
Heim >Datenbank >MySQL-Tutorial >Grundlegendes zu physischen MySQL-Dateien
Grundlegendes zu physischen MySQL-Dateien

- coldplay.xixinach vorne
- 2020-11-16 17:02:592335Durchsuche
In der Spalte „MySQL-Tutorial“ werden physische MySQL-Dateien vorgestellt.
1. Datenbankdatenspeicherdatei
innodb_data_home_dir (Datenspeicherverzeichnis) und innodb_data_file_path (Konfiguration des Namens jeder Datei). > Mehrere ibdata-Dateien können gleichzeitig konfiguriert werden #innodb_data_file_path = ibdata1:2000M;ibdata2:10M:autoextend Die Konfigurationsmethoden für gemeinsam genutzten Tabellenbereich und exklusiven Tabellenbereich basieren auf der Speichermethode der Daten. Gemeinsamer Tabellenbereich: Alle Tabellendaten und Indexdateien einer bestimmten Datenbank werden in einer Datei abgelegt. innodb_data_home_dir(数据存放目录)和 innodb_data_file_path (配置每个文件的名称) 两个参数配置组成 innodb_data_file_path 中可以一次配置多个ibdata文件 #innodb_data_file_path = ibdata1:2000M;ibdata2:10M:autoextend 配置方式共享表空间以及独占表空间都是针对数据的存储方式而言的。
共享表空间: 某一个数据库的所有的表数据,索引文件全部放在一个文件中。
独占表空间: 每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有 一个.ibd文件。其中这个文件包括了 单独一个表的数据 内容以及索引内容。
4.1 两者对比
共享表空间:
优点: 可以放表空间分成多个文件存放到各个磁盘上。数据和文件放在一起方便管理。
缺点: 所有的数据和索引存放到一个文件中,多个表及索引在表空间中混合存储,这样对于一个表做了大量删除操作后表空间中将会有大量的空隙,特别是对于统计分析,日志系统这类应用最不适合用共享表空间。
独立表空间:
优点:
每个表都有自已独立的表空间。
每个表的数据和索引都会存在自已的表空间中。
可以实现单表在不同的数据库中移动。
-
空间可以回收
a)
Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodbExklusiver Tabellenbereich: Jede Tabelle wird in einer unabhängigen Datei generiert und gespeichert. Jede Tabelle verfügt über eine .frm-Tabellenbeschreibungsdatei und eine .ibd-Datei. Diese Datei enthält den Dateninhalt und den Indexinhalt einer einzelnen Tabelle.4.1 Vergleich zwischen den beiden
Gemeinsamer Tabellenbereich:
Vorteile: Der Tabellenbereich kann in mehrere Dateien aufgeteilt und dort gespeichert werden jede Festplatte. Daten und Dateien werden zur einfachen Verwaltung zusammengestellt.
Nachteile: Alle Daten und Indizes werden in einer Datei gespeichert, und mehrere Tabellen und Indizes werden gemischt und im Tabellenbereich gespeichert. Auf diese Weise entsteht eine große Anzahl von Löschvorgängen für eine Tabelle Anzahl der Lücken im Tabellenbereich, insbesondere für die statistische Analyse zeigt, dass Anwendungen wie Protokollierungssysteme für gemeinsam genutzte Tabellenbereiche höchst ungeeignet sind.
