
Heim >Datenbank >MySQL-Tutorial >Zusammenfassung der Datenbanktransaktionen und MySQL-Transaktionen
Zusammenfassung der Datenbanktransaktionen und MySQL-Transaktionen

- coldplay.xixinach vorne
- 2020-12-30 16:33:522584Durchsuche
MySQL-TutorialZusammenfassung von Datenbanktransaktionen und MySQL-Transaktionen

Empfohlen (kostenlos): MySQL-Tutorial
Transaktionsfunktionen: ACID
Aus geschäftlicher Sicht Ja Eine Reihe von Operationen in der Datenbank ist erforderlich, um 4 Merkmale aufrechtzuerhalten:
- Atomizität: Eine Transaktion muss als unteilbare Mindestarbeitseinheit betrachtet werden. Alle Operationen in der gesamten Transaktion müssen entweder erfolgreich übermittelt werden oder alle fehlschlagen und ausgeführt werden Für eine Transaktion ist es unmöglich, nur einen Teil der Vorgänge auszuführen.
- Konsistenz: Die Datenbank wechselt immer von einem Konsistenzzustand in einen anderen. Folgende Bankbeispiele werden genannt.
- Isolation: Im Allgemeinen sind von einer Transaktion vorgenommene Änderungen für andere Transaktionen nicht sichtbar, bevor sie endgültig festgeschrieben werden. Beachten Sie hier das „Allgemeine“, das später in der Transaktionsisolationsstufe besprochen wird.
- Dauerhaftigkeit: Sobald eine Transaktion festgeschrieben wurde, werden ihre Änderungen dauerhaft in der Datenbank gespeichert. Selbst wenn das System zu diesem Zeitpunkt abstürzt, gehen die geänderten Daten nicht verloren. (Es besteht auch ein gewisser Zusammenhang zwischen der Persistenzsicherheit und der Aktualisierungsprotokollstufe. Unterschiedliche Stufen entsprechen unterschiedlichen Datensicherheitsstufen.)
Um ACID besser zu verstehen, nehmen Sie die Bankkontoüberweisung als Beispiel:
START TRANSACTION;SELECT balance FROM checking WHERE customer_id = 10233276;UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;COMMIT;
- Atomizität: Entweder vollständig festschreiben (der Prüfsaldo von 10233276 wird um 200 reduziert und der Sparsaldo wird um 200 erhöht) oder vollständig zurückgesetzt (die Salden beider Tabellen ändern sich nicht)
- Konsistenz: Die Konsistenz dieses Beispiels Dies spiegelt sich in der Tatsache wider, dass sich 200 Yuan nicht ändern, weil Nachdem das Datenbanksystem bis Zeile 3 ausgeführt wurde, stürzt es ab und verschwindet vor Zeile 4, da die Transaktion noch nicht festgeschrieben wurde.
- Isolierung: Die Betriebsanweisungen in einer Transaktion dürfen von den Anweisungen anderer Transaktionen isoliert werden. Wenn beispielsweise Transaktion A nach Zeile 3 und vor Zeile 4 ausgeführt wird und Transaktion B den Prüfsaldo abfragt, ist dies weiterhin möglich Beachten Sie, dass bei Transaktion A 200 Yuan abgezogen wurden (das Kontogeld bleibt unverändert), da die Transaktionen A und B voneinander isoliert sind. Bevor Transaktion A festgeschrieben wird, kann Transaktion B die Datenänderungen nicht beobachten.
- Beharrlichkeit: Das ist leicht zu verstehen.
