
Heim >PHP-Framework >Denken Sie an PHP >ThinkPHP-Datenbankoperationen, gespeicherte Prozeduren, Datensätze, verteilte Datenbanken
ThinkPHP-Datenbankoperationen, gespeicherte Prozeduren, Datensätze, verteilte Datenbanken

- 藏色散人nach vorne
- 2021-01-28 17:15:232421Durchsuche
Die folgende Tutorial-Kolumne von thinkphp stellt Ihnen die gespeicherten Prozeduren, Datensätze und verteilten Datenbanken von ThinkPHP-Datenbankoperationen vor. Ich hoffe, dass sie Freunden in Not hilfreich sein werden!

Gespeicherte Prozeduren
5.0 unterstützt gespeicherte Prozeduren sp_query, die wie folgt aufgerufen werden können:
$result = Db::query('call sp_query(8)');
Gibt ein zweidimensionales Array oder Sie zurück kann Parameterbindung verwenden, zum Beispiel:
$result = Db::query('call sp_query(?)',[8]);
// 或者命名绑定$result = Db::query('call sp_query(:id)',['id'=>8]);
dataset
Das Abfrageergebnis der Datenbank ist auch der Datensatz. In der Standardkonfiguration ist der Typ des Datensatzes ein zweidimensionales Array. Wir können es in eine Datensatzklasse konfigurieren, Sie können mehr objektbasierte Vorgänge für den Datensatz unterstützen. Sie können den Parameter resultset_type der Datenbank wie folgt konfigurieren:
return [ // 数据库类型 'type' => 'mysql', // 数据库连接DSN配置 'dsn' => '', // 服务器地址 'hostname' => '127.0.0.1', // 数据库名 'database' => 'thinkphp', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '', // 数据库连接参数 'params' => [], // 数据库编码默认采用utf8 'charset' => 'utf8', // 数据库表前缀 'prefix' => 'think_', // 数据集返回类型 'resultset_type' => 'collection',];
Die zurückgegebenen Das Datensatzobjekt ist thinkCollection, das die gleiche Verwendung wie ein Array bietet. Darüber hinaus sind einige zusätzliche Methoden gekapselt. Sie können das Datensatzobjekt direkt über ein Array bedienen, zum Beispiel:
// 获取数据集
$users = Db::name('user')->select();
// 直接操作第一个元素
$item = $users[0];
// 获取数据集记录数
$count = count($users);
// 遍历数据集
foreach($users as $user){ echo $user['name']; echo $user['id'];
}
Beachten Sie, dass Sie, wenn Sie beurteilen möchten, ob der Datensatz leer ist, nicht direkt empty zur Beurteilung verwenden können, sondern isEmpty verwenden müssen Methode des zu beurteilenden Datensatzobjekts, zum Beispiel:
$users = Db::name('user')->select();if($users->isEmpty()){ echo '数据集为空';
}
Collection-Klasse enthält die folgenden Hauptmethoden:
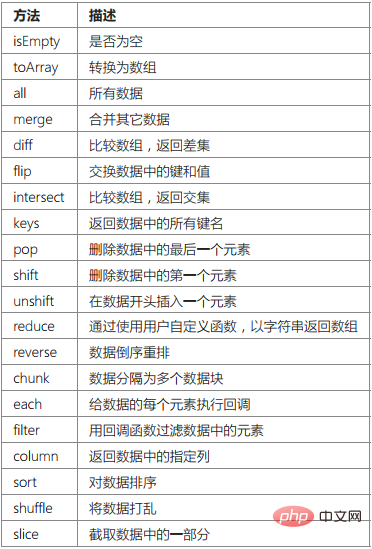
Wenn die Abfrage nur einzelner Daten das Datensatzobjekt zurückgeben muss, können Sie
Db::name('user') ->fetchClass('\think\Collection') ->select();
verwenden Verteilte Datenbank
ThinkPHP verfügt über eine integrierte Verteilungsunterstützung für verteilte Datenbanken, einschließlich der Lese-/Schreibtrennung von Master-Slave-Datenbanken, aber verteilte Datenbanken müssen vom gleichen Datenbanktyp sein.
