
Heim >Datenbank >MySQL-Tutorial >MYSQL Advanced für Big Data Learning
MYSQL Advanced für Big Data Learning

- coldplay.xixinach vorne
- 2021-01-27 09:48:442491Durchsuche
Kostenlose Lernempfehlung: MySQL-Video-Tutorial System
 1.3 Datenbankspeicher-Engine Auswahl
1.3 Datenbankspeicher-Engine Auswahl
1.4 Datenbankparameterkonfiguration1.5 Datenbankstrukturdesign und SQL-Anweisungen (Schlüssel)2 Hardwareaspekte
2.1 CPU-Ressourcen und verfügbare Speichergröße
- 2.1.1 So wählen Sie die CPU aus
-
- 2.1.2 Speicher
- 2.1.2.1 Häufig verwendete MySQL-Speicher-Engines
- 2.1.2.2 Tipps
- 2.1.2.3 So wählen Sie den Speicher aus
- 2.2 Festplattenkonfiguration und -auswahl
- 2.2 .1 Verwendung Traditionelle Maschinenfestplatte
- 2.2.2 Verwenden Sie RAID, um die Leistung einer herkömmlichen Maschinenfestplatte zu verbessern
- 2.2.2.1 Was ist RAID? 2.2.2.2 RAID-Level
- 2.2.2.2.1 RAID 0
- 2.2.2.2.2 RAID 1
- 2.2.2.2.3 RAID 5 – Häufig verwendete RAID-Gruppen
2.2.2.2.4 RAID 10 – Häufig verwendete RAID-Gruppen
- 2.2.2.3 RAID-Level-Auswahl
- 2.2. 3 Verwenden Sie Solid-State-Storage-SSD- und PCIe-Karten
- 2.2.4 Verwenden Sie Netzwerkspeicher NAS und SAN
- 2.2.4.1 Netzwerkspeicher-Nutzungsszenarien
- 2.2.4.2 Einschränkungen der Netzwerkleistung
-
- 2.2.4.3 Auswirkungen auf die Netzwerkleistung
- 2.3 Zusammenfassung: 3. Einfluss des Betriebssystems auf die Leistung Aspekte, die Auswirkungen auf die Leistung
- 1.1 Hardware-Aspekt
- 1.2 Serversystem
- Im Allgemeinen ist das Betriebssystem von PCs Windows. Verschiedene Versionen von Windows-Systemen weisen unterschiedliche Leistung auf, oder bestimmte Parameter sind so konfiguriert, dass sie unterschiedliche Leistung bewirken. Dies gilt auch für Serversysteme, und Parametereinstellungen wirken sich auch auf die Serverleistung aus.
- 1.3 Auswahl der Datenbankspeicher-Engine
-
- MySQL verfügt über eine Plug-in-Speicher-Engine, und je nach Geschäftsanforderungen können verschiedene Speicher-Engines ausgewählt werden. Verschiedene Speicher-Engines haben auch unterschiedliche Eigenschaften:
- MyISAM: unterstützt keine Transaktionen und Sperren auf Tabellenebene.
- 1.4 Datenbankparameterkonfiguration
Für verschiedene Speicher-Engines sind ihre Parameterkonfigurationen unterschiedlich. Einige Parameter haben einen minimalen Einfluss auf die Speicher-Engine, aber einige Parameter spielen eine entscheidende Rolle für die Leistung. Daher ist es auch wichtig, Parameter basierend auf der ausgewählten Speicher-Engine und unterschiedlichen Geschäftsanforderungen zu optimieren. - 1.5 Datenbankstrukturdesign und SQL-Anweisungen (Schlüsselpunkte)
- Wenn wir die Datenbankstruktur entwerfen, sollten wir überlegen, welche Art von SQL-Anweisungen wir in Zukunft auf der Datenbank ausführen werden, um die Tabellenstruktur abzufragen und zu aktualisieren Nur so können wir eine Tischstruktur entwerfen, die den Anforderungen entspricht.
- Unser Fokus auf die Optimierung der Datenbankleistung liegt also auf:
Design der Datenbanktabellenstruktur
Schreiben und Optimieren von SQL-Anweisungen
Im Folgenden finden Sie eine detaillierte Beschreibung jedes Aspekts. 2. Hardware-Aspekte Die CPU ist so hoch wie möglich, aber aufgrund der Kosten oder verschiedener Faktoren sind wir oft gezwungen, nur eine davon auszuwählen. Wie sollten wir also die beste Lösung auswählen? Daher müssen wir beim Kauf einer CPU auf mehrere Punkte achten:
- Ist unsere Anwendung CPU-intensiv?
- Wenn unsere Anwendung CPU-intensiv ist, benötigen wir zur Beschleunigung der SQL-Verarbeitung natürlich bessereCPUs, nicht mehrCPUs.
- Für das aktuelle MySQL unterstützt dualCPU nicht die gleichzeitige Verarbeitung desselben SQL.
- Was ist die Parallelität unseres Systems?
- Wenn unser System mehr Durchsatz benötigt, gilt: Je mehr CPUs wir haben, desto besser. Angenommen, wir haben 40 CPUs, können wir dann 40 SQLs gleichzeitig verarbeiten?
- Messung der Datenbankverarbeitungsfähigkeiten: QPS, was sich auf die Anzahl der gleichzeitig verarbeiteten SQLs bezieht. Dieser Indikator ist jedoch die Anzahl der in 1 Sekunde verarbeiteten SQLs, die im vorherigen Punkt erläuterte gleichzeitige Verarbeitung erfolgt jedoch in der Nanosekundendimension.
- MySQL wird normalerweise in Webanwendungen verwendet, und der Grad der Parallelität ist häufig relativ groß. Zu diesem Zeitpunkt ist die Anzahl der CPUs wichtiger als die CPU-Frequenz.
- Die von uns verwendete Version von MySQL
- Vor Version 5.0 hatte MySQL keine gute Unterstützung für Multi-Core-CPUs und die Einschränkungen auf dem System waren sehr gravierend. Die Unterstützung für Multi -Core-CPUs ist nicht gut. Daher wird empfohlen, die neueste Version von MySQL zu verwenden, um eine bessere Leistung zu erzielen.
- 32-Bit- oder 64-Bit-CPU wählen? 🔜
Die Größe des Speichers wirkt sich direkt auf die Leistung der Datenbank aus. Der Speicher ist derzeit viel effizienter als die Festplatte. Daher kann das Zwischenspeichern von Daten im Speicher die Serverleistung erheblich verbessern.
