? Welches wird offiziell empfohlen?
Antwort: Redisson, Jedis, Salat usw. Redisson wird offiziell empfohlen.
18. Was sind die Vor- und Nachteile von Jedis und Redisson?
Antwort: Jedis ist ein von Redis in Java implementierter Client, dessen API relativ umfassende Unterstützung für Redis-Befehle bietet. Im Vergleich zu Jedis sind seine Funktionen einfacher und unterstützen keine Zeichenfolgenoperationen unterstützt keine Redis-Funktionen wie Sortieren, Transaktionen, Pipelines und Partitionen.
Der Zweck von Redisson besteht darin, die Trennung der Benutzeranliegen von Redis zu fördern, damit sich Benutzer mehr auf die Verarbeitung der Geschäftslogik konzentrieren können.
19. Wie lege ich ein Passwort fest und verifiziere es in Redis?
Passwort festlegen: config set requirepass 123456
Autorisierungspasswort: auth 123456
20 Sprechen Sie über das Konzept des Redis-Hash-Slots?
Antwort: Der Redis-Cluster verwendet kein konsistentes Hashing, sondern führt das Konzept der Hash-Slots ein. Jeder Schlüssel besteht die CRC16-Prüfung und Modulo 16384, um zu bestimmen, welcher Slot im platziert werden soll Cluster ist für einen Teil der Hash-Slots verantwortlich.

21. Was ist das Master-Slave-Replikationsmodell des Redis-Clusters?
Antwort: Um den Cluster weiterhin verfügbar zu machen, wenn einige Knoten ausfallen oder die meisten Knoten nicht kommunizieren können, verwendet der Cluster ein Master-Slave-Replikationsmodell und jeder Knoten verfügt über N-1-Replikate
22 Redis-Cluster verliert Schreibvorgänge? Warum?
Antwort: Redis garantiert keine starke Datenkonsistenz, was bedeutet, dass der Cluster in der Praxis unter bestimmten Bedingungen Schreibvorgänge verlieren kann.
23. Wie werden Redis-Cluster repliziert?
Antwort: Asynchrone Replikation
24. Was ist die maximale Anzahl von Knoten in einem Redis-Cluster?
Antwort: 16384.
25. Wie wähle ich eine Datenbank für den Redis-Cluster aus?
Antwort: Der Redis-Cluster kann derzeit keine Datenbank auswählen und der Standardwert ist Datenbank 0.
26. Wie teste ich die Konnektivität von Redis?
Antwort: Verwenden Sie den Ping-Befehl.
27. Wie versteht man Redis-Transaktionen?
Antwort:
(1) Eine Transaktion ist eine einzelne isolierte Operation: Alle Befehle in der Transaktion werden serialisiert und der Reihe nach ausgeführt. Während der Ausführung der Transaktion wird diese nicht durch Befehlsanfragen anderer Clients unterbrochen.
(2) Eine Transaktion ist eine atomare Operation: Entweder werden alle Befehle in der Transaktion ausgeführt, oder keiner von ihnen wird ausgeführt.
28. Welche Befehle beziehen sich auf Redis-Transaktionen?
Antwort: MULTI, EXEC, DISCARD, WATCH
29, wie stelle ich die Ablaufzeit bzw. die dauerhafte Gültigkeit des Redis-Schlüssels ein?
Antwort: EXPIRE- und PERSIST-Befehle.
30. Wie führt Redis eine Speicheroptimierung durch?
Antwort: Eine Hash-Tabelle (d. h. die in einer Hash-Tabelle gespeicherte Zahl ist klein) benötigt sehr wenig Speicher, daher sollten Sie Ihr Datenmodell so weit wie möglich in eine Hash-Tabelle abstrahieren. Wenn in Ihrem Websystem beispielsweise ein Benutzerobjekt vorhanden ist, legen Sie keinen separaten Schlüssel für den Namen, den Nachnamen, die E-Mail-Adresse und das Passwort des Benutzers fest. Speichern Sie stattdessen alle Informationen des Benutzers in einer Hash-Tabelle.
