
Heim >Datenbank >MySQL-Tutorial >Lassen Sie uns lernen, was eine MySQL-Datenbank ist (3)
Lassen Sie uns lernen, was eine MySQL-Datenbank ist (3)

- coldplay.xixinach vorne
- 2021-02-15 08:57:163041Durchsuche
Kostenlose Lernempfehlung: MySQL-Video-Tutorial
Inhaltsverzeichnis
- Fuzzy-Abfrage
- Einschränkungen von Tabellen
- Beziehungen zwischen Tabellen
- Viele zu eins Assoziation
- Many-to-many-Assoziation
- Eins-zu-eins-Assoziation
Fuzzy-Abfrage
Wir können die gewünschten Daten anhand des grob bereitgestellten Inhalts finden. Es unterscheidet sich von = Abfrage, die den Typ char annimmt. Beispiele für Daten vom Typ varchar:
create table c1(x char(10));create table c2(x varchar(10));insert c1 values('io');insert c2 values('io');
Fuzzy-Abfrage verwendet like
select * from c1 where x like 'io';select * from c2 where x like 'io';
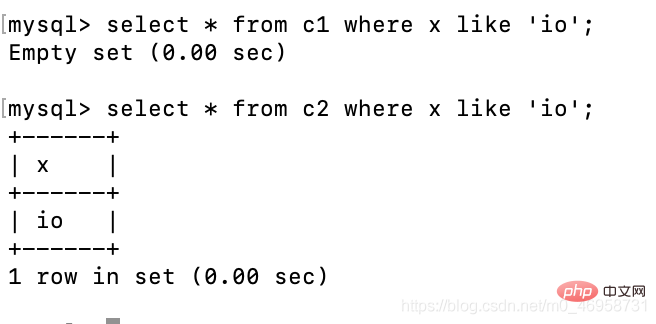
Es kann festgestellt werden, dass x in c1 vom Typ char ist. Wir verwenden Fuzzy-Abfrage, um zu sehen, ob io vorhanden ist Daten, die nicht angezeigt werden können, aber wir übergeben = Aber sie können abgefragt werden

Um auf diese Weise eine Abfrage durchzuführen, müssen Sie den gesamten Inhalt dieses Felds eingeben, bevor Sie die gespeicherten Daten abfragen können Der char-Typ ist hier weniger als 10 Zeichen lang, daher werden Leerzeichen verwendet. Bei der Abfrage müssen Sie auch Leerzeichen verwenden. Wir können auch die von der Fuzzy-Abfrage bereitgestellte Abfragemethode verwenden. % steht für eine beliebige 0 oder mehr Charaktere.
select * from c1 where x like 'io%';

Wenn wir nur wissen, dass die zweite Ziffer ein o ist und den Anfang und das Ende nicht kennen, können wir Folgendes verwenden: _, um ein beliebiges einzelnes Zeichen darzustellen, und dann % verwenden, um die folgenden Zeichen abzugleichen
select * from c1 where x like '_o%';