2.1.2.1 Häufig verwendete MySQL-Speicher-EnginesEs gibt zwei häufig verwendete Speicher-Engines: MyISAM und InnoDB.
MyISAM
: Der Index wird im Speicher abgelegt und die Daten werden auf der Festplatte gespeichert. 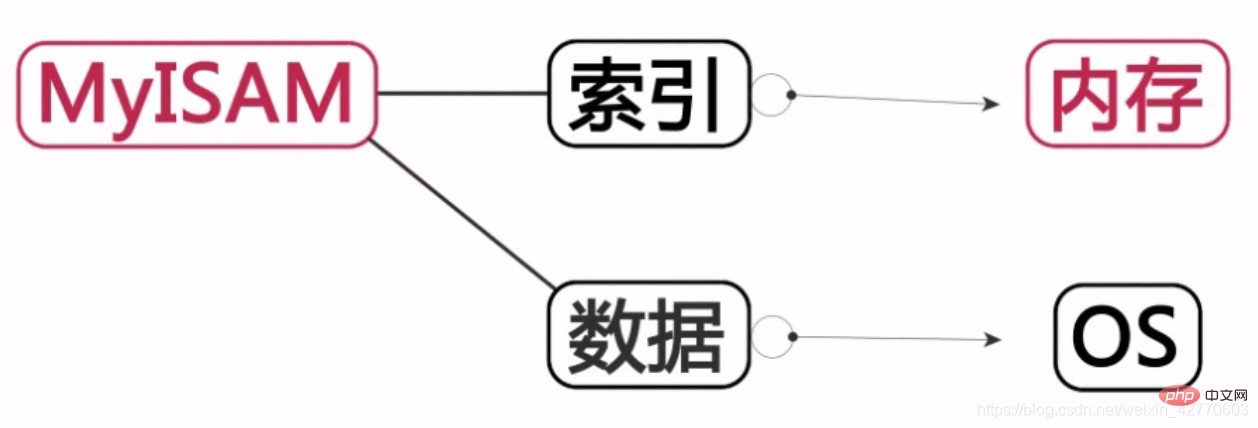 InnoDB:
InnoDB:
Sowohl Indizes als auch Daten werden im Speicher gespeichert, wodurch die Betriebseffizienz der Datenbank verbessert wird. 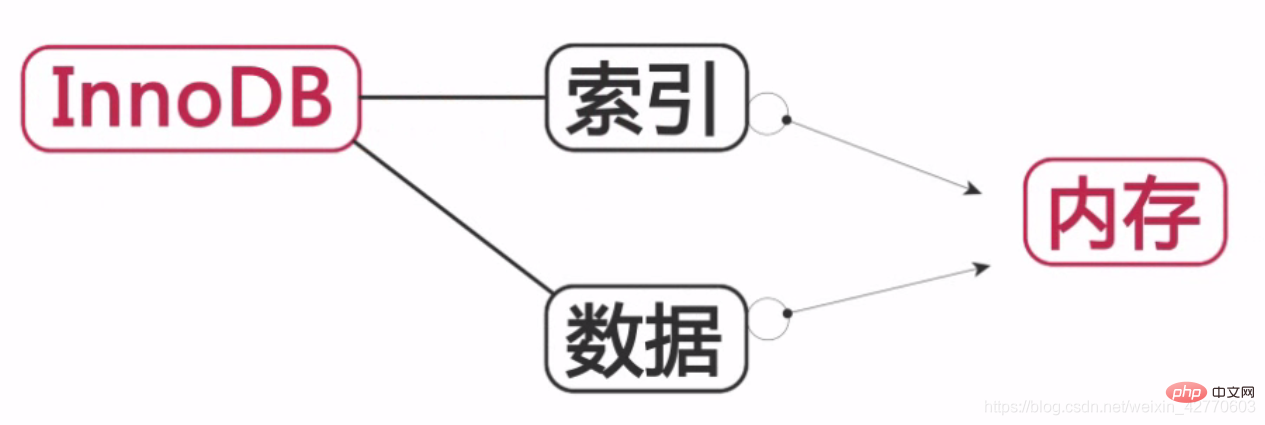 2.1.2.2 Tipps
2.1.2.2 Tipps
- Wenn die Daten in unserer Datenbank 100 GB groß sind, kann die maximale Leistung durch die Auswahl des Speichers um 128 GB erreicht werden. Wenn es sich zu diesem Zeitpunkt bei allen Daten um heiße Daten handelt, ist eine Verwendung im Speicher nicht erforderlich 256 GB Speicher, aber die Wahl eines größeren Speichers verbessert auch die Leistung anderer Dienste wie des Betriebssystems, und es besteht keine Notwendigkeit, kurzfristig über eine Speicheraufrüstung nachzudenken.
-
Bei Schreibvorgängen im Speichercache können Sie das Schreiben verzögern, um die Belastung der Datenbank zu verringern. Der Speicher bietet bereits eine gute Unterstützung für Lesevorgänge, und Schreibvorgänge können auch im Speicher ausgeführt werden. Obwohl das Schreiben auf die Festplatte nicht vermieden werden kann, können wir den Eingabevorgang verzögern und mehrere Schreibvorgänge zu einem zusammenführen Schreiben Sie, um den Druck auf die Datenbank zu verringern. Die Datenbank bietet eine ähnliche Funktion, mit der mehrere Schreibvorgänge im Cache-Pool zu einem zusammengefasst und schließlich auf die Festplatte geschrieben werden können. 2.1.2.3 So wählen Sie Speicher aus Partikel, Frequenz, Spannung, Verifizierungstechnologie und Modell. -
Wählen Sie den Speicher basierend auf der Datenbankgröße.
2.2 Festplattenkonfiguration und -auswahl
- Obwohl der Speicher eine große Rolle bei der Datenbankleistung spielt, können wir die Auswirkungen des IO-Subsystems auf die Leistung nicht ignorieren. Derzeit verwenden wir üblicherweise die folgenden 4 Arten von Festplattenoptionen:
- 2.2.1 Verwenden Sie herkömmliche Maschinenfestplatten
- Eigenschaften: großer Speicherplatz, niedriger Preis, am häufigsten verwendet, am häufigsten, langsames Lesen und Schreiben
SpeicherkapazitätÜbertragungsgeschwindigkeit
Zugriffszeit
SpindelgeschwindigkeitPhysische Größe- 2.2.2.1 Was ist RAID
- RAID ist die Abkürzung für Redundant Arrays of Independent Disks. Vereinfacht gesagt besteht die Funktion von RAID darin, mehrere Festplatten mit geringerer Kapazität zu einer Gruppe von Festplatten mit größerer Kapazität zusammenzufassen und Datenredundanz bereitzustellen, um die Datenintegrität sicherzustellen.