Unabhängiger Tabellenbereich:Vorteile:🎜
- 🎜Jeder Tisch verfügt über seinen eigenen unabhängigen Tabellenbereich. 🎜🎜
- 🎜Die Daten und Indizes jeder Tabelle werden in einem eigenen Tabellenbereich gespeichert. 🎜🎜
- 🎜Eine einzelne Tabelle kann zwischen verschiedenen Datenbanken verschoben werden. 🎜🎜
- 🎜Speicherplatz kann zurückgefordert werden🎜🎜a) Die Operation
Drop tablekann den Tabellenplatz automatisch zurückgewinnen. Für statistische Analysen oder Tageswerttabellen können Sie ihn nach dem Löschen einer großen Datenmenge verwenden :alter table TableName engine=innodb; Nicht genutzten Speicherplatz recyceln. 🎜🎜b) Bei Tabellen, die unabhängige Tabellenbereiche verwenden, hat die Fragmentierung des Tabellenbereichs unabhängig davon, wie sie gelöscht werden, keinen ernsthaften Einfluss auf die Leistung und es besteht immer noch die Möglichkeit, damit umzugehen. Nachteile: Die einzelne Tabelle ist zu groß, beispielsweise mehr als 100 G. Im Vergleich dazu sind die Effizienz und Leistung der Verwendung exklusiver Tabellenbereiche höher. Die Konvertierung zwischen gemeinsam genutzten Tabellenbereichen und unabhängigen Tabellenbereichen ist höher. 🎜🎜🎜show variables like "innodb_file_per_table"; ON代表独立表空间管理,OFF代表共享表空间管理; 修改数据库的表空间管理方式 修改innodb_file_per_table的参数值即可,但是修改不能影响之前已经 使用过的共享表空间和独立表空间; innodb_file_per_table=1 为使用独占表空间 innodb_file_per_table=0 为使用共享表空间复制代码🎜2. Protokolle🎜🎜🎜Protokolldateien: Abfrageprotokoll, langsames Abfrageprotokoll, Fehlerprotokoll, Transaktionsprotokoll, Binlog-Protokoll, Fehlerprotokoll, Relay-Protokoll🎜
2.1 查询日志
查询日志在mysql中被称之为 general log(通用日志),不要被"查询日志"的名字误导,错误的以为查询日志只会记录select语句,其实不然,查询日志记录了数据库执行的命令,不管这些语句是否正确,都会被记录,我想这也是 general log 之所以"通用"的原因吧,由于数据库操作命令有可能非常多而且执行比较频繁,所以当开启了查询日志以后,数据库可能需要不停的写入查询日志,这样会增大服务器的IO压力,增加很多系统开销,所以默认情况下,mysql的查询日志是没有开启的,但是开启查询日志也有助于我们分析哪些语句执行密集,执行密集的select语句对应的数据是否能够被缓存,查询日志也可以帮助我们分析问题,所以,我们可以根据实际情况决定是否开启查询日志,如果需要可以手动开启。如果开启了查询日志,那么我们可以通过如下3种方式存储查询日志。
方式1:将查询日志存放于指定的日志文件中。
方式2:将查询日志存放于
mysql.general_log表中。方式3:将查询日志同时存放于指定的日志文件与mysql库的general_log表中。
查看查询日志是否开启
show VARIABLES LIKE 'general_log';复制代码

show variables where variable_name like "%general_log%" or variable_name="log_output";复制代码

general_log:表示查询日志是否开启,ON表示开启,OFF表示未开启,默认为OFF
log_output:表示当查询日志开启以后,以哪种方式存放,log_output可以设置为4种值,"FILE"、"TABLE"、"FILE,TABLE"、"NONE"。
# 设置查询日志的输出方式 set global log_output=[none|file|table|file,table]; # 设置general log的日志文件路径 set global general_log_file='/tmp/general.log'; # 开启general log set global general_log=on; # 关闭general log set global general_log=off;复制代码
2.2 慢日志
所谓的慢查询就是通过设置来记录超过一定时间的SQL语句!
开启MySQL的慢查询日志功能