31. Wie funktioniert der Redis-Recyclingprozess?
A: Ein Client hat einen neuen Befehl ausgeführt und neue Daten hinzugefügt. Redi prüft die Speichernutzung, wenn sie größer als das maximale Speicherlimit ist, wird sie gemäß der festgelegten Richtlinie recycelt. Ein neuer Befehl wird ausgeführt usw. Wir überschreiten also ständig die Grenze der Speichergrenze, indem wir ständig die Grenze erreichen und dann ständig unter die Grenze zurückkehren. Wenn das Ergebnis eines Befehls dazu führt, dass viel Speicher beansprucht wird (z. B. das Speichern der Schnittmenge einer großen Menge in einem neuen Schlüssel), dauert es nicht lange, bis das Speicherlimit durch diese Speichernutzung überschritten wird.
32. Welche Möglichkeiten gibt es, die Speichernutzung von Redis zu reduzieren?
Antwort: Wenn Sie eine 32-Bit-Redis-Instanz verwenden, können Sie Sammlungstypdaten wie Hash, Liste, sortierter Satz, Satz usw. gut nutzen, da es normalerweise viele kleine Schlüsselwerte geben kann kompakter zusammen gespeichert werden.
33. Was passiert, wenn Redis nicht mehr genügend Speicher hat?
Antwort: Wenn die festgelegte Obergrenze erreicht ist, gibt der Redis-Schreibbefehl eine Fehlermeldung zurück (der Lesebefehl kann jedoch weiterhin normal zurückgegeben werden). Sie können Redis auch als Cache verwenden, um den Konfigurationseliminierungsmechanismus zu verwenden Erreicht die Speicherobergrenze, wird der Inhalt geleert. Entfernen Sie den alten Inhalt.
34. Wie viele Schlüssel kann eine Redis-Instanz maximal speichern? Liste, Menge, sortierte Menge Wie viele Elemente können sie maximal speichern?
A: Theoretisch kann Redis bis zu 232 Schlüssel verarbeiten, und in tatsächlichen Tests speicherte jede Instanz mindestens 250 Millionen Schlüssel. Wir testen einige größere Werte. Jede Liste, Menge und sortierte Menge kann 232 Elemente enthalten. Mit anderen Worten: Das Speicherlimit von Redis ist die Menge an Speicher, die im System verfügbar ist.
35. Es gibt 20 Millionen Daten in MySQL, aber nur 200.000 Daten werden in Redis gespeichert.
Antwort: Wenn die Größe des Redis-Speicherdatensatzes auf eine bestimmte Größe ansteigt, wird die Dateneliminierungsstrategie implementiert.
Verwandtes Wissen: Redis bietet 6 Dateneliminierungsstrategien:
volatile-lru: Wählen Sie die zuletzt verwendeten Daten aus dem Datensatz (server.db[i].expires) mit einer Ablaufzeit aus, um sie zu eliminieren
volatile- ttl: Wählen Sie die abzulaufenden Daten aus dem Datensatz (server.db[i].expires) mit einer festgelegten Ablaufzeit aus und entfernen Sie sie.
volatile-random: Wählen Sie den Datensatz mit einer Ablaufzeit (server.db[i] aus .expires) Wählen Sie beliebige Daten aus dem zu eliminierenden Datensatz aus
allkeys-lru: Wählen Sie die zuletzt verwendeten Daten aus dem zu eliminierenden Datensatz (server.db[i].dict) aus
allkeys-random: Wählen Sie die Daten aus Wählen Sie aus dem Datensatz (server.db[i].dict) willkürlich die Dateneliminierung aus. Keine Enviction (Räumung): Verbieten Sie die Räumung von Daten. Für welches Szenario ist Redis am besten geeignet?
1. SitzungscacheEines der am häufigsten verwendeten Szenarien für die Verwendung von Redis ist der Sitzungscache. Der Vorteil von Caching-Sitzungen mit Redis gegenüber anderen Stores wie Memcached besteht darin, dass Redis Persistenz bietet. Bei der Verwaltung eines Caches, der nicht unbedingt Konsistenz erfordert, wären die meisten Menschen unzufrieden, wenn alle Warenkorbinformationen des Benutzers verloren gehen würden. Wäre das dann immer noch der Fall? Da sich Redis im Laufe der Jahre verbessert hat, ist es glücklicherweise leicht herauszufinden, wie man Redis richtig zum Zwischenspeichern von Sitzungsdokumenten verwendet. Auch die bekannte kommerzielle Plattform Magento stellt ein Plug-in für Redis zur Verfügung.