2.2.2.2 RAID-Level
2.2.2.2.1 RAID 0
RAID 0 ist der früheste RAID-Modus, auch Data Striping genannt. Es ist die einfachste Form unter den Komponenten-Festplatten-Arrays. Es erfordert nur mehr als 2 Festplatten. Es ist kostengünstig und kann die Leistung und den Durchsatz der gesamten Festplatte verbessern. RAID 0 bietet keine Redundanz- oder Fehlerwiederherstellungsfunktionen, ist aber mit den niedrigsten Implementierungskosten verbunden. Unter Berücksichtigung der Datenwiederherstellungs- und Zuverlässigkeitsfaktoren ist RAID 0 jedoch zur teuersten Konfiguration geworden, da es bei RAID 0 keine Redundanz gibt und die Wahrscheinlichkeit einer Datenbeschädigung höher ist als bei einer einzelnen Festplatte. Denn Datenschäden auf jeder Festplatte führen zu Datenverlust. Beispielsweise ist die Wahrscheinlichkeit einer Beschädigung eines RAID 0, das aus drei Festplatten besteht, dreimal höher als bei einer einzelnen Festplatte. Daher eignet sich RAID 0 für Situationen, in denen keine einzelnen Daten verloren gehen, wie zum Beispiel: eine Standby-Datenbank, die jederzeit von anderen Datenbanken geklont werden kann, oder einige Datenbanken, die nur einmal verwendet werden müssen. Einfach ausgedrückt besteht RAID 0 darin, Festplatten in Reihe zu verbinden, um eine größere Festplatte zu bilden, wie zum Beispiel: 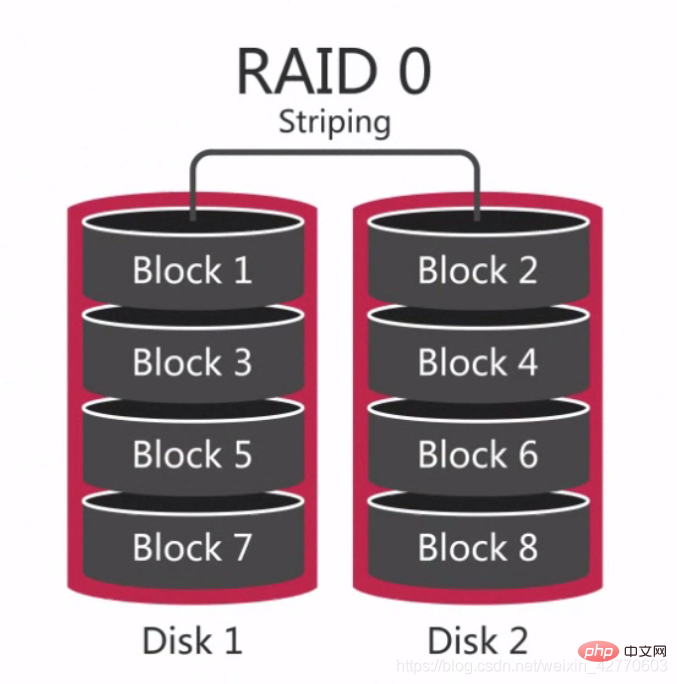 Und im gleichzeitigen Prozess kann die dreifache Leistung einer einzelnen Festplatte erreicht werden.
Und im gleichzeitigen Prozess kann die dreifache Leistung einer einzelnen Festplatte erreicht werden.
2.2.2.2.2 RAID 1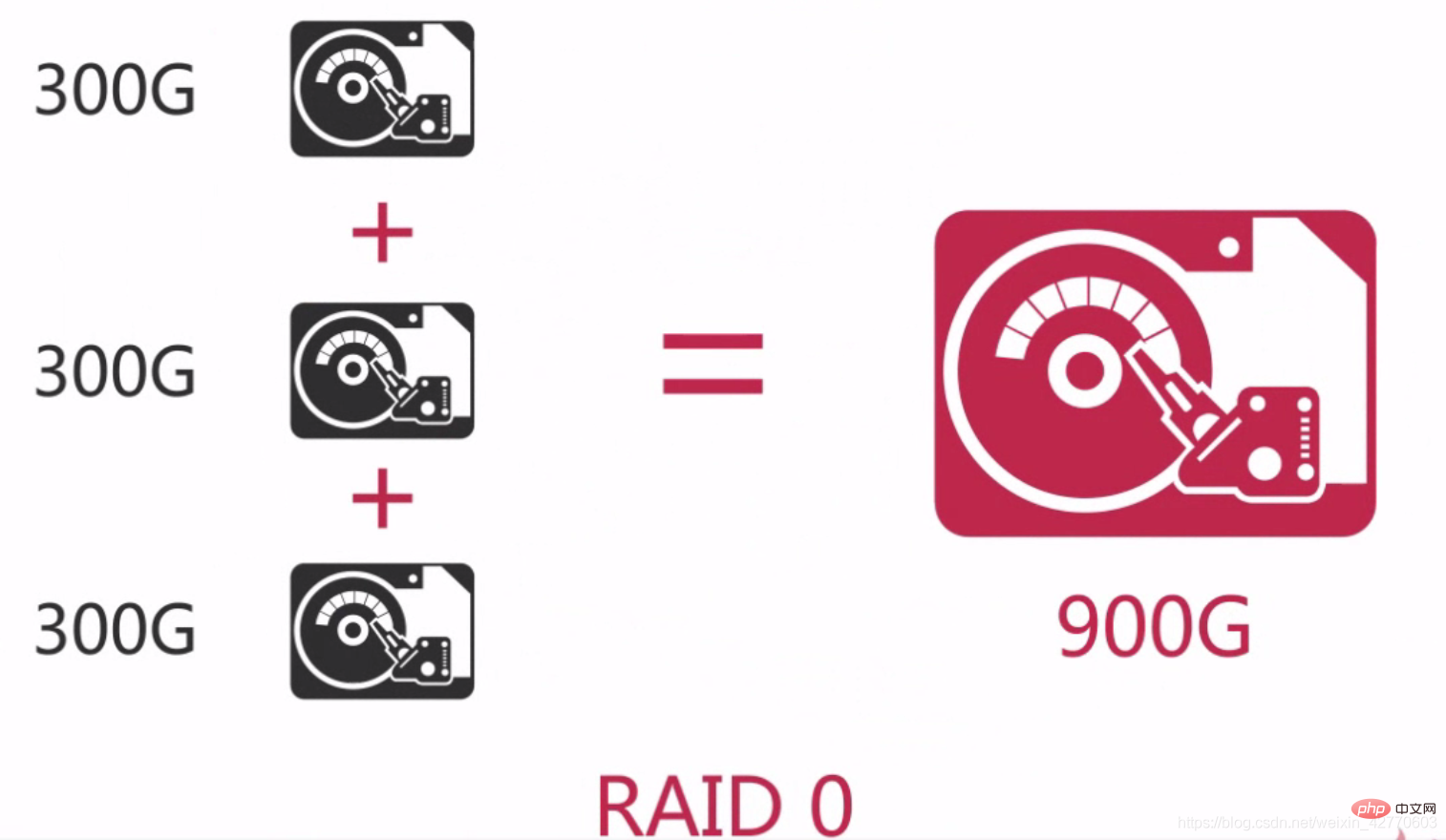
RAID 1 wird auch „Festplattenspiegelung“ genannt. Das Prinzip besteht darin, die Daten einer Festplatte auf eine andere Festplatte zu spiegeln werden auf eine andere Festplatte geschrieben. Generieren Sie Image-Dateien auf begrenzten Festplatten, um die Zuverlässigkeit und Reparierbarkeit des Systems zu maximieren, ohne die Leistung zu beeinträchtigen.
