
Redis erklärt das Prinzip der verteilten Datenbank-CAP

- coldplay.xixinach vorne
- 2021-02-09 17:49:343051Durchsuche

Empfohlen (kostenlos): redis
Was sind die traditionellen ACIDs? A (Atomizität) Atomizität, C (Konsistenz) Konsistenz und I (Isolation) Unabhängigkeit
D (Haltbarkeit) Persistenz Die relationale Datenbank folgt den ACID-Regeln und ist den Transaktionen in der realen Welt sehr ähnlich zu sagen:
Alle Vorgänge in einer Transaktion sind entweder abgeschlossen oder nicht. Die Bedingung für den Erfolg einer Transaktion ist, dass alle Vorgänge in der Transaktion fehlschlagen . Beispielsweise ist eine Banküberweisung zur Überweisung von 100 Yuan von Konto A auf Konto B in zwei Schritte unterteilt: 1) 100 Yuan von Konto A abheben 2) 100 Yuan auf Konto B einzahlen; Diese beiden Schritte werden entweder zusammen abgeschlossen oder nicht zusammen abgeschlossen. Wenn nur der erste Schritt abgeschlossen wird und der zweite Schritt fehlschlägt, wird das Geld ohne Angabe von Gründen um 100 Yuan geringer ausfallen.
2. C (Konsistenz) Konsistenz
Konsistenz ist auch relativ einfach zu verstehen, was bedeutet, dass die Datenbank immer in einem konsistenten Zustand sein muss und
der Vorgang der Transaktion die ursprünglichen Konsistenzbeschränkungen nicht ändert der Datenbank.
3. I (Isolation) UnabhängigkeitDie sogenannte Unabhängigkeit bedeutet, dass sich gleichzeitige Transaktionen nicht gegenseitig beeinflussen
Wenn die Daten, auf die eine Transaktion zugreifen soll, von einer anderen Transaktion geändert werden Transaktion Wenn eine Transaktion nicht festgeschrieben ist, werden die Daten, auf die sie zugreift, von der nicht festgeschriebenen Transaktion nicht beeinflusst. Beispielsweise gibt es eine Transaktion, bei der 100 Yuan von Konto A auf Konto B überwiesen werden. Wenn die Transaktion noch nicht abgeschlossen ist und B zu diesem Zeitpunkt sein Konto überprüft, werden ihm die neu hinzugefügten 100 Yuan nicht angezeigt4 , D (Dauerhaftigkeit) Haltbarkeit
Dauerhaftigkeit bedeutet, dass nach der Übermittlung einer Transaktion die von ihr vorgenommenen Änderungen dauerhaft in der Datenbank gespeichert werden und auch bei einer Ausfallzeit nicht verloren gehen.
CAP
C: Konsistenz (starke Konsistenz)A: Verfügbarkeit (Verfügbarkeit) P: Partitionstoleranz (Partitionstoleranz) oder verteilte Toleranz
CAP-Theorie bedeutet, dass es in einem verteilten Speichersystem höchstens möglich ist nur die beiden oben genannten Punkte erreichen.Starke Konsistenz: Beispielsweise ist das, was in den Daten steht, das, was es ist. Alle Datensicherungen im verteilten System haben gleichzeitig den gleichen Wert. (Entspricht dem Zugriff aller Knoten auf dieselbe neueste Datenkopie)
Verfügbarkeit: Beispielsweise ist es unmöglich, Taobao Double Eleven nicht zu verwenden.Kann der gesamte Cluster noch auf die Lese- und Schreibanforderungen des Clients reagieren, nachdem einige Knoten im Cluster ausgefallen sind? (Hohe Verfügbarkeit für Datenaktualisierungen) Partitionsfehlertoleranz: In der Praxis entspricht die Partitionierung der zeitlichen Begrenzung der Kommunikation.