- Die Isolierung von Transaktionen wird durch Sperren, MVCC usw. erreicht. (Zusammenfassung der MySQL-Sperren)
- Die Atomizität, Konsistenz und Haltbarkeit von Transaktionen werden durch Transaktionsprotokolle erreicht (siehe unten)
Isolationsebene von Transaktionen
Probleme, die durch gleichzeitige Transaktionen verursacht werden
- Verlorene Aktualisierung: Wenn zwei oder mehr Transaktionen aufgrund jeder Transaktion dieselbe Zeile auswählen und die Zeile dann basierend auf dem ursprünglich ausgewählten Wert aktualisieren, ohne die Existenz anderer Transaktionen zu kennen, Es tritt ein Problem mit verlorenen Aktualisierungen auf – die letzte Aktualisierung überschreibt die von anderen Transaktionen vorgenommenen Aktualisierungen. Beispielsweise erstellen zwei Redakteure elektronische Kopien desselben Dokuments. Jeder Redakteur ändert seine Kopie selbstständig und speichert dann die geänderte Kopie, wobei das Originaldokument überschrieben wird. Der Bearbeiter, der zuletzt eine Kopie seiner Änderungen gespeichert hat, überschreibt die von einem anderen Bearbeiter vorgenommenen Änderungen. Dieses Problem kann vermieden werden, wenn ein Editor nicht auf dieselbe Datei zugreifen kann, bis ein anderer Editor die Transaktion abschließt und festschreibt.
- Dirty Reads: Eine Transaktion ändert einen Datensatz, die Daten dieses Datensatzes befinden sich zu diesem Zeitpunkt in einem inkonsistenten Zustand; eine andere Transaktion liest ebenfalls denselben Datensatz liest diese „schmutzigen“ Daten und führt eine entsprechende Weiterverarbeitung durch, was zu nicht festgeschriebenen Datenabhängigkeiten führt. Dieses Phänomen wird treffend als „Dirty Reading“ bezeichnet.
- Nicht wiederholbare Lesevorgänge: Eine Transaktion liest die zuvor gelesenen Daten einige Zeit nach dem Lesen einiger Daten erneut und stellt dann fest, dass sich die gelesenen Daten geändert haben oder einige Der Datensatz wurde gelöscht! Dieses Phänomen wird als „nicht wiederholbares Lesen“ bezeichnet.
- Phantom-Lesevorgänge: Eine Transaktion liest zuvor abgerufene Daten gemäß denselben Abfragebedingungen erneut, stellt dann jedoch fest, dass andere Transaktionen neue Daten eingefügt haben, die ihre Abfragebedingungen erfüllen. Dieses Phänomen wird als „Phantom-Lesevorgänge“ bezeichnet.
Der Unterschied zwischen Phantomlesen und nicht wiederholbarem Lesen:
- Der Schwerpunkt des nicht wiederholbaren Lesens liegt auf der Änderung: In derselben Transaktion und unter denselben Bedingungen unterscheiden sich die zum ersten Mal gelesenen Daten von den zum zweiten Mal gelesenen Daten. (Da andere Transaktionen in der Mitte Änderungen übermittelt haben)
- Der Schwerpunkt des Phantomlesens liegt auf dem Hinzufügen oder Löschen: In derselben Transaktion und unter denselben Bedingungen ist die Anzahl der zum ersten und zweiten Mal ausgelesenen Datensätze unterschiedlich. (Da andere Transaktionen in der Mitte Einfügungen/Löschungen verursachten)
Lösungen für Probleme, die durch gleichzeitige Transaktionsverarbeitung verursacht werden:
„Update-Verlust“ sollte normalerweise vollständig vermieden werden. Das Verhindern von Aktualisierungsverlusten kann jedoch nicht allein durch den Datenbanktransaktionscontroller gelöst werden. Die Anwendung muss die erforderlichen Sperren für die zu aktualisierenden Daten hinzufügen. Daher sollte die Verhinderung von Aktualisierungsverlusten in der Verantwortung der Anwendung liegen.
"Dirty Read", "Non-Repeatable Read" und "Phantom Read" sind eigentlich Datenbank-Lesekonsistenzprobleme, die durch die Bereitstellung eines bestimmten Transaktionsisolationsmechanismus durch die Datenbank gelöst werden müssen:
Einer ist Sperren: Sperren Überprüfen Sie die Daten vor dem Lesen, um zu verhindern, dass andere Transaktionen die Daten ändern.
Das andere ist die Daten-Mehrversions-Parallelitätskontrolle (kurz MVCC oder MCC), auch bekannt als Mehrversionsdatenbank: Ohne das Hinzufügen von Sperren wird durch einen bestimmten Mechanismus ein konsistenter Daten-Snapshot des Datenanforderungszeitpunkts erstellt (Snapshot) und verwenden Sie diesen Snapshot, um eine bestimmte Ebene (Anweisungsebene oder Transaktionsebene) konsistenter Lesevorgänge bereitzustellen. Aus der Sicht des Benutzers scheint es, dass die Datenbank mehrere Versionen derselben Daten bereitstellen kann.
