
Heim >Backend-Entwicklung >Python-Tutorial >Einführung in Python zum Crawlen von Bilibili-Videos
Einführung in Python zum Crawlen von Bilibili-Videos

- coldplay.xixinach vorne
- 2020-12-09 17:18:339509Durchsuche
Python-Video-Tutorial In der Spalte „Python-Video-Tutorial“ erfahren Sie, wie Sie Videos crawlen können
Dieser Artikel erklärt Ihnen hauptsächlich Let's Ich verwende Python, um Videos auf Bilibili zu crawlen. Erstens bin ich ein  Big-Data-Entwicklungsingenieur
Big-Data-Entwicklungsingenieur
abholen, Bitte stellen Sie den Link zum Originalartikel wieder her, wenn Sie es weiterleiten, danke 1. Umgebungsvorbereitung
Die Umgebung, die ich bin Die Verwendung hier dient nur als Referenz:
Entwicklungstools : PycharmPython-Umgebung: Python-3.8.0Abhängige Pakete: Shutil, OS, Re, Json, Choices, Requests, LXML
Zweitens: Seitenanalyse
Ich werde eine sehr lange Zeit in Anspruch nehmen. Nehmen wir als Beispiel das Video des beliebten Teacher Ma.
Video-Link: https://www.bilibili.com/video/BV1Ef4y1i78b?from=search&seid=12072538764197074893
Video-Link-Analyse Wir benötigen nur BV1Ef4y1i78b
, das sich hinter dem Video befindet? Nein. Der zweite Teil erfasst das Paket. Das
Video hier auf Bilibili ist in mehrere kurze Segmente unterteilt. Nachdem wir uns die Quellcode-Analyse angesehen haben, können wir <script analysieren der inhalt in> gibt einen JSON-String zurück und kann analysiert werden, um die gewünschten Daten zu erhalten. . <img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/2b9837f83bc78cc8e8824e900c7aa456-1.png" class="lazy" alt="Bildbeschreibung hier einfügen"/></script>
wird wie folgt an uns zurückgegeben:
Die für uns wirklich nützlichen Informationen sind in den Daten enthalten
- Unter den Daten können wir den gewünschten Inhalt deutlich sehen, z. B. die Videoqualität, die Videoadresse usw. Hinweis: Wenn Sie die Adresse erhalten und Wenn Sie direkt darauf zugreifen, können Sie nicht darauf zugreifen. Wenn Sie ohne Referrer direkt im Browser darauf zugreifen, können Sie die Seite nicht finden.
video后面? 号前面 - 第二部分抓包,哔哩哔哩这里的视频被分成多个小段了经过看源码分析后我们可以解析
<script></script>中的内容返回一个json串解析获取我们想要的数据即可。.
- 分析返回json中的具体内容

返回给我们的们如下,真正对我们有用的信息在data中
在data 下面我们就可以清晰的看到我们想要的内容了,如视频的画质,以及视频的地址等,注意:如果你拿到地址直接进行访问的话是访问不到了,哔哩哔哩中添加了Referer Der Inhalt, den wir analysieren müssen, ist wie folgt:
- Die Dauer des Videos
- Die Qualität des Videos
- Die URL des Videos
- Die URL des Audios
- Audio- und Video-Zusammenführung
-
3. Code-Übungen rreee

