
Detaillierte Analyse der Datenstruktur und Datenoperationen von Redis

- coldplay.xixinach vorne
- 2021-02-08 16:20:072316Durchsuche

Empfohlen (kostenlos): redis
Redis kann Datenoperationen auf Mikrosekundenebene durchführen. Es gibt zwei Hauptgründe, warum Redis eine so herausragende Leistung erzielen kann:
- Redis ist eine In-Memory-Datenbank. Alle Vorgänge werden im Speicher ausgeführt und die Speicherzugriffsgeschwindigkeit selbst ist sehr hoch.
- Redis verfügt über effiziente Datentypen und Datenstrukturen.

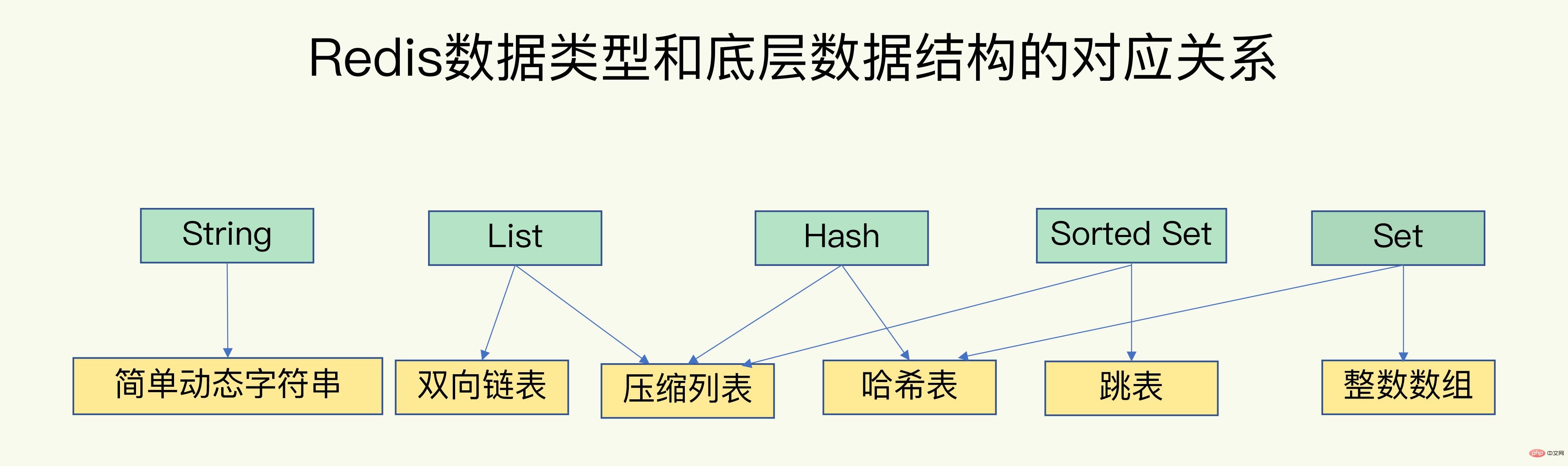
Um einen schnellen Zugriff vom Schlüssel auf den Wert zu erreichen, verwendet Redis eine Hash-Tabelle zum Speichern von Schlüssel-Wert-Paaren. Der Eintrag im Hash-Bucket speichert Zeiger auf den tatsächlichen Schlüssel und Wert. Der Wertzeiger kann auch verwendet werden Gefunden. 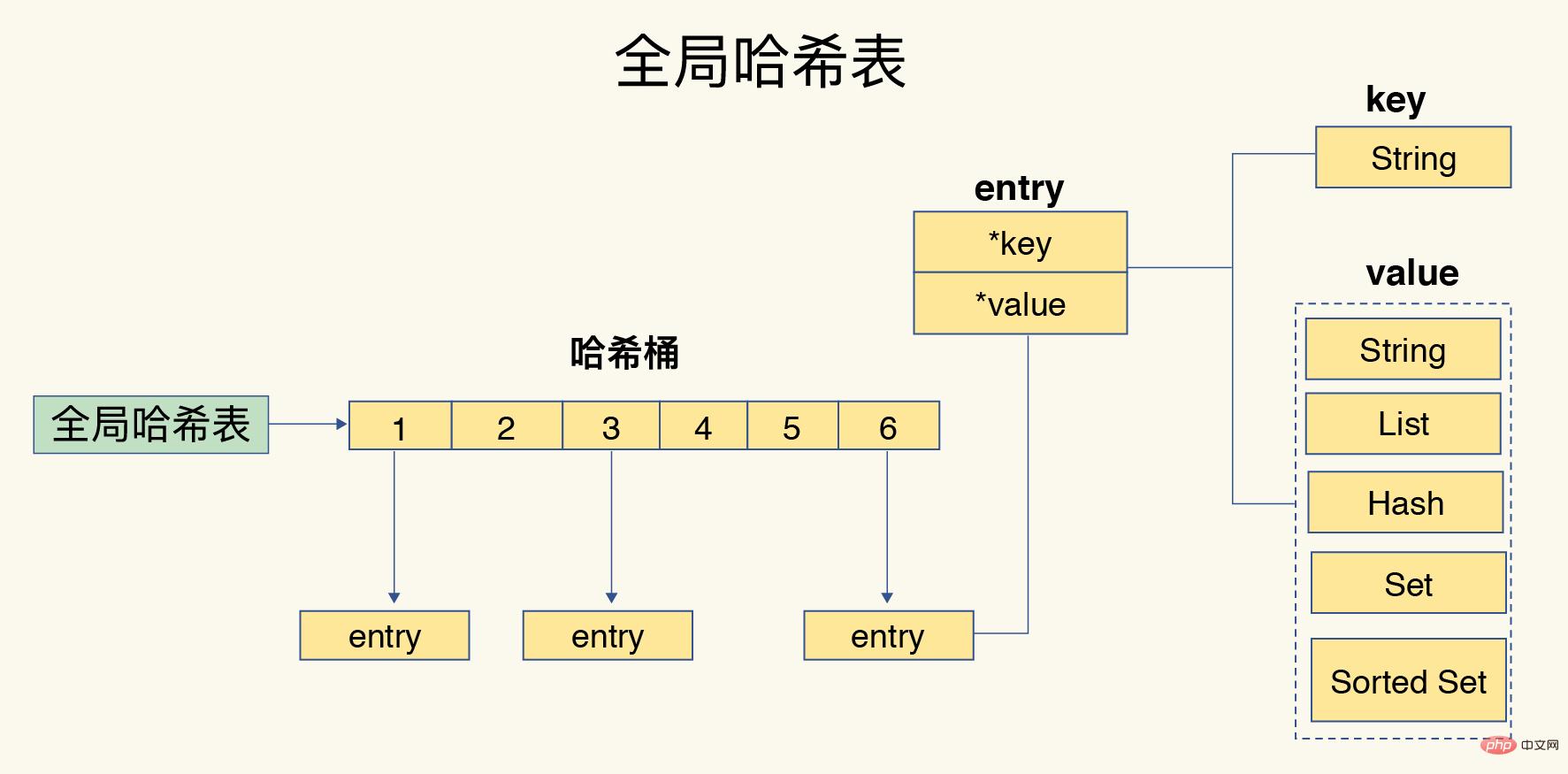