Der SQL-Standard definiert 4 Arten von Isolationsstufen. Jede Stufe gibt an, welche in einer Transaktion vorgenommenen Änderungen innerhalb und zwischen Transaktionen sichtbar und welche unsichtbar sind. Niedrigere Isolationsstufen unterstützen im Allgemeinen eine höhere Parallelität und haben einen geringeren Systemaufwand.
Stufe 1: Nicht festgeschriebenen Inhalt lesen (nicht festgeschriebenen Inhalt lesen)
- Alle Transaktionen können die Ausführungsergebnisse anderer nicht festgeschriebener Transaktionen sehen.
- Diese Isolationsstufe wird aufgrund ihrer Leistung in praktischen Anwendungen selten verwendet. Die Leistung ist nicht viel besser als andere Ebenen
- Das durch diese Ebene verursachte Problem ist - Dirty Read: Nicht festgeschriebene Daten werden gelesen
Ebene 2: Read Committed (lesen Sie den übermittelten Inhalt)
Dies ist für die meisten die Standardisolationsstufe Datenbanksysteme (jedoch nicht der MySQL-Standard)
Es erfüllt die einfache Definition von Isolation: Eine Transaktion kann nur Änderungen sehen, die von festgeschriebenen Transaktionen vorgenommen wurden
Das Problem mit dieser Isolationsstufe ist - Nicht wiederholbares Lesen: Nicht wiederholbares Lesen bedeutet dass wir möglicherweise unterschiedliche Ergebnisse sehen, wenn wir genau dieselbe Select-Anweisung in derselben Transaktion ausführen. Mögliche Gründe für diese Situation sind:
Es gibt eine Cross-Transaktion mit einem neuen Commit, die zu Datenänderungen führt.
Wenn eine Datenbank von mehreren Instanzen betrieben wird, befinden sich in dieser Instanz andere Instanzen derselben Transaktion Während der Verarbeitung kann es zu neuen Commits kommen
Stufe 3: Wiederholbares Lesen (wieder lesbar)
- Dies ist die Standard-Transaktionsisolationsstufe von MySQL
- Es stellt sicher, dass beim Abrufen mehrere Instanzen derselben Transaktion gleichzeitig gelesen werden Daten, Sie werden die gleichen Datenzeilen sehen.
- Mögliche Probleme auf dieser Ebene – Phantom-Lesen: Wenn der Benutzer einen bestimmten Bereich von Datenzeilen liest, fügt eine andere Transaktion eine weitere Datenzeile in den Bereich ein. Neue Zeilen, wenn Benutzer die Datenzeilen lesen In diesem Bereich finden sie neue „Phantom“-Zeilen, die das Phantom-Leseproblem durch den Multiversion-Parallelitätskontrollmechanismus (MVCC, Multiversion Concurrency Control) lösen
Mehrversions-Parallelitätskontrolle:Die meisten Transaktionsspeicher-Engine-Implementierungen von MySQL sind keine einfachen Sperren auf Zeilenebene. Basierend auf der Überlegung, die Parallelität zu verbessern, wird im Allgemeinen gleichzeitig die Multiversions-Parallelitätskontrolle (MVCC) implementiert, einschließlich Oracle und PostgreSQL. Die Implementierungen variieren jedoch.
MVCC wird implementiert, indem eine Momentaufnahme der Daten zu einem bestimmten Zeitpunkt gespeichert wird. Mit anderen Worten: Unabhängig davon, wie lange die Implementierung dauert, sind die von jedem Ding angezeigten Daten konsistent.
Es ist in optimistische Parallelitätskontrolle und pessimistische Parallelitätskontrolle unterteilt.