Nach dem Austausch einer neuen Festplatte nimmt die Datensynchronisierung viel Zeit in Anspruch. Der Datenzugriff wird dadurch zwar nicht beeinträchtigt, die Leistung des Systems wird jedoch beeinträchtigt. RAID 1 kann in vielen Fällen eine gute Leseleistung und redundante Daten zwischen verschiedenen Festplatten bieten, sodass die Datenredundanz sehr gut ist. RAID 1 kann besser lesen als RAID 0 und eignet sich daher besser zum Speichern von Protokollen oder ähnlichen Aufgaben.
2.2.2.2.3 RAID 5 – Gemeinsame RAID-Gruppe 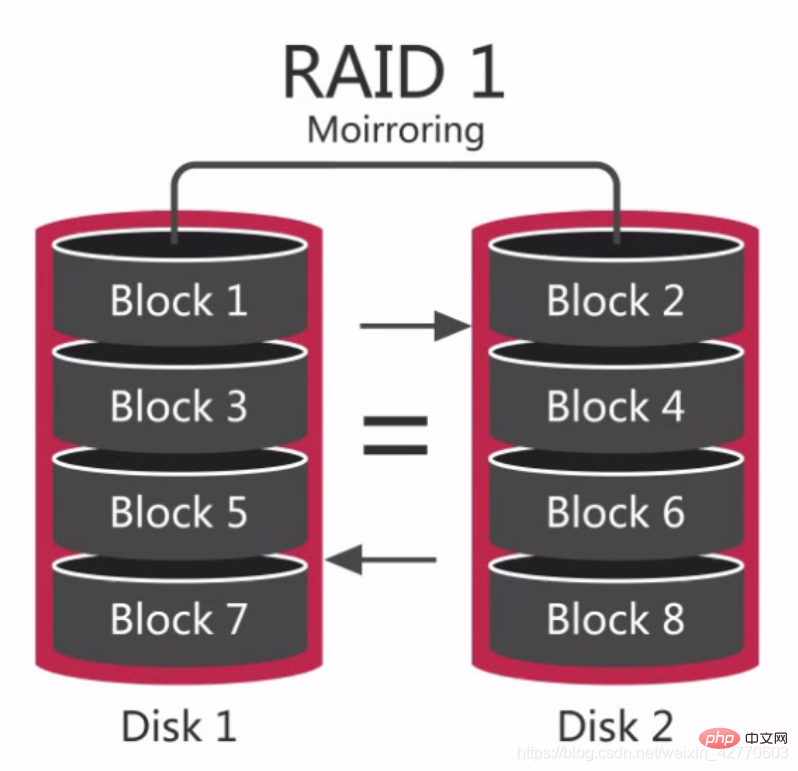
RAID 5 wird auch als Distributed Parity Disk Array bezeichnet. Die
Daten werden über verteilte Paritätsblöcke auf mehrere Festplatten verteilt
, sodass bei einem Datenausfall auf der Festplatte diese aus den Paritätsblöcken wiederhergestellt werden können. Wenn jedoch zwei Festplatten ausfallen, können die Daten des gesamten Volumes nicht wiederhergestellt werden.
Für RAID 0 und RAID 1 ist dies die wirtschaftlichste redundante Konfiguration, da die gesamte Array-Konfiguration nur die Kapazität von 1 Festplatte benötigt.
Das Schreiben ist auf RAID 5 langsamer, da für jeden Schreibvorgang zwei Lesevorgänge und zwei Schreibvorgänge zwischen den Festplatten erforderlich sind, um den Wert der gespeicherten Prüfziffer zu berechnen. Allerdings sind sowohl zufällige als auch sequentielle Lesevorgänge schnell, da beim Lesen keine Paritätsbits berechnet werden müssen RAID 5 eignet sich besser für lesebasierte Datenbankdienste. Das größte Problem bei RAID 5 besteht darin, dass die Festplatte ausfällt, da die Daten anderen Festplatten neu zugewiesen werden müssen, was die Leistung der Festplatte erheblich beeinträchtigt. Daher ist es am besten, bei erneutem Lesen RAID 5 zu verwenden. 2.2.2.2.4 RAID 10 – Häufig verwendete RAID-Gruppen 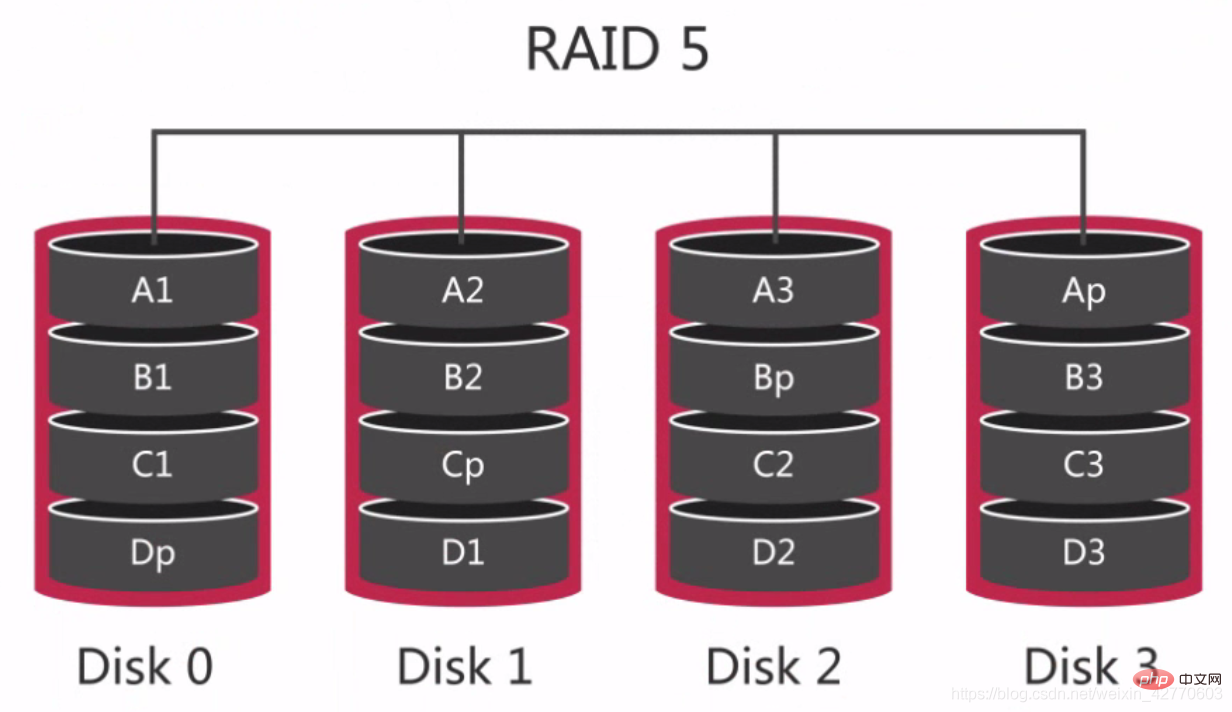 RAID 10 wird auch als Sliced Mirror bezeichnet. Es führt zuerst RAID 1 auf den Festplatten und dann RAID 0 auf den beiden Sätzen von RAID 1-Festplatten durch, sodass es im Vergleich zu RAID 5 eine gute Leistung beim Lesen und Schreiben aufweist und einfacher und schneller wiederhergestellt werden kann.
