
Werfen wir einen Blick auf die Redis-Clusterarchitektur und den Vergleich

- coldplay.xixinach vorne
- 2021-03-12 11:17:052194Durchsuche

1、Redis3.0
· Vorteile
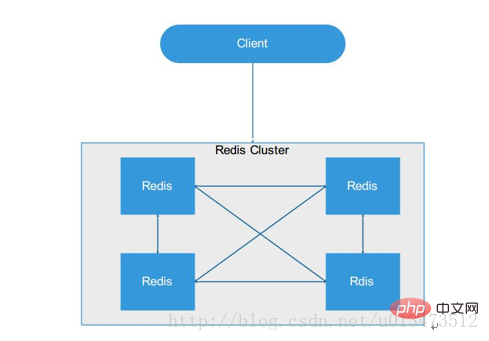
aKein zentraler Knoten
b.Daten werden auf mehreren Redis Instanzen gespeichert und entsprechend Slot c erweitert
/schrumpfende Knoten d Automatisches Failover(
Knoten tauschen Statusinformationen über das Gossip -Protokoll aus, Abstimmungsmechanismus ist abgeschlossen Slave zu Master Rollenförderung ) e. Reduziert den Betriebs- und Wartungsaufwand Kosten, verbessert die Skalierbarkeit des Systems und die hohe Verfügbarkeit
(empfohlen (kostenlos): redis
undPipeline Unterstützung )
d. Failover Knotenerkennung ist zu langsam, nicht so gut wie "
ZentralknotenZooKeep er"zeitnah
e. Klatsch Der Overhead von Nachrichtenf. Es ist nicht möglich, heiße und kalte Daten anhand von Statistiken zu unterscheiden 2、Proxy +Redis-Cluster
·Vorteile Smart Client:
a. Vergleichen Aufgrund der Verwendung von Proxys reduziert den Verbrauch einer Netzwerkübertragungsschicht und ist effizienter.
Proxy:
a stellt eine Reihe von HTTP Restful -Schnittstellen zur Isolierung des zugrunde liegenden Speichers bereit. Völlig transparent für den Kunden, sprachübergreifende Anrufe.
b. Upgrade und Wartung sind relativ einfach. Um Redis-Cluster zu warten, müssen Sie nur Proxy reibungslos aktualisieren.
c. Hierarchischer Speicher, der zugrunde liegende Speicher ist heißer und kalter heterogener Speicher.
d. Berechtigungskontrolle, Proxy kann die Whitelist über den geheimen Schlüssel steuern, um einige illegale Anfragen herauszufiltern. Und Sie können auch den vom Benutzer angeforderten supergroßen Wert steuern und filtern.
e. Sicherheit, Sie können einige gefährliche Befehle blockieren, wie z. f. Kapazitätskontrolle, Kapazitätsbegrenzung basierend auf verschiedenen Benutzerkapazitätsanwendungen. g. Logische Ressourcenisolation, basierend auf dem
Schlüsselplus Präfixen zum Isolieren von Ressourcen.
h.Überwachen Sie versteckte Punkte, überwachen Sie versteckte Punkte und andere Informationen für verschiedene Schnittstellen. · Nachteile
Smart Client
:a Die Unreife des Clients beeinträchtigt die Stabilität der Anwendung und erhöht die Schwierigkeit der Entwicklung.
b. MultiOp und
Pipelinehaben begrenzte Unterstützung.
c.Verbindungswartung, Intelligente Client-Wartung von Socket
, der mit jedem Knoten im Cluster verbunden ist.Proxy: a Die Proxy-Schicht hat eine weitere Weiterleitung, was zu einem gewissen Leistungsverlust führt.
b. Erweiterung
/Beim Verkleinern sind die Betriebs- und Wartungsanforderungen hoch und es ist schwierig, eine reibungslose Erweiterung und Kontraktion zu erreichen Die Redis-Cli-Cluster-Unterstützung ist sehr einfach und nutzt daher immer die Tatsache, dass Redis-Cluster-Knoten einen Client zum richtigen Knoten umleiten können. Ein seriöser Client ist in der Lage, dies zu verbessern und die Zuordnung zwischen Hash-Slots und Knotenadressen zwischenzuspeichern. Um die richtige Verbindung zum richtigen Knoten direkt zu verwenden, wird die Karte nur aktualisiert, wenn sich etwas in der Clusterkonfiguration ändert, beispielsweise nach einem Failover oder nachdem der Systemadministrator das Clusterlayout durch Hinzufügen oder Entfernen von Knoten geändert hat.
Die allgemeine Idee ist dass der aktuelle offizielleredis-Cluster-Client über einfache Funktionen verfügt und auf redisKnotenumleitung angewiesen ist, um die
redis-Instanz im Cluster zu finden, in dem sich die Daten befinden. Es besteht Bedarf an einem umfassenderen Client, der konsistente Hash-,
Failover- und Clusterverwaltungsfunktionen erreichen kann. Daher ist die Verwendung des offiziellen redis-Clusters keine kluge Wahl. Dieser Artikel bietet
3Lösungen als Referenz. Wenn es etwas Unangemessenes gibt, können Sie es gerne mit mir besprechen.