Konfigurieren Sie „database.deploy“ auf 1, um die Unterstützung verteilter Datenbanken zu nutzen. Wenn eine verteilte Datenbank verwendet wird, können Datenbankkonfigurationsinformationen wie folgt definiert werden:
//分布式数据库配置定义 return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,192.168.1.2', // 数据库名 'database' => 'demo', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '',]
Die Anzahl der verbundenen Datenbanken hängt von der Anzahl der Hostnamendefinitionen ab, sodass auch zwei identische IPs wiederholt definiert werden müssen, wenn jedoch andere Parameter vorhanden sind das Gleiche Es besteht keine Notwendigkeit, die Definition zu wiederholen, zum Beispiel:
'hostport'=>'3306,3306'
und
'hostport'=>'3306'
sind gleichwertig.
'username'=>'user1', 'password'=>'pwd1',
und
'username'=>'user1,user1', 'password'=>'pwd1,pwd1',
sind gleichwertig.
Sie können auch festlegen, ob das Lesen und Schreiben der verteilten Datenbank getrennt ist. Standardmäßig sind Lesen und Schreiben nicht getrennt, dh jeder Server kann Lese- und Schreibvorgänge ausführen. Für die Master-Slave-Datenbank ist dies erforderlich Legen Sie die Lese- und Schreibtrennung fest, indem Sie die folgenden Einstellungen vornehmen:
'rw_separate' => true,
Bei der Lese-Schreib-Trennung handelt es sich bei der standardmäßigen ersten Datenbankkonfiguration um die Konfigurationsinformationen des Hauptservers, der für das Schreiben von Daten verantwortlich ist Wenn der Parameter festgelegt ist, können mehrere Hauptserver zum Schreiben unterstützt werden. Andere sind für das Lesen von Daten aus den Konfigurationsinformationen der Datenbank verantwortlich, und die Anzahl ist nicht begrenzt. Jedes Mal, wenn Sie eine Verbindung zum Slave-Server herstellen und einen Lesevorgang durchführen, wählt das System zufällig einen Slave-Server aus.
Sie können „slave_no“ auch festlegen, um einen Server für Lesevorgänge anzugeben.
Wenn in der Slave-Datenbankverbindung ein Fehler auftritt, wird automatisch auf die Hauptdatenbankverbindung umgeschaltet.
Wenn Sie die CURD-Operation des Modells aufrufen, ermittelt das System automatisch, ob es sich bei der aktuell ausgeführten Methode um eine Leseoperation oder eine Schreiboperation handelt. Wenn Sie natives SQL verwenden, müssen Sie die Standardregeln des Systems beachten: Schreibvorgänge müssen die Ausführungsmethode des Modells verwenden, Lesevorgänge müssen die Abfragemethode des Modells verwenden, sonst kommt es zu einem Master-Slave-Lese- und Schreibchaos.
Hinweis: Die Datensynchronisierungsarbeit der Master-Slave-Datenbank ist nicht im Framework implementiert und die Datenbank muss ihren eigenen Synchronisierungs- oder Replikationsmechanismus berücksichtigen.
Das obige ist der detaillierte Inhalt vonThinkPHP-Datenbankoperationen, gespeicherte Prozeduren, Datensätze, verteilte Datenbanken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wir stellen vor: Homestead, die ThinkPHP-Entwicklungsumgebung
- ThinkPHP-Datenbankvorgang zum Herstellen einer Verbindung zur Datenbank
- ThinkPHP-Datenbankoperationen: Hinzufügen, Löschen, Ändern und Abfragen
- Abfragemethoden für ThinkPHP-Datenbankoperationen, Abfragesyntax, Kettenoperationen
- ThinkPHP-Datenbankoperations-Aggregationsabfrage, Zeitabfrage, erweiterte Abfrage