2. Full Page Cache (FPC)Zusätzlich zu den grundlegenden Sitzungstoken bietet Redis auch eine sehr einfache FPC-Plattform. Zurück zum Konsistenzproblem: Selbst wenn die Redis-Instanz neu gestartet wird, werden Benutzer aufgrund der Festplattenpersistenz keinen Rückgang der Seitenladegeschwindigkeit feststellen. Dies ist eine große Verbesserung, ähnlich wie bei PHP Local FPC. Nehmen wir noch einmal Magento als Beispiel: Magento bietet ein Plugin zur Verwendung von Redis als Full-Page-Cache-Backend. Darüber hinaus verfügt Pantheon für WordPress-Benutzer über ein sehr gutes Plug-in wp-redis, das Ihnen dabei helfen kann, die von Ihnen durchsuchten Seiten so schnell wie möglich zu laden. 3. WarteschlangeEiner der großen Vorteile von Redis im Bereich der Speicher-Engines besteht darin, dass es Listen- und Set-Operationen bereitstellt, wodurch Redis als gute Plattform für Nachrichtenwarteschlangen verwendet werden kann. Die von Redis als Warteschlange verwendeten Operationen ähneln den Push/Pop-Operationen lokaler Programmiersprachen (wie Python) für Listen. Wenn Sie in Google schnell nach „Redis-Warteschlangen“ suchen, werden Sie sofort auf eine große Anzahl von Open-Source-Projekten stoßen. Der Zweck dieser Projekte besteht darin, mit Redis sehr gute Back-End-Tools zu erstellen, um verschiedene Warteschlangenanforderungen zu erfüllen. Celery verfügt beispielsweise über ein Backend, das Redis als Broker verwendet. Sie können es hier anzeigen. 4, Bestenliste/ZählerRedis implementiert den Vorgang des Erhöhens oder Verringerns von Zahlen im Speicher sehr gut. Sets und sortierte Sets machen es uns auch sehr einfach, diese Operationen durchzuführen. Redis stellt lediglich diese beiden Datenstrukturen bereit. Um also die Top-10-Benutzer aus der sortierten Menge zu erhalten – nennen wir sie „user_scores“, müssen wir es einfach so machen: Dies setzt natürlich voraus, dass Sie es basierend auf den Bewertungen Ihrer Benutzer tun. Zunehmende Sortierung. Wenn Sie den Benutzer und die Punktzahl des Benutzers zurückgeben möchten, müssen Sie dies wie folgt ausführen: ZRANGE user_scores 0 10 WITHSCORES Agora Games ist ein gutes Beispiel, das in Ruby implementiert ist und dessen Rankings Redis zum Speichern von Daten verwenden. Dies können Sie hier sehen.
5. Publish/Subscribe
Last (aber sicherlich nicht zuletzt) ist die Publish/Subscribe-Funktion von Redis. Es gibt tatsächlich viele Anwendungsfälle für Publish/Subscribe. Ich habe gesehen, wie Leute es in sozialen Netzwerkverbindungen, als Auslöser für Veröffentlichungs-/Abonnement-basierte Skripte und sogar zum Aufbau von Chat-Systemen mithilfe der Veröffentlichungs-/Abonnementfunktion von Redis verwenden!

37 Wenn es 100 Millionen Schlüssel in Redis gibt und 100.000 davon mit einem festen, bekannten Präfix beginnen, was wäre, wenn Sie sie alle finden würden?
Antwort: Verwenden Sie den Befehl „keys“, um die Schlüsselliste des angegebenen Modus zu scannen.
Die andere Partei fragte dann: Wenn dieser Redis Dienste für Online-Unternehmen bereitstellt, welche Probleme gibt es bei der Verwendung des Tastenbefehls?
Zu diesem Zeitpunkt müssen Sie eine wichtige Funktion von Redis beantworten: Redis ist Single-Threaded. Die Schlüsselanweisung führt dazu, dass der Thread für einen bestimmten Zeitraum blockiert wird und der Onlinedienst angehalten wird. Der Dienst kann erst wiederhergestellt werden, wenn die Anweisung ausgeführt wird. Zu diesem Zeitpunkt können Sie den Scan-Befehl verwenden, um die Schlüsselliste des angegebenen Modus zu extrahieren, es besteht jedoch eine gewisse Wahrscheinlichkeit einer Duplizierung. Führen Sie dies jedoch nur einmal auf dem Client aus, dies wird jedoch insgesamt der Fall sein länger sein als die direkte Verwendung von Tastenbefehlen.