RAID 10 wird auch als Sliced Mirror bezeichnet. Es führt zuerst RAID 1 auf den Festplatten und dann RAID 0 auf den beiden Sätzen von RAID 1-Festplatten durch, sodass es im Vergleich zu RAID 5 eine gute Leistung beim Lesen und Schreiben aufweist und einfacher und schneller wiederhergestellt werden kann.
Wenn bei RAID 10 eine Festplatte beschädigt ist, hat dies schwerwiegende Auswirkungen auf die Leistung, da während des Lese- und Schreibvorgangs zwei benachbarte Festplatten gleichzeitig gelesen werden können. Wenn eine beschädigt ist, ist dies möglich nur von einer einzelnen Festplatte lesen, sodass unsere Leistung im schlimmsten Fall um 50 % sinkt.
2.2.2.3 Auswahl des RAID-Levels
| Level | Funktionen | Redundanz | Anzahl der Festplatten | Lesen | Schreiben |
|---|---|---|---|---|---|
| RAID 0 | Billig, schnell, gefährlich | Nein | N | Schnell | Schnell |
| RAID 1 | Schnelles Lesen, einfach und sicher | Ja | 2 | Schnell | Langsam |
| RAID 5 | Sicher, kostengünstig | Es gibt | N+1 | schnell | Hängt von der langsamsten Festplatte ab |
| RAID 10 | teuer, schnell, sicher | Es gibt | 2N | schnell | schnell |
2.2.3 Solid-State-Speicher SSD und PCIe-Karten verwenden
Solid-State-Speicher wird auch Flash-Speicher genannt.
Eigenschaften:
- Bessere zufällige Lese- und Schreibleistung als SSD mit mechanischer Festplatte
- Bessere Unterstützung für Parallelität als SSD mit mechanischer Festplatte
- Leichter zu beschädigen als SSD mit mechanischer Festplatte
SSD-Funktionen:
- Verwendung der SATA-Schnittstelle, traditionell Festplatten können ohne Änderungen ausgetauscht werden
- SSDs mit SATA-Schnittstelle unterstützen auch RAID-Technologie
Solid-State-Storage-PCIe-Kartenfunktionen:
- Die SATA-Schnittstelle kann nicht verwendet werden und erfordert spezielle Treiber und Konfigurationen
- Der Preis ist höher teurer als SSD, aber die Leistung ist besser als SSD
Nutzungsszenarien von Solid-State-Speichern
- Geeignet für Szenarien mit einer großen Anzahl zufälliger E/A
- Wird zur Lösung des E/A-Engpasses einzelner verwendet -Threaded Load
2.2.4 Verwendung von Netzwerkspeicher NAS und SAN
SAN (Strorage Area Network) und NAS (Network-Attached Storage) sind zwei Methoden zum Anschließen externer Dateispeichergeräte an den Server.
SAN:
Das SAN-Gerät ist über Glasfaser mit dem Server verbunden. Der Zugriff auf das Gerät erfolgt über die Blockschnittstelle und der Server kann es als Festplatte verwenden.

Funktionen von SAN: 
NAS:
NAS-Geräte nutzen Netzwerkverbindungen und der Zugriff erfolgt über dateibasierte Protokolle wie NFS oder SMB.
2.2.4.1 Szenarien für die Verwendung von Netzwerkspeicher
Geeignet für die Datenbanksicherung.
2.2.4.2 Einschränkungen der Netzwerkleistung
Die Einschränkungen der Netzwerkleistung sind hauptsächlich Latenz und Bandbreite.
2.2.4.3 Der Einfluss des Netzwerks auf die Leistung
- Der Einfluss der Netzwerkbandbreite auf die Leistung
- Der Einfluss der Netzwerkqualität auf die Leistung
Empfehlung:- Verwenden Sie leistungsstarke Netzwerkschnittstellengeräte und Switches mit hoher Bandbreite
- Um mehrere Netzwerkkarten zu binden, um Verfügbarkeit und Bandbreite zu verbessern
- Isolieren Sie das Netzwerk so weit wie möglich
2.3 Zusammenfassung
CPU:
- 64-Bit-CPU muss unter einem 64-Bit-System funktionieren
- Für Szenarien mit hoher Parallelität ist die Anzahl der CPUs wichtiger als die Frequenz. Je höher die Frequenz, desto besser:
- Wählen Sie den Speicher mit der höchsten Frequenz des Motherboards
Die Größe des Speichers ist wichtig für die Leistung, also machen Sie ihn so groß wie möglich
- PCIe -> RAID10 -> SAN
- MySQL geeignete Betriebssysteme: Windows, FreeBSD, Solaris, Linux
Kernelbezogene Parameter (/etc/sysctl.conf)
-
net.core.somaxconn = 65535net.core.somaxconn = 65535
对于处于一个监听状态的端口,都有一个自己的监听队列,这个参数决定了每个端口的监听队列的最大长度。这个参数的默认值可能会比较小,对于很大的服务器来说是不够的,一般会修改成2048或更大的值。 -
net.core.netdev_max_backlog=65535net.ipv4.tcp_max_syn_backlog=65535
其中backlog这个参数决定了在每个网络接口接收数据包的速率比内核处理机处理快的时候,允许被发送到队列中的数据包的最大的数目,而另一个参数了是决定了这些还未获得对方连接的这种请求可保存在队中的最大数目。对于超过这个值大小的连接可能会被抛弃,所以要同时调大一些。 -
net.ipv4.tcp_fin_timeout = 10
这个参数是用于控制tcp连接处理的等待状态的超时时间。对于连接比较频繁的系统,通常由大量的连接数处于等待状态,这个参数的设置就是减少连接超时的时间,加快tcp的回收速度。同样有对tcp连接有影响的参数有以下两个:net.ipv4.tcp_tw_reuse = 1、net.ipv4.tcp_tw_recycle = 1
这三个参数都是主要加快tcp的回收,在高负载的系统下,如果tcp连接被占满的话,就会出现连接数据库500的错误,因此这三个参数的作用是很大的。 -
net.core.wmem_default = 87380、net.core.wmem_max = 16777216、net.core.r0mem_default = 87380、net.core.rmem_max = 16777216
以上4个参数决定了tcp连接接收和发送缓冲区大小的默认值和最大值。对于数据库来说,应该把这几个参数的值调整的稍微大一些。 -
net.ipv4.tcp_keepalive_time = 120、net.ipv4.tcp_keepalive_intvl = 30、net.ipv4.tcp_keepalive_probes = 3
以上三个参数用于减少失效连接所占用的tcp系统资源的数量,加快资源回收的效率,net.ipv4.tcp_keepalive_time是表示tcp发送tcp_keepalive探测消息的时间的间隔,单位为秒, 用于确认tcp连接是否有效。net.ipv4.tcp_keepalive_intvl用于当探测这个tcp连接没有反应后,重新发送探测消息的时间间隔,单位为秒,net.ipv4.tcp_keepalive_probes表示在认定tcp连接失效之前,需要发送多少个tcp_keepalive探测消息。这三个参数的默认值对于一个平常系统来说稍微有点大了,所以这里分别对它们改为了小了一些。 -
