
Heim >Java >JavaInterview Fragen >Java-Interview – Datenstruktur
Java-Interview – Datenstruktur

- 王林nach vorne
- 2020-11-25 15:57:112155Durchsuche

Zu den gängigen Datenstrukturen gehören: Java-Interview – Datenstruktur, Hashtable, ConcurrentJava-Interview – Datenstruktur.
(Verwandte Videofreigabe: Java-Lehrvideo)
Lassen Sie uns sie separat vorstellen:
Java-Interview – Datenstruktur
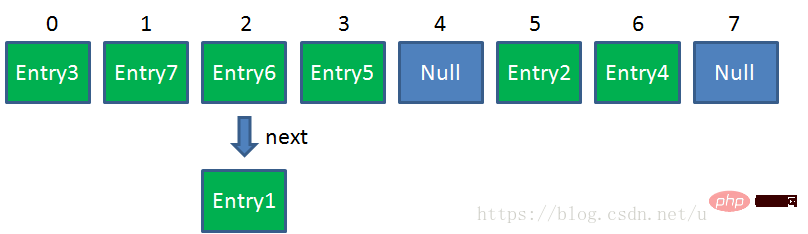
- Zugrunde liegende Implementierung: Die zugrunde liegende Gesamtstruktur von Java-Interview – Datenstruktur ist ein Array und jedes Element im Array Eine weitere verlinkte Liste. Jedes Mal, wenn ein Objekt (Put) hinzugefügt wird, wird ein verknüpftes Listenobjekt (Objekttyp) generiert. Jeder Eintrag in der Karte ist ein Element im Array (Map.Entry ist ein
<key>). code> ), der einen Verweis vom aktuellen Element auf das nächste Element enthält, das eine verknüpfte Liste bildet. </key> - 存储原理:当向HsahMap中添加元素的时候,首先计算Key对象的Hash值,得到数组下标,如果数组该位置为空则插入,否则遍历这个位置链表。当某个节点Key对象和Node对象均和新元素的equals时,用新元素的Value对象替换该节点的Value对象,否则插入新节点。(注意:JDK 8之后加入了红黑树)
<key></key>),它具有由当前元素指向下一个元素的引用,这就构成了链表。Java-Interview – Datenstruktur长度为2的n次幂是为了让length-1的二进制值所有位全为1,这种情况下,hash值与(table.length - 1)进行&运算计算index时,其结果就等同于hashcode后几位的值,此时只要输入的hashcode本身分布均匀,Hash算法的结果就是均匀的。所以,Java-Interview – Datenstruktur的默认长度为16是为了降低hash碰撞的几率,同时也是一种合适的大小。
Hashtable
| 比较点 | Java-Interview – Datenstruktur | Hashtable | |||
|---|---|---|---|---|---|
| 实现原理 | 见上小节 | 和Java-Interview – Datenstruktur的实现原理几乎一样 | |||
| Key和Value | 允许Key和Value为null | 不允许Key和Value为null | |||
| 扩容策略 | 2倍扩容oldThr
|
2倍+1扩容(oldCapacity Speicherprinzip: Berechnen Sie beim Hinzufügen von Elementen zu HsahMap zuerst den Hash-Wert des Schlüsselobjekts und rufen Sie den Array-Index ab. Wenn die Array-Position leer ist, fügen Sie ihn ein, andernfalls durchlaufen Sie die verknüpfte Liste an dieser Position. Wenn das Schlüsselobjekt und das Knotenobjekt eines Knotens beide gleich dem neuen Element sind, ersetzen Sie das Wertobjekt des Knotens durch das Wertobjekt des neuen Elements. Andernfalls fügen Sie einen neuen Knoten ein. (
| Hinweis|||
Hashtable
(oldCapacity 🎜🎜🎜🎜Sicherheit🎜🎜Thread-unsicher🎜🎜Thread-sicher 🎜🎜🎜🎜<blockquote><p>Die Implementierung der Hashtable-Thread-Sicherheitsstrategie ist sehr kostspielig. Alle zugehörigen Get/Put-Vorgänge sind synchronisiert und die Leistung ist in stark umkämpften Parallelitätsszenarien sehr schlecht. </p></blockquote>
<h3>ConcurrentJava-Interview – Datenstruktur</h3>
<p>ConcurrentJava-Interview – Datenstruktur ist eine threadsichere und effiziente Java-Interview – Datenstruktur-Implementierung, die im Java-Parallelitätspaket bereitgestellt wird. Sie verwendet eine sehr ausgefeilte <strong>Segmentsperre</strong>-Strategie. Das Segment erbt von ReentrantLock und ist eine Wiedereintrittssperre. Jedes Segment ist eine Sub-Hash-Tabelle, und im Segment wird ein HashEntry-Array verwaltet. In einer gleichzeitigen Umgebung muss bei der Verarbeitung von Daten aus verschiedenen Segmenten keine Sperrkonkurrenz berücksichtigt werden. </p>