Syntax der SQL-Fuzzy-Abfrage für
„SELECT Column FROM Table WHERE Column LIKE ‚;pattern‘;“. 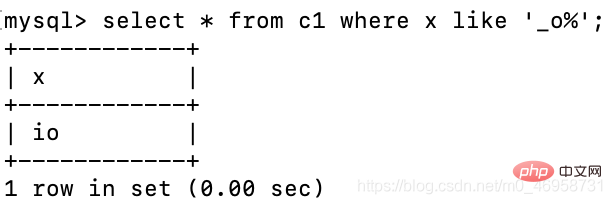
SQL bietet vier Übereinstimmungsmodi:
SELECT * FROM user WHERE name LIKE ';%三%';Einführung:findet alle Namen mit „drei“ im Namen wie „Zhang San“, „Dreibeinige Katze“, „Tang Sanzang“, usw.;
- 三
_ steht für ein beliebiges einzelnes Zeichen. Anweisung:
SELECT * FROM user WHERE name LIKE ';- ';
Wird find Output „Old 1“, „Old 2“, ..., „Old 9“
Finden Sie nur „Tang Sanzang“, dessen Name drei Zeichen hat und das mittlere „三“ ist; SELECT * FROM user WHERE name LIKE ' ;三_ _'; Finden Sie nur „dreibeinige Katze“, deren Name drei Zeichen hat und das erste Zeichen „三“ ist; Anweisung:
SELECT * FROM user WHERE name LIKE ';[张李王]三';
findet „Zhang San“, „Li San“, „Wang San“ (anstelle von „Zhang Li Wang San“); [] enthält eine Reihe von Zeichen (01234, abcde usw.) und kann als „0-4“, „a-e“ abgekürzt werden
SELECT * FROM user WHERE name LIKE ';老[1-9]';- Wenn Sie nach dem „-“-Zeichen suchen, geben Sie es bitte zuerst ein: ';张三[-1-9]';
[^ ] steht für ein einzelnes Zeichen, das nicht in Klammern aufgeführt ist. Aussage:
SELECT * FROM user WHERE name LIKE ';[^Zhang Liwang]三';
findet „Zhao San“, „Sun San“ usw., die nicht den Nachnamen „Zhang“, „Li“, „Wang“ haben. ;
SELECT * FROM user WHERE name LIKE ';老[^1-4]';
schließt „alt 1“ bis „alt 4“ aus und sucht nach „alt 5“, „alt 6“, ..., „ alte 9".
Tabelleneinschränkungen
Einschränkungsbedingungen wie die Breite des Datentyps sind optionale Parameter
- Funktion: Wird verwendet, um die Integrität und Konsistenz der Daten sicherzustellen
-
-
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录FOREIGN KEY (FK) 标识该字段为该表的外键NOT NULL 标识该字段不能为空UNIQUE KEY (UK) 标识该字段的值是唯一的AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)DEFAULT 为该字段设置默认值UNSIGNED 无符号 ZEROFILL 使用0填充
nicht null: Die wörtliche Bedeutung besteht darin, dass nach dem Festlegen jedes Mal, wenn ein Wert eingefügt wird, der Wert für das Feld festgelegt werden muss
Standard: Wenn kein Wert für das Feld festgelegt ist, verwenden Sie den Wert Wir haben einen Standardwert nach dem Standardwert definiert.
EINZIGARTIGER SCHLÜSSEL: Nachdem ein Feld diese Einschränkung festgelegt hat, kann der von ihm festgelegte Wert nur einmal (eindeutig) in der gesamten Tabelle existieren.
PRIMÄRSCHLÜSSEL: Der Primärschlüssel ist die Innodb-Speicher-Engine Die Grundlage für die Organisation von Daten wird von InnoDB als indexorganisierte Tabelle bezeichnet. In einer Tabelle darf es nur einen Primärschlüssel geben.
Der Primärschlüssel ist die eindeutige Kennung, die einen Datensatz bestimmen kannAUTO_INCREMENT: Nach der Einstellung wird dieses Feld jedes Mal, wenn ein Wert in die Tabelle eingefügt wird, automatisch um eine Zahl erhöht, aber dieses Feld muss vom Typ Ganzzahl sein und muss auch der Primärschlüssel sein
Fremdschlüssel: Fremdschlüssel, der ein Feld dieser Tabelle mit einem Feld einer anderen Tabelle verknüpft. Nach der Zuordnung muss der Wert dieses Felds dem Wert des zugehörigen Felds entsprechen.
我们创建表,通常会有一个id字段作为索引标识作用,并且会将它设置为主键和自增。
实例:
create table test(
id int primary key auto_increment,
identity varchar(18) not null unique key, --身份证必须唯一
gender varchar(18) default '男');insert test(identity) values('123456789012345678');
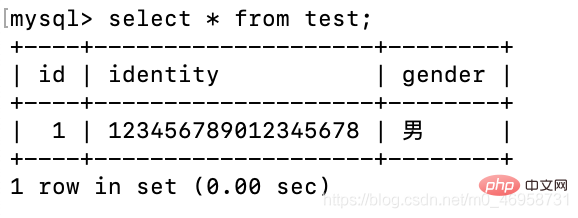
当身份字段插入相同值,则会报错,因为字段设置了唯一值
insert test(identity,gender) values('0123456789012345678','女');