Wenn das System die Datenkonsistenz nicht innerhalb des Zeitlimits erreichen kann, bedeutet dies, dass eine Partitionierung aufgetreten ist und für den aktuellen Vorgang eine Auswahl zwischen C und A getroffen werden muss. Zum Beispiel: Taobao-Taschen
Für eine starke Konsistenz setzen wir voraus, dass die Anzahl der Likes für diese Tasche 141 beträgt, was nicht falsch sein darf. Eine genaue Anleitung ist erforderlich, aber in Zeiten hoher Parallelität ist es schwierig, die Dateneinheitlichkeit sicherzustellen.
Für hohe Verfügbarkeit: Es kann eine schwache Konsistenz geben, z. B. das Zulassen von Fehlern bei der Anzahl der Likes und Ansichten, aber es kann nicht zu einer Lähmung der Website führen. Daher verwenden die meisten Website-Architekturen AP. Schwache Konsistenz + hohe Verfügbarkeit
Für Nosql muss Partitionstoleranz erreicht werden Das verteilte System befindet sich möglicherweise nicht in derselben Stadt, z. B. Taobao, aber die Inhaltsverteilung ist Ihnen am nächsten. Taobao-Server können Server in Hangzhou, Shanghai und Suzhou haben.
Da die aktuelle Netzwerkhardware definitiv Probleme wie Verzögerungen und Paketverluste aufweisen wird, müssen wir Partitionstoleranz erreichen. Daher können wir nur einen Kompromiss zwischen Konsistenz und Verfügbarkeit eingehen. Kein NoSQL-System kann diese drei Punkte gleichzeitig garantieren.
CA Traditionelle Oracle-Datenbank AP-Auswahl der meisten Website-Architekturen CP Redis, Mongodb
Hinweis: Bei verteilter Architektur müssen Kompromisse eingegangen werden.
Schaffe ein Gleichgewicht zwischen Konsistenz und Benutzerfreundlichkeit. Die meisten Webanwendungen erfordern eigentlich keine starke Konsistenz. Daher ist der Verzicht auf C für P die aktuelle Richtung verteilter Datenbankprodukte.
Die Wahl zwischen Konsistenz und Verfügbarkeit
Für Web2.0-Websites sind viele der Hauptfunktionen relationaler Datenbanken oft nutzlos
Anforderungen an die Konsistenz von Datenbanktransaktionen
Viele Web-Echtzeitsysteme erfordern keine strengen Datenbanktransaktionen, die Anforderungen Die Anforderungen an die Lesekonsistenz sind sehr niedrig und in einigen Fällen sind die Anforderungen an die Schreibkonsistenz nicht hoch. Ermöglicht letztendliche Konsistenz.
Die Echtzeit-Schreib- und Leseanforderungen der Datenbank
Wenn Sie bei relationalen Datenbanken ein Datenelement einfügen und es sofort abfragen, können Sie die Daten definitiv lesen, aber für viele Webanwendungen sind die Anforderungen nicht so hoch Beispielsweise ist es völlig akzeptabel, dass meine Abonnenten nach dem Posten einer Nachricht auf Weibo die Nachrichten erst nach ein paar Sekunden oder sogar nach mehr als zehn Sekunden sehen.
Nachfrage nach komplexen SQL-Abfragen, insbesondere nach Abfragen für mehrere Tabellen
In jedem Websystem mit einer großen Datenmenge sind verwandte Abfragen mehrerer großer Tabellen sowie komplexe Berichtsabfragen vom Typ Datenanalyse, insbesondere SNS, sehr tabu der Website vermeidet diese Situation aus Sicht der Nachfrage und des Produktdesigns. Oft gibt es nur Primärschlüsselabfragen einer einzelnen Tabelle und einfache bedingte Paging-Abfragen einer einzelnen Tabelle. Die Funktion von SQL ist stark geschwächt.
Klassisches CAP-Diagramm
Der Kern der CAP-Theorie ist: Ein verteiltes System kann die drei Anforderungen Konsistenz, Verfügbarkeit und Partitionsfehlertoleranz nicht gleichzeitig erfüllen. Es kann nur zwei davon gleichzeitig gut erfüllen . .