kernel.shmmax = 4294967295
这个参数是Linux内核参数中最重要的参数之一,用于定义单个共享内存段的最大值。
注意:- 这个参数应该设置的足够大,以便能在一个共享内存段下容纳下整个的Innodb缓冲池的大小。
- 这个值的大小对于64为Linux系统,可取的最大值为物理内存值 - 1 byte,建议值为大于物理内存段的一半,一般取直大于Innodb缓冲池的大小即可,可以取物理内存 - 1 byte。
-
vm.swappiness = 0
这个参数当内存不足时会对性能产生比较明显的影响。这个参数就是告诉Linux系统内核除非虚拟内存完全满了,否则不要使用交换区。
Linux系统内存交换分区:
在Linux系统安装时都会有一个特殊的磁盘分区,称之为系统交换分区。如果我们使用free -m在系统中查看可以看到类似下面的内容,其中swap就是交换分区。当操作系统因为没有足够的内存时就会将一些虚拟内存写到磁盘的交换区中这样就会发生内存交换。
在MySQL服务所在的Linux系统上完全禁用交换分区,会带来以下两点风险:- 降低操作系统的性能
- 容易造成内存溢出,崩溃,或都被操作系统Kill掉
增加资源限制(/etc/security/limit.conf)limit.conf Für einen Port im Abhörstatus verfügt er über eine eigene Abhörwarteschlange. Dieser Parameter bestimmt die maximale Länge der Abhörwarteschlange für jeden Port. Der Standardwert dieses Parameters ist möglicherweise relativ klein, was für große Server nicht ausreicht. Er wird im Allgemeinen auf einen Wert von 2048 oder höher geändert. net.core.netdev_max_backlog=65535net.ipv4.tcp_max_syn_backlog=65535 Der Backlog-Parameter bestimmt die Anzahl der Datenpakete, die auf jeder Netzwerkschnittstelle empfangen werden. Die maximale Anzahl von Paketen, die an die Warteschlange gesendet werden dürfen, wenn die Rate schneller ist als die des Kernel-Prozessors, und ein weiterer Parameter bestimmt die maximale Anzahl solcher Anfragen, die noch keine Verbindung von der anderen Partei erhalten haben, die beibehalten werden kann die Warteschlange. Verbindungen, die diesen Wert überschreiten, werden möglicherweise verworfen. Erhöhen Sie daher gleichzeitig die Größe.
Der Backlog-Parameter bestimmt die Anzahl der Datenpakete, die auf jeder Netzwerkschnittstelle empfangen werden. Die maximale Anzahl von Paketen, die an die Warteschlange gesendet werden dürfen, wenn die Rate schneller ist als die des Kernel-Prozessors, und ein weiterer Parameter bestimmt die maximale Anzahl solcher Anfragen, die noch keine Verbindung von der anderen Partei erhalten haben, die beibehalten werden kann die Warteschlange. Verbindungen, die diesen Wert überschreiten, werden möglicherweise verworfen. Erhöhen Sie daher gleichzeitig die Größe. net.ipv4.tcp_fin_timeout = 10
Dieser Parameter wird verwendet, um die Timeout-Zeit des Wartezustands der TCP-Verbindungsverarbeitung zu steuern. Bei Systemen mit relativ häufigen Verbindungen befindet sich normalerweise eine große Anzahl von Verbindungen im Wartezustand. Die Einstellung dieses Parameters dient dazu, die Zeitüberschreitung der Verbindung zu verkürzen und das TCP-Recycling zu beschleunigen. Es gibt auch zwei Parameter, die sich auf TCP-Verbindungen auswirken:
net.ipv4.tcp_tw_reuse = 1, net.ipv4.tcp_tw_recycle = 1🎜 Diese drei Parameter sind es hauptsächlich Beschleunigt das TCP-Recycling. Wenn in einem Hochlastsystem die TCP-Verbindung voll ist, tritt ein Datenbankverbindungsfehler von 500 auf. Daher sind diese drei Parameter sehr wichtig. 🎜net.core.wmem_default = 87380, net.core.wmem_max = 16777216, net.core.r0mem_default = 87380, net.core.rmem_max = 16777216🎜 Die oben genannten 4 Parameter bestimmen die Standard- und Maximalwerte der Empfangs- und Sendepuffergrößen der TCP-Verbindung. Für die Datenbank sollten die Werte dieser Parameter etwas größer angepasst werden. 🎜net.ipv4.tcp_keepalive_time = 120, net.ipv4.tcp_keepalive_intvl = 30, net.ipv4.tcp_keepalive_probes = 3🎜 Die oben genannten drei Parameter werden verwendet, um die Menge der durch fehlgeschlagene Verbindungen belegten TCP-Systemressourcen zu reduzieren und die Effizienz des Ressourcenrecyclings zu beschleunigen. net.ipv4.tcp_keepalive_time stellt das Zeitintervall dar, in dem TCP tcp_keepalive-Erkennungsnachrichten sendet , in Sekundeneinheiten, wird verwendet, um zu bestätigen, ob die TCP-Verbindung gültig ist. net.ipv4.tcp_keepalive_intvl wird verwendet, um die Erkennungsnachricht erneut zu senden, nachdem festgestellt wurde, dass die TCP-Verbindung nicht geantwortet hat. Gibt an, wie viele tcp_keepalive-Erkennungsnachrichten gesendet werden müssen, bevor die TCP-Verbindung fehlschlägt. Die Standardwerte dieser drei Parameter sind für ein normales System etwas zu groß, daher werden sie hier auf kleinere Werte geändert. 🎜kernel.shmmax = 4294967295🎜 Dieser Parameter ist einer der wichtigsten Parameter in den Linux-Kernel-Parametern und wird verwendet, um den Maximalwert eines einzelnen Shared-Memory-Segments zu definieren. 🎜Hinweis: - 🎜Dieser Parameter sollte groß genug eingestellt werden, um die gesamte Größe des Innodb-Pufferpools in einem gemeinsam genutzten Speichersegment aufzunehmen. 🎜Für 64-Bit-Linux-Systeme ist der maximal mögliche Wert der physische Speicherwert – 1 Byte. Der empfohlene Wert ist größer als die Hälfte des physischen Speichersegments. Im Allgemeinen ist er größer als die Größe des Innodb-Puffers Pool. Es kann physischer Speicher sein - 1 Byte.