# 查看是否开启 未使用索引的SQL记录日志查询 show variables like 'log_queries_not_using_indexes'; # 开启 未使用索引的SQL记录日志查询 set global log_queries_not_using_indexs=on/off; # 查看超过多长时间的查询记入慢查询日志中 show variables like 'long_query_time'; # 设置记录时长,0为全部记录,设置之后需重新启动 set global long_query_time=10 # 查看是否开启 mysql慢查询日志功能 show variables like 'slow_qurey_log' # 开启、关闭慢日志 set global slow_qurey_log=on/off; # 查看日志记录位置 show variables like 'slow_query_log_file'; #日志存储方式 show variables like "log_output";复制代码
- flie方式
select sleep(10) 执行完成查看日志
# Time: 2020-10-26T05:12:09.564006Z # User@Host: root[root] @ localhost [] Id: 12 # Query_time: 10.000272 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 SET timestamp=1603689119; select sleep(10);复制代码
-
table方式

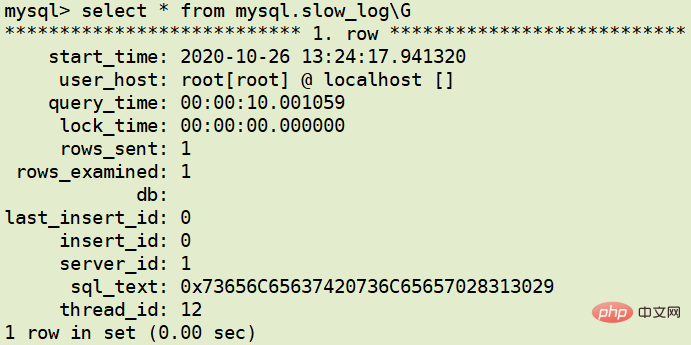
日志分析工具 mysqldumpslow
查看 mysqldumpslow 的帮助信息:
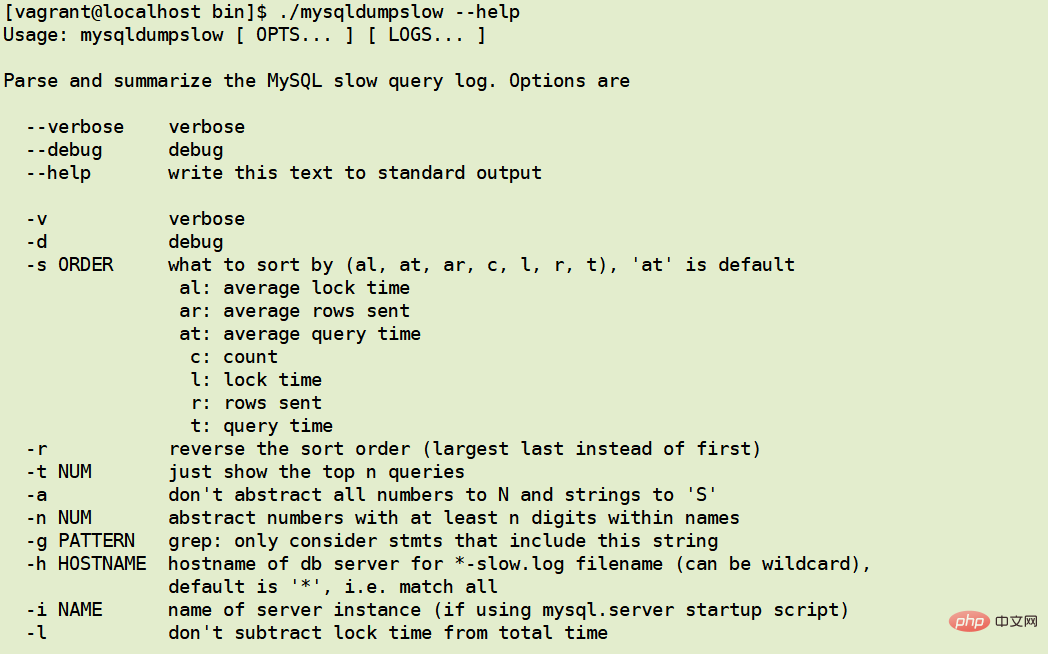
-s ORDER ORDER排序依据(al,at,ar,c,l,r,t),“at”是默认值 al: 平均锁定时间 ar: 平均发送行数 at: 平均查询时间 c: 计数 l: 锁定时间 r: 已发送行 t: 查询时间 -r 反转排序顺序(最大的最后一个而不是第一个) -t NUM 只显示前n个查询 -a 不要将所有数字抽象为N,将字符串抽象为“S” -n NUM 名字中至少有n个数字的抽象数字 -g PATTERN grep: 只考虑包含此字符串的记录 -h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard), default is '*', i.e. match all -i NAME name of server instance (if using mysql.server startup script) -l don't subtract lock time from total time复制代码
2.3 错误日志
错误日志(Error Log)是 MySQL 中最常用的一种日志,主要记录 MySQL 服务器启动和停止过程中的信 息、服务器在运行过程中发生的故障和异常情况等。
# 查看错误日志记录位置
show variables like "log_error";
# 在 MySQL 中,可以使用 mysqladmin 命令来开启新的错误日志,以保证 MySQL 服务器上的硬盘空间。
# mysqladmin 命令的语法如下:
mysqladmin -uroot -p flush-logs
# 执行该命令后,MySQL 服务器首先会自动创建一个新的错误日志,然后将旧的错误日志更名为 filename.err-old 。可以手动直接删除。
#配置文件中配置
[mysqld]
log-error=dir/{filename}复制代码
2.4 二进制日志
二进制日志(Binary Log)也可叫作变更日志(Update Log),是 MySQL 中非常重要的日志。主要用于记录数据库的变化情况,即 SQL 语句的 DDL 和 DML 语句,不包含数据记录查询操作。
# 查看 binary log 日志是否开启,binary log日志默认关闭
show variables like "log_bin";
# 在MySQL中可以再配置文件中开启二进制文件日志
[mysqld]
log-bin=dir/{filename}复制代码
其中,dir 参数指定二进制文件的存储路径;filename 参数指定二进制文件的文件名,其形式为 filename.number,number 的形式为 000001、000002 等,每次重启 MySQL 服务后,都会生成一个新的二进制日志文件,这些日志文件的文件名中 filename 部分不会改变,number 会不断递增。
二进制日志的格式有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
每一条会修改数据的 sql 语句会记录到 binlog 中。优点是并不需要记录每一条 sql 语句和每一行的数据变化, 减少了 binlog 日志量,节约 IO ,提高性能。缺点是在某些情况下会导致 master-slave 中的数据不一致(如 sleep() 函数, last_insert_id() ,以及 user-defined functions(udf) 等会出现问题)复制代码
② ROW模式(RBR)
不记录每条 sql 语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下 的存储过程、或 function 、或 trigger 的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是 alter table的时候会让日志暴涨。复制代码
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用 STATEMENT 模式保存 binlog ,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog , MySQL 会根据执行的 SQL 语句选择日志保存方式。复制代码
