
Heim >Datenbank >MySQL-Tutorial >Mein Verständnis von MySQL fünf: Sperren und Sperrregeln
Mein Verständnis von MySQL fünf: Sperren und Sperrregeln

- coldplay.xixinach vorne
- 2020-11-11 17:10:282031Durchsuche
Die Spalte „MySQL-Tutorial“ stellt den fünften Artikel von MySQL vor, der sich mit Sperren und Sperrregeln beschäftigt.
Der fünfte Teil der MySQL-Reihe, der Hauptinhalt ist Sperre (Sperre), einschließlich granularer Klassifizierung von Sperren, Zeilensperren, Lückensperren und Sperrregeln.
Der Zweck der Einführung von Sperren durch MySQL besteht darin, das Problem des gleichzeitigen Schreibens zu lösen. Wenn beispielsweise zwei Transaktionen gleichzeitig in denselben Datensatz schreiben, führt dies zu einem Fehler Schreibproblem. Hierbei handelt es sich um jede Art von Ausnahme, die auf der Isolationsebene nicht auftreten darf. Die Funktion der Sperre besteht darin, die Ausführung zweier gleichzeitiger Schreibvorgänge in einer bestimmten Reihenfolge zu ermöglichen, um Probleme mit schmutzigen Schreibvorgängen zu vermeiden.
 Zunächst möchte ich feststellen, dass die in diesem Artikel verwendeten Beispiele
Zunächst möchte ich feststellen, dass die in diesem Artikel verwendeten Beispiele
 Zunächst möchte ich feststellen, dass die in diesem Artikel verwendeten Beispiele
Zunächst möchte ich feststellen, dass die in diesem Artikel verwendeten BeispieleCREATE TABLE `user` ( `id` int(12) NOT NULL AUTO_INCREMENT, `name` varchar(36) NULL DEFAULT NULL, `age` int(12) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `age`(`age`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1;insert into user values (5,'重塑',5),(10,'达达',10),(15,'刺猬',15);复制代码Die in diesem Artikel beschriebenen Beispiele unterliegen alle der MySQL InnoDB-Speicher-Engine und der Isolationsstufe „Repeatable Read“ (Wiederholbares Lesen).
1. Klassifizierung der Sperrgranularität
Aus Sicht der Sperrgranularität können Sperren in MySQL in drei Typen unterteilt werden: globale Sperren, Sperren auf Tabellenebene und Zeilensperren.
1.1 Globale SperreDie globale Sperre sperrt die gesamte Datenbank. Zu diesem Zeitpunkt befindet sich die Datenbank im schreibgeschützten Zustand. Alle Anweisungen, die die Datenbank ändern, umfassen DDL (Data Definition Language) und DML (Data Manipulation Language). Für Hinzufügungen, Löschungen und Änderungen werden Anweisungen blockiert, bis die globale Sperre der Datenbank aufgehoben wird.
Der häufigste Ort, an dem globale Sperren verwendet werden, ist die Durchführung einer
vollständigen Datenbanksicherung. Wir können die Sperrvorgänge globaler Sperren durch die folgenden Anweisungen implementieren:
-- 加全局锁flush tables with read lock;-- 释放全局锁unlock table;复制代码Wenn die Clientverbindung getrennt wird, wird dies automatisch der Fall sein Geben Sie die globale Sperre frei.
1.2 Sperre auf TabellenebeneSperre auf Tabellenebene sperrt die gesamte Tabelle. Zu den Sperren auf Tabellenebene in MySQL gehören:
Tabellensperre,AbsichtssperreMetadatensperre
(Metadatensperre),
( Absichtssperre). ) und
Auto-Inkrement-Sperre (AUTO-INC-Sperre). 1.2.1 TabellensperreSo sperren und lösen Sie die Tabellensperre: Sperren: Tabelle sperren, Tabellenname lesen/schreiben;Sperre aufheben: entsperren Tabelle;
Tabellenbenutzer sperren). read), dann kann in derselben Clientverbindung dieselbe Tabelle (Benutzertabelle) nur gelesen und nicht geschrieben werden, bevor die Lesesperre auf Tabellenebene aufgehoben wird, während in anderen Clientverbindungen nur Lesevorgänge ausgeführt werden können auf dieser Tabelle (Benutzertabelle) und Schreibvorgänge können nicht ausgeführt werden. Wenn eine Schreibsperre auf Tabellenebene (lock table user write) hinzugefügt wird, kann die Tabelle in derselben Clientverbindung gelesen und geschrieben werden, andere Clientverbindungen können jedoch weder lesen noch schreiben Operationen.