4. Zusammenfassung 到 Okay, wir werden das Video in Bilibili erfolgreich herauskriechen.
Verwandte kostenlose Lernempfehlungen:php-Programmierung
(Video)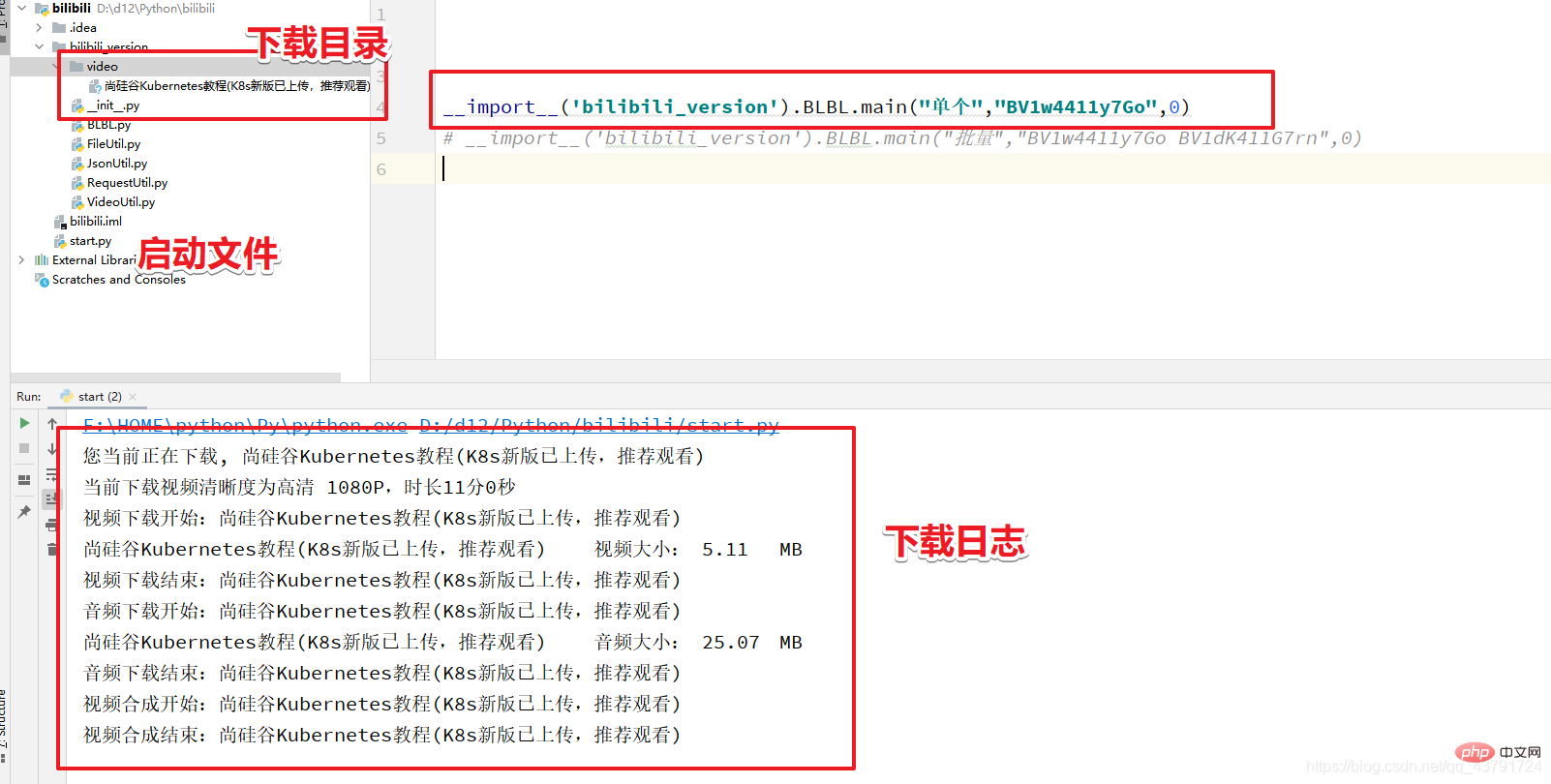
Das obige ist der detaillierte Inhalt vonEinführung in Python zum Crawlen von Bilibili-Videos. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in das Video-Crawling mit dem Python-Crawler
- Ist es schwierig, PHP zu lernen, nachdem man Python kennt?
- So lesen Sie eine TXT-Datei in Python
- Python implementiert verschiedene Optimierungsalgorithmen
- Eine kurze Diskussion darüber, wie Sie vscode zum Debuggen von Python-Code auf einem Mac verwenden