Schema 1 Entwickelt mit nginx(OpenResty Weg)
Die Gründe sind wie folgt:
a.SingleMaster Mehrere Work Modi, jeder Work ist der gleiche Einzelprozess-Single-Thread-Modus wie Redis und beide basieren auf dem Epoll ereignisgesteuerten Modus.
b. Nginxverwendet eine asynchrone und nicht blockierende Methode zur Verarbeitung von Anforderungen, ein effizientes asynchrones Framework.
c.Geringe Speichernutzung und verfügt über eigene Methoden zur Speicherpoolverwaltung. Das Zusammenfassen einer großen Anzahl kleiner Speicheranwendungen kann schneller sein als Malloc. Reduzieren Sie die Speicherfragmentierung und verhindern Sie Speicherlecks. Reduzieren Sie die Komplexität der Speicherverwaltung.
d.Um die Zugriffsgeschwindigkeit von Nginx zu verbessern, verwendet Nginx einen eigenen Satz von Verbindungspools.
eDas Wichtigste ist, die Entwicklung kundenspezifischer Module zu unterstützen.
fIn der Branche können Nginx und Redis als zwei großartige Artefakte angesehen werden. Die Leistung ist sehr gut.
Lösung 2 Codis (Agentenbasierte RedisClusterlösung übernommen von Wandoujia)
Referenzcodis offizielles Dokument https://github . com/CodisLabs/codis
Codisist ein kompletter Satz von Caching-Lösungen, einschließlich Hochverfügbarkeit, Daten-Sharding, Überwachung, dynamischer Erweiterung usw..
verwendetApps->Agent->rediscluster Diese Methode wird grundsätzlich ab einem bestimmten Umfang übernommen.
Schema3 Unabhängig entwickeltes RedisSmart Client
Implementiert hauptsächlichRedis-SlotsManagement, f Aailover , Konsistenz Hash Funktion.
4, Redis 3.0ClusterDer Redis 3.0-Cluster übernimmt das P2P-Modell und ist vollständig dezentralisiert. „Redis“ unterteilt alle Key in 16384 einen Slot, und jede Redis-Instanz ist für einen Teil von Slot verantwortlich . Alle Informationen (Knoten, Ports, Slot usw.) im Cluster werden durch regelmäßigen Datenaustausch zwischen Knoten aktualisiert. Redis Redis-Instanz. Wenn die erforderlichen Daten nicht in der Instanz vorhanden sind, verwenden Sie einen Umleitungsbefehl, um den Client zum Zugriff auf die erforderliche Instanz zu leiten. Redis 3.0
( )RedisDer Client ist in. Auf der Redis2-Instanz Greifen Sie auf bestimmte Daten zu; ( ) gefunden in Redis2, dass diese Daten in Redis3 gefunden wurden. Senden Sie in diesem Fall einen Neuladevorgang an Redis Client-gesteuerter Befehl; ( ) RedisNach Erhalt des umgeleiteten Befehls greift der Client auf die Redis3-Instanz zu, um die erforderlichen Daten abzurufen. Die Clusterlösung von Redis 3.0 1) Redis Instanz verfügt über "Datenspeicher" und “ Route Redirect“, vollständig dezentrales Design. Dies hat den Vorteil, dass die Bereitstellung sehr einfach ist. Stellen Sie Redis einfach direkt bereit, im Gegensatz zu Codis, das so viele Komponenten und Abhängigkeiten hat. Das Problem besteht jedoch darin, dass es schwierig ist, das Unternehmen schmerzlos zu aktualisieren. Wenn eines Tages ein schwerwiegender Fehler im Redis-Cluster auftritt, können wir nur den gesamten Redis-Cluster zurücksetzen. 2) hat große Änderungen am Protokoll vorgenommen und der entsprechende Redis-Client muss ebenfalls aktualisiert werden. Wer kann sicherstellen, dass es nach dem Upgrade des Redis-Clients keine Bugs Redis-Clients im Code ebenfalls eine sehr mühsame Sache. 5, Redis4.0 (1)Alle redisKnoten sind miteinander verbunden. andere(PING-PONG Mechanismus) , Binärprotokolle werden intern verwendet, um Übertragungsgeschwindigkeit und Bandbreite zu optimieren; (2)AusfallAusfall eines Knotens wird nur wirksam, wenn mehr als die Hälfte der Knoten im Cluster einen Ausfall erkennen; Kunde Das Terminal ist direkt mit dem redis-Knoten verbunden, ohne dass eine Zwischenschicht Proxy erforderlich ist. Der Client muss sich nicht mit allen Knoten im Cluster verbinden, sondern einfach mit jedem verfügbaren Knoten im Cluster. insert Slot , cluster ist für die Aufrechterhaltung des node<->slot<->value verantwortlich. 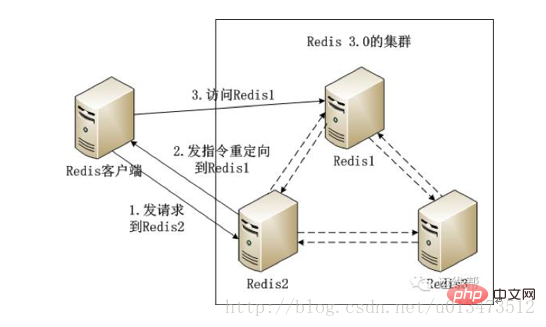 Redis
Redis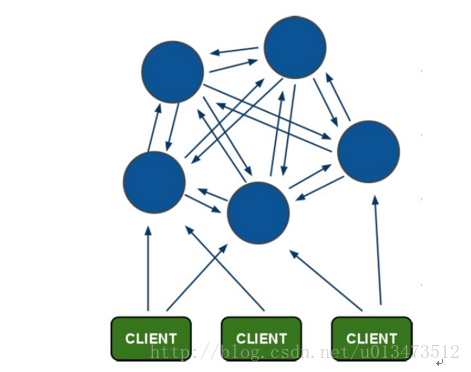
Das obige ist der detaillierte Inhalt vonWerfen wir einen Blick auf die Redis-Clusterarchitektur und den Vergleich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!