1.2.2 MetadatensperreDie zweite Art der Sperre auf Tabellenebene ist die - Metadatensperre
lock table tableName read/write;
- 释放锁:
unlock table;
lock table tableName read/write;
unlock table;
需要注意的是,表锁的加锁也限制了同一个客户端链接的操作权限,如加了表级读锁(lock table user read),那么在同一个客户端链接中在释放表级读锁以前,对同一张表(user 表)也只能进行读操作,无法进行写操作,而其他客户端链接对该表(user 表)只能进行读操作,无法进行写操作。
如加了表级写锁(lock table user write),在同一个客户端链接中可对表进行读写操作,而其他客户端链接既无法进行读操作也无法进行写操作。
1.2.2 元数据锁
第二种表级锁是元数据锁(MDL, Meta Data Lock),元数据锁会在客户端访问表的时候自动加锁,在客户端提交事务时释放锁,它防止了以下场景出现的问题:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user; | |
| alter table user add column birthday datetime; | |
| select * from user; |
如上表,sessionA 开启了一个事务,并进行一次查询,在这之后另外一个客户端 sessionB 给 user 表新增了一个 birthday 字段,然后 sessionA (MDL, Metadatensperre), die auf die Tabelle auf dem Client zugreift Seite Die Sperre wird automatisch gesperrt, wenn der Client die Transaktion übermittelt, was Probleme in den folgenden Szenarien verhindert:
sessionB
| Tabellenbenutzer ändern, Spalte Geburtstag, Datum und Uhrzeit hinzufügen; | |
例如,sessionA 开启了一个事务,并对 id=5 这一行加上了行级排它锁,此时 sessionB 将对 user 表加上表级排它锁(只要 user 表中有一行被其他事务持有读锁或写锁即加锁失败)。
如果没有意向锁,sessionB 将扫描 user 表中的每一行,判断它们是否被其他事务加锁,然后才能得出 sessionB 的此次表级排它锁加锁是否成功。
而有了意向锁之后,在 sessionB 将对 user 表加锁时,会直接判断 user 表是否被其他事务加上了意向锁,若有则加锁失败,若无则可以加上表级排它锁。
意向锁的加锁规则:
- 事务在获取行级共享锁(S锁)前,必须获取表的意向共享锁(IS锁)或意向排它锁(IX锁)
- 事务在获取行级排它锁(X锁)前,必须获取表的意向排它锁(IX锁)
1.2.4 自增锁
第四种表级锁是自增锁,这是一种特殊的表级锁,只存在于被设置为 AUTO_INCREMENT 自增列,如 user 表中的 id 列。
自增锁会在 insert 语句执行完成后立即释放。同时,自增锁与其他事务的意向锁可共享,与其他事务的自增锁、共享锁和排它锁都是不兼容的。
1.3 行锁
行锁是由存储引擎实现的,从行锁的兼容性来看,InnoDB 实现了两种标准行锁:共享锁(Shared Locks,简称S锁)和排它锁(Exclusive Locks,简称X锁)。
这两种行锁的兼容关系与上面元数据锁的兼容关系是一样的,可以用下面的表格表示。
| 事务A\事务B | 共享锁(S锁) | 排它锁(X锁) |
|---|---|---|
| 共享锁(S锁) | 兼容 | 冲突 |
| 排它锁(X锁) | 冲突 | 冲突 |
而从行锁的粒度继续细分,又可以分为记录锁(Record Lock)、间隙锁(Gap Lock)、Next-key Lock。
1.3.1 记录锁(Record Lock)
我们一般所说的行锁都是指记录锁,它会把数据库中的指定记录行加上锁。
假设事务A中执行以下语句(未提交):
begin;update user set name='达闻西' where id=5;复制代码
InnoDB 至少会在 id=5 这一行上加一把行级排它锁(X锁),不允许其他事务操作 id=5 这一行。
需要注意的是,这把锁是加在 id 列的主键索引上的,也就是说行级锁是加在索引上的。
假设现在有另一个事务B想要执行一条更新语句:
update user set name='大波浪' where id=5;复制代码
这时候,这条更新语句将被阻塞,直到事务A提交以后,事务B才能继续执行。
1.3.2 间隙锁(Gap Lock)
间隙锁,顾名思义就是给记录之间的间隙加上锁。
需要注意的是,间隙锁只存在于可重复读(Repeatable Read)隔离级别下。
不知道大家还记不记得幻读?