<p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/041/936426dca161c51f1aba61a5982011b4-1.png" class="lazy" alt="ConcurrentJava-Interview – Datenstruktur"></p>
<h2>LinkedJava-Interview – Datenstruktur, TreeMap, TreeSet</h2>
<ul>
<li>LinkedJava-Interview – Datenstruktur: Sequentielle Zugriffs-Java-Interview – Datenstruktur (basierend auf Array- und doppelt verknüpfter Listenimplementierung). </li>
<li>TreeMap: Interne Sortierung (basierend auf der Rot-Schwarz-Baum-Implementierung). </li>
<li>TreeSet: Sammlung geordneter Mengen (basierend auf der Binärbaumimplementierung). </li>
</ul>
<h2>ArrayList, LinkedList, Vector</h2>
<ul>
<li>ArrayList: dynamisches Array (basierend auf der Array-Implementierung). </li>
<li>LinkedList: geordnetes Array (implementiert basierend auf einer doppelt verknüpften Liste). </li>
<li>Vektor: Objektcontainer, der Objekte unterschiedlichen Typs ablegen kann (implementiert basierend auf Arrays). </li>
</ul>
<h2>Sammlung und Sammlungen</h2>
<ul>
<li>Sammlung: Die übergeordnete Schnittstelle der Sammlungsklasse und die Unterschnittstellen umfassen hauptsächlich Liste, Satz, Warteschlange usw. </li>
<li>Sammlungen: Stellt Werkzeugklassen zum Suchen, Sortieren, Ersetzen und Thread-Sicherheitsoperationen für Sammlungen bereit. </li>
</ul>
<p> (Weitere verwandte Empfehlungen für Interviewfragen: <a href="https://www.php.cn/java/interview/" target="_blank">Java-Interviewfragen und -antworten</a>) </p>
<h1>Binärbaum</h1>
<h2>Gemeinsame Binärbaumkonzepte</h2>
<ul>
<li><p>B+-Baum: Siehe Datenbankabschnitt<em>https://blog.csdn.net/ u012102104/ Artikel/Details/79773362</em></p></li>
<li><p>Ausgeglichener Binärbaum (AVL-Baum): Der absolute Wert der Tiefendifferenz zwischen dem linken und rechten Teilbaum jedes Knotens überschreitet nicht 1. </p></li>
<li><p>Huffman-Baum: Der Binärbaum mit der kleinsten gewichteten Pfadlänge wird als optimaler Binärbaum bezeichnet. Die Huffman-Baumkonstruktion ist nicht eindeutig, aber die Summe der gewichteten Pfadlängen aller Blattknoten ist die kleinste. </p></li>
<li>
<p>Rot-Schwarz-Baum: Ein selbstausgleichender binärer Suchbaum, seine Eigenschaften sind: </p>
<ol>
<li>Knoten sind rot oder schwarz. </li>
<li>Der Wurzelknoten ist schwarz. </li>
<li>Jeder Blattknoten ist ein schwarzer leerer Knoten (NIL-Knoten). </li>
<li>Die beiden untergeordneten Knoten jedes roten Knotens sind schwarz. </li>
<li>Alle Pfade von jedem Knoten zu jedem seiner Blätter enthalten die gleiche Anzahl schwarzer Knoten. </li>
</ol>
<blockquote><p>Auf allen Pfaden von jedem Blatt zur Wurzel dürfen nicht zwei aufeinanderfolgende rote Knoten vorhanden sein</p></blockquote>
</li>
</ul>
|
Das obige ist der detaillierte Inhalt vonJava-Interview – Datenstruktur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:csdn.net. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen
Vorheriger Artikel:Java-Interview – Verarbeitung mit hoher ParallelitätNächster Artikel:Java-Interview – Verarbeitung mit hoher Parallelität