So funktioniert MVCC: InnoDBs MVCC wird implementiert, indem zwei versteckte Spalten hinter jeder Datensatzzeile gespeichert werden. Eine dieser beiden Spalten speichert die Erstellungszeit der Zeile und die andere speichert die Ablaufzeit (Löschzeit) der Zeile. Gespeichert wird natürlich nicht die Echtzeit, sondern die Systemversionsnummer. Bei jedem Start einer neuen Transaktion wird die Systemversionsnummer automatisch hinzugefügt. Die Systemversionsnummer zu Beginn der Transaktion wird als Versionsnummer der Transaktion verwendet, mit der die Versionsnummer jeder Datensatzzeile zum Vergleich abgefragt wird.
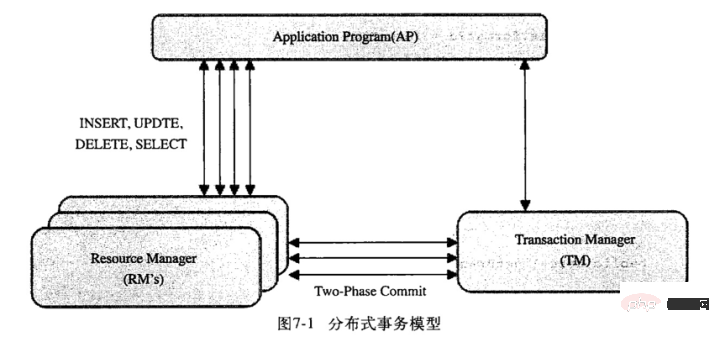
So funktioniert MVCC unter der Isolationsstufe REPEATABLE READ:InnoDB prüft jeden Zeilendatensatz gemäß den folgenden Bedingungen: Stufe 4: Serialisierbar Dies ist die höchste IsolationsstufeSie löst das Phantomleseproblem, indem Transaktionen so angeordnet werden, dass sie nicht miteinander in Konflikt geraten können. Kurz gesagt, es fügt jeder gelesenen Datenzeile eine gemeinsame Sperre hinzu. Zusammenfassung der MySQL-Sperre Jede spezifische Datenbank implementiert die oben genannten 4 Isolationsstufen nicht unbedingt vollständig. Beispiel: Derzeit sind die meisten Speicher-Engines auf diese Weise implementiert. Wir nennen es normalerweise Write-Ahead-Logging (Write-Ahead-Logging). 事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。 1.redo log 在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。 在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例: 记录1: 记录2: 记录3: 记录4: 记录5: 2.undo log undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。 以下是undo+redo事务的简化过程 假设有2个数值,分别为A和B,值为1,2 1. start transaction; 2. 记录 A=1 到undo log; 3. update A = 3; 4. 记录 A=3 到redo log; 5. 记录 B=2 到undo log; 6. update B = 4; 7. 记录B = 4 到redo log; 8. 将redo log刷新到磁盘 9. commit 在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。 所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。 Mysql中的事务使用 MySQL的服务层不管理事务,而是由下层的存储引擎实现。比如InnoDB。 MySQL支持本地事务的语句: 事务使用注意点: 自动提交(autocommit): InnoDB在事务执行过程中,使用两阶段锁协议: 随时都可以执行锁定,InnoDB会根据隔离级别在需要的时候自动加锁; 锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在同一时刻被释放。 InnoDB也支持通过特定的语句进行显示锁定(存储引擎层): MySQL Server层的显示锁定: (更多阅读:MySQL锁总结) MySQL对分布式事务的支持 分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。 MySQL 从 5.0.3 开始支持分布式事务,当前分布式事务只支持 InnoDB 存储引擎。一个分布式事务会涉及多个行动,这些行动本身是事务性的。所有行动都必须一起成功完成,或者一起被回滚。 如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM): 分布式事务采用两段式提交(two-phase commit)的方式: 分布式事务(XA 事务)的 SQL 语法主要包括: 虽然 MySQL 支持分布式事务,但是在测试过程中,还是发现存在一些问题: 如果分支事务在执行到 prepare 状态时,数据库异常,且不能再正常启动,需要使用备份和 binlog 来恢复数据,那么那些在 prepare 状态的分支事务因为并没有记录到 binlog,所以不能通过 binlog 进行恢复,在数据库恢复后,将丢失这部分的数据。 如果分支事务的客户端连接异常中止,那么数据库会自动回滚未完成的分支事务,如果此时分支事务已经执行到 prepare 状态, 那么这个分布式事务的其他分支可能已经成功提交,如果这个分支回滚,可能导致分布式事务的不完整,丢失部分分支事务的内容。
InnoDB speichert die aktuelle Systemversionsnummer als Zeilenversionsnummer für jede neu eingefügte Zeile.