幻读是指在同一事务中,连续执行两次同样的查询语句,第二次的查询语句可能会返回之前不存在的行。
间隙锁的提出正是为了防止幻读中描述的幻影记录的插入而提出的,举个例子。
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where age=5;(N1) | |
| insert into user values(2, '大波浪', 5) | |
| update user set name='达闻西' where age=5; | |
| select * from user where age=5;(N2) |
sessionA 中有两处查询N1和N2,它们的查询条件都是 age=5,唯一不同的是在N2处的查询前有一条更新语句。
照理说在 RR 隔离级别下,同一个事务中两次查询相同的记录,结果应该是一样的。但是在经过更新语句的当前读查询后(更新语句的影响行数是2),N1和N2的查询结果并不相同,N2的查询将 sessionB 插入的数据也查出来了,这就是幻读。
而如果在 sessionA 中的两次次查询都用上间隙锁,比如都改为select * from user where age=5 for update。那么 sessionA 中的当前读查询语句至少会将id在(-∞, 5)和(5, 10)之间的间隙加上间隙锁,不允许其他事务插入主键id属于这两个区间的记录,即会将 sessionB 的插入语句阻塞,直到 sessionA 提交之后,sessionB 才会继续执行。
也就是说,当N2处的查询执行时,sessionB 依旧是被阻塞的状态,所以N1和N2的查询结果是一样的,都是(5,重塑,5),也就解决了幻读的问题。
1.3.3 Next-key Lock
Next-key Lock 其实就是记录锁与记录锁前面间隙的间隙锁组合的产物,它既阻止了其他事务在间隙的插入操作,也阻止了其他事务对记录的修改操作。
2. 加锁规则
不知道大家有没有注意到,我在行锁部分描述记录锁、间隙锁加锁的具体记录时,用的是「至少」二字,并没有详细说明具体加锁的是哪些记录,这是因为记录锁、间隙锁和 Next-key Lock 的加锁规则是十分复杂的,这也是本文主要讨论的内容。
关于加锁规则的叙述将分为三个方面:唯一索引列、普通索引列和普通列,每一方面又将细分为等值查询和范围查询两方面。
需要注意的是,这里加的锁都是指排它锁。
在开始之前,先来回顾一下示例表以及表中可能存在的行级锁。
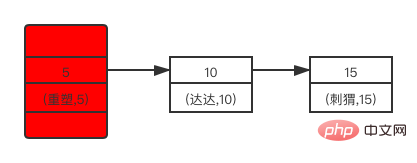
mysql> select * from user; +----+--------+------+| id | name | age | +----+--------+------+| 5 | 重塑 | 5 | | 10 | 达达 | 10 | | 15 | 刺猬 | 15 | +----+--------+------+3 rows in set (0.00 sec)复制代码
表中可能包含的行级锁首先是每一行的记录锁——(5,重塑,5),(10,达达,5),(15,刺猬,15)。
假设 user 表的索引值有最大值 maxIndex 和最小值 minIndex,user 表还可能存在间隙锁(minIndex,5),(5,10),(10,15),(15,maxIndex)。
共三个记录锁和四个间隙锁。
2.1 唯一索引列等值查询
首先来说唯一索引列的等值查询,这里的等值查询可以分为两种情况:命中与未命中。
当唯一索引列的等值查询命中时:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where id=5 for update; | |
| insert into user values(1,'斯斯与帆',1),(6,'夏日阳光',6),(11,'告五人',11),(16,'面孔',16); | |
| update user set age=18 where id=5;(Blocked) | |
| update user set age=18 where id=10; | |
| update user set age=18 where id=15; |