我们会发现,id不对劲啊,那是因为笔者之前进行两次插入值操作,但是值并没有成功插入进去,但是这个自增却受到了影响.
这个时候,我们进行两部操作就可以解决这个问题。
alter table test drop id;alter table test add id int primary key auto_increment first;
删除id字段,再重新设置。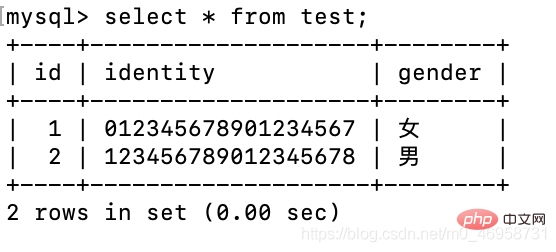
很神奇是不是,这个MySQL的底层机制。vary 良心
还需要注意的是:我们使用delete删除一条记录时,并不会影响自增
delete from test where id = 2;insert test(identity,gender) values('111111111111111111','男');
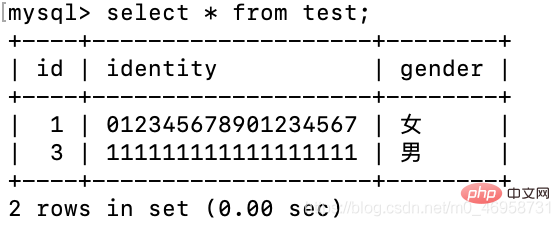
关于这个操作,如果我们只是删除单条记录的话,可以使用上序提供的方法还调整自增的值,而如果是删除整个表记录的话,使用以下方法:
truncate test;
效果演示:delete删除整个表记录
效果演示:truncate删除整个表记录
联合主键
确保设置为主键的某几个字段的数据相同
主键的一个目的就是确定数据的唯一性,它跟唯一约束的区别就是,唯一约束可以有一个NULL值,但是主键不能有NULL值,再说联合主键,联合主键就是说,当一个字段可能存在重复值,无法确定这条数据的唯一性时,再加上一个字,两个字段联合起来确定这条数据的唯一性。比如你提到的id和name为联合主键,在插入数据时,当id相同,name不同,或者id不同,name相同时数据是允许被插入的,但是当id和name都相同时,数据是不允许被插入的。
实例:
create table test( id int, name varchar(10), primary key(id,name)); insert test values(1,1);

如果再次插入两个主键相同的数据,则会报错
只要设置主键的两个字段,在一条记录内,数据不完全相同就没有问题。
外键的话,我们在表之间的关联进行演示
表之间的关联
我们这里先介绍表之间的关联,后面再学习联表查询
通过某一个字段,或者通过某一张表,将多个表关联起来。
我们一张表处理好不行吗,为什么要关联,像这样?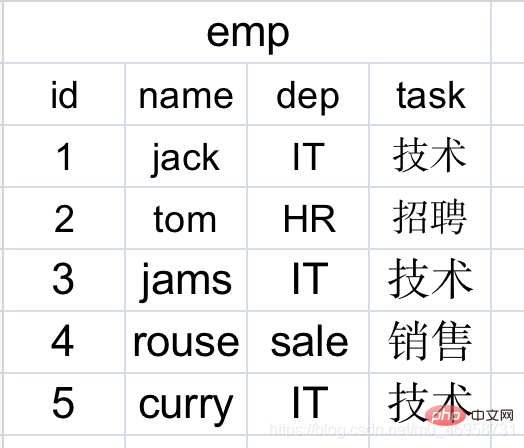
有没有发现一个问题,有些员工它们对应的是相同部门,一张表就重复了很多次记录,随着员工数量的增加,就会出现越来越多个重复记录,相对更占用空间了。
那么我们需要将部门单独使用一张表,再将员工这个使用一个字段关联到另一个表内,我们可以使用外键,也可以不使用外键,先来演示外键的好处吧
多对一关联
如:多个员工对应一个部门。
员工表,先别急着创建,请向下看
create table emp( id int primary key auto_increment, name varchar(10) not null, dep_id int, foreign key(dep_id) references dep(id) on update cascade # 级联更新 on delete cascade); # 级联删除
上面外键的作用就是:
dep_id字段关联了dep表的id字段:
当dep表的id字段值修改后,该表的dep_id字段下面如果有和dep表id相同值的则会一起更改。
如果dep表删除了某一条记录,当emp表的dep_id与dep表删除记录的id值对上以后,emp表这条记录也会被随之删除。
注意:必须是外键已存在,所以需要先创建部门表,再创建员工表
部门表
create table dep( id int primary key auto_increment, name varchar(16) not null unique key, task varchar(16) not null);
emp表的dep_id字段设置的数据必须是dep表已存在的id
所以我们需要先向dep表插入记录
insert dep(name,task) values('IT','技术'),('HR','招聘'),('sale','销售');
员工表插入记录
insert emp(name,dep_id) values
('jack',1),
('tom',2),
('jams',1),
('rouse',3),
('curry',2);
# ('go',4) 报错,在关联外键的id字段中找不到
注意:如果我们emp表的dep_id字段插入的数据,在dep表中的id字段不存在该数据时,就会报错。
查询我们创建后的效果
这样就把这两个表关联起来了,目前我们先不了解多表查询,这个先了解的是,表之间的关联。
我们再来看一下同步更新以及删除,外键的改动被关联表会受到影响
update dep set id=33333 where id = 3;
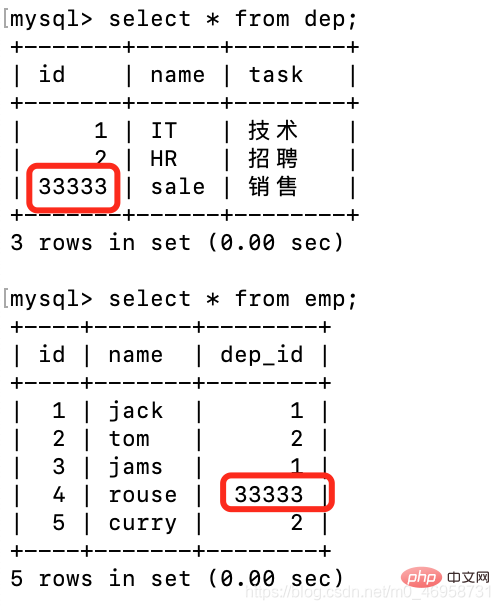
再来体验一下同步删除
delete from dep where id = 33333;

