
Ausführung einer SQL-Anweisung

- coldplay.xixinach vorne
- 2021-02-17 10:32:062479Durchsuche

Empfohlen (kostenlos): SQL
Zero, Datenbanktreiber
- MySQL-Treiber hilft uns, eine Verbindung zur Datenbank auf der untersten Ebene herzustellen. Erst nachdem die Verbindung hergestellt wurde, können wir die folgende Interaktion.
1. Datenbankverbindungspool
- Zu den Datenbankverbindungspools gehören Druid, C3P0, DBCP
- Die Verwendung von Verbindungspools erspart den Aufwand für das ständige Erstellen und Zerstören von Threads erheblich. Dies ist die berühmte „Pooling“-Idee Unabhängig davon, ob es sich um einen Thread-Pool oder einen HTTP-Verbindungspool handelt, können Sie dessen Vorhandensein sehen SQL-Schnittstelle zur Verarbeitung.
3. Der Abfrageparser
- analysiert die von der SQL-Schnittstelle übergebene SQL-Anweisung und übersetzt sie in eine Sprache, die MySQL verstehen kann.
4. MySQL-Abfrageoptimierer
- MySQL wählt den entsprechenden Index basierend auf dem Minimalkostenprinzip
IO-Kosten
: das heißt, das Laden von Daten von der Festplatte Die Speicherkosten betragen standardmäßig 1. MySQL liest Daten in Form von Seiten. Das heißt, wenn bestimmte Daten verwendet werden, werden diese Daten nicht nur gelesen Lesen Sie auch in den Speicher neben den Daten. Dies ist das berühmte Prinzip der Programmlokalität, sodass MySQL jedes Mal eine ganze Seite liest und die Kosten für eine Seite 1 betragen. Daher hängen die IO-Kosten hauptsächlich mit der Größe der Seite zusammen.- CPU-Kosten: Nach dem Einlesen der Daten in den Speicher muss auch festgestellt werden, ob die Daten die Bedingungen erfüllen, sowie die Kosten für Sortierung und andere CPU-Vorgänge Offensichtlich hängt es von der Anzahl der Zeilen ab. Standardmäßig betragen die Kosten für die Erkennung von Datensätzen 0,2.
- Der MySQL-Optimierer berechnet den Index mit den geringsten Kosten von „IO-Kosten + CPU“ für die Ausführung
- 5. Speicher-Engine
- Der Abfrageoptimierer ruft die Speicher-Engine-Schnittstelle auf, um SQL auszuführen, was bedeutet, dass Es ist wirklich Die Aktion der SQL-Ausführung ist in der Speicher-Engine abgeschlossen
- .
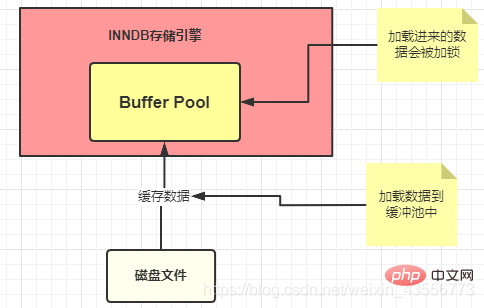
Jedes Mal, wenn SQL ausgeführt wird, werden die Daten in den Speicher geladen: Pufferpool
- 6. Executor
- Der Executor ruft schließlich die Speicher-Engine-Schnittstelle gemäß einer Reihe von Ausführungsplänen auf, um die Ausführung von SQL abzuschließen. 7. Pufferpool: Pufferpool (Pufferpool) ist eine sehr wichtige Speicherstruktur in der Die InnoDB-Speicher-Engine fungiert als Cache. Pufferpool bedeutet, dass wir die Abfrageergebnisse im Pufferpool speichern, sodass später Anfragen vorliegen Wenn nicht, werden sie auf der Festplatte gesucht und dann im Pufferpool abgelegt. Die im Pufferpool verwendeten Daten werden gesperrt.
8. Drei Protokolldateien
: Das Erscheinungsbild der Daten aufzeichnen, bevor sie geändert werden 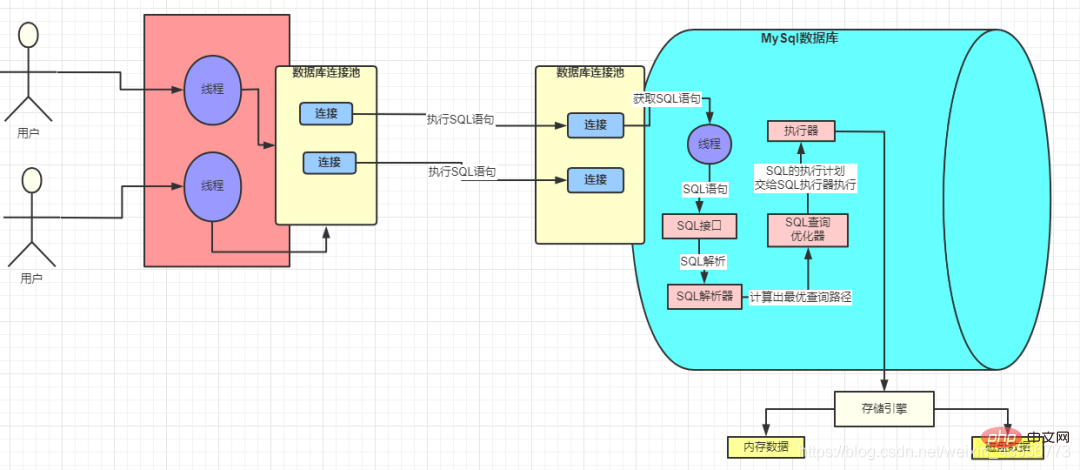
Funktion: Protokolldateien rückgängig machen, um das Transaktions-Rollback abzuschließen
- 2. Redo-Protokolldatei : Zeichnet die geänderten Daten auf
-
 Redo zeichnet den Wert nach der Datenänderung auf. Unabhängig davon, ob die Transaktion übermittelt wird oder nicht, wird sie aufgezeichnet
Redo zeichnet den Wert nach der Datenänderung auf. Unabhängig davon, ob die Transaktion übermittelt wird oder nicht, wird sie aufgezeichnet
3. Bin-Protokolldatei: Zeichnen Sie den gesamten Vorgang auf
Eigenschaften: Redo-Log log kann übergeben werden. Der Konfigurationsparameter max_bin log_size legt die Größe jeder bin log-Datei fest (es wird jedoch im Allgemeinen nicht empfohlen, sie zu ändern). |
Implementierungsmethode | |
|---|---|---|
| bin-Protokoll wird durch Anhängen aufgezeichnet. Wenn die Dateigröße größer als der angegebene Wert ist, werden nachfolgende Protokolle in neuen Dateien aufgezeichnet. | Nutzungsszenarien. max_bin log_size设置每个bin log文件的大小(但是一般不建议修改)。 |
|
| 实现方式 |
redo log是InnoDB引擎层实现的(也就是说是 Innodb 存储引起过独有的) |
bin log是 MySQL 层实现的,所有引擎都可以使用 bin log日志 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | bin log 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 使用场景 |
redo log适用于崩溃恢复(crash-safe)(这一点其实非常类似与 Redis 的持久化特征) |
bin log |
Das obige ist der detaillierte Inhalt vonAusführung einer SQL-Anweisung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:csdn.net. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen
Vorheriger Artikel:Einführung in die Datenbank-SQL-AnsichtNächster Artikel:Einführung in die Datenbank-SQL-Ansicht