Das Ausführungsergebnis von sessionB in der obigen Tabelle ist, dass mit Ausnahme der Update-Anweisung der Zeilen-ID=5, die blockiert ist, andere Anweisungen normal ausgeführt werden. sessionB 的执行结果是除了 id=5 行的更新语句被阻塞,其他语句都正常执行。
sessionB 中的 insert 语句是为了检查间隙锁,update 语句是为了检查记录锁(行锁)。执行结果表明 user 表的所有间隙都没有被上锁,记录锁中只有 id=5 这一行被上锁了。
所以,当唯一索引列的等值查询命中时,只会给命中的记录加锁。
当唯一索引列的等值查询未命中时:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where id=3 for update; | |
| insert into user values (2,'反光镜',2);(Blocked) | |
| update user set age=18 where id=5; | |
| insert into user values (6,'夏日阳光',6); | |
| update user set age=18 where id=10; | |
| insert into user values (11,'告五人',11); | |
| update user set age=18 where id=15; | |
| insert into user values (16,'面孔',16); |
上表的执行结果是 sessionB 中 id=2 的记录插入被阻塞,其他语句正常执行。
根据执行结果可以知道 sessionA 给 user 表加的锁是间隙锁(1,5)。
所以,当唯一索引列的等值查询未命中时,会给id值所在的间隙加上间隙锁。
2.2 唯一索引列范围查询
范围查询比等值查询要更复杂一些,它需要考虑到边界值存在于表中,以及是否命中边界值。
首先来看边界值存在于表中,但未命中的情况:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where id | |
| insert into user values (1,'斯斯与帆',1);(Blocked) | |
| update user set age=18 where id=5;(Blocked) | |
| insert into user values (6,'夏日阳光',6);(Blocked) | |
| update user set age=18 where id=10;(Blocked) | |
| insert into user values (11,'告五人',11); | |
| update user set age=18 where id=15; | |
| insert into user values (16,'面孔',16) ; |
此时 sessionA 给 user 表加上的锁是记录锁 id=5,id=10 以及间隙锁(minIndex,5),(5,10)。
我们知道间隙锁+记录锁就是 Next-key Lock,所以上述的加锁情况可以看作是两条 Next-key Lock:(minIndex, 5],(5,10],即 Next-key Lock
sessionB dient zur Überprüfung der Lückensperre und die Aktualisierungsanweisung zur Überprüfung der Datensatzsperre (Zeilensperre). Die Ausführungsergebnisse zeigen, dass nicht alle Lücken in der Benutzertabelle gesperrt sind und nur die Zeile mit der ID = 5 in der Datensatzsperre gesperrt ist. 