38. Wenn es eine große Anzahl von Schlüsseln gibt, die gleichzeitig ablaufen sollen, worauf sollten Sie generell achten?
Antwort: Wenn die Ablaufzeit einer großen Anzahl von Schlüsseln zu konzentriert eingestellt ist, kann es bei Redis zum Zeitpunkt des Ablaufs zu einer kurzen Verzögerung kommen. Im Allgemeinen muss der Zeit ein Zufallswert hinzugefügt werden, um die Ablaufzeit zu verteilen.
39. Haben Sie Redis jemals als asynchrone Warteschlange verwendet?
Antwort: Im Allgemeinen wird die Listenstruktur als Warteschlange verwendet, rpush erzeugt Nachrichten und lpop verbraucht Nachrichten. Wenn keine Nachricht von lpop eingeht, schlafen Sie eine Weile und versuchen Sie es erneut. Was ist, wenn die andere Partei fragt, ob Schlaf genutzt werden kann? Es gibt auch einen Befehl namens blpop in list. Wenn keine Nachricht vorhanden ist, wird er blockiert, bis die Nachricht eintrifft. Was ist, wenn die andere Partei fragt, ob es einmal produziert und mehrmals konsumiert werden kann? Mithilfe des Pub/Sub-Topic-Abonnentenmodells kann eine 1:N-Nachrichtenwarteschlange implementiert werden.
Wenn die andere Partei fragt, was sind die Nachteile von Pub/Sub?
Wenn der Verbraucher offline geht, gehen die produzierten Nachrichten verloren, sodass Sie eine professionelle Nachrichtenwarteschlange wie RabbitMQ verwenden müssen.
Wenn die andere Partei fragt, wie Redis die Verzögerungswarteschlange implementiert?
Ich schätze, jetzt willst du den Interviewer totprügeln, wenn du einen Baseballschläger in der Hand hast, warum stellst du dann so detaillierte Fragen? Aber Sie waren sehr zurückhaltend und antworteten dann ruhig: Verwenden Sie sortedset, verwenden Sie den Zeitstempel als Bewertung, den Nachrichteninhalt als Schlüssel, rufen Sie zadd auf, um die Nachricht zu erstellen, und der Verbraucher verwendet die Anweisung zrangebyscore, um die Daten abzurufen, die vor N Sekunden abgefragt wurden zur Bearbeitung. An dieser Stelle hat Ihnen der Interviewer heimlich einen Daumen nach oben gegeben. Aber was er nicht wusste war, dass du in diesem Moment hinter dem Stuhl deinen Mittelfinger hobst.
40. Haben Sie jemals eine verteilte Redis-Sperre verwendet?
Verwenden Sie zuerst setnx, um die Sperre zu ergreifen. Nachdem Sie sie ergriffen haben, fügen Sie der Sperre mit „expire“ eine Ablaufzeit hinzu, um zu verhindern, dass die Sperre vergisst, sie freizugeben.
Zu diesem Zeitpunkt wird Ihnen die andere Partei mitteilen, dass Ihre Antwort gut ist, und dann fragen, was passiert, wenn der Prozess unerwartet abstürzt oder aus Wartungsgründen neu gestartet werden muss, bevor er „expire after setnx“ ausführt? Zu diesem Zeitpunkt müssen Sie eine überraschende Rückmeldung geben: Oh ja, diese Sperre wird niemals aufgehoben. Dann müssen Sie sich am Kopf kratzen, einen Moment so tun, als ob das nächste Ergebnis Ihre eigene Initiative wäre, und dann antworten: Ich erinnere mich, dass der Befehl set sehr komplexe Parameter hat. Dies sollte in der Lage sein, setnx festzulegen und abzulaufen gleichzeitig zu einer Gebrauchsanweisung zusammengefasst! Zu diesem Zeitpunkt wird die andere Partei lächeln und leise in seinem Herzen sagen: Presse, dieser Typ ist nicht schlecht.