这就是外键带给我们的效果,有利也有弊:
- 优点:关联性强,只能设置已存在的内容,并且同步更新与删除
- 缺点:当删除外键表的某一条记录,关联表中有关联性的记录会被全部删除
多对多关联
多张表互相关联
如:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
这时使用外键会出现一个弊端,那就是先创建哪张表呢?它们都互相对应,是不是很矛盾呢?解决办法:第三张表,关联书的id与作者的id
book表
create table book( id int primary key auto_increment, name varchar(30));
author表
create table author( id int primary key auto_increment, name varchar(30));
中间表:负责将两张表进行关联
create table authorRbook( id int primary key auto_increment, author_id int, book_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, foreign key(author_id) references author(id) on update cascade on delete cascade);
多名作者关联一本书,或者一名作者关联多本书,书也要体现出谁关联了它
book表插入数据:
insert book(name) values
('斗破苍穹'),
('斗罗大陆'),
('武动乾坤');
author表插入数据:
insert author(name) values
('jack'),
('tom'),
('jams'),
('rouse'),
('curry'),
('john');
关联表插入数据:
insert authorRbook(author_id,book_id) values (1,1), (1,2), (1,3), (2,1), (2,3), (3,2), (4,1), (5,1), (5,3), (6,2);
目前的对应关系就是:
jack:斗破苍穹、斗罗大陆、武动乾坤
tom:斗破苍穹、武动乾坤
jams:斗罗大陆
rouse:斗破苍穹
curry:斗破苍穹、武动乾坤
jhon:斗罗大陆
一个作者可以产于多本书的编写,同时,每本书都会标明产于的作者
一对一关联
路人有可能变成某个学校的学生,即一对一关系。
在这之前,路人不属于学校。
原理就是:学校通过广告,或者通过电话邀请,将路人变成了学生。
路人表
create table passers_by(
id int primary key auto_increment,
name varchar(10),
age int);
insert passers_by(name,age) values
('jack',18),
('tom',19),
('jams',23);
学校表
create table school(
id int primary key auto_increment,
class varchar(10),
student_id int unique key,
foreign key(student_id) references passers_by(id)
on update cascade
on delete cascade);insert school(class,student_id) values
('Mysql入门到放弃',1),
('Python入门到运维',3),
('Java从入门到音乐',2);
数据存储的设计,需要提前设计好表的关联 关系,将关系全部设计好以后,剩下的只是往里存数据了,后续我们会了解到联表查询相关内容,将有关联性的内容,以虚拟表的形式查询出来,查询出来的数据可能来自多个表。
表的关联,建议使用以下方式
- 多对多 > 多对一 > 一对一
相关免费学习推荐:mysql数据库(视频)
Das obige ist der detaillierte Inhalt vonLassen Sie uns lernen, was eine MySQL-Datenbank ist (3). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Werfen Sie einen Blick auf die erstaunlichen impliziten Konvertierungen von MySQL
- Einführung der PHP7.3.5-Kapselungsklasse für den Zugriff auf die MySQL-Datenbank
- Zusammenfassung der häufigen MySQL-Fehleranalyse und -Lösungen
- Über die Verwendung von MySQL-Tests
- Beherrschen Sie MYSQL Advanced
- Die MySQL5.7-Datenbank führt Tabellenverbindungen, Unterabfragen und Fremdschlüssel ein
- So zeigen Sie MySQL-Vorgangsdatensätze in Navicat an