Wenn also die entsprechende Abfrage der eindeutigen Indexspalte trifft, sperrt
nur den Trefferdatensatz
.| ) |
|
| |
In Benutzerwerte einfügen (6,'Sommersonne',6); |
| Benutzersatzalter=18 aktualisieren, wobei ID=10; | |
|
In Benutzer einfügen Werte (11,'Sue five people',11); |
|
| In Benutzerwerte einfügen (16,'Gesicht' ,16) ; | |
| Anhand der Ausführungsergebnisse können wir erkennen, dass die von |

2.2 Eindeutige Indexspaltenbereichsabfrage
🎜Bereichsabfrage ist komplexer als Gleichwertabfrage Es muss berücksichtigt werden, dass der Grenzwert in der Tabelle vorhanden ist und ob Die Grenze ist erreicht. 🎜🎜Schauen wir uns zunächst die Situation an, in der der Grenzwert in der Tabelle vorhanden ist, aber fehlt: 🎜🎜🎜🎜🎜sessionA🎜🎜sessionB🎜🎜🎜🎜🎜🎜begin;🎜🎜🎜🎜🎜🎜🎜select * from wo ID sessionA ist eine Datensatzsperreid =5,id=10 und eine Lückensperre (minIndex,5),(5,10). 🎜🎜Wir wissen, dass Lückensperre + Datensatzsperre Next-Key-Sperre ist, daher kann die obige Sperrsituation als zwei Next-Key-Sperre betrachtet werden: (minIndex, 5 ] ,(5,10], also Next-key Lock - (minIndex,10]. 🎜🎜🎜🎜🎜🎜Wenn der Grenzwert in der Tabelle vorhanden ist und gleichzeitig trifft: 🎜 🎜🎜 🎜🎜sessionA🎜🎜sessionB🎜🎜🎜🎜🎜🎜begin;🎜🎜🎜🎜🎜🎜🎜select * from user where id此时 sessionA 给 user 表加上的锁是Next-key Lock —— (minIndex,15]。
当边界值不存在于表中时,不可能命中,故只有未命中一种情况:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where id | |
| insert into user values (1,'斯斯与帆',1);(Blocked) | |
| update user set age=18 where id=5;(Blocked) | |
| insert into user values (6,'夏日阳光',6);(Blocked) | |
| update user set age=18 where id=10;(Blocked) | |
| insert into user values (11,'告五人',11); | |
| update user set age=18 where id=15; | |
| insert into user values (16,'面孔',16) ; |
此时 sessionA 给 user 表加上的锁是 Next-key Lock —— (minIndex,10],与第一种情况一样。
综上所述,在对唯一索引进行范围查询时:
- 会给范围中的记录加上记录锁,间隙加上间隙锁
- 对于范围查询(大于/大于等于/小于/小于等于)是比较特殊的,它会将记录锁加到第一个边界之外的记录上,若其中有额外的间隙也会加上间隙锁(即会将
Next-key Lock加到第一个边界之外的记录上)
需要注意的是,第一条中所说的间隙指的是,边界值所在的间隙,如间隙为(5,10),查询条件为 id>7 时,这个间隙锁就是(5,10),而不是(7,10)。
第二条举例1:查询条件为 idNext-key Lock 锁会加到 id=10 的记录上,被锁住的范围是(minIndex,10]。
第二条举例2:查询条件为 idNext-key Lock 锁会加到 id=15 的记录上,被锁住的范围是(minIndex,15]。
第二条举例3:查询条件为 id>10,第一个边界之外的记录是 id=10,
Next-key Lock锁会加到 id=10 的记录上,由于Next-key Lock锁指的是记录以左的部分,所以被锁住的范围是(5,maxIndex]。
2.3 普通索引列等值查询
普通索引与唯一索引的区别就在于唯一索引可以根据索引列确定唯一性,所以等值查询的加锁规则也有不同之处。
给 user 表再加一条记录:
INSERT INTO user VALUES (11, '达达2.0', 10);复制代码
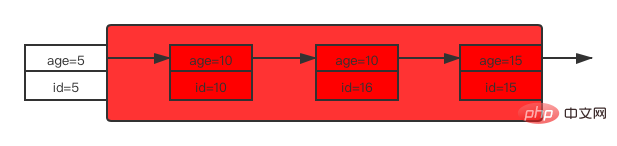
这时 user 表的索引 age 结构如下图所示:

在索引 age 中可能存在的行锁是4个记录锁以及5个间隙锁。
先来看索引 age 上的加锁情况:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where age=10 for update; | |
| insert into user values (2,'达达',2); | |
| update user set name='痛仰' where age=5; | |
| insert into user values (6,'达达',6);(Blocked) | |
| update user set name='痛仰' where age=10 and id=10;(Blocked) | |
| update user set name='痛仰' where age=10 and id=16;)(Blocked) | |
| insert into user values (17,'达达',10);(Blocked) | |
| insert into user values (11,'达达',11);(Blocked) | |
| update user set name='痛仰' where age=15; | |
| insert into user values (16,'面孔',16) ; |
Nach den Anweisungen und Ausführungsergebnissen in der obigen Tabelle zu urteilen, ist die Sperrsituation für das Indexalter:
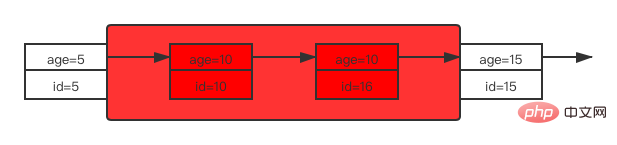
Das heißt, der Sperrbereich für das Indexalter beträgt (5, 15).