Die relevanten Wissenspunkte werden in einer Mindmap zusammengefasst
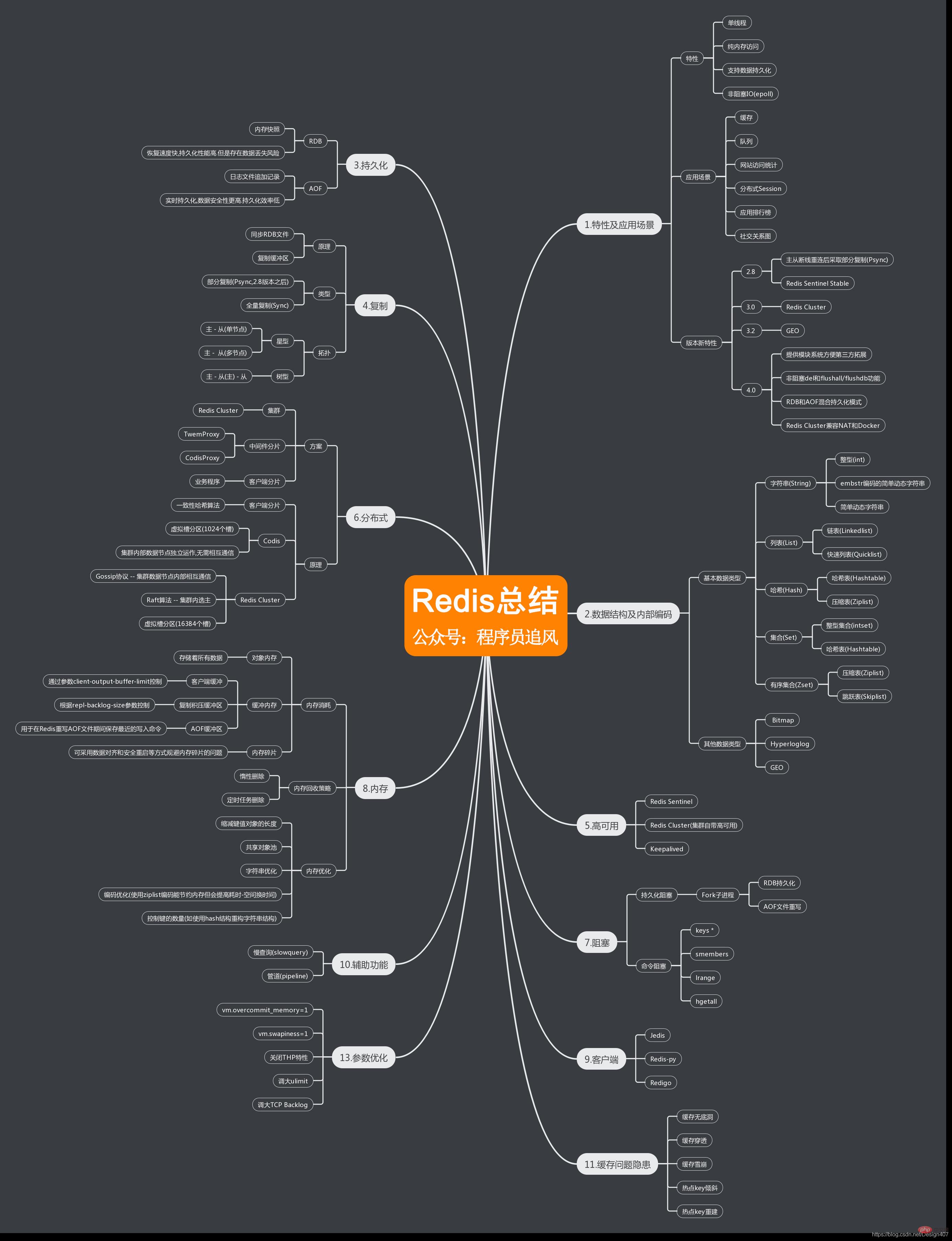
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Einführung in die Programmierung! !
Das obige ist der detaillierte Inhalt von40 Redis-Interviewfragen, die Sie nicht verpassen dürfen (einschließlich Antworten und Mindmaps). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Lösen Sie das Problem des überverkauften Redis-Bestands
- Einführung in die Bereitstellung des Redis-Clusters auf K8s
- Einführung der Redis-Leistungsüberwachung
- Detaillierte Erläuterung des Redis-Mechanismus für hohe Verfügbarkeit und hohe Parallelität
- 21 Punkte, auf die Sie bei der Verwendung von Redis achten müssen (Zusammenfassung)