binlog复制配置
在mysql的配置文件 my.cnf 或中,可以通过一下选项配置 binary log
binlog_format = MIXED //binlog日志格式,mysql默认采用statement,建议使用mixed log-bin = mysql-bin //binlog日志文件 expire_logs_days = 7 //binlog过期清理时间 max_binlog_size = 100m //binlog每个日志文件大小 binlog_cache_size = 4m //binlog缓存大小 max_binlog_cache_size = 512m //最大binlog缓存大小 server-id = 1复制代码
2.5二进制文件基本操作
可以使用如下命令查看 MySQL 中有哪些二进制日志文件:
show binary logsshow master status命令用来查看当前的二进制日志;二进制日志使用二进制格式存储,不能直接打开查看。如果需要查看二进制日志,使用
show binlog events in 'mysql-bin.000001';命令。-
删除二进制文件
- 使用
RESET MASTER语句可以删除的所有二进制日志 - 每个二进制日志文件后面有一个 6 位数的编号,如 000001。使用
PURGE MASTER LOGS TO 'filename.number'语句,可以删除指定二进制日志的编号之前的日志 - 使用
PURGE MASTER LOGS TO 'yyyy-mm-dd hh:MM:ss'语句,可以删除指定时间之前创建的二进制日志
- 使用
-
使用二进制文件恢复数据
-
创建数据库
CREATE TABLE `33hao_activity` ( `activity_id` mediumint(9) NOT NULL AUTO_INCREMENT COMMENT 'id', `activity_title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '标题', `activity_type` enum('1','2') CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '活动类型 1:商品 2:团购', `activity_banner` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '活动横幅大图片', `activity_style` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '活动页面模板样式标识码', `activity_desc` varchar(1000) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '描述', `activity_start_date` int(10) UNSIGNED NOT NULL DEFAULT 0 COMMENT '开始时间', `activity_end_date` int(10) UNSIGNED NOT NULL DEFAULT 0 COMMENT '结束时间', `activity_sort` tinyint(1) UNSIGNED NOT NULL DEFAULT 255 COMMENT '排序', `activity_state` tinyint(1) UNSIGNED NOT NULL DEFAULT 1 COMMENT '活动状态 0为关闭 1为开启', PRIMARY KEY (`activity_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '活动表' ROW_FORMAT = Compact;复制代码 -
新增 2 条数据
INSERT INTO `33hao_activity` VALUES (1, '2017年跨年满即送活动', '1', '05364373801675235.jpg', 'default_style', '', 1483113600, 1483286400, 0, 0); INSERT INTO `33hao_activity` VALUES (2, '转盘抽奖弹窗', '1', '06480453986921327.jpg', '', '转盘抽奖弹窗', 1594656000, 1594915200, 0, 0);复制代码
-
删除数据
drop table `33hao_activity`;复制代码
-
恢复数据
-
根据节点需要我们查看日志文件提供给我们的数据库创建,表创建,数据新增等时创建的语句节点,从而恢复数据。
mysqlbinlog --start-position=154 --stop-position=2062 D:/phpstudy_pro/Extensions/MySQL5.7.26/data/mysql-bin.000001 | mysql -uroot -p复制代码
-
根据时间恢复数据
mysqlbinlog --start-datetime='2020-09-27 22:22:22' --stop-datetime='2020-09-27 22:30:00' /www/server/data/mysql-bin.000036 | mysql -uroot -p复制代码
-
直接执行binlog日志
mysqlbinlog /www/server/data/mysql-bin.000036 | mysql -uroot -p复制代码
-
-
更多相关免费学习推荐:mysql教程(视频)
Das obige ist der detaillierte Inhalt vonGrundlegendes zu physischen MySQL-Dateien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!