Da gewöhnliche Indizes die Eindeutigkeit von Datensätzen nicht bestimmen können, findet in gewöhnlichen Indexspaltenäquivalentabfragen beim Sperren des Indexalters den ersten Alterswert kleiner als 10 (d. h. 5) und den ersten Alterswert größer als 10. Der Wert (d. h. 15) Lücken innerhalb dieses Bereichs werden mit Lückensperren hinzugefügt und Datensätze werden mit Datensatzsperren hinzugefügt .
Dies ist die Sperrsituation für das Indexalter. Da die Abfrageanweisung alle Spalten des Datensatzes abfragen soll, wird gemäß den Abfrageregeln der entsprechende ID-Wert für das Indexalter zur Ausführung an den Primärschlüssel-Indexbaum zurückgegeben eine Tabellenrückgabeoperation, um alle Spalten abzurufen, daher werden auch Sperren für den Primärschlüsselindex gesetzt. Hier sind die Primärschlüssel-IDs der Datensätze, die alter=10 erfüllen, 10 bzw. 16, sodass diese beiden Zeilen ebenfalls ausschließlich für den Primärschlüsselindex gesperrt werden.
Das heißt, wenn eine normale Indexspaltenäquivalentabfrage an die Tabelle zurückgegeben werden muss, wird der Primärschlüssel, der dem Datensatz entspricht, der die Bedingungen erfüllt, ebenfalls mit einer Datensatzsperre hinzugefügt.
Wenn Sie hier
sessionA中的查询改为select id from user where age=10 lock in share mode;eingeben, wird der Tabellenrückgabevorgang aufgrund der Deckungsindexoptimierung nicht ausgeführt, sodass der Primärschlüsselindex nicht gesperrt wird. 2.4 Abfrage + Limit für gewöhnliche Indexspalten
begin;
| select * from user where age=10 limit 1 for update; | |
|---|---|
|
| In User Values einfügen (2,'da Da' , 2); Blockiert|
| Benutzersatznamen aktualisieren = 'Schmerz', wo Alter = 15; | |
| Es ist ersichtlich, dass: Limit-Syntax nur Datensätzen Sperren hinzufügt, die die Bedingungen erfüllen kann die Vergrößerung des Sperrbereichs verringern. | |
| Schauen wir uns als Nächstes die Bereichsabfrage für gewöhnliche Indexspalten an (hier wird nur der Sperrbereich des Indexalters besprochen. Durch das Sperren des Primärschlüsselindex wird der entsprechende ID-Wert gesperrt, falls vorhanden ist eine Rückgabetabelle): |
|
| sessionB |
|
| Blockiert | )
Blockiert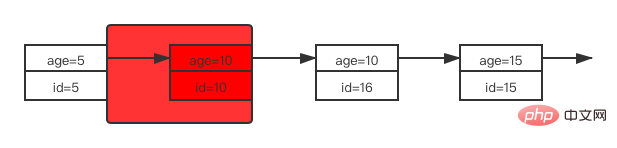 )
)
Benutzersatzname='Schmerz' aktualisieren, wobei Alter=15;(
Blockiert
)| Einfügen in Benutzerwerte (16,'Gesicht',16) ; | |
|---|---|
Das obige ist der detaillierte Inhalt vonMein Verständnis von MySQL fünf: Sperren und Sperrregeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- MySQL-Transaktionsverarbeitung mit hoher Parallelität und Sperrung
- Detaillierte Erläuterung der Schritte zur Handhabung von Sperrtransaktionen mit hoher Parallelität mit PHP+MySQL
- So sperren Sie Redis
- Wie implementiert man Sperren und Entsperren in PHP?
- Das heutige umfassende Verständnis der MySQL-Sperrtypen und Sperrprinzipien