InnoDB speichert die aktuelle Systemversionsnummer als Zeilenlöschung für jede gelöschte Zeile Identifikation
InnoDB speichert die aktuelle Systemversionsnummer als Zeilenversionsnummer für eine neu eingefügte Zeile und speichert die aktuelle Systemversionsnummer in der ursprünglichen Zeile als Löschkennung
MVCC funktioniert nur unter zwei Isolationsstufen: COMMITTED READ (Leseübermittlung) und REPEATABLE READ (wiederholbares Lesen). Sie können sich MVCC als eine Variante des Sperrens auf Zeilenebene vorstellen, aber es vermeidet in vielen Fällen Sperrvorgänge und hat einen geringeren Overhead. Obwohl die Implementierungsmechanismen verschiedener Datenbanken unterschiedlich sind, implementieren die meisten von ihnen nicht blockierende Lesevorgänge (Lesen erfordert keine Sperre und können nicht wiederholbare Lesevorgänge und Phantom-Lesevorgänge vermeiden), und Schreibvorgänge sperren nur die erforderlichen Zeilen (Schreiben muss gesperrt sein). ). Andernfalls führt das gleichzeitige Schreiben durch verschiedene Transaktionen zu Dateninkonsistenzen.
Auf dieser Ebene kann es zu einer großen Anzahl von Zeitüberschreitungen und Sperrkonkurrenz kommen

Die Implementierung von Transaktionen basiert auf der Speicher-Engine der Datenbank. Verschiedene Speicher-Engines bieten unterschiedliche Ebenen der Unterstützung für Transaktionen. Zu den Speicher-Engines, die Transaktionen in MySQL unterstützen, gehören innoDB und NDB.
START TRANSACTION | BEGIN [WORK] COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE] ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE] SET AUTOCOMMIT = {0 | 1}
tables 被执行。
务类型的表进行特别的处理,因为 COMMIT、ROLLBACK 只能对事务类型的表进行提交和回滚。
不同的 SAVEPOINT。需要注意的是,如果定义了相同名字的 SAVEPOINT,则后面定义的SAVEPOINT 会覆盖之前的定义。对于不再需要使用的 SAVEPOINT,可以通过 RELEASE SAVEPOINT 命令删除 SAVEPOINT, 删除后的 SAVEPOINT, 不能再执行 ROLLBACK TO SAVEPOINT命令。
Mysql默认采用自动提交模式,可以通过设置autocommit变量来启用或禁用自动提交模式select ... lock in share mode //共享锁 select ... for update //排他锁
lock table和unlock table
XA {START|BEGIN} xid [JOIN|RESUME]
如果分支事务在达到 prepare 状态时,数据库异常重新启动,服务器重新启动以后,可以继续对分支事务进行提交或者回滚得操作,但是提交的事务没有写 binlog,存在一定的隐患,可能导致使用 binlog 恢复丢失部分数据。如果存在复制的数据库,则有可能导致主从数据库的数据不一致。
总之, MySQL 的分布式事务还存在比较严重的缺陷, 在数据库或者应用异常的情况下,
可能会导致分布式事务的不完整。如果应用对于数据的完整性要求不是很高,则可以考虑使
用。如果应用对事务的完整性有比较高的要求,那么对于当前的版本,则不推荐使用分布式
事务。
Das obige ist der detaillierte Inhalt vonZusammenfassung der Datenbanktransaktionen und MySQL-Transaktionen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Zeichnen Sie die MySQL-Entwicklungsspezifikationen auf
- Lösen Sie die Probleme, die beim Upgrade des Docker-MySQL-Containers auf MySQL8 auftreten
- Vorheriger Artikel Analyse der MySQL-Anweisungssperre
- Detaillierte Erläuterung der Implementierung des MySQL-Verbindungspools basierend auf Swoole
- Verstehen Sie den GTID-basierten Replikationsmodus von MySQL