Daher werden NoSQL-Datenbanken gemäß dem CAP-Prinzip in drei Kategorien unterteilt: Erfüllung des CA-Prinzips, Erfüllung des CP-Prinzips und Erfüllung des AP-Prinzips:
CA – Single-Point-Cluster, ein System, das Konsistenz und Verfügbarkeit erfüllt, Hat normalerweise eine schlechte Skalierbarkeit. Zu leistungsfähig.
CP – Ein System, das Konsistenz erfüllt und Partitionen tolerieren muss, aber in der Regel keine besonders hohe Leistung aufweist.
AP – Ein System, das Verfügbarkeit und Partitionstoleranz erfüllt und im Allgemeinen geringere Konsistenzanforderungen haben kann. 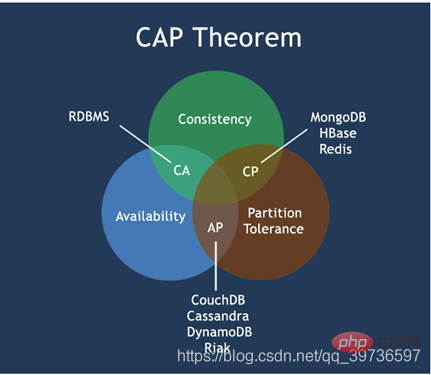
BASE
BASE ist eine vorgeschlagene Lösung, um das Problem der verringerten Verfügbarkeit zu lösen, das durch die starke Konsistenz relationaler Datenbanken verursacht wird.
BASE ist eigentlich die Abkürzung der folgenden drei Begriffe:
Basically Available
Soft State
Eventually Consistent
Seine Idee besteht darin, den Bedarf des Systems an Datenkonsistenz zu einem bestimmten Zeitpunkt zu lockern und im Gegenzug eine Verbesserung der allgemeinen Skalierbarkeit und Leistung zu erreichen des Systems. Warum sagen wir das? Der Grund dafür ist, dass große Systeme aufgrund der geografischen Verteilung und der extrem hohen Leistungsanforderungen häufig keine verteilten Transaktionen verwenden können. Um diese Indikatoren zu erhalten, müssen wir sie auf andere Weise vervollständigen Die Lösung für dieses Problem
Einführung in verteilt + Cluster
Verteiltes System (verteiltes System)
besteht aus mehreren Computern und Kommunikationssoftwarekomponenten, die über ein Computernetzwerk (lokales Netzwerk oder Weitverkehrsnetzwerk) verbunden sind. Verteilte Systeme sind auf dem Netzwerk aufgebaute Softwaresysteme. Gerade aufgrund der Eigenschaften von Software weisen verteilte Systeme ein hohes Maß an Zusammenhalt und Transparenz auf. Daher liegt der Unterschied zwischen Netzwerken und verteilten Systemen eher in der High-Level-Software (insbesondere dem Betriebssystem) als in der Hardware. Verteilte Systeme können auf verschiedenen Plattformen wie PCs, Workstations, LANs und WANs usw. eingesetzt werden.
Vereinfacht ausgedrückt:
Verteilt: Verschiedene Servicemodule (Projekte) werden auf mehreren Servern bereitgestellt. Sie kommunizieren und rufen über RPC/RMI auf, um externe Dienste bereitzustellen und innerhalb der Gruppe zusammenzuarbeiten.
Cluster: Das gleiche Servicemodul wird auf mehreren verschiedenen Servern bereitgestellt und eine einheitliche Planung wird durch verteilte Planungssoftware durchgeführt, um externe Dienste und Zugriff bereitzustellen.
Das obige ist der detaillierte Inhalt vonRedis erklärt das Prinzip der verteilten Datenbank-CAP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine Anleitung zur Verwendung von Redis mit Lumen
- So öffnen Sie den Redis-Port unter Linux
- Welche Möglichkeiten gibt es, Redis zu starten?
- Einführung in Redis-Lernen und die vier Hauptklassifizierungen von NoSQL-Datenbanken
- Verwenden Sie die Redis-Datenbank, um Benutzerinformationen zu speichern
- Eingehende Analyse von Redis