vm.swappiness = 0🎜 Dieser Parameter hat erhebliche Auswirkungen auf die Leistung, wenn nicht genügend Arbeitsspeicher vorhanden ist. Dieser Parameter weist den Linux-Systemkern an, den Swap-Bereich nicht zu verwenden, es sei denn, der virtuelle Speicher ist vollständig voll. 🎜Linux-Systemspeicher-Swap-Partition: 🎜 Wenn das Linux-System installiert ist, gibt es eine spezielle Festplattenpartition, die System-Swap-Partition genannt wird . Wenn wir free -m verwenden, um das System anzuzeigen, sehen wir etwas Ähnliches wie das Folgende, wobei swap die Swap-Partition ist. Wenn das Betriebssystem nicht über genügend Speicher verfügt, schreibt es etwas virtuellen Speicher in den Swap-Bereich der Festplatte und es kommt zu einem Speicheraustausch. 🎜 Das vollständige Deaktivieren der Swap-Partition auf dem Linux-System, auf dem sich der MySQL-Dienst befindet, birgt die folgenden zwei Risiken: - 🎜Verringerung der Leistung des Betriebssystems🎜Es kann leicht zu einem Speicherüberlauf, Absturz oder Vom Betriebssystem getötet
Ressourcenlimits erhöhen (/ etc/security/limit .conf) 🎜limit.conf Diese Datei ist eigentlich die Konfigurationsdatei von Linx PAM, dem Plug-in-Authentifizierungsmodul. 🎜 Eine der wichtigeren Parameterkonfigurationen ist die Begrenzung der Anzahl geöffneter Dateien. 🎜🎜🎜 Fazit: Erhöhen Sie die Anzahl der geöffneten Dateien auf 65535, um sicherzustellen, dass genügend Dateihandles geöffnet werden können. 🎜 Hinweis: Änderungen an dieser Datei müssen neu gestartet werden, damit sie wirksam werden. 🎜
Festplattenplanungsrichtlinie (/sys/block/devname/queue/scheduler)
Sie können den Befehl cat /sys/block/sda/queue/scheduler verwenden, um die von der aktuellen Festplatte verwendete Planungsrichtlinie anzuzeigen . Der folgende noop anticipatory termine [cfq] ist die standardmäßige cfq-Planungsrichtlinie des Systems. cat /sys/block/sda/queue/scheduler查看当前磁盘所使用的调度策略。下面的noop anticipatory deadline [cfq]为系统默认的cfq调度策略。
在MySQL数据库服务下,cfq并不合适,是由于在MySQL工作过程中,cfq会在队列中插入一些不必要的请求,导致很差的响应时间。
除了cfq调度策略,还有以下几种策略:
noop(电梯式调度策略):
deadline(截止时间调度策略):
anticipatory(预料I/O调度策略):
我们可以输入以下命令来改变磁盘的调度策略:echo schedulerName > /sys/block/sda/queue/scheduler
如:echo deadline > /sys/block/sda/queue/scheduler
4 文件系统对性能的影响
推荐使用XFS文件系统,在EXT3和EXT4下需要配置以下参数:
EXT3/4系统的挂载参数(/etc/fstab):
-
data=writeback | ordered | journal
这个参数一共有三个可选择的值,writeback表示只有元数据写入到日志,元数据写入和数据写入并不是同步的。这是一种最快的配置,因为InnoDB原本有自己的事务日志,所以通常是InnoDB最好的选择。ordered只会记录元数据,但提供了一些一致性的保证,在写元数据之前,会先写数据,使它们保持一致,这个选项比writeback稍微慢一点,但出现崩溃会更加安全。journal提供了原子日志的行为,在数据写入到最终的日志之前,将记录到日志中。这个选项对于InnoDB显然是没有必要的,也是三种中最慢的一种。 -
noatime、nodiratime
这两个选项用于记录文件的访问时间和读取目录的时间。设置了这两个参数可以减少一些写的操作。系统在读取文件和目录时也不必写操作来记录以上两个时间。
下面是文件/dev/sda1/ext4中的一些配置:noatime,nodiratime,data=writeback 1 1Unter dem MySQL-Datenbankdienst ist cfq nicht geeignet, da cfq während des Arbeitsprozesses von MySQL einige unnötige Anforderungen in die Warteschlange einfügt, was zu einer schlechten Antwortzeit führt.
noop (Aufzugsplanungsstrategie): Frist (Terminplanungsstrategie):
vorausschauend (erwartete E/A-Planungsstrategie): 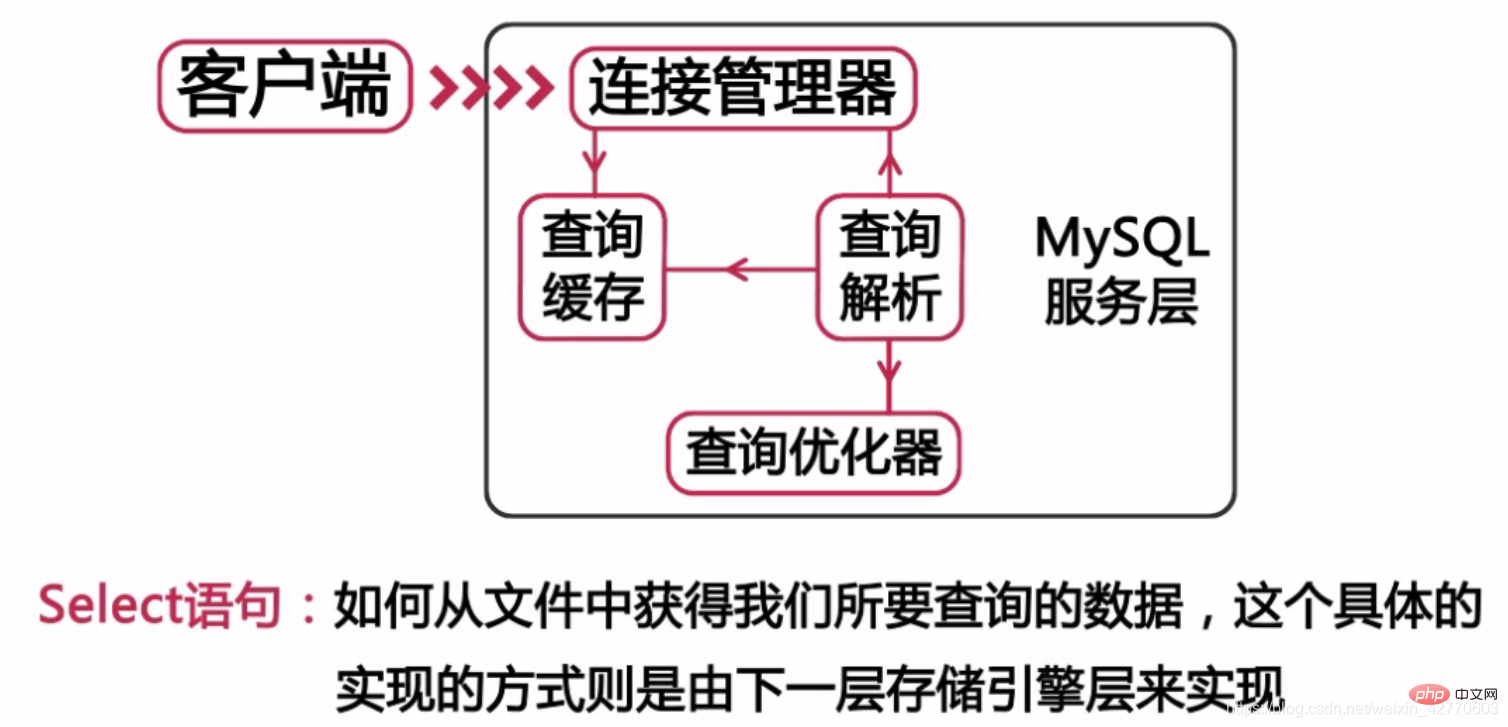
Wir können den folgenden Befehl eingeben, um die Festplattenplanungsrichtlinie zu ändern: echo SchedulerName > /sys/block/sda/queue/scheduler
For Beispiel: echo Deadline > /sys/block/sda/queue/scheduler 4 Die Auswirkung des Dateisystems auf die Leistung
4 Die Auswirkung des Dateisystems auf die Leistung
Es wird empfohlen, das XFS-Dateisystem zu verwenden Konfigurationen sind unter EXT3- und EXT4-Parametern erforderlich:
data=writeback | bestellt |. Dieser Parameter hat drei optionale Werte: <code>writebackCode> bedeutet, dass nur Metadaten in das Protokoll geschrieben werden und das Schreiben von Metadaten und Daten nicht synchronisiert ist. Dies ist die schnellste Konfiguration und normalerweise die beste Wahl für InnoDB, da InnoDB ursprünglich über ein eigenes Transaktionsprotokoll verfügt. <code>orderedzeichnet nur Metadaten auf, bietet jedoch einige Konsistenzgarantien. Vor dem Schreiben von Metadaten werden die Daten zuerst geschrieben, um sie konsistent zu machen. Diese Option ist etwas langsamer. aber sicherer vor Unfällen.journalstellt das Verhalten der atomaren Protokollierung bereit, bei der Daten im Protokoll aufgezeichnet werden, bevor sie in das endgültige Protokoll geschrieben werden. Diese Option ist für InnoDB offensichtlich unnötig und die langsamste der drei. 🎜-
noatime,nodiratime🎜 Diese beiden Optionen werden verwendet, um die Zugriffszeit der Datei und den Zeitpunkt des Lesens des Verzeichnisses aufzuzeichnen. Durch das Festlegen dieser beiden Parameter können einige Schreibvorgänge reduziert werden. Das System muss beim Lesen von Dateien und Verzeichnissen keine Schreibvorgänge ausführen, um die oben genannten beiden Zeiten aufzuzeichnen. 🎜 Im Folgenden sind einige Konfigurationen in der Datei/dev/sda1/ext4aufgeführt: 🎜noatime,nodiratime,data=writeback 1 1🎜🎜🎜🎜5 MySQL-Architektur 🎜🎜🎜 Die oberste Schicht der Architektur wird als Client bezeichnet. Diese Schicht stellt den Client dar, der über das MySQL-Verbindungsprotokoll wie PHP, JAVA, C API, .Net, ODBC, JDBC usw. eine Verbindung zu MySQL herstellen kann Hier ist diese Ebene nicht nur für die MySQL-Architektur gültig. Die meisten CS-Architekturdienste übernehmen diese Architektur. Diese Schicht übernimmt hauptsächlich einige Funktionen wie Verbindungsverarbeitung, Autorisierungsauthentifizierung und Sicherheit. Jeder mit MySQL verbundene Client hat einen Thread im Serverprozess. Die Abfrage dieser Verbindung wird nur in diesem Thread ausgeführt. Wie bereits erwähnt, verwendet jede Verbindungsabfrage nur einen CPU. 🎜 In der zweiten Schicht dieses Systems befinden sich dann die meisten Kern-MySQL-Dienste in dieser Schicht, wie in der folgenden Abbildung dargestellt. 🎜🎜🎜 Unsere häufig verwendeten DDL- oder DML-Anweisungen werden auf dieser Ebene definiert. Aber wir müssen uns nur eines merken. Alle speicherübergreifenden Engine-Funktionen werden in dieser Schicht implementiert, da diese Schicht auch als Serviceschicht bezeichnet wird. 🎜 Die dritte Schicht unseres Struktursystems ist die Speicher-Engine-Schicht. MySQL ist eine sehr hervorragende Open-Source-Datenbank, die eine Reihe von Speicher-Engine-Schnittstellen definiert. Solange sie die Anforderungen der Speicher-Engine erfüllt, können wir eine MySQL-Datenbank entwickeln . Wählen Sie eine Speicher-Engine, die Ihren Anforderungen vollständig entspricht, wie beispielsweise unsere häufig verwendete InnoDB. Derzeit werden viele Speicher-Engines von MySQL unterstützt, wie in der Abbildung unten dargestellt: 🎜🎜🎜🎜Hinweis🎜: Die Speicher-Engine ist eher für Tabellen gedacht als für Bibliotheken (Verschiedene Tabellen in einer Bibliothek können unterschiedliche Speicher-Engines verwenden) 🎜 Nachfolgend wählen wir einige der am häufigsten verwendeten Speicher-Engines für eine kurze Erklärung aus. Die von MySQL verwendete Speicher-Engine hat einen direkten Einfluss auf die Leistung der Datenbank. Ich hoffe, Sie können einige Funktionen der Speicher-Engine sorgfältig lesen und die Speicher-Engine erst verwenden, wenn Sie fertig sind. 🎜Weitere verwandte kostenlose Lernempfehlungen: MySQL-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonMYSQL Advanced für Big Data Learning. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Einführung in die Mitarbeiter der MySQL-Installationstestdatenbank
- Einführung der PHP7.3.5-Kapselungsklasse für den Zugriff auf die MySQL-Datenbank
- Zusammenfassung der häufigen MySQL-Fehleranalyse und -Lösungen
- Einführung des Bibliotheksverwaltungssystems basierend auf Java und MySQL
- Beherrschen Sie MYSQL Advanced