Wenn die Hash-Tabelle immer mehr Daten enthält, kommt es zu Hash-Konflikten, dh die Hash-Werte mehrerer Schlüssel können demselben Hash-Bucket entsprechen. Redis verwendet verkettetes Hashing, um Hash-Konflikte zu lösen. Dies bedeutet, dass mehrere Elemente im selben Hash-Bucket in einer verknüpften Liste gespeichert werden und die Elemente nacheinander durch Zeiger verknüpft werden. 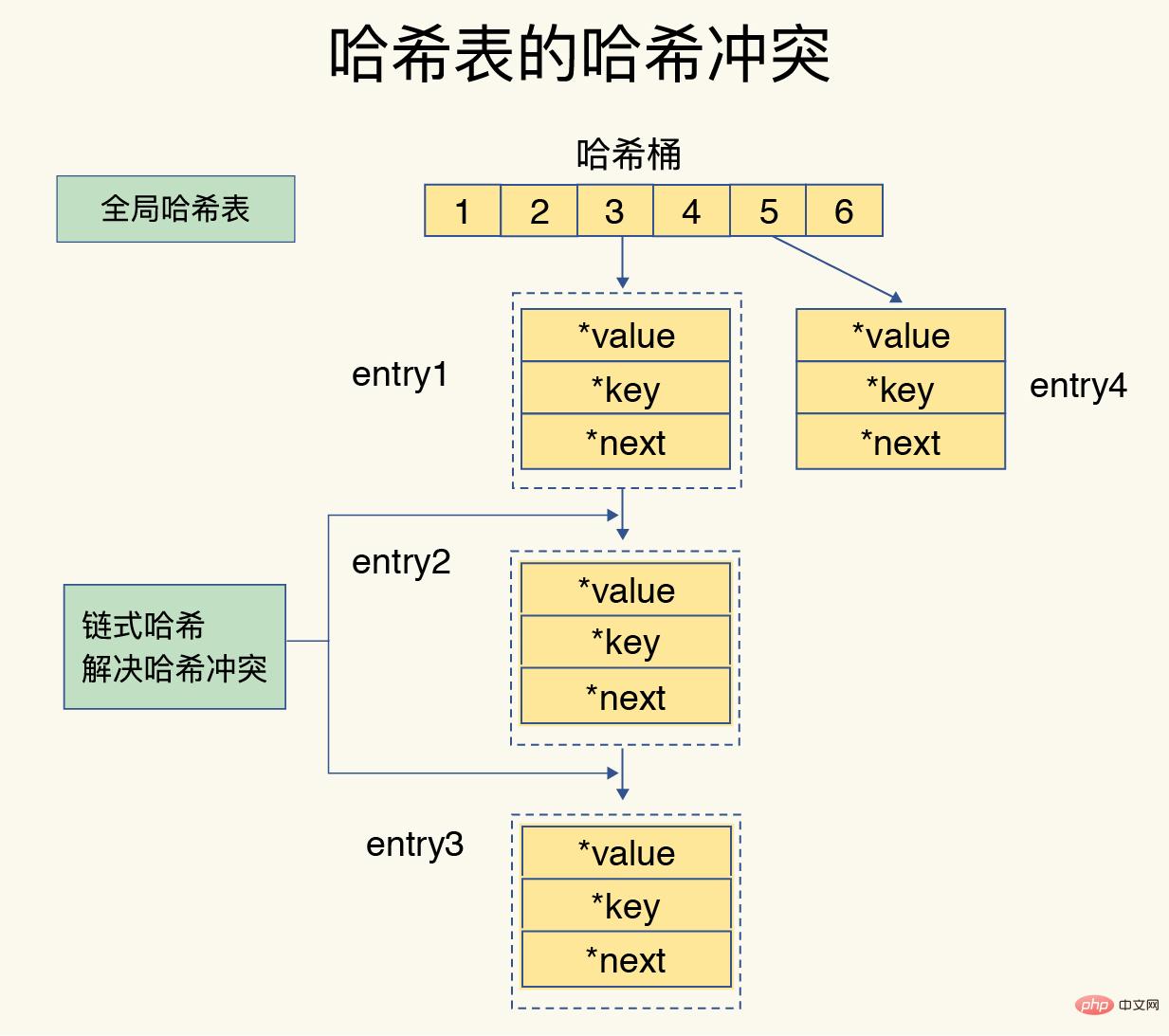
Wenn es immer mehr Hash-Konflikte gibt, führt dies dazu, dass die Hash-Konfliktkette zu lang wird, was zu langer Zeit und geringer Effizienz bei der Suche nach Elementen führt. Um dieses Problem zu lösen, führt Redis einen Rehash-Vorgang für die Hash-Tabelle durch, um mehrere Eintragselemente verteilt zu speichern, wodurch die Anzahl der Elemente in einem einzelnen Hash-Bucket reduziert und dadurch Konflikte in einem einzelnen Bucket reduziert werden.
Redis verwendet standardmäßig zwei globale Hash-Tabellen für effizientes Rehash. Hash-Tabelle 1 wird standardmäßig zu Beginn verwendet, und Hash-Tabelle 2 weist keinen Speicherplatz zu. Wenn die Daten weiter zunehmen, führt Redis das Rehash durch die folgenden Schritte durch:
- Geben Sie Hash-Tabelle 2 größeren Speicherplatz zu.
- Kopieren Sie die Daten in Hash-Tabelle 1 in Hash-Tabelle 2.
- Geben Sie den Speicherplatz von Hash-Tabelle 1 frei und reservieren Sie ihn für die nächste Rehash-Erweiterung. Schritt 2: Wenn eine große Menge vorhanden ist Wenn Daten auf einmal kopiert werden, ist der Redis-Thread möglicherweise blockiert und kann keine anderen Anforderungen mehr bedienen. Daher verwendet Redis progressives Rehash, was bedeutet, dass bei jeder Verarbeitung einer Anforderung alle Einträge an dieser Indexposition kopiert werden.
Für den Wert vom Typ String kann der CRUD-Vorgang direkt nach dem Finden des Hash-Buckets ausgeführt werden. Bei Sammlungen wird CRUD in der Sammlung ausgeführt, nachdem der entsprechende Hash-Bucket über die globale Hash-Tabelle gefunden wurde. Die Betriebseffizienz einer Sammlung hängt von der zugrunde liegenden Datenstruktur und der Betriebskomplexität ab. 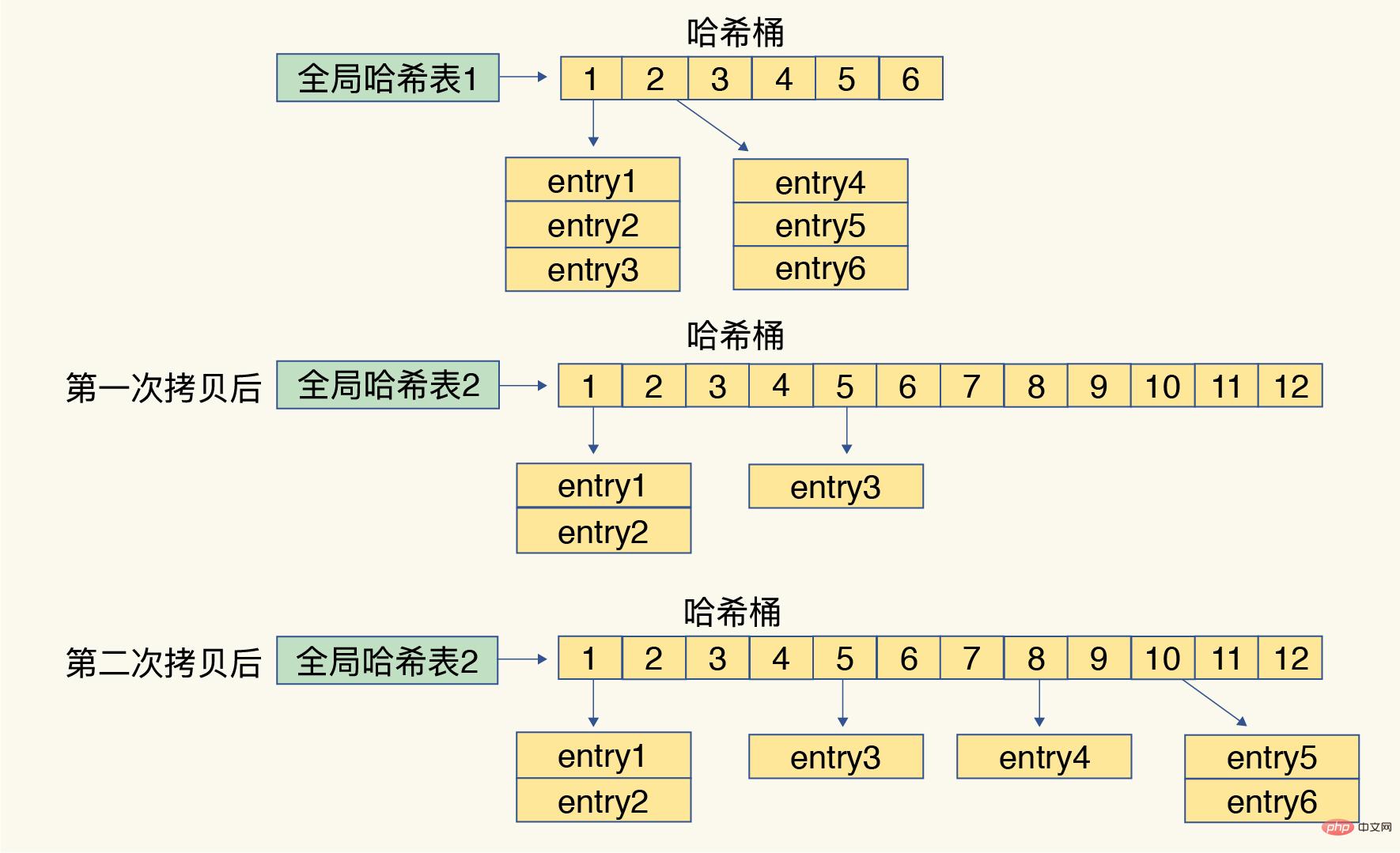
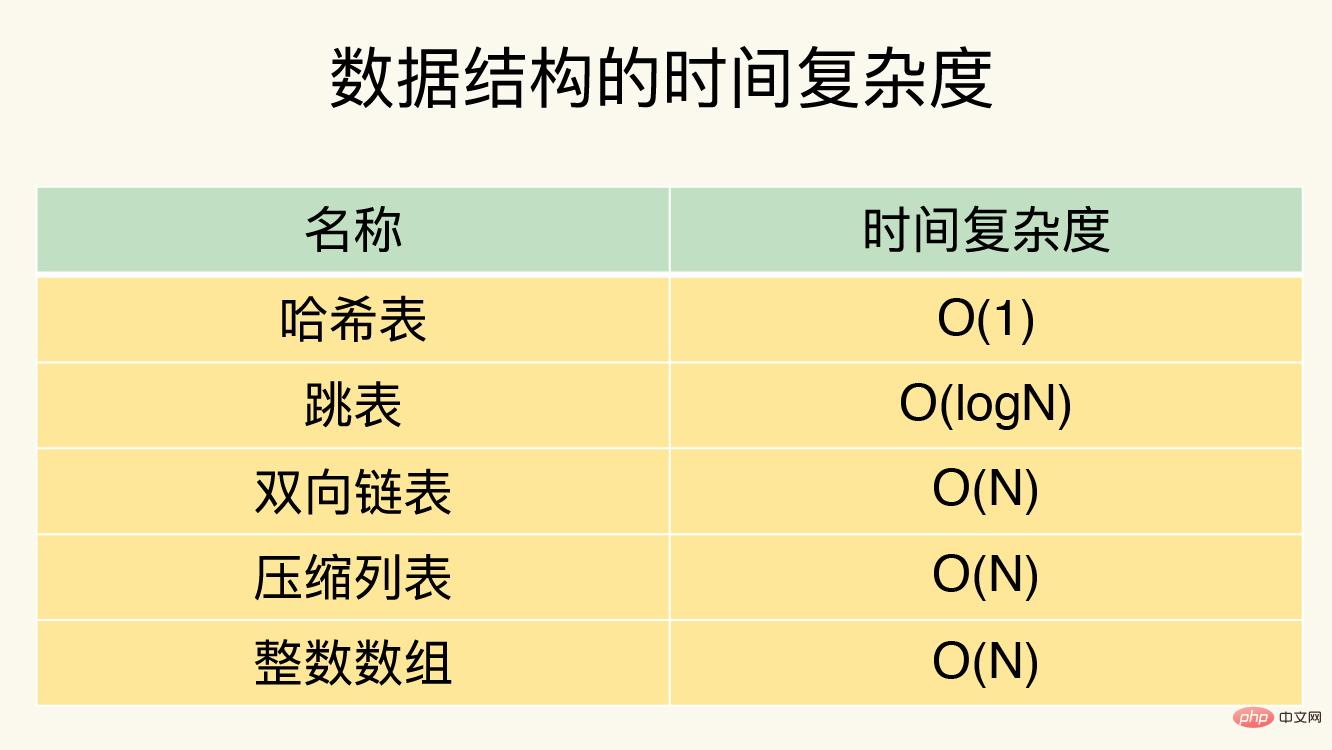 Einzelelementoperation ist die Basis, und die Operationskomplexität ist O(1);
Einzelelementoperation ist die Basis, und die Operationskomplexität ist O(1);
- Hash: HGET, HSET, HDEL;
- Set-Typ SADD, SREM, SRANDMEMBER usw.
- Range-Operationen sind sehr zeitaufwändig und die Operationskomplexität beträgt O(N).
Hash: HGETALL; - Set: SMEMBERS;
- List: LRANGE
- ZSet: ZRANGE
- Statistische Operationen sind normalerweise effizient, mit einer Operationskomplexität von O(1).
Es gibt nur wenige Ausnahmen und die Operationskomplexität beträgt O(1). - Liste: LPOP, RPOP, LPUSH, RPUSH
Das obige ist der detaillierte Inhalt vonDetaillierte Analyse der Datenstruktur und Datenoperationen von Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So machen Sie Redis aus der Ferne zugänglich
- Einführung in das Redis-Lernen von NoSQL
- So installieren Sie die Redis-Datenbank unter dem Centos-System
- So öffnen Sie den Redis-Port unter Linux
- Redis Learning stellt aktuelle NoSQL-Anwendungsszenarien vor
- Einführung in Redis-Lernen und die vier Hauptklassifizierungen von